

Τα web δεδομένα αυξάνονται εκρηκτικά — και μαζί τους αυξάνεται και η πίεση να τα προλαβαίνουμε. Έχω δει από πρώτο χέρι πόσο συχνά οι ομάδες πωλήσεων και operations ξοδεύουν περισσότερο χρόνο σε φύλλα Excel και στο copy-paste από ιστοσελίδες, παρά στη λήψη αποφάσεων. Σύμφωνα με τη Salesforce, οι πωλητές πλέον αφιερώνουν έως και το 70% του χρόνου τους σε μη εμπορικές εργασίες, ενώ η Asana αναφέρει ότι το 60% της εργασίας είναι απλώς «εργασία γύρω από την εργασία». Πρόκειται για αμέτρητες ώρες που χάνονται σε χειροκίνητη συλλογή δεδομένων — ώρες που θα μπορούσαν να αξιοποιηθούν για κλείσιμο συμφωνιών ή λανσάρισμα καμπανιών.
Η καλή είδηση; Το web scraping έχει πλέον περάσει στο mainstream και δεν χρειάζεται να είστε developer για να εκμεταλλευτείτε τη δύναμή του. Η Ruby είναι εδώ και χρόνια αγαπημένη επιλογή για αυτοματοποίηση εξαγωγής web δεδομένων, όμως όταν τη συνδυάζετε με σύγχρονα AI web scrapers όπως το Thunderbit, έχετε το καλύτερο και από τους δύο κόσμους — ευελιξία για όσους γράφουν κώδικα και απλότητα χωρίς κώδικα για όλους τους υπόλοιπους. Είτε είστε marketer, είτε διαχειριστής e-commerce, είτε απλώς κάποιος που έχει κουραστεί από το ατελείωτο copy-paste, αυτός ο οδηγός θα σας δείξει πώς να αξιοποιήσετε το web scraping με Ruby και AI — χωρίς να απαιτείται κώδικας.
Δοκιμάστε το Thunderbit για Web Scraping χωρίς Κώδικα
Τι είναι το Web Scraping με Ruby; Η πύλη σας προς την αυτοματοποιημένη συλλογή δεδομένων
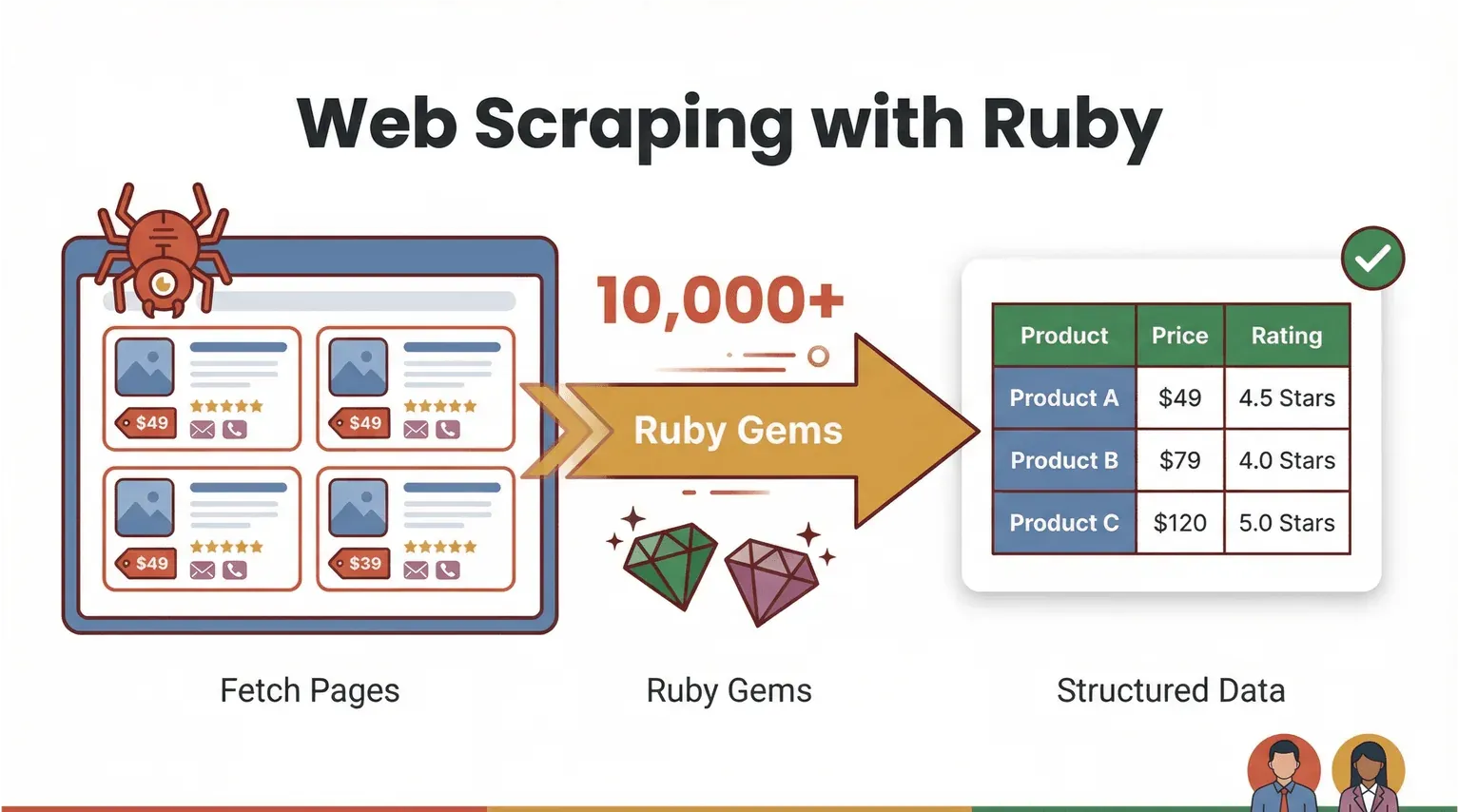
Ας ξεκινήσουμε από τα βασικά. Το web scraping είναι η διαδικασία κατά την οποία χρησιμοποιείτε λογισμικό για να «τραβήξετε» σελίδες από το web και να εξαγάγετε συγκεκριμένες πληροφορίες — όπως τιμές προϊόντων, στοιχεία επικοινωνίας ή αξιολογήσεις — σε δομημένη μορφή (σκεφτείτε CSV ή Excel). Με τη Ruby, το web scraping γίνεται ταυτόχρονα ισχυρό και προσιτό. Η γλώσσα ξεχωρίζει για τη σαφή σύνταξή της και το τεράστιο οικοσύστημα από “gems” (βιβλιοθήκες) που κάνουν την αυτοματοποίηση παιχνιδάκι (Ruby Programming Language).
Πώς μοιάζει λοιπόν στην πράξη το «web scraping με Ruby»; Φανταστείτε ότι θέλετε να συλλέξετε όλα τα ονόματα και τις τιμές προϊόντων από ένα e-commerce site. Με τη Ruby, μπορείτε να γράψετε ένα script που:
- Κατεβάζει τη web σελίδα (χρησιμοποιώντας μια βιβλιοθήκη όπως η HTTParty)
- Αναλύει το HTML για να βρει τα δεδομένα που θέλετε (με το Nokogiri)
- Τα εξάγει σε υπολογιστικό φύλλο ή βάση δεδομένων
Εδώ όμως αρχίζει το πραγματικά ενδιαφέρον: δεν χρειάζεται πάντα να γράφετε κώδικα. AI-powered web scrapers χωρίς κώδικα, όπως το Thunderbit, μπορούν πλέον να κάνουν τη βαριά δουλειά — να διαβάζουν σελίδες, να αναγνωρίζουν πεδία και να εξάγουν καθαρούς πίνακες δεδομένων με λίγα μόνο κλικ. Η Ruby παραμένει εξαιρετική «κόλλα αυτοματοποίησης» για εξατομικευμένες ροές εργασίας, αλλά τα AI web scrapers ανοίγουν την πόρτα ώστε και οι business users να μπουν στο παιχνίδι.
Τι είναι το Data Scraping; Get Started Free
Γιατί το Web Scraping με Ruby έχει σημασία για τις επιχειρηματικές ομάδες

Ας μιλήσουμε ρεαλιστικά: κανείς δεν θέλει να περνάει τη μέρα του κάνοντας copy-paste δεδομένων. Η ζήτηση για αυτοματοποιημένη εξαγωγή web δεδομένων εκτοξεύεται — και όχι άδικα. Δείτε πώς το web scraping με Ruby (και εργαλεία AI) αλλάζει τις επιχειρηματικές λειτουργίες:
- Lead Generation: Συλλέξτε άμεσα στοιχεία επικοινωνίας από directories ή το LinkedIn για το sales pipeline σας.
- Παρακολούθηση τιμών ανταγωνιστών: Ελέγχετε αλλαγές τιμών σε εκατοντάδες SKU e-commerce — τέλος στα χειροκίνητα checks.
- Δημιουργία καταλόγου προϊόντων: Συγκεντρώστε πληροφορίες προϊόντων και εικόνες για το δικό σας store ή marketplace.
- Έρευνα αγοράς: Συλλέξτε reviews, αξιολογήσεις ή άρθρα ειδήσεων για ανάλυση τάσεων.
Το ROI είναι ξεκάθαρο: οι ομάδες που αυτοματοποιούν τη συλλογή web δεδομένων κερδίζουν ώρες κάθε εβδομάδα, μειώνουν τα λάθη και αποκτούν πιο φρέσκα, πιο αξιόπιστα δεδομένα. Στη βιομηχανία, για παράδειγμα, το 70% των εταιρειών εξακολουθεί να συλλέγει δεδομένα χειροκίνητα, παρότι ο όγκος των δεδομένων έχει διπλασιαστεί μέσα σε μόλις δύο χρόνια. Πρόκειται για τεράστια ευκαιρία αυτοματοποίησης.
Δείτε μια σύντομη σύνοψη του πώς το web scraping με Ruby και εργαλεία AI προσφέρει αξία:
| Use Case | Manual Pain Point | Benefit of Automation | Typical Outcome |
|---|---|---|---|
| Lead Generation | Copying emails one by one | Scrape thousands in minutes | 10x more leads, less grunt work |
| Price Monitoring | Daily site checks | Scheduled, automated price pulls | Real-time pricing intelligence |
| Catalog Building | Manual data entry | Bulk extraction & formatting | Faster launches, fewer errors |
| Market Research | Reading reviews by hand | Scrape and analyze at scale | Deeper, fresher insights |
Και δεν είναι μόνο θέμα ταχύτητας — η αυτοματοποίηση σημαίνει λιγότερα λάθη και πιο συνεπή δεδομένα, κάτι κρίσιμο όταν το 58% των ηγετών δηλώνει ότι οι αποφάσεις τους βασίζονται σε ανακριβή ή ασυνεπή δεδομένα.
Εξερευνώντας λύσεις Web Scraping: Ruby Scripts vs. AI Web Scraper Tools
Λοιπόν, πρέπει να γράψετε το δικό σας Ruby script ή να χρησιμοποιήσετε ένα AI-powered, no-code web scraper; Ας δούμε αναλυτικά τις επιλογές.
Ruby Scripting: Απόλυτος έλεγχος, μεγαλύτερη συντήρηση
Το οικοσύστημα της Ruby είναι γεμάτο gems για κάθε ανάγκη scraping:
- Nokogiri: Η πιο κλασική επιλογή για parsing HTML και XML.
- HTTParty: Για λήψη web σελίδων και APIs.
- Mechanize: Για sites που απαιτούν cookies, φόρμες και πλοήγηση.
- Selenium / Watir: Για αυτοματοποίηση πραγματικών browsers (ιδανικό για sites με έντονο JavaScript).
Με τα Ruby scripts έχετε πλήρη ευελιξία — προσαρμοσμένη λογική, καθαρισμό δεδομένων και σύνδεση με τα δικά σας συστήματα. Αλλά αναλαμβάνετε και τη συντήρηση: όταν αλλάζει η δομή μιας ιστοσελίδας, το script σας μπορεί να «σπάσει». Και αν δεν είστε άνετοι με τον κώδικα, υπάρχει και η καμπύλη μάθησης.
AI Web Scrapers & No-Code Εργαλεία: Γρήγορα, φιλικά και προσαρμοστικά
Τα σύγχρονα no-code web scrapers όπως το Thunderbit αλλάζουν τα δεδομένα. Αντί να γράφετε κώδικα, απλώς:
- Ανοίγετε το Chrome extension
- Πατάτε “AI Suggest Fields” για να αφήσετε την AI να εντοπίσει τι πρέπει να εξαχθεί
- Πατάτε “Scrape” και εξάγετε τα δεδομένα σας
Το Thunderbit προσαρμόζεται στις αλλαγές στη διάταξη των σελίδων, χειρίζεται subpages (όπως λεπτομέρειες προϊόντων) και εξάγει απευθείας σε Excel, Google Sheets, Airtable ή Notion. Είναι ιδανικό για επιχειρηματικούς χρήστες που θέλουν αποτέλεσμα χωρίς ταλαιπωρία.
Δείτε μια σύγκριση δίπλα-δίπλα:
| Approach | Pros | Cons | Best For |
|---|---|---|---|
| Ruby Scripting | Full control, custom logic, flexible | Steeper learning curve, maintenance | Developers, advanced users |
| AI Web Scraper | No-code, fast setup, adapts to changes | Less granular control, some limits | Business users, ops teams |
Η τάση είναι σαφής: όσο οι ιστοσελίδες γίνονται πιο σύνθετες (και πιο αμυντικές), τα AI web scrapers εξελίσσονται σε πρώτη επιλογή για τις περισσότερες επιχειρηματικές ροές εργασίας.
Ξεκινώντας: Ρύθμιση του περιβάλλοντος Ruby για Web Scraping
Αν είστε έτοιμοι να δοκιμάσετε Ruby scripting, ας στήσουμε το περιβάλλον σας. Το καλό νέο; Η Ruby εγκαθίσταται εύκολα και λειτουργεί σε Windows, macOS και Linux.
Βήμα 1: Εγκαταστήστε τη Ruby
- Windows: Κατεβάστε το RubyInstaller και ακολουθήστε τα βήματα. Φροντίστε να συμπεριλάβετε το MSYS2 για τη δημιουργία native extensions (απαραίτητο για gems όπως το Nokogiri).
- macOS/Linux: Χρησιμοποιήστε το rbenv για διαχείριση εκδόσεων. Στο Terminal:
brew install rbenv ruby-build
rbenv install 4.0.4
rbenv global 4.0.4
(Ελέγξτε τη σελίδα λήψεων της Ruby για την πιο πρόσφατη σταθερή έκδοση.)
Βήμα 2: Εγκαταστήστε το Bundler και τα βασικά gems
Το Bundler βοηθά στη διαχείριση των εξαρτήσεων:
gem install bundler
Δημιουργήστε ένα Gemfile για το project σας:
source 'https://rubygems.org'
gem 'nokogiri'
gem 'httparty'
Έπειτα εκτελέστε:
bundle install
Έτσι διασφαλίζετε ότι το περιβάλλον σας είναι συνεπές και έτοιμο για scraping.
Βήμα 3: Δοκιμάστε τη ρύθμιση
Δοκιμάστε το παρακάτω στο IRB (το διαδραστικό shell της Ruby):
require 'nokogiri'
require 'httparty'
puts Nokogiri::VERSION
Αν δείτε έναν αριθμό έκδοσης, είστε έτοιμοι!
Βήμα-βήμα: Φτιάχνοντας το πρώτο σας Ruby Web Scraper
Ας δούμε ένα πραγματικό παράδειγμα — scraping δεδομένων προϊόντων από το Books to Scrape, ένα site σχεδιασμένο για εξάσκηση στο scraping.
Ακολουθεί ένα απλό Ruby script που εξάγει τίτλους βιβλίων, τιμές και διαθεσιμότητα:
require "net/http"
require "uri"
require "nokogiri"
require "csv"
BASE_URL = "https://books.toscrape.com/"
def fetch_html(url)
uri = URI.parse(url)
res = Net::HTTP.get_response(uri)
raise "HTTP #{res.code} for #{url}" unless res.is_a?(Net::HTTPSuccess)
res.body
end
def scrape_list_page(list_url)
html = fetch_html(list_url)
doc = Nokogiri::HTML(html)
products = doc.css("article.product_pod").map do |pod|
title = pod.css("h3 a").first["title"]
price = pod.css(".price_color").text.strip
stock = pod.css(".availability").text.strip.gsub(/\s+/, " ")
{ title: title, price: price, stock: stock }
end
next_rel = doc.css("li.next a").first&.[]("href")
next_url = next_rel ? URI.join(list_url, next_rel).to_s : nil
[products, next_url]
end
rows = []
url = "#{BASE_URL}catalogue/page-1.html"
while url
products, url = scrape_list_page(url)
rows.concat(products)
end
CSV.open("books.csv", "w", write_headers: true, headers: %w[title price stock]) do |csv|
rows.each { |r| csv << [r[:title], r[:price], r[:stock]] }
end
puts "Wrote #{rows.length} rows to books.csv"
Αυτό το script κατεβάζει κάθε σελίδα, αναλύει το HTML, εξάγει τα δεδομένα και τα γράφει σε CSV αρχείο. Μπορείτε να ανοίξετε το books.csv σε Excel ή Google Sheets.
Συνήθη σημεία προσοχής:
- Αν δείτε σφάλματα για ελλιπή gems, ελέγξτε ξανά το Gemfile και τρέξτε
bundle install. - Για sites που φορτώνουν δεδομένα με JavaScript, θα χρειαστείτε εργαλείο αυτοματοποίησης browser όπως Selenium ή Watir.
Απογειώστε το Ruby Scraping με το Thunderbit: AI Web Scraper στην πράξη
Ας δούμε πώς το Thunderbit μπορεί να πάει το scraping σας στο επόμενο επίπεδο — χωρίς να γράψετε κώδικα.
Το Thunderbit είναι ένα AI web scraper Chrome extension που σας επιτρέπει να εξάγετε δομημένα δεδομένα από οποιαδήποτε ιστοσελίδα με μόλις δύο κλικ. Δείτε πώς λειτουργεί:
- Ανοίγετε το Thunderbit extension στη σελίδα που θέλετε να κάνετε scrape.
- Πατάτε “AI Suggest Fields”. Η AI του Thunderbit σαρώνει τη σελίδα και προτείνει τις καλύτερες στήλες για εξαγωγή (όπως “Product Name”, “Price”, “Stock”).
- Πατάτε “Scrape”. Το Thunderbit συλλέγει τα δεδομένα, χειρίζεται την pagination και ακολουθεί ακόμη και subpages αν χρειάζεστε περισσότερες λεπτομέρειες.
- Εξάγετε τα δεδομένα σας απευθείας σε Excel, Google Sheets, Airtable ή Notion.
Αυτό που κάνει το Thunderbit ξεχωριστό είναι η δυνατότητά του να διαχειρίζεται σύνθετες, δυναμικές σελίδες — χωρίς εύθραυστα selectors ή κώδικα. Και αν θέλετε να συνδυάσετε ροές εργασίας, μπορείτε να χρησιμοποιήσετε το Thunderbit για την εξαγωγή των δεδομένων και στη συνέχεια να τα επεξεργαστείτε ή να τα εμπλουτίσετε περαιτέρω με ένα Ruby script.
Pro tip: Το scraping subpages στο Thunderbit σώζει χρόνο σε ομάδες e-commerce και real estate. Συλλέξτε μια λίστα από product links και μετά αφήστε το Thunderbit να επισκεφθεί το καθένα για να αντλήσει αναλυτικά specs, εικόνες ή reviews — εμπλουτίζοντας αυτόματα το dataset σας.
Πώς να κάνετε Scrape οποιαδήποτε ιστοσελίδα με AI Get Started Free
Πρακτικό παράδειγμα: Scraping δεδομένων προϊόντων και τιμών e-commerce με Ruby και Thunderbit
Ας τα συνδυάσουμε όλα με μια πρακτική ροή εργασίας για ομάδες e-commerce.
Σενάριο: Θέλετε να παρακολουθείτε τιμές ανταγωνιστών και λεπτομέρειες προϊόντων σε εκατοντάδες SKU.
Βήμα 1: Χρησιμοποιήστε το Thunderbit για να κάνετε scrape την κύρια λίστα προϊόντων
- Ανοίξτε τη σελίδα προϊόντων του ανταγωνιστή.
- Εκκινήστε το Thunderbit, πατήστε “AI Suggest Fields” (π.χ. Product Name, Price, URL).
- Πατήστε “Scrape” και εξαγάγετε τα αποτελέσματα σε CSV.
Βήμα 2: Εμπλουτίστε τα δεδομένα με subpage scraping
- Στο Thunderbit, χρησιμοποιήστε τη λειτουργία “Scrape Subpages” για να επισκεφθείτε τη σελίδα λεπτομερειών κάθε προϊόντος και να εξαγάγετε επιπλέον πεδία (όπως περιγραφή, stock ή εικόνες).
- Εξάγετε τον εμπλουτισμένο πίνακα.
Βήμα 3: Επεξεργασία ή ανάλυση με Ruby
- Χρησιμοποιήστε ένα Ruby script για να καθαρίσετε, να μετασχηματίσετε ή να αναλύσετε περαιτέρω τα δεδομένα. Για παράδειγμα, ίσως θέλετε να:
- μετατρέψετε τις τιμές σε ενιαίο νόμισμα
- φιλτράρετε τα είδη που δεν είναι διαθέσιμα
- δημιουργήσετε συνοπτικά στατιστικά
Ακολουθεί ένα απλό Ruby snippet για να φιλτράρετε τα διαθέσιμα προϊόντα:
require 'csv'
rows = CSV.read('products.csv', headers: true)
in_stock = rows.select { |row| row['stock'].include?('In stock') }
CSV.open('in_stock_products.csv', 'w', write_headers: true, headers: rows.headers) do |csv|
in_stock.each { |row| csv << row }
end
Αποτέλεσμα:
Πηγαίνετε από ακατέργαστες web σελίδες σε έναν καθαρό, αξιοποιήσιμο πίνακα δεδομένων — έτοιμο για ανάλυση τιμολόγησης, σχεδιασμό αποθεμάτων ή καμπάνιες marketing. Και όλα αυτά χωρίς να γράψετε ούτε μία γραμμή κώδικα scraping.
Χωρίς Κώδικα, χωρίς πρόβλημα: Αυτοματοποιώντας την εξαγωγή web δεδομένων για όλους
Ένα από τα αγαπημένα μου στοιχεία στο Thunderbit είναι το πώς δίνει δύναμη σε μη τεχνικούς χρήστες. Δεν χρειάζεται να ξέρετε Ruby, HTML ή CSS — απλώς ανοίξτε το extension, αφήστε την AI να κάνει τη δουλειά της και εξαγάγετε τα δεδομένα σας.
Καμπύλη μάθησης: Με τα Ruby scripts, θα πρέπει να μάθετε τα βασικά του προγραμματισμού και της δομής του web. Με το Thunderbit, ο χρόνος ρύθμισης μετριέται σε λεπτά, όχι σε ημέρες.
Ενσωμάτωση: Το Thunderbit εξάγει απευθείας στα εργαλεία που ήδη χρησιμοποιούν οι επιχειρηματικές ομάδες — Excel, Google Sheets, Airtable, Notion. Μπορείτε ακόμη να προγραμματίσετε επαναλαμβανόμενα scrapes για συνεχή παρακολούθηση.
Ανατροφοδότηση χρηστών: Έχω δει ομάδες marketing, sales ops και e-commerce managers να χρησιμοποιούν το Thunderbit για να αυτοματοποιήσουν τα πάντα, από τη δημιουργία λιστών leads μέχρι την παρακολούθηση τιμών — χωρίς ποτέ να καλέσουν το IT.
Καλές πρακτικές: Συνδυάζοντας Ruby και AI Web Scraper για επεκτάσιμη αυτοματοποίηση
Θέλετε να χτίσετε μια στιβαρή και επεκτάσιμη ροή scraping; Ορίστε οι βασικές μου συμβουλές:
- Διαχειριστείτε αλλαγές στις ιστοσελίδες: Τα AI web scrapers όπως το Thunderbit προσαρμόζονται αυτόματα, αλλά αν χρησιμοποιείτε Ruby scripts, να είστε έτοιμοι να ενημερώνετε selectors όταν αλλάζει ένα site.
- Προγραμματίστε τα scrapes σας: Χρησιμοποιήστε τη λειτουργία προγραμματισμού του Thunderbit για τακτική λήψη δεδομένων. Για Ruby, στήστε ένα cron job ή έναν task scheduler.
- Μαζική επεξεργασία: Για μεγάλα datasets, χωρίστε το scraping σε batches ώστε να αποφύγετε αποκλεισμούς ή επιβάρυνση του συστήματός σας.
- Μορφοποίηση δεδομένων: Πάντα να καθαρίζετε και να επαληθεύετε τα δεδομένα πριν την ανάλυση — τα exports του Thunderbit είναι δομημένα, αλλά τα custom Ruby scripts μπορεί να χρειάζονται επιπλέον ελέγχους.
- Συμμόρφωση: Κάνετε scrape μόνο δημόσια διαθέσιμα δεδομένα, σεβαστείτε το
robots.txtκαι δώστε προσοχή στους νόμους περί ιδιωτικότητας (ιδίως στην ΕΕ — το GDPR ισχύει για scraped προσωπικά δεδομένα). - Σχέδια εναλλακτικής: Αν ένα site γίνει υπερβολικά σύνθετο ή μπλοκάρει το scraping, αναζητήστε επίσημα APIs ή εναλλακτικές πηγές δεδομένων.
Πότε να χρησιμοποιήσετε τι;
- Χρησιμοποιήστε Ruby scripts όταν χρειάζεστε πλήρη έλεγχο, προσαρμοσμένη λογική ή σύνδεση με εσωτερικά συστήματα.
- Χρησιμοποιήστε Thunderbit όταν θέλετε ταχύτητα, ευκολία και προσαρμοστικότητα — ειδικά για εφάπαξ ή επαναλαμβανόμενες επιχειρηματικές εργασίες.
- Συνδυάστε και τα δύο για προχωρημένες ροές: αφήστε το Thunderbit να κάνει την εξαγωγή και μετά χρησιμοποιήστε τη Ruby για εμπλουτισμό, QA ή integration.
Συμπέρασμα και βασικά σημεία
Το web scraping με Ruby ήταν πάντα μια υπερδύναμη για την αυτοματοποίηση της συλλογής δεδομένων — όμως πλέον, με AI web scrapers όπως το Thunderbit, αυτή η δύναμη είναι προσβάσιμη σε όλους. Είτε είστε developer που αναζητά ευελιξία είτε επιχειρηματικός χρήστης που απλώς θέλει αποτελέσματα, μπορείτε να αυτοματοποιήσετε την εξαγωγή web δεδομένων, να γλιτώσετε ώρες χειροκίνητης δουλειάς και να πάρετε καλύτερες, ταχύτερες αποφάσεις.
Αυτά είναι τα βασικά που ελπίζω να κρατήσετε:
- Η Ruby είναι ένα εξαιρετικό εργαλείο για web scraping και αυτοματοποίηση — ειδικά με gems όπως το Nokogiri και το HTTParty.
- Τα AI web scrapers όπως το Thunderbit κάνουν την εξαγωγή δεδομένων προσιτή και σε μη προγραμματιστές, με λειτουργίες όπως το “AI Suggest Fields” και το subpage scraping.
- Ο συνδυασμός Ruby και Thunderbit σας δίνει το καλύτερο και από τους δύο κόσμους: γρήγορη εξαγωγή χωρίς κώδικα, μαζί με προσαρμοσμένη αυτοματοποίηση και ανάλυση.
- Η αυτοματοποίηση της συλλογής web δεδομένων είναι στρατηγική κίνηση για sales, marketing και e-commerce ομάδες — μειώνει τη χειροκίνητη εργασία, βελτιώνει την ακρίβεια και ξεκλειδώνει νέες γνώσεις.
Έτοιμοι να ξεκινήσετε; Κατεβάστε το Thunderbit, δοκιμάστε ένα απλό Ruby script και δείτε πόσο χρόνο μπορείτε να εξοικονομήσετε. Και αν θέλετε να εμβαθύνετε, επισκεφθείτε το Thunderbit Blog για περισσότερους οδηγούς, tips και πρακτικά παραδείγματα.
Κατεβάστε την Thunderbit Chrome Extension
Συχνές ερωτήσεις
1. Χρειάζεται να ξέρω προγραμματισμό για να χρησιμοποιήσω το Thunderbit στο web scraping;
Όχι. Το Thunderbit έχει σχεδιαστεί για μη τεχνικούς χρήστες. Απλώς ανοίξτε το extension, πατήστε “AI Suggest Fields” και αφήστε την AI να κάνει τα υπόλοιπα. Μπορείτε να εξάγετε τα δεδομένα σας σε Excel, Google Sheets, Airtable ή Notion — χωρίς κώδικα.
2. Ποια είναι τα βασικά πλεονεκτήματα της Ruby για web scraping;
Η Ruby προσφέρει ισχυρές βιβλιοθήκες όπως το Nokogiri και το HTTParty για ευέλικτες, προσαρμοσμένες ροές scraping. Είναι ιδανική για developers που θέλουν πλήρη έλεγχο, προσαρμοσμένη λογική και ενσωμάτωση με άλλα συστήματα.
3. Πώς λειτουργεί η δυνατότητα “AI Suggest Fields” του Thunderbit;
Η AI του Thunderbit σαρώνει τη web σελίδα, εντοπίζει τα πιο σχετικά πεδία δεδομένων (όπως ονόματα προϊόντων, τιμές, emails) και σας προτείνει έναν δομημένο πίνακα. Μπορείτε να προσαρμόσετε τις στήλες όπως θέλετε πριν κάνετε scraping.
4. Μπορώ να συνδυάσω το Thunderbit με Ruby scripts για πιο προχωρημένες ροές εργασίας;
Απολύτως. Πολλές ομάδες χρησιμοποιούν το Thunderbit για εξαγωγή δεδομένων (ειδικά από σύνθετα ή δυναμικά sites) και στη συνέχεια τα επεξεργάζονται ή τα αναλύουν περαιτέρω με Ruby scripts. Αυτή η υβριδική προσέγγιση είναι εξαιρετική για custom reporting ή εμπλουτισμό δεδομένων.
5. Είναι το web scraping νόμιμο και ασφαλές για επαγγελματική χρήση;
Το web scraping είναι νόμιμο όταν συλλέγετε δημόσια διαθέσιμα δεδομένα και σέβεστε τους όρους χρήσης της ιστοσελίδας και τους νόμους περί ιδιωτικότητας. Ελέγχετε πάντα το robots.txt και αποφύγετε τη συλλογή προσωπικών δεδομένων χωρίς κατάλληλη συγκατάθεση — ειδικά για χρήστες στην ΕΕ υπό το GDPR.
Θέλετε να δείτε πώς το web scraping μπορεί να μεταμορφώσει τη ροή εργασίας σας; Δοκιμάστε το δωρεάν πλάνο του Thunderbit ή πειραματιστείτε σήμερα με ένα Ruby script. Και αν κολλήσετε, το Thunderbit Blog και το Thunderbit YouTube Channel είναι γεμάτα tutorials και tips για να κυριαρχήσετε στην αυτοματοποίηση web δεδομένων — χωρίς κώδικα.
Δοκιμάστε το Thunderbit AI Web Scraper Get Started Free
Μάθετε περισσότερα




