
Keywords
καλύτερη γλώσσα για web scraping, καλύτερη γλώσσα προγραμματισμού για web scraping, web scraping με python
Ποια γλώσσα προγραμματισμού να διαλέξεις για web scraping; Η απάντηση είναι «εξαρτάται» από το project σου — και έχω δει developers να πετάνε το λάπτοπ από τα νεύρα όταν πάνε με τη λάθος επιλογή.
Η αγορά λογισμικού web scraping έφτασε τα . Η σωστή γλώσσα σημαίνει πιο γρήγορα αποτελέσματα και λιγότερη συντήρηση. Η λάθος επιλογή σημαίνει scrapers που σπάνε, και Σαββατοκύριακα που εξαφανίζονται.
Φτιάχνω εργαλεία αυτοματοποίησης εδώ και χρόνια. Παρακάτω θα δεις επτά γλώσσες που έχω χρησιμοποιήσει για scraping — με παραδείγματα κώδικα, τίμια υπέρ/κατά και το πότε αξίζει να αφήσεις τον κώδικα στην άκρη και να πας κατευθείαν στο αντί γι’ αυτό.
Πώς επιλέξαμε την καλύτερη γλώσσα για Web Scraping
Στο web scraping, δεν είναι όλες οι γλώσσες «ίδιες κι όμοιες». Έχω δει projects να απογειώνονται (και να γκρεμίζονται) ανάλογα με λίγους, αλλά κρίσιμους παράγοντες:
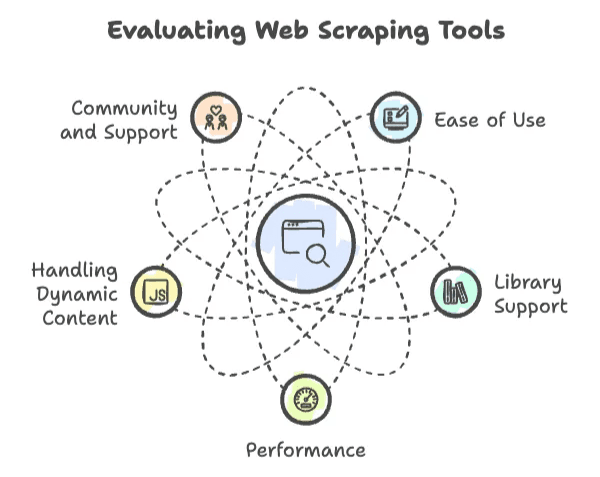
- Ευκολία χρήσης: Πόσο γρήγορα ξεκινάς; Είναι ανθρώπινη η σύνταξη ή χρειάζεσαι… διδακτορικό για να γράψεις «Hello, World»;
- Υποστήριξη βιβλιοθηκών: Υπάρχουν ώριμες βιβλιοθήκες για HTTP requests, parsing HTML και χειρισμό δυναμικού περιεχομένου; Ή το πας «χειροποίητα» και ξαναφτιάχνεις τον τροχό;
- Απόδοση: Μπορεί να «σηκώσει» εκατομμύρια σελίδες ή αρχίζει να λαχανιάζει μετά από λίγες εκατοντάδες;
- Διαχείριση δυναμικού περιεχομένου: Τα σύγχρονα sites έχουν κόλλημα με JavaScript. Η γλώσσα σου μπορεί να ακολουθήσει τον ρυθμό;
- Κοινότητα και υποστήριξη: Όταν κολλήσεις (και θα κολλήσεις), υπάρχει κόσμος να σε ξεμπλοκάρει;
Με βάση αυτά τα κριτήρια — και αρκετές δοκιμές μέχρι αργά — αυτές είναι οι 7 γλώσσες που θα καλύψω:
- Python: Η κλασική επιλογή για αρχάριους και έμπειρους.
- JavaScript & Node.js: Ο «βασιλιάς» του δυναμικού περιεχομένου.
- Ruby: Καθαρή σύνταξη, γρήγορα scripts.
- PHP: Απλότητα στην πλευρά του server.
- C++: Όταν χρειάζεσαι ωμή ταχύτητα.
- Java: Έτοιμη για enterprise και κλιμάκωση.
- Go (Golang): Γρήγορη και φοβερή στο concurrency.
Και αν σκέφτεσαι «Shuai, δεν θέλω να γράψω καθόλου κώδικα», κάτσε μέχρι το τέλος για το Thunderbit.
Web Scraping με Python: Η πιο φιλική “δύναμη” για αρχάριους
Ξεκινάμε με το αγαπημένο του κοινού: Python. Αν ρωτήσεις ένα δωμάτιο γεμάτο data folks «ποια είναι η καλύτερη γλώσσα προγραμματισμού για web scraping;», θα ακούσεις «Python» να γυρίζει σαν ρεφρέν.
Γιατί Python;
- Φιλική σύνταξη για αρχάριους: Διαβάζεται σχεδόν σαν φυσική γλώσσα.
- Ασύγκριτη υποστήριξη βιβλιοθηκών: Από για parsing HTML, μέχρι για crawling μεγάλης κλίμακας, για HTTP και για αυτοματοποίηση browser — τα έχει όλα.
- Τεράστια κοινότητα: Πάνω από μόνο για web scraping.
Παράδειγμα Python: Scraping του τίτλου μιας σελίδας
1import requests
2from bs4 import BeautifulSoup
3response = requests.get("<https://example.com>")
4soup = BeautifulSoup(response.text, 'html.parser')
5title = soup.title.string
6print(f"Page title: {title}")Δυνατά σημεία:
- Γρήγορη ανάπτυξη και prototyping.
- Άπειρα tutorials και Q&A.
- Ιδανική για ανάλυση δεδομένων — κάνεις scrape με Python, αναλύεις με pandas, οπτικοποιείς με matplotlib.
Περιορισμοί:
- Πιο αργή από compiled γλώσσες σε τεράστιες εργασίες.
- Σε πολύ δυναμικά sites μπορεί να γίνει «βαριά» (αν και Selenium και Playwright βοηθούν).
- Δεν είναι η καλύτερη επιλογή για scraping εκατομμυρίων σελίδων με αστραπιαία ταχύτητα.
Συμπέρασμα:
Αν ξεκινάς τώρα ή θέλεις να βγάλεις αποτέλεσμα γρήγορα, η Python είναι η καλύτερη γλώσσα για web scraping — τελεία. .
JavaScript & Node.js: Scraping δυναμικών websites χωρίς κόπο
Αν η Python είναι ο ελβετικός σουγιάς, η JavaScript (και το Node.js) είναι το ηλεκτρικό δράπανο — ειδικά για μοντέρνα sites που «στήνονται» με JavaScript.
Γιατί JavaScript/Node.js;
- Φτιαγμένη για δυναμικό περιεχόμενο: Τρέχει στο περιβάλλον του browser, άρα «βλέπει» ό,τι βλέπει ο χρήστης — ακόμη κι αν το site είναι React, Angular ή Vue.
- Async από τη φύση της: Το Node.js μπορεί να σηκώσει εκατοντάδες αιτήματα ταυτόχρονα.
- Οικεία στους web devs: Αν έχεις φτιάξει site, ήδη μιλάς JavaScript.
Βασικές βιβλιοθήκες:
- : Αυτοματοποίηση Headless Chrome.
- : Αυτοματοποίηση πολλών browsers.
- : Parsing HTML τύπου jQuery για Node.
Παράδειγμα Node.js: Scraping τίτλου σελίδας με Puppeteer
1const puppeteer = require('puppeteer');
2(async () => {
3 const browser = await puppeteer.launch();
4 const page = await browser.newPage();
5 await page.goto('<https://example.com>', { waitUntil: 'networkidle2' });
6 const title = await page.title();
7 console.log(`Page title: ${title}`);
8 await browser.close();
9})();Δυνατά σημεία:
- Διαχειρίζεται εγγενώς περιεχόμενο που γίνεται render με JavaScript.
- Τέλειο για infinite scroll, pop-ups και διαδραστικά sites.
- Αποδοτικό για concurrent scraping μεγάλης κλίμακας.
Περιορισμοί:
- Το async μπορεί να μπερδέψει αρχάριους.
- Οι headless browsers τρώνε μνήμη αν τρέξεις πολλούς ταυτόχρονα.
- Λιγότερα εργαλεία ανάλυσης δεδομένων σε σχέση με Python.
Πότε είναι η JavaScript/Node.js η καλύτερη γλώσσα για web scraping;
Όταν ο στόχος σου είναι δυναμικός ή όταν θέλεις να αυτοματοποιήσεις ενέργειες μέσα στον browser. .
Ruby: Καθαρή σύνταξη για γρήγορα scripts web scraping
Η Ruby δεν είναι μόνο για Rails και «ποιητικό» κώδικα. Είναι και μια τίμια επιλογή για web scraping — ειδικά αν σου αρέσει ο κώδικας να διαβάζεται σαν χαϊκού.
Γιατί Ruby;
- Ευανάγνωστη, εκφραστική σύνταξη: Γράφεις scraper που διαβάζεται σχεδόν σαν λίστα για το σούπερ μάρκετ.
- Ιδανική για prototyping: Γρήγορη στη συγγραφή, εύκολη στις αλλαγές.
- Βασικές βιβλιοθήκες: για parsing, για αυτοματοποίηση πλοήγησης.
Παράδειγμα Ruby: Scraping τίτλου σελίδας
1require 'open-uri'
2require 'nokogiri'
3html = URI.open("<https://example.com>")
4doc = Nokogiri::HTML(html)
5title = doc.at('title').text
6puts "Page title: #{title}"Δυνατά σημεία:
- Πολύ καθαρή και συνοπτική.
- Ιδανική για μικρά projects, one-off scripts ή αν ήδη δουλεύεις Ruby.
Περιορισμοί:
- Πιο αργή από Python ή Node.js σε μεγάλα workloads.
- Λιγότερες βιβλιοθήκες και μικρότερη κοινότητα ειδικά για scraping.
- Όχι ιδανική για sites με πολύ JavaScript (αν και μπορείς να χρησιμοποιήσεις Watir ή Selenium).
Πού ταιριάζει καλύτερα:
Αν είσαι Rubyist ή θέλεις να στήσεις γρήγορα ένα script, η Ruby είναι απόλαυση. Για τεράστιο, δυναμικό scraping, καλύτερα να κοιτάξεις αλλού.
PHP: Απλότητα στον server για εξαγωγή δεδομένων από το web
Η PHP μπορεί να σου βγάζει «παλιά σχολή», αλλά είναι ακόμα εδώ — ειδικά αν θες να κάνεις scraping κατευθείαν στον server σου.
Γιατί PHP;
- Τρέχει παντού: Οι περισσότεροι web servers έχουν ήδη PHP.
- Εύκολη ενσωμάτωση σε web apps: Κάνεις scrape και εμφανίζεις δεδομένα στο site σου σε μία ροή.
- Βασικές βιβλιοθήκες: για HTTP, για requests, για headless browser automation.
Παράδειγμα PHP: Scraping τίτλου σελίδας
1<?php
2$ch = curl_init("<https://example.com>");
3curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
4$html = curl_exec($ch);
5curl_close($ch);
6$dom = new DOMDocument();
7@$dom->loadHTML($html);
8$title = $dom->getElementsByTagName("title")->item(0)->nodeValue;
9echo "Page title: $title\n";
10?>Δυνατά σημεία:
- Εύκολη ανάπτυξη/ανέβασμα σε servers.
- Καλή όταν το scraping είναι μέρος ενός web workflow.
- Γρήγορη για απλές εργασίες scraping στην πλευρά του server.
Περιορισμοί:
- Περιορισμένη υποστήριξη βιβλιοθηκών για πιο «βαθύ» scraping.
- Δεν είναι φτιαγμένη για υψηλό concurrency ή scraping σε μεγάλη κλίμακα.
- Τα sites με πολύ JavaScript είναι ζόρικα (αν και το Panther βοηθά).
Πού ταιριάζει καλύτερα:
Αν το stack σου είναι ήδη PHP ή θέλεις να κάνεις scrape και να εμφανίζεις δεδομένα στο site σου, η PHP είναι πρακτική επιλογή. .
C++: Web scraping υψηλής απόδοσης για μεγάλης κλίμακας projects
Η C++ είναι το «muscle car» των γλωσσών. Αν θες ωμή ταχύτητα και απόλυτο έλεγχο — και δεν σε τρομάζει λίγη χειρωνακτική δουλειά — μπορεί να σε πάει πολύ μακριά.
Γιατί C++;
- Αστραπιαία: Ξεπερνά τις περισσότερες γλώσσες σε CPU-bound εργασίες.
- Λεπτομερής έλεγχος: Μνήμη, threads, βελτιστοποιήσεις απόδοσης.
- Βασικές βιβλιοθήκες: για HTTP, για parsing.
Παράδειγμα C++: Scraping τίτλου σελίδας
1#include <curl/curl.h>
2#include <iostream>
3#include <string>
4size_t WriteCallback(void* contents, size_t size, size_t nmemb, void* userp) {
5 std::string* html = static_cast<std::string*>(userp);
6 size_t totalSize = size * nmemb;
7 html->append(static_cast<char*>(contents), totalSize);
8 return totalSize;
9}
10int main() {
11 CURL* curl = curl_easy_init();
12 std::string html;
13 if(curl) {
14 curl_easy_setopt(curl, CURLOPT_URL, "<https://example.com>");
15 curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
16 curl_easy_setopt(curl, CURLOPT_WRITEDATA, &html);
17 CURLcode res = curl_easy_perform(curl);
18 curl_easy_cleanup(curl);
19 }
20 std::size_t startPos = html.find("<title>");
21 std::size_t endPos = html.find("</title>");
22 if(startPos != std::string::npos && endPos != std::string::npos) {
23 startPos += 7;
24 std::string title = html.substr(startPos, endPos - startPos);
25 std::cout << "Page title: " << title << std::endl;
26 } else {
27 std::cout << "Title tag not found" << std::endl;
28 }
29 return 0;
30}Δυνατά σημεία:
- Ασύγκριτη ταχύτητα για τεράστιες εργασίες scraping.
- Ιδανική για ενσωμάτωση scraping σε συστήματα υψηλής απόδοσης.
Περιορισμοί:
- Απότομη καμπύλη εκμάθησης.
- Χειροκίνητη διαχείριση μνήμης.
- Λίγες high-level βιβλιοθήκες· όχι ιδανική για δυναμικό περιεχόμενο.
Πού ταιριάζει καλύτερα:
Όταν πρέπει να κάνεις scrape εκατομμύρια σελίδες ή όταν η απόδοση είναι απολύτως κρίσιμη. Αλλιώς, μπορεί να κάψεις περισσότερο χρόνο σε debugging παρά σε scraping.
Java: Web scraping λύσεις έτοιμες για enterprise
Η Java είναι το «εργαλείο δουλειάς» στον enterprise κόσμο. Αν φτιάχνεις κάτι που πρέπει να τρέχει για πάντα, να σηκώνει πολύ data και να στέκεται όρθιο σε κάθε σενάριο, η Java είναι δυνατός σύμμαχος.
Γιατί Java;
- Σταθερή και κλιμακώσιμη: Ιδανική για μεγάλα, μακροχρόνια scraping projects.
- Strong typing και error handling: Λιγότερες εκπλήξεις στην παραγωγή.
- Βασικές βιβλιοθήκες: για parsing, για browser automation, για HTTP.
Παράδειγμα Java: Scraping τίτλου σελίδας
1import org.jsoup.Jsoup;
2import org.jsoup.nodes.Document;
3public class ScrapeTitle {
4 public static void main(String[] args) throws Exception {
5 Document doc = Jsoup.connect("<https://example.com>").get();
6 String title = doc.title();
7 System.out.println("Page title: " + title);
8 }
9}Δυνατά σημεία:
- Υψηλή απόδοση και concurrency.
- Εξαιρετική για μεγάλα, συντηρήσιμα codebases.
- Καλή υποστήριξη για δυναμικό περιεχόμενο (μέσω Selenium ή HtmlUnit).
Περιορισμοί:
- Πιο «φλύαρη» σύνταξη· περισσότερο setup από scripting γλώσσες.
- Υπερβολή για μικρά, one-off scripts.
Πού ταιριάζει καλύτερα:
Scraping σε enterprise κλίμακα ή όταν χρειάζεσαι αξιοπιστία και κλιμάκωση χωρίς συμβιβασμούς.
Go (Golang): Γρήγορο και concurrent web scraping
Η Go είναι σχετικά νέα, αλλά ήδη κάνει μπαμ — ειδικά για scraping υψηλής ταχύτητας με concurrency.
Γιατί Go;
- Ταχύτητα compiled γλώσσας: Σχεδόν όσο γρήγορη όσο η C++.
- Concurrency ενσωματωμένο: Τα goroutines κάνουν το παράλληλο scraping παιχνιδάκι.
- Βασικές βιβλιοθήκες: για scraping, για parsing.
Παράδειγμα Go: Scraping τίτλου σελίδας
1package main
2import (
3 "fmt"
4 "github.com/gocolly/colly"
5)
6func main() {
7 c := colly.NewCollector()
8 c.OnHTML("title", func(e *colly.HTMLElement) {
9 fmt.Println("Page title:", e.Text)
10 })
11 err := c.Visit("<https://example.com>")
12 if err != nil {
13 fmt.Println("Error:", err)
14 }
15}Δυνατά σημεία:
- Πολύ γρήγορη και αποδοτική για scraping μεγάλης κλίμακας.
- Εύκολη ανάπτυξη (ένα binary).
- Εξαιρετική για concurrent crawling.
Περιορισμοί:
- Μικρότερη κοινότητα από Python ή Node.js.
- Λιγότερες high-level βιβλιοθήκες scraping.
- Για sites με πολύ JavaScript χρειάζεται έξτρα setup (Chromedp ή Selenium).
Πού ταιριάζει καλύτερα:
Όταν χρειάζεσαι scraping σε κλίμακα ή όταν η Python δεν «βγαίνει» σε ταχύτητα. .
Σύγκριση των καλύτερων γλωσσών προγραμματισμού για Web Scraping
Ας τα βάλουμε όλα σε μία εικόνα. Παρακάτω είναι μια σύγκριση δίπλα-δίπλα για να διαλέξεις την καλύτερη γλώσσα για web scraping το 2026:
| Γλώσσα/Εργαλείο | Ευκολία χρήσης | Απόδοση | Υποστήριξη βιβλιοθηκών | Διαχείριση δυναμικού περιεχομένου | Καλύτερη χρήση |
|---|---|---|---|---|---|
| Python | Πολύ υψηλή | Μέτρια | Εξαιρετική | Καλή (Selenium/Playwright) | Γενικής χρήσης, αρχάριοι, ανάλυση δεδομένων |
| JavaScript/Node.js | Μέτρια | Υψηλή | Ισχυρή | Εξαιρετική (εγγενώς) | Δυναμικά sites, async scraping, web devs |
| Ruby | Υψηλή | Μέτρια | Αξιοπρεπής | Περιορισμένη (Watir) | Γρήγορα scripts, prototyping |
| PHP | Μέτρια | Μέτρια | Μέτρια | Περιορισμένη (Panther) | Server-side, ενσωμάτωση σε web apps |
| C++ | Χαμηλή | Πολύ υψηλή | Περιορισμένη | Πολύ περιορισμένη | Κρίσιμη απόδοση, τεράστια κλίμακα |
| Java | Μέτρια | Υψηλή | Καλή | Καλή (Selenium/HtmlUnit) | Enterprise, υπηρεσίες που τρέχουν συνεχώς |
| Go (Golang) | Μέτρια | Πολύ υψηλή | Αναπτυσσόμενη | Μέτρια (Chromedp) | Υψηλή ταχύτητα, concurrent scraping |
Πότε να αποφύγεις τον κώδικα: Thunderbit ως no-code λύση για Web Scraping
Ας το πούμε όπως είναι: κάποιες φορές θες απλώς τα δεδομένα — χωρίς κώδικα, χωρίς debugging, χωρίς το κλασικό «μα γιατί δεν πιάνει αυτός ο selector;». Εκεί κουμπώνει το .
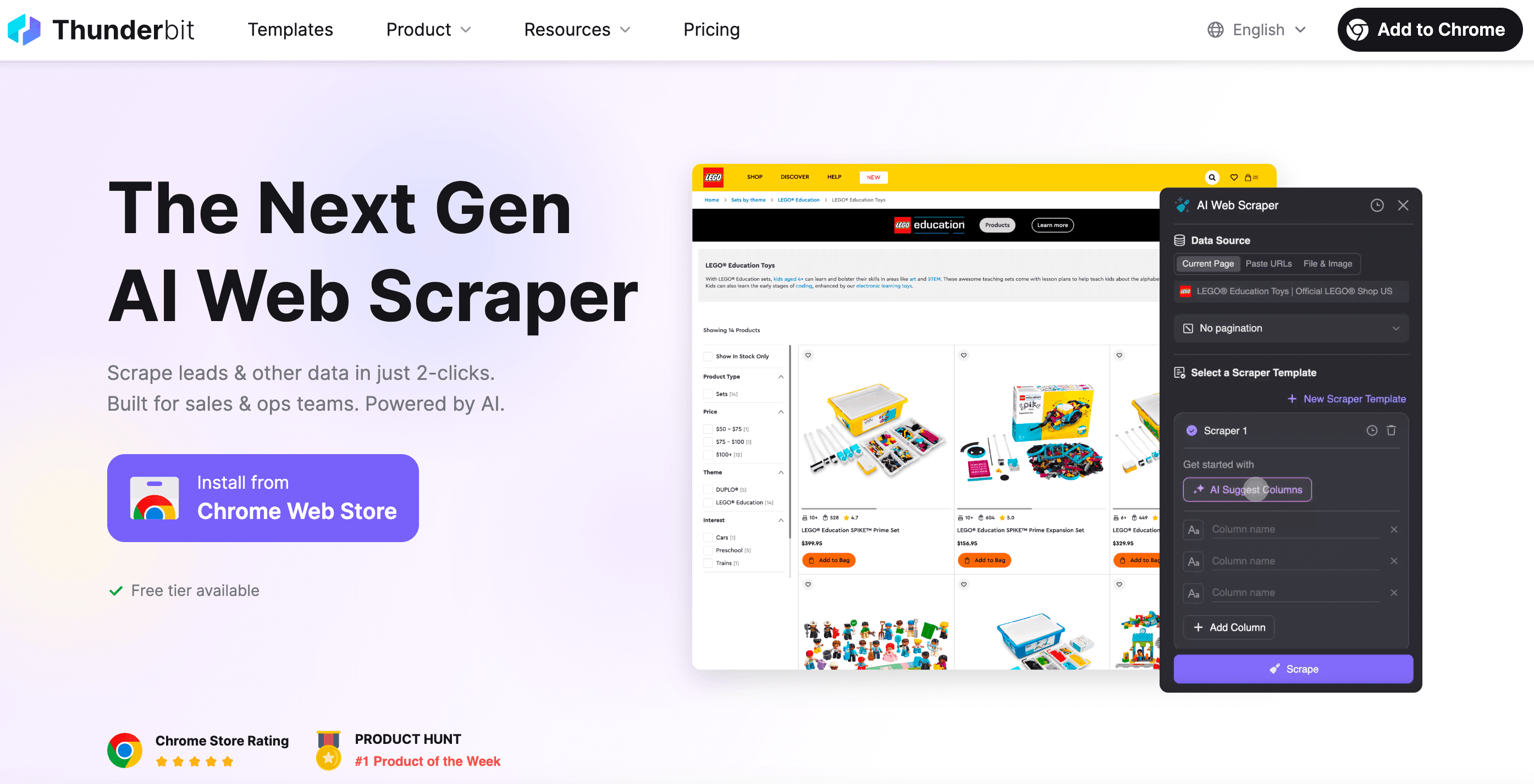
Ως συνιδρυτής του Thunderbit, ο στόχος μου ήταν να φτιάξω ένα εργαλείο που κάνει το web scraping τόσο απλό όσο το να παραγγείλεις φαγητό. Τι είναι αυτό που κάνει το Thunderbit να ξεχωρίζει:
- Ρύθμιση σε 2 κλικ: Πατάς «AI Suggest Fields» και μετά «Scrape». Χωρίς δράματα με HTTP requests, proxies ή anti-bot τρικ.
- Έξυπνα templates: Ένα scraper template προσαρμόζεται σε διαφορετικά layouts. Δεν ξαναγράφεις scraper κάθε φορά που αλλάζει ένα site.
- Scraping σε Browser & Cloud: Διαλέγεις scraping μέσα από τον browser (τέλειο για sites με login) ή στο cloud (σφαίρα για δημόσια δεδομένα).
- Διαχειρίζεται δυναμικό περιεχόμενο: Η AI του Thunderbit δουλεύει με πραγματικό browser — άρα μπορεί να χειριστεί infinite scroll, pop-ups, logins και άλλα ωραία.
- Εξαγωγή παντού: Κατέβασμα σε Excel, Google Sheets, Airtable, Notion ή απλή αντιγραφή στο clipboard.
- Χωρίς συντήρηση: Αν αλλάξει το site, απλώς ξανατρέχεις την AI πρόταση πεδίων. Τέλος τα ξενύχτια με debugging.
- Προγραμματισμός & αυτοματοποίηση: Ρυθμίζεις scrapers να τρέχουν σε πρόγραμμα — χωρίς cron jobs και χωρίς server setup.
- Εξειδικευμένοι extractors: Θες emails, τηλέφωνα ή εικόνες; Το Thunderbit έχει one-click extractors και γι’ αυτά.
Και το καλύτερο; Δεν χρειάζεται να ξέρεις ούτε μία γραμμή κώδικα. Το Thunderbit είναι φτιαγμένο για business users, marketers, ομάδες πωλήσεων, επαγγελματίες real estate — γενικά για όποιον χρειάζεται δεδομένα, χτες.
Θες να το δεις live; ή δες demos στο .
Συμπέρασμα: Πώς να διαλέξεις την καλύτερη γλώσσα για Web Scraping το 2026
Το web scraping το 2026 είναι πιο προσβάσιμο — και πιο δυνατό — από ποτέ. Μετά από χρόνια «στα χαρακώματα» της αυτοματοποίησης, αυτά είναι τα βασικά:
- Η Python παραμένει η καλύτερη γλώσσα για web scraping αν θες να ξεκινήσεις γρήγορα και να έχεις άφθονους πόρους.
- Η JavaScript/Node.js είναι ασυναγώνιστη για δυναμικά sites με πολύ JavaScript.
- Η Ruby και η PHP είναι εξαιρετικές για γρήγορα scripts και web ενσωμάτωση, ειδικά αν τις δουλεύεις ήδη.
- Η C++ και η Go είναι ιδανικές όταν χρειάζεσαι ταχύτητα και κλίμακα.
- Η Java είναι η κλασική επιλογή για enterprise και μακροχρόνια projects.
- Και αν θες να αποφύγεις εντελώς τον κώδικα; Το είναι το «κρυφό σου όπλο».
Πριν ξεκινήσεις, κάνε στον εαυτό σου μερικές ερωτήσεις:
- Πόσο μεγάλο είναι το project μου;
- Χρειάζεται να χειριστώ δυναμικό περιεχόμενο;
- Πόσο άνετα είμαι τεχνικά;
- Θέλω να χτίσω λύση ή απλώς να πάρω τα δεδομένα;
Δοκίμασε ένα από τα snippets παραπάνω ή βάλε το Thunderbit στο επόμενο project σου. Και αν θες να το πας πιο βαθιά, δες το για περισσότερους οδηγούς, tips και ιστορίες από πραγματικά scraping projects.
Καλό scraping — και μακάρι τα δεδομένα σου να είναι πάντα καθαρά, δομημένα και… ένα κλικ μακριά.
Υ.Γ. Αν ποτέ χαθείς σε rabbit hole web scraping στις 2 τα ξημερώματα, θυμήσου: υπάρχει πάντα το Thunderbit. Ή ο καφές. Ή και τα δύο.
Συχνές Ερωτήσεις (FAQs)
1. Ποια είναι η καλύτερη γλώσσα προγραμματισμού για web scraping το 2026;
Η Python παραμένει η κορυφαία επιλογή χάρη στην ευανάγνωστη σύνταξη, τις ισχυρές βιβλιοθήκες (όπως BeautifulSoup, Scrapy και Selenium) και τη μεγάλη κοινότητα. Είναι ιδανική τόσο για αρχάριους όσο και για επαγγελματίες, ειδικά όταν συνδυάζεις scraping με ανάλυση δεδομένων.
2. Ποια γλώσσα είναι καλύτερη για scraping σε websites με πολύ JavaScript;
Η JavaScript (Node.js) είναι η καλύτερη επιλογή για δυναμικά sites. Εργαλεία όπως Puppeteer και Playwright σου δίνουν πλήρη έλεγχο του browser, ώστε να αλληλεπιδράς με περιεχόμενο που φορτώνεται μέσω React, Vue ή Angular.
3. Υπάρχει no-code επιλογή για web scraping;
Ναι — το είναι ένα no-code AI Web Scraper που καλύπτει τα πάντα: από δυναμικό περιεχόμενο μέχρι scheduling. Απλώς πάτα «AI Suggest Fields» και ξεκίνα. Είναι ιδανικό για ομάδες πωλήσεων, marketing ή operations που χρειάζονται δομημένα δεδομένα γρήγορα.
Μάθε περισσότερα: