

Η βελτιστοποίηση των list queries στο Apollo δεν είναι απλώς μια τεχνική άσκηση — είναι δεξιότητα επιβίωσης για όποιον στηρίζεται σε δεδομένα ειδήσεων σε πραγματικό χρόνο, σε αυτοματοποιημένη εξαγωγή ειδήσεων ή σε γρήγορες ροές εργασίας πωλήσεων και operations. Έχω δει από κοντά πώς ένα αργό list query μπορεί να μετατρέψει ένα καλοδουλεμένο dashboard σε σημείο συμφόρησης, αφήνοντας τις ομάδες πωλήσεων να κοιτάνε loaders που γυρίζουν και τα στελέχη operations να ψάχνουν λύσεις σε spreadsheets. Σε έναν κόσμο όπου το 60% του χρόνου των sales reps χάνεται ήδη σε μη πωλησιακές εργασίες, κάθε χιλιοστό του δευτερολέπτου μετράει.
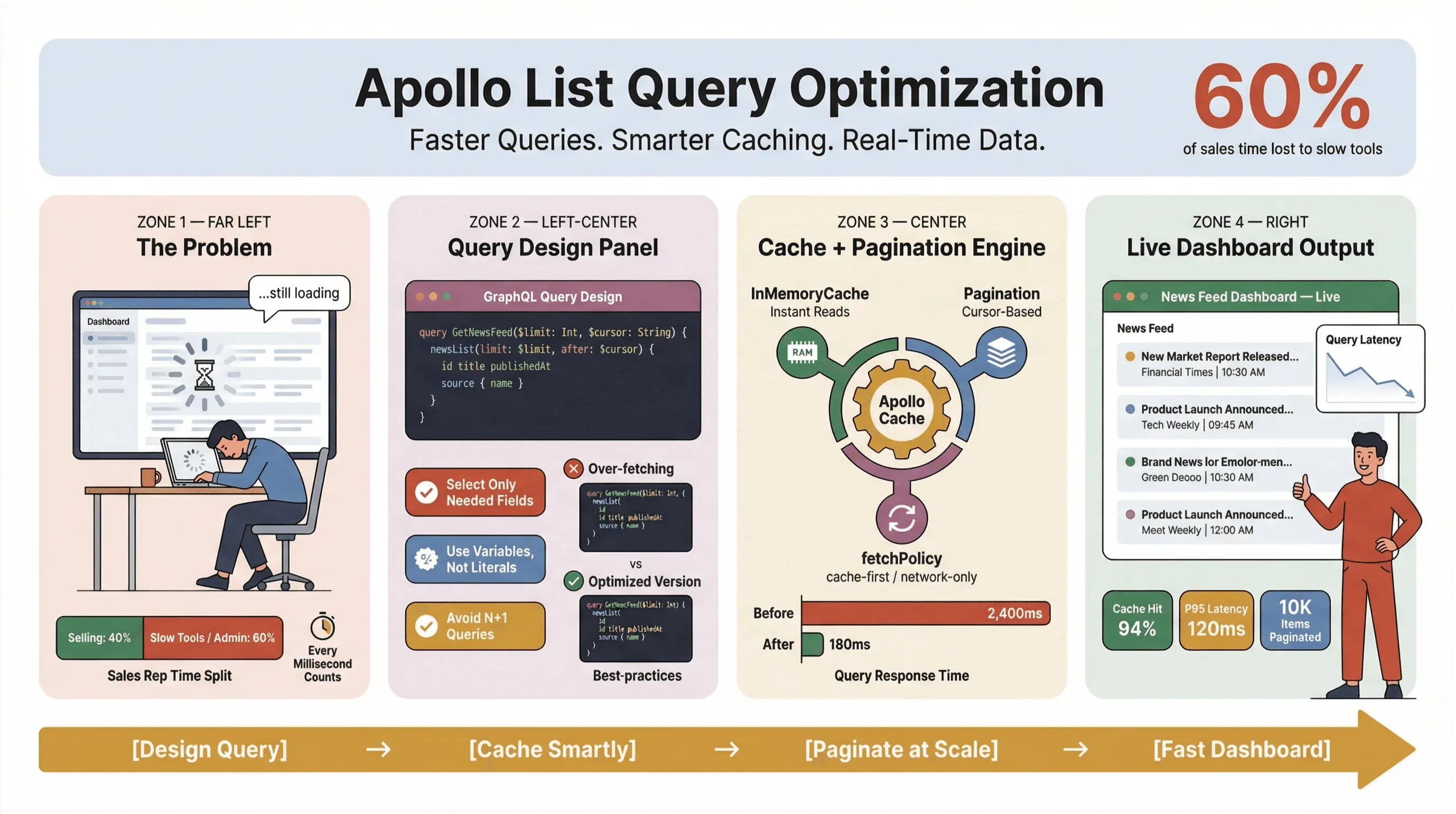
Λοιπόν, πώς κρατάς τα Apollo Client list queries γρήγορα, αξιόπιστα και συνεπή σε κλίμακα — ειδικά όταν κάνεις scraping ειδήσεων, παρακολουθείς leads ή τροφοδοτείς κρίσιμα dashboards; Σε αυτόν τον οδηγό, θα περάσω από πρακτικές που έχουν αντέξει στην παραγωγή: σχεδιασμό queries, caching, pagination και ενσωμάτωση no-code εργαλείων όπως το Thunderbit για να αυτοματοποιήσεις τη βαριά δουλειά της εξαγωγής ειδήσεων.
--- Είτε είσαι developer, είτε product manager, είτε απλώς το άτομο που όλοι κατηγορούν όταν το dashboard αργεί, αυτό είναι το playbook σου για την απόδοση των Apollo GraphQL λιστών.
Δοκιμάστε το Thunderbit για αυτοματοποιημένη εξαγωγή ειδήσεων
Γιατί να βελτιστοποιήσετε τα Apollo list queries; (apollo client list performance, optimize apollo list queries)
Ας το πούμε απλά: κανείς δεν θέλει να περιμένει να φορτώσουν οι τίτλοι ειδήσεων ή τα sales leads. Σε επιχειρησιακά περιβάλλοντα — ειδικά σε όσα βασίζονται σε αυτοματοποιημένη εξαγωγή ειδήσεων ή δεδομένα σε πραγματικό χρόνο — τα αργά Apollo list queries δεν είναι απλώς ενοχλητικά· κοστίζουν χρήματα, καθυστερούν αποφάσεις και σπρώχνουν τους ανθρώπους πίσω στη χειροκίνητη δουλειά. Η επαναλαμβανόμενη έρευνα του Slack Workforce Lab δείχνει σταθερά ότι οι εργαζόμενοι γραφείου περνούν περίπου το ένα τρίτο — και σε πιο πρόσφατες αναφορές κοντά στο 40% — της μέρας τους σε χαμηλής αξίας, επαναλαμβανόμενες εργασίες, συχνά επειδή τα εργαλεία τους σπάνε τη ροή σε αργές επιφάνειες.
Να τι συμβαίνει όταν τα list queries δεν είναι βελτιστοποιημένα:
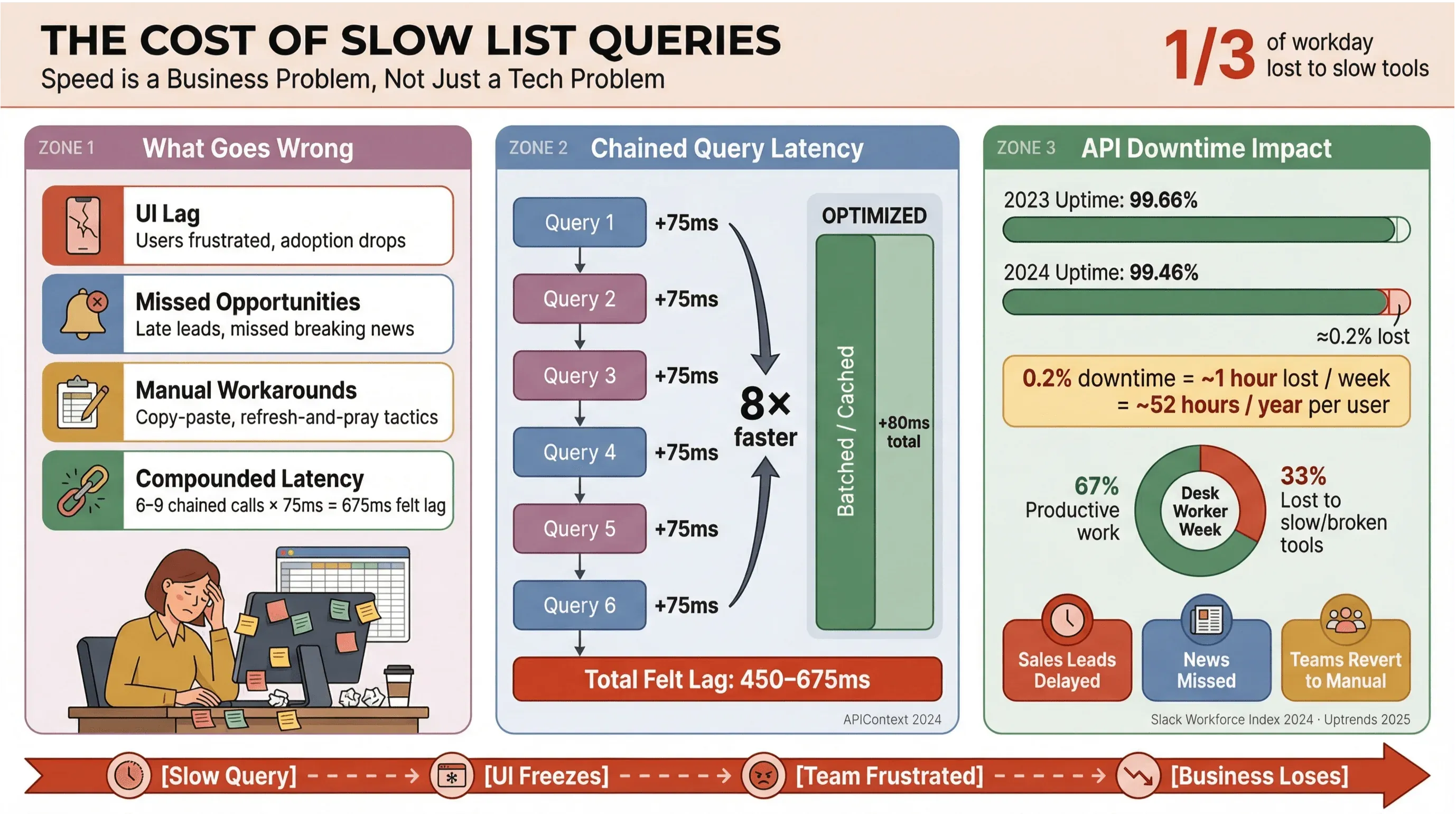
- Καθυστέρηση στο UI: Οι χρήστες βλέπουν lag, κάτι που φέρνει εκνευρισμό και ρίχνει την υιοθέτηση.
- Χαμένες ευκαιρίες: Στις πωλήσεις ή στην παρακολούθηση ειδήσεων, ακόμα και λίγα δευτερόλεπτα καθυστέρησης μπορεί να σημαίνουν χαμένο hot lead ή breaking news.
- Χειροκίνητες λύσεις ανάγκης: Οι ομάδες γυρνούν στο copy-paste, στα spreadsheets ή στο «refresh και προσευχή».
- Συσσωρευμένη καθυστέρηση: Κάθε αργό API call προστίθεται — αν η ροή σας ενεργοποιεί 6–9 εξαρτώμενα queries, μια μέτρια καθυστέρηση 75ms ανά call μπορεί να φουσκώσει σε 450–675ms αντιληπτό lag (APIContext).
Και δεν είναι μόνο θέμα ταχύτητας. Η διακοπή λειτουργίας API αυξάνεται, με το μέσο uptime να πέφτει από 99.66% σε 99.46% μέσα σε μόλις έναν χρόνο — κάτι που μεταφράζεται σε σχεδόν μία ώρα χαμένης παραγωγικότητας την εβδομάδα για εφαρμογές με πολλά list δεδομένα. Όταν η επιχείρησή σας εξαρτάται από δεδομένα ειδήσεων σε πραγματικό χρόνο, αυτό είναι ρίσκο που δεν μπορείς να αγνοήσεις.
Επιλογή σωστής δομής δεδομένων και πεδίων (apollo graphql list best practices)
Ένα από τα πιο συνηθισμένα λάθη που βλέπω (και ναι, το έχω κάνει κι εγώ) είναι να αντιμετωπίζεται κάθε list query σαν detail query. Στο GraphQL έχεις τη δυνατότητα να τραβήξεις ακριβώς ό,τι χρειάζεσαι — οπότε αξιοποίησέ το. Η υπερβολική ανάκτηση δεδομένων είναι εχθρός της απόδοσης, ειδικά σε εργαλεία scraping ειδήσεων και dashboards σε πραγματικό χρόνο.
Προσαρμογή πεδίων για αυτοματοποιημένη εξαγωγή ειδήσεων
Ας πούμε ότι χτίζετε ένα news feed. Χρειάζεστε πραγματικά ολόκληρο το άρθρο, όλα τα tags, τα σχόλια και τα bios των συντακτών στο list query σας; Πιθανότατα όχι. Δείτε τη διαφορά:
Αποδοτικό List Query:
query NewsFeed($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
cursor
node {
id
title
url
sourceName
publishedAt
}
}
pageInfo { endCursor hasNextPage }
}
}
Ανεπαρκές List Query (Μην το κάνετε αυτό):
query NewsFeedTooHeavy($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
node {
id title url publishedAt
fullText
summary
entities { ... }
relatedArticles { ... }
}
}
}
}
Το πρώτο query είναι λιτό και γρήγορο — ιδανικό για ταξινόμηση, φιλτράρισμα και απόδοση γραμμών. Το δεύτερο; Είναι detail query μεταμφιεσμένο, τραβάει τεράστια payloads και επιβραδύνει τα πάντα (GraphQL spec, Apollo best practices).
Χρήσιμη συμβουλή: Χρησιμοποίησε μια προσέγγιση δύο επιπέδων — τραβά μόνο ελαφριά πεδία στη λίστα σου και φόρτωσε βαριές λεπτομέρειες (όπως πλήρες κείμενο ή NLP enrichment) μόνο όταν ο χρήστης ανοίγει ένα item ή περνά τον δείκτη πάνω του.
Αξιοποιώντας το Apollo Client Cache για ταχύτερα queries (apollo client list performance)
Το Apollo Client cache είναι ο πιο δυνατός μοχλός που έχεις για την απόδοση των list queries. Όταν ρυθμιστεί σωστά, σου επιτρέπει:
- Να εξυπηρετείς επαναλαμβανόμενα queries αμέσως (χωρίς network round-trips)
- Να μειώνεις το φορτίο στον server και το κόστος των API
- Να έχεις ομαλή πλοήγηση πίσω/μπροστά και αλλαγές φίλτρων
Αλλά το caching δεν είναι μαγικό — θέλει σωστή ρύθμιση και πειθαρχία.
Ρύθμιση αποτελεσματικών cache policies
Το Apollo υποστηρίζει αρκετές fetch policies:
| Πολιτική | Τι κάνει | Καλύτερη χρήση για λίστες ειδήσεων |
|---|---|---|
| cache-first | Διαβάζει από την cache και, αν λείπει κάτι, κάνει fetch από το δίκτυο | Επανεπίσκεψη λιστών, αλλαγή φίλτρων, πλοήγηση πίσω/μπροστά |
| network-only | Κάνει πάντα fetch από το δίκτυο | Χειροκίνητο refresh, «τελευταίοι τίτλοι» |
| cache-and-network | Επιστρέφει πρώτα την cache και μετά ενημερώνει με το network response | Γρήγορο πρώτο render + ενημέρωση στο παρασκήνιο (ιδανικό για news feeds) |
| no-cache | Κάνει πάντα fetch, δεν αποθηκεύει ποτέ στην cache | Μοναδικά ευαίσθητα queries (σπάνιο για λίστες) |
Για δεδομένα ειδήσεων σε πραγματικό χρόνο, μου αρέσει το cache-and-network — δίνει αμέσως αποτελέσματα στους χρήστες και μετά ενημερώνεται στο παρασκήνιο. Απλώς πρόσεξε το UI flicker αν τα δεδομένα σου αναδιατάσσονται κατά το refresh (GitHub issue).
Συμβουλές ρύθμισης cache:
- Χρησιμοποιήστε σταθερά IDs (
idή_id) για κανονικοποίηση (Apollo cache docs). - Προσαρμόστε το μέγεθος της cache και το garbage collection για μεγάλες λίστες (memory management).
- Αποφύγετε να αποθηκεύετε τεράστια, μη κανονικοποιημένα blobs κάτω από το
ROOT_QUERY— μπορεί να μπλοκάρει την εφαρμογή σας (community report).
Υλοποίηση pagination και περιορισμός του πλήθους στοιχείων (apollo graphql list best practices)
Αν φορτώνεις εκατοντάδες ή χιλιάδες άρθρα ειδήσεων ή sales leads μονομιάς, ζητάς πρόβλημα. Το pagination δεν είναι απλώς λειτουργία UX — είναι απαραίτητο για την απόδοση.
Το Apollo υποστηρίζει τόσο offset-based όσο και cursor-based pagination. Δείτε πώς συγκρίνονται:
| Τύπος pagination | Πλεονεκτήματα | Μειονεκτήματα | Καλύτερο για |
|---|---|---|---|
| Offset-based | Απλό, εύκολο στην υλοποίηση | Μπορεί να παραλείψει/διπλασιάσει items αν αλλάξουν τα δεδομένα | Αμετάβλητες ή μικρές λίστες |
| Cursor-based | Σταθερό, χειρίζεται καλά τις αλλαγές δεδομένων | Λίγο πιο περίπλοκο | News feeds, μεγάλες λίστες |
Για τις περισσότερες λίστες ειδήσεων ή leads σε πραγματικό χρόνο, το cursor-based pagination είναι η σωστή επιλογή. Κρατά τα δεδομένα συνεπή ακόμα κι όταν μπαίνουν νέα items ή διαγράφονται παλιά (GraphQL Foundation).
Συμβουλές για pagination στο Apollo:
- Ρύθμισε τα
keyArgsγια να ελέγχεις τα cache keys των paginated fields (docs). - Υλοποίησε μια συνάρτηση
mergeγια να συνδυάζεις σελίδες στην cache. - Χρησιμοποίησε
fetchMoreγια να φορτώνεις επιπλέον σελίδες χωρίς να αντικαθιστάς τα προηγούμενα αποτελέσματα.
Πρακτικά patterns pagination για εργαλεία scraping ειδήσεων
Ένα τυπικό UI για scraping ειδήσεων θα:
- Εμφανίζει τους τελευταίους 20–50 τίτλους (μόνο ελαφριά πεδία)
- Φορτώνει περισσότερα με scroll ή με click στο «επόμενη σελίδα»
- Τραβά λεπτομέρειες μόνο όταν χρειάζεται
Έτσι το UI μένει γρήγορο, το API παραμένει υγιές και οι χρήστες σου πιο παραγωγικοί.
Ενσωμάτωση του Thunderbit για αυτοματοποιημένη εξαγωγή ειδήσεων
Τώρα ας μιλήσουμε για το βασικό ερώτημα: από πού προέρχονται όλα αυτά τα δομημένα δεδομένα ειδήσεων εξαρχής; Εκεί μπαίνει το Thunderbit.
Αποκτήστε την επέκταση Thunderbit για Chrome Get Started Free
Το Thunderbit είναι μια no-code AI web scraper επέκταση για Chrome που μπορεί να εξάγει τίτλους ειδήσεων, URLs, πηγές, συγγραφείς, ημερομηνίες δημοσίευσης, summaries και εικόνες από σχεδόν οποιοδήποτε site — χωρίς να χρειάζεται κώδικας. Έχω δει ομάδες να χρησιμοποιούν το Thunderbit για να αυτοματοποιούν ολόκληρη τη διαδικασία εξαγωγής ειδήσεων, μετατρέποντας μη δομημένες ιστοσελίδες σε καθαρά, δομημένα δεδομένα που μπορούν να περάσουν απευθείας σε database ή GraphQL API.
Συνδυάζοντας το Thunderbit με το Apollo για δεδομένα ειδήσεων σε πραγματικό χρόνο
Ακολουθεί ένα workflow που μου αρέσει για ομάδες πωλήσεων και operations που χρειάζονται ενημερωμένες ειδήσεις:
- Επίπεδο εξαγωγής: Χρησιμοποιήστε το News Scraper template του Thunderbit για να τραβάτε δομημένα δεδομένα ειδήσεων από στοχευμένα sites σε πρόγραμμα.
- Επίπεδο αποθήκευσης: Αποθηκεύστε τα scraped δεδομένα σε μια βάση σχεδιασμένη για γρήγορη ανάκτηση.
- Επίπεδο GraphQL: Εκθέστε ένα list field
newsFeedκαι ένα detail fieldnewsArticle(id)μέσω του API σας. - Επίπεδο client: Χρησιμοποιήστε το Apollo Client για να φέρετε τη λίστα (λιτά πεδία, με pagination) και να φορτώνετε λεπτομέρειες μόνο όταν χρειάζεται.
Αυτό το pipeline «scrape → store → query» σημαίνει ότι τα Apollo queries σας δουλεύουν πάντα με φρέσκα, δομημένα δεδομένα — χωρίς χειροκίνητο copy-paste ή εύθραυστα scripts.
Bonus: Το Thunderbit μπορεί επίσης να εμπλουτίσει τις λίστες σας με επιπλέον πεδία (όπως sentiment ή κατηγορία) χρησιμοποιώντας τις AI-powered field suggestions, κάνοντας το news feed σας ακόμη πιο έξυπνο.
Βήμα προς βήμα οδηγός: Βελτιστοποίηση Apollo list queries
Έτοιμοι να το εφαρμόσετε; Ορίστε η checklist που χρησιμοποιώ για τη βελτιστοποίηση Apollo list queries:
-
Κάντε τα queries πιο ελαφριά
- Ζητήστε μόνο τα πεδία που χρειάζονται για την προβολή της λίστας (title, URL, timestamp κ.λπ.).
- Μεταφέρετε τα βαριά πεδία (full text, εικόνες, enrichment) σε detail queries.
-
Υλοποιήστε pagination
- Χρησιμοποιήστε cursor-based pagination για μεγάλες ή δυναμικές λίστες.
- Ρυθμίστε τις συναρτήσεις
keyArgsκαιmergeγια σωστή cache συμπεριφορά.
-
Αξιοποιήστε το Apollo Cache
- Κανονικοποιήστε τα entities με σταθερά IDs.
- Επιλέξτε τη σωστή fetch policy (
cache-and-networkείναι εξαιρετικό για ειδήσεις). - Προσαρμόστε το μέγεθος της cache και το garbage collection ανάλογα με τον όγκο των δεδομένων.
-
Ενσωματώστε αυτοματοποιημένη εξαγωγή
- Χρησιμοποιήστε το Thunderbit για να αυτοματοποιήσετε το scraping ειδήσεων και να κρατάτε τα δεδομένα φρέσκα.
- Εξάγετε δομημένα δεδομένα απευθείας στη βάση ή στο spreadsheet σας.
-
Παρακολουθήστε και εντοπίστε προβλήματα
- Χρησιμοποιήστε το Apollo Client Devtools για να εξετάζετε queries, cache και απόδοση.
- Προσέξτε μεγάλα cache writes, υπερβολικά watched queries και stutter στο UI.
- Παρακολουθήστε το p95/p99 latency και τα error rates (New Relic, Uptrends).
Παρακολούθηση και αντιμετώπιση προβλημάτων απόδοσης queries
Τα Devtools του Apollo είναι σωτήρια εδώ. Μπορείς να:
- Ελέγξεις ενεργά queries και την κατάσταση της cache
- Εντοπίσεις διπλά queries ή υπερβολικούς watchers
- Αναγνωρίσεις μεγάλα cache blobs ή προβλήματα κανονικοποίησης
Αν βλέπεις lag στο UI ή αργές ενημερώσεις, έλεγξε για:
- Υπερβολικά μεγάλα list queries (μείωσέ τα)
- Κακή κανονικοποίηση cache (διόρθωσε τα IDs σου)
- Προβλήματα στο pagination merge (έλεγξε τα
keyArgsκαιmerge)
Και μην ξεχνάς να μετράς tail latency — όχι μόνο τους μέσους όρους. Εκεί κρύβεται ο πραγματικός πόνος του χρήστη.
Σύγκριση παραδοσιακών και AI-driven προσεγγίσεων για scraping ειδήσεων
Ας είμαστε ειλικρινείς: παλιότερα το scraping ειδήσεων σήμαινε custom scripts, ταλαιπωρία με headless browsers και προσευχή να μην αλλάξει το layout του site από τη μια μέρα στην άλλη. Τώρα, με AI-driven εργαλεία όπως το Thunderbit, μπορείς να αυτοματοποιήσεις όλη τη διαδικασία — χωρίς κώδικα, χωρίς δράμα.
| Προσέγγιση | Δυνατά σημεία | Περιορισμοί για επιχειρησιακούς χρήστες |
|---|---|---|
| Scripted scraping | Απόλυτα παραμετροποιήσιμο, φθηνό σε μεγάλη κλίμακα | Υψηλή συντήρηση, απαιτεί χρόνο από engineers |
| Managed scraping platforms | Γρήγορο ξεκίνημα, αναλαμβάνει το anti-bot handling | Χρειάζεται ακόμη ρύθμιση, το κόστος αυξάνεται με τη χρήση |
| AI-driven extraction (Thunderbit) | Αντιμετωπίζει δύσκολα layouts, δεν χρειάζεται κώδικας | Το output χρειάζεται QA, ενσωμάτωση με το schema σας |
| No-code visual scrapers | Προσιτό για μη μηχανικούς | Μπορεί να χαλάσει με αλλαγές στο UI, περιορισμένη κλίμακα |
| Proxy/unlocker infra | Παρακάμπτει μπλοκαρίσματα, υποστηρίζει υψηλό throughput | Χρειάζεται ακόμη λογική εξαγωγής, ρίσκα συμμόρφωσης |
Νομική σημείωση: Η εξαγωγή δημόσιων δεδομένων είναι γενικά νόμιμη, αλλά να σέβεστε πάντα τους όρους χρήσης και τα rate limits (Reuters).
Βασικά συμπεράσματα για τις best practices των Apollo GraphQL list queries
Ας τα συνοψίσουμε στα ουσιώδη:
- Βελτιστοποιήστε για ταχύτητα και σαφήνεια: Κάντε τα list queries πιο λιτά, βάλτε pagination και αξιοποιήστε επιθετικά την cache.
- Η δομή μετράει: Τραβήξτε μόνο ό,τι χρειάζεστε — μεταφέρετε τα βαριά πεδία σε detail queries.
- Η cache είναι σύμμαχος: Χρησιμοποιήστε την κανονικοποίηση και τις fetch policies του Apollo για άμεση απόδοση δεδομένων.
- Αυτοματοποιήστε την εξαγωγή: Εργαλεία όπως το Thunderbit κάνουν το scraping ειδήσεων και το enrichment λιστών προσβάσιμο σε όλους.
- Παρακολουθήστε και βελτιώνετε: Χρησιμοποιήστε Devtools και dashboards observability για να εντοπίζετε bottlenecks νωρίς.
Για ομάδες πωλήσεων, operations και ειδήσεων, αυτές οι πρακτικές σημαίνουν λιγότερο χρόνο αναμονής, περισσότερο χρόνο δράσης — και πολύ λιγότερα μηνύματα στο Slack του τύπου «γιατί είναι τόσο αργό;».
Συμπέρασμα: Επόμενα βήματα για τη βελτιστοποίηση των Apollo list queries σας
Αν ακόμα τρέχεις βαριά, unpaginated ή cache-ανεπαρκή list queries, τώρα είναι η στιγμή να τα ελέγξεις και να τα αναβαθμίσεις. Ξεκίνα μικρά: περιόρισε τα fields, πρόσθεσε pagination και ρύθμισε σωστά την cache σου. Έπειτα, ανέβα επίπεδο ενσωματώνοντας εργαλεία αυτοματοποιημένης εξαγωγής όπως το Thunderbit για να κρατάς τα δεδομένα σου φρέσκα και αξιοποιήσιμα.
Θέλεις να το ψάξεις πιο βαθιά; Δες τα Apollo docs, το Thunderbit Blog ή μπες στο Apollo Community για πρακτικές συμβουλές και troubleshooting. Και αν είσαι έτοιμος να αυτοματοποιήσεις την εξαγωγή ειδήσεων, δοκίμασε το News Scraper template του Thunderbit — είναι game changer για όποιον χρειάζεται δεδομένα σε πραγματικό χρόνο χωρίς ταλαιπωρία.
Χρησιμοποιήστε το template News Scraper του Thunderbit
Αν δεν κάνεις τίποτε άλλο αφού το διαβάσεις αυτό: περιόρισε τα πεδία των list queries σου, πρόσθεσε cursor-based pagination και επίλεξε μια λογική fetch policy. Μόνο αυτές οι τρεις αλλαγές συνήθως μεταφέρουν ένα list query από «αισθητή» καθυστέρηση σε «απαρατήρητη» — και σε αφήνουν να εστιάσεις στα δεδομένα, όχι στο loading state.
Συχνές ερωτήσεις
1. Γιατί τα Apollo list queries επιβραδύνονται σε dashboards ειδήσεων σε πραγματικό χρόνο ή πωλήσεων;
Τα list queries μπορεί να γίνουν αργά αν τραβούν υπερβολικά πολλά δεδομένα, δεν έχουν pagination ή δεν είναι σωστά cached. Σε ροές εργασίας υψηλής συχνότητας, όπως η παρακολούθηση ειδήσεων, ακόμη και μικρές καθυστερήσεις συσσωρεύονται, προκαλώντας lag στο UI και απώλεια παραγωγικότητας.
2. Ποιος είναι ο καλύτερος τρόπος να δομήσω τα Apollo list queries για αυτοματοποιημένη εξαγωγή ειδήσεων;
Ζητήστε μόνο τα πεδία που χρειάζονται για να εμφανιστεί η λίστα σας (π.χ. title, URL, timestamp). Μεταφέρετε τα βαριά πεδία (όπως full article text ή εικόνες) σε detail queries και χρησιμοποιήστε pagination για να κρατάτε τα payloads μικρά και γρήγορα.
3. Πώς βελτιώνει το cache του Apollo Client την απόδοση των λιστών;
Η cache του Apollo αποθηκεύει δεδομένα που έχουν ήδη ανακτηθεί, επιτρέποντας άμεσες απαντήσεις σε επαναλαμβανόμενα queries. Η σωστή κανονικοποίηση της cache και οι fetch policies (όπως το cache-and-network) μπορούν να επιταχύνουν σημαντικά τις προβολές λιστών και να μειώσουν το φορτίο στον server.
4. Πώς μπορεί το Thunderbit να βοηθήσει στο scraping ειδήσεων και στην ενσωμάτωση με το Apollo;
Το Thunderbit είναι ένα no-code AI web scraper που εξάγει δομημένα δεδομένα ειδήσεων από οποιοδήποτε site. Μπορείς να το χρησιμοποιήσεις για να αυτοματοποιήσεις την εξαγωγή ειδήσεων και στη συνέχεια να τροφοδοτήσεις αυτά τα δεδομένα στη βάση σου ή στο GraphQL API για χρήση με το Apollo Client.
5. Ποια εργαλεία μπορώ να χρησιμοποιήσω για να παρακολουθώ και να εντοπίζω προβλήματα στην απόδοση των Apollo list queries;
Τα Apollo Client Devtools σού επιτρέπουν να εξετάζεις queries, κατάσταση cache και απόδοση σε πραγματικό χρόνο. Συνδύασέ τα με dashboards observability (όπως New Relic ή Uptrends) για να παρακολουθείς latency και error rates και βελτιστοποίησε τον σχεδιασμό των queries σου για τα καλύτερα αποτελέσματα.
Θέλεις περισσότερες συμβουλές για web scraping, automation και ροές δεδομένων σε πραγματικό χρόνο; Δες το Thunderbit Blog για αναλύσεις, tutorials και ό,τι πιο πρόσφατο σε AI-powered παραγωγικότητα.
Δοκιμάστε το Thunderbit AI Web Scraper Get Started Free
Μάθετε περισσότερα
- Πώς να βελτιστοποιήσετε τις λίστες του Apollo για αποτελεσματική διαχείριση leads
- Εμπλουτισμός δεδομένων Apollo: λειτουργίες, οφέλη και ενίσχυση με AI
- Πώς να κατακτήσετε το Apollo prospecting: οδηγός βήμα προς βήμα
- Πώς να χρησιμοποιήσετε pagination σε web scraper για αποδοτική εξαγωγή
- Πώς να χρησιμοποιήσετε pagination σε web scraper για αποδοτική εξαγωγή




