

Αν έχετε προσπαθήσει ποτέ να φτιάξετε μια στοχευμένη λίστα πωλήσεων, να εντοπίσετε νέες αγορές ή να συγκρίνετε ανταγωνιστές, ξέρετε πόσο μεγάλο «θησαυροφυλάκιο» είναι το Google Maps. Και το πιο σημαντικό: με πάνω από 1,5 δισεκατομμύριο αναζητήσεις “κοντά μου” κάθε μήνα και το 76% των τοπικών χρηστών να επισκέπτονται μια επιχείρηση μέσα σε 24 ώρες (thinkwithgoogle.com), η ζήτηση για ενημερωμένα επιχειρηματικά δεδομένα με βάση την τοποθεσία δεν ήταν ποτέ μεγαλύτερη.
Είτε ασχολείστε με πωλήσεις, μάρκετινγκ ή operations, η εξαγωγή δομημένων δεδομένων από το Google Maps μπορεί να κάνει τη διαφορά ανάμεσα σε ένα κρύο τηλεφώνημα και σε ένα ζεστό lead με υψηλή πιθανότητα μετατροπής.
Έχω περάσει χρόνια στο SaaS και στον αυτοματισμό και έχω δει από πρώτο χέρι πώς οι ομάδες χρησιμοποιούν Python (και πλέον εργαλεία με τεχνητή νοημοσύνη όπως το Thunderbit) για να μετατρέψουν το Google Maps σε στρατηγικό πλεονέκτημα.
Σε αυτόν τον οδηγό, θα αναλύσω ακριβώς πώς να κάνετε εξαγωγή δεδομένων από το Google Maps με Python το 2026—βήμα προς βήμα, με κώδικα, συμβουλές συμμόρφωσης και σύγκριση με λύσεις χωρίς κώδικα. Είτε είστε προχωρημένος χρήστης Python είτε απλώς θέλετε τη γρηγορότερη διαδρομή προς αξιοποιήσιμα δεδομένα, βρίσκεστε στο σωστό μέρος.
Τι Σημαίνει η Εξαγωγή Δεδομένων από το Google Maps με Python;
Ας ξεκινήσουμε από τα βασικά: η Εξαγωγή δεδομένων από το Google Maps με Python σημαίνει ότι αντλούμε προγραμματιστικά πληροφορίες για επιχειρήσεις—όπως ονόματα, διευθύνσεις, αξιολογήσεις, κριτικές, τηλέφωνα και συντεταγμένες—από το Google Maps, ώστε να μπορείτε να τις αναλύσετε, να τις φιλτράρετε και να τις εξαγάγετε για επιχειρηματική χρήση.

Υπάρχουν δύο βασικοί τρόποι να το κάνετε αυτό:
- Google Maps Places API: Ο επίσημος, αδειοδοτημένος τρόπος. Χρησιμοποιείτε ένα API key για να κάνετε ερωτήματα στους διακομιστές της Google και να λάβετε δομημένα δεδομένα JSON. Είναι σταθερό, προβλέψιμο και (στις περισσότερες περιπτώσεις) συμβατό, αλλά συνοδεύεται από όρια και κόστος.
- Web Scraping του HTML: Αυτοματοποιείτε έναν browser (με εργαλεία όπως Playwright ή Selenium) για να φορτώνει το Google Maps, να εκτελεί αναζητήσεις και να αναλύει τη σελίδα που αποδίδεται. Είναι πιο ευέλικτο αλλά εύθραυστο—η Google αλλάζει συχνά τη δομή του site της και η εξαγωγή από το HTML μπορεί να παραβιάζει τους όρους της.
Συνήθη πεδία δεδομένων που μπορείτε να εξαγάγετε:
- Όνομα επιχείρησης
- Κατηγορία/τύπος
- Πλήρης διεύθυνση (συν πόλη, πολιτεία, ταχυδρομικό κώδικα, χώρα)
- Γεωγραφικό πλάτος και μήκος
- Αριθμός τηλεφώνου
- URL ιστοσελίδας
- Βαθμολογία και αριθμός κριτικών
- Επίπεδο τιμών
- Κατάσταση επιχείρησης (ανοιχτή/κλειστή)
- Ώρες λειτουργίας
- Place ID (το μοναδικό αναγνωριστικό της Google)
- URL του Google Maps
Γιατί έχει σημασία αυτό; Επειδή αυτά τα πεδία τροφοδοτούν τα πάντα, από τη δημιουργία leads και τον σχεδιασμό περιοχών μέχρι τη σύγκριση ανταγωνιστών και την έρευνα αγοράς. Το κλειδί είναι να στοχεύετε τα σωστά δεδομένα για τους επιχειρηματικούς σας στόχους—μην κάνετε απλώς τυφλό scraping.
Γιατί οι Ομάδες Πωλήσεων και Μάρκετινγκ Εξάγουν Δεδομένα από το Google Maps με Python
Ας το δούμε πρακτικά. Γιατί τόσες ομάδες πωλήσεων και μάρκετινγκ είναι τόσο προσκολλημένες στα δεδομένα του Google Maps το 2026;
- Δημιουργία Leads: Φτιάξτε υπερ-στοχευμένες λίστες τοπικών επιχειρήσεων, με στοιχεία επικοινωνίας και αξιολογήσεις, για καμπάνιες προσέγγισης.
- Σχεδιασμός Περιοχών: Χαρτογραφήστε περιοχές πωλήσεων, ζώνες παράδοσης ή περιοχές εξυπηρέτησης με βάση την πραγματική πυκνότητα και τους τύπους επιχειρήσεων.
- Παρακολούθηση Ανταγωνισμού: Παρακολουθήστε τις τοποθεσίες, τις αξιολογήσεις και τις κριτικές των ανταγωνιστών με την πάροδο του χρόνου για να εντοπίσετε τάσεις και ευκαιρίες.
- Έρευνα Αγοράς: Αναλύστε κατηγορίες επιχειρήσεων, ώρες λειτουργίας και το συναίσθημα των κριτικών για να καθοδηγήσετε τις στρατηγικές go-to-market.
- Επιλογή Τοποθεσίας: Για real estate και retail, αξιολογήστε πιθανές τοποθεσίες με βάση τις κοντινές παροχές, την επισκεψιμότητα και τον ανταγωνισμό.
Πραγματικός αντίκτυπος: Σύμφωνα με το HubSpot 2025 State of Sales, το 92% των οργανισμών πωλήσεων σχεδιάζει να αυξήσει τις επενδύσεις σε AI/δεδομένα, και οι ομάδες που χρησιμοποιούν στοχευμένα τοπικά δεδομένα βλέπουν ποσοστά μετατροπής έως και 8× υψηλότερα από εκείνες που βασίζονται σε γενικές cold lists (martal.ca). Μια μελέτη για lead generation σε franchise έδειξε 15 $ νέων εσόδων για κάθε 1 $ που δαπανήθηκε σε λίστες leads βασισμένες στο Google Maps.
Συσχέτιση επιχειρηματικών στόχων με τα πεδία του Google Maps:
| Επιχειρηματικός Στόχος | Απαιτούμενα Πεδία του Google Maps |
|---|---|
| Τοπική λίστα leads | name, address, phone, website, category |
| Σχεδιασμός περιοχών | name, lat/lng, business_status, opening_hours |
| Σύγκριση ανταγωνιστών | name, rating, userRatingCount, priceLevel, reviews |
| Επιλογή τοποθεσίας | category, lat/lng, review density, openingDate |
| Πληροφορίες για συναίσθημα/μενού | reviews, editorialSummary, photos, types |
| Προσέγγιση μέσω email/τηλεφώνου | nationalPhoneNumber, websiteUri (και μετά εμπλουτισμός ανάλογα με τις ανάγκες) |
Ρύθμιση του Python Google Maps Scraper: Εργαλεία και Απαιτήσεις
Πριν ξεκινήσετε το scraping, θα χρειαστεί να ρυθμίσετε το περιβάλλον Python και να συγκεντρώσετε τα σωστά εργαλεία. Να τι χρειάζεστε το 2026:
1. Εγκατάσταση Python και Απαραίτητων Βιβλιοθηκών
Προτεινόμενη έκδοση Python: 3.10 ή νεότερη.
Εγκαταστήστε τις βασικές βιβλιοθήκες:
pip install \
requests==2.33.1 httpx==0.28.1 \
beautifulsoup4==4.14.3 lxml==6.0.3 \
pandas==2.3.3 \
selenium==4.43.0 playwright==1.58.0 \
googlemaps==4.10.0 google-maps-places==0.8.0 \
schedule==1.2.2 APScheduler==3.11.2 \
python-dotenv==1.2.2 tenacity==9.1.4
playwright install chromium
Τι κάνουν αυτά:
requests,httpx: HTTP requests (κλήσεις API)beautifulsoup4,lxml: Ανάλυση HTML (για web scraping)pandas: Καθαρισμός, ανάλυση και εξαγωγή δεδομένωνselenium,playwright: Αυτοματοποίηση browser (για scraping HTML)googlemaps,google-maps-places: Clients για το Google Maps APIschedule,APScheduler: Προγραμματισμός εργασιώνpython-dotenv: Φόρτωση API keys με ασφάλεια από αρχεία.envtenacity: Λογική επανάληψης για διαχείριση σφαλμάτων
2. Αποκτήστε Google Maps API Key (για scraping μέσω API)
- Μεταβείτε στο Google Cloud Console.
- Δημιουργήστε ή επιλέξτε ένα project.
- Ενεργοποιήστε τη χρέωση (απαιτείται, ακόμη και για χρήση στο δωρεάν επίπεδο).
- Ενεργοποιήστε το “Places API (New)” στο APIs & Services > Library.
- Μεταβείτε στο Credentials > Create Credentials > API Key.
- Περιορίστε το key σας σε συγκεκριμένα APIs και IPs για λόγους ασφάλειας.
- Αποθηκεύστε το API key σας σε αρχείο
.env(ποτέ μην το κάνετε commit στον κώδικα):
GOOGLE_MAPS_API_KEY=your_actual_api_key_here
Σημείωση: Από τον Μάρτιο του 2025, η Google δεν προσφέρει πλέον ένα καθολικό δωρεάν credit 200 $/μήνα. Αντίθετα, υπάρχουν δωρεάν μηνιαία όρια ανά βαθμίδα API (δείτε τις επίσημες τιμές).
Πώς να Εξαγάγετε Δεδομένα από το Google Maps με Python: Οδηγός Βήμα προς Βήμα
Ας αναλύσουμε και τις δύο βασικές προσεγγίσεις—μέσω API και scraping HTML—ώστε να επιλέξετε αυτήν που ταιριάζει στις ανάγκες σας.
Προσέγγιση 1: Χρήση του Google Maps Places API (Προτεινόμενο)
Βήμα 1: Εγκατάσταση και Εισαγωγή των Απαραίτητων Βιβλιοθηκών
import os
import httpx
import pandas as pd
from dotenv import load_dotenv
Βήμα 2: Φορτώστε το API Key σας με Ασφάλεια
load_dotenv()
API_KEY = os.environ["GOOGLE_MAPS_API_KEY"]
Βήμα 3: Δημιουργήστε το Ερώτημα Αναζήτησής σας
Θα χρησιμοποιήσετε το endpoint Text Search για να βρείτε επιχειρήσεις που ταιριάζουν στα κριτήριά σας.
URL = "https://places.googleapis.com/v1/places:searchText"
FIELD_MASK = ",".join([
"places.id", "places.displayName", "places.formattedAddress",
"places.location", "places.rating", "places.userRatingCount",
"places.priceLevel", "places.types",
"places.nationalPhoneNumber", "places.websiteUri",
"nextPageToken",
])
Βήμα 4: Κάντε το API Request
def text_search(query, lat, lng, radius=3000, min_rating=4.0):
body = {
"textQuery": query,
"minRating": min_rating, # φίλτρο από την πλευρά του server
"includedType": "restaurant",
"openNow": False,
"pageSize": 20,
"locationBias": {
"circle": {
"center": {"latitude": lat, "longitude": lng},
"radius": radius,
}
},
}
headers = {
"Content-Type": "application/json",
"X-Goog-Api-Key": API_KEY,
"X-Goog-FieldMask": FIELD_MASK, # Να το ορίζετε πάντα!
}
r = httpx.post(URL, json=body, headers=headers, timeout=30)
r.raise_for_status()
return r.json()
Βήμα 5: Χειρισμός της Σελιδοποίησης και Συλλογή των Αποτελεσμάτων
def collect_all_results(query, lat, lng, radius=3000, min_rating=4.0):
results = []
next_page_token = None
while True:
data = text_search(query, lat, lng, radius, min_rating)
places = data.get('places', [])
results.extend(places)
next_page_token = data.get('nextPageToken')
if not next_page_token:
break
return results
Βήμα 6: Εξαγάγετε τα Δεδομένα με Pandas
df = pd.DataFrame(collect_all_results("coffee shops in Brooklyn", 40.6782, -73.9442))
df.to_csv("brooklyn_coffee_shops.csv", index=False)
Χρήσιμες συμβουλές:
- Ορίζετε πάντα το header
X-Goog-FieldMaskγια να ελέγχετε το κόστος. Αν ζητήσετε κριτικές ή φωτογραφίες, η τιμή ανά 1.000 αιτήματα μπορεί να ανέβει από 5 $ σε 25 $ (λεπτομέρειες τιμολόγησης). - Χρησιμοποιήστε φίλτρα από την πλευρά του server (όπως
minRating,includedType,locationBias) για να μην ξοδεύετε credits σε άσχετα αποτελέσματα. - Κρατήστε τιμές
place_idγια αποδιπλοποίηση και μελλοντικές ενημερώσεις.
Προσέγγιση 2: Web Scraping του HTML του Google Maps (Για Εκπαιδευτική/Μεμονωμένη Χρήση)
Προειδοποίηση: Το Google Maps είναι εφαρμογή μίας σελίδας. Πρέπει να χρησιμοποιήσετε αυτοματοποίηση browser (Playwright ή Selenium), και το scraping του HTML μπορεί να παραβιάζει τους όρους της Google. Χρησιμοποιήστε το για έρευνα, όχι για παραγωγική χρήση.
Βήμα 1: Εγκαταστήστε το Playwright και Εκκινήστε έναν Browser
from playwright.sync_api import sync_playwright
import time, re
def scrape_maps(query, max_results=100):
with sync_playwright() as pw:
browser = pw.chromium.launch(headless=True)
ctx = browser.new_context(
user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
locale="en-US",
)
page = ctx.new_page()
page.goto("https://www.google.com/maps", timeout=60_000)
page.fill("#searchboxinput", query)
page.click('button[aria-label="Search"]')
page.wait_for_selector('div[role="feed"]')
feed = page.locator('div[role="feed"]')
prev = 0
while True:
feed.evaluate("el => el.scrollBy(0, el.scrollHeight)")
time.sleep(2)
count = page.locator('div[role="feed"] > div > div[jsaction]').count()
if count == prev or count >= max_results:
break
prev = count
if page.locator("text=You've reached the end of the list").count():
break
rows = []
cards = page.locator('div[role="feed"] > div > div[jsaction]')
for i in range(cards.count()):
c = cards.nth(i)
name = c.locator("div.fontHeadlineSmall").inner_text() if c.locator("div.fontHeadlineSmall").count() else ""
rating_el = c.locator('span[role="img"]').first
raw = rating_el.get_attribute("aria-label") if rating_el.count() else ""
m = re.search(r"([\d.]+)\s+stars?\s+([\d,]+)\s+Reviews", raw or "")
rating = float(m.group(1)) if m else None
reviews = int(m.group(2).replace(",", "")) if m else None
rows.append({"name": name, "rating": rating, "reviews": reviews})
browser.close()
return rows
Συμβουλές:
- Η Google αλλάζει τυχαία τις CSS classes κάθε λίγες εβδομάδες, οπότε αυτός ο κώδικας μπορεί να χρειάζεται τακτικές ενημερώσεις.
- Χρησιμοποιήστε καθυστερήσεις που μοιάζουν ανθρώπινες και αποφύγετε το πολύ γρήγορο scraping για να μειώσετε τον κίνδυνο αποκλεισμού.
- Ποτέ μην προσπαθείτε να παρακάμψετε CAPTCHAs ή το σύστημα SearchGuard της Google—αυτό μπορεί να σας εκθέσει σε νομικό κίνδυνο.
Αποφύγετε το Τυφλό Scraping: Πώς να Στοχεύσετε Ακριβώς τα Δεδομένα που Χρειάζεστε
Το να κάνετε scraping σε όλα είναι συνταγή για χαμένο χρόνο και φουσκωμένα datasets. Δείτε πώς να στοχεύετε μόνο τα δεδομένα που έχουν σημασία:
- Δημιουργήστε στοχευμένες λίστες URL: Χρησιμοποιήστε τα φίλτρα αναζήτησης του ίδιου του Google Maps (κατηγορία, τοποθεσία, αξιολόγηση, ανοιχτό τώρα) για να περιορίσετε τα αποτελέσματα πριν από το scraping.
- Χρησιμοποιήστε αντιστοίχιση φράσεων: Αναζητήστε ακριβείς τύπους επιχειρήσεων ή λέξεις-κλειδιά (π.χ. “vegan bakery in Austin”).
- Φίλτρα τοποθεσίας: Καθορίστε πόλη, γειτονιά ή ακόμη και συντεταγμένες και ακτίνα για ακριβή στόχευση.
- Φιλτράρισμα από την πλευρά του server (API): Χρησιμοποιήστε
minRating,includedTypeκαιlocationBiasστο σώμα του API request. - Φιλτράρισμα από την πλευρά του client (Python): Μετά το scraping, χρησιμοποιήστε pandas για να φιλτράρετε επιχειρήσεις με αξιολόγηση πάνω από 4.0, περισσότερες από 50 κριτικές ή συγκεκριμένες κατηγορίες.
Παράδειγμα: Φιλτράρισμα μόνο εστιατορίων στο Μανχάταν με βαθμολογία πάνω από 4.0
df = pd.DataFrame(results)
filtered = df[(df['rating'] >= 4.0) & (df['types'].apply(lambda x: 'restaurant' in x))]
filtered.to_csv("manhattan_top_restaurants.csv", index=False)
Χρήση Python Libraries για Οργάνωση και Εξαγωγή Δεδομένων του Google Maps
Μόλις εξαγάγετε τα δεδομένα σας, ήρθε η ώρα να τα καθαρίσετε, να τα αναλύσετε και να τα εξαγάγετε για την ομάδα σας.
Καθαρισμός και Δομή Δεδομένων με Pandas
import pandas as pd
df = pd.read_json("brooklyn_restaurants.json")
df = (
df.dropna(subset=["name", "address"])
.drop_duplicates(subset=["place_id"])
.assign(
name=lambda d: d["name"].str.strip(),
phone=lambda d: d["phone"].astype(str)
.str.replace(r"\D", "", regex=True)
.str.replace(r"^1?(\d{10})$", r"+1\1", regex=True),
rating=lambda d: pd.to_numeric(d["rating"], errors="coerce"),
user_ratings_total=lambda d: pd.to_numeric(
d["user_ratings_total"], errors="coerce"
).fillna(0).astype("int32"),
)
)
Ανάλυση και Σύνοψη Δεδομένων
Παράδειγμα: Μέση βαθμολογία ανά γειτονιά
by_neighborhood = (
df.groupby("neighborhood", as_index=False)
.agg(avg_rating=("rating", "mean"),
n_places=("place_id", "nunique"),
median_reviews=("user_ratings_total", "median"))
.sort_values("avg_rating", ascending=False)
)
Εξαγωγή σε Excel ή CSV
df.to_csv("brooklyn_top.csv", index=False)
df.to_excel("brooklyn_top.xlsx", index=False, sheet_name="Top Rated")
Μεγάλα datasets; Χρησιμοποιήστε μορφή Parquet για ταχύτητα και αποδοτικότητα στον χώρο:
df.to_parquet("brooklyn_top.parquet", compression="zstd")
Thunderbit: Εναλλακτική με Τεχνητή Νοημοσύνη αντί για Python Google Maps Scraper
Αν τώρα σκέφτεστε, «αυτό θέλει πολλή ρύθμιση για μια απλή λίστα leads», δεν είστε μόνοι. Ακριβώς γι’ αυτό δημιουργήσαμε το Thunderbit—ένα εργαλείο web scraping χωρίς κώδικα, με τεχνητή νοημοσύνη, που κάνει την εξαγωγή δεδομένων από το Google Maps (και πολλά ακόμη) τόσο εύκολη όσο μερικά κλικ.
Γιατί Thunderbit;
- Δεν απαιτείται κώδικας ή API key: Απλώς ανοίξτε το Thunderbit Chrome Extension, μεταβείτε στο Google Maps και κάντε κλικ στο “AI Suggest Fields”.
- Ανίχνευση πεδίων με AI: Το AI του Thunderbit διαβάζει τη σελίδα και προτείνει τις σωστές στήλες—όνομα, διεύθυνση, αξιολόγηση, τηλέφωνο, ιστοσελίδα και άλλα.
- Scraping υποσελίδων: Θέλετε να εμπλουτίσετε τον πίνακά σας με δεδομένα από την ιστοσελίδα κάθε επιχείρησης; Το Thunderbit μπορεί να επισκεφθεί κάθε υποσελίδα και να αντλήσει αυτόματα επιπλέον πληροφορίες.
- Εξαγωγή σε Excel, Google Sheets, Airtable ή Notion: Τέλος το μπέρδεμα με pandas—απλώς πατάτε “Export” και τα δεδομένα σας είναι έτοιμα για την ομάδα.
- Προγραμματισμένο scraping: Ρυθμίστε επαναλαμβανόμενες εργασίες για να παρακολουθείτε ανταγωνιστές ή να ανανεώνετε αυτόματα τη λίστα leads.
- Μηδενική συντήρηση: Το AI του Thunderbit προσαρμόζεται στις αλλαγές του site, ώστε να μην διορθώνετε συνεχώς σπασμένα scripts.
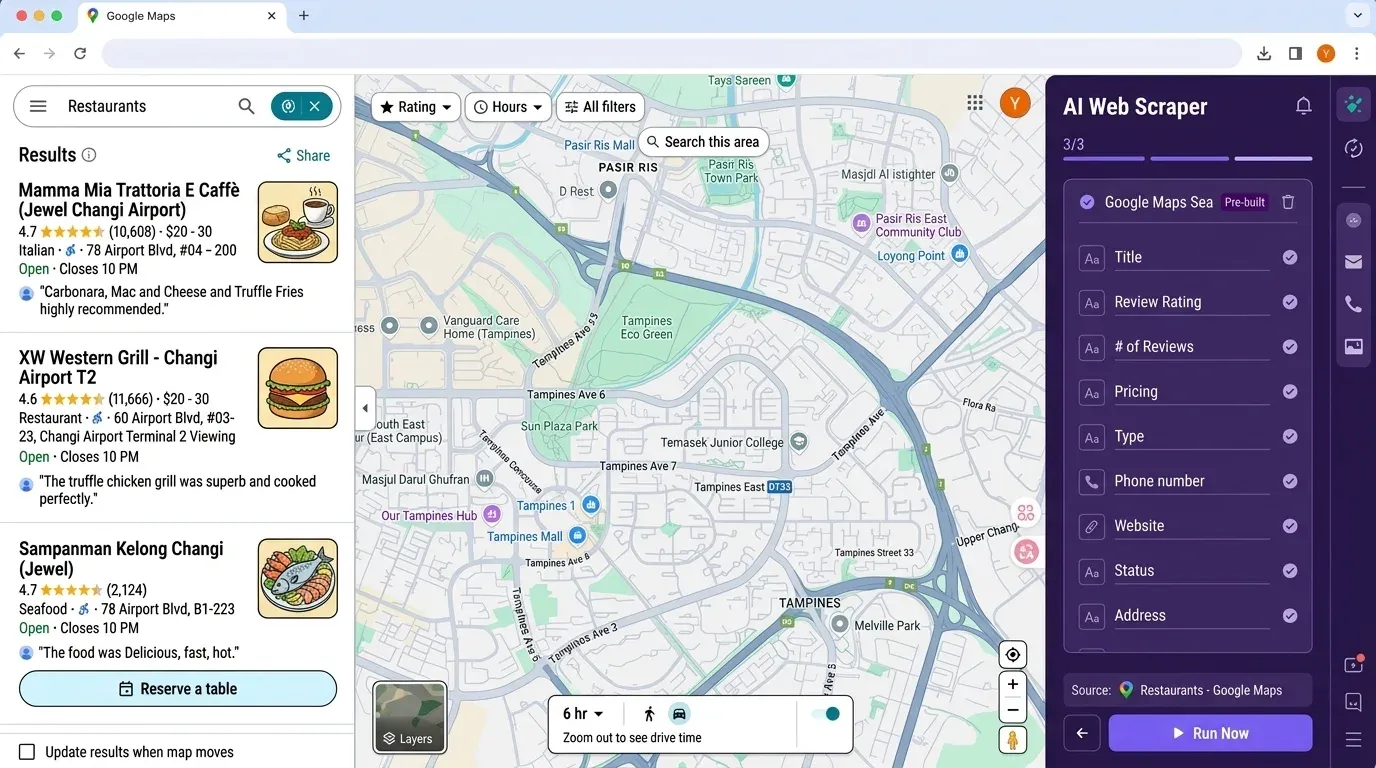
Ροή εργασίας Thunderbit vs Python:
| Βήμα | Python Scraper | Thunderbit |
|---|---|---|
| Εγκατάσταση εργαλείων | 30–60 λεπτά (Python, pip, libraries) | 2 λεπτά (Chrome Extension) |
| Ρύθμιση API key | 10–30 λεπτά (Cloud Console) | Δεν χρειάζεται |
| Επιλογή πεδίων | Χειροκίνητος κώδικας, field masks | AI Suggest Fields (1 κλικ) |
| Εξαγωγή δεδομένων | Γράψιμο/εκτέλεση scripts, διαχείριση σφαλμάτων | Κάντε κλικ στο “Scrape” |
| Εξαγωγή | pandas σε CSV/Excel | Export σε Excel/Sheets/Notion |
| Συντήρηση | Χειροκίνητες ενημερώσεις για αλλαγές στο site | Το AI προσαρμόζεται αυτόματα |
Μπόνους: Το Thunderbit το εμπιστεύονται πάνω από 30.000 χρήστες παγκοσμίως, και το δωρεάν πλάνο σάς επιτρέπει να εξάγετε έως 6 σελίδες (ή 10 με trial boost) χωρίς κόστος.
Συμμόρφωση: Όροι Χρήσης του Google Maps και Ηθική στο Scraping
Εδώ είναι το σημείο όπου τα περισσότερα tutorials Python γίνονται επικίνδυνα ξεπερασμένα. Να τι πρέπει να γνωρίζετε το 2026:
- Οι Όροι Χρήσης της Google Maps Platform §3.2.3 απαγορεύουν αυστηρά το scraping, το caching ή την εξαγωγή δεδομένων εκτός των επίσημων APIs (cloud.google.com). Η μόνη εξαίρεση: οι τιμές γεωγραφικού πλάτους/μήκους μπορούν να αποθηκεύονται προσωρινά έως 30 ημέρες· τα Place IDs μπορούν να αποθηκεύονται επ’ αόριστον.
- Οι χρήστες του API δεσμεύονται συμβατικά: Αν χρησιμοποιείτε API key, έχετε συμφωνήσει με τους όρους της Google—even αν αντλείτε μόνο δημόσια δεδομένα.
- Η παράκαμψη τεχνικών φραγμών (CAPTCHAs, SearchGuard) αποτελεί πλέον πιθανή παραβίαση του DMCA §1201, η οποία μπορεί να επιφέρει ποινικές κυρώσεις (ppc.land).
- GDPR και νόμοι περί ιδιωτικότητας: Αν συλλέγετε προσωπικά δεδομένα (emails, τηλέφωνα, ονόματα αξιολογητών) από το Google Maps, πρέπει να έχετε νόμιμη βάση και να σέβεστε αιτήματα διαγραφής. Η γαλλική CNIL επέβαλε πρόστιμο 200.000 € στην KASPR το 2024 για scraping επαφών από το LinkedIn (edpb.europa.eu).
- Βέλτιστες πρακτικές:
- Προτιμήστε το Places API όπου είναι δυνατό.
- Περιορίστε τον ρυθμό των αιτημάτων (≤10 QPS για API, 1–2 req/s για HTML scraping).
- Ποτέ μην παρακάμπτετε CAPTCHAs ή τεχνικά μπλοκαρίσματα.
- Μην αναδιανέμετε προσωπικά δεδομένα που εξάγατε.
- Σεβαστείτε αιτήματα opt-out και διαγραφής.
- Ελέγχετε πάντα τους τοπικούς νόμους—GDPR, CCPA και άλλοι εφαρμόζονται ενεργά.
Συμπέρασμα: Αν σας απασχολεί η συμμόρφωση, μείνετε στο API και ελαχιστοποιήστε τα δεδομένα που συλλέγετε. Για τους περισσότερους επιχειρηματικούς χρήστες, ένα εργαλείο χωρίς κώδικα όπως το Thunderbit μειώνει το ρίσκο (χωρίς API key, χωρίς αναδιανομή).
Προγραμματισμός και Αυτοματοποίηση της Εξαγωγής από το Google Maps με Python
Αν χρειάζεται να διατηρείτε τα δεδομένα σας φρέσκα—για παράδειγμα, για εβδομαδιαία παρακολούθηση ανταγωνιστών ή μηνιαίες ενημερώσεις της λίστας leads—ο αυτοματισμός είναι ο καλύτερός σας σύμμαχος.
Απλός Προγραμματισμός με schedule
import schedule, time
from my_scraper import run_job
schedule.every().day.at("03:00").do(run_job, query="restaurants in Brooklyn")
schedule.every(6).hours.do(run_job, query="coffee shops in Manhattan")
while True:
schedule.run_pending()
time.sleep(30)
Προγραμματισμός Επιπέδου Παραγωγής με APScheduler
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.triggers.cron import CronTrigger
sched = BackgroundScheduler(timezone="America/New_York")
sched.add_job(
run_job,
CronTrigger(hour=3, minute=15, jitter=600), # 3:15 π.μ. ± 10 λεπτά
kwargs={"query": "restaurants in Brooklyn"},
id="brooklyn_daily",
max_instances=1,
coalesce=True,
misfire_grace_time=3600,
)
sched.start()
Συμβουλές για Ασφαλή Αυτοματοποίηση
- Προσθέστε τυχαίο jitter στο πρόγραμμα για να αποφύγετε προβλέψιμα μοτίβα.
- Για HTML scraping, μην ξεπερνάτε ποτέ τα 1–2 αιτήματα το δευτερόλεπτο.
- Για χρήση API, παρακολουθείτε το quota σας και ρυθμίστε ειδοποιήσεις χρέωσης.
- Καταγράφετε πάντα τα σφάλματα και διατηρείτε ένα αρχείο “dead-letter” για αποτυχημένα αιτήματα.
Μπόνους Thunderbit: Με το Thunderbit, μπορείτε να προγραμματίσετε επαναλαμβανόμενα scrapes απευθείας από το UI—χωρίς κώδικα, χωρίς cron jobs, χωρίς ρύθμιση server.
Βασικά Συμπεράσματα: Αποδοτική, Στοχευμένη και Συμβατή Εξαγωγή Δεδομένων από το Google Maps
Ας συνοψίσουμε τα βασικά:
- Το Google Maps είναι η Νο. 1 πηγή για δεδομένα τοποθεσίας επιχειρήσεων, τροφοδοτώντας τα πάντα, από lead generation έως έρευνα αγοράς.
- Το scraping με Python προσφέρει ευελιξία και έλεγχο, αλλά συνοδεύεται από κόστος εγκατάστασης, συντήρησης και συμμόρφωσης—ιδίως καθώς εντείνονται τα μέτρα κατά των bots και η νομική επιβολή της Google.
- Η εξαγωγή μέσω API είναι η πιο ασφαλής και πιο κλιμακούμενη διαδρομή για τις περισσότερες ομάδες. Χρησιμοποιείτε πάντα field masks και φίλτρα από την πλευρά του server για να ελέγχετε το κόστος.
- Το HTML scraping είναι εύθραυστο και ριψοκίνδυνο—χρησιμοποιήστε το μόνο για περιστασιακή έρευνα και ποτέ μην παρακάμπτετε τεχνικά εμπόδια.
- Στοχεύστε τα δεδομένα σας: Χρησιμοποιήστε αντιστοίχιση φράσεων, φίλτρα τοποθεσίας και ροές εργασίας με pandas για να εξαγάγετε μόνο ό,τι χρειάζεστε.
- Το Thunderbit είναι η γρηγορότερη λύση για μη προγραμματιστές: με AI, χωρίς ρύθμιση, άμεση εξαγωγή και ενσωματωμένο προγραμματισμό.
- Η συμμόρφωση έχει σημασία: Σεβαστείτε τους όρους της Google, τους νόμους περί ιδιωτικότητας και τα rate limits για να αποφύγετε νομικούς πονοκεφάλους.
Για περισσότερα tutorials και συμβουλές, δείτε το Thunderbit Blog και το κανάλι μας στο YouTube.
Συχνές Ερωτήσεις
1. Είναι νόμιμο να εξάγετε δεδομένα από το Google Maps με Python το 2026;
Η εξαγωγή δεδομένων από το Google Maps μέσω του επίσημου API επιτρέπεται εντός των όρων της Google, αρκεί να σέβεστε τα quotas και να μην αναδιανέμετε περιορισμένα δεδομένα. Η εξαγωγή HTML από το Google Maps απαγορεύεται ρητά από τους Όρους Χρήσης της Google και ενέχει νομικό κίνδυνο, ειδικά αν παρακάμπτετε τεχνικά εμπόδια ή συλλέγετε προσωπικά δεδομένα χωρίς συναίνεση. Πάντα να ελέγχετε τους τοπικούς νόμους (GDPR, CCPA κ.λπ.) και να ακολουθείτε τις βέλτιστες πρακτικές συμμόρφωσης.
2. Ποια είναι η διαφορά ανάμεσα στη χρήση του Google Maps API και στο web scraping του HTML;
Το API είναι σταθερό, αδειοδοτημένο και σχεδιασμένο για εξαγωγή δεδομένων, αλλά απαιτεί API key και υπόκειται σε quotas και κόστος. Το HTML scraping χρησιμοποιεί αυτοματοποίηση browser για να αντλήσει δεδομένα από τη σελίδα που αποδίδεται, αλλά είναι εύθραυστο (η δομή αλλάζει συχνά), μπορεί να παραβιάζει τους όρους και είναι πιο ριψοκίνδυνο νομικά. Για τις περισσότερες επιχειρηματικές χρήσεις, η προτεινόμενη διαδρομή είναι το API.
3. Πόσο κοστίζει η εξαγωγή δεδομένων από το Google Maps με Python το 2026;
Η τιμολόγηση του Places API της Google γίνεται ανά 1.000 αιτήματα και κυμαίνεται από 5 $ (Essentials) έως 25 $ (Enterprise+Atmosphere), ανάλογα με τα πεδία που ζητάτε. Υπάρχουν δωρεάν μηνιαία όρια (10.000 για Essentials, 5.000 για Pro, 1.000 για Enterprise), αλλά η εξαγωγή σε μεγάλη κλίμακα μπορεί να αθροιστεί γρήγορα. Χρησιμοποιείτε πάντα field masks και φίλτρα από την πλευρά του server για να ελέγχετε το κόστος.
4. Πώς συγκρίνεται το Thunderbit με τα Python-based Google Maps scrapers;
Το Thunderbit είναι ένα εργαλείο web scraping χωρίς κώδικα, με τεχνητή νοημοσύνη, που σας επιτρέπει να εξάγετε δεδομένα από το Google Maps (και πολλά άλλα) χωρίς προγραμματισμό, API keys ή συντήρηση. Είναι ιδανικό για ομάδες πωλήσεων και μάρκετινγκ που θέλουν γρήγορες, αξιόπιστες εξαγωγές σε Excel, Google Sheets, Airtable ή Notion. Για τεχνικούς χρήστες που χρειάζονται προσαρμοσμένη λογική, η Python προσφέρει μεγαλύτερη ευελιξία αλλά απαιτεί περισσότερη ρύθμιση και διαχείριση συμμόρφωσης.
5. Πώς μπορώ να αυτοματοποιήσω επαναλαμβανόμενη εξαγωγή δεδομένων από το Google Maps;
Με Python, χρησιμοποιήστε βιβλιοθήκες προγραμματισμού όπως το schedule ή το APScheduler για να εκτελείτε τον scraper σας σε καθορισμένα διαστήματα (ημερησίως, εβδομαδιαίως κ.λπ.). Προσθέστε τυχαίο jitter για να αποφεύγετε τον εντοπισμό και παρακολουθείτε το API quota σας. Με το Thunderbit, μπορείτε να προγραμματίσετε επαναλαμβανόμενα scrapes απευθείας από το UI—χωρίς κώδικα ή ρύθμιση server.
Έτοιμοι να μετατρέψετε το Google Maps στο υπερ-όπλο σας για πωλήσεις και μάρκετινγκ; Είτε είστε λάτρης της Python είτε θέλετε την πιο γρήγορη λύση χωρίς κώδικα, τα εργαλεία υπάρχουν ήδη το 2026. Δοκιμάστε το Thunderbit για άμεσο scraping με AI—ή σηκώστε τα μανίκια και βουτήξτε στο API. Όπως και να έχει, ας είναι οι λίστες leads σας φρέσκες, οι εξαγωγές σας καθαρές και οι καμπάνιες σας γεμάτες τοπικούς υποψήφιους πελάτες με υψηλή πιθανότητα μετατροπής. Καλή εξαγωγή!
Μάθετε Περισσότερα
- Εκμάθηση Python Web Scraping: Λήψη Δεδομένων από Ιστοσελίδα
- Πώς να Χρησιμοποιήσετε το BeautifulSoup: Εκμάθηση Python Web Scraping
- Εκμάθηση Python Web Scraping: Πώς να Εξάγετε Δεδομένα από Ιστοσελίδα
- Πώς να Εξάγετε Δεδομένα από Ιστοσελίδα με Python Αποτελεσματικά
- Πώς να Γράψετε ένα Web Scraper με Python: Από την Αρχή μέχρι το Τέλος




