
Υπάρχει κάτι παράξενα ικανοποιητικό στο να βλέπεις ένα script να διασχίζει με ταχύτητα έναν ιστότοπο και να συλλέγει δεδομένα, ενώ εσύ πίνεις τον καφέ σου. Αν είσαι σαν κι εμένα, πιθανότατα έχεις αναρωτηθεί: «Πώς μπορώ να κάνω το web scraping πιο γρήγορο, πιο έξυπνο και λιγότερο κουραστικό;»
Αυτό ακριβώς ήταν που με έφερε στον κόσμο του OpenClaw web scraping. Σε ένα ψηφιακό τοπίο όπου πάνω από το 90% των επιχειρήσεων βασίζονται στην εξαγωγή δεδομένων από το web για τα πάντα, από sales leads μέχρι market intelligence, η εξοικείωση με τα σωστά εργαλεία δεν είναι απλώς τεχνολογικό κατόρθωμα — είναι επιχειρηματική αναγκαιότητα.
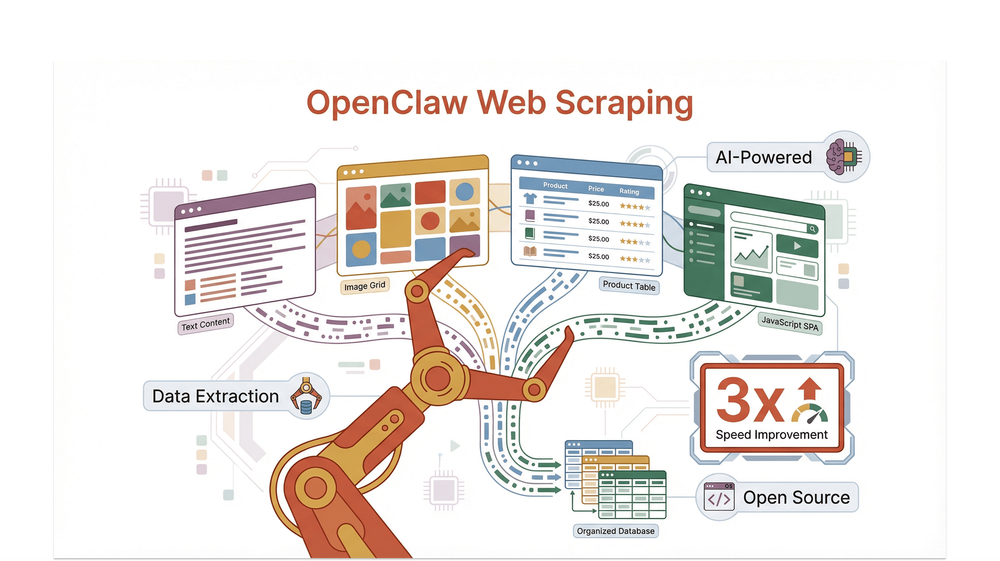
Το OpenClaw έχει εξελιχθεί γρήγορα σε αγαπημένο εργαλείο της κοινότητας του scraping, ιδιαίτερα για όσους αντιμετωπίζουν δυναμικούς, πλούσιους σε εικόνες ή σύνθετους ιστότοπους που κάνουν τα παραδοσιακά scrapers να λαχανιάζουν.
Σε αυτόν τον οδηγό, θα σε περάσω από όλα: από τη ρύθμιση του OpenClaw μέχρι τη δημιουργία προηγμένων, αυτοματοποιημένων ροών εργασίας. Και επειδή μου αρέσει να εξοικονομώ χρόνο, θα σου δείξω πώς να απογειώσεις το scraping σου με τις λειτουργίες AI του Thunderbit, για μια ροή εργασίας που δεν είναι μόνο ισχυρή, αλλά και πραγματικά ευχάριστη στη χρήση.
Δοκίμασε το Thunderbit για πιο έξυπνο web scraping
Τι είναι το OpenClaw Web Scraping;
Ας ξεκινήσουμε από τα βασικά. Ο όρος OpenClaw web scraping αναφέρεται στη χρήση της πλατφόρμας OpenClaw — ενός self-hosted, ανοιχτού κώδικα agent gateway — για την αυτοματοποίηση της εξαγωγής δεδομένων από ιστοτόπους. Το OpenClaw δεν είναι απλώς ένα ακόμη scraper· είναι ένα αρθρωτό σύστημα που συνδέει τα αγαπημένα σου κανάλια συνομιλίας (όπως το Discord ή το Telegram) με μια σουίτα εργαλείων για agents, όπως web fetchers, εργαλεία αναζήτησης, αλλά και έναν managed browser για εκείνους τους ιστότοπους με έντονη χρήση JavaScript που κάνουν άλλα εργαλεία να ιδρώνουν.
Τι κάνει το OpenClaw να ξεχωρίζει στην εξαγωγή δεδομένων από το web; Έχει σχεδιαστεί ώστε να είναι ταυτόχρονα ευέλικτο και ανθεκτικό. Μπορείς να χρησιμοποιήσεις ενσωματωμένα εργαλεία όπως το web_fetch για απλή εξαγωγή μέσω HTTP, να ανοίξεις έναν Chromium browser υπό έλεγχο agent για δυναμικό περιεχόμενο ή να προσθέσεις skills που έχουν δημιουργηθεί από την κοινότητα (όπως το openclaw-plugin-web-scraper) για πιο προχωρημένες ροές εργασίας. Είναι ανοιχτού κώδικα (με άδεια MIT), συντηρείται ενεργά και διαθέτει ένα ζωντανό οικοσύστημα από plugins και skills, γεγονός που το καθιστά κορυφαία επιλογή για όποιον παίρνει σοβαρά το scraping σε μεγάλη κλίμακα.
Το OpenClaw χειρίζεται ένα ευρύ φάσμα τύπων δεδομένων και μορφών ιστοτόπων, όπως:
- Κείμενο και δομημένο HTML
- Εικόνες και σύνδεσμοι πολυμέσων
- Δυναμικό περιεχόμενο που αποδίδεται με JavaScript
- Σύνθετες, πολυεπίπεδες DOM δομές
Και επειδή βασίζεται σε agents, μπορείς να συντονίζεις εργασίες scraping, να αυτοματοποιείς αναφορές και ακόμη και να αλληλεπιδράς με τα δεδομένα σου σε πραγματικό χρόνο — όλα από την αγαπημένη σου εφαρμογή συνομιλίας ή το terminal.
Γιατί το OpenClaw είναι ένα Ισχυρό Εργαλείο για Εξαγωγή Δεδομένων από το Web
Γιατί λοιπόν τόσοι επαγγελματίες των δεδομένων και λάτρεις του αυτοματισμού στρέφονται στο OpenClaw; Ας αναλύσουμε τα τεχνικά του πλεονεκτήματα που το κάνουν δύναμη-πακέτο για web scraping:
Ταχύτητα και Συμβατότητα
Η αρχιτεκτονική του OpenClaw είναι φτιαγμένη για ταχύτητα. Το βασικό του εργαλείο web_fetch αξιοποιεί αιτήματα HTTP GET με έξυπνη εξαγωγή περιεχομένου, caching και διαχείριση ανακατευθύνσεων. Σε εσωτερικά και κοινοτικά benchmarks, το OpenClaw ξεπερνά σταθερά παλαιότερα εργαλεία όπως το BeautifulSoup ή το Selenium όταν εξάγει μεγάλους όγκους δεδομένων από στατικούς και ημι-δυναμικούς ιστότοπους (docs.openclaw.ai).
Αλλά εκεί όπου το OpenClaw πραγματικά λάμπει είναι η συμβατότητα. Χάρη στο managed browser mode, μπορεί να χειριστεί ιστοτόπους που βασίζονται στη JavaScript για την απόδοση του περιεχομένου — κάτι που μπλοκάρει πολλά παραδοσιακά scrapers. Είτε στοχεύεις έναν κατάλογο e-commerce γεμάτο εικόνες είτε μια single-page εφαρμογή με infinite scroll, το Chromium profile που ελέγχεται από agent του OpenClaw κάνει τη δουλειά.
Αντοχή στις Αλλαγές του Ιστότοπου
Ένα από τα μεγαλύτερα προβλήματα στο web scraping είναι η αντιμετώπιση ενημερώσεων του site που σπάνε τα scripts σου. Το σύστημα plugins και skills του OpenClaw έχει σχεδιαστεί ώστε να είναι ανθεκτικό. Για παράδειγμα, τα wrappers γύρω από τη βιβλιοθήκη Scrapling προσφέρουν προσαρμοστική εξαγωγή, πράγμα που σημαίνει ότι το scraper σου μπορεί να «μετακινήσει» ξανά τα στοιχεία ακόμη κι αν αλλάξει η διάταξη του site — τεράστιο πλεονέκτημα για μακροπρόθεσμα projects.
Απόδοση στην Πράξη
Σε δοκιμές δίπλα-δίπλα, οι ροές εργασίας με βάση το OpenClaw έδειξαν:

- Έως και 3x ταχύτερη εξαγωγή σε σύνθετους ιστότοπους πολλών σελίδων, σε σύγκριση με παραδοσιακούς Python scrapers (scrapling.readthedocs.io)
- Υψηλότερα ποσοστά επιτυχίας σε δυναμικές σελίδες με έντονη χρήση JavaScript, χάρη στο managed browser
- Καλύτερο χειρισμό σελίδων με μικτό περιεχόμενο (κείμενο, εικόνες, αποσπάσματα HTML)
Οι μαρτυρίες χρηστών συχνά τονίζουν την ικανότητα του OpenClaw να «απλώς δουλεύει» εκεί όπου άλλα εργαλεία αποτυγχάνουν — ειδικά όταν πρόκειται για εξαγωγή δεδομένων από sites με δύσκολη διάταξη ή μέτρα αντι-bot.
Ξεκινώντας: Ρύθμιση του OpenClaw για Web Scraping
Έτοιμος να βουτήξεις; Δες πώς να βάλεις το OpenClaw να τρέχει στο σύστημά σου.
Βήμα 1: Εγκατάσταση του OpenClaw
Το OpenClaw υποστηρίζει Windows, macOS και Linux. Η επίσημη τεκμηρίωση προτείνει να ξεκινήσεις με το καθοδηγούμενο onboarding flow:
openclaw onboard
Αυτή η εντολή σε καθοδηγεί στην αρχική ρύθμιση, συμπεριλαμβανομένων ελέγχων περιβάλλοντος και βασικής παραμετροποίησης.
Βήμα 2: Εγκατάσταση των Απαραίτητων Εξαρτήσεων
Ανάλογα με τη ροή εργασίας σου, μπορεί να χρειαστείς:
- Node.js (για το βασικό gateway)
- Python 3.10+ (για plugins/skills που χρησιμοποιούν Python, όπως τα Scrapling wrappers)
- Chromium/Chrome (για managed browser mode)
Στο Linux, ίσως χρειαστεί να εγκαταστήσεις επιπλέον πακέτα για υποστήριξη browser. Η τεκμηρίωση έχει μια αφιερωμένη ενότητα αντιμετώπισης προβλημάτων για συνηθισμένα ζητήματα.
Βήμα 3: Ρύθμιση των Εργαλείων Web
Ρύθμισε τον πάροχο web αναζήτησής σου:
openclaw configure --section web
Έτσι μπορείς να επιλέξεις ανάμεσα σε παρόχους όπως το Brave, το DuckDuckGo ή το Firecrawl.
Βήμα 4: Εγκατάσταση Plugins ή Skills (Προαιρετικό)
Για να ξεκλειδώσεις προχωρημένο scraping, εγκατέστησε plugins ή skills της κοινότητας. Για παράδειγμα, για να προσθέσεις το openclaw-plugin-web-scraper:
git clone https://github.com/hvkeyn/openclaw-plugin-web-scraper.git
cd openclaw-plugin-web-scraper
openclaw plugins install .
openclaw gateway restart

Χρήσιμες Συμβουλές για Αρχάριους
- Τρέξε
openclaw security auditμετά την εγκατάσταση νέων plugins για έλεγχο ευπαθειών (docs.openclaw.ai). - Αν χρησιμοποιείς Node μέσω nvm, έλεγξε ξανά τα CA certificates σου — οι ασυμφωνίες μπορούν να χαλάσουν τα HTTPS αιτήματα (docs.openclaw.ai).
- Πάντα να απομονώνεις plugins και browser components σε VM ή container για επιπλέον ασφάλεια.
Οδηγός Αρχάριου: Το Πρώτο σου OpenClaw Scraping Project
Ας φτιάξουμε ένα απλό scraping project — χωρίς να χρειάζεται διδακτορικό στην πληροφορική.
Βήμα 1: Επίλεξε τον Ιστότοπο-Στόχο
Διάλεξε έναν ιστότοπο με δομημένα δεδομένα, όπως μια σελίδα προϊόντων ή έναν κατάλογο. Για αυτό το παράδειγμα, ας κάνουμε scraping στους τίτλους προϊόντων από μια demo e-commerce σελίδα.
Βήμα 2: Κατανόησε τη Δομή του DOM
Χρησιμοποίησε το εργαλείο “Inspect Element” του browser σου για να βρεις τα HTML tags που περιέχουν τα δεδομένα που θέλεις (π.χ. <h2 class="product-title">).
Βήμα 3: Ρύθμισε Φίλτρα Εξαγωγής
Με τα skills του OpenClaw που βασίζονται στο Scrapling, μπορείς να χρησιμοποιήσεις CSS selectors για να στοχεύσεις στοιχεία. Δες ένα δείγμα script με το skill openclaw-ultra-scraping:
PYTHON=/opt/scrapling-venv/bin/python3
$PYTHON scripts/scrape.py fetch "https://example.com/products" --css "h2.product-title::text"
Αυτή η εντολή ανακτά τη σελίδα και εξάγει όλους τους τίτλους προϊόντων.
Βήμα 4: Ασφαλής Διαχείριση Δεδομένων
Εξήγαγε τα αποτελέσματά σου σε CSV ή JSON για εύκολη ανάλυση:
$PYTHON scripts/scrape.py fetch "https://example.com/products" --css "h2.product-title::text" -f csv -o products.csv
Βασικές Έννοιες με Απλά Λόγια
- Tool schemas: Ορίζουν τι μπορεί να κάνει κάθε tool ή skill (fetch, extract, crawl).
- Skill registration: Προσθέτεις νέες δυνατότητες scraping στο OpenClaw μέσω ClawHub ή με χειροκίνητη εγκατάσταση.
- Safe data handling: Πάντα να ελέγχεις και να καθαρίζεις τα outputs πριν τα χρησιμοποιήσεις σε production.
Αυτοματοποιώντας Σύνθετες Ροές Εργασίας Scraping με το OpenClaw

Μόλις κατακτήσεις τα βασικά, είναι ώρα για αυτοματοποίηση. Δες πώς να στήσεις μια ροή εργασίας που τρέχει μόνη της (ενώ εσύ ασχολείσαι με πιο σημαντικά πράγματα — όπως το μεσημεριανό).
Βήμα 1: Δημιούργησε και Καταχώρισε Custom Skills
Γράψε ή εγκατέστησε skills που ταιριάζουν στις δικές σου ανάγκες εξαγωγής. Για παράδειγμα, μπορεί να θέλεις να κάνεις scraping σε πληροφορίες προϊόντων και εικόνες και μετά να στέλνεις καθημερινή αναφορά.
Βήμα 2: Ρύθμισε Προγραμματισμένες Εργασίες
Σε Linux ή macOS, χρησιμοποίησε το cron για να προγραμματίσεις τα scraping scripts σου:
0 6 * * * /usr/bin/python3 /path/to/scrape.py fetch "https://example.com/products" --css "h2.product-title::text" -f csv -o /data/products_$(date +\%F).csv
Στα Windows, χρησιμοποίησε το Task Scheduler με παρόμοιες παραμέτρους.
Βήμα 3: Ενσωμάτωσε με Άλλα Εργαλεία
Για δυναμική πλοήγηση (π.χ. κλικ σε κουμπιά ή σύνδεση), συνδύασε το OpenClaw με Selenium ή Playwright. Πολλά OpenClaw skills μπορούν να καλέσουν αυτά τα εργαλεία ή να δεχτούν scripts αυτοματοποίησης browser.
Σύγκριση Χειροκίνητης και Αυτοματοποιημένης Ροής Εργασίας
| Βήμα | Χειροκίνητη Ροή Εργασίας | Αυτοματοποιημένη Ροή Εργασίας OpenClaw |
|---|---|---|
| Εξαγωγή δεδομένων | Τρέχεις το script με το χέρι | Προγραμματισμένη μέσω cron/Task Scheduler |
| Δυναμική πλοήγηση | Κάνεις κλικ χειροκίνητα | Αυτοματοποιημένη με Selenium/skills |
| Εξαγωγή δεδομένων | Αντιγραφή/επικόλληση ή λήψη | Αυτόματη εξαγωγή σε CSV/JSON |
| Αναφορές | Χειροκίνητη περίληψη | Αυτόματη δημιουργία και αποστολή αναφορών |
| Διαχείριση σφαλμάτων | Διορθώνεις καθώς προχωράς | Ενσωματωμένες επαναλήψεις/καταγραφή |
Το αποτέλεσμα; Περισσότερα δεδομένα, λιγότερη αγγαρεία και μια ροή εργασίας που κλιμακώνεται μαζί με τις φιλοδοξίες σου.
Ενίσχυση της Αποδοτικότητας: Ενσωμάτωση των Λειτουργιών AI Scraping του Thunderbit με το OpenClaw
Και τώρα περνάμε στο πραγματικά ενδιαφέρον κομμάτι. Ως συνιδρυτής του Thunderbit, πιστεύω πολύ στον συνδυασμό του καλύτερου και από τους δύο κόσμους: της ευέλικτης μηχανής scraping του OpenClaw και της ανίχνευσης πεδίων με AI και της εξαγωγής του Thunderbit.
Πώς το Thunderbit Απογειώνει το OpenClaw
- Προτάσεις Πεδίων με AI: Το Thunderbit μπορεί να αναλύσει αυτόματα μια web σελίδα και να προτείνει τις καλύτερες στήλες για εξαγωγή — τέλος στο μάντεμα των CSS selectors.
- Άμεση Εξαγωγή Δεδομένων: Εξήγαγε τα δεδομένα που έκανες scraping απευθείας σε Excel, Google Sheets, Airtable ή Notion με ένα μόνο κλικ (Thunderbit Docs).
- Υβριδική Ροή Εργασίας: Χρησιμοποίησε το OpenClaw για σύνθετη πλοήγηση και λογική scraping, και μετά πέρασε τα αποτελέσματα στο Thunderbit για αντιστοίχιση πεδίων, εμπλουτισμό και εξαγωγή.

Παράδειγμα Υβριδικής Ροής Εργασίας
- Χρησιμοποίησε το managed browser ή το Scrapling skill του OpenClaw για να εξαγάγεις ακατέργαστα δεδομένα από έναν δυναμικό ιστότοπο.
- Εισήγαγε τα αποτελέσματα στο Thunderbit.
- Πάτησε “AI Suggest Fields” για αυτόματη αντιστοίχιση των δεδομένων.
- Εξήγαγε στη μορφή ή πλατφόρμα που προτιμάς.
Αυτός ο συνδυασμός αλλάζει τα δεδομένα για ομάδες που χρειάζονται και ισχύ και ευκολία χρήσης — σκέψου sales ops, e-commerce analysts και όποιον έχει βαρεθεί να παλεύει με μπερδεμένα υπολογιστικά φύλλα.
Δοκίμασε τα AI Suggest Fields του Thunderbit
Αντιμετώπιση Προβλημάτων σε Πραγματικό Χρόνο: Συνηθισμένα Σφάλματα του OpenClaw και Πώς να τα Διορθώσεις
Ακόμη και τα καλύτερα εργαλεία κολλάνε πού και πού. Ορίστε ένας γρήγορος οδηγός για τη διάγνωση και τη διόρθωση συνηθισμένων προβλημάτων scraping στο OpenClaw:
Συχνά Σφάλματα
- Προβλήματα αυθεντικοποίησης: Ορισμένοι ιστότοποι μπλοκάρουν bots ή απαιτούν σύνδεση. Χρησιμοποίησε το managed browser του OpenClaw ή ενσωμάτωσέ το με Selenium για ροές login (docs.openclaw.ai).
- Αποκλεισμένα αιτήματα: Κάνε περιστροφή user agents, χρησιμοποίησε proxies ή μείωσε τον ρυθμό αιτημάτων σου για να αποφύγεις bans.
- Αποτυχίες parsing: Έλεγξε ξανά τους CSS/XPath selectors σου· οι ιστότοποι μπορεί να έχουν αλλάξει δομή.
- Σφάλματα plugin/skill: Τρέξε
openclaw plugins doctorγια να διαγνώσεις προβλήματα με εγκατεστημένες επεκτάσεις (docs.openclaw.ai).
Εντολές Διάγνωσης
openclaw status– Έλεγχος κατάστασης gateway και εργαλείων.openclaw security audit– Σάρωση για ευπάθειες.openclaw browser --browser-profile openclaw status– Έλεγχος της υγείας του browser automation.
Πόροι Κοινότητας
Καλές Πρακτικές για Αξιόπιστο και Κλιμακώσιμο OpenClaw Scraping

Θέλεις το scraping σου να παραμένει ομαλό και βιώσιμο; Ορίστε η λίστα ελέγχου μου:
- Σεβάσου το robots.txt: Κάνε scraping μόνο εκεί που επιτρέπεται.
- Περιορισμός ρυθμού αιτημάτων: Απόφυγε να βομβαρδίζεις τους ιστότοπους με υπερβολικά πολλά αιτήματα το δευτερόλεπτο.
- Επαλήθευση αποτελεσμάτων: Πάντα να ελέγχεις τα δεδομένα σου για πληρότητα και ακρίβεια.
- Παρακολούθηση χρήσης: Κατέγραφε τις εκτελέσεις scraping και πρόσεχε για σφάλματα ή bans.
- Χρησιμοποίησε proxies για κλίμακα: Κάνε περιστροφή IPs για να αποφύγεις rate limits.
- Ανάπτυξη στο cloud: Για μεγάλα jobs, τρέξε το OpenClaw σε VM ή σε containerized περιβάλλον.
- Χειρίσου τα σφάλματα με χάρη: Βάλε επαναλήψεις και fallback logic στα scripts σου.
| Κάνε | Μην κάνεις |
|---|---|
| Χρησιμοποίησε επίσημα plugins/skills | Εγκαθιστάς άκριτα μη αξιόπιστο κώδικα |
| Τρέχε τακτικά security audits | Αγνοείς προειδοποιήσεις για ευπάθειες |
| Δοκίμασε σε staging πριν την παραγωγή | Κάνεις scraping σε ευαίσθητα ή ιδιωτικά δεδομένα |
| Τεκμηρίωσε τις ροές εργασίας σου | Βασίζεσαι σε hardcoded selectors |
Προχωρημένες Συμβουλές: Προσαρμογή και Επέκταση του OpenClaw για Μοναδικές Ανάγκες
Αν είσαι έτοιμος να πας σε full power-user mode, το OpenClaw σου επιτρέπει να φτιάξεις custom skills και plugins για εξειδικευμένες εργασίες.
Ανάπτυξη Custom Skills
- Ακολούθησε τα OpenClaw skill SDK docs για να δημιουργήσεις νέα εργαλεία εξαγωγής.
- Χρησιμοποίησε Python ή TypeScript, ανάλογα με το επίπεδο άνεσής σου.
- Καταχώρισε το skill σου στο ClawHub για εύκολο μοίρασμα και επαναχρησιμοποίηση.
Προχωρημένες Λειτουργίες
- Διαδοχική σύνδεση skills: Συνδύασε πολλαπλά βήματα εξαγωγής (π.χ. κάνε scraping σε μια σελίδα λίστας και μετά επισκέψου κάθε σελίδα λεπτομερειών).
- Headless browsers: Χρησιμοποίησε το managed Chromium του OpenClaw ή ενσωμάτωσε το Playwright για ιστοτόπους με έντονη χρήση JavaScript.
- Ενσωμάτωση AI agents: Σύνδεσε το OpenClaw με εξωτερικές AI υπηρεσίες για πιο έξυπνη ανάλυση ή εμπλουτισμό δεδομένων.
Διαχείριση Σφαλμάτων και Context
- Χτίσε ισχυρό error handling στα skills σου (try/except στην Python, error callbacks στο TypeScript).
- Χρησιμοποίησε context objects για να περνάς κατάσταση ανάμεσα στα βήματα scraping.
Για έμπνευση, δες τα skills που συνέβαλε η κοινότητα και το Scrapling API reference.
Συμπέρασμα & Βασικά Συμπεράσματα
Καλύψαμε πολλά — από την εγκατάσταση του OpenClaw και το πρώτο σου scrape μέχρι τη δημιουργία αυτοματοποιημένων, υβριδικών ροών εργασίας με το Thunderbit. Να τι ελπίζω να κρατήσεις:
- Το OpenClaw είναι μια ευέλικτη δύναμη ανοιχτού κώδικα για εξαγωγή δεδομένων από το web, ειδικά σε σύνθετους ή δυναμικούς ιστότοπους.
- Το οικοσύστημα plugins/skills του σου επιτρέπει να καλύψεις τα πάντα — από απλά fetches μέχρι προχωρημένο, πολυβηματικό scraping.
- Ο συνδυασμός του OpenClaw με τις λειτουργίες AI του Thunderbit κάνει την αντιστοίχιση πεδίων, την εξαγωγή δεδομένων και την αυτοματοποίηση ροών εργασίας παιχνιδάκι.
- Μείνε ασφαλής και σύμμορφος: Έλεγξε το περιβάλλον σου, σεβάσου τους κανόνες των site και επαλήθευσε τα δεδομένα σου.
- Μην φοβάσαι να πειραματιστείς: Η κοινότητα του OpenClaw είναι ενεργή και φιλόξενη — μπες μέσα, δοκίμασε νέα skills και μοιράσου τις επιτυχίες σου.
Αν θέλεις να ανεβάσεις ακόμη περισσότερο την αποδοτικότητα του scraping σου, το Thunderbit είναι εδώ για να βοηθήσει. Και αν θέλεις να συνεχίσεις να μαθαίνεις, δες το Thunderbit Blog για περισσότερες εις βάθος αναλύσεις και πρακτικούς οδηγούς.
Καλή εξαγωγή δεδομένων — και μακάρι οι selectors σου να βρίσκουν πάντα στόχο.
Συχνές Ερωτήσεις
1. Τι κάνει το OpenClaw διαφορετικό από τα παραδοσιακά web scrapers όπως το BeautifulSoup ή το Scrapy;
Το OpenClaw έχει χτιστεί ως agent gateway με αρθρωτά εργαλεία, υποστήριξη managed browser και σύστημα plugins/skills. Αυτό το κάνει πιο ευέλικτο για δυναμικούς, με έντονη χρήση JavaScript ή πλούσιους σε εικόνες ιστότοπους, και πιο εύκολο για end-to-end αυτοματοποίηση ροών εργασίας σε σύγκριση με παραδοσιακά, βαριά σε κώδικα frameworks (docs.openclaw.ai).
2. Μπορώ να χρησιμοποιήσω το OpenClaw αν δεν είμαι προγραμματιστής;
Ναι! Το onboarding flow και το οικοσύστημα plugins του OpenClaw είναι φιλικά για αρχάριους. Για πιο σύνθετες εργασίες, μπορείς να χρησιμοποιήσεις skills που έχει φτιάξει η κοινότητα ή να συνδυάσεις το OpenClaw με no-code εργαλεία όπως το Thunderbit για εύκολη αντιστοίχιση πεδίων και εξαγωγή.
3. Πώς μπορώ να αντιμετωπίσω συνηθισμένα σφάλματα στο OpenClaw;
Ξεκίνα με openclaw status και openclaw security audit. Για προβλήματα με plugins, χρησιμοποίησε το openclaw plugins doctor. Δες την επίσημη τεκμηρίωση και τα GitHub issues για λύσεις σε κοινά προβλήματα.
4. Είναι ασφαλές και νόμιμο να χρησιμοποιώ το OpenClaw για web scraping;
Όπως με κάθε scraper, να σέβεσαι πάντα τους όρους χρήσης του ιστότοπου και το robots.txt. Το OpenClaw είναι ανοιχτού κώδικα και τρέχει τοπικά, αλλά πρέπει να ελέγχεις τα plugins για ασφάλεια και να αποφεύγεις το scraping ευαίσθητων ή ιδιωτικών δεδομένων χωρίς άδεια (github.com).
5. Πώς μπορώ να συνδυάσω το OpenClaw με το Thunderbit για καλύτερα αποτελέσματα;
Χρησιμοποίησε το OpenClaw για τη σύνθετη λογική scraping και μετά εισήγαγε τα ακατέργαστα δεδομένα σου στο Thunderbit. Το AI Suggest Fields του Thunderbit θα αντιστοιχίσει αυτόματα τα δεδομένα σου, και μπορείς να εξάγεις απευθείας σε Excel, Google Sheets, Notion ή Airtable — κάνοντας τη ροή εργασίας σου πιο γρήγορη και πιο αξιόπιστη (Thunderbit Docs).
Θέλεις να δεις πώς το Thunderbit μπορεί να απογειώσει το scraping σου; Κατέβασε την επέκταση Chrome και ξεκίνα να χτίζεις πιο έξυπνες, υβριδικές ροές εργασίας σήμερα. Και μην ξεχάσεις να δεις το Thunderbit YouTube Channel για πρακτικά σεμινάρια και συμβουλές.
Δοκίμασε το Thunderbit για πιο έξυπνο web scraping Get Started Free
Μάθε περισσότερα
- Πώς να εγκαταστήσετε το Claude Chrome Extension: Ένας απλός οδηγός
- Τι είναι το Markdown for Agents της Cloudflare; Μια αναλυτική επισκόπηση
- Τα 10 καλύτερα εργαλεία web crawling για αποδοτική εξαγωγή δεδομένων
- Τα 10 καλύτερα εργαλεία λογισμικού web scraper το 2026
- Πώς να αναζητήσεις μια διεύθυνση email αποτελεσματικά το 2026




