
Ο ιστός ξεχειλίζει από πολύτιμα δεδομένα — είτε δουλεύετε στις πωλήσεις, στο ecommerce ή στην έρευνα αγοράς, το web scraping είναι το μυστικό όπλο για παραγωγή leads, παρακολούθηση τιμών και ανταγωνιστική ανάλυση. Όμως υπάρχει μια παγίδα: όσο περισσότερες επιχειρήσεις αξιοποιούν το scraping, τόσο πιο επιθετικά αντιδρούν οι ιστοσελίδες. Στην πραγματικότητα, πάνω από το , ενώ τα είναι πλέον ο κανόνας. Αν έχετε δει ποτέ το Python script σας να τρέχει ομαλά για 20 λεπτά και μετά ξαφνικά να πέφτει σε έναν τοίχο από 403 errors, ξέρετε πόσο πραγματική είναι η απογοήτευση.
Έχω περάσει χρόνια στο SaaS και στον αυτοματισμό και έχω δει από πρώτο χέρι πώς τα projects scraping μπορούν μέσα σε μια στιγμή να περάσουν από το «ουάου, αυτό είναι εύκολο» στο «γιατί με μπλοκάρουν παντού;». Ας μπούμε λοιπόν στα πρακτικά: θα σας δείξω πώς να κάνετε web scraping χωρίς να μπλοκάρεστε σε Python, θα μοιραστώ τις καλύτερες τεχνικές και αποσπάσματα κώδικα και θα δείξω πότε αξίζει να εξετάσετε εναλλακτικές με τεχνητή νοημοσύνη όπως το . Είτε είστε έμπειρος Python developer είτε απλώς τα βγάζετε πέρα με scraping, θα φύγετε με ένα toolbox για αξιόπιστη εξαγωγή δεδομένων χωρίς μπλοκαρίσματα.
Τι σημαίνει Web Scraping χωρίς να μπλοκάρεστε σε Python;
Στον πυρήνα του, το web scraping χωρίς μπλοκάρισμα σημαίνει εξαγωγή δεδομένων από ιστοσελίδες με τρόπο που δεν ενεργοποιεί τους μηχανισμούς άμυνας κατά των bots. Στον κόσμο της Python, αυτό δεν αφορά μόνο ένα loop με requests.get() — αφορά το να περνάτε απαρατήρητοι, να μιμείστε πραγματικούς χρήστες και να μένετε ένα βήμα μπροστά από τα συστήματα ανίχνευσης.
Γιατί Python; Η — χάρη στην απλή σύνταξή της, το τεράστιο οικοσύστημά της (σκεφτείτε: requests, BeautifulSoup, Scrapy, Selenium) και την ευελιξία της για τα πάντα, από μικρά scripts μέχρι κατανεμημένους crawlers. Όμως η δημοφιλία έχει και τίμημα: πολλά anti-bot συστήματα είναι πλέον ρυθμισμένα να εντοπίζουν μοτίβα scraping που βασίζονται σε Python.
Άρα, αν θέλετε αξιόπιστο scraping, πρέπει να πάτε πέρα από τα βασικά. Αυτό σημαίνει να καταλάβετε πώς οι ιστότοποι ανιχνεύουν bots και πώς μπορείτε να τους ξεγελάσετε — χωρίς να ξεπεράσετε ηθικά ή νομικά όρια.
Γιατί έχει σημασία να αποφεύγετε τα μπλοκαρίσματα στα Python web scraping projects
Το να μπλοκαριστείτε δεν είναι απλώς ένα τεχνικό εμπόδιο — μπορεί να εκτροχιάσει ολόκληρες επιχειρηματικές ροές εργασίας. Ας το δούμε πιο καθαρά:
| Χρήση | Επίπτωση του να μπλοκαριστείτε |
|---|---|
| Παραγωγή Leads | Ελλιπείς ή παρωχημένες λίστες υποψήφιων πελατών, απώλεια πωλήσεων |
| Παρακολούθηση Τιμών | Χαμένες αλλαγές τιμών ανταγωνιστών, κακές αποφάσεις τιμολόγησης |
| Συγκέντρωση Περιεχομένου | Κενά σε ειδήσεις, κριτικές ή ερευνητικά δεδομένα |
| Market Intelligence | Τυφλά σημεία στην παρακολούθηση ανταγωνιστών ή κλάδου |
| Αγγελίες Ακινήτων | Ανακριβή ή ξεπερασμένα δεδομένα ακινήτων, χαμένες ευκαιρίες |
Όταν ένα scraper μπλοκάρεται, δεν χάνετε απλώς δεδομένα — σπαταλάτε πόρους, ρισκάρετε θέματα συμμόρφωσης και πιθανόν παίρνετε λάθος επιχειρηματικές αποφάσεις με βάση ελλιπείς πληροφορίες. Σε έναν κόσμο όπου το , η αξιοπιστία είναι το παν.
Πώς οι ιστοσελίδες εντοπίζουν και μπλοκάρουν Python web scrapers
Οι ιστοσελίδες έχουν γίνει πολύ πιο έξυπνες στο να εντοπίζουν bots. Ακολουθούν οι πιο συνηθισμένες άμυνες κατά του scraping που θα συναντήσετε (, ):
- IP Address Blacklisting: Υπερβολικά πολλά αιτήματα από το ίδιο IP; Μπλοκάρεται.
- Έλεγχοι User-Agent και Headers: Αιτήματα με ελλιπή ή γενικά headers (όπως το προεπιλεγμένο
python-requests/2.25.1) ξεχωρίζουν. - Rate Limiting: Πάρα πολλά αιτήματα σε σύντομο χρονικό διάστημα ενεργοποιούν throttling ή bans.
- CAPTCHAs: Παζλ του τύπου «αποδείξτε ότι είστε άνθρωπος» που τα bots δεν μπορούν να λύσουν εύκολα.
- Behavioral Analysis: Τα sites παρακολουθούν ρομποτικά μοτίβα — για παράδειγμα, το ίδιο κλικ στο ίδιο χρονικό διάστημα.
- Honeypots: Κρυφοί σύνδεσμοι ή πεδία με τα οποία αλληλεπιδρούν μόνο bots.
- Browser Fingerprinting: Συλλογή λεπτομερειών για το πρόγραμμα περιήγησής σας και τη συσκευή σας για εντοπισμό εργαλείων αυτοματισμού.
- Cookie και Session Tracking: Bots που δεν χειρίζονται σωστά cookies ή sessions γίνονται γρήγορα αντιληπτά.
Σκεφτείτε το σαν έλεγχο ασφαλείας σε αεροδρόμιο: αν μοιάζετε, συμπεριφέρεστε και κινείστε όπως όλοι οι άλλοι, περνάτε χωρίς πρόβλημα. Αν εμφανιστείτε με καμπαρντίνα και γυαλιά ηλίου, περιμένετε περισσότερες ερωτήσεις.
Βασικές τεχνικές Python για Web Scraping χωρίς μπλοκαρίσματα
Πάμε στα ουσιαστικά: πώς να αποφεύγετε πρακτικά τα μπλοκαρίσματα όταν κάνετε scraping με Python. Αυτές είναι οι βασικές στρατηγικές που πρέπει να γνωρίζει κάθε scraper:

Εναλλασσόμενα Proxies και IP Addresses
Γιατί έχει σημασία: Αν όλα τα αιτήματά σας προέρχονται από το ίδιο IP, είστε εύκολος στόχος για IP bans. Τα rotating proxies σάς επιτρέπουν να μοιράζετε τα αιτήματα σε πολλά IP, κάνοντας πολύ δυσκολότερο τον αποκλεισμό σας.
Πώς να το κάνετε σε Python:
1import requests
2proxies = [
3 "<http://proxy1.example.com:8000>",
4 "<http://proxy2.example.com:8000>",
5 # ...more proxies
6]
7for i, url in enumerate(urls):
8 proxy = {"http": proxies[i % len(proxies)]}
9 response = requests.get(url, proxies=proxy)
10 # process responseΜπορείτε να χρησιμοποιήσετε επί πληρωμή proxy services (όπως residential ή rotating proxies) για μεγαλύτερη αξιοπιστία ().
Ρύθμιση User-Agent και Προσαρμοσμένων Headers
Γιατί έχει σημασία: Τα προεπιλεγμένα headers της Python φωνάζουν «bot». Μιμηθείτε πραγματικά browsers ορίζοντας user-agent και άλλα headers.
Παράδειγμα κώδικα:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9",
4 "Accept-Encoding": "gzip, deflate, br",
5 "Connection": "keep-alive"
6}
7response = requests.get(url, headers=headers)Εναλλάσσετε τα user-agents για περισσότερη μυστικότητα ().
Τυχαίος Χρονισμός και Μοτίβα Αιτημάτων
Γιατί έχει σημασία: Τα bots είναι γρήγορα και προβλέψιμα· οι άνθρωποι είναι πιο αργοί και πιο τυχαίοι. Προσθέστε καθυστερήσεις και αλλάξτε την πλοήγησή σας.
Python tip:
1import time, random
2for url in urls:
3 response = requests.get(url)
4 time.sleep(random.uniform(2, 7)) # Περιμένετε 2–7 δευτερόλεπταΜπορείτε επίσης να τυχαιοποιείτε τα click paths και τα scroll patterns αν χρησιμοποιείτε Selenium.
Διαχείριση Cookies και Sessions
Γιατί έχει σημασία: Πολλά sites απαιτούν cookies ή session tokens για πρόσβαση στο περιεχόμενο. Τα bots που τα αγνοούν μπλοκάρονται.
Πώς να το χειριστείτε σε Python:
1import requests
2session = requests.Session()
3response = session.get(url)
4# session will handle cookies automaticallyΓια πιο σύνθετες ροές, χρησιμοποιήστε Selenium για να καταγράψετε και να επαναχρησιμοποιήσετε cookies.
Προσομοίωση Ανθρώπινης Συμπεριφοράς με Headless Browsers
Γιατί έχει σημασία: Ορισμένα sites χρησιμοποιούν JavaScript, κίνηση ποντικιού ή scrolling ως σήματα πραγματικών χρηστών. Headless browsers όπως το Selenium ή το Playwright μπορούν να μιμηθούν αυτές τις ενέργειες.
Παράδειγμα με Selenium:
1from selenium import webdriver
2from selenium.webdriver.common.action_chains import ActionChains
3import random, time
4driver = webdriver.Chrome()
5driver.get(url)
6actions = ActionChains(driver)
7actions.move_by_offset(random.randint(0, 100), random.randint(0, 100)).perform()
8time.sleep(random.uniform(2, 5))Αυτό σας βοηθά να παρακάμψετε το behavioral analysis και το δυναμικό περιεχόμενο ().
Προηγμένες στρατηγικές: Παράκαμψη CAPTCHAs και Honeypots σε Python
Τα CAPTCHAs έχουν σχεδιαστεί για να σταματούν τα bots επιτόπου. Αν και ορισμένες Python βιβλιοθήκες μπορούν να λύσουν απλά CAPTCHAs, οι περισσότεροι σοβαροί scrapers βασίζονται σε υπηρεσίες τρίτων (όπως 2Captcha ή Anti-Captcha) για να τα λύσουν με χρέωση ().
Παράδειγμα ενσωμάτωσης:
1# Pseudocode for using 2Captcha API
2import requests
3captcha_id = requests.post("<https://2captcha.com/in.php>", data={...}).text
4# Περιμένετε τη λύση και στη συνέχεια υποβάλετέ την μαζί με το αίτημά σαςΤα Honeypots είναι κρυφά πεδία ή σύνδεσμοι με τους οποίους θα αλληλεπιδράσουν μόνο bots. Αποφύγετε να κάνετε κλικ ή να υποβάλετε οτιδήποτε δεν είναι ορατό σε έναν πραγματικό browser ().
Σχεδιασμός ανθεκτικών request headers με Python libraries
Πέρα από το user-agent, μπορείτε να εναλλάσσετε και να τυχαιοποιείτε άλλα headers (όπως Referer, Accept, Origin κ.ά.) για να περνάτε ακόμη πιο απαρατήρητοι.
Με Scrapy:
1class MySpider(scrapy.Spider):
2 custom_settings = {
3 'DEFAULT_REQUEST_HEADERS': {
4 'User-Agent': '...',
5 'Accept-Language': 'en-US,en;q=0.9',
6 # More headers
7 }
8 }Με Selenium: Χρησιμοποιήστε browser profiles ή extensions για να ορίσετε headers ή κάντε injection μέσω JavaScript.
Κρατήστε τη λίστα των headers ενημερωμένη — αντιγράψτε πραγματικά browser requests από τα DevTools του browser για έμπνευση.
Όταν το παραδοσιακό Python scraping δεν αρκεί: Η άνοδος της anti-bot τεχνολογίας
Η πραγματικότητα είναι η εξής: όσο πιο δημοφιλές γίνεται το scraping, τόσο αναβαθμίζονται και οι anti-bot άμυνες. . Η ανίχνευση με τεχνητή νοημοσύνη, τα δυναμικά thresholds αιτημάτων και το browser fingerprinting κάνουν πιο δύσκολο από ποτέ ακόμη και για προχωρημένα Python scripts να περνούν απαρατήρητα ().
Κάποιες φορές, όσο έξυπνος κι αν είναι ο κώδικάς σας, θα φτάσετε σε αδιέξοδο. Εκεί είναι που αξίζει να εξετάσετε μια διαφορετική προσέγγιση.
Thunderbit: μια εναλλακτική AI Web Scraper αντί για Python scraping
Όταν η Python φτάνει στα όριά της, το έρχεται ως no-code, AI-powered web scraper σχεδιασμένο για επαγγελματίες χρήστες — όχι μόνο για developers. Αντί να παλεύετε με proxies, headers και CAPTCHAs, ο AI agent του Thunderbit διαβάζει την ιστοσελίδα, προτείνει τα καλύτερα πεδία για εξαγωγή και χειρίζεται τα πάντα, από πλοήγηση σε subpages μέχρι εξαγωγή δεδομένων.
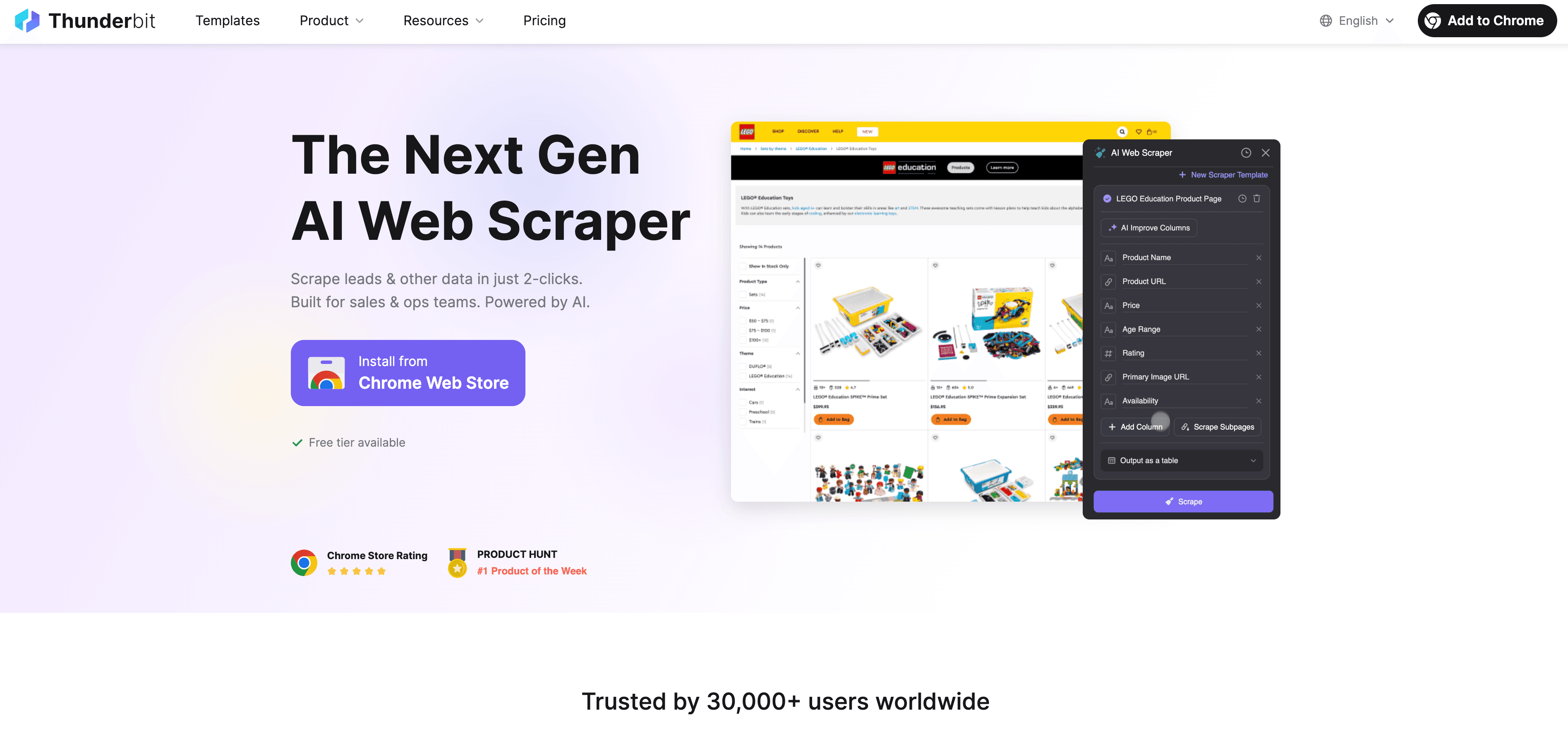
Τι κάνει το Thunderbit διαφορετικό;
- AI Field Suggestion: Κάντε κλικ στο “AI Suggest Fields” και το Thunderbit σαρώνει τη σελίδα, προτείνει στήλες και δημιουργεί ακόμη και οδηγίες εξαγωγής.
- Subpage Scraping: Το Thunderbit μπορεί να επισκεφθεί κάθε subpage (όπως λεπτομέρειες προϊόντων ή προφίλ LinkedIn) και να εμπλουτίσει αυτόματα τον πίνακά σας.
- Cloud ή Browser Scraping: Επιλέξτε την ταχύτερη επιλογή — cloud για δημόσια sites, browser για σελίδες με login.
- Scheduled Scraping: Το ρυθμίζετε μία φορά και το ξεχνάτε — το Thunderbit μπορεί να κάνει scraping σε πρόγραμμα, ώστε τα δεδομένα σας να παραμένουν πάντα φρέσκα.
- Άμεσα Templates: Για δημοφιλή sites (Amazon, Zillow, Shopify κ.λπ.), το Thunderbit προσφέρει templates με ένα κλικ — χωρίς καμία ρύθμιση.
- Δωρεάν Εξαγωγή Δεδομένων: Εξαγωγή σε Excel, Google Sheets, Airtable ή Notion — χωρίς επιπλέον χρεώσεις.
Το Thunderbit το εμπιστεύονται πάνω από , και δεν χρειάζεται να γράψετε ούτε μία γραμμή κώδικα.
Πώς το Thunderbit βοηθά τους χρήστες να αποφεύγουν μπλοκαρίσματα και να αυτοματοποιούν την εξαγωγή δεδομένων
Το AI του Thunderbit δεν μιμείται απλώς ανθρώπινη συμπεριφορά — προσαρμόζεται σε κάθε site σε πραγματικό χρόνο, μειώνοντας τον κίνδυνο μπλοκαρίσματος. Δείτε πώς:
- Το AI προσαρμόζεται σε αλλαγές διάταξης: Τέλος τα σπασμένα scripts όταν ένα site αλλάζει design.
- Χειρισμός subpages και pagination: Το Thunderbit ακολουθεί αυτόματα συνδέσμους και λίστες με σελιδοποίηση, όπως ένας πραγματικός χρήστης.
- Cloud scraping σε μεγάλη κλίμακα: Κάντε scrape έως και 50 σελίδες ταυτόχρονα, με αστραπιαία ταχύτητα.
- Χωρίς κώδικα, χωρίς συντήρηση: Αφιερώστε τον χρόνο σας στην ανάλυση, όχι στο debugging.
Για πιο αναλυτική ματιά, δείτε το .
Σύγκριση Python Scraping vs. Thunderbit: Ποιο να επιλέξετε;
Ας τα βάλουμε δίπλα δίπλα:
| Χαρακτηριστικό | Python Scraping | Thunderbit |
|---|---|---|
| Χρόνος Ρύθμισης | Μέτριος–Υψηλός (scripts, proxies κ.λπ.) | Χαμηλός (2 κλικ, το AI κάνει τα υπόλοιπα) |
| Τεχνική Εμπειρία | Απαιτείται κώδικας | Δεν χρειάζεται κώδικας |
| Αξιοπιστία | Διαφέρει (εύκολα σπάει) | Υψηλή (το AI προσαρμόζεται στις αλλαγές) |
| Κίνδυνος Μπλοκαρίσματος | Μέτριος–Υψηλός | Χαμηλός (το AI μιμείται χρήστη, προσαρμόζεται) |
| Κλιμάκωση | Χρειάζεται custom code/cloud setup | Ενσωματωμένο cloud/batch scraping |
| Συντήρηση | Συχνή (αλλαγές site, μπλοκαρίσματα) | Ελάχιστη (το AI προσαρμόζεται αυτόματα) |
| Επιλογές Εξαγωγής | Χειροκίνητες (CSV, DB) | Άμεση εξαγωγή σε Sheets, Notion, Airtable, CSV |
| Κόστος | Δωρεάν (αλλά χρονοβόρο) | Δωρεάν πακέτο, επί πληρωμή πλάνα για κλίμακα |
Πότε να χρησιμοποιήσετε Python:
- Χρειάζεστε πλήρη έλεγχο, προσαρμοσμένη λογική ή ενσωμάτωση με άλλα Python workflows.
- Κάνετε scraping σε sites με ελάχιστες άμυνες κατά των bots.
Πότε να χρησιμοποιήσετε Thunderbit:
- Θέλετε ταχύτητα, αξιοπιστία και μηδενική ρύθμιση.
- Κάνετε scraping σε σύνθετα ή συχνά μεταβαλλόμενα sites.
- Δεν θέλετε να ασχολείστε με proxies, CAPTCHAs ή κώδικα.
Βήμα προς βήμα οδηγός: Ρύθμιση Web Scraping χωρίς μπλοκάρισμα σε Python
Ας δούμε ένα πρακτικό παράδειγμα: scraping δεδομένων προϊόντων από ένα δείγμα site, εφαρμόζοντας παράλληλα βέλτιστες πρακτικές κατά των μπλοκαρισμάτων.
1. Εγκαταστήστε τις απαραίτητες βιβλιοθήκες
1pip install requests beautifulsoup4 fake-useragent2. Προετοιμάστε το script σας
1import requests
2from bs4 import BeautifulSoup
3from fake_useragent import UserAgent
4import time, random
5ua = UserAgent()
6urls = ["<https://example.com/product/1>", "<https://example.com/product/2>"] # Αντικαταστήστε με τα URLs σας
7for url in urls:
8 headers = {
9 "User-Agent": ua.random,
10 "Accept-Language": "en-US,en;q=0.9"
11 }
12 response = requests.get(url, headers=headers)
13 if response.status_code == 200:
14 soup = BeautifulSoup(response.text, "html.parser")
15 # Εξάγετε τα δεδομένα εδώ
16 print(soup.title.text)
17 else:
18 print(f"Blocked or error on {url}: {response.status_code}")
19 time.sleep(random.uniform(2, 6)) # Τυχαία καθυστέρηση3. Προσθέστε εναλλαγή proxy (προαιρετικά)
1proxies = [
2 "<http://proxy1.example.com:8000>",
3 "<http://proxy2.example.com:8000>",
4 # Περισσότερα proxies
5]
6for i, url in enumerate(urls):
7 proxy = {"http": proxies[i % len(proxies)]}
8 headers = {"User-Agent": ua.random}
9 response = requests.get(url, headers=headers, proxies=proxy)
10 # ...υπόλοιπος κώδικας4. Χειριστείτε cookies και sessions
1session = requests.Session()
2for url in urls:
3 response = session.get(url, headers=headers)
4 # ...υπόλοιπος κώδικας5. Συμβουλές αντιμετώπισης προβλημάτων
- Αν βλέπετε πολλά σφάλματα 403/429, επιβραδύνετε τα αιτήματά σας ή δοκιμάστε νέα proxies.
- Αν συναντήσετε CAPTCHAs, σκεφτείτε να χρησιμοποιήσετε Selenium ή μια υπηρεσία επίλυσης CAPTCHA.
- Ελέγχετε πάντα το
robots.txtτου site και τους όρους χρήσης.
Συμπέρασμα και βασικά σημεία
Το web scraping σε Python είναι ισχυρό — αλλά το μπλοκάρισμα παραμένει μόνιμος κίνδυνος όσο εξελίσσεται η anti-bot τεχνολογία. Ο καλύτερος τρόπος να αποφεύγετε τα μπλοκαρίσματα; Συνδυάστε τεχνικές βέλτιστες πρακτικές (rotating proxies, έξυπνα headers, τυχαίες καθυστερήσεις, διαχείριση sessions και headless browsers) με σεβασμό στους κανόνες και την ηθική των sites.
Όμως κάποιες φορές, ακόμη και τα καλύτερα Python tricks δεν αρκούν. Εκεί ξεχωρίζουν εργαλεία με AI όπως το — προσφέροντας έναν no-code, ανθεκτικό στα μπλοκαρίσματα και φιλικό προς τις επιχειρήσεις τρόπο για να εξάγετε γρήγορα τα δεδομένα που χρειάζεστε.
Θέλετε να δείτε πόσο εύκολο μπορεί να γίνει το scraping; και δοκιμάστε το μόνοι σας — ή δείτε το μας για περισσότερες συμβουλές και οδηγούς scraping.
Συχνές Ερωτήσεις
1. Γιατί οι ιστοσελίδες μπλοκάρουν Python web scrapers;
Οι ιστοσελίδες μπλοκάρουν scrapers για να προστατεύσουν τα δεδομένα τους, να αποτρέψουν υπερφόρτωση των servers και να σταματήσουν τα αυτοματοποιημένα bots από το να καταχρώνται τις υπηρεσίες τους. Τα Python scripts εντοπίζονται εύκολα αν χρησιμοποιούν προεπιλεγμένα headers, δεν χειρίζονται cookies ή στέλνουν πάρα πολλά αιτήματα πολύ γρήγορα.
2. Ποιοι είναι οι πιο αποτελεσματικοί τρόποι να αποφεύγετε το μπλοκάρισμα όταν κάνετε scraping με Python;
Χρησιμοποιήστε rotating proxies, ορίστε ρεαλιστικά user-agent και headers, τυχαιοποιήστε τον χρόνο των αιτημάτων, διαχειριστείτε cookies/sessions και προσομοιώστε ανθρώπινη συμπεριφορά με εργαλεία όπως το Selenium ή το Playwright.
3. Πώς βοηθά το Thunderbit να αποφεύγετε μπλοκαρίσματα σε σύγκριση με τα Python scripts;
Το Thunderbit χρησιμοποιεί AI για να προσαρμόζεται στη διάταξη των sites, να μιμείται ανθρώπινη περιήγηση και να χειρίζεται αυτόματα subpages και pagination. Μειώνει τον κίνδυνο μπλοκαρίσματος επειδή περνά απαρατήρητο και ενημερώνει την προσέγγισή του σε πραγματικό χρόνο — χωρίς να χρειάζονται κώδικας ή proxies.
4. Πότε πρέπει να χρησιμοποιήσω Python scraping και πότε ένα AI εργαλείο όπως το Thunderbit;
Χρησιμοποιήστε Python όταν χρειάζεστε προσαρμοσμένη λογική, ενσωμάτωση με άλλο Python code ή όταν κάνετε scraping σε απλά sites. Χρησιμοποιήστε το Thunderbit για γρήγορο, αξιόπιστο και κλιμακούμενο scraping — ειδικά όταν τα sites είναι σύνθετα, αλλάζουν συχνά ή μπλοκάρουν επιθετικά τα scripts.
5. Είναι νόμιμο το web scraping;
Το web scraping είναι νόμιμο για δημόσια διαθέσιμα δεδομένα, αλλά πρέπει να σέβεστε τους όρους χρήσης, τις πολιτικές απορρήτου και τους σχετικούς νόμους κάθε site. Ποτέ μη κάνετε scraping σε ευαίσθητα ή ιδιωτικά δεδομένα και να ενεργείτε πάντα ηθικά και υπεύθυνα.
Έτοιμοι να κάνετε scraping πιο έξυπνα και όχι πιο δύσκολα; Δοκιμάστε το Thunderbit και αφήστε τα μπλοκαρίσματα πίσω σας.
Μάθετε περισσότερα:
- Scraping Google News με Python: Ένας βήμα-προς-βήμα οδηγός
- Δημιουργήστε ένα εργαλείο παρακολούθησης τιμών Best Buy με Python
- 14 τρόποι για Web Scraping χωρίς μπλοκάρισμα
- 10 κορυφαίες συμβουλές για το πώς να μην μπλοκαριστείτε όταν κάνετε Web Scraping