Είναι παράνομο το web scraping; Αυτή είναι η ερώτηση του εκατομμυρίου που ακούω κάθε εβδομάδα από ιδρυτές, marketers και data geeks.
Με το — και για πρώτη φορά η αυτοματοποιημένη κίνηση να ξεπερνά την ανθρώπινη δραστηριότητα — και με ένα τεράστιο κομμάτι αυτής να αφορά web scraping για business intelligence, πωλήσεις και εκπαίδευση AI, δεν είναι περίεργο που όλοι προσπαθούν να καταλάβουν πού χαράσσονται τα νομικά όρια.
Τη μία μέρα βλέπεις πρωτοσέλιδο για δικαστική απόφαση που λέει ότι το scraping δημόσιων δεδομένων επιτρέπεται. Την επόμενη, οι ρυθμιστικές αρχές προειδοποιούν για «παράνομη» συλλογή δεδομένων από social media. Είναι μπερδεμένο, ακόμη και για ανθρώπους σαν εμένα που περνούν τις μέρες τους χτίζοντας AI web scraping tools στην .
Λοιπόν, είναι παράνομο το web scraping; Η απάντηση δεν είναι ένα απλό ναι ή όχι. Εξαρτάται από το τι κάνεις scrape, από πού το κάνεις scrape, πώς χρησιμοποιείς τα δεδομένα και τι λέει ο νόμος στη χώρα σου.
Σε αυτή τη σε βάθος ανάλυση, θα ξεκαθαρίσω το νομικό τοπίο, θα καταρρίψω μερικούς κοινούς μύθους και θα μοιραστώ πρακτικές συμβουλές — μαζί με μερικές ιστορίες από το πεδίο — για να μείνεις compliant, είτε είσαι solo founder είτε μέλος μιας data team σε Fortune 500.
Web Scraping και ο νόμος: Υπάρχει ξεκάθαρη γραμμή;
Αν ελπίζεις σε απάντηση μίας πρότασης, θα σου γλιτώσω λίγο χρόνο: ο νόμος δεν έχει χαράξει μια καθαρή, φωτεινή γραμμή για το web scraping.
Αντί γι’ αυτό, υπάρχει ένα μωσαϊκό από αλληλοεπικαλυπτόμενους κανόνες — ιδιοκτησία δεδομένων, ιδιωτικότητα, πνευματική ιδιοκτησία, νόμοι κατά του hacking και οι διαβόητοι Όροι Χρήσης (Terms of Service, ToS). Ο καθένας μπορεί να παίξει ρόλο, και η απάντηση συχνά εξαρτάται από το συγκεκριμένο σενάριο ().
Ας σπάσουμε τα πράγματα σε τρεις μεγάλες νομικές κατηγορίες:
- Ιδιοκτησία δεδομένων: Γενικά, τα γεγονότα και οι δημόσιες πληροφορίες (όπως τιμές ή τηλέφωνα) δεν προστατεύονται από copyright. Όμως δημιουργικό περιεχόμενο (άρθρα, εικόνες) και ιδιόκτητες βάσεις δεδομένων μπορεί να προστατεύονται — ειδικά στην ΕΕ, όπου υπάρχουν τα λεγόμενα "database rights" ().
- Ιδιωτικότητα: Οι σύγχρονοι νόμοι περί ιδιωτικότητας (σκέψου GDPR στην Ευρώπη, PIPL στην Κίνα) αντιμετωπίζουν τα προσωπικά δεδομένα ως ρυθμιζόμενο περιουσιακό στοιχείο — ακόμη κι αν είναι δημοσιευμένα δημόσια. Το scraping ονομάτων, email ή social profiles χωρίς νόμιμη βάση μπορεί να σε βάλει σε μπελάδες ().
- Συμβάσεις (Όροι Χρήσης): Πολλές ιστοσελίδες απαγορεύουν ρητά το scraping στους ToS τους. Αν και οι ToS δεν είναι νόμοι, τα δικαστήρια μπορούν να τις αντιμετωπίσουν ως δεσμευτικές συμβάσεις. Η παραβίασή τους μπορεί να οδηγήσει σε αγωγές και, σε ορισμένες περιπτώσεις, ακόμη και να ενεργοποιήσει αντι-hacking διατάξεις αν παρακάμψεις τεχνικούς φραγμούς ().
Άρα, είναι παράνομο το web scraping; Μερικές φορές ναι, μερικές φορές όχι, και συχνά «εξαρτάται». Η λεπτομέρεια κρύβει τον διάβολο.
Σύγκριση νομικών προσεγγίσεων: ΗΠΑ, ΕΕ, Ηνωμένο Βασίλειο, Κίνα
Ορίστε ένας γρήγορος πίνακας για να δεις πώς προσεγγίζουν το web scraping οι μεγάλες περιοχές:
| Περιοχή | Scraping δημόσιων δεδομένων | Scraping προσωπικών/ιδιωτικών δεδομένων | Επιβολή & αξιοσημείωτα σημεία |
|---|---|---|---|
| ΗΠΑ | Γενικά επιτρέπεται για δημόσια δεδομένα (βλ. hiQ v. LinkedIn). Η παραβίαση ToS μπορεί να οδηγήσει σε αστικές αγωγές. | Περιορίζεται/είναι παράνομο αν παρακάμπτεις logins ή κάνεις κακή χρήση προσωπικών δεδομένων. Μπορεί να ισχύουν πολιτειακοί νόμοι (όπως ο CCPA). | Εξώδικες προειδοποιήσεις, μπλοκάρισμα IP, αγωγές. Ο CFAA εφαρμόζεται αν παρακάμψεις τεχνικά εμπόδια. |
| ΕΕ | Επιτρέπεται υπό προϋποθέσεις για μη προσωπικά, δημόσια δεδομένα. Μπορεί να ισχύουν δικαιώματα βάσεων δεδομένων. Ο EU AI Act (2026) προσθέτει απαιτήσεις διαφάνειας για δεδομένα εκπαίδευσης AI. | Πολύ αυστηρά ρυθμισμένο υπό τον GDPR — ακόμη και τα δημόσια προσωπικά δεδομένα χρειάζονται νόμιμη βάση. | Οι Αρχές Προστασίας Δεδομένων μπορούν να επιβάλουν πρόστιμα για παραβιάσεις ιδιωτικότητας. Εφαρμόζονται επίσης copyright και δικαιώματα βάσεων δεδομένων. Ο EU AI Act απαγορεύει το scraping εικόνων προσώπων για AI. |
| Ηνωμένο Βασίλειο | Παρόμοιο με την ΕΕ. Δημόσια, μη προσωπικά δεδομένα μπορούν να γίνουν scrape, αλλά πρέπει να γίνονται σεβαστά τα δικαιώματα δεδομένων και οι συμβάσεις. | Αυστηρό για προσωπικά δεδομένα — εφαρμόζεται ο UK GDPR. Ο Computer Misuse Act ποινικοποιεί την μη εξουσιοδοτημένη πρόσβαση. | Η ICO μπορεί να επιβάλει κυρώσεις για παραβιάσεις προστασίας δεδομένων. Τα δικαστήρια μπορούν να εφαρμόσουν τους ToS. |
| Κίνα | Αυστηρά ελεγχόμενο. Δημόσια, μη προσωπικά δεδομένα μπορούν να γίνουν scrape για εσωτερική χρήση, αλλά το περιβάλλον είναι προσεκτικό. | Πολύ περιορισμένο — ο PIPL απαιτεί συναίνεση για προσωπικά δεδομένα. Ισχύουν νόμοι κατά του αθέμιτου ανταγωνισμού. | Ποινικές υποθέσεις για scraping μεγάλης κλίμακας. Τα δικαστήρια χρησιμοποιούν τον νόμο περί αθέμιτου ανταγωνισμού για να σταματήσουν μη εξουσιοδοτημένο scraping. |
(, )
Είναι παράνομο το Web Scraping; Κύριοι νομικοί παράγοντες που πρέπει να λάβεις υπόψη
Τι καθορίζει πραγματικά αν το scraping project σου είναι νόμιμο ή επικίνδυνο; Ορίστε οι βασικοί παράγοντες:
- Δημόσια vs. ιδιωτικά δεδομένα: Το scraping δεδομένων που μπορεί να δει οποιοσδήποτε στο ανοιχτό web είναι γενικά ασφαλέστερο. Το scraping περιεχομένου πίσω από login, paywall ή τεχνικό φράγμα; Αυτό πιθανότατα είναι παράνομο ().
- Φύση των δεδομένων: Τα προσωπικά δεδομένα (ονόματα, email, προφίλ) ενεργοποιούν νόμους περί ιδιωτικότητας. Το περιεχόμενο με copyright (άρθρα, εικόνες) δεν μπορεί να αντιγραφεί μαζικά. Τα καθαρά γεγονότα (τιμές, καιρός) είναι συνήθως ελεύθερα προς χρήση ().
- Σκοπός χρήσης: Η εσωτερική ανάλυση ή η έρευνα αντιμετωπίζεται πιο επιεικώς από την αναδημοσίευση ή την πώληση scraped data. Η χρήση scraped δεδομένων για άμεσο ανταγωνισμό με την πηγή; Αυτό είναι αγωγή που περιμένει να συμβεί ().
- Συμμόρφωση με τους κανόνες της ιστοσελίδας: Να ελέγχεις πάντα το robots.txt και τους ToS. Το robots.txt δεν είναι νομικά δεσμευτικό, αλλά είναι καλή πρακτική να το σέβεσαι. Οι παραβιάσεις ToS μπορεί να σημαίνουν αστικές αγωγές ή και χειρότερα ().
- Τεχνικά μέτρα: Το scraping με ταχύτητες που μοιάζουν ανθρώπινες και χωρίς παράκαμψη μέτρων ασφαλείας είναι το κλειδί. Το να βομβαρδίζεις έναν server ή να αποφεύγεις CAPTCHAs μπορεί να περάσει τη γραμμή προς το hacking ().
Τι άλλαξε το 2024–2026: Κύριες δικαστικές υποθέσεις και ρυθμίσεις
Το νομικό τοπίο για το web scraping έχει αλλάξει δραματικά από το 2023. Ορίστε οι εξελίξεις που πρέπει να γνωρίζει κάθε scraper:
Σημαντικές δικαστικές αποφάσεις
-
Meta v. Bright Data (2024): Ομοσπονδιακό δικαστήριο των ΗΠΑ . Ο δικαστής έκρινε ότι «ένας επισκέπτης δεν θεωρείται “χρήστης” εκτός αν έχει λογαριασμό». Η Meta απέσυρε λίγο αργότερα τις υπόλοιπες αξιώσεις. Πρόκειται για μια ιστορική νίκη για το scraping δημόσιων δεδομένων.
-
X Corp v. Bright Data (2024): Το Twitter (νυν X) έχασε παρόμοια αγωγή, ενισχύοντας την ίδια αρχή: το scraping δημόσια προσβάσιμων δεδομένων χωρίς σύνδεση δεν παραβιάζει τους ToS, επειδή ο scraper δεν συμφώνησε ποτέ με αυτούς τους όρους.
-
Reddit v. Perplexity AI (Οκτώβριος 2025): Το Reddit , επικαλούμενο το DMCA και ισχυριζόμενο παράκαμψη συστημάτων κατά των bots. Αυτό δείχνει μια νέα νομική στρατηγική: οι πλατφόρμες στρέφονται σε αξιώσεις copyright και anti-circumvention αντί για τον CFAA.
-
NYT v. OpenAI (Μάρτιος 2025): Ομοσπονδιακός δικαστής , απορρίπτοντας το αίτημα της OpenAI για απόρριψη. Αυτό μπορεί να δημιουργήσει σημαντικό προηγούμενο σχετικά με το αν το scraping περιεχομένου για εκπαίδευση μοντέλων AI θεωρείται «fair use».
-
Συμβιβασμός της Anthropic (Σεπτέμβριος 2025): Η Anthropic συμφώνησε να πληρώσει 1,5 δισεκατομμύριο δολάρια για συμβιβασμό σε αμερικανική συλλογική αγωγή copyright σχετικά με τη χρήση προστατευμένων κειμένων για την εκπαίδευση του AI μοντέλου της — σήμα ότι το κόστος του scraping για AI είναι πολύ πραγματικό.
Η μεγάλη τάση: Από τον CFAA στο συμβόλαιο και το copyright
Το μοτίβο είναι ξεκάθαρο: ο CFAA (Computer Fraud and Abuse Act) χάνει τη δύναμή του ως όπλο εναντίον scrapers δημόσιων δεδομένων. Εταιρείες που προσπάθησαν να χρησιμοποιήσουν τον CFAA κατά του scraping δημόσιων δεδομένων — Meta, X, LinkedIn — απέτυχαν σε μεγάλο βαθμό. Αντί γι’ αυτό, η νομική μάχη μετατοπίζεται σε:
- Δίκαιο συμβάσεων (παραβιάσεις ToS — αλλά τα δικαστήρια λένε ότι οι μη χρήστες δεν δεσμεύονται από τους ToS)
- Αξιώσεις copyright (ιδίως για δεδομένα εκπαίδευσης AI)
- Νόμους anti-circumvention (DMCA Section 1201)
Για τους scrapers, αυτό σημαίνει ότι ο νομικός κίνδυνος δεν εξαφανίστηκε — απλώς μεταφέρθηκε αλλού.
Ρυθμιστικές αλλαγές
- Ενημερώσεις του CCPA 2026: Οι αναθεωρημένοι κανονισμοί CCPA της Καλιφόρνιας , προσθέτοντας νέους κανόνες για τεχνολογία αυτοματοποιημένης λήψης αποφάσεων (ADMT), αξιολογήσεις κινδύνου και υποχρεώσεις data broker.
- Νέοι πολιτειακοί νόμοι ιδιωτικότητας στις ΗΠΑ: Η Indiana, το Kentucky και το Rhode Island θέσπισαν ολοκληρωμένους νόμους περί ιδιωτικότητας με ισχύ από το 2026.
- EU AI Act: Η πλήρης επιβολή ξεκινά — απαιτώντας από τους developers AI να αποκαλύπτουν τις πηγές των training data, να σέβονται τις εξαιρέσεις copyright opt-out και να απαγορεύουν το scraping εικόνων προσώπων για συστήματα AI.
- AI Accountability for Publishers Act (Φεβρουάριος 2026): Προτεινόμενος νόμος των ΗΠΑ που θα απαιτεί από τις εταιρείες AI να ζητούν άδεια και να πληρώνουν publishers πριν κάνουν scrape το περιεχόμενό τους.
Οι πολιτικές scraping των μεγάλων πλατφορμών: Τι πρέπει να ξέρεις
Δεν αντιμετωπίζουν όλες οι ιστοσελίδες το scraping με τον ίδιο τρόπο. Ορίστε μια ανάλυση ανά πλατφόρμα για το τι επιτρέπουν οι μεγαλύτερες ιστοσελίδες, τι μπλοκάρουν και τι έχουν πει τα δικαστήρια:
| Πλατφόρμα | ToS για scraping | Τεχνικές άμυνες | Νομική επιβολή | Τι είναι πρακτικά ασφαλές |
|---|---|---|---|---|
| Google (Search & Maps) | Απαγορεύει την αυτοματοποιημένη πρόσβαση στους ToS. Η Maps Platform έχει ρητή ρήτρα "No Scraping". | Προκλήσεις SearchGuard JS, CAPTCHAs, rate limiting. Ενημερωμένο robots.txt το 2025 για μπλοκάρισμα AI crawlers. | Μήνυσε scrapers τον Δεκέμβριο 2025 με χρήση DMCA. Μπλοκάρει ενεργά AI crawlers (Anthropic, Meta, OpenAI). | Το scraping δημόσιων δεδομένων επιχειρήσεων από το Google Maps έχει νομική βάση υπέρ του χρήστη (πρότυπο hiQ), αλλά να αναμένεις τεχνικά μπλοκαρίσματα. Χρησιμοποίησε επίσημα APIs όπου είναι δυνατόν. |
| Amazon | Απαγορεύει ρητά όλο το scraping στους Όρους Χρήσης («χωρίς ρομπότ, spider, scraper ή άλλα αυτοματοποιημένα μέσα»). | Επιθετικός εντοπισμός bots, CAPTCHA, μπλοκάρισμα IP. Το robots.txt μπλοκάρει όλα τα bots εκτός από Googlebot/Bingbot. Μπλοκάρει ρητά AI crawlers από το 2025. | Μήνυσε την Perplexity AI τον Νοέμβριο 2025. Στέλνει τακτικά εξώδικες προειδοποιήσεις. Ενημέρωσε το BSA τον Μάρτιο 2026 με κανόνες για AI agents. | Τα δημόσια δεδομένα προϊόντων (τιμές, καταχωρίσεις) είναι πραγματικά δεδομένα και μπορούν να γίνουν scrape βάσει αμερικανικού δικαίου, αλλά η Amazon αντιδρά σκληρά. Περιόρισε τον ρυθμό των αιτημάτων και απόφυγε προσωπικά δεδομένα. |
| Απαγορεύει το scraping στους ToS· απαιτεί συμφωνία χρήστη για πρόσβαση στις υπηρεσίες. | Login walls για τα περισσότερα δεδομένα προφίλ, ανίχνευση anti-bot, rate limiting. | Η υπόθεση hiQ επιβεβαίωσε ότι το scraping δημόσιων προφίλ δεν παραβιάζει τον CFAA, αλλά η LinkedIn κέρδισε σε αξιώσεις συμβολαίου/αθέμιτου ανταγωνισμού όταν χρησιμοποιήθηκαν ψεύτικοι λογαριασμοί. | Τα δημόσια προφίλ (ορατά χωρίς login) έχουν νομική βάση για scraping. Ποτέ μην δημιουργείς ψεύτικους λογαριασμούς και μην κάνεις scrape δεδομένα πίσω από login. | |
| Meta (Facebook & Instagram) | Οι ToS απαγορεύουν το scraping· ξεχωριστοί κανόνες για δεδομένα συνδεδεμένων και μη συνδεδεμένων χρηστών. | Login walls για το μεγαλύτερο μέρος του περιεχομένου, προηγμένος εντοπισμός bots. | Έχασε από τη Bright Data το 2024 — το δικαστήριο έκρινε ότι οι ToS δεν ισχύουν για scrapers που δεν είναι συνδεδεμένοι. Απέσυρε τις υπόλοιπες αξιώσεις. | Τα δημόσια δεδομένα (σελίδες επιχειρήσεων, δημόσιες αναρτήσεις) που φαίνονται χωρίς login είναι σε ασφαλέστερη θέση. Ποτέ μην κάνεις scrape ιδιωτικά προφίλ ή δεδομένα πίσω από login. |
| X (Twitter) | Ενημέρωσε τους ToS το 2023 για να απαγορεύσει όλο το scraping και crawling χωρίς γραπτή συναίνεση. Κατάργησε την παλιά εξαίρεση robots.txt. | Το robots.txt μπλοκάρει όλους τους crawlers (Disallow: /). Προκλήσεις Cloudflare Turnstile. Αυστηρά rate limits (300 req/hr). Βαθμολόγηση αξιοπιστίας IP. | Έχασε από τη Bright Data για δημόσια δεδομένα, αλλά περιορίζει επιθετικά την τεχνική πρόσβαση. | Τα δημόσια tweets και προφίλ έχουν νομική βάση για scraping, αλλά τα τεχνικά εμπόδια του X είναι από τα πιο δύσκολα το 2026. Να περιμένεις μπλοκαρίσματα χωρίς premium proxy υποδομή. |
Το βασικό συμπέρασμα: Τα δικαστήρια έχουν κρίνει σταθερά ότι το scraping δημόσια ορατών δεδομένων χωρίς login δεν παραβιάζει τον CFAA. Όμως οι πλατφόρμες μπορούν ακόμη να σε κυνηγήσουν με βάση το δίκαιο συμβάσεων, το copyright ή τους νόμους anti-circumvention — και θα σου κάνουν τη ζωή δύσκολη με τεχνικά εμπόδια. Να κάνεις πάντα scraping με υπευθυνότητα.
Δεδομένα εκπαίδευσης AI και Web Scraping: Το νέο νομικό μέτωπο
Αν παρακολουθείς τις ειδήσεις το 2026, ξέρεις ότι το scraping δεδομένων για την εκπαίδευση μοντέλων AI έχει γίνει το πιο καυτό νομικό πεδίο μάχης. Να τι συμβαίνει:
- Οι αγωγές για copyright συσσωρεύονται. Οι New York Times, συγγραφείς και εκδότες έχουν μηνύσει την OpenAI, την Anthropic και άλλους, ισχυριζόμενοι ότι η μαζική συλλογή προστατευμένου περιεχομένου για εκπαίδευση LLMs δεν αποτελεί "fair use". Η Anthropic κατέληξε σε μεγάλο συμβιβασμό 1,5 δισ. δολαρίων το 2025 — ένδειξη ότι το κόστος του scraping για AI είναι απολύτως πραγματικό.
- Η υπεράσπιση του "fair use" είναι αβέβαιη. Τα αμερικανικά δικαστήρια δεν έχουν ακόμη εκδώσει οριστική απόφαση για το αν η εκπαίδευση AI με scraped data είναι fair use. Οι πρώτες αποφάσεις δείχνουν ότι εξαρτάται σε μεγάλο βαθμό από το πώς αποκτήθηκαν τα δεδομένα και τι γίνεται με το αποτέλεσμα του AI.
- Νέα νομοθεσία έρχεται. Ο (κατατέθηκε τον Φεβρουάριο 2026) στοχεύει να απαιτεί από τις εταιρείες AI να παίρνουν άδεια και να πληρώνουν publishers πριν κάνουν scrape το περιεχόμενό τους.
- Ο EU AI Act (πλήρης εφαρμογή ) απαιτεί από τους developers AI να αποκαλύπτουν τις πηγές των training data, να σέβονται τα machine-readable copyright opt-outs (βάσει της εξαίρεσης TDM της Οδηγίας Copyright) και να επισημαίνουν το περιεχόμενο που παράγεται από AI. Επίσης απαγορεύει συστήματα AI που κάνουν scrape εικόνες προσώπων από το διαδίκτυο.
- Οι AI/LLM crawlers εκτοξεύονται. Οι AI crawlers τετραπλασίασαν το μερίδιό τους στην κίνηση του web από 2,6% σε 10,1% μέσα σε μόλις οκτώ μήνες. Μόνο το GPTBot της OpenAI αυξήθηκε κατά 305%. Ως απάντηση, μεγάλοι ιστότοποι (Amazon, Reddit, NYT) ενημερώνουν το robots.txt για να μπλοκάρουν ρητά AI crawlers.
Τι σημαίνει αυτό για σένα: Αν κάνεις scraping για παραδοσιακούς επιχειρηματικούς σκοπούς (lead gen, παρακολούθηση τιμών, έρευνα αγοράς), αυτοί οι ειδικοί για AI κανόνες μπορεί να μην ισχύουν άμεσα. Αλλά αν τροφοδοτείς τα scraped δεδομένα σε AI μοντέλα, προχώρα εξαιρετικά προσεκτικά — και πάρε νομική συμβουλή.
Νόμοι για το Web Scraping σε όλο τον κόσμο: Γρήγορη σύγκριση
Ας απομακρυνθούμε λίγο και ας δούμε πώς διαμορφώνονται οι κανόνες παγκοσμίως:
- Ηνωμένες Πολιτείες: Δεν υπάρχει καθολική απαγόρευση. Το scraping δημόσιων ιστοσελίδων είναι γενικά νόμιμο (), και οι αποφάσεις Meta και X Corp το 2024 ενίσχυσαν ακόμη περισσότερο τη θέση υπέρ του scraping δημόσιων δεδομένων. Όμως το scraping πίσω από logins ή τεχνικά μπλοκαρίσματα μπορεί ακόμη να ενεργοποιήσει τον CFAA. Η τάση τώρα στρέφεται προς τις εταιρείες που χρησιμοποιούν δίκαιο συμβάσεων και αξιώσεις copyright αντί γι’ αυτό. Οι νόμοι ιδιωτικότητας επεκτείνονται γρήγορα: ο CCPA έλαβε σημαντικές ενημερώσεις με ισχύ από 1η Ιανουαρίου 2026, συμπεριλαμβανομένων νέων κανόνων για αυτοματοποιημένη λήψη αποφάσεων και υποχρεώσεις data broker. Η Indiana, το Kentucky και το Rhode Island θέσπισαν επίσης ολοκληρωμένους νόμους ιδιωτικότητας το 2026.
- Ευρωπαϊκή Ένωση: Αυστηροί νόμοι ιδιωτικότητας. Ο GDPR εφαρμόζεται ακόμη και σε δημόσια προσωπικά δεδομένα. Τα δικαιώματα βάσεων δεδομένων μπορούν να μπλοκάρουν μαζικό scraping δομημένων δεδομένων (). ΝΕΟ: Ο τίθεται σε πλήρη εφαρμογή στις 2 Αυγούστου 2026, απαιτώντας από τους developers AI να αποκαλύπτουν τις πηγές των training data και να σέβονται τα copyright opt-outs. Ο νόμος απαγορεύει το scraping εικόνων προσώπων από το διαδίκτυο για συστήματα AI.
- Ηνωμένο Βασίλειο: Αντικατοπτρίζει τους κανόνες της ΕΕ μετά το Brexit. Τα δημόσια δεδομένα μπορούν να γίνουν scrape, αλλά το scraping προσωπικών πληροφοριών ρυθμίζεται αυστηρά. Ο Computer Misuse Act μπορεί να ποινικοποιήσει τη μη εξουσιοδοτημένη πρόσβαση.
- Κίνα: Πολύ περιοριστική. Οι PIPL και Data Security Law απαιτούν συναίνεση για προσωπικά δεδομένα. Τα δικαστήρια χρησιμοποιούν τον νόμο περί αθέμιτου ανταγωνισμού για να μπλοκάρουν το scraping που βλάπτει επιχειρήσεις ().
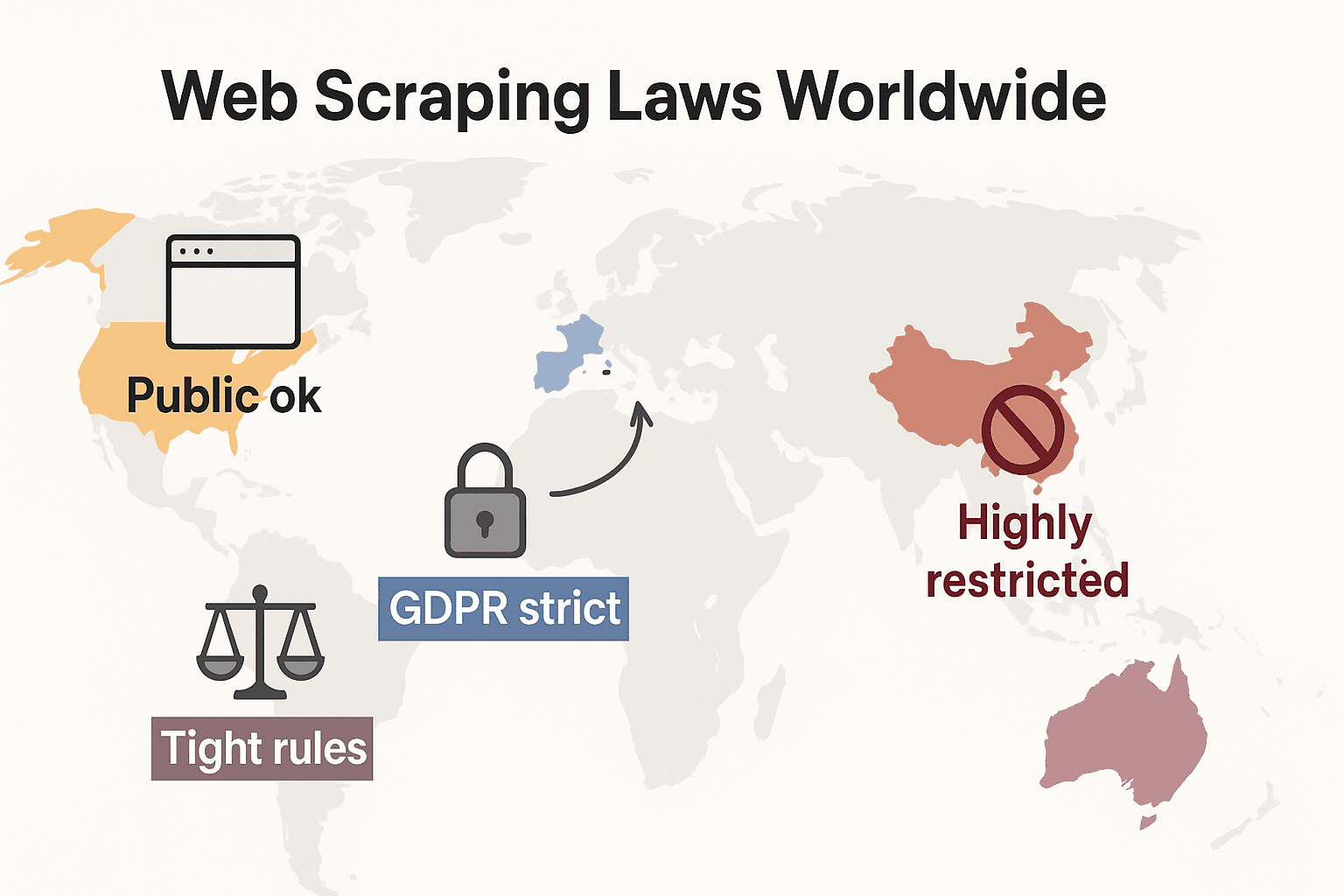
Συμπέρασμα: το scraping δημόσιων, μη προσωπικών δεδομένων για εσωτερική χρήση είναι γενικά το ασφαλέστερο. Οτιδήποτε άλλο; Έλεγξε τους τοπικούς νόμους και προχώρα με προσοχή.
Συνηθισμένοι μύθοι για τη νομιμότητα του Web Scraping
Ας καταρρίψουμε μερικούς μύθους που ακούω συνέχεια:
- Μύθος 1: «Το web scraping είναι παράνομο, τελεία.»
Λάθος. Δεν υπάρχει νόμος που να απαγορεύει κάθε web scraping. Αυτό που έχει σημασία είναι πώς και τι κάνεις scrape (). - Μύθος 2: «Αν τα δεδομένα είναι δημόσια, μπορώ να τα κάνω ό,τι θέλω.»
Όχι ακριβώς. Τα δημόσια δεδομένα μπορεί να προστατεύονται ακόμη από νόμους ιδιωτικότητας ή copyright, και οι ToS μπορεί να περιορίζουν ορισμένες χρήσεις (). - Μύθος 3: «Το web scraping είναι το ίδιο με το hacking.»
Όχι. Το scraping δημόσιων web pages δεν είναι hacking. Η παράκαμψη logins ή τεχνικών φραγμών είναι άλλη ιστορία (). - Μύθος 4: «Αν δεν με πιάσουν, είμαι εντάξει.»
Επικίνδυνη σκέψη. Πολλοί ιστότοποι χρησιμοποιούν τεχνολογία κατά των bots και θα το αντιληφθούν. Η σιωπή δεν είναι συναίνεση. - Μύθος 5: «Αν δώσω αναφορά πηγής ή το χρησιμοποιώ εσωτερικά, είναι εντάξει.»
Η απόδοση δεν υπερισχύει του copyright ή της νομοθεσίας για την ιδιωτικότητα. Η εσωτερική χρήση είναι ασφαλέστερη, αλλά δεν αποτελεί ελεύθερη άδεια. - Μύθος 6: «Όλο το web scraping παραβιάζει την ιδιωτικότητα.»
Δεν περιλαμβάνει κάθε scraping προσωπικά δεδομένα. Αλλά το scraping μεγάλου όγκου προσωπικών πληροφοριών χωρίς προστασίες είναι σχεδόν πάντα παράνομο (). - Μύθος 7: «Αν οι ToS μιας ιστοσελίδας απαγορεύουν το scraping, είναι πάντα παράνομο να κάνεις scrape.»
Όχι απαραίτητα. Το 2024, τα δικαστήρια αποφάσισαν στις υποθέσεις Meta v. Bright Data και X Corp v. Bright Data ότι οι ToS δεν μπορούν να δεσμεύσουν χρήστες που δεν συμφώνησαν ποτέ με αυτούς — δηλαδή, αν κάνεις scraping χωρίς να συνδεθείς ή να δημιουργήσεις λογαριασμό, οι ToS της ιστοσελίδας μπορεί να μη σε αφορούν. Αυτό εξακολουθεί να είναι αναπτυσσόμενο πεδίο, αλλά είναι σημαντική μετατόπιση.
Πώς να κάνεις scraping δεδομένων νόμιμα: Βέλτιστες πρακτικές συμμόρφωσης
Ορίστε η δική μου checklist για νόμιμο, ηθικό web scraping:
- Διάβασε και σεβάσου τους Όρους Χρήσης της ιστοσελίδας. Αν λένε «no scraping», σκέψου να σταματήσεις ή ζήτησε άδεια ().
- Μείνε στα δημόσια δεδομένα. Αν χρειάζεσαι κωδικό πρόσβασης, είναι περιορισμένα — μην τα κάνεις scrape ().
- Έλεγξε το robots.txt και κάνε crawl με ευγένεια. Δεν είναι νομικά δεσμευτικό, αλλά είναι σωστή συμπεριφορά. Μην βομβαρδίζεις τους servers — άπλωσε τα αιτήματά σου χρονικά ().
- Απόφυγε τα προσωπικά δεδομένα εκτός αν έχεις νόμιμη βάση. Αν πρέπει να τα συλλέξεις, συμμορφώσου με GDPR/CCPA και ελαχιστοποίησε όσα συλλέγεις.
- Μην αναδημοσιεύεις μαζικά scraped περιεχόμενο. Πρόσθεσε αξία ή ανάλυση, ή πάρε άδεια ().
- Μην τροφοδοτείς scraped περιεχόμενο σε AI μοντέλα χωρίς να ελέγξεις το copyright. Το νομικό τοπίο αλλάζει γρήγορα — πάρε συμβουλή αν αυτό είναι το use case σου.
- Χρησιμοποίησε επίσημα APIs ή data exports όταν υπάρχουν. Είναι σχεδιασμένα γι’ αυτόν τον σκοπό και συνήθως είναι ασφαλέστερα ().
- Να είσαι διαφανής και υπεύθυνος. Αν συλλέγεις προσωπικά δεδομένα, ενημέρωσε τους ανθρώπους και κράτα αρχείο των ενεργειών σου.
- Ελαχιστοποίησε και προστάτεψε τα δεδομένα σου. Συλλέγεις μόνο ό,τι χρειάζεσαι, κράτα τα ακριβή και αποθήκευσέ τα με ασφάλεια.
- Μείνε ενημερωμένος και ζήτα νομική συμβουλή για οριακές περιπτώσεις. Οι νόμοι και οι δικαστικές αποφάσεις αλλάζουν γρήγορα — ειδικά ο EU AI Act και οι πολιτειακοί νόμοι ιδιωτικότητας στις ΗΠΑ. Όταν αμφιβάλλεις, ρώτα έναν ειδικό.
Χρήση εργαλείων Web Scraping νόμιμα: Τι πρέπει να ξέρουν οι επιχειρήσεις
Τα εργαλεία web scraping όπως η κάνουν τη συλλογή δεδομένων προσβάσιμη και σε μη προγραμματιστές, αλλά πρέπει να τα χρησιμοποιείς υπεύθυνα:
- Διάλεξε εργαλεία με επίκεντρο τη συμμόρφωση. Η Thunderbit, για παράδειγμα, κάνει scrape μόνο ό,τι μπορείς να δεις στο browser σου — χωρίς ύποπτα API hacks ή μη εξουσιοδοτημένη πρόσβαση ().
- Μείνε σε νόμιμες χρήσεις. Η εσωτερική ανάλυση, η έρευνα αγοράς και η παρακολούθηση ανταγωνιστικών τιμών είναι γενικά ασφαλείς. Αναδημοσίευση ή πώληση scraped data; Πολύ πιο ριψοκίνδυνη.
- Ρύθμισε τα εργαλεία για συμμόρφωση. Όρισε καθυστερήσεις crawl, σεβάσου το robots.txt και χρησιμοποίησε templates που συλλέγουν μόνο ό,τι χρειάζεσαι.
- Κράτησέ το εσωτερικά. Η εσωτερική χρήση scraped δεδομένων είναι ασφαλέστερη από την αναδημοσίευσή τους.
- Εκπαίδευσε την ομάδα σου. Βεβαιώσου ότι όλοι καταλαβαίνουν τους κανόνες και τις βέλτιστες πρακτικές.
- Αξιοποίησε ενσωματωμένα χαρακτηριστικά συμμόρφωσης. Η Thunderbit προειδοποιεί τους χρήστες για ριψοκίνδυνες ιστοσελίδες, κάνει scrape με ταχύτητες που μοιάζουν ανθρώπινες και δεν αποθηκεύει τα δεδομένα σου στους servers της.
- Μην το πιέζεις. Αν ένα εργαλείο δεν μπορεί να κάνει scrape μια ιστοσελίδα, μην προσπαθήσεις να το παρακάμψεις. Δεν είναι όλα τα δεδομένα προσβάσιμα χωρίς ρίσκο.
Η προσέγγιση της Thunderbit: Ενίσχυση compliant AI web scraping
Στην , έχουμε αφιερώσει πολύ χρόνο στη συμμόρφωση. Δες πώς το AI Web Scraper μας βοηθά τους χρήστες να μένουν στη σωστή πλευρά του νόμου:
- Κάνει scrape μόνο ό,τι μπορείς να δεις. Η Thunderbit λειτουργεί μέσα στη συνεδρία του browser σου, άρα δεν μπορεί να προσπελάσει δεδομένα που δεν θα μπορούσες να αντιγράψεις χειροκίνητα.
- Καθοδηγεί τους χρήστες με προειδοποιήσεις. Αν προσπαθήσεις να κάνεις scrape μια ιστοσελίδα με αυστηρές πολιτικές κατά του scraping, η Thunderbit θα σε ειδοποιήσει.
- Ταχύτητες scraping που μοιάζουν ανθρώπινες. Είτε κάνεις scrape τοπικά είτε στο cloud, η Thunderbit αποφεύγει να βομβαρδίζει servers.
- Προσαρμόσιμη επιλογή δεδομένων. Η AI μας προτείνει σχετικές στήλες, βοηθώντας σε να συλλέγεις μόνο ό,τι χρειάζεσαι.
- Υποστήριξη υποσελίδων και σελιδοποίησης. Η Thunderbit πλοηγείται σε ιστοσελίδες όπως ένας πραγματικός χρήστης, σεβόμενη τη δομή τους.
- Ιδιωτικότητα και ασφάλεια. Τα δεδομένα σου μένουν μαζί σου — η Thunderbit δεν τα αποθηκεύει ούτε τα επαναχρησιμοποιεί.
- Εξαγωγές φιλικές προς τη συμμόρφωση. Εξάγετε απευθείας σε Google Sheets, Airtable, Notion ή CSV για ασφαλή, εσωτερική χρήση.
- Προγραμματισμός και αυτοματοποίηση. Ρύθμισε επαναλαμβανόμενα scrapes σε υπεύθυνα διαστήματα.
- Υποστήριξη πολλών γλωσσών. Το UI της Thunderbit υποστηρίζει 34 γλώσσες, κάνοντας τη συμμόρφωση προσβάσιμη παγκοσμίως.
- Τακτικές ενημερώσεις templates. Τα instant templates μας για δημοφιλείς ιστοσελίδες παραμένουν ενημερωμένα με νομικές και τεχνικές αλλαγές.
Ενσωματώνοντας τη συμμόρφωση στο προϊόν, η Thunderbit βοηθά τις ομάδες να συλλέγουν τα δεδομένα που χρειάζονται — χωρίς νομικά πονοκεφάλια.
Να μένεις μπροστά: Προσαρμογή σε νομικές και τεχνικές αλλαγές στο Web Scraping
Το web scraping δεν είναι παιχνίδι «το στήνεις και το ξεχνάς». Οι νόμοι και οι δομές των ιστοσελίδων εξελίσσονται συνεχώς. Δες πώς να μείνεις μπροστά:
- Παρακολούθησε τις νομικές εξελίξεις. Ο ρυθμός αλλαγών επιταχύνθηκε το 2024–2026 — ακολούθησε ειδήσεις για τεχνολογικό δίκαιο, ενημερώσεις ρυθμιστικών αρχών και industry blogs (όπως της ). Έχε το νου σου στην επιβολή του EU AI Act (Αύγουστος 2026), στους νέους πολιτειακούς νόμους ιδιωτικότητας στις ΗΠΑ και στις συνεχιζόμενες υποθέσεις copyright για AI.
- Προσαρμόσου στις τεχνικές αλλαγές. Οι ιστοσελίδες ενημερώνουν συνεχώς τα layouts και τις άμυνες κατά των bots. Μεγάλες πλατφόρμες (Amazon, X, Google) ενίσχυσαν σημαντικά τις άμυνές τους το 2025–2026. Η AI και τα templates της Thunderbit έχουν σχεδιαστεί για να προσαρμόζονται αυτόματα.
- Αγκαλιάσε τα επίσημα APIs όταν υπάρχουν. Αν μια ιστοσελίδα περάσει σε μοντέλο επί πληρωμή API, σκέψου να μεταβείς εκεί για αξιοπιστία και συμμόρφωση.
- Κάνε τακτικό audit στο scraping σου. Κατέγραψε τις πηγές σου, έλεγξε για αλλαγές στους ToS ή στις πολιτικές και προσαρμόζε τη στρατηγική σου όπου χρειάζεται.
- Αξιοποίησε τις ενημερώσεις templates της Thunderbit. Η ομάδα μας κρατά τα templates ενημερωμένα, ώστε να μην ανησυχείς για breaking changes ή νέες απαιτήσεις συμμόρφωσης.
- Μείνε ευέλικτος. Αν μια πηγή δεδομένων γίνει πολύ ριψοκίνδυνη, στράφηκε σε άλλη ή αναζήτησε συνεργασία.
Με τα σωστά εργαλεία και τη σωστή νοοτροπία, μπορείς να κρατήσεις τη ροή δεδομένων σου να κινείται — χωρίς να πατάς σε νομικές νάρκες.
Συμπέρασμα: Πλοήγηση στο νομικό τοπίο του Web Scraping
Το web scraping δεν είναι από τη φύση του παράνομο — είναι ένα ισχυρό εργαλείο για επιχειρήσεις, έρευνα και καινοτομία. Αλλά όπως κάθε εργαλείο, έχει κανόνες. Το κλειδί είναι να καταλαβαίνεις τι κάνεις scrape, πώς το κάνεις scrape και τι θα κάνεις με τα δεδομένα. Σεβάσου τους τοπικούς νόμους, τήρησε τις πολιτικές των ιστοσελίδων και χρησιμοποίησε compliance-focused εργαλεία όπως η για να κρατάς τις λειτουργίες σου απολύτως νόμιμες.
Οι δικαστικές αποφάσεις του 2024–2026 (Meta v. Bright Data, X Corp v. Bright Data) ενίσχυσαν τη θέση υπέρ του scraping δημόσιων δεδομένων, αλλά νέοι κίνδυνοι εμφανίζονται γύρω από τα δεδομένα εκπαίδευσης AI, τις αξιώσεις copyright και τον EU AI Act. Οι πολιτικές ανά πλατφόρμα διαφέρουν σημαντικά — Google, Amazon, LinkedIn, Meta και X εφαρμόζουν διαφορετικά τους κανόνες τους — οπότε γνώριζε το τοπίο πριν κάνεις scrape.
Αν ποτέ δεν είσαι σίγουρος, ζήτησε νομική συμβουλή — ειδικά για μεγάλα ή ευαίσθητα projects. Και να θυμάσαι: το νομικό τοπίο αλλάζει συνεχώς, άρα μείνε ενημερωμένος και ευέλικτος.
Θέλεις να μάθεις περισσότερα για web scraping, συμμόρφωση και αυτοματοποίηση; Δες το για περισσότερους οδηγούς ή δοκίμασε την μόνος σου.
Συχνές ερωτήσεις
1. Είναι το web scraping παράνομο παντού;
Όχι. Το web scraping δεν είναι από μόνο του παράνομο, αλλά η νομιμότητά του εξαρτάται από το τι κάνεις scrape, πώς το κάνεις scrape και πού βρίσκεσαι. Το scraping δημόσιων, μη προσωπικών δεδομένων για εσωτερική χρήση επιτρέπεται γενικά στις περισσότερες περιοχές, αλλά το scraping προσωπικών ή προστατευμένων με copyright δεδομένων, ή η παραβίαση των όρων μιας ιστοσελίδας, μπορεί να είναι παράνομο ().
2. Το robots.txt κάνει το scraping παράνομο αν το αγνοήσω;
Το robots.txt δεν είναι νομικά δεσμευτικό, αλλά είναι βέλτιστη πρακτική να το σέβεσαι. Η αγνόησή του από μόνη της δεν θα σε κάνει να δεχτείς αγωγή, αλλά μπορεί να σε κάνει να φαίνεσαι σαν «κακός παράγοντας» αν υπάρξει διαφωνία ().
3. Μπορώ να κάνω scrape Google, Amazon ή LinkedIn;
Είναι περίπλοκο. Και οι τρεις απαγορεύουν το scraping στους ToS τους, αλλά τα δικαστήρια έχουν κρίνει ότι οι ToS μπορεί να μην δεσμεύουν μη συνδεδεμένους χρήστες (δες Meta v. Bright Data και X Corp v. Bright Data, και οι δύο το 2024). Το scraping δημόσια ορατών δεδομένων (τιμές προϊόντων, καταχωρίσεις επιχειρήσεων, δημόσια προφίλ) είναι γενικά νομικά υποστηρίξιμο στις ΗΠΑ. Ωστόσο, κάθε πλατφόρμα επιβάλλει τους κανόνες της διαφορετικά: η Amazon είναι η πιο επιθετική νομικά (μήνυσε την Perplexity AI τον Νοέμβριο 2025), η LinkedIn βασίζεται σε τεχνικά εμπόδια και αξιώσεις συμβολαίου, ενώ η Google χρησιμοποιεί όλο και περισσότερο επιβολή με βάση το DMCA. Να κάνεις πάντα scraping με υπευθυνότητα και να περιμένεις τεχνικά αντίμετρα.
4. Μπορώ να κάνω scrape Facebook ή Instagram;
Μετά το Meta v. Bright Data (2024), το scraping δημόσιων δεδομένων από Facebook και Instagram χωρίς σύνδεση έχει ισχυρότερη νομική βάση. Το δικαστήριο έκρινε ότι οι ToS της Meta δεν ισχύουν για μη χρήστες. Όμως ποτέ μην δημιουργείς ψεύτικους λογαριασμούς και μην κάνεις scrape δεδομένα πίσω από login walls — εκεί ξεπερνάς τα όρια.
5. Μπορώ να κάνω scrape το X (Twitter);
Το X ενημέρωσε τους ToS του το 2023 για να απαγορεύσει όλο το scraping χωρίς γραπτή συναίνεση και έχει αναπτύξει επιθετικές τεχνικές άμυνες (Cloudflare Turnstile, rate limits 300 αιτήματα/ώρα, scoring αξιοπιστίας IP). Ωστόσο, η Bright Data κέρδισε στα δικαστήρια σε παρόμοιες βάσεις — τα δημόσια δεδομένα που έγιναν scrape χωρίς λογαριασμό δεν δεσμεύονται από τους ToS του X. Τεχνικά, το X είναι μία από τις πιο δύσκολες πλατφόρμες για scraping το 2026.
6. Είναι νόμιμο το scraping δεδομένων για εκπαίδευση AI μοντέλων;
Αυτή είναι η μεγαλύτερη ανοιχτή ερώτηση το 2026. Σημαντικές αγωγές (NYT v. OpenAI, ο συμβιβασμός 1,5 δισ. της Anthropic) δείχνουν σημαντικό νομικό ρίσκο. Ο EU AI Act απαιτεί αποκάλυψη των πηγών των training data και σεβασμό των copyright opt-outs. Ο προτεινόμενος AI Accountability for Publishers Act θα απαιτούσε άδεια και πληρωμή. Αν κάνεις scraping για να εκπαιδεύσεις AI, ζήτησε νομική συμβουλή πριν προχωρήσεις.
7. Ποιος είναι ο ασφαλέστερος τρόπος να χρησιμοποιώ εργαλεία web scraping όπως το Thunderbit;
Μείνε στο scraping δημόσιων δεδομένων, σεβάσου τους όρους της ιστοσελίδας, απόφυγε προσωπικές πληροφορίες εκτός αν έχεις νόμιμη βάση και χρησιμοποίησε τα δεδομένα εσωτερικά. Η Thunderbit έχει σχεδιαστεί για να σε βοηθά να μένεις compliant, κάνοντας scrape μόνο ό,τι φαίνεται στον browser σου και προειδοποιώντας σε για ριψοκίνδυνες ιστοσελίδες ().
8. Μπορώ να κάνω scrape δεδομένα για εμπορική χρήση;
Εξαρτάται. Η χρήση scraped δεδομένων για εσωτερική ανάλυση ή έρευνα είναι γενικά ασφαλέστερη. Η αναδημοσίευση ή πώληση scraped δεδομένων, ειδικά αν είναι προστατευμένα με copyright ή αφορούν προσωπικά δεδομένα, είναι πολύ πιο ριψοκίνδυνη και μπορεί να απαιτεί άδεια ή άδεια χρήσης.
9. Πώς μένω ενημερωμένος για νομικές και τεχνικές αλλαγές στο web scraping;
Ακολούθησε ειδήσεις για τεχνολογικό δίκαιο, παρακολούθησε τις αλλαγές ToS ή πολιτικών στις στοχευμένες ιστοσελίδες σου και χρησιμοποίησε εργαλεία όπως η Thunderbit που ενημερώνουν τα templates και τα compliance features τους τακτικά. Βασικά σημεία για το 2026: επιβολή του EU AI Act (Αύγουστος), συνεχιζόμενες υποθέσεις copyright για AI και νέοι πολιτειακοί νόμοι ιδιωτικότητας στις ΗΠΑ. Όταν αμφιβάλλεις, συμβουλέψου έναν νομικό επαγγελματία.