
Το GitHub δείχνει πλέον πάνω από . Ακούγεται σαν μπουφές. Η παγίδα; Μόνο περίπου το 28% δείχνει κάποια δραστηριότητα συντήρησης τους τελευταίους δώδεκα μήνες. Τις τελευταίες εβδομάδες έψαξα αυτά τα repos, δοκίμασα endpoints, διάβασα ουρές issues και διασταύρωσα τις ενημερώσεις πολιτικής του ίδιου του Reddit. Στόχος μου: να σε γλιτώσω από το να κάνεις clone ένα repo, να παλέψεις με το OAuth και να ανακαλύψεις, καταμεσής της νύχτας, ότι όλο το σύστημα είχε χαλάσει σιωπηλά το 2024. Το τοπίο του Reddit scraper GitHub το 2026 είναι ένα νεκροταφείο καλών προθέσεων, με λίγα πραγματικά χρήσιμα εργαλεία διάσπαρτα εδώ κι εκεί. Αυτός ο οδηγός καλύπτει τι εξακολουθεί να δουλεύει, τι χάλασε, πότε να προσπεράσεις τελείως τον κώδικα και πώς να μείνεις στη σωστή πλευρά της ολοένα πιο αυστηρής επιβολής κανόνων του Reddit. Αν ψάχνεις για shortcut, το είναι η no-code επιλογή που φτιάξαμε ακριβώς για τέτοιου είδους πρόβλημα — αλλά θα είμαι ειλικρινής και για το πού οι λύσεις με κώδικα εξακολουθούν να βγάζουν περισσότερο νόημα.
Τι είναι ένα Reddit Scraper GitHub Repo (και γιατί τόσα πολλά είναι χαλασμένα)
Ένα repo τύπου "reddit scraper github" είναι συνήθως ένα open-source project σε Python (ή μερικές φορές JavaScript) που αυτοματοποιεί τη λήψη posts, comments, δεδομένων χρηστών ή media από το Reddit. Συνήθως χωρίζονται σε τέσσερις κατηγορίες:
- API wrappers (όπως το PRAW): χρησιμοποιούν το επίσημο API του Reddit, απαιτούν OAuth και ακολουθούν τους κανόνες του Reddit.
- Εργαλεία βασισμένα σε Pushshift/PSAW: χρησιμοποιούν το τεράστιο αρχείο του Pushshift για ιστορικά δεδομένα Reddit.
- Scrapers για public
.jsonendpoints: προσθέτουν.jsonστα URLs του Reddit ή χτυπούν δημόσια endpoints χωρίς αυθεντικοποίηση. - Browser-based scrapers: χρησιμοποιούν Playwright, Selenium ή browser extensions για να φορτώσουν σελίδες του Reddit και να εξαγάγουν το περιεχόμενο που αποδίδεται.
Γιατί χάλασαν τόσα πολλά; Τρεις λόγοι.
- Η αναδιάρθρωση της τιμολόγησης του API του Reddit στα μέσα του 2023. Τα δωρεάν όρια του API έπεσαν στις . Η υψηλότερη εμπορική χρήση κοστίζει πλέον 0,24 δολάρια ανά 1.000 API calls. Πολλά repos χτίστηκαν για έναν κόσμο όπου η πρόσβαση στο API ήταν ουσιαστικά απεριόριστη — και εκείνος ο κόσμος έχει φύγει.
- Η δημόσια πρόσβαση στο Pushshift ανακλήθηκε. Το Pushshift ήταν η ραχοκοκαλιά για ιστορική έρευνα στο Reddit. Μόλις το Reddit το περιόρισε, μεγάλο μέρος των repos για "historical scraping" έχασε την κύρια πηγή δεδομένων του. Κάποια README εξακολουθούν να δείχνουν αυτά τα εργαλεία ως ζωντανά, αλλά η εξάρτηση από κάτω έχει χαθεί για τον συνηθισμένο χρήστη.
- Το Reddit σκλήρυνε τόσο την πολιτική όσο και την επιβολή της. Η ενημέρωση του robots.txt το 2024, η του 2025 και η του Μαρτίου 2026 δείχνουν ξεκάθαρα ότι το Reddit δεν αντιμετωπίζει πλέον το μαζικό scraping ως ακίνδυνο παρασκήνιο. Έχει μάλιστα .
Το αποτέλεσμα: ψάχνεις "reddit scraper github" και βρίσκεις εκατοντάδες αποτελέσματα. Οι ημερομηνίες τελευταίου commit και ο αριθμός ανοιχτών issues λένε μια πολύ διαφορετική ιστορία.
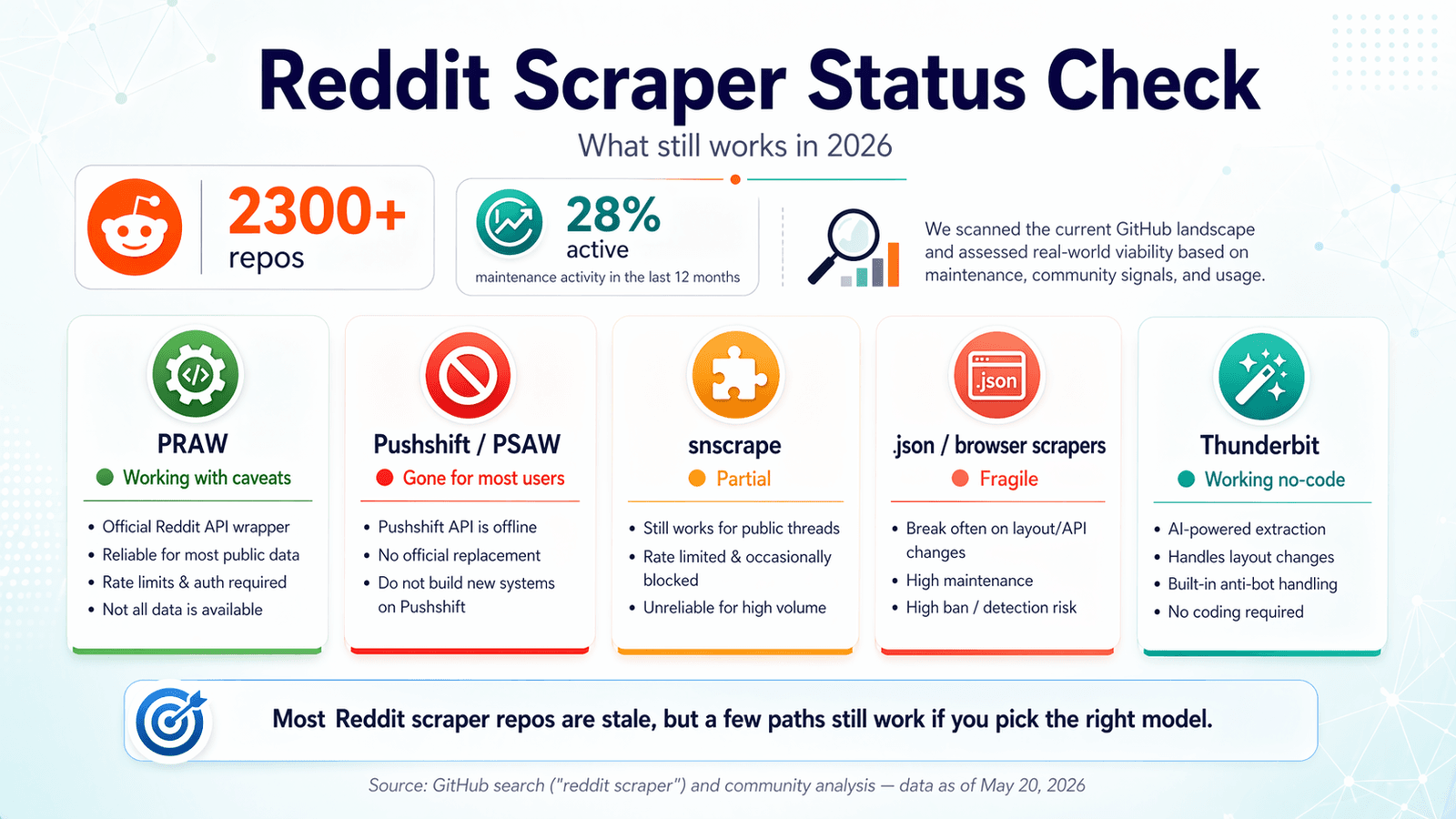
Έλεγχος κατάστασης Reddit Scraper GitHub για το 2026: Τι εξακολουθεί να δουλεύει
Τα περισσότερα ανταγωνιστικά άρθρα γράφτηκαν το 2023 ή το 2024 και δεν ενημερώθηκαν ποτέ. Οι χρήστες στα forums συνεχίζουν να βρίσκουν σφάλματα σε repos που δούλευαν πριν από έναν χρόνο — η έκκληση ενός χρήστη, "Keep running into Reddit API limitation error :\ Any ideas how I can get past this?" είναι ουσιαστικά η εμπειρία Reddit scraper το 2026 σε μία πρόταση.
Έκανα έναν έλεγχο φρεσκάδας, επαληθευμένο μέχρι τον Απρίλιο του 2026. Να τι βρήκα.
PRAW: Το επίσημο Python wrapper
Κατάσταση: ✅ Εξακολουθεί να δουλεύει, με επιφυλάξεις.
Το (Python Reddit API Wrapper) παραμένει η πιο αξιόπιστη open-source βάση για scraping στο Reddit. Συντηρείται ενεργά — 4.099 stars, τελευταίο push στις 20 Απριλίου 2026, μόλις 6 ανοιχτά issues και το (κυκλοφόρησε τον Οκτώβριο του 2024).
Δυνατά σημεία: Επίσημο, καλά τεκμηριωμένο, αφαιρεί τη μεγαλύτερη πολυπλοκότητα από το API του Reddit.
Περιορισμοί το 2026:
- Αυστηρότερες απαιτήσεις OAuth. Χρειάζεσαι εγγεγραμμένο Reddit app με εγκεκριμένη περιγραφή χρήσης.
- Χαμηλότερα rate limits από το 2024 (100 queries/λεπτό με OAuth, 10 χωρίς).
- Το σκληρό όριο περίπου 1.000 posts στη λίστα παραμένει. Συζητήσεις στην κοινότητα στο r/redditdev και στο Stack Overflow επιβεβαιώνουν: ανά endpoint λίστας.
Το PRAW είναι η ασφαλέστερη επιλογή αν μπορείς να μείνεις μέσα στο πλαίσιο του API.
Απλώς δεν είναι πια ένα ελεύθερο bulk scraper.
Αν θέλεις έναν πρακτικό οδηγό για τη διαδρομή του επίσημου API, αυτό το tutorial ταιριάζει καλά σε αυτή την ενότητα:
Pushshift / PSAW: Το αρχείο που σκοτείνιασε
Κατάσταση: ❌ Η δημόσια πρόσβαση έχει χαθεί.
Το ήταν το Python wrapper που όλοι χρησιμοποιούσαν για το Pushshift, το οποίο παλιότερα ήταν ο πιο εύκολος δρόμος για ιστορικά δεδομένα Reddit. Το 2026, το repo είναι archived, το README λέει κυριολεκτικά "THIS REPOSITORY IS STALE," και πρόσφατα ανοιχτά issues περιλαμβάνουν διαμάντια όπως "Pushshift.io UNABLE to connect" και "The code not working. Possibly due to pushshift api."
Ακαδημαϊκή πρόσβαση ίσως εξακολουθεί να υπάρχει μέσω συγκεκριμένων καναλιών, αλλά για όποιον ψάχνει σήμερα "reddit scraper github", το Pushshift/PSAW δεν είναι βιώσιμη επιλογή. Αν χρειάζεσαι βαθιά ιστορικά δεδομένα Reddit, θα πρέπει να δεις εγκεκριμένη ακαδημαϊκή πρόσβαση σε δεδομένα ή αδειοδοτημένες διαδρομές.
snscrape (Reddit Module): Μερικό και αναξιόπιστο
Κατάσταση: ⚠️ Μερικό — διαλείποντα σφάλματα, σε μεγάλο βαθμό χωρίς συντήρηση.
Το έχει 5.337 stars, αλλά το τελευταίο push ήταν στις 15 Νοεμβρίου 2023. Το README εξακολουθεί να λέει ότι το Reddit scraping υποστηρίζεται "via Pushshift." Ανοιχτά issues σχετικά με το Reddit περιλαμβάνουν "Error reddit scraping" και "Reddit scraper returns no submissions before 2022-11-03," χωρίς πρόσφατη ουσιαστική δραστηριότητα επιδιόρθωσης.
Μπορεί να δουλέψει για μικρά, μεμονωμένα pulls σε ορισμένα περιβάλλοντα, αλλά δεν είναι αξιόπιστο για παραγωγή ή επαναλαμβανόμενα scrapes. Αντιμετώπισέ το ως legacy.
Playwright και scrapers για .json endpoints: Το workaround που δουλεύει (μερικές φορές)
Κατάσταση: ✅ Δουλεύει, αλλά είναι εύθραυστο.
Η ιδέα εδώ είναι απλή: χρησιμοποίησε έναν headless browser (Playwright, Puppeteer) για να φορτώσεις σελίδες του Reddit και να κάνεις scrape το rendered περιεχόμενο, ή πρόσθεσε .json στα URLs του Reddit για να πάρεις δομημένα δεδομένα χωρίς το επίσημο API.
Δυνατά σημεία: Δεν χρειάζεται API key, μπορεί να παρακάμψει το όριο των 1.000 posts, δίνει πρόσβαση στο rendered περιεχόμενο.
Αδύνατα σημεία: Σπάει όταν το Reddit αλλάζει το front-end layout ή τη δομή JSON, μπορεί να ενεργοποιήσει anti-bot μηχανισμούς και απαιτεί πιο τεχνικό setup. Στη δική μου δοκιμή αυτόν τον μήνα, τα άμεσα requests προς δημόσια Reddit .json endpoints επέστρεψαν απαντήσεις 403. Αυτό δεν σημαίνει ότι κάθε περιβάλλον θα μπλοκαριστεί, αλλά σημαίνει ότι το .json shortcut δεν είναι πια κάτι που πρέπει να θεωρείς δεδομένο ότι θα "δουλεύει απλώς".
Repos όπως το είναι αναζωογονητικά ειλικρινή γι’ αυτό: το README προειδοποιεί τους χρήστες να "Use with rotating proxies, or Reddit might gift you with an IP ban." Αυτή είναι ουσιαστικά η ιστορία του Απριλίου 2026 σε μία πρόταση.
Αν αξιολογείς τη διαδρομή του browser-automation workaround, αυτό το tutorial για Playwright είναι πολύ καλό συμπλήρωμα στην παρακάτω ενότητα:
Thunderbit: Browser scraping με AI (χωρίς κώδικα, χωρίς API key)
Κατάσταση: ✅ Λειτουργεί — προσαρμόζεται αυτόματα στις αλλαγές της σελίδας.
Το ακολουθεί εντελώς διαφορετική προσέγγιση. Είναι ένα που χρησιμοποιεί AI για να διαβάζει σελίδες του Reddit, να προτείνει πεδία δεδομένων (τίτλο post, συγγραφέα, upvotes, timestamp, URL κ.λπ.) και να εξάγει δομημένα δεδομένα σε δύο κλικ. Χωρίς ρύθμιση OAuth, χωρίς εγγραφή API key, χωρίς περιβάλλον Python, χωρίς διαχείριση dependencies. Το AI διαβάζει τη σελίδα ξανά κάθε φορά, οπότε όταν το Reddit αλλάζει το layout του, το Thunderbit προσαρμόζεται αυτόματα αντί να χαλάει σιωπηλά.
Δωρεάν εξαγωγή σε CSV, Google Sheets, Airtable ή Notion. Υποστηρίζει pagination και scraping υποσελίδων (π.χ. scraping μιας λίστας subreddit και μετά επίσκεψη σε κάθε post για λήψη comments). Για το κοινό που θέλει δεδομένα Reddit χωρίς να συντηρεί ένα GitHub repo, αυτή είναι η διαδρομή με τη μικρότερη αντίσταση.
(Πλήρης διαφάνεια: φτιάξαμε το Thunderbit, άρα έχω μια προκατάληψη — αλλά θα είμαι ξεκάθαρος αργότερα σε αυτό το άρθρο για το πού οι λύσεις με κώδικα εξακολουθούν να βγάζουν περισσότερο νόημα.)
Συνοπτικός πίνακας κατάστασης, δίπλα-δίπλα
| Εργαλείο / Κατηγορία | Δουλεύει ακόμη (Απρίλιος 2026); | Απαιτεί API Key; | Σημειώσεις |
|---|---|---|---|
| PRAW | ✅ Ναι, με επιφυλάξεις | Ναι (OAuth) | Η καλύτερα συντηρημένη open-source βάση. Περιορίζεται από rate limits και το όριο 1.000 posts. |
| Pushshift / PSAW | ❌ Όχι (για τους περισσότερους χρήστες) | N/A | Η δημόσια πρόσβαση έχει χαθεί. Το repo είναι archived. |
| snscrape (μονάδα Reddit) | ⚠️ Μερικό / αναξιόπιστο | Όχι | Ακόμη τεκμηριώνει το Reddit "via Pushshift." Η συντήρηση έχει παγώσει από το 2023. |
| Scrapers για .json / public endpoints | ⚠️ Μερικό | Όχι | Μπορεί να δουλέψουν, αλλά τα direct requests μπλοκάρονται όλο και πιο συχνά. Εξαρτώνται από proxies. |
| Playwright / browser scrapers | ✅ Ναι, αλλά εύθραυστα | Συνήθως όχι | Το πιο βιώσιμο DIY workaround χωρίς API. Οι αλλαγές στη σελίδα και τα anti-bot checks εξακολουθούν να μετρούν. |
| Thunderbit | ✅ Ναι | Όχι | Ροή εργασίας AI/browser. Χωρίς OAuth, χωρίς selectors. Η καλύτερη επιλογή για μη προγραμματιστές. |
Rate limits, το όριο των 1.000 posts και τι πραγματικά βοηθά
Αυτό είναι το νούμερο 1 σημείο πόνου για όποιον χρησιμοποιεί ένα reddit scraper GitHub project. Τα threads στα forums είναι γεμάτα απογοήτευση: "tired of runs dying halfway through because of rate limits," "Why am I only getting around 1,000 items?" Οι δύο βασικοί περιορισμοί είναι τα rate limits του API του Reddit (αιτήματα ανά λεπτό) και το όριο λίστας περίπου 1.000 posts (το API επιστρέφει μόνο τα πιο πρόσφατα ~1.000 posts ανά endpoint λίστας).
Καλύτερες πρακτικές διαχείρισης rate limits
Η τρέχουσα δημόσια βάση του Reddit: . Να πώς το χειρίζεσαι πρακτικά:
- Exponential backoff. Αν πάρεις απάντηση rate-limit, περίμενε και μετά ξαναδοκίμασε με μεγαλύτερη καθυστέρηση κάθε φορά (1s, 2s, 4s, 8s…). Μην πυροβολείς απλώς το endpoint ασταμάτητα.
- Διάβασε τα headers
X-Ratelimit-Remaining. Οι απαντήσεις του API του Reddit περιέχουν headers που σου λένε πόσα requests σου απομένουν και πότε μηδενίζεται το παράθυρο. Ρύθμισε τον ρυθμό σου με βάση αυτά τα values, όχι με εικασίες. - Εναλλασσόμενα user-agents. Κάποια repos το προτείνουν για αποφυγή εντοπισμού. Μπορεί να βοηθήσει, αλλά χρησιμοποίησέ το ηθικά — όχι για να παρακάμπτεις bans που έχεις κερδίσει.
- Κατέγραψε τα πάντα. Πρόσθεσε logging για API responses, rate-limit headers και errors. Όταν το scraper σου πεθαίνει στις 2 π.μ., τα logs είναι ο καλύτερός σου φίλος.
Πώς να ξεπεράσεις το όριο των 1.000 posts
Το πιο αξιόπιστο workaround για το όριο περίπου 1.000 στοιχείων του API είναι το chunking με χρονικά παράθυρα:
- Κάνε query σε ένα χρονικό τμήμα χρησιμοποιώντας τις παραμέτρους timestamp
beforeκαιafter. - Μετακίνησε το παράθυρο μπροστά (ή πίσω).
- Επανάλαβε.
- Κάνε deduplicate με βάση το post ID.
Δεν είναι κομψό, αλλά είναι πιο ειλικρινές από το να προσποιείσαι ότι ένα loop αιτημάτων μπορεί να τραβήξει οποιοδήποτε ιστορικό από ένα listing endpoint. Για πραγματικά ιστορικά δεδομένα, θα χρειαζόσουν εγκεκριμένη ακαδημαϊκή πρόσβαση ή αδειοδοτημένη διαδρομή — το Pushshift δεν είναι πλέον η προεπιλεγμένη απάντηση.
Το browser-based scraping (Playwright ή Thunderbit) παρακάμπτει εντελώς αυτό το όριο, επειδή κάνει scrape ό,τι αποδίδεται στη σελίδα και όχι ό,τι επιστρέφει το API. Η λειτουργία pagination του Thunderbit σού επιτρέπει να περνάς από σελίδα σε σελίδα και να συλλέγεις δεδομένα σε όσες σελίδες χρειάζεσαι.
Deduplication και ανάκτηση από σφάλματα
Τα περισσότερα reddit scraper GitHub repos δεν χειρίζονται dedup ή error recovery από προεπιλογή. Οι χρήστες παραπονιούνται ρητά ότι "none had deduping, rate limit avoidance after errors, checking if files are already downloaded." Να τι πρέπει να κάνεις:
- Deduplication: Κάνε hash το ID κάθε post (ή το ID + το περιεχόμενο). Αποθήκευσε τα hashes που έχεις ήδη δει σε μια απλή βάση SQLite ή ακόμη και σε ένα flat file. Πριν την εισαγωγή, έλεγξε αν το hash υπάρχει ήδη. Αυτό είναι ιδιαίτερα σημαντικό όταν κόβεις τα χρονικά παράθυρα σε κομμάτια ή ξανατρέχεις αποτυχημένες εργασίες.
- Ανάκτηση από σφάλματα: Αποθήκευσε την πρόοδο σε ένα checkpoint file μετά από κάθε Ν εγγραφές. Αν η εκτέλεση αποτύχει, ξαναξεκίνα από το τελευταίο checkpoint αντί από το μηδέν. Έτσι μια εργασία 3 ωρών που πεθαίνει στη 2η ώρα γίνεται συνέχιση 1 ώρας.
Πώς προσεγγίζουν διαφορετικές μέθοδοι αυτούς τους περιορισμούς

| Προσέγγιση | Χειρισμός rate limits | >1k posts; | Αυτόματο dedup; | Ανάκτηση από σφάλματα; |
|---|---|---|---|---|
| PRAW (raw) | Χειροκίνητα (sleep/retry) | ❌ (όριο API) | ❌ | ❌ |
| PRAW + chunking με χρονικά παράθυρα | Χειροκίνητα | ✅ (workaround) | ❌ | ❌ (εκτός αν το προσθέσεις) |
| Playwright .json scraping | N/A (χωρίς API) | ✅ | ❌ | ❌ |
| Thunderbit (browser scraping) | Ενσωματωμένο (AI pacing) | ✅ (pagination) | N/A (οπτικός έλεγχος) | Ενσωματωμένο |
Όταν ένα Reddit Scraper GitHub Repo δεν είναι η απάντηση: Η no-code διαδρομή
Τα περισσότερα άρθρα για reddit scraper GitHub υποθέτουν ότι ξέρεις Python. Όμως πολλοί από όσους ψάχνουν λύσεις για Reddit scraping είναι marketers, sales reps, ερευνητές ή ανεξάρτητοι founders που δεν γράφουν Python καθημερινά. Για αυτό το κοινό, ένα GitHub repo φέρνει κρυφό κόστος:
- Ρύθμιση OAuth credentials και ενός Reddit developer app
- Διαχείριση Python virtual environments και conflicts εξαρτήσεων
- Debugging αινιγματικών μηνυμάτων σφάλματος όταν αλλάζουν τα internals του PRAW
- Διαχείριση ανάκλησης API keys αν το Reddit αποφασίσει ότι η χρήση σου δεν έχει εγκριθεί
- Συντήρηση του script κάθε φορά που το Reddit αλλάζει κάτι
Δεν είναι υποθετικά αυτά. Το έχει 2.563 stars και 107 ανοιχτά issues. Πρόσφατες αναφορές περιλαμβάνουν "Struggling to install," "PRAW module error," και "Exception not allowing to even authenticate."
Χρησιμοποίησε GitHub repo αν...
- Χρειάζεσαι custom λογική scraping (π.χ. συγκεκριμένη διαδρομή μέσα σε comment tree, ενσωμάτωση με custom NLP pipeline).
- Θέλεις να το ενσωματώσεις σε υπάρχον Python data pipeline.
- Χρειάζεσαι scraping σε πολύ μεγάλη κλίμακα με custom storage (database, data warehouse).
- Νιώθεις άνετα να συντηρείς κώδικα και να αντιμετωπίζεις breaking changes.
Χρησιμοποίησε no-code εργαλείο αν...
- Χρειάζεσαι δεδομένα Reddit γρήγορα — μέσα σε λεπτά, όχι ώρες setup.
- Δεν θέλεις να διαχειρίζεσαι API keys, OAuth apps ή Python environments.
- Θέλεις να εξάγεις απευθείας σε spreadsheets, Notion ή Airtable για άμεση χρήση.
- Θέλεις το εργαλείο να προσαρμόζεται αυτόματα όταν αλλάζει το layout του Reddit.
Το Thunderbit ταιριάζει απόλυτα στη no-code λογική. Οι χρήστες μπορούν να σε 2 κλικ με AI-suggested fields, να εξάγουν δωρεάν σε CSV/Google Sheets/Airtable/Notion και να χειρίζονται pagination χωρίς να γράφουν κώδικα. Το browser-based scraping σημαίνει μηδενική ρύθμιση OAuth και μηδενική εγγραφή API key.
Γρήγορος οδηγός: Scraping Reddit με Thunderbit (βήμα προς βήμα)
- Εγκατέστησε το .
- Πήγαινε στη σελίδα του Reddit που θέλεις να κάνεις scrape (subreddit, αποτελέσματα αναζήτησης, προφίλ χρήστη).
- Κάνε κλικ στο "AI Suggest Fields." Το Thunderbit διαβάζει τη σελίδα και προτείνει στήλες — τίτλο post, συγγραφέα, upvotes, timestamp, URL κ.λπ.
- Ρύθμισε τα πεδία αν χρειάζεται, μετά κάνε κλικ στο "Scrape."
- Έλεγξε τον πίνακα δεδομένων. Προαιρετικά κάνε κλικ στο "Scrape Subpages" για να επισκεφθείς κάθε post και να τραβήξεις comments ή πρόσθετες λεπτομέρειες.
- Εξήγαγε στο προτιμώμενο σημείο: Google Sheets, Excel, Airtable, Notion, CSV ή JSON.
Δύο λεπτά. Μηδέν γραμμές κώδικα. Αν θέλεις να το δεις στην πράξη, ρίξε μια ματιά στο .
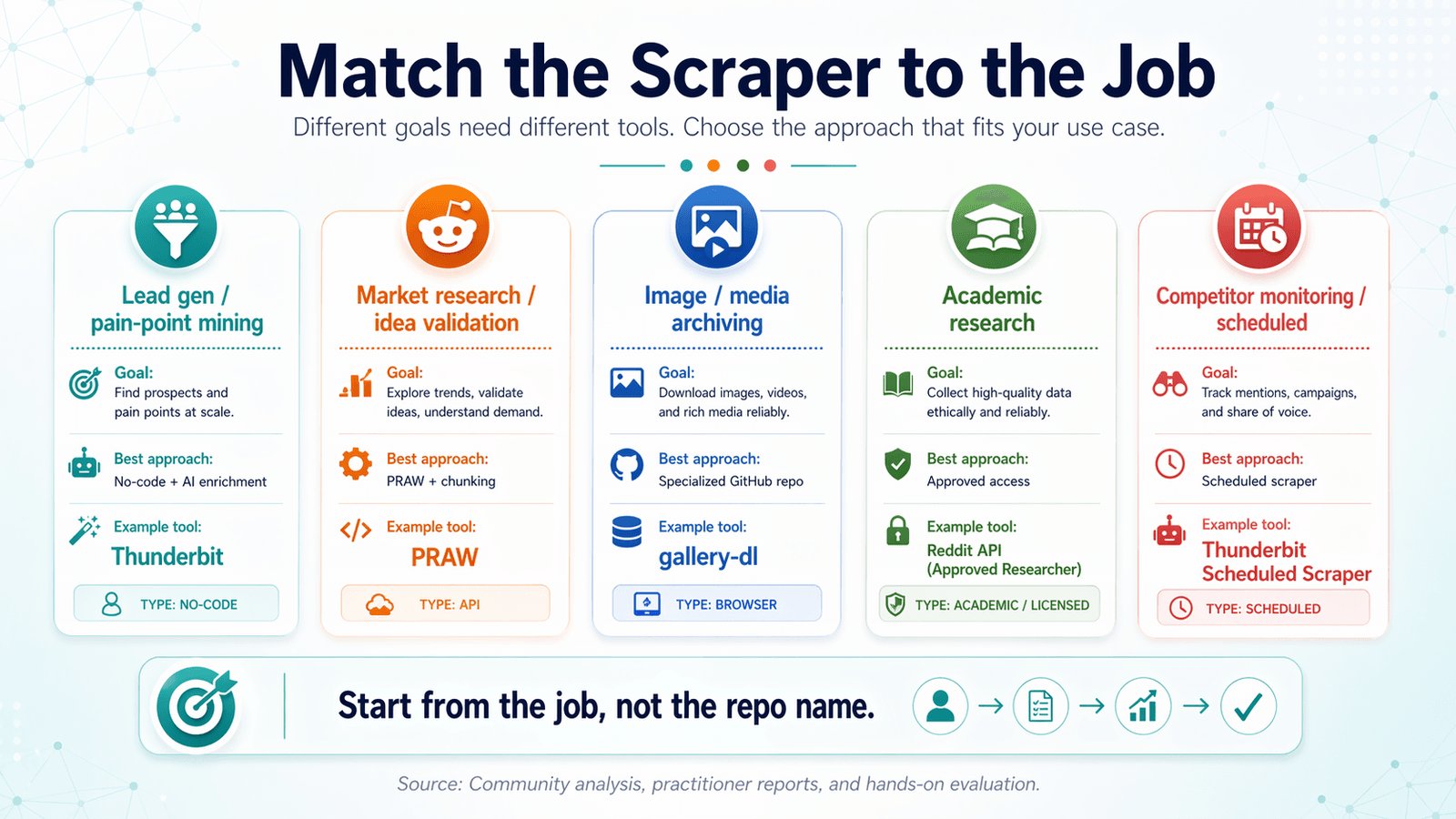
Ταιριάξε το Reddit Scraper στη δουλειά: Μήτρα απόφασης ανά use case
Τα περισσότερα άρθρα για reddit scraper GitHub οργανώνονται με βάση το εργαλείο. Αυτό είναι ανάποδα.
Ξεκίνα από τον στόχο σου και δούλεψε προς τα πίσω για να βρεις το σωστό εργαλείο.
Lead generation και ανάλυση pain points
Τι χρειάζεσαι: Posts + comments με φιλτράρισμα λέξεων-κλειδιών, AI tagging/labeling, εξαγωγή σε format έτοιμα για CRM.
Καλύτερη προσέγγιση: No-code scraper με AI enrichment.
Προτεινόμενο εργαλείο: (AI labeling + εξαγωγή σε Google Sheets/Airtable για εισαγωγή σε CRM).
Παράδειγμα ροής εργασίας: Κάνε scrape ένα subreddit για posts που αναφέρουν συγκεκριμένο pain point. Χρησιμοποίησε το Field AI Prompt του Thunderbit για να κατηγοριοποιήσεις συναίσθημα ή να επισημάνεις θέματα. Εξήγαγε στο Airtable ή στο Google Sheet της ομάδας πωλήσεων.
Έρευνα αγοράς και επικύρωση ιδεών
Τι χρειάζεσαι: Τίτλους posts υψηλού όγκου + scores, δεδομένα τάσεων σε επίπεδο subreddit.
Καλύτερη προσέγγιση: PRAW με chunking χρονικών παραθύρων για όγκο ή Thunderbit για γρήγορα pulls.
Παράδειγμα: Scraping του r/SaaS ή του r/startups για trending θέματα και μοτίβα upvote τις τελευταίες 90 ημέρες.
Αρχειοθέτηση εικόνων και media
Τι χρειάζεσαι: URLs media, deduplication, προγραμματισμένες εκτελέσεις.
Καλύτερη προσέγγιση: Εξειδικευμένο GitHub repo (π.χ. ) + cron job.
Σημείωση: Το dedup μετράει πολύ εδώ — η ίδια εικόνα που ανεβαίνει σε πολλά subreddits είναι συνηθισμένη.
Ακαδημαϊκή έρευνα και ιστορικά δεδομένα
Τι χρειάζεσαι: Ιστορικά δεδομένα, πλήρη comment trees, μεγάλα datasets.
Καλύτερη προσέγγιση: Εγκεκριμένη ακαδημαϊκή πρόσβαση ή αδειοδοτημένη διαδρομή δεδομένων. Το Pushshift δεν είναι πια γενικής χρήσης απάντηση.
Έλεγχος πραγματικότητας: Αυτό είναι το δυσκολότερο use case το 2026 λόγω των περιορισμών του Pushshift και των αυστηρότερων πολιτικών δεδομένων του Reddit.
Παρακολούθηση ανταγωνιστών και προγραμματισμένο scraping
Τι χρειάζεσαι: Επαναλαμβανόμενα scrapes σε καθορισμένα διαστήματα, ανίχνευση αλλαγών.
Καλύτερη προσέγγιση: Το του Thunderbit (περιγράφεις το χρονικό διάστημα σε απλά αγγλικά, βάζεις URLs, πατάς Schedule) ή cron + script για όσους δουλεύουν με κώδικα.
Πίνακας μήτρας απόφασης ανά use case
| Use Case | Τι χρειάζεσαι | Καλύτερη προσέγγιση | Παράδειγμα εργαλείου |
|---|---|---|---|
| Lead gen / pain-point mining | Posts + comments, φιλτράρισμα λέξεων-κλειδιών, AI tagging | No-code scraper + AI enrichment | Thunderbit |
| Έρευνα αγοράς / επικύρωση ιδεών | Τίτλοι posts υψηλού όγκου + scores, δεδομένα ανά subreddit | PRAW + chunking χρονικών παραθύρων ή Thunderbit | PRAW ή Thunderbit |
| Αρχειοθέτηση εικόνων/media | URLs media, dedup, προγραμματισμένες εκτελέσεις | Εξειδικευμένο GitHub repo + cron | bulk-downloader-for-reddit |
| Ακαδημαϊκή έρευνα | Ιστορικά δεδομένα, πλήρη comment trees | Εγκεκριμένη ακαδημαϊκή πρόσβαση ή Playwright | Pushshift academic API (αν είναι διαθέσιμο) |
| Παρακολούθηση ανταγωνιστών / προγραμματισμένο | Επαναλαμβανόμενα scrapes, ανίχνευση αλλαγών | Scheduled scraper | Thunderbit Scheduled Scraper ή cron + script |
Πώς να αξιολογήσεις οποιοδήποτε Reddit Scraper GitHub Repo πριν δεσμευτείς
Πριν κάνεις clone ένα repo και αρχίσεις το debugging, πέρασε αυτόν τον έλεγχο υγείας 5 λεπτών. Θα σου γλιτώσει ώρες.
Ο έλεγχος υγείας repo των 5 λεπτών
- Ημερομηνία τελευταίου commit. Αν έχει περάσει πάνω από 6 μήνες, προχώρα με προσοχή. Το API του Reddit αλλάζει συχνά.
- Αναλογία ανοιχτών προς κλειστών issues. Μεγάλος αριθμός άλυτων issues είναι κόκκινη σημαία. Δες αν πρόσφατα issues αναφέρουν auth failures, 403s ή διακοπές του Pushshift.
- Αρχείο LICENSE. Έλεγξε αν υπάρχει. Χωρίς άδεια = νομικά ασαφές (περισσότερα παρακάτω).
- Εξαρτήσεις. Είναι οι απαιτούμενες βιβλιοθήκες ενημερωμένες; Χρησιμοποιεί deprecated packages; Ένα
requirements.txtγεμάτο pinned εκδόσεις του 2022 είναι προειδοποιητικό σημάδι. - Ποιότητα README. Εξηγεί καθαρά το setup; Υπάρχουν παραδείγματα χρήσης; Κακή τεκμηρίωση = περισσότερος χρόνος debugging για σένα.
- Stars vs. forks vs. πρόσφατη δραστηριότητα. Πολλά stars αλλά χαμηλή πρόσφατη δραστηριότητα μπορεί να σημαίνουν ότι το project ήταν δημοφιλές, αλλά τώρα έχει εγκαταλειφθεί. Σύγκρινε τα stars με την ημερομηνία
pushed_at.
Ένα γρήγορο παράδειγμα: το έχει 364 stars — φαίνεται αξιόπιστο με μια πρώτη ματιά. Αλλά το repo είναι archived και το README λέει "THIS REPOSITORY IS STALE."
Τα stars από μόνα τους δεν λένε όλη την ιστορία.
Tips για να πάρεις το μέγιστο από τη ρύθμιση Reddit Scraper GitHub
Αν αποφασίσεις να πας από τη διαδρομή του κώδικα, να πώς θα γλιτώσεις πονοκέφαλους.
Χρησιμοποίησε πάντα virtual environment
Ένα virtual environment κρατά τις εξαρτήσεις του scraper απομονωμένες, ώστε να μη συγκρούονται με άλλα Python projects. Μία εντολή: python -m venv venv και μετά το ενεργοποιείς πριν εγκαταστήσεις οτιδήποτε. Είναι βασική υγιεινή, αλλά έχω δει αρκετά GitHub issues με τίτλο "module not found" για να ξέρω ότι αξίζει να το επαναλαμβάνω.
Φύλαξε με ασφάλεια τα credentials
Μην hardcodeάρεις ποτέ το Reddit API client ID ή το secret μέσα στο script. Χρησιμοποίησε environment variables ή ένα .env file και πρόσθεσε το .env στο .gitignore. Αν κατά λάθος ανεβάσεις credentials στο GitHub, κάνε τους αμέσως rotation — bots ψάχνουν για εκτεθειμένα API keys.
Κατέγραψε τα πάντα
Πρόσθεσε logging για API responses, rate-limit headers και errors. Όταν κάτι χαλάει, τα logs είναι η διαφορά ανάμεσα στο "ξέρω ακριβώς τι συνέβη" και στο "δεν έχω ιδέα γιατί σταμάτησε".
Προγραμμάτισε και αυτοματοποίησε με σκέψη
Αν τρέχεις επαναλαμβανόμενα scrapes, χρησιμοποίησε cron (Linux/Mac) ή Task Scheduler (Windows) — αλλά παρακολούθησε για αποτυχίες. Ένα cron job που αποτυγχάνει σιωπηλά για δύο εβδομάδες είναι χειρότερο από το καθόλου automation.
Εναλλακτικά: το του Thunderbit σού επιτρέπει να περιγράψεις το διάστημα σε απλά αγγλικά, χωρίς να χρειάζεσαι cron syntax.
Καλές νομικές και ηθικές πρακτικές για scraping στο Reddit
Αυτό δεν είναι πρόχειρη αποποίηση ευθύνης. Το Reddit επιβάλλει επιθετικά τους όρους του από τις αλλαγές του API το 2023, και το scraping προσωπικών δεδομένων έχει πραγματική νομική έκθεση.
Να τι έχει πραγματικά σημασία.
Οι Όροι Χρήσης του Reddit: Τι λένε πραγματικά
Η του Reddit (αναθεωρημένη έως τις 31 Μαρτίου 2026) απαγορεύει ρητά την πρόσβαση, αναζήτηση ή συλλογή δεδομένων από τις υπηρεσίες με αυτοματοποιημένα μέσα, εκτός αν το επιτρέπουν οι όροι ή ξεχωριστή συμφωνία. Οι και οι προσθέτουν περισσότερες λεπτομέρειες: το Reddit μπορεί να παρακολουθεί και να ελέγχει τη χρήση από developers, να αλλάζει ή να διακόπτει την πρόσβαση και να μπλοκάρει οριστικά την πρόσβαση για υπερβολική ή καταχρηστική χρήση. Η εμπορική χρήση γενικά απαιτεί ρητή έγκριση.
Η του Μαρτίου 2026 πάει ακόμα παραπέρα: απαιτείται έγκριση πριν από την πρόσβαση σε δεδομένα Reddit μέσω API, η μη εγκεκριμένη εμπορική εκμετάλλευση και οι χρήσεις AI/data-mining απαγορεύονται, και η επιβολή μπορεί να περιλαμβάνει ανάκληση tokens, αναστολή apps ή λογαριασμών και αναστολή σχετικών bots ή domains.
Συμμόρφωση με το robots.txt
Το τρέχον του Reddit είναι ασυνήθιστα περιοριστικό:
1User-agent: *
2Disallow: /Αυτό είναι καθολική απαγόρευση για όλους τους αυτοματοποιημένους user agents. Παραπέμπει επίσης στην . Είναι πολύ αυστηρότερο από τα πιο επιτρεπτικά μοτίβα robots.txt που κάποιοι developers εξακολουθούν να θεωρούν δεδομένα από παλιότερες νόρμες web-scraping.
Καλύτερη πρακτική: έλεγχε πάντα το robots.txt πριν κάνεις scrape, ακόμα κι αν το εργαλείο σου δεν το επιβάλλει αυτόματα.
Προσωπικά δεδομένα και ιδιωτικότητα (GDPR/CCPA)
Αν κάνεις scraping usernames, ιστορικό posts ή οποιαδήποτε προσωπικά αναγνωρίσιμη πληροφορία, μπορεί να ισχύουν οι (ΕΕ) και CCPA (Καλιφόρνια). Καλύτερη πρακτική: ανωνυμοποίησε ή συγκέντρωσε τα προσωπικά δεδομένα πριν τα αποθηκεύσεις. Μην χτίζεις προφίλ μεμονωμένων χρηστών χωρίς νόμιμη βάση.
Άδεια GitHub repo: έλεγξε πριν χτίσεις πάνω του
Πολλά reddit scraper GitHub repos χρησιμοποιούν MIT ή Apache άδειες (περιοριστικά επιτρεπτές), αλλά κάποια δεν έχουν καθόλου LICENSE file — πράγμα που νομικά σημαίνει "all rights reserved." Πριν κάνεις fork, τροποποιήσεις ή χτίσεις πάνω σε ένα repo, έλεγχε πάντα το LICENSE file. Χωρίς άδεια = νομικά ασαφές, ανεξάρτητα από το πόσα stars έχει.
Η επιβολή είναι πραγματική το 2025–2026
Η ιστορία επιβολής του Reddit δεν σταμάτησε το 2023. Το Reddit υπέβαλε καταγγελία κατά της Anthropic το 2025, υποστηρίζοντας μη εξουσιοδοτημένο scraping/χρήση περιεχομένου Reddit, και επίσης κινήθηκε νομικά στο Reddit v. SerpApi στα τέλη του 2025. Αυτά είναι σημάδια ότι το Reddit είναι πρόθυμο να προχωρήσει σε νομική επιβολή, όχι μόνο σε τεχνικό μπλοκάρισμα.
Πώς να διαλέξεις τη σωστή προσέγγιση Reddit Scraper GitHub το 2026
Το τοπίο του reddit scraper GitHub έχει αλλάξει δραματικά από το 2023. Τα περισσότερα repos είναι ξεπερασμένα. Τα rate limits και το όριο 1.000 posts είναι πραγματικοί περιορισμοί. Το Pushshift έχει φύγει για τον συνηθισμένο χρήστη. Και η στοίβα πολιτικών του Reddit είναι πιο σαφής και πιο επιβεβλημένη από ποτέ.
Η σύντομη εκδοχή:
- Το PRAW παραμένει η πιο αξιόπιστη open-source βάση αν μπορείς να αποδεχθείς τα όρια του API του Reddit και θέλεις να χτίσεις custom λογική.
- Το Pushshift/PSAW δεν είναι πια απάντηση γενικής χρήσης.
- Το snscrape Reddit module είναι legacy και αναξιόπιστο.
- Τα .json και public-endpoint scrapers είναι εύθραυστα και συχνά μπλοκάρονται το 2026.
- Τα browser-based εργαλεία — είτε Playwright repos είτε no-code επιλογές όπως το — είναι η πιο πρακτική διαδρομή για πολλούς χρήστες, ειδικά για μη προγραμματιστές.
Ξεκίνα από το use case σου, όχι από το εργαλείο. Κάνε τον 5λεπτο έλεγχο υγείας του repo πριν δεσμευτείς σε οποιοδήποτε GitHub project.
Και αν προτιμάς να παραλείψεις το setup και να ξεκινήσεις scraping στο Reddit μέσα σε λεπτά, .
Συχνές ερωτήσεις
Ποια είναι τα καλύτερα open-source Reddit scrapers στο GitHub το 2026;
Το παραμένει το πιο αξιόπιστο API wrapper, με ενεργή συντήρηση και καλή τεκμηρίωση. Το είναι ένα αξιόπιστο συντηρούμενο CLI tool βασισμένο στο PRAW. Scrapers βασισμένοι σε Playwright δουλεύουν για scraping χωρίς API, και το Reddit module του snscrape είναι μερικώς λειτουργικό αλλά σε μεγάλο βαθμό χωρίς συντήρηση. Να ελέγχεις πάντα την ημερομηνία τελευταίου commit και τα open issues πριν χρησιμοποιήσεις οποιοδήποτε repo — τα περισσότερα από τα στο GitHub είναι ξεπερασμένα.
Είναι νόμιμο το scraping στο Reddit;
Το scraping δημόσια διαθέσιμων δεδομένων βρίσκεται σε νομικά γκρίζα ζώνη, αλλά οι ίδιοι οι όροι του Reddit είναι περιοριστικοί. Η , οι , η , η και το πιέζουν όλοι ενάντια στο μη εξουσιοδοτημένο μαζικό scraping. Η εμπορική αναδιανομή scraped δεδομένων μπορεί να απαιτεί ρητή άδεια από το Reddit. Αν κάνεις scraping προσωπικών δεδομένων, μπορεί να ισχύουν επίσης οι GDPR και CCPA.
Πώς ξεπερνάω τα rate limits του Reddit API;
Χρησιμοποίησε exponential backoff, παρακολούθησε τα headers X-Ratelimit-Remaining και σκέψου το time-window chunking για να δουλέψεις μέσα στα όρια. Το browser-based scraping (Playwright ή ) παρακάμπτει τα rate limits του API επειδή κάνει scrape rendered σελίδες, αλλά έχει τις δικές του παραμέτρους (ταχύτητα φόρτωσης σελίδας, anti-bot μέτρα). Δεν υπάρχει μαγικό κόλπο για να αφαιρέσεις εντελώς τα rate limits — επιβάλλονται από τον server.
Μπορώ να κάνω scrape το Reddit χωρίς API key;
Ναι. Scrapers βασισμένοι σε Playwright και το τέχνασμα με τα .json URL δεν χρειάζονται API keys. Το επίσης δεν χρειάζεται API key, αφού κάνει scraping μέσω browser. Τα trade-offs: τα .json endpoints μπλοκάρονται όλο και πιο συχνά (επιστρέφοντας 403 σε πολλά περιβάλλοντα από τον Απρίλιο του 2026), και το browser-based scraping είναι πιο αργό και πιο απαιτητικό σε πόρους από τα API calls.
Τι συνέβη με το Pushshift για το Reddit scraping;
Η δημόσια πρόσβαση στο API του Pushshift αφαιρέθηκε μετά τις αλλαγές αδειοδότησης δεδομένων του Reddit που ξεκίνησαν το 2023. Το wrapper είναι archived και ξεπερασμένο. Περιορισμένη ακαδημαϊκή πρόσβαση μπορεί να υπάρχει μέσω συγκεκριμένων εγκεκριμένων καναλιών, αλλά για τους περισσότερους χρήστες που ψάχνουν σήμερα "reddit scraper github", το Pushshift δεν είναι πια βιώσιμη επιλογή. Αν χρειάζεσαι βαθιά ιστορικά δεδομένα Reddit, δες τις εγκεκριμένες ακαδημαϊκές ή αδειοδοτημένες διαδρομές δεδομένων του Reddit.
Μάθε περισσότερα