
Υπάρχει κάτι πραγματικά διαχρονικό στο να ανοίγεις ένα terminal, να γράφεις μία και μόνο εντολή και να βλέπεις τα «ωμά» web δεδομένα να σκάνε μπροστά σου—λες και άνοιξες μια χαραμάδα στο Matrix. Για developers και πιο προχωρημένους τεχνικούς χρήστες, το είναι αυτό το μικρό «μαγικό ραβδί»: ένα λιτό command-line εργαλείο που τρέχει αθόρυβα σε δισεκατομμύρια συσκευές, από cloud servers μέχρι… το έξυπνο ψυγείο σου. Και ακόμη και το 2026, με όλα τα φανταχτερά no-code και AI εργαλεία scraping εκεί έξω, το web scraping με curl παραμένει κλασική επιλογή για όποιον θέλει ταχύτητα, έλεγχο και αυτοματοποίηση μέσω scripts.
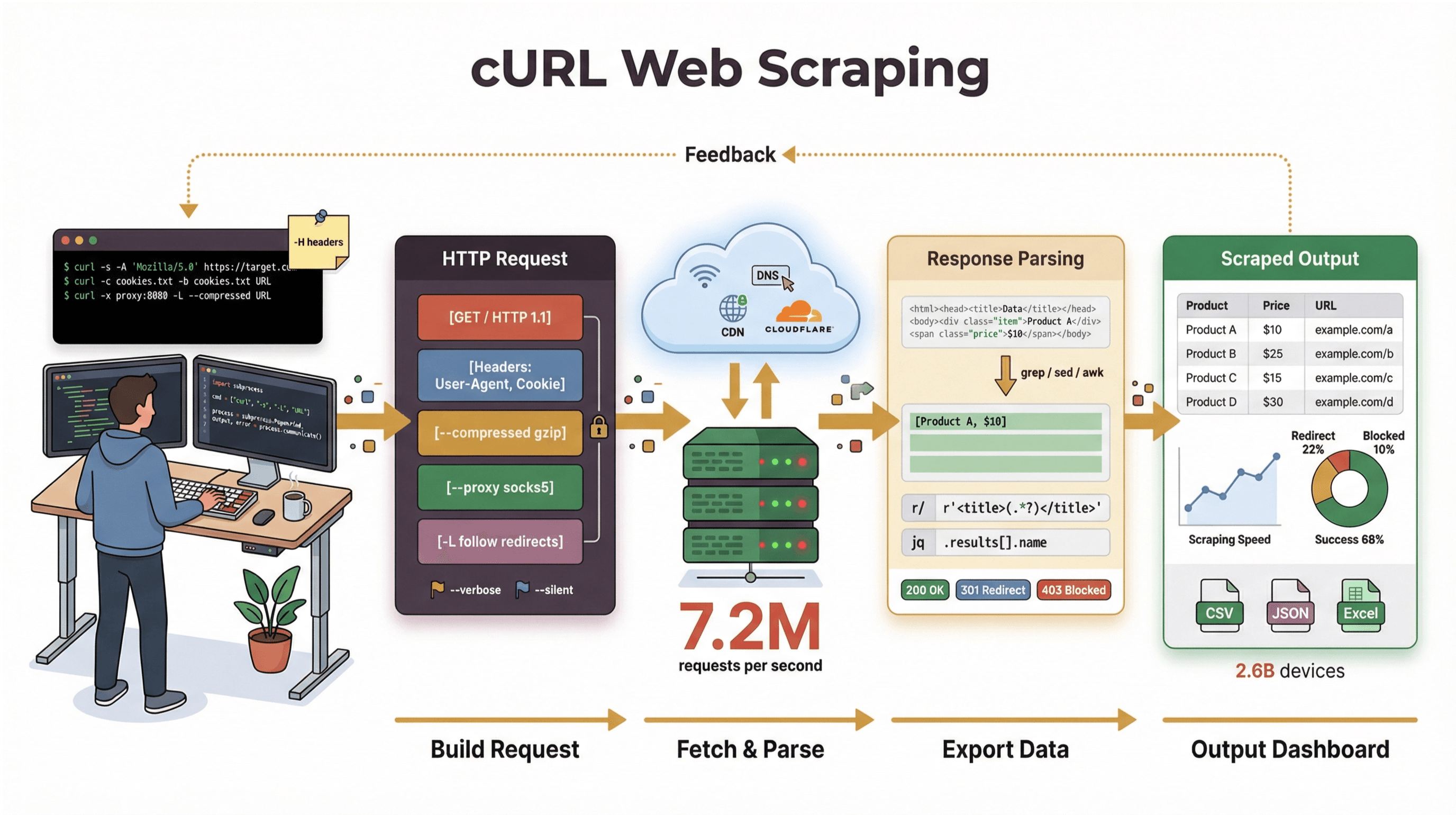 Έχω περάσει χρόνια φτιάχνοντας εργαλεία αυτοματοποίησης και βοηθώντας ομάδες να «δαμάσουν» web δεδομένα, και ακόμη πιάνω το cURL όταν θέλω να κατεβάσω μια σελίδα, να κάνω debug ένα API ή να στήσω στα γρήγορα ένα πρώτο scraping workflow. Σε αυτόν τον οδηγό θα σε πάω βήμα-βήμα σε ένα curl web scraping tutorial που πιάνει και τα βασικά και πιο προχωρημένα κόλπα—με αληθινά παραδείγματα εντολών, πρακτικά tips και μια ρεαλιστική εικόνα για το πού το cURL λάμπει (και πού «σκαλώνει»). Και αν είσαι περισσότερο business user και δεν θες να ακουμπήσεις καθόλου γραμμή εντολών, θα δεις πώς το , το AI-powered web scraper μας, σε πάει από το «χρειάζομαι αυτά τα δεδομένα» στο «ορίστε το spreadsheet» με δύο κλικ—χωρίς κώδικα.
Έχω περάσει χρόνια φτιάχνοντας εργαλεία αυτοματοποίησης και βοηθώντας ομάδες να «δαμάσουν» web δεδομένα, και ακόμη πιάνω το cURL όταν θέλω να κατεβάσω μια σελίδα, να κάνω debug ένα API ή να στήσω στα γρήγορα ένα πρώτο scraping workflow. Σε αυτόν τον οδηγό θα σε πάω βήμα-βήμα σε ένα curl web scraping tutorial που πιάνει και τα βασικά και πιο προχωρημένα κόλπα—με αληθινά παραδείγματα εντολών, πρακτικά tips και μια ρεαλιστική εικόνα για το πού το cURL λάμπει (και πού «σκαλώνει»). Και αν είσαι περισσότερο business user και δεν θες να ακουμπήσεις καθόλου γραμμή εντολών, θα δεις πώς το , το AI-powered web scraper μας, σε πάει από το «χρειάζομαι αυτά τα δεδομένα» στο «ορίστε το spreadsheet» με δύο κλικ—χωρίς κώδικα.
Πάμε να δούμε γιατί το cURL παραμένει επίκαιρο για web scraping το 2025, πώς να το αξιοποιήσεις σωστά και πότε αξίζει να στραφείς σε κάτι ακόμη πιο δυνατό.
Τι είναι το cURL; Η βάση του web-scraping-with-curl
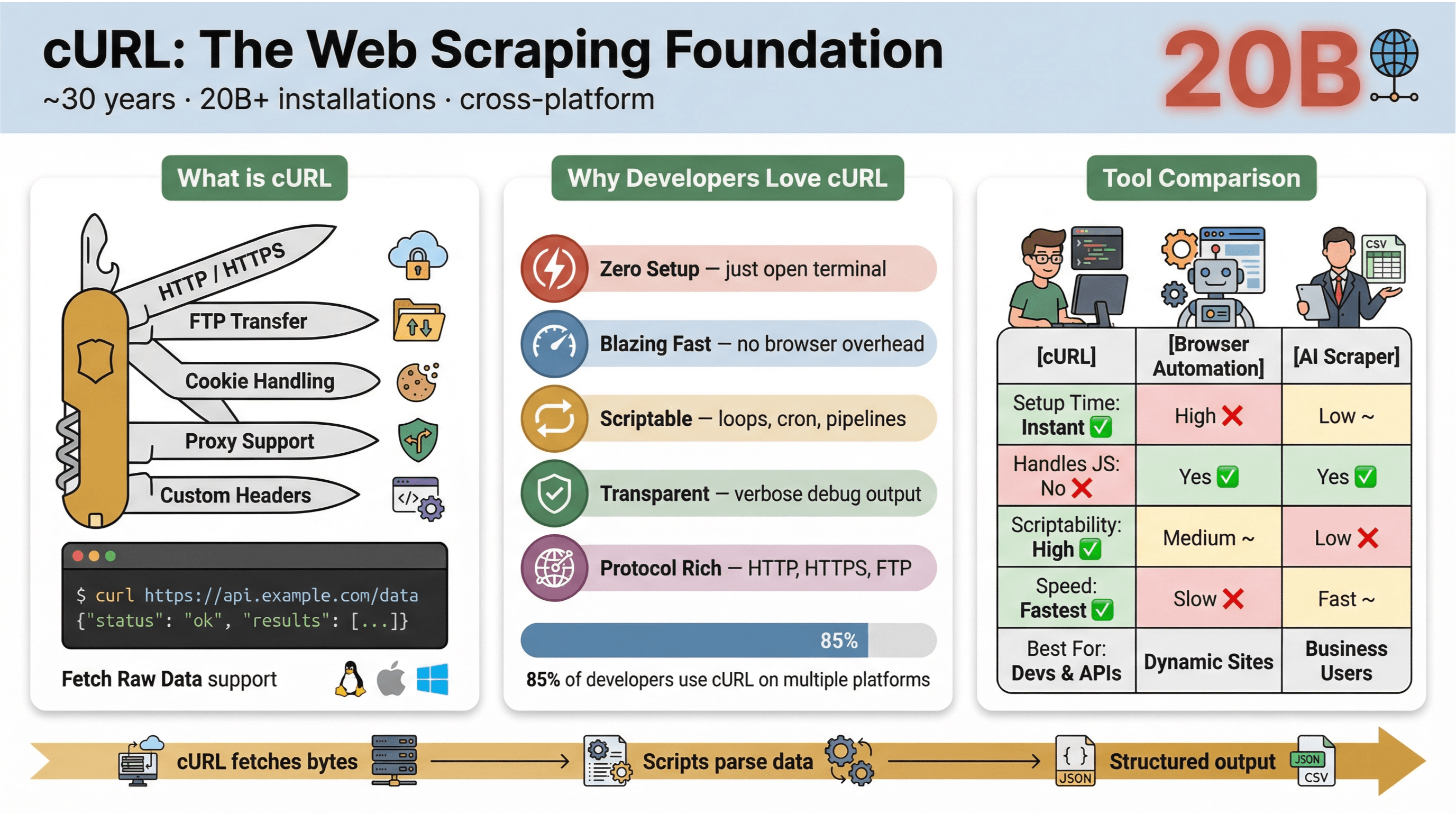
Στον πυρήνα του, το είναι εργαλείο και βιβλιοθήκη γραμμής εντολών για μεταφορά δεδομένων μέσω URLs. Υπάρχει εδώ και σχεδόν 30 χρόνια (ναι, όντως) και είναι παντού—ενσωματωμένο σε λειτουργικά συστήματα, τροφοδοτώντας scripts και σηκώνοντας μεταφορές δεδομένων σε πάνω από . Αν έχεις τρέξει ποτέ μια γρήγορη εντολή για να φέρεις μια web σελίδα, να τεστάρεις ένα API ή να κατεβάσεις ένα αρχείο, είναι πολύ πιθανό να έχεις χρησιμοποιήσει cURL.
 Να τι κάνει το cURL τόσο αγαπητό για web scraping:
Να τι κάνει το cURL τόσο αγαπητό για web scraping:
- Ελαφρύ και cross-platform: Τρέχει σε Linux, macOS, Windows, ακόμη και σε embedded συσκευές.
- Υποστήριξη πρωτοκόλλων: Διαχειρίζεται HTTP, HTTPS, FTP και άλλα.
- Ιδανικό για scripts: Τέλειο για αυτοματοποίηση, cron jobs και «glue code».
- Χωρίς αλληλεπίδραση χρήστη: Σχεδιασμένο για non-interactive χρήση—ιδανικό για batch jobs και pipelines.
Ας το πούμε ξεκάθαρα: η βασική δουλειά του cURL είναι να φέρνει «ωμά» δεδομένα—HTML, JSON, εικόνες, ό,τι θες. Δεν κάνει parsing, δεν κάνει render και δεν στα οργανώνει. Σκέψου το cURL σαν το «πρώτο χιλιόμετρο» του web scraping: σου φέρνει τα bytes, αλλά μετά θα χρειαστείς άλλα εργαλεία (π.χ. Python scripts, grep/sed/awk ή έναν AI web scraper) για να τα κάνεις δομημένη πληροφορία.
Αν θες τα επίσημα docs, δες τον οδηγό .
Γιατί να χρησιμοποιήσεις cURL για Web Scraping; (curl web scraping tutorial)
Γιατί λοιπόν developers και τεχνικοί χρήστες γυρνάνε ξανά και ξανά στο cURL για web scraping, παρότι υπάρχουν τόσα καινούρια εργαλεία; Αυτά είναι τα δυνατά του χαρτιά:
- Ελάχιστη προετοιμασία: Χωρίς εγκαταστάσεις, χωρίς dependencies—ανοίγεις terminal και ξεκινάς.
- Ταχύτητα: Φέρνεις δεδομένα άμεσα, χωρίς να περιμένεις να φορτώσει browser.
- Ευκολία αυτοματοποίησης: Κάνεις loop σε URLs, αυτοματοποιείς requests και «αλυσοδένεις» εντολές.
- Πλούσια υποστήριξη features: Cookies, proxies, redirects, custom headers και πολλά ακόμη.
- Διαφάνεια: Βλέπεις ακριβώς τι γίνεται με verbose/debug output.
Στην , πάνω από το 85% είπε ότι χρησιμοποιεί το cURL command-line tool, και σχεδόν όλοι ανέφεραν χρήση σε πολλαπλές πλατφόρμες. Παραμένει ο «ελβετικός σουγιάς» για HTTP requests, γρήγορα data pulls και troubleshooting.
Ακολουθεί μια σύντομη σύγκριση του cURL με άλλες μεθόδους scraping:
| Χαρακτηριστικό | cURL | Αυτοματοποίηση Browser (π.χ. Selenium) | AI Web Scraper (π.χ. Thunderbit) |
|---|---|---|---|
| Χρόνος Setup | Άμεσος | Υψηλός | Χαμηλός |
| Αυτοματισμός με scripts | Υψηλός | Μεσαίος | Χαμηλός (χωρίς κώδικα) |
| Υποστήριξη JavaScript | Όχι | Ναι | Ναι (Thunderbit: μέσω browser) |
| Cookies/Session Support | Χειροκίνητο | Αυτόματο | Αυτόματο |
| Δόμηση δεδομένων | Χειροκίνητη (μετά) | Χειροκίνητη (μετά) | Με AI/βάσει templates |
| Ιδανικό για | Devs, γρήγορα pulls | Σύνθετα, δυναμικά sites | Business users, δομημένο export |
Με λίγα λόγια: το cURL είναι ασυναγώνιστο για γρήγορα, scriptable «τραβήγματα» δεδομένων—ειδικά για στατικές σελίδες, APIs ή απλά workflows. Όμως, μόλις χρειαστείς parsing σύνθετου HTML, JavaScript ή δομημένη εξαγωγή, θα θες κάτι πιο εξειδικευμένο.
Ξεκινώντας: Βασικά παραδείγματα εντολών cURL για web scraping
Πάμε πρακτικά. Δες πώς χρησιμοποιείς το cURL για βασικές δουλειές web scraping, βήμα-βήμα.
Λήψη «ωμού» HTML με cURL
Η πιο απλή φάση: κατεβάζεις το HTML μιας σελίδας.
1curl https://books.toscrape.com/Η εντολή φέρνει την αρχική σελίδα του , ενός δημόσιου demo site για web scraping. Θα δεις το ακατέργαστο HTML στο terminal—ψάξε για tags όπως <title> ή αποσπάσματα όπως “In stock.”
Αποθήκευση εξόδου σε αρχείο
Θες να κρατήσεις το HTML για parsing αργότερα; Χρησιμοποίησε το -o:
1curl -o page.html https://books.toscrape.com/Τώρα θα έχεις ένα page.html με όλο το περιεχόμενο. Τέλειο για ανάλυση ή parsing με άλλα εργαλεία.
Αποστολή POST requests με cURL
Χρειάζεται να στείλεις φόρμα ή να μιλήσεις με API; Χρησιμοποίησε το -d για POST. Παράδειγμα με το , που είναι φτιαγμένο για HTTP testing:
1curl -X POST https://httpbin.org/post -d "key1=value1&key2=value2"Θα πάρεις JSON απάντηση που «αντανακλά» τα δεδομένα που έστειλες—ιδανικό για δοκιμές και πρωτότυπα.
Έλεγχος headers και debugging
Πολλές φορές θες να δεις τα response headers ή να κάνεις debug το request:
-
Μόνο headers (HEAD request):
1curl -I https://books.toscrape.com/ -
Headers μαζί με body:
1curl -i https://httpbin.org/get -
Verbose/debug output:
1curl -v https://books.toscrape.com/
Αυτά τα flags σε βοηθούν να καταλάβεις τι παίζει «πίσω από την κουρτίνα»—must για troubleshooting.
Γρήγορος πίνακας αναφοράς:
| Εργασία | Παράδειγμα εντολής | Σημειώσεις |
|---|---|---|
| Λήψη HTML | curl URL | Εμφανίζει HTML στο terminal |
| Αποθήκευση σε αρχείο | curl -o file.html URL | Γράφει την έξοδο σε αρχείο |
| Έλεγχος headers | curl -I URL ή curl -i URL | -I μόνο HEAD, -i headers μαζί με body |
| POST δεδομένα φόρμας | curl -d "a=1&b=2" URL | Στέλνει form-encoded δεδομένα |
| Debug request/response | curl -v URL | Δείχνει αναλυτικές πληροφορίες request/response |
Για περισσότερα παραδείγματα, δες τα .
Πάμε ένα επίπεδο πάνω: Προχωρημένο web scraping με cURL (web-scraping-with-curl)
Αφού νιώσεις άνετα με τα βασικά, το cURL σου ανοίγει πιο προχωρημένες δυνατότητες για πιο σύνθετα scraping σενάρια.
Διαχείριση cookies και sessions
Πολλά sites θέλουν cookies για να κρατάνε login sessions ή να παρακολουθούν χρήστες. Με cURL μπορείς να αποθηκεύεις και να ξαναχρησιμοποιείς cookies μεταξύ requests:
1# Αποθήκευση cookies μετά το login
2curl -c cookies.txt https://example.com/login
3# Χρήση cookies σε επόμενα requests
4curl -b cookies.txt https://example.com/accountΈτσι μιμείσαι browser sessions και μπαίνεις σε σελίδες πίσω από login (εφόσον δεν υπάρχει JavaScript challenge).
Μίμηση User-Agent και custom headers
Κάποια sites σερβίρουν διαφορετικό περιεχόμενο ανάλογα με User-Agent ή headers. Από default, το cURL δηλώνει “curl/VERSION”, κάτι που μπορεί να φέρει blocks ή «πειραγμένο» περιεχόμενο. Για να μοιάζει με browser:
1curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" https://example.com/Μπορείς επίσης να βάλεις custom headers, π.χ. γλώσσα:
1curl -H "Accept-Language: en-US,en;q=0.9" https://example.com/Έτσι αυξάνεις τις πιθανότητες να πάρεις το ίδιο περιεχόμενο που θα έβλεπε ένας κανονικός browser.
Χρήση proxies για web scraping
Θες να περάσεις τα requests από proxy (geo-testing ή αποφυγή IP bans); Χρησιμοποίησε το -x:
1curl -x http://proxy.example.org:4321 https://remote.example.org/Χρησιμοποίησε proxies υπεύθυνα και σύμφωνα με τους όρους χρήσης του site.
Αυτοματοποίηση scraping πολλών σελίδων
Θες να κατεβάσεις πολλές σελίδες—π.χ. paginated λίστες προϊόντων; Ένα απλό shell loop αρκεί:
1for p in $(seq 2 5); do
2 curl -s -o "books-page-${p}.html" \
3 "https://books.toscrape.com/catalogue/category/books_1/page-${p}.html"
4 sleep 1
5doneΑυτό κατεβάζει τις σελίδες 2 έως 5 του καταλόγου και τις αποθηκεύει σε ξεχωριστά αρχεία. (Η σελίδα 1 είναι η αρχική.)
Περιορισμοί του web-scraping-with-curl: Τι πρέπει να γνωρίζεις
Όσο κι αν γουστάρω το cURL, δεν είναι πανάκεια. Αυτά είναι τα σημεία που πονάει:
- Δεν εκτελεί JavaScript: Δεν μπορεί να χειριστεί σελίδες που θέλουν JavaScript για να εμφανίσουν περιεχόμενο ή να λύσουν anti-bot challenges ().
- Απαιτεί χειροκίνητο parsing: Παίρνεις HTML/JSON, αλλά πρέπει να το δουλέψεις μόνος σου—συνήθως με έξτρα scripts/εργαλεία.
- Περιορισμένη διαχείριση sessions: Πολύπλοκα logins, tokens ή multi-step φόρμες γίνονται γρήγορα «μπέρδεμα».
- Χωρίς ενσωματωμένη δόμηση δεδομένων: Δεν μετατρέπει σελίδες σε γραμμές/πίνακες/spreadsheets.
- Εύκολος στόχος για anti-bot ανίχνευση: Πολλά sites έχουν πλέον πιο «σκληρές» άμυνες (JavaScript, fingerprinting, CAPTCHAs) που το cURL δεν μπορεί να ξεπεράσει ().
Σύντομη σύγκριση:
| Περιορισμός | Μόνο cURL | Σύγχρονα εργαλεία scraping (π.χ. Thunderbit) |
|---|---|---|
| Υποστήριξη JavaScript | Όχι | Ναι |
| Δόμηση δεδομένων | Χειροκίνητη | Αυτόματη (AI/Template) |
| Διαχείριση sessions | Χειροκίνητη | Αυτόματη |
| Παράκαμψη anti-bot | Περιορισμένη | Προχωρημένη (browser-based/AI) |
| Ευκολία χρήσης | Τεχνική | Μη τεχνική |
Για στατικές σελίδες και APIs, το cURL είναι φοβερό. Για οτιδήποτε πιο δυναμικό ή προστατευμένο, θα χρειαστείς πιο «βαρύ» εργαλείο.
Thunderbit vs. cURL: Η καλύτερη προσέγγιση για μη τεχνικούς χρήστες
Ας μιλήσουμε τώρα για το , το AI-powered web scraper Chrome Extension μας. Αν είσαι σε πωλήσεις, marketing ή operations και απλώς θες να περάσεις δεδομένα από έναν ιστότοπος curl σε Excel, Google Sheets ή Notion—χωρίς να ακουμπήσεις terminal—το Thunderbit είναι κομμένο και ραμμένο για σένα.
Δες πώς στέκεται απέναντι στο cURL:
| Χαρακτηριστικό | cURL | Thunderbit |
|---|---|---|
| Περιβάλλον χρήσης | Γραμμή εντολών | Point-and-click (Chrome Extension) |
| AI πρόταση πεδίων | Όχι | Ναι (το AI διαβάζει τη σελίδα, προτείνει στήλες) |
| Pagination/Subpages | Χειροκίνητο scripting | Αυτόματο (το AI εντοπίζει και κάνει scraping) |
| Εξαγωγή δεδομένων | Χειροκίνητα (parse + save) | Απευθείας σε Excel, Google Sheets, Notion, Airtable |
| JavaScript/Protected pages | Όχι | Ναι (scraping μέσα από browser) |
| Χωρίς κώδικα | Όχι (θέλει scripting) | Ναι (το χρησιμοποιεί ο καθένας) |
| Δωρεάν χρήση | Πάντα δωρεάν | Δωρεάν έως 6 σελίδες (10 με trial boost) |
Με το Thunderbit, ανοίγεις το extension, πατάς “AI Suggest Fields” και αφήνεις το AI να αποφασίσει τι δεδομένα να εξάγει. Μπορείς να κάνεις scraping πίνακες, λίστες, λεπτομέρειες προϊόντων και ακόμη να επισκέπτεται subpages αυτόματα. Μετά κάνεις export απευθείας στα εργαλεία που ήδη χρησιμοποιείς—χωρίς parsing και χωρίς πονοκέφαλο.
Το Thunderbit το εμπιστεύονται πάνω από και είναι ιδιαίτερα δημοφιλές σε ομάδες πωλήσεων, ecommerce και real estate που θέλουν γρήγορα δομημένα δεδομένα.
Θες να το δοκιμάσεις; .
Συνδυάζοντας cURL και Thunderbit: Ευέλικτες στρατηγικές web scraping
Αν είσαι τεχνικός χρήστης, δεν χρειάζεται να κολλήσεις σε ένα μόνο εργαλείο. Στην πράξη, πολλές ομάδες παίζουν μπάλα με cURL και Thunderbit μαζί για μέγιστη ευελιξία:
- Πρωτότυπο με cURL: Γρήγορος έλεγχος endpoints, headers και συμπεριφοράς του site.
- Κλιμάκωση με Thunderbit: Όταν θες δομημένα δεδομένα, scraping πολλών σελίδων ή επαναλήψιμο workflow, περνάς στο Thunderbit για point-and-click εξαγωγή και άμεσο export.
Παράδειγμα workflow για market research:
- Χρησιμοποίησε cURL για να κατεβάσεις μερικές σελίδες και να δεις τη δομή του HTML.
- Εντόπισε τα πεδία που σε νοιάζουν (π.χ. ονόματα προϊόντων, τιμές, reviews).
- Άνοιξε το Thunderbit, πάτησε “AI Suggest Fields” και άφησε το AI να στήσει τον scraper.
- Κάνε scraping όλες τις σελίδες (και subpages ή paginated λίστες) και κάνε export σε Google Sheets.
- Ανάλυσε, μοιράσου και αξιοποίησε τα δεδομένα—χωρίς χειροκίνητο parsing.
Γρήγορος πίνακας απόφασης:
| Σενάριο | cURL | Thunderbit | Και τα δύο |
|---|---|---|---|
| Γρήγορο fetch API ή στατικής σελίδας | ✅ | ||
| Δομημένα δεδομένα σε spreadsheet | ✅ | ||
| Debugging headers/cookies | ✅ | ||
| Δυναμικές/JS-heavy σελίδες | ✅ | ||
| Επαναλήψιμο no-code workflow | ✅ | ||
| Πρωτότυπο και μετά κλιμάκωση | ✅ | ✅ | Υβριδικό workflow |
Συνηθισμένες δυσκολίες και παγίδες στο web scraping με cURL
Πριν το παρακάνεις με το cURL, αξίζει να δεις τις πραγματικές δυσκολίες που θα βρεις μπροστά σου:
- Anti-bot συστήματα: Πολλά sites έχουν πλέον προηγμένες άμυνες (JavaScript challenges, CAPTCHAs, fingerprinting) που το cURL δεν μπορεί να παρακάμψει ().
- Θέματα ποιότητας δεδομένων: Αλλαγές στο HTML, ελλείποντα πεδία ή ασυνεπείς δομές μπορούν να «σπάσουν» τα scripts.
- Κόστος συντήρησης: Κάθε αλλαγή στο site σημαίνει update στη λογική parsing.
- Νομικοί/συμμορφωτικοί κίνδυνοι: Τσέκαρε πάντα όρους χρήσης, robots.txt και σχετική νομοθεσία πριν κάνεις scraping. Το ότι κάτι είναι δημόσιο δεν σημαίνει ότι μπορείς να το χρησιμοποιήσεις όπως θες (, ).
- Όρια κλιμάκωσης: Το cURL είναι τέλειο για μικρές δουλειές, αλλά σε μεγάλης κλίμακας scraping θα χρειαστείς διαχείριση proxies, rate limits και error handling.
Συμβουλές για troubleshooting και συμμόρφωση:
- Ξεκίνα πάντα από sites με άδεια ή demo (όπως το ).
- Σεβάσου τα rate limits—μη «βαράς» endpoints.
- Απόφυγε scraping προσωπικών δεδομένων αν δεν έχεις νόμιμη βάση.
- Αν πέσεις σε JavaScript ή CAPTCHA, σκέψου να πας σε browser-based εργαλείο όπως το Thunderbit.
Σύνοψη βήμα-βήμα: Πώς να κάνεις Web Scraping με cURL
Checklist γρήγορης αναφοράς για web-scraping-with-curl:
- Εντόπισε το/τα URL στόχου: Ξεκίνα από στατική σελίδα ή API endpoint.
- Φέρε τη σελίδα:
curl URL - Αποθήκευσε την έξοδο σε αρχείο:
curl -o file.html URL - Δες headers/debug:
curl -I URL,curl -v URL - Στείλε POST δεδομένα:
curl -d "a=1&b=2" URL - Χειρίσου cookies/sessions:
curl -c cookies.txt ...,curl -b cookies.txt ... - Όρισε custom headers/User-Agent:
curl -A "..." -H "..." URL - Ακολούθησε redirects:
curl -L URL - Χρησιμοποίησε proxies (αν χρειάζεται):
curl -x proxy:port URL - Αυτοματοποίησε multi-page scraping: Με shell loops ή scripts.
- Κάνε parsing και δόμηση δεδομένων: Με επιπλέον εργαλεία/scripts.
- Πέρασε στο Thunderbit για δομημένο, no-code scraping ή δυναμικές σελίδες.
Συμπέρασμα & βασικά σημεία: Διάλεξε το σωστό εργαλείο web scraping
Το web-scraping-with-curl παραμένει μια πολύ δυνατή δεξιότητα για τεχνικούς χρήστες το 2026—ειδικά για γρήγορα data pulls, prototyping και αυτοματοποίηση. Η ταχύτητα, η ευελιξία σε scripts και η πανταχού παρουσία του cURL το κάνουν βασικό εργαλείο σε κάθε developer toolbox. Όμως, όσο το web γίνεται πιο δυναμικό και πιο προστατευμένο, και όσο οι business χρήστες ζητούν δομημένα δεδομένα χωρίς κώδικα, εργαλεία όπως το αλλάζουν το παιχνίδι.
Βασικά συμπεράσματα:
- Χρησιμοποίησε cURL για στατικές σελίδες, APIs και γρήγορο prototyping—ιδίως όταν θες απόλυτο έλεγχο.
- Πήγαινε σε Thunderbit (ή αντίστοιχους AI web scrapers) όταν χρειάζεσαι δομημένα δεδομένα, όταν έχεις δυναμικές/JavaScript-heavy σελίδες ή όταν θες no-code, business-friendly workflow.
- Συνδύασέ τα για μέγιστη ευελιξία: πρωτότυπο με cURL, κλιμάκωση και δόμηση με Thunderbit.
- Κάνε scraping υπεύθυνα—σεβάσου όρους χρήσης, rate limits και νομικά όρια.
Θες να δεις πόσο εύκολο μπορεί να γίνει το web scraping; και δες στην πράξη την AI-powered εξαγωγή δεδομένων. Αν θες να το πας πιο βαθιά, δες το για περισσότερα tutorials, tips και insights. Ίσως σου αρέσουν επίσης:
Καλή επιτυχία στο scraping—και μακάρι τα δεδομένα σου να είναι πάντα καθαρά, δομημένα και… ένα command (ή ένα κλικ) μακριά.
Συχνές ερωτήσεις (FAQs)
1. Μπορεί το cURL να χειριστεί σελίδες που γίνονται render με JavaScript;
Όχι, το cURL δεν εκτελεί JavaScript. Φέρνει το «ωμό» HTML όπως το στέλνει ο server. Αν μια σελίδα χρειάζεται JavaScript για να εμφανίσει περιεχόμενο ή για να περάσει anti-bot challenges, το cURL δεν θα μπορέσει να πάρει τα δεδομένα. Σε αυτές τις περιπτώσεις, χρησιμοποίησε browser-based εργαλεία όπως το .
2. Πώς αποθηκεύω την έξοδο του cURL απευθείας σε αρχείο;
Χρησιμοποίησε το -o: curl -o filename.html URL. Έτσι γράφει το response body σε αρχείο αντί να το εμφανίζει στο terminal.
3. Ποια είναι η διαφορά ανάμεσα σε cURL και Thunderbit για web scraping;
Το cURL είναι εργαλείο γραμμής εντολών για λήψη «ωμών» web δεδομένων—ιδανικό για τεχνικούς χρήστες και αυτοματοποίηση. Το Thunderbit είναι ένα AI-powered Chrome Extension για business χρήστες που θέλουν να εξάγουν δομημένα δεδομένα από οποιοδήποτε site, να χειριστούν δυναμικές σελίδες και να κάνουν export απευθείας σε εργαλεία όπως Excel ή Google Sheets—χωρίς κώδικα.
4. Είναι νόμιμο να κάνω scraping ιστοσελίδες με cURL;
Το scraping δημόσιων δεδομένων είναι γενικά νόμιμο στις ΗΠΑ μετά από πρόσφατες δικαστικές αποφάσεις, αλλά πάντα να ελέγχεις τους όρους χρήσης του site, το robots.txt και τη σχετική νομοθεσία. Απόφυγε scraping προσωπικών ή προστατευμένων δεδομένων χωρίς άδεια και σεβάσου τα rate limits και τις ηθικές πρακτικές (, ).
5. Πότε να περάσω από cURL σε πιο προχωρημένο εργαλείο όπως το Thunderbit;
Αν χρειάζεσαι scraping σε δυναμικές/JavaScript-heavy σελίδες, αν θες δομημένα δεδομένα σε spreadsheet ή αν προτιμάς no-code workflow, το Thunderbit είναι καλύτερη επιλογή. Χρησιμοποίησε cURL για γρήγορες τεχνικές εργασίες· χρησιμοποίησε Thunderbit για business-friendly, επαναλήψιμη εξαγωγή δεδομένων.
Για περισσότερα tips και tutorials, επισκέψου το ή δες το .