

Τα περισσότερα tutorials για eBay scraping έχουν διάρκεια ζωής περίπου τριών μηνών. Το ξέρω, γιατί η ομάδα μας στο Thunderbit βλέπει συνεχώς developers να παλεύουν με σπασμένα code snippets, παρωχημένα CSS selectors και GitHub repos που «δούλευαν» αλλά σταμάτησαν σιωπηλά μετά από δύο redesigns του eBay.
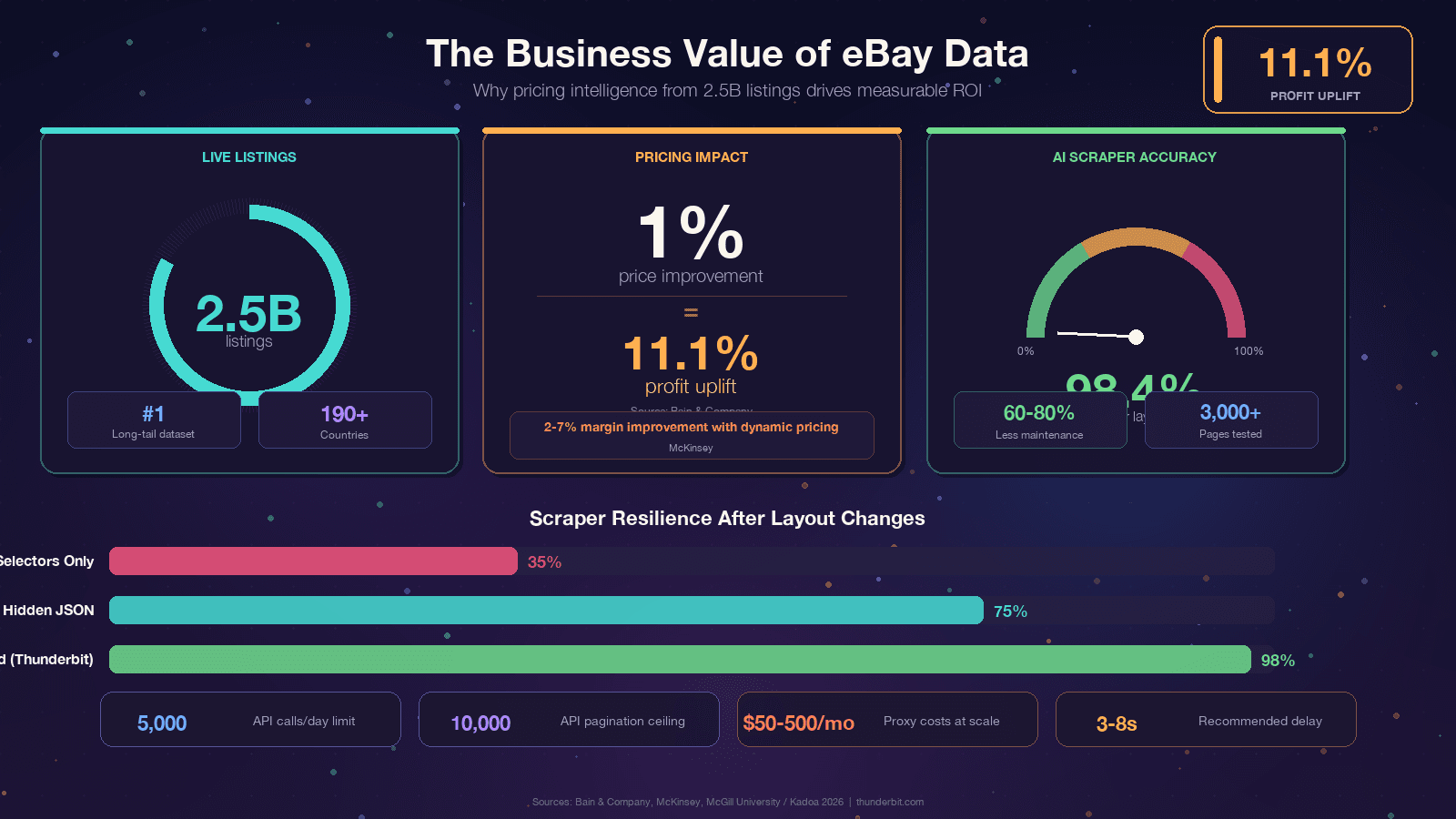
eBay φιλοξενεί περίπου 2,5 δισεκατομμύρια ενεργές καταχωρίσεις — το μεγαλύτερο dataset long-tail τιμολόγησης στο ανοιχτό web μετά το Amazon. Αυτά τα δεδομένα τροφοδοτούν τα πάντα, από pricing για μεταπωλητές μέχρι competitive intelligence. Όμως η προγραμματική πρόσβαση είναι κινούμενος στόχος: το React-based frontend του eBay αλλάζει συνεχώς τα CSS class names, τα A/B tests εμφανίζουν διαφορετικές DOM δομές σε διαφορετικούς χρήστες και το Akamai Bot Manager παρεμβάλλεται ανάμεσα σε εσάς και το HTML. Αυτός ο οδηγός σάς δίνει Python code που λειτουργεί σήμερα, εξηγεί γιατί χαλάνε οι scrapers ώστε να χτίζετε ανθεκτικά εργαλεία, αναλύει ειλικρινά την απόφαση eBay API vs scraping και δείχνει και μια no-code λύση όταν το Python δεν αξίζει την προσπάθεια εγκατάστασης.
Τι σημαίνει να κάνεις scrape το eBay με Python;
Το web scraping του eBay με Python σημαίνει ότι γράφετε scripts που κατεβάζουν προγραμματικά σελίδες του eBay, αναλύουν το HTML (ή το κρυφό JSON) και εξάγουν δομημένα δεδομένα — τίτλους, τιμές, στοιχεία πωλητή, ημερομηνίες πώλησης, λεπτομέρειες παραλλαγών — σε μορφή που μπορείτε πραγματικά να χρησιμοποιήσετε, όπως CSV, spreadsheet ή βάση δεδομένων.
Μπορείτε να κάνετε scrape σε διάφορους τύπους σελίδων του eBay:
- Σελίδες αποτελεσμάτων αναζήτησης (π.χ. όλες οι καταχωρίσεις για "AirPods Pro")
- Σελίδες μεμονωμένων προϊόντων (πλήρεις προδιαγραφές, εικόνες, στοιχεία πωλητή)
- Sold/completed listings (πραγματικές τιμές και ημερομηνίες συναλλαγών)
- Προφίλ πωλητών και αξιολογήσεις
Η Python είναι η πιο πρακτική γλώσσα για αυτή τη δουλειά. Το οικοσύστημά της — Requests, BeautifulSoup, lxml, pandas — κάνει απλό το κατέβασμα σελίδων, το parsing του HTML και τη διαχείριση δεδομένων. Υπάρχει όμως σημαντική διαφορά ανάμεσα στο να κάνετε scrape το HTML του site και στο να χρησιμοποιείτε το επίσημο API του eBay — κάτι που θα καλύψω αμέσως μετά.
Γιατί να κάνετε scrape το eBay; Πραγματικές επιχειρηματικές χρήσεις
Αν διαβάζετε αυτό το άρθρο, πιθανότατα έχετε ήδη έναν λόγο. Παρ’ όλα αυτά, αξίζει να το δούμε με βάση το πραγματικό επιχειρηματικό όφελος, γιατί το ROI των δεδομένων του eBay είναι εντυπωσιακό. Η Bain διαπίστωσε ότι μια βελτίωση 1% στην τιμή που τελικά επιτυγχάνεται μεταφράζεται σε αύξηση κέρδους 11,1% σε χιλιάδες επιχειρήσεις. Η McKinsey αποδίδει στο δυναμικό pricing έως 5% αύξηση πωλήσεων και 2–7% βελτίωση περιθωρίου στο retail.
Οι πιο συνηθισμένες χρήσεις που βλέπω είναι:
| Χρήση | Απαραίτητα δεδομένα | Επιχειρηματικό αποτέλεσμα |
|---|---|---|
| Παρακολούθηση τιμών & repricing | Ενεργές τιμές καταχωρίσεων, μεταφορικά, κατάσταση | Ανταγωνιστική τιμολόγηση, προστασία περιθωρίου |
| Ανάλυση ανταγωνισμού | Σειρές προϊόντων, προσφορές, όροι αποστολής | Στρατηγική τοποθέτηση, κενά στο assortment |
| Έρευνα αγοράς & εντοπισμός τάσεων | Ρυθμός νέων καταχωρίσεων, τάσεις κατηγορίας, μοτίβα ζήτησης | Εντοπισμός νέων προϊόντων, πρόβλεψη ζήτησης |
| Τιμολόγηση μεταπώλησης / αποτίμηση | Τιμές πώλησης, ημερομηνίες πώλησης, κατάσταση | Δίκαιη αγοραία αξία, αποφάσεις buy-box |
| Ανάλυση sentiment | Αξιολογήσεις, ratings, πολιτική επιστροφών | Γνώση ποιότητας προϊόντος, ικανοποίηση πελατών |
| Lead generation | Προφίλ πωλητών, πληροφορίες καταστήματος, στοιχεία επικοινωνίας | B2B προσέγγιση σε πωλητές με υψηλό GMV |
Το κοινό σημείο: το eBay έχει τα δεδομένα, αλλά είναι κλειδωμένα μέσα στις web σελίδες.
Το scraping είναι ο τρόπος να τα μετατρέψετε σε ανταγωνιστικό πλεονέκτημα.
Επίσημο API του eBay vs Python Web Scraping: Τι να διαλέξετε;
Αυτό είναι το ερώτημα που θα ήθελα να απαντούν πιο ειλικρινά τα περισσότερα tutorials. Το eBay προσφέρει επίσημα APIs — κυρίως το Browse API — και πολλοί αναρωτιούνται αν πρέπει να τα χρησιμοποιήσουν ή να κάνουν απευθείας scrape. Η απάντηση εξαρτάται απόλυτα από το ποια δεδομένα χρειάζεστε.
| Κριτήριο | eBay Browse/Finding API | Python Web Scraping |
|---|---|---|
| Sold/completed listings | Περιορισμένη πρόσβαση — υπάρχει το Marketplace Insights API αλλά η πρόσβαση συχνά απορρίπτεται | Πλήρης πρόσβαση μέσω URL params LH_Sold=1&LH_Complete=1 |
| Όρια κλήσεων | 5.000 κλήσεις/ημέρα στο βασικό επίπεδο | Διαχείριση από εσάς (εξαρτάται από proxies) |
| Πεδίο δεδομένων | Προκαθορισμένο (τίτλος, τιμή, κατηγορία, βασικά στοιχεία πωλητή) | Ό,τι φαίνεται στη σελίδα (reviews, πλήρεις προδιαγραφές, variant matrix) |
| Πολυπλοκότητα ρύθμισης | OAuth 2.0, εγγραφή app, API keys | pip install + κώδικας |
| Σταθερότητα | Σταθερά endpoints | Χαλάει όταν αλλάζει το HTML |
| Κόστος | Υπάρχει δωρεάν επίπεδο, πληρωμή για όγκο | Δωρεάν κώδικας, αλλά κόστος proxies σε μεγάλη κλίμακα |
| Variant/MSKU data | Μερικώς — συχνά μόνο parent SKU | Πλήρες (μέσω parsing του hidden JSON) |
| Βάθος pagination | σκληρό όριο 10.000 items | Θεωρητικά απεριόριστο |
Μια σύντομη σημείωση: το παλιό Finding API (που είχε το findCompletedItems) καταργήθηκε πλήρως τον Φεβρουάριο του 2025. Αν χρησιμοποιείτε ebaysdk-python ή οποιαδήποτε βιβλιοθήκη που χτυπά το Finding module, αυτή τη στιγμή δεν λειτουργεί σε production.
Η δική μου σύσταση: Χρησιμοποιήστε το Browse API για σταθερά, μεσαίου όγκου, δομημένα catalog queries σε ενεργές καταχωρίσεις. Χρησιμοποιήστε Python scraping όταν χρειάζεστε sold prices, reviews, variant data ή οποιοδήποτε πεδίο δεν εκθέτει το API. Πολλές ομάδες χρησιμοποιούν και τα δύο.
Ποια εργαλεία και βιβλιοθήκες χρειάζεστε για να κάνετε scrape το eBay με Python
Πριν γράψουμε κώδικα, ας δούμε την εργαλειοθήκη. Στις περισσότερες σελίδες του eBay δεν χρειάζεστε headless browser — τα δεδομένα είναι ενσωματωμένα στο server-rendered HTML.
| Βιβλιοθήκη | Σκοπός |
|---|---|
requests ή httpx | HTTP client για λήψη σελίδων του eBay |
curl_cffi | HTTP client με πραγματικό browser TLS fingerprinting (κρίσιμο για το Akamai) |
beautifulsoup4 | HTML parser για εξαγωγή με CSS selectors |
lxml | Γρήγορο backend parser για το BeautifulSoup |
jmespath | Γλώσσα query για parsing nested JSON blobs |
pandas | Διαχείριση δεδομένων και export σε CSV/Excel |
gspread | Ενσωμάτωση με Google Sheets |
Εγκαταστήστε τα όλα με μία εντολή:
pip install requests httpx curl_cffi beautifulsoup4 lxml jmespath pandas gspread
Χρησιμοποιήστε Python 3.11+ — το pandas 3.0 απαιτεί 3.10+, και η 3.11 προσφέρει κέρδος απόδοσης 10–60% σε I/O-bound εργασίες.
Μια βιβλιοθήκη αξίζει ειδική αναφορά: το curl_cffi είναι η σημαντικότερη αναβάθμιση που μπορεί να κάνει ένα eBay scraper το 2026. Το eBay χρησιμοποιεί Akamai Bot Manager, και ο βασικός μηχανισμός εντοπισμού του Akamai είναι το TLS fingerprinting. Τα απλά requests εκπέμπουν ένα Python-shaped JA3 fingerprint που μπλοκάρεται αμέσως. Το curl_cffi μιμείται το TLS handshake ενός πραγματικού Chrome browser, κάτι που καλύπτει περίπου το 90% των targets που προστατεύονται από Akamai χωρίς να χρειαστεί headless browser.
Δοκιμάστε το Thunderbit για οποιαδήποτε ιστοσελίδα
Βήμα προς βήμα: Πώς να κάνετε scrape τα αποτελέσματα αναζήτησης του eBay με Python
Αυτό είναι το βασικό tutorial. Θα κάνουμε scrape τις σελίδες αποτελεσμάτων αναζήτησης του eBay για product listings.
- Δυσκολία: Αρχάριος–Ενδιάμεσος
- Χρόνος που απαιτείται: ~30 λεπτά για το πρώτο λειτουργικό scrape
- Τι θα χρειαστείτε: Python 3.11+, τις παραπάνω βιβλιοθήκες, ένα terminal και ένα eBay search URL-στόχο
Βήμα 1: Στήστε το Python project σας
Δημιουργήστε έναν φάκελο project και εγκαταστήστε τις εξαρτήσεις:
mkdir ebay-scraper && cd ebay-scraper
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
pip install requests curl_cffi beautifulsoup4 lxml pandas
Δημιουργήστε ένα αρχείο με όνομα scrape_ebay.py. Αυτός είναι ο χώρος εργασίας σας.
Βήμα 2: Φτιάξτε το URL αναζήτησης του eBay
Η δομή του search URL του eBay είναι απλή. Το βασικό parameter είναι το _nkw (keyword):
import urllib.parse
keyword = "airpods pro"
base_url = "https://www.ebay.com/sch/i.html"
params = {
"_nkw": keyword,
"_ipg": "120", # items per page: 60, 120 ή 240 (το 240 μπορεί να ενεργοποιήσει bot flags)
"_pgn": "1", # αριθμός σελίδας
}
url = f"{base_url}?{urllib.parse.urlencode(params)}"
print(url)
# https://www.ebay.com/sch/i.html?_nkw=airpods+pro&_ipg=120&_pgn=1
Άλλα χρήσιμα parameters:
LH_BIN=1— μόνο Buy It Now_sacat=175673— συγκεκριμένη κατηγορία_sop=12— ταξινόμηση με best match (10 = χαμηλότερη τιμή+μεταφορικά, 13 = newly listed)LH_Complete=1&LH_Sold=1— sold/completed listings (θα καλυφθούν σε ξεχωριστή ενότητα παρακάτω)
Βήμα 3: Στείλτε request και διαχειριστείτε την απάντηση
Εδώ το curl_cffi αποδεικνύει την αξία του. Ένα απλό requests.get() συχνά επιστρέφει 403 από το Akamai. Με το curl_cffi, μιμούμαστε πραγματικό Chrome browser:
from curl_cffi import requests as cffi_requests
import random, time
USER_AGENTS = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64; rv:124.0) Gecko/20100101 Firefox/124.0",
]
HEADERS = {
"User-Agent": random.choice(USER_AGENTS),
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
}
def fetch_page(url, max_retries=5):
delay = 2
for attempt in range(max_retries):
try:
r = cffi_requests.get(url, impersonate="chrome124", headers=HEADERS, timeout=30)
if r.status_code == 200:
return r.text
if r.status_code in (403, 429, 503):
retry_after = r.headers.get("Retry-After")
sleep_for = float(retry_after) if retry_after else delay + random.uniform(0, 1)
print(f" Status {r.status_code}, retrying in {sleep_for:.1f}s...")
time.sleep(sleep_for)
delay *= 2
continue
r.raise_for_status()
except Exception as e:
print(f" Request error: {e}, retrying...")
time.sleep(delay)
delay *= 2
raise RuntimeError(f"Failed after {max_retries} retries: {url}")
Το exponential backoff με jitter είναι σημαντικό — τα σταθερά sleep intervals είναι από μόνα τους fingerprint bot.
Βήμα 4: Αναλύστε τις καταχωρίσεις προϊόντων από τη σελίδα αναζήτησης
Το eBay βρίσκεται αυτή τη στιγμή σε μεταβατική φάση μεταξύ δύο layouts για τα αποτελέσματα αναζήτησης. Ένας ανθεκτικός scraper πρέπει να χειρίζεται και τα δύο:
| Πεδίο | Legacy Layout | Νέο Layout |
|---|---|---|
| Container κάρτας | li.s-item | li.s-card ή div.su-card-container |
| Τίτλος | .s-item__title | .s-card__title |
| URL | a.s-item__link[href] | a.su-link[href] |
| Τιμή | span.s-item__price | .s-card__price |
Ο κώδικας parsing που καλύπτει και τα δύο layouts:
from bs4 import BeautifulSoup
def parse_search_results(html):
soup = BeautifulSoup(html, "lxml")
cards = soup.select("li.s-item, li.s-card, div.su-card-container")
results = []
for card in cards:
# Τίτλος — δοκιμάζουμε και τα δύο layouts
title_el = card.select_one(".s-item__title, .s-card__title")
title = title_el.get_text(strip=True) if title_el else None
# Παραλείπουμε το ψεύτικο placeholder card "Shop on eBay"
if not title or "Shop on eBay" in title:
continue
# Τιμή
price_el = card.select_one("span.s-item__price, .s-card__price")
price = price_el.get_text(strip=True) if price_el else None
# URL
link_el = card.select_one("a.s-item__link[href], a.su-link[href]")
url = link_el["href"].split("?")[0] if link_el else None
# Εικόνα
img_el = card.select_one("img.s-item__image-img, .s-card__image img")
image = None
if img_el:
image = img_el.get("src") or img_el.get("data-src")
# Μεταφορικά
ship_el = card.select_one("span.s-item__shipping, span.s-item__logisticsCost, .s-card__attribute-row")
shipping = ship_el.get_text(strip=True) if ship_el else None
results.append({
"title": title,
"price": price,
"url": url,
"image": image,
"shipping": shipping,
})
return results
Η παγίδα με το πρώτο phantom card είναι κλασικό gotcha. Το πρώτο li.s-item σε πολλές σελίδες αναζήτησης του eBay είναι ένα hidden placeholder με τίτλο "Shop on eBay" και χωρίς πραγματική τιμή. Πάντα να το φιλτράρετε.
Βήμα 5: Χειριστείτε pagination για να κάνετε scrape πολλές σελίδες
eBay κάνει pagination μέσω του parameter _pgn. Το link της επόμενης σελίδας χρησιμοποιεί το a.pagination__next:
import urllib.parse
def scrape_ebay_search(keyword, max_pages=5):
all_results = []
for page_num in range(1, max_pages + 1):
params = {"_nkw": keyword, "_ipg": "120", "_pgn": str(page_num)}
url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
print(f"Scraping page {page_num}: {url}")
html = fetch_page(url)
results = parse_search_results(html)
if not results:
print(f" No results on page {page_num}, stopping.")
break
all_results.extend(results)
print(f" Found {len(results)} listings (total: {len(all_results)})")
# Ευγενική καθυστέρηση — 3 έως 8 δευτερόλεπτα με τυχαία μεταβλητότητα
time.sleep(random.uniform(3, 8))
return all_results
Το τυχαίο jitter 3–8 δευτερολέπτων δεν είναι προαιρετικό.
Το Akamai layer του eBay εντοπίζει συνεχή ρυθμό πάνω από 1 request/δευτ. από το ίδιο IP.
Βήμα 6: Εξάγετε τα δεδομένα σας σε CSV ή JSON
import pandas as pd
results = scrape_ebay_search("airpods pro", max_pages=3)
df = pd.DataFrame(results)
df.to_csv("ebay_airpods.csv", index=False)
df.to_json("ebay_airpods.json", orient="records", indent=2)
print(f"Exported {len(df)} listings to CSV and JSON.")
Τώρα θα πρέπει να έχετε ένα καθαρό spreadsheet με eBay listings. Στο δικό μου μηχάνημα, το scraping 3 σελίδων (360 listings) πήρε περίπου 45 δευτερόλεπτα μαζί με τις καθυστερήσεις.
Πώς να κάνετε scrape τις σελίδες προϊόντων του eBay με Python
Τα αποτελέσματα αναζήτησης δίνουν μια σύνοψη. Οι σελίδες προϊόντων έχουν τα πιο χρήσιμα στοιχεία: πλήρεις περιγραφές, βαθμολογίες πωλητή, item specifics, carousels εικόνων και δεδομένα παραλλαγών.
Parsing μιας μεμονωμένης σελίδας προϊόντος
eBay item pages βρίσκονται στη διαδρομή /itm/<ITEM_ID>. Η πιο σταθερή οδός εξαγωγής είναι το JSON-LD — το eBay ενσωματώνει ένα Product schema block που αντέχει σχεδόν σε όλα τα CSS reshuffles:
import json
def parse_item_page(html):
soup = BeautifulSoup(html, "lxml")
item = {}
# 1. JSON-LD — η πιο σταθερή οδός εξαγωγής
for tag in soup.find_all("script", type="application/ld+json"):
try:
data = json.loads(tag.string or "")
except (json.JSONDecodeError, TypeError):
continue
if isinstance(data, dict) and data.get("@type") == "Product":
item["title"] = data.get("name")
item["brand"] = (data.get("brand") or {}).get("name")
item["images"] = data.get("image")
offers = data.get("offers") or {}
item["price"] = offers.get("price")
item["currency"] = offers.get("priceCurrency")
break
# 2. CSS fallbacks για πεδία που δεν υπάρχουν στο JSON-LD
def first_text(selectors):
for sel in selectors:
el = soup.select_one(sel)
if el and el.get_text(strip=True):
return el.get_text(strip=True)
return None
item.setdefault("title", first_text([
"h1.x-item-title__mainTitle",
"h1.x-item-title__mainTitle .ux-textspans--BOLD",
]))
item["condition"] = first_text([
".x-item-condition-text .ux-textspans",
])
item["seller"] = first_text([
".x-sellercard-atf__info__about-seller a .ux-textspans",
])
item["shipping"] = first_text([
"div.ux-labels-values--shipping .ux-textspans--BOLD",
])
# 3. Item specifics
specifics = {}
for dl in soup.select(".ux-layout-section-evo__item--table-view dl.ux-labels-values"):
k = dl.select_one(".ux-labels-values__labels-content .ux-textspans")
v = dl.select_one(".ux-labels-values__values-content .ux-textspans")
if k and v:
specifics[k.get_text(strip=True).rstrip(":")] = v.get_text(strip=True)
item["specifics"] = specifics
return item
Το μοτίβο εδώ — πρώτα JSON-LD, μετά CSS fallbacks — είναι το κλειδί για scrapers που δεν χαλάνε κάθε τρίμηνο. Περισσότερα γι’ αυτό πιο κάτω.
Scraping eBay Product Variants (MSKU Data)
Ορισμένες καταχωρίσεις του eBay έχουν πολλές παραλλαγές — διαφορετικά χρώματα, μεγέθη, χωρητικότητες αποθήκευσης. Το ορατό DOM δείχνει μόνο ένα εύρος τιμής, όπως "$899 έως $1,099", μέχρι ο χρήστης να επιλέξει μια επιλογή. Η πραγματική τιμολόγηση ανά παραλλαγή βρίσκεται σε ένα κρυφό JavaScript object που λέγεται MSKU.
Αυτό είναι ένα σημείο όπου το eBay API δίνει μόνο μερικά δεδομένα (parent SKU), οπότε το scraping είναι καλύτερη επιλογή.
import re, json
def extract_variants(html):
# Η μη απληστία στο match είναι κρίσιμη — το greedy .+ καταπίνει ολόκληρη τη σελίδα
m = re.search(r'"MSKU"\s*:\s*(\{.+?\})\s*,\s*"QUANTITY"', html, re.DOTALL)
if not m:
return []
try:
msku = json.loads(m.group(1))
except json.JSONDecodeError:
return []
item_labels = {str(k): v["displayLabel"] for k, v in msku.get("menuItemMap", {}).items()}
skus = []
for combo_key, variation_id in msku.get("variationCombinations", {}).items():
option_ids = combo_key.split("_")
options = [item_labels.get(oid, oid) for oid in option_ids]
var = msku.get("variationsMap", {}).get(str(variation_id), {})
bin_model = var.get("binModel", {})
price_spans = bin_model.get("price", {}).get("textSpans", [{}])
price = price_spans[0].get("text") if price_spans else None
qty = var.get("quantity")
skus.append({
"options": options,
"price": price,
"quantity_available": qty,
"variation_id": variation_id,
})
return skus
Αυτό το μη απληθές (.+?) στο regex είναι το σημείο όπου σκοντάφτουν οι περισσότεροι scrapers του eBay. Το greedy .+ καταπίνει τα πάντα μέχρι το τελευταίο "QUANTITY" στη σελίδα, δημιουργώντας malformed JSON. Έχω δει αυτό το bug σε τουλάχιστον τρία tutorials που «δούλευαν».
Πώς να κάνετε scrape τα sold και completed listings του eBay με Python
Αυτό είναι το use case που δικαιολογεί το scraping αντί για το API. Τα sold-item δεδομένα — τι πουλήθηκε πραγματικά, σε ποια τιμή και πότε — είναι το gold standard για έρευνα αγοράς, τιμολόγηση μεταπώλησης και αποτιμήσεις. Το eBay Browse API δεν τα παρέχει. Το Marketplace Insights API θεωρητικά το κάνει, αλλά η πρόσβαση είναι “Limited Release” και συχνά απορρίπτεται.
Τα URL parameters που χρειάζεστε είναι LH_Complete=1 (completed listings) και LH_Sold=1 (μόνο όσα πουλήθηκαν πραγματικά). Πρέπει να τα βάλετε και τα δύο. Αν βάλετε μόνο LH_Sold=1, σε ορισμένες κατηγορίες επιστρέφει σιωπηλά ενεργές καταχωρίσεις — αυτό είναι το #1 λάθος που κάνει η κοινότητα.
def scrape_sold_listings(keyword, max_pages=3):
all_sold = []
for page_num in range(1, max_pages + 1):
params = {
"_nkw": keyword,
"_ipg": "120",
"_pgn": str(page_num),
"LH_Complete": "1",
"LH_Sold": "1",
}
url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
print(f"Scraping sold page {page_num}...")
html = fetch_page(url)
soup = BeautifulSoup(html, "lxml")
cards = soup.select("li.s-item")
for card in cards:
title_el = card.select_one(".s-item__title")
title = title_el.get_text(strip=True) if title_el else None
if not title or "Shop on eBay" in title:
continue
# Περιλαμβάνουμε μόνο πραγματικά sold items (πράσινη τιμή POSITIVE)
sold_tag = card.select_one(
".s-item__title--tag .POSITIVE, .s-item__caption--signal.POSITIVE"
)
if sold_tag is None:
continue # Completed listing που δεν πουλήθηκε — το παραλείπουμε
price_el = card.select_one("span.s-item__price")
price = price_el.get_text(strip=True) if price_el else None
# Ανάγνωση ημερομηνίας πώλησης
sold_date = None
import re, datetime as dt
card_text = card.get_text()
m = re.search(r"Sold\s+([A-Z][a-z]{2}\s+\d{1,2},\s*\d{4})", card_text)
if m:
sold_date = dt.datetime.strptime(m.group(1), "%b %d, %Y").strftime("%Y-%m-%d")
link_el = card.select_one("a.s-item__link[href]")
url = link_el["href"].split("?")[0] if link_el else None
all_sold.append({
"title": title,
"sold_price": price,
"sold_date": sold_date,
"url": url,
})
if not cards:
break
time.sleep(random.uniform(3, 8))
return all_sold
Η βασική διαφορά στο HTML: τα sold items δείχνουν την τιμή με πράσινο χρώμα (μέσα σε wrapper .POSITIVE), ενώ τα unsold completed listings δείχνουν την τιμή με κόκκινο και διακριτή διαγραφή. Πάντα φιλτράρετε με βάση την κλάση .POSITIVE.
Γιατί χαλάνε οι scrapers του eBay (και πώς να φτιάξετε ανθεκτικούς)
Αν ο scraper σας για το eBay σταμάτησε να λειτουργεί, δεν είστε μόνοι. Αυτό είναι το #1 πρόβλημα σε κάθε νήμα forum για scraping του eBay που έχω διαβάσει. Το ερώτημα δεν είναι αν θα χαλάσει ο scraper σας — είναι πότε.
Γιατί συμβαίνει:
- Το eBay χρησιμοποιεί React-based rendering με δυναμικά παραγόμενα class names που αλλάζουν σε κάθε deploy
- Τα A/B tests δίνουν διαφορετικές DOM δομές σε διαφορετικούς χρήστες (το dual
s-item/s-cardlayout είναι ζωντανό παράδειγμα αυτή τη στιγμή) - Περιοδικά redesigns αλλάζουν το nesting του HTML, ακόμη κι όταν τα δεδομένα παραμένουν ίδια
- Παλιά selectors όπως
#itemTitleκαι#prcIsumέχουν αφαιρεθεί εδώ και χρόνια, αλλά συνεχίζουν να εμφανίζονται σε tutorials
Όπως το θέτει ο οδηγός του Scrapfly για το 2026: «Η πραγματική πρόκληση με το eBay web scraping είναι η διαχείριση των αλλαγών στα CSS selectors του eBay. Το eBay ενημερώνει τακτικά το frontend του, σπάζοντας scrapers που βασίζονται σε συγκεκριμένα class names.»
Στρατηγικές άμυνας για eBay scrapers μεγάλης διάρκειας
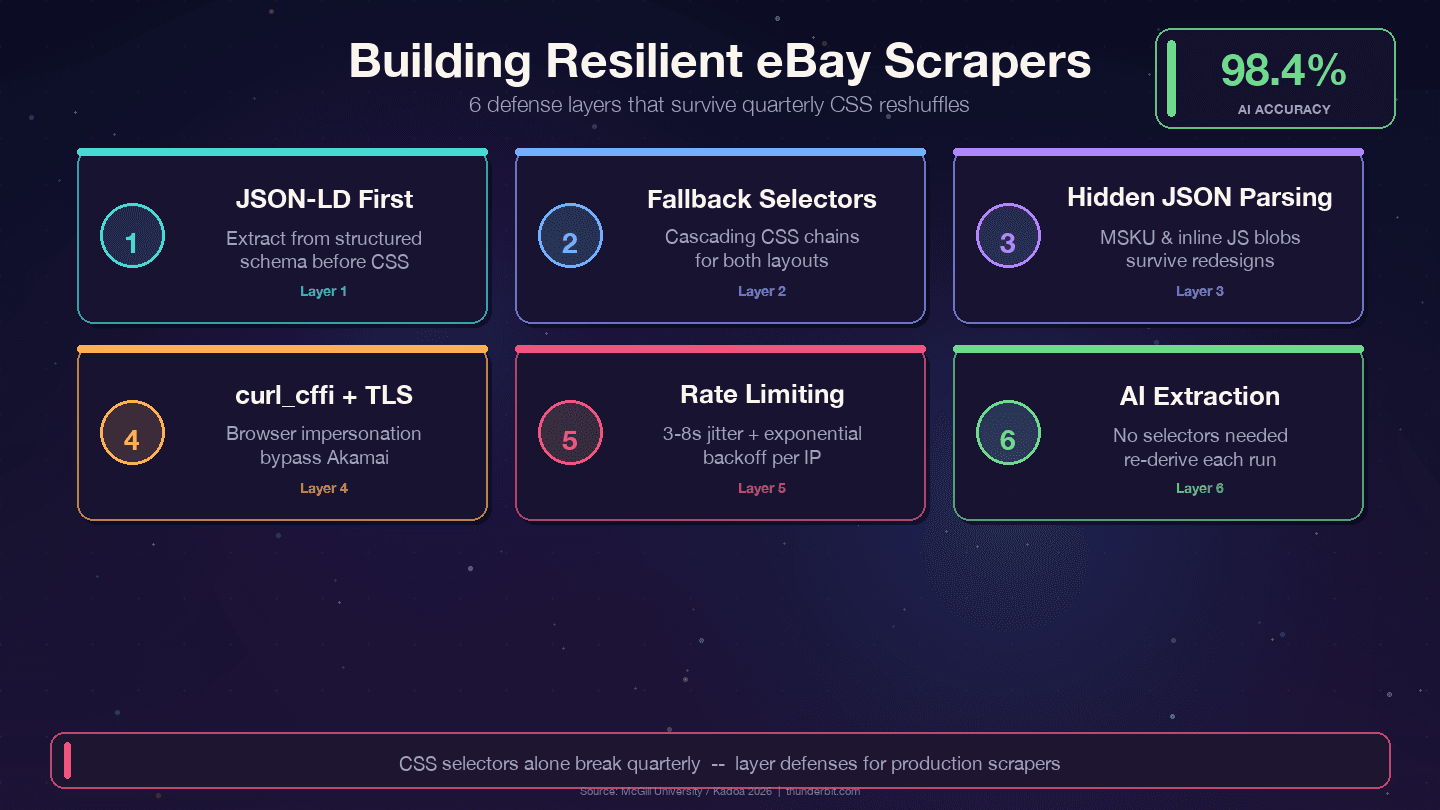
Τέσσερις στρατηγικές που αντέχουν στις τριμηνιαίες ανακατατάξεις του eBay:
1. Προτιμήστε JSON-LD αντί για CSS selectors. Το eBay ενσωματώνει structured Product schema δεδομένα σε κάθε item page. Το data layer αλλάζει πολύ λιγότερο από το presentation layer — οι designers αναδομούν CSS classes κάθε τρίμηνο, αλλά ονόματα πεδίων όπως price, name και seller συνδέονται με internal APIs και σπάνια αλλάζουν.
2. Χρησιμοποιήστε cascading fallback selectors. Μην βασίζεστε ποτέ σε έναν μόνο CSS selector. Δώστε πάντα εναλλακτικές:
def first_text(soup, selectors):
for sel in selectors:
el = soup.select_one(sel)
if el and el.get_text(strip=True):
return el.get_text(strip=True)
return None
title = first_text(soup, [
"h1.x-item-title__mainTitle",
"h1.x-item-title__mainTitle .ux-textspans--BOLD",
"[data-testid='x-item-title'] h1",
])
3. Αναλύστε κρυφά JSON blobs. Το object MSKU για variants και τα inline JavaScript δεδομένα επιβιώνουν των CSS αλλαγών επειδή δημιουργούνται server-side. Το regex extraction από <script> tags απαιτεί περισσότερη δουλειά στην αρχή, αλλά μειώνει δραματικά τη συντήρηση.
4. Καταγράφετε αποτυχίες selectors. Βάλτε monitoring ώστε να ξέρετε πότε ένας selector σταματά να ταιριάζει, όχι απλώς ότι τα δεδομένα σας είναι κενά:
if title is None:
print(f"WARNING: title selector failed for {url}")
5. Χρησιμοποιήστε curl_cffi με browser impersonation. Αυτό αντιμετωπίζει το TLS fingerprinting του Akamai χωρίς headless browser.
Η AI-powered εναλλακτική: χωρίς συντήρηση selectors
Αν έχετε κουραστεί να διορθώνετε selectors κάθε λίγους μήνες, υπάρχει μια θεμελιωδώς διαφορετική προσέγγιση. Εργαλεία όπως το Thunderbit χρησιμοποιούν AI για να διαβάζουν τη σελίδα εκ νέου κάθε φορά και να παράγουν αυτόματα τη λογική εξαγωγής. Μια μελέτη του McGill University δοκίμασε AI απέναντι σε selector-based scrapers σε 3.000 σελίδες και βρήκε ότι οι AI μέθοδοι κράτησαν ακρίβεια 98,4% ακόμα και μετά από αλλαγές στο layout, ενώ industry benchmarks μιλούν για μείωση 60–80% στη συντήρηση των scrapers.
| Προσέγγιση | Σπάει όταν το eBay αλλάζει το HTML; | Προσπάθεια συντήρησης |
|---|---|---|
| Hardcoded CSS selectors | Ναι, κάθε τρίμηνο | Υψηλή — συνεχείς διορθώσεις |
| Εξαγωγή hidden JSON / JSON-LD | Σπάνια | Χαμηλή |
| AI-based scraping (Thunderbit) | Όχι — η AI ξαναβρίσκει selectors σε κάθε run | Καμία |
Κάντε scrape δεδομένα eBay με AI Get Started Free
Θα καλύψω το workflow του Thunderbit αναλυτικά παρακάτω. Προς το παρόν, το συμπέρασμα είναι αυτό: αν χτίζετε έναν scraper που θέλετε να τρέχει για μήνες, επενδύστε σε extraction με προτεραιότητα το JSON και σε fallback selectors. Αν δεν θέλετε καθόλου να συντηρείτε selectors, η AI προσέγγιση αξίζει να τη δείτε.
Πώς να αυτοματοποιήσετε επαναλαμβανόμενα eBay scrapes για παρακολούθηση τιμών
Ένα one-time scrape είναι χρήσιμο. Όμως η παρακολούθηση τιμών, η παρακολούθηση αποθέματος και η ανάλυση ανταγωνισμού απαιτούν επαναλαμβανόμενη συλλογή δεδομένων. Κάθε άρθρο για ανταγωνιστές αναφέρει το price monitoring ως use case, αλλά σχεδόν κανένα δεν δείχνει πώς να το αυτοματοποιήσετε στην πράξη.
Επιλογή 1: Cron Jobs (Linux/macOS) ή Task Scheduler (Windows)
Η απλούστερη προσέγγιση. Τυλίξτε το Python script σας σε ένα cron job. Χρησιμοποιείτε πάντα το απόλυτο path προς το Python του virtualenv σας — το cron τρέχει με ελάχιστο environment:
crontab -e
# Κάθε μέρα στις 08:15
15 8 * * * /Users/me/ebay/venv/bin/python /Users/me/ebay/scrape_ebay.py >> /Users/me/ebay/scrape.log 2>&1
Στα Windows, χρησιμοποιήστε PowerShell:
$A = New-ScheduledTaskAction -Execute "C:\Users\me\ebay\venv\Scripts\python.exe" -Argument "C:\Users\me\ebay\scrape_ebay.py"
$T = New-ScheduledTaskTrigger -Daily -At 8:15am
Register-ScheduledTask -TaskName "eBayScraper" -Action $A -Trigger $T
Αυτό απαιτεί μηχάνημα που μένει πάντα ανοιχτό, και εσείς διαχειρίζεστε μόνοι σας proxies και anti-bot μέτρα.
Επιλογή 2: Cloud Functions (Serverless)
Το AWS Lambda ή το Google Cloud Functions σάς επιτρέπουν να τρέχετε scrapers χωρίς dedicated server. Μεγαλύτερη προσπάθεια αρχικής ρύθμισης — πρέπει να πακετάρετε dependencies, να χειριστείτε timeouts (το Lambda σταματά στα 15 λεπτά) και πάλι να διαχειριστείτε proxies. Αλλά χωρίς συντήρηση server.
Επιλογή 3: No-Code scheduling με Thunderbit
Η λειτουργία Scheduled Scraper του Thunderbit σάς επιτρέπει να περιγράψετε το χρονικό διάστημα με απλή γλώσσα (π.χ. "κάθε μέρα στις 8 το πρωί"), να δώσετε τα eBay URLs και να πατήσετε Schedule. Τρέχει στο cloud με ενσωματωμένο anti-bot handling.
| Προσέγγιση | Προσπάθεια ρύθμισης | Χρειάζεται server; | Χειρίζεται anti-bot; |
|---|---|---|---|
| Cron + Python script | Μεσαία | Ναι (μηχάνημα πάντα ανοιχτό) | Εσείς διαχειρίζεστε proxies |
| Cloud function (Lambda) | Υψηλή | Όχι (serverless) | Εσείς διαχειρίζεστε proxies |
| Thunderbit Scheduled Scraper | Χαμηλή (το περιγράφετε με λόγια) | Όχι (cloud-based) | Ενσωματωμένο |
Για αποθήκευση δεδομένων από επαναλαμβανόμενα scrapes, η σωστή λύση για price history είναι μια τοπική SQLite database. Χρησιμοποιήστε ON CONFLICT ... DO UPDATE (όχι INSERT OR REPLACE, που σπάει foreign keys και μηδενίζει columns):
CREATE TABLE IF NOT EXISTS listings (
item_id TEXT PRIMARY KEY,
title TEXT NOT NULL,
price REAL,
last_price REAL,
first_seen_at TEXT DEFAULT (datetime('now')),
last_seen_at TEXT DEFAULT (datetime('now'))
);
CREATE TABLE IF NOT EXISTS price_history (
item_id TEXT NOT NULL,
observed_at TEXT NOT NULL DEFAULT (datetime('now')),
price REAL NOT NULL,
PRIMARY KEY (item_id, observed_at)
);
Δοκιμάστε το Thunderbit Scheduled Scraper
Δεν θέλετε να γράψετε κώδικα; Πώς να κάνετε scrape το eBay σε 2 λεπτά με το Thunderbit
Έχω αφιερώσει 2.000 λέξεις σε Python code. Τώρα θέλω να είμαι ειλικρινής για το πότε δεν το χρειάζεστε.
Αν είστε business user που κάνει one-off market research, μεταπωλητής που ελέγχει συγκρίσιμες τιμές ή ομάδα ecommerce που χρειάζεται δεδομένα σήμερα χωρίς dev sprint, το Python είναι υπερβολή. Η εγκατάσταση, η συντήρηση selectors, η διαχείριση proxies — είναι πολλή επιβάρυνση για το «θέλω απλώς αυτές τις 200 καταχωρίσεις σε ένα spreadsheet».
Πώς κάνει scrape το Thunderbit στο eBay (βήμα προς βήμα)
- Εγκαταστήστε το Thunderbit Chrome Extension — δεν απαιτείται πιστωτική κάρτα.
- Μεταβείτε σε οποιαδήποτε σελίδα αποτελεσμάτων αναζήτησης ή προϊόντος του eBay στο Chrome.
- Πατήστε "AI Suggest Fields" στο sidebar του Thunderbit. Η AI διαβάζει τη σελίδα και προτείνει στήλες: Title, Price, Condition, Shipping, Seller, Rating.
- Πατήστε "Scrape." Το extension περνάει από το pagination και γεμίζει τον πίνακα δεδομένων. Ειδικά για το eBay, το Thunderbit έχει έτοιμα instant scraper templates που λειτουργούν με ένα κλικ.
- Εξάγετε σε Google Sheets, Airtable, Notion, CSV, JSON ή Excel — δωρεάν.
Όλη η διαδικασία διαρκεί λιγότερο από 2 λεπτά.
Το μέτρησα.
Εμπλουτισμός υποσελίδων: πάρτε δεδομένα detail page χωρίς επιπλέον κώδικα
Αφού κάνετε scrape μια σελίδα αποτελεσμάτων αναζήτησης, το Thunderbit μπορεί να επισκεφθεί τη σελίδα λεπτομερειών κάθε listing και να προσθέσει επιπλέον πεδία — πλήρεις προδιαγραφές, στοιχεία πωλητή, περιγραφή, όλες τις εικόνες. Αυτό αντικαθιστά τις 20+ γραμμές Python code που γράψαμε νωρίτερα για scraping υποσελίδων με ένα μόνο κλικ.
Πότε εξακολουθεί να αξίζει η Python
Η Python κερδίζει όταν χρειάζεστε:
- Scraping μεγάλης κλίμακας (δεκάδες χιλιάδες σελίδες ανά run)
- Πολύ εξατομικευμένη λογική parsing ή μετασχηματισμό δεδομένων
- Ενσωμάτωση σε υπάρχοντα data pipelines (Airflow, dbt, Kafka)
- Λεπτομερή έλεγχο TLS/session για προχωρημένη anti-bot δουλειά
- Unit economics — σε εκατομμύρια rows, ένα συντηρούμενο stack συμφέρει περισσότερο από ένα credit-based SaaS
Για τα περισσότερα one-off ή μεσαίας κλίμακας projects, το Thunderbit είναι πιο γρήγορο και πιο απλό. Για production pipelines σε μεγάλη κλίμακα, η Python δίνει πλήρη έλεγχο.
Συμβουλές για να αποφύγετε το μπλοκάρισμα όταν κάνετε scrape το eBay με Python
Το Akamai layer του eBay είναι πραγματικό. Αυτό που όντως δουλεύει στην πράξη:
- Χρησιμοποιήστε
curl_cffiμεimpersonate="chrome124"— είναι η μεγαλύτερη μεμονωμένη βελτίωση σε σχέση με τα απλάrequests - Εναλλάξτε User-Agent strings από λίστα με σύγχρονες εκδόσεις browser (Chrome 143, Firefox 124, Safari 26)
- Προσθέστε τυχαίες καθυστερήσεις 3–8 δευτερολέπτων ανάμεσα στα requests — τα σταθερά διαστήματα αποτελούν fingerprint
- Χρησιμοποιήστε residential ή rotating proxies για οτιδήποτε ξεπερνά λίγες δεκάδες σελίδες. Τα datacenter IPs (AWS, GCP, DigitalOcean) εντοπίζονται γρήγορα από το Akamai.
- Σεβαστείτε το
robots.txt— τα περισσότερα filtered browse URLs είναι ρητά Disallowed· οι item-detail pages (/itm/<id>) όχι - Διαχειριστείτε τα CAPTCHAs με ευγενικό τρόπο — εντοπίστε τα και ξαναδοκιμάστε με άλλο IP ή χρησιμοποιήστε υπηρεσία επίλυσης CAPTCHAs
- Μην βομβαρδίζετε τον server. Το προηγούμενο της eBay v. Bidder's Edge δείχνει ότι το trespass to chattels εφαρμόζεται όταν το scraping επιβαρύνει πραγματικά τους servers. Αν μείνετε στο 1 request/δευτ. ανά IP, είστε πολύ κάτω από αυτό το όριο.
Για εμπορική χρήση υψηλού όγκου, σκεφτείτε να χρησιμοποιήσετε το Browse API για ενεργές καταχωρίσεις και targeted scraping μόνο για sold comps και δεδομένα που δεν εκθέτει το API. Αυτή η υβριδική προσέγγιση είναι καθαρότερη τόσο τεχνικά όσο και νομικά.
Είναι νόμιμο να κάνετε scrape το eBay με Python;
Δεν είμαι δικηγόρος και αυτό το blog post δεν αποτελεί νομική συμβουλή. Οπότε θα το κρατήσω σύντομο.
Το νομικό τοπίο έχει μετακινηθεί υπέρ του scraping δημοσίως διαθέσιμων δεδομένων. Τα βασικά precedents:
- hiQ v. LinkedIn (9th Cir., 2022): το scraping δημοσίως προσβάσιμων δεδομένων δεν παραβιάζει το CFAA
- Van Buren v. United States (SCOTUS, 2021): περιόρισε τη διάταξη του CFAA περί "exceeds authorized access"
- Meta v. Bright Data (N.D. Cal., 2024): το scraping σε κατάσταση logged-out δεν παραβιάζει τους όρους χρήσης της πλατφόρμας επειδή ο scraper δεν είναι "user"
Παρόλα αυτά, η ενημέρωση του eBay User Agreement τον Φεβρουάριο του 2026 απαγορεύει ρητά «buy-for-me agents, LLM-driven bots ή οποιοδήποτε end-to-end flow που επιχειρεί να τοποθετήσει παραγγελίες χωρίς ανθρώπινο έλεγχο». Η γραμμή είναι σαφής: το read-only scraping δημόσιων σελίδων είναι σε σταθερή βάση· η αυτοματοποίηση checkout όχι.
Καλές πρακτικές: κάντε scrape μόνο δημόσια ορατά δεδομένα. Μην δημιουργείτε ψεύτικους λογαριασμούς και μην παρακάμπτετε login walls. Μην μεταπωλείτε μαζικά εικόνες καταχωρίσεων που προστατεύονται από πνευματικά δικαιώματα. Και ζητήστε νομική συμβουλή για projects εμπορικής κλίμακας.
Συμπέρασμα και βασικά σημεία
Η Python είναι ο πιο ευέλικτος τρόπος για να κάνετε scrape το eBay, αλλά απαιτεί συνεχή συντήρηση καθώς αλλάζει το HTML του site. Το πλαίσιο απόφασης είναι το εξής:
- Χρησιμοποιήστε το eBay Browse API για σταθερά, μεσαίου όγκου, δομημένα queries σε ενεργές καταχωρίσεις
- Χρησιμοποιήστε Python scraping για sold listings, reviews, variant data και οτιδήποτε δεν εκθέτει το API
- Χρησιμοποιήστε το Thunderbit αν θέλετε δεδομένα eBay χωρίς να γράφετε ή να συντηρείτε κώδικα
Ο κώδικας σε αυτόν τον οδηγό δίνει προτεραιότητα στην ανθεκτικότητα: πρώτα extraction από JSON-LD, μετά cascading CSS fallbacks, και parsing κρυφού JSON για variants. Αυτή η πολυεπίπεδη προσέγγιση σημαίνει ότι ο scraper σας δεν θα πεθάνει την επόμενη φορά που η frontend ομάδα του eBay βγάλει redesign.
Αν θέλετε να δοκιμάσετε τη no-code διαδρομή, το δωρεάν επίπεδο του Thunderbit σάς επιτρέπει να το δοκιμάσετε άμεσα σε σελίδες eBay. Και αν θέλετε να δείτε πώς λειτουργεί το eBay scraper template, είναι ένα κλικ μακριά.
Για περισσότερα σχετικά με εργαλεία web scraping, δείτε τους οδηγούς μας για τα καλύτερα automated web scraping tools, πώς να κάνετε scrape δεδομένα από ιστοσελίδες σε Excel και τα καλύτερα Python web scraping tools. Μπορείτε επίσης να δείτε tutorials στο Thunderbit YouTube Channel.
Δοκιμάστε το Thunderbit για eBay scraping Get Started Free
Συχνές ερωτήσεις
1. Μπορώ να κάνω free scrape το eBay με Python;
Ναι. Όλες οι βιβλιοθήκες (Requests, BeautifulSoup, curl_cffi, pandas) είναι δωρεάν και open source. Τα κόστη εμφανίζονται σε μεγάλη κλίμακα — τα residential proxies για high-volume scraping κοστίζουν συνήθως 50–500$/μήνα, ανάλογα με το bandwidth. Για μικρά projects (λίγες εκατοντάδες σελίδες), μπορείτε να κάνετε scrape από το home IP σας με προσεκτικό rate limiting.
2. Πώς κάνω scrape τα sold items και completed listings του eBay με Python;
Προσθέστε LH_Complete=1&LH_Sold=1 στα URL parameters της αναζήτησής σας. Πρέπει να βάλετε και τα δύο — το LH_Sold=1 μόνο του σε ορισμένες κατηγορίες επιστρέφει σιωπηλά ενεργές καταχωρίσεις. Φιλτράρετε τα αποτελέσματα ελέγχοντας την CSS class .POSITIVE στο στοιχείο τιμής, που δείχνει πραγματική πώληση και όχι ληγμένη καταχώριση που δεν πουλήθηκε.
3. Μπλοκάρει το eBay το web scraping;
Το eBay χρησιμοποιεί Akamai Bot Manager, που εντοπίζει scrapers κυρίως μέσω TLS fingerprinting και behavioral analysis. Τα απλά requests συχνά επιστρέφουν 403. Η χρήση του curl_cffi με browser impersonation, rotating User-Agents και τυχαίες καθυστερήσεις 3–8 δευτερολέπτων ανάμεσα στα requests καλύπτει τα περισσότερα blocks. Τα residential proxies βοηθούν σε μεγάλη κλίμακα.
4. Να χρησιμοποιήσω το eBay API ή web scraping;
Χρησιμοποιήστε το Browse API για σταθερά queries μεσαίου όγκου σε ενεργές καταχωρίσεις (έως 5.000 calls/ημέρα). Χρησιμοποιήστε scraping όταν χρειάζεστε ιστορικό sold prices, πλήρη variant/MSKU data, reviews ή οποιοδήποτε πεδίο δεν εκθέτει το API. Το Marketplace Insights API θεωρητικά παρέχει sold data, αλλά η πρόσβαση είναι περιορισμένη και συχνά απορρίπτεται.
5. Ποιος είναι ο πιο εύκολος τρόπος να κάνω scrape το eBay χωρίς κώδικα;
Το Thunderbit Chrome extension χρησιμοποιεί AI για να διαβάζει σελίδες eBay, να προτείνει στήλες δεδομένων και να εξάγει listings με ένα κλικ. Χειρίζεται pagination, enrichment υποσελίδων και export σε Google Sheets, Excel, Airtable ή Notion. Τα έτοιμα eBay scraper templates το κάνουν ακόμη πιο γρήγορο για συνηθισμένες περιπτώσεις χρήσης.
Μάθετε περισσότερα
- Master Python Web Scraper: Οδηγός βήμα προς βήμα με παράδειγμα
- Python Web Scraping Tutorial: Ανάκτηση δεδομένων από ιστοσελίδα
- Πώς να χρησιμοποιήσετε το BeautifulSoup: Python tutorial για web scraping
- Python Web Scraping Tutorial: Πώς να κάνετε scrape μια ιστοσελίδα
- Πώς να γράψετε ένα web scraper με Python: από την αρχή μέχρι το τέλος




