

Το dashboard μου στο OpenRouter έδειχνε ήδη 47 δολάρια ως το μεσημέρι μιας Τρίτης. Είχα τρέξει ίσως καμιά δεκαριά εργασίες κώδικα — τίποτα τρελό, λίγη αναδιάρθρωση και μερικά bug fixes. Τότε κατάλαβα ότι οι προεπιλογές του OpenClaw έστελναν αθόρυβα κάθε αλληλεπίδραση, ακόμα και τα background heartbeat pings, μέσω του Claude Opus, με χρέωση 15+ δολάρια ανά εκατομμύριο tokens.
Αν έχεις δει κι εσύ παρόμοιες εκπλήξεις — και από ό,τι φαίνεται στα forums, πολλοί έχουν («Ήδη έχω ξοδέψει 40 δολάρια και ούτε καν το χρησιμοποιώ πολύ», έγραψε ένας χρήστης) — αυτός ο οδηγός σε περνάει από την πλήρη διαδικασία ελέγχου και βελτιστοποίησης που χρησιμοποίησα για να ρίξω το μηνιαίο κόστος μου περίπου κατά 90%. Όχι απλώς «βάλε φθηνότερο μοντέλο», αλλά μια συστηματική αποδόμηση του πού πηγαίνουν πραγματικά τα tokens, πώς να τα παρακολουθείς, ποια budget μοντέλα αντέχουν σε πραγματική agentic εργασία και τρία configs που μπορείς να κάνεις copy-paste σήμερα. Όλη η διαδικασία πήρε ένα απόγευμα.
Τι είναι η χρήση tokens στο OpenClaw και γιατί είναι τόσο υψηλή από προεπιλογή;
Τα tokens είναι η μονάδα χρέωσης για κάθε AI αλληλεπίδραση στο OpenClaw. Σκέψου τα σαν μικροσκοπικά κομμάτια κειμένου — περίπου 4 αγγλικοί χαρακτήρες ανά token. Κάθε μήνυμα που στέλνεις, κάθε απάντηση που λαμβάνεις, κάθε background διαδικασία που ενεργοποιείται: όλα χρεώνονται σε tokens.
Το πρόβλημα είναι ότι οι προεπιλογές του OpenClaw είναι ρυθμισμένες για μέγιστη ικανότητα, όχι για ελάχιστο κόστος. Out of the box, το βασικό μοντέλο είναι το anthropic/claude-opus-4-5 — η ακριβότερη διαθέσιμη επιλογή. Τα heartbeat pings; Τρέχουν κι αυτά στο Opus. Οι sub-agents που ανοίγουν για βοηθητικές εργασίες; Επίσης Opus. Το να χρησιμοποιείς Opus για ένα heartbeat ping είναι σαν να προσλαμβάνεις νευροχειρουργό για να βάλει ένα Band-Aid. Τεχνικά σωστό, οικονομικά καταστροφικό.
Οι περισσότεροι χρήστες δεν καταλαβαίνουν ότι πληρώνουν premium τιμές για τελείως απλές background εργασίες. Η προεπιλεγμένη ρύθμιση ουσιαστικά υποθέτει ότι θέλεις το καλύτερο μοντέλο για τα πάντα, συνεχώς — και σε χρεώνει αναλόγως.
Γιατί η μείωση της χρήσης tokens στο OpenClaw εξοικονομεί κάτι παραπάνω από χρήματα
Το προφανές όφελος είναι η εξοικονόμηση κόστους. Αλλά υπάρχουν και δευτερεύοντα κέρδη που αθροίζονται με τον χρόνο.
Τα φθηνότερα μοντέλα είναι συχνά πιο γρήγορα. Το Gemini 2.5 Flash-Lite τρέχει περίπου με 214 tokens το δευτερόλεπτο σε σύγκριση με τα 51 του Opus — δηλαδή περίπου 4x βελτίωση ταχύτητας σε κάθε αλληλεπίδραση. Το GPT-OSS-120B στο Cerebras φτάνει τα 1.917 tokens το δευτερόλεπτο, δηλαδή περίπου 35x πιο γρήγορο από το Opus. Σε ένα agentic loop με 50+ tool-calling βήματα, αυτή η διαφορά σημαίνει ότι τελειώνεις σε λεπτά αντί να περιμένεις το βασανιστικό 13,6 δευτερόλεπτα time-to-first-token του Opus σε κάθε γύρο.
Επίσης αποκτάς περισσότερο περιθώριο πριν φτάσεις σε rate limits, λιγότερες κομμένες συνεδρίες και χώρο να κλιμακώσεις τη χρήση χωρίς να κλιμακώνεται μαζί της και το άγχος για τον λογαριασμό.
Εκτιμώμενη εξοικονόμηση ανά προφίλ χρήσης:
| Προφίλ χρήστη | Εκτιμώμενη μηνιαία δαπάνη (προεπιλογή) | Μετά την πλήρη βελτιστοποίηση | Μηνιαία εξοικονόμηση |
|---|---|---|---|
| Ελαφρύ (~10 ερωτήματα/ημέρα) | ~$100 | ~$12 | ~88% |
| Μέτριο (~50 ερωτήματα/ημέρα) | ~$500 | ~$90 | ~82% |
| Βαρύ (~200+ ερωτήματα/ημέρα) | ~$1,750 | ~$220 | ~87% |
Αυτά δεν είναι θεωρητικά. Ένας developer κατέγραψε πτώση από $600–750/μήνα σε $3–4/ημέρα — πραγματική μείωση 90% — συνδυάζοντας model routing με τις κρυφές διαρροές που καλύπτει παρακάτω ο οδηγός.
Ανατομία της χρήσης tokens στο OpenClaw: πού πηγαίνει πραγματικά κάθε token
Αυτό είναι το κομμάτι που παραλείπουν οι περισσότεροι οδηγοί βελτιστοποίησης, και είναι και το πιο σημαντικό. Δεν μπορείς να διορθώσεις κάτι που δεν βλέπεις.
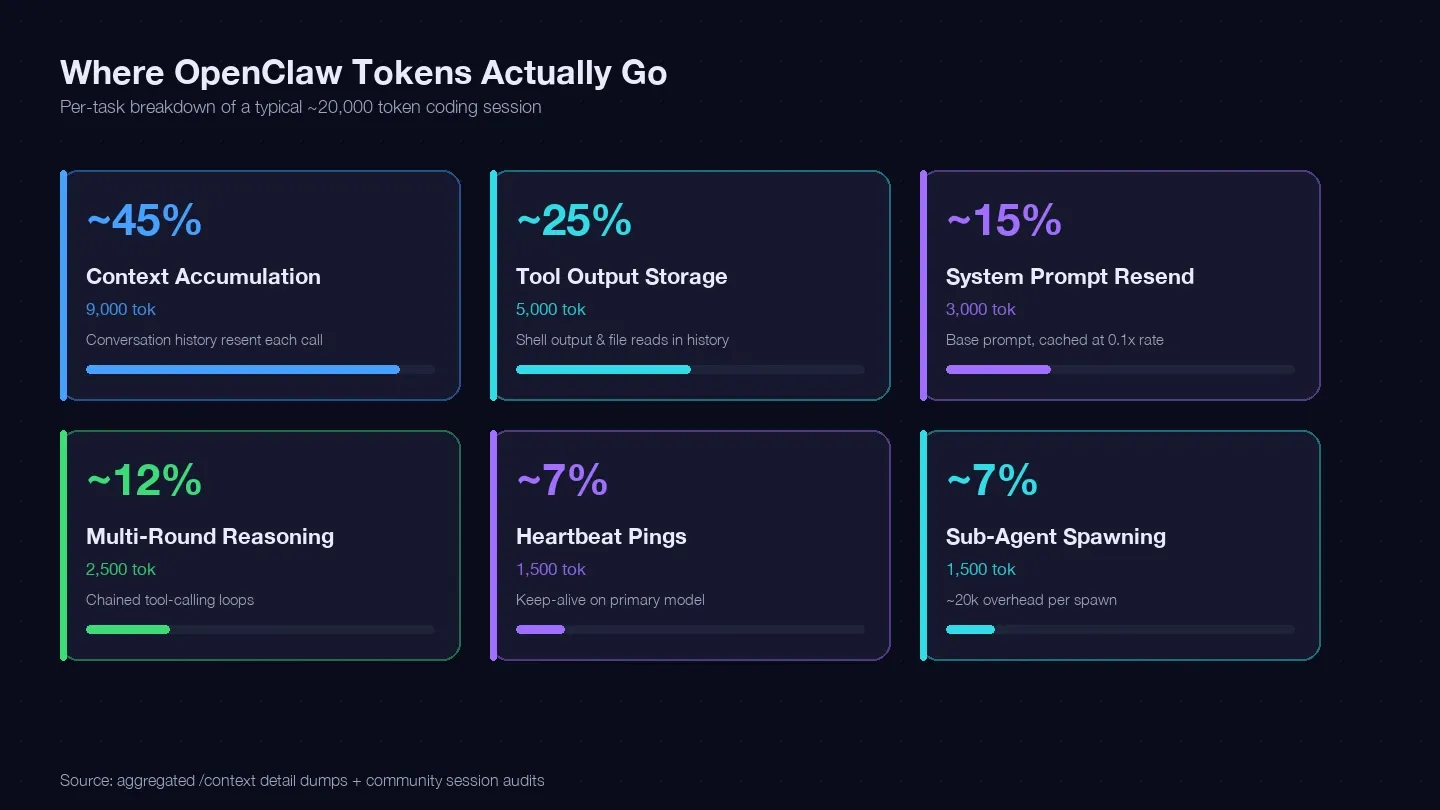
Έκανα audit σε αρκετές συνεδρίες και το συνέκρινα με τον οδηγό βελτιστοποίησης κόστους του LaoZhang και με community /context dumps για να χτίσω ένα token ledger για μια τυπική εργασία κώδικα. Να πού κατέληξαν περίπου 20.000 tokens:
| Κατηγορία token | Τυπικό % του συνόλου | Παράδειγμα (1 εργασία κώδικα) | Μπορείς να το ελέγξεις; |
|---|---|---|---|
| Συσσώρευση context (το ιστορικό της συνομιλίας ξαναστέλνεται σε κάθε κλήση) | ~40–50% | ~9.000 tokens | Ναι — /clear, /compact, πιο σύντομες συνεδρίες |
| Αποθήκευση αποτελεσμάτων εργαλείων (shell output, file reads που κρατιούνται στο history) | ~20–30% | ~5.000 tokens | Ναι — μικρότερα reads, πιο περιορισμένο scope εργαλείων |
| Επαναποστολή system prompt (~15K base) | ~10–15% | ~3.000 tokens | Μερικώς — cache reads στο 0,1x rate |
| Πολυγύρος λογισμός (αλυσιδωτά tool-calling loops) | ~10–15% | ~2.500 tokens | Επιλογή μοντέλου + καλύτερα prompts |
| Heartbeat / keep-alive pings | ~5–10% | ~1.500 tokens | Ναι — αλλαγή ρύθμισης |
| Sub-agent κλήσεις | ~5–10% | ~1.500 tokens | Ναι — model routing |
Το μεγαλύτερο κομμάτι — η συσσώρευση context — είναι το ιστορικό της συνομιλίας σου που ξαναστέλνεται σε κάθε API call. Ένα πραγματικό session dump έδειξε 185.400 tokens μόνο στο bucket Messages, πριν καν απαντήσει το μοντέλο. Το system prompt και τα εργαλεία πρόσθεσαν άλλα ~35.800 tokens σταθερού overhead από πάνω.
Το συμπέρασμα: αν δεν καθαρίζεις τις συνεδρίες ανάμεσα σε άσχετες εργασίες, πληρώνεις για να μεταδίδεις ξανά όλο το ιστορικό της συνομιλίας σου σε κάθε γύρο.
Πώς να παρακολουθείς τη χρήση tokens στο OpenClaw (δεν μπορείς να κόψεις κάτι που δεν βλέπεις)
Πριν αλλάξεις οτιδήποτε, χρειάζεσαι ορατότητα στο πού πάνε τα tokens σου. Το να πας κατευθείαν στο «βάλε φθηνότερο μοντέλο» χωρίς monitoring είναι σαν να προσπαθείς να χάσεις κιλά χωρίς ποτέ να ανέβεις στη ζυγαριά.
Έλεγξε το dashboard σου στο OpenRouter
Αν δρομολογείς μέσω OpenRouter, η σελίδα Activity είναι το πιο εύκολο dashboard χωρίς setup. Μπορείς να φιλτράρεις ανά model, provider, API key και χρονική περίοδο. Το Usage Accounting view σπάει τα δεδομένα σε prompt, completion, reasoning και cached tokens σε κάθε request. Υπάρχει και κουμπί Export (CSV ή PDF) για πιο μακροχρόνια ανάλυση.
Τι να κοιτάξεις: ποιο μοντέλο κατανάλωσε τα περισσότερα tokens και αν τα heartbeat ή τα sub-agent requests εμφανίζονται ως απροσδόκητα μεγάλα line items.
Κάνε audit στα τοπικά API logs σου
Το OpenClaw αποθηκεύει session data στο ~/.openclaw/agents.main/sessions/sessions.json, όπου περιλαμβάνεται το totalTokens ανά session. Μπορείς επίσης να τρέξεις openclaw logs --follow --json για real-time logging ανά request.
Μια σημαντική λεπτομέρεια: το sessions.json totalTokens δεν ενημερώνεται μετά το compaction, οπότε το dashboard μπορεί να δείχνει παλιές τιμές πριν από το compaction. Εμπιστεύσου τα /status και /context detail περισσότερο από τα αποθηκευμένα totals.
Χρησιμοποίησε τρίτα εργαλεία παρακολούθησης (για μεσαίους έως βαρείς χρήστες)
Το LiteLLM proxy σου δίνει ένα OpenAI-compatible endpoint μπροστά από 100+ providers και καταγράφει αυτόματα το κόστος ανά virtual key, model, χρήστη και ομάδα. Το killer feature του: σκληρά budgets ανά key που επιβιώνουν του /clear — ένας sub-agent που ξεφεύγει δεν μπορεί να ξεπεράσει το όριο που έβαλες.
Το Helicone είναι ακόμη πιο απλό — μια αλλαγή base URL σε μία γραμμή που σου δίνει Sessions view, ομαδοποιώντας σχετικά requests. Ένα prompt τύπου «φτιάξε αυτό το bug» που διασπάται σε 8+ sub-agent calls εμφανίζεται ως μία γραμμή session με το πραγματικό συνολικό κόστος. Δωρεάν tier: 10.000 requests/μήνα.
Γρήγοροι έλεγχοι μέσα στο OpenClaw
Για καθημερινό monitoring, τέσσερις εντολές μέσα στη συνεδρία κάνουν τη δουλειά:
/status— δείχνει χρήση context, τελευταία input/output tokens, εκτιμώμενο κόστος/usage full— usage footer ανά απάντηση/context detail— ανάλυση tokens ανά αρχείο, skill και εργαλείο/compact [guidance]— αναγκαστικό compaction με προαιρετικό focus string
Τρέξε /context detail πριν και μετά από αλλαγές στη ρύθμιση. Έτσι μετράς αν οι βελτιστοποιήσεις σου όντως έπιασαν τόπο.
Η μάχη για το πιο οικονομικό μοντέλο του OpenClaw: ποια budget LLMs αντέχουν πραγματικά στην agentic εργασία
Εδώ τα περισσότερα guides κάνουν λάθος. Σου δείχνουν έναν πίνακα τιμών, δείχνουν τη φθηνότερη γραμμή και τελειώνουν εκεί. Τα benchmarks δεν προβλέπουν πραγματική agentic απόδοση — κάτι που η κοινότητα έχει επισημάνει δυνατά και επανειλημμένα. Όπως το έθεσε ένας χρήστης: «τα benchmarks δεν βοηθούν να καταλάβεις ποιο δουλεύει καλύτερα για agentic AI».
Το κρίσιμο insight: το πιο φθηνό μοντέλο δεν είναι πάντα το πιο φθηνό αποτέλεσμα. Ένα μοντέλο που αποτυγχάνει και ξαναδοκιμάζει τέσσερις φορές κοστίζει περισσότερο από ένα μεσαίας κατηγορίας μοντέλο που πετυχαίνει με την πρώτη. Σε production agent systems, υπολόγιζε 5–10% retry rate — και αν πέντε LLM calls είναι αλυσιδωμένα και το βήμα τέσσερα αποτύχει, ένα naive retry ξανατρέχει και τα πέντε βήματα.
Να ο πίνακας ικανοτήτων μου, με “Real Agentic Score” βασισμένο σε πραγματικές αναφορές χρηστών και όχι σε συνθετικά benchmarks:
| Μοντέλο | Input $/1M | Output $/1M | Αξιοπιστία tool-calling | Λογισμός πολλών βημάτων | Real Agentic Score (1–5) | Ιδανικό για |
|---|---|---|---|---|---|---|
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | Μικτή — περιστασιακοί κύκλοι | Βασικό | ⭐2.5 | Heartbeats, απλά lookups |
| GPT-OSS-120B | $0.04 | $0.19 | Επαρκής | Επαρκής | ⭐3.0 | Budget πειραματισμός, εργασίες με ανάγκη ταχύτητας |
| DeepSeek V3.2 | $0.26 | $0.38 | Ασταθές (6 ανοιχτά issues) | Καλό | ⭐3.0 | Έμφαση στον λογισμό, ελάχιστο tool calling |
| Kimi K2.5 | $0.38 | $1.72 | Καλό (μέσω :exacto) | Επαρκές | ⭐3.5 | Απλό έως μεσαίο coding |
| MiniMax M2.5 / M2.7 | $0.28 | $1.10 | Καλό | Καλό | ⭐4.0 | Καθημερινό coding γενικής χρήσης |
| Claude Haiku 4.5 | $1.00 | $5.00 | Εξαιρετική | Καλό | ⭐4.5 | Αξιόπιστο fallback μεσαίας κατηγορίας |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Εξαιρετική | Εξαιρετική | ⭐5.0 | Πολύπλοκες εργασίες πολλών βημάτων |
| Claude Opus 4.5/4.6 | $5.00 | $15.00 | Εξαιρετική | Εξαιρετική | ⭐5.0 | Μόνο για τα πιο δύσκολα προβλήματα |
Προειδοποίηση για DeepSeek και Gemini Flash στο tool calling
Το DeepSeek V3.2 δείχνει εξαιρετικό στα χαρτιά — 72–74% στο SWE-Bench, 11–36x φθηνότερο από το Sonnet. Στην πράξη, έξι ξεχωριστά GitHub issues σε Cline, Roo Code, Continue και NVIDIA NIM καταγράφουν σπασμένη συμπεριφορά στο tool-calling. Η καταληκτική κρίση της Composio: «το DeepSeek V3.2 έφτιαξε κομμάτια της εφαρμογής αλλά σκάλωσε στην εκτέλεση, στην ταχύτητα και στην αξιοπιστία.» Η μονοφραστική άποψη του Zvi Mowshowitz: «okay and cheap, but.»
Το Gemini 2.5 Flash έχει παρόμοιο κενό. Ένα thread στο Google AI Developers Forum με τίτλο «Very frustrating experience with Gemini 2.5 function calling performance» ξεκινά με τη φράση: «η συμπεριφορά function calling των μοντέλων Gemini έχει γίνει εντελώς αναξιόπιστη και απρόβλεπτη.»
Το OpenRouter επισήμανε μια κρίσιμη λεπτομέρεια: «η τάση ενός μοντέλου να καλεί εργαλεία και η ακρίβεια αυτών των κλήσεων μπορεί να διαφέρει δραματικά μεταξύ hosts με τα ίδια weights.» Αν δρομολογείς φθηνά μοντέλα μέσω OpenRouter, ψάξε για το tag :exacto — μια σιωπηλή αλλαγή provider μπορεί να μετατρέψει ένα αξιόπιστο φθηνό μοντέλο σε ακριβό retry loop μέσα σε μια νύχτα.
Πότε να χρησιμοποιείς κάθε μοντέλο
- Gemini Flash-Lite: Heartbeats, keep-alive pings, απλό Q&A. Ποτέ για πολυβήματο tool calling.
- MiniMax M2.5/M2.7: Η καθημερινή σου επιλογή για γενικές εργασίες κώδικα. SWE-Pro 56.22, Terminal-Bench 2 57,0% με κλάσμα της τιμής του Sonnet.
- Claude Haiku 4.5: Το αξιόπιστο fallback όταν τα φθηνά μοντέλα «πνίγονται» στα tool calls. Εξαιρετική αξιοπιστία tool-calling με ~3x χαμηλότερο κόστος από το Sonnet.
- Claude Sonnet 4.6: Πολύπλοκη agentic εργασία πολλών βημάτων. Εδώ παίρνεις πραγματική αξία για τα χρήματά σου.
- Claude Opus: Κράτησέ το για τα πιο δύσκολα προβλήματα. Μην το αφήνεις να είναι η προεπιλογή σου για τίποτα.
(Οι τιμές των μοντέλων αλλάζουν συχνά — επιβεβαίωσε τα τρέχοντα rates στο OpenRouter ή στις σελίδες των providers πριν «κλειδώσεις» κάποιο config.)
Οι κρυφές διαρροές tokens που παραλείπουν οι περισσότεροι οδηγοί
Χρήστες σε forums αναφέρουν ότι η απενεργοποίηση συγκεκριμένων λειτουργιών μειώνει δραστικά το κόστος, αλλά κανένας οδηγός που βρήκα δεν δίνει ενιαίο checklist όλων των κρυφών διαρροών μαζί με το πραγματικό token impact. Η πλήρης ανάλυση:
| Κρυφή διαρροή | Κόστος σε tokens ανά εμφάνιση | Πώς να το διορθώσεις | Config key |
|---|---|---|---|
| Default heartbeat στο Opus | ~100.000 tokens/run χωρίς απομόνωση | Haiku override + isolatedSession | heartbeat.model, heartbeat.isolatedSession: true |
| Δημιουργία sub-agent | ~20.000 tokens ανά spawn πριν γίνει οποιαδήποτε δουλειά | Δρομολόγηση sub-agents στο Haiku | subagents.model |
| Φόρτωση πλήρους context codebase | ~3.000–15.000 tokens ανά auto-explore | .clawignore για node_modules, dist, lockfiles | .clawrules + .clawignore |
| Memory auto-summarize | ~500–2.000 tokens/session | Απενεργοποίηση ή μείωση συχνότητας | memory: false ή memory.max_context_tokens |
| Συσσώρευση ιστορικού συνομιλίας | ~500+ tokens/turn (σωρευτικά) | Νέες συνεδρίες για άσχετες εργασίες | /clear discipline |
| Overhead εργαλείων MCP server | ~7.000 tokens για 4 servers· 50.000+ για 5+ | Κράτα το MCP minimal | Αφαίρεσε αχρησιμοποίητα MCPs |
| Εκκίνηση skill/plugin | 200–1.000 tokens ανά φορτωμένο skill | Απενεργοποίησε αχρησιμοποίητα skills | skills.entries.<name>.enabled: false |
| Agent Teams (plan mode) | ~7x το standard session cost | Μόνο για πραγματικά παράλληλη εργασία | Προτίμησε σειριακά |
Η διαρροή από τα heartbeats αξίζει ξεχωριστή αναφορά. Από προεπιλογή, τα heartbeats χτυπούν στο βασικό μοντέλο (Opus) κάθε 30 λεπτά. Βάζοντας isolatedSession: true ρίχνεις αυτό το κόστος από ~100.000 tokens ανά run στα 2.000–5.000 tokens — μείωση 95–98% μόνο σε αυτή την κατηγορία.
Τρία γρήγορα κέρδη που εξοικονομούν τα περισσότερα tokens σε λιγότερο από δύο λεπτά
Και τα τρία είναι χωρίς ρίσκο και παίρνουν λιγότερο από δύο λεπτά:
-
/clearανάμεσα σε άσχετες εργασίες (5 δευτερόλεπτα). Αυτό είναι το νούμερο ένα token saver. Η κοινή γνώμη στα forums το τοποθετεί στο 50–70% μείωση μόνο και μόνο επειδή καθαρίζεις το session history πριν ξεκινήσεις νέα δουλειά. Θυμήσου εκείνο το bucket Messages με 185k tokens από το /context dump; Το/clearτο μηδενίζει. -
/model haiku-4.5για τις βαριές, απλές δουλειές (10 δευτερόλεπτα). Το τακτικό switching μοντέλου δίνει 60–80% μείωση κόστους σε ρουτίνες εργασίες. Το Haiku χειρίζεται άψογα τα πιο απλά coding tasks, τα file lookups και τα commit messages. -
Μίκρυνε το
.clawrulesσε <200 γραμμές + πρόσθεσε.clawignore(90 δευτερόλεπτα). Το rules file φορτώνει σε κάθε μήνυμα. Στις 200 γραμμές είναι περίπου ~1.500–2.000 tokens ανά turn· στις 1.000 γραμμές είναι 8.000–10.000 tokens που επιβαρύνουν μόνιμα κάθε request. Σε συνδυασμό με ένα.clawignoreπου αποκλείειnode_modules/,dist/, lockfiles και generated code, ένας developer ισχυρίζεται 92% μείωση tokens μόνο από αυτή την πειθαρχία.
Βήμα-βήμα: τρία έτοιμα configs που μπορείς να αντιγράψεις για να κόψεις δραστικά τη χρήση tokens στο OpenClaw

Ακολουθούν τρεις πλήρεις, σχολιασμένες ρυθμίσεις openclaw.json — από το «μόλις ξεκίνα» μέχρι το «πλήρης στοίβα βελτιστοποίησης». Κάθε μία περιλαμβάνει inline σχόλια και εκτιμήσεις μηνιαίου κόστους.
Πριν ξεκινήσεις:
- Δυσκολία: Αρχάριος (Config A) → Μεσαίο επίπεδο (Config B) → Προχωρημένος (Config C)
- Χρόνος που χρειάζεται: ~5 λεπτά για το Config A, ~15 λεπτά για το Config C
- Τι θα χρειαστείς: εγκατεστημένο OpenClaw, έναν text editor, πρόσβαση στο
~/.openclaw/openclaw.json
Config A: Αρχάριος — απλώς εξοικονόμησε χρήματα
Πέντε γραμμές. Μηδενική πολυπλοκότητα. Αντικαθιστά το default model από Opus σε Sonnet, απενεργοποιεί το memory overhead και απομονώνει τα heartbeats στο Haiku.
// ~/.openclaw/openclaw.json
{
"agents": {
"defaults": {
"model": { "primary": "anthropic/claude-sonnet-4-6" }, // ήταν Opus — άμεση εξοικονόμηση 3-5x
"heartbeat": {
"every": "55m", // ευθυγράμμιση με TTL 1h για μέγιστα cache hits
"model": "anthropic/claude-haiku-4-5", // Haiku για pings, όχι Opus
"isolatedSession": true // ~100k → 2-5k tokens ανά run
}
}
},
"memory": { "enabled": false } // εξοικονομεί ~500-2k tokens/session
}
Τι πρέπει να δεις μετά την εφαρμογή: Τρέξε /status πριν και μετά. Το κόστος ανά request πρέπει να πέσει αισθητά και τα heartbeat entries στο OpenRouter Activity page να δείχνουν Haiku αντί για Opus.
| Επίπεδο χρήσης | Προεπιλογή (Opus) | Config A (Sonnet + Haiku heartbeats) | Εξοικονόμηση |
|---|---|---|---|
| Ελαφρύ (~10 q/day) | ~$100 | ~$35 | 65% |
| Μέτριο (~50 q/day) | ~$500 | ~$250 | 50% |
| Βαρύ (~200 q/day) | ~$1,750 | ~$900 | 49% |
Config B: Μεσαίο επίπεδο — έξυπνη δρομολόγηση τριών επιπέδων
Primary Sonnet για αληθινή δουλειά. Haiku για sub-agents και compaction. Gemini Flash-Lite ως budget fallback όταν το Claude είναι throttled. Οι αλυσίδες fallback χειρίζονται αυτόματα τα provider outages.
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"anthropic/claude-haiku-4-5", // αν το Sonnet είναι throttled
"google/gemini-2.5-flash-lite" // εξαιρετικά φθηνή τελευταία λύση
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m", // 55min < TTL 1h = cache hits
"model": "google/gemini-2.5-flash-lite", // ψιλά για κάθε ping
"isolatedSession": true,
"lightContext": true // ελάχιστο context στα heartbeat calls
},
"subagents": {
"maxConcurrent": 4, // από το default 8
"model": "anthropic/claude-haiku-4-5" // οι sub-agents δεν χρειάζονται Sonnet
},
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5", // summaries μέσω Haiku
"memoryFlush": { "enabled": true }
}
}
}
}
Αναμενόμενο αποτέλεσμα: Τα sub-agent entries στα logs σου πρέπει τώρα να δείχνουν τιμολόγηση Haiku. Τα heartbeats πρέπει να είναι σχεδόν μηδενικού κόστους. Η αλυσίδα fallback σημαίνει ότι ένα outage του Claude δεν μπλοκάρει τη συνεδρία σου — απλώς υποβαθμίζεται ομαλά στο Gemini.
| Επίπεδο χρήσης | Προεπιλογή | Config B | Εξοικονόμηση |
|---|---|---|---|
| Ελαφρύ | ~$100 | ~$20 | 80% |
| Μέτριο | ~$500 | ~$150 | 70% |
| Βαρύ | ~$1,750 | ~$500 | 71% |
Config C: Power user — πλήρης στοίβα βελτιστοποίησης
Ανάθεση μοντέλου ανά sub-agent, context compaction καρφωμένο στο Haiku, δρομολόγηση vision στο Gemini Flash, αυστηρό .clawrules + .clawignore, απενεργοποίηση αχρησιμοποίητων skills. Αυτό είναι το config που σε φέρνει στο εύρος εξοικονόμησης 85–90%.
{
"agents": {
"defaults": {
"workspace": "~/clawd",
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"openrouter/anthropic/claude-sonnet-4-6", // άλλος provider ως backup
"minimax/minimax-m2-7", // φθηνό καθημερινό fallback
"anthropic/claude-haiku-4-5" // τελευταία λύση
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
},
"minimax/minimax-m2-7": {
"params": { "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m",
"model": "google/gemini-2.5-flash-lite",
"isolatedSession": true,
"lightContext": true,
"activeHours": "09:00-19:00" // καθόλου heartbeats τη νύχτα
},
"subagents": {
"maxConcurrent": 4,
"model": "anthropic/claude-haiku-4-5"
},
"contextPruning": { "mode": "cache-ttl", "ttl": "1h" },
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5",
"identifierPolicy": "strict",
"memoryFlush": { "enabled": true }
},
"bootstrapMaxChars": 12000, // από το default 20000 κάτω
"imageModel": "google/gemini-3-flash" // vision tasks μέσω φθηνού μοντέλου
}
},
"memory": { "enabled": true, "max_context_tokens": 800 }, // ελάχιστη μνήμη
"skills": {
"entries": {
"web-search": { "enabled": false },
"image-generation": { "enabled": false },
"audio-transcribe": { "enabled": false }
}
}
}
Παράδειγμα override ανά subagent — επικόλλησέ το στο ~/.openclaw/agents/lint-runner/SOUL.md:
---
name: lint-runner
description: Εκτελεί ελέγχους lint/format και εφαρμόζει απλές διορθώσεις
tools: [Bash, Read, Edit]
model: anthropic/claude-haiku-4-5
---
Ελάχιστο βιώσιμο .clawignore — αυτό και μόνο κόβει τυπικά bootstraps από 150k χαρακτήρες προς τα 30–50k:
node_modules/
dist/
build/
.next/
coverage/
.venv/
vendor/
*.lock
package-lock.json
yarn.lock
pnpm-lock.yaml
*.min.js
*.min.css
**/__snapshots__/
**/*.snap
| Επίπεδο χρήσης | Προεπιλογή | Config C | Εξοικονόμηση |
|---|---|---|---|
| Ελαφρύ | ~$100 | ~$12 | 88% |
| Μέτριο | ~$500 | ~$90 | 82% |
| Βαρύ | ~$1,750 | ~$220 | 87% |
Αυτοί οι αριθμοί ευθυγραμμίζονται με δύο ανεξάρτητες αναφορές πραγματικών χρηστών: την καταγεγραμμένη περίπτωση του Praney Behl από $600–750/μήνα → $3–4/ημέρα (μείωση 90%) και τα case studies του LaoZhang που δείχνουν $943 → $347 (63%), $1.750 → $1.000 (64%), $200 → $70 (65%) με μερική βελτιστοποίηση.
Χρησιμοποιώντας την εντολή /model για να ελέγχεις τη χρήση tokens στο OpenClaw on-the-fly
Η εντολή /model αλλάζει το ενεργό μοντέλο για τον επόμενο γύρο, ενώ διατηρεί το conversation context σου — χωρίς reset, χωρίς χαμένο ιστορικό. Αυτή είναι η καθημερινή συνήθεια που συσσωρεύει εξοικονόμηση με τον χρόνο.
Πρακτική ροή εργασίας:
- Δουλεύεις σε ένα δύσκολο refactor πολλών αρχείων; Μείνε στο Sonnet.
- Γρήγορη ερώτηση τύπου «τι κάνει αυτό το regex;»;
/model haiku, ρώτα, και μετά/model sonnetγια επιστροφή. - Commit message ή γυάλισμα εγγράφου;
/model flash-lite, και τελείωσες.
Μπορείς να στήσεις aliases στο openclaw.json κάτω από commands.aliases για να χαρτογραφήσεις σύντομα ονόματα (haiku, sonnet, opus, flash) σε πλήρη provider strings. Γλιτώνεις μερικά πληκτρολογήματα σε κάθε αλλαγή.
Ο λογαριασμός: 50 ερωτήματα/ημέρα στο Sonnet είναι περίπου 3 δολάρια/ημέρα. Τα ίδια 50 ερωτήματα μοιρασμένα 70/20/10 σε Haiku/Sonnet/Opus είναι περίπου 1,10 δολάρια/ημέρα. Σε έναν μήνα, αυτό γίνεται $90 → $33 — 63% φθηνότερα χωρίς να αλλάξεις εργαλεία, μόνο συνήθειες.
Bonus: Παρακολούθηση τιμών μοντέλων OpenClaw ανά provider με το Thunderbit
Παρακολούθησε τις τιμές μοντέλων ανά provider με AI Get Started Free
Με τόσα πολλά μοντέλα και providers — OpenRouter, direct Anthropic API, Google AI Studio, DeepSeek, MiniMax — οι τιμές αλλάζουν συνεχώς. Η Anthropic έκοψε ξαφνικά την τιμή του output στο Opus κατά ~67%. Η Google μείωσε τα Gemini free-tier limits 50–80% τον Δεκέμβριο του 2025. Το να κρατάς ένα στατικό spreadsheet τιμών ενημερωμένο χειροκίνητα είναι χαμένη μάχη.
Το Thunderbit το λύνει χωρίς κανένα scraping code. Είναι ένα AI web scraper Chrome extension φτιαγμένο ακριβώς για αυτού του είδους τη δομημένη εξαγωγή δεδομένων.
Η ροή που χρησιμοποιώ:
- Άνοιξε τη σελίδα μοντέλων του OpenRouter στο Chrome και πάτα το "AI Suggest Fields" του Thunderbit. Διαβάζει τη σελίδα και προτείνει columns — όνομα μοντέλου, τιμή εισόδου, τιμή εξόδου, context window, provider.
- Πάτα Scrape, και μετά κάνε export κατευθείαν στο Google Sheets.
- Στήσε scheduled scrape σε απλά αγγλικά — «κάθε Δευτέρα στις 9 π.μ., ξανακάνε scrape τη λίστα μοντέλων του OpenRouter» — και θα τρέχει αυτόματα στο cloud.
Από εκεί και πέρα, ο προσωπικός σου tracker τιμών ενημερώνεται μόνος του. Κάθε μοντέλο που ξαφνικά φθηναίνει κατά 30% — ή κάθε provider που αποκτά Exacto tag — θα εμφανίζεται στο spreadsheet σου το πρωί της Δευτέρας χωρίς να κουνήσεις το δάχτυλο. Έχουμε γράψει περισσότερα για AI data extraction για επιχειρήσεις στο blog μας.
Συγκρίνεις τιμές ανάμεσα σε direct provider pages (Anthropic, Google, DeepSeek); Το subpage scraping του Thunderbit ακολουθεί κάθε link μοντέλου στη σελίδα λεπτομερειών του και τραβά τα rates ανά provider — χρήσιμο όταν θέλεις να δεις αν το να δρομολογήσεις το Kimi K2.5 μέσω OpenRouter είναι φθηνότερο από το να πας απευθείας μέσω NVIDIA Build. Δες το Thunderbit pricing για δωρεάν tier και λεπτομέρειες πλάνων.
Βασικά συμπεράσματα για τη μείωση της χρήσης tokens του OpenClaw
Το πλαίσιο: Κατανόησε → Παρακολούθησε → Δρομολόγησε → Βελτιστοποίησε.
Οι κινήσεις με τον μεγαλύτερο αντίκτυπο, σε σειρά:
- Μην αφήνεις το Opus ως προεπιλογή. Άλλαξε το primary model σε Sonnet ή MiniMax M2.7. Μόνο αυτό ρίχνει το κόστος 3–5x.
- Απομόνωσε τα heartbeats. Βάλε
isolatedSession: trueκαι δρομολόγησε τα heartbeats στο Gemini Flash-Lite. Αυτό μετατρέπει μια διαρροή ~100k tokens σε ~2–5k. - Δρομολόγησε τα sub-agents στο Haiku. Κάθε spawn φορτώνει ~20k tokens context πριν κάνει οποιαδήποτε δουλειά. Μην το αφήνεις να συμβαίνει στο Opus.
- Χρησιμοποίησε το
/clearθρησκευτικά. Δωρεάν, παίρνει 5 δευτερόλεπτα και η κοινή εμπειρία λέει ότι σώζει περισσότερο από κάθε άλλη μεμονωμένη κίνηση. - Πρόσθεσε
.clawignore. Ο αποκλεισμός τωνnode_modules, lockfiles και build artifacts κόβει δραματικά το bootstrap context. - Παρακολούθησε με
/context detailπριν και μετά τις αλλαγές. Αν δεν το μετράς, δεν μπορείς να το βελτιώσεις.
Το πιο οικονομικό μοντέλο εξαρτάται από την εργασία. Gemini Flash-Lite για heartbeats. MiniMax M2.7 για καθημερινό coding. Haiku για αξιόπιστο tool calling. Sonnet για σύνθετη εργασία πολλών βημάτων. Opus μόνο για τα πραγματικά πιο δύσκολα προβλήματα — και τίποτα άλλο.
Οι περισσότεροι αναγνώστες μπορούν να δουν 50–70% εξοικονόμηση σε ένα μόνο απόγευμα με το Config A ή B. Η πλήρης μείωση 85–90% απαιτεί να στοιβάξεις όλα τα παραπάνω — model routing, διόρθωση κρυφών διαρροών, .clawignore, πειθαρχία στα sessions — αλλά είναι εφικτή και διατηρείται.
Συχνές ερωτήσεις
1. Πόσο κοστίζει το OpenClaw τον μήνα;
Εξαρτάται απόλυτα από τη ρύθμιση, τον όγκο χρήσης και τις επιλογές μοντέλων. Οι ελαφριοί χρήστες (~10 ερωτήματα/ημέρα) συνήθως ξοδεύουν $5–30/μήνα με βελτιστοποίηση, ή $100+ με τις προεπιλογές. Οι μέτριοι χρήστες (~50 ερωτήματα/ημέρα) κινούνται περίπου στα $90–400/μήνα. Οι βαρείς χρήστες μπορούν να φτάσουν τα $600–2.000+/μήνα με τις προεπιλογές — μία καταγεγραμμένη ακραία περίπτωση έφτασε τα $5.623 σε έναν μόνο μήνα. Η εσωτερική τηλεμετρία της Anthropic δείχνει median περίπου $13/developer/active-day.
2. Ποιο είναι το πιο οικονομικό μοντέλο του OpenClaw που εξακολουθεί να δουλεύει καλά για coding;
Το MiniMax M2.5/M2.7 είναι η καλύτερη καθημερινή επιλογή γενικής χρήσης — καλή αξιοπιστία στο tool-calling, SWE-Pro 56.22, με περίπου $0.28/$1.10 ανά εκατομμύριο tokens. Για heartbeats και απλά lookups, το Gemini 2.5 Flash-Lite στα $0.10/$0.40 είναι εξαιρετικά δύσκολο να ξεπεραστεί. Το Claude Haiku 4.5 στα $1/$5 είναι το αξιόπιστο μεσαίο fallback όταν χρειάζεσαι άριστο tool-calling χωρίς τις τιμές του Sonnet.
3. Μπορώ να χρησιμοποιήσω μοντέλα free-tier με το OpenClaw;
Τεχνικά ναι. Το GPT-OSS-120B είναι δωρεάν στο tag :free του OpenRouter και στο NVIDIA Build. Το Gemini Flash-Lite έχει free tier (15 RPM, 1.000 requests/ημέρα). Το DeepSeek δίνει 5M δωρεάν tokens με την εγγραφή. Αλλά τα free tiers έχουν επιθετικά rate limits, πιο αργές ταχύτητες και αναξιόπιστη διαθεσιμότητα. Τα φθηνά paid models — μερικά λεπτά ανά εκατομμύριο tokens — είναι πολύ πιο αξιόπιστα για καθημερινή χρήση.
4. Χάνω το context αν αλλάζω μοντέλο στη μέση της συνομιλίας με το /model;
Όχι. Το /model διατηρεί ολόκληρο το session context σου — ο επόμενος γύρος δρομολογείται στο νέο μοντέλο με πλήρες ιστορικό ανέπαφο. Αυτό επιβεβαιώνεται στην τεκμηρίωση concepts του OpenClaw και λειτουργεί το ίδιο και στο Claude Code. Μπορείς άνετα να πηγαίνεις από Haiku για γρήγορες ερωτήσεις σε Sonnet για σύνθετη δουλειά χωρίς να χάνεις τίποτα.
5. Ποιος είναι ο πιο γρήγορος τρόπος να μειώσω σήμερα τον λογαριασμό μου στο OpenClaw;
Πληκτρολόγησε /clear ανάμεσα σε άσχετες εργασίες. Είναι δωρεάν, παίρνει πέντε δευτερόλεπτα και σβήνει το ιστορικό της συνομιλίας που ξαναστέλνεται σε κάθε API call. Μία πραγματική συνεδρία έδειξε 185.000 tokens συσσωρευμένου message history — όλο αυτό μεταδιδόταν και χρεωνόταν ξανά σε κάθε γύρο. Το να το καθαρίζεις πριν ξεκινήσεις νέα δουλειά είναι η συνήθεια με τη μεγαλύτερη απόδοση.
Δοκίμασε το Thunderbit για AI Web Scraping Get Started Free




