Σπασμένοι σύνδεσμοι. Ορφανές σελίδες. Μια σελίδα “test” από το 2019 που, κάπως, την έχει ευρετηριάσει η Google. Αν διαχειρίζεσαι site, ξέρεις ακριβώς τι ζόρι είναι αυτό.
Ένας καλός crawler ιστοσελίδας τα ξετρυπώνει όλα — και σου χαρτογραφεί όλο το site για να διορθώσεις ό,τι χρειάζεται. Παρ’ όλα αυτά, πολλοί μπερδεύουν το web crawling με το web scraping. Και όχι, δεν είναι το ίδιο πράγμα.
Δοκίμασα 10 δωρεάν crawlers πάνω σε πραγματικές ιστοσελίδες. Κάποιοι είναι φοβεροί για SEO audits. Άλλοι “γράφουν” περισσότερο όταν θες εξαγωγή δεδομένων. Παρακάτω θα δεις τι έπιασε τόπο — και τι με άφησε παγωτό.
Τι είναι ένας Website Crawler; Τα βασικά με απλά λόγια
Ας το βάλουμε σε τάξη από την αρχή: ένας website crawler δεν είναι το ίδιο με έναν web scraper. Ναι, στην καθημερινή κουβέντα οι όροι συχνά παίζουν σαν συνώνυμα, αλλά στην πράξη κάνουν άλλη δουλειά. Σκέψου τον crawler σαν τον “χαρτογράφο” του site σου: τριγυρνά παντού, ακολουθεί κάθε link και φτιάχνει έναν “χάρτη” με όλες τις σελίδες. Η αποστολή του είναι η ανακάλυψη: να βρίσκει URLs, να αποτυπώνει τη δομή του site και να εντοπίζει/καταγράφει περιεχόμενο. Αυτό κάνουν και οι μηχανές αναζήτησης τύπου Google με τα bots τους, και πάνω σε αυτό πατάνε τα SEO εργαλεία για να τσεκάρουν την υγεία ενός site ().
Ο web scraper, από την άλλη, είναι ο “μεταλλωρύχος” των δεδομένων. Δεν τον νοιάζει να φτιάξει πλήρη χάρτη — θέλει να βγάλει το “ζουμί”: τιμές προϊόντων, ονόματα εταιρειών, αξιολογήσεις, emails, ό,τι κυνηγάς. Οι scrapers εξάγουν συγκεκριμένα πεδία από τις σελίδες που εντοπίζουν οι crawlers ().
Ώρα για αναλογία:
- Crawler: Ο τύπος που περνάει από κάθε διάδρομο σε ένα σούπερ μάρκετ και καταγράφει όλα τα προϊόντα.
- Scraper: Ο τύπος που πάει καρφί στο ράφι με τους καφέδες και σημειώνει την τιμή για κάθε βιολογικό χαρμάνι.
Γιατί έχει σημασία; Γιατί αν θες απλώς να βρεις όλες τις σελίδες του site σου (π.χ. για SEO audit), θες crawler. Αν θες να τραβήξεις όλες τις τιμές προϊόντων από το site ενός ανταγωνιστή, θες scraper — ή, ιδανικά, ένα εργαλείο που τα κάνει και τα δύο.
Γιατί να χρησιμοποιήσεις Online Web Crawler; Τα βασικά οφέλη για την επιχείρηση
Γιατί να μπεις σε αυτή τη διαδικασία; Γιατί το web δεν “μαζεύεται” — φουσκώνει. Πάνω από για να βελτιστοποιούν τα sites τους, ενώ κάποια SEO εργαλεία κάνουν crawl .
Τι μπορεί να σου δώσει ένας crawler ιστοσελίδας:
- SEO Audits: Εντοπισμός σπασμένων links, ελλιπών τίτλων, διπλότυπου περιεχομένου, orphan pages και πολλά ακόμη ().
- Έλεγχος links & QA: Πιάνει 404 και redirect loops πριν τα φάνε στη μάπα οι χρήστες σου ().
- Δημιουργία sitemap: Αυτόματη παραγωγή XML sitemaps για μηχανές αναζήτησης και για εσωτερικό σχεδιασμό ().
- Απογραφή περιεχομένου: Λίστα με όλες τις σελίδες, την ιεραρχία τους και τα metadata.
- Συμμόρφωση & προσβασιμότητα: Έλεγχος κάθε σελίδας για WCAG, SEO και νομική συμμόρφωση ().
- Απόδοση & ασφάλεια: Εντοπισμός αργών σελίδων, υπερβολικά μεγάλων εικόνων ή θεμάτων ασφαλείας ().
- Δεδομένα για AI & ανάλυση: Χρήση των δεδομένων του crawl σε analytics ή AI εργαλεία ().
Ένας γρήγορος πίνακας που δένει use cases με ρόλους:
| Use Case | Ιδανικό για | Όφελος / Αποτέλεσμα |
|---|---|---|
| SEO & Site Auditing | Marketing, SEO, Ιδιοκτήτες μικρών επιχειρήσεων | Εντοπισμός τεχνικών θεμάτων, βελτιστοποίηση δομής, καλύτερες κατατάξεις |
| Content Inventory & QA | Content Managers, Webmasters | Έλεγχος ή μεταφορά περιεχομένου, εντοπισμός σπασμένων links/εικόνων |
| Lead Generation (Scraping) | Πωλήσεις, Biz Dev | Αυτοματοποίηση prospecting, ενημέρωση CRM με φρέσκα leads |
| Competitive Intelligence | E-commerce, Product Managers | Παρακολούθηση τιμών ανταγωνιστών, νέων προϊόντων, αλλαγών αποθέματος |
| Sitemap & Structure Cloning | Developers, DevOps, Consultants | Αντιγραφή δομής για redesign ή backups |
| Content Aggregation | Ερευνητές, Media, Analysts | Συλλογή δεδομένων από πολλά sites για ανάλυση ή παρακολούθηση τάσεων |
| Market Research | Analysts, ομάδες AI Training | Συλλογή μεγάλων datasets για ανάλυση ή εκπαίδευση μοντέλων AI |
()
Πώς επιλέξαμε τα καλύτερα δωρεάν εργαλεία Website Crawler
Έχω ξενυχτήσει αρκετά (και έχω πιει περισσότερους καφέδες απ’ όσους σηκώνει η αξιοπρέπεια) δοκιμάζοντας crawlers, διαβάζοντας τεκμηρίωση και τρέχοντας δοκιμαστικά crawls. Αυτά ήταν τα κριτήριά μου:
- Τεχνικές δυνατότητες: Στέκεται σε σύγχρονα sites (JavaScript, logins, δυναμικό περιεχόμενο);
- Ευκολία χρήσης: Είναι φιλικό για μη τεχνικούς ή θέλει “μαγικά” σε command line;
- Όρια δωρεάν πλάνου: Είναι όντως δωρεάν ή απλώς “δόλωμα”;
- Online πρόσβαση: Είναι cloud εργαλείο, desktop app ή βιβλιοθήκη κώδικα;
- Μοναδικά χαρακτηριστικά: Έχει κάτι ξεχωριστό — όπως AI extraction, οπτικά sitemaps ή event-driven crawling;
Δοκίμασα κάθε εργαλείο, τσέκαρα feedback χρηστών και έβαλα δυνατότητες δίπλα-δίπλα. Αν ένα εργαλείο με έκανε να θέλω να πετάξω το laptop από το παράθυρο, απλά δεν πέρασε.
Πίνακας σύγκρισης: 10 κορυφαίοι δωρεάν Website Crawlers με μια ματιά
| Εργαλείο & Τύπος | Βασικές δυνατότητες | Καλύτερο για | Τεχνικές απαιτήσεις | Λεπτομέρειες δωρεάν πλάνου |
|---|---|---|---|---|
| BrightData (Cloud/API) | Enterprise crawling, proxies, JS rendering, επίλυση CAPTCHA | Συλλογή δεδομένων μεγάλης κλίμακας | Χρήσιμες βασικές τεχνικές γνώσεις | Δωρεάν δοκιμή: 3 scrapers, 100 records ο καθένας (περίπου 300 συνολικά) |
| Crawlbase (Cloud/API) | Crawling μέσω API, anti-bot, proxies, JS rendering | Devs που θέλουν υποδομή crawling στο backend | Ενσωμάτωση API | Δωρεάν: ~5.000 API calls για 7 ημέρες, μετά 1.000/μήνα |
| ScraperAPI (Cloud/API) | Εναλλαγή proxies, JS rendering, async crawl, έτοιμα endpoints | Devs, παρακολούθηση τιμών, SEO data | Ελάχιστο setup | Δωρεάν: 5.000 API calls για 7 ημέρες, μετά 1.000/μήνα |
| Diffbot Crawlbot (Cloud) | AI crawl + εξαγωγή, knowledge graph, JS rendering | Δομημένα δεδομένα σε κλίμακα, AI/ML | Ενσωμάτωση API | Δωρεάν: 10.000 credits/μήνα (περίπου 10k σελίδες) |
| Screaming Frog (Desktop) | SEO audit, ανάλυση links/meta, sitemap, custom extraction | SEO audits, διαχειριστές site | Desktop app, GUI | Δωρεάν: 500 URLs ανά crawl, μόνο βασικές λειτουργίες |
| SiteOne Crawler (Desktop) | SEO, performance, accessibility, security, offline export, Markdown | Devs, QA, migration, τεκμηρίωση | Desktop/CLI, GUI | Δωρεάν & open-source, 1.000 URLs στο GUI report (ρυθμιζόμενο) |
| Crawljax (Java, OpenSrc) | Event-driven crawl για JS-heavy sites, static export | Devs, QA για δυναμικές web εφαρμογές | Java, CLI/config | Δωρεάν & open-source, χωρίς όρια |
| Apache Nutch (Java, OpenSrc) | Distributed, plugins, Hadoop integration, custom search | Custom search engines, crawling μεγάλης κλίμακας | Java, command-line | Δωρεάν & open-source, μόνο κόστος υποδομής |
| YaCy (Java, OpenSrc) | Peer-to-peer crawl & search, privacy, indexing web/intranet | Ιδιωτική αναζήτηση, αποκέντρωση | Java, browser UI | Δωρεάν & open-source, χωρίς όρια |
| PowerMapper (Desktop/SaaS) | Οπτικά sitemaps, accessibility, QA, browser compatibility | Agencies, QA, οπτική χαρτογράφηση | GUI, εύκολο | Δωρεάν δοκιμή: 30 ημέρες, 100 σελίδες (desktop) ή 10 σελίδες (online) ανά scan |
BrightData: Cloud Website Crawler επιπέδου enterprise

Το BrightData είναι το “βαρύ πυροβολικό” στο web crawling. Είναι cloud πλατφόρμα με τεράστιο proxy network, JavaScript rendering, επίλυση CAPTCHA και IDE για custom crawls. Αν κάνεις συλλογή δεδομένων σε μεγάλη κλίμακα — π.χ. παρακολούθηση τιμών σε εκατοντάδες e-commerce sites — η υποδομή του BrightData δύσκολα κοντράρεται ().
Δυνατά σημεία:
- Σπάει “δύσκολα” sites με anti-bot μηχανισμούς
- Κλιμακώνεται άνετα για enterprise ανάγκες
- Έτοιμα templates για δημοφιλή sites
Περιορισμοί:
- Δεν έχει μόνιμο δωρεάν πλάνο (μόνο trial: 3 scrapers, 100 records ο καθένας)
- Υπερβολή για απλά audits
- Θέλει χρόνο εξοικείωσης για μη τεχνικούς
Αν χρειάζεσαι crawling σε κλίμακα, το BrightData είναι σαν να νοικιάζεις μονοθέσιο Formula 1. Απλώς μην περιμένεις να μείνει δωρεάν μετά το test drive ().
Crawlbase: Δωρεάν Web Crawler μέσω API για developers

Το Crawlbase (πρώην ProxyCrawl) είναι στημένο για προγραμματιστικό crawling. Καλείς το API με ένα URL και σου επιστρέφει το HTML — ενώ από πίσω χειρίζεται proxies, geotargeting και CAPTCHAs ().
Δυνατά σημεία:
- Πολύ υψηλά ποσοστά επιτυχίας (99%+)
- Διαχειρίζεται sites με έντονο JavaScript
- Ιδανικό για ενσωμάτωση σε δικές σου εφαρμογές ή workflows
Περιορισμοί:
- Θέλει ενσωμάτωση API ή SDK
- Δωρεάν πλάνο: ~5.000 API calls για 7 ημέρες, μετά 1.000/μήνα
Αν είσαι developer και θες crawling (και πιθανώς scraping) σε κλίμακα χωρίς να στήσεις/συντηρείς proxies, το Crawlbase είναι πολύ τίμια επιλογή ().
ScraperAPI: Πιο απλό crawling για δυναμικές σελίδες

Το ScraperAPI είναι το API τύπου “φέρε μου τη σελίδα και άσε τα δύσκολα σε μένα”. Του δίνεις URL, αυτό αναλαμβάνει proxies, headless browsers και anti-bot μηχανισμούς και σου επιστρέφει HTML (ή δομημένα δεδομένα για ορισμένα sites). Είναι πολύ δυνατό σε δυναμικές σελίδες και έχει γενναιόδωρο δωρεάν επίπεδο χρήσης ().
Δυνατά σημεία:
- Πολύ εύκολο για developers (ουσιαστικά ένα API call)
- Διαχειρίζεται CAPTCHAs, IP bans, JavaScript
- Δωρεάν: 5.000 API calls για 7 ημέρες, μετά 1.000/μήνα
Περιορισμοί:
- Δεν δίνει οπτικές αναφορές crawl
- Αν θες να ακολουθεί links, πρέπει να γράψεις εσύ τη λογική του crawl
Αν θες να “κουμπώσεις” web crawling στον κώδικά σου μέσα σε λίγα λεπτά, το ScraperAPI είναι από τις πιο προφανείς επιλογές.
Diffbot Crawlbot: Αυτόματη ανακάλυψη δομής site με AI

Το Diffbot Crawlbot πάει ένα βήμα παραπέρα: δεν κάνει μόνο crawl — χρησιμοποιεί AI για να κατηγοριοποιεί σελίδες και να εξάγει δομημένα δεδομένα (άρθρα, προϊόντα, events κ.λπ.) σε JSON. Σαν να έχεις έναν “ρομποτικό ασκούμενο” που καταλαβαίνει τι βλέπει ().
Δυνατά σημεία:
- Εξαγωγή με AI, όχι απλή συλλογή σελίδων
- Υποστηρίζει JavaScript και δυναμικό περιεχόμενο
- Δωρεάν: 10.000 credits/μήνα (περίπου 10k σελίδες)
Περιορισμοί:
- Απευθύνεται κυρίως σε developers (API integration)
- Δεν είναι “οπτικό” SEO εργαλείο — ταιριάζει περισσότερο σε data projects
Αν θες δομημένα δεδομένα σε κλίμακα, ειδικά για AI ή analytics, το Diffbot είναι πραγματικό εργαλείο-δύναμη.
Screaming Frog: Δωρεάν desktop SEO crawler

Το Screaming Frog είναι ο κλασικός desktop crawler για SEO audits. Στη δωρεάν έκδοση κάνει crawl έως 500 URLs ανά σάρωση και σου βγάζει τα πάντα: σπασμένα links, meta tags, διπλότυπο περιεχόμενο, sitemaps και πολλά ακόμη ().
Δυνατά σημεία:
- Γρήγορο, λεπτομερές και “στάνταρ” στον χώρο του SEO
- Χωρίς κώδικα — βάζεις URL και ξεκινάς
- Δωρεάν έως 500 URLs ανά crawl
Περιορισμοί:
- Μόνο desktop (όχι cloud)
- Προχωρημένες λειτουργίες (JS rendering, scheduling) θέλουν πληρωμένη άδεια
Αν ασχολείσαι σοβαρά με SEO, το Screaming Frog είναι must — απλώς μην περιμένεις να κάνει crawl δωρεάν ένα site 10.000 σελίδων.
SiteOne Crawler: Export στατικού site και τεκμηρίωση

Το SiteOne Crawler είναι “ελβετικός σουγιάς” για τεχνικά audits. Είναι open-source, cross-platform και μπορεί να κάνει crawl, audit και ακόμη και export το site σου σε Markdown για τεκμηρίωση ή offline χρήση ().
Δυνατά σημεία:
- Καλύπτει SEO, performance, accessibility, security
- Export για αρχειοθέτηση ή migration
- Δωρεάν & open-source, χωρίς όρια χρήσης
Περιορισμοί:
- Πιο τεχνικό από κάποια καθαρά GUI εργαλεία
- Το GUI report περιορίζεται σε 1.000 URLs από προεπιλογή (ρυθμίζεται)
Αν είσαι developer, QA ή consultant και θες βαθιά εικόνα (και γουστάρεις open source), το SiteOne είναι κρυφό διαμαντάκι.
Crawljax: Open-source Java crawler για δυναμικές σελίδες
Το Crawljax είναι “ειδική περίπτωση”: έχει σχεδιαστεί για σύγχρονες web εφαρμογές με πολύ JavaScript, κάνοντας προσομοίωση αλληλεπιδράσεων χρήστη (clicks, συμπλήρωση φορμών κ.λπ.). Είναι event-driven και μπορεί ακόμη να παράγει στατική έκδοση ενός δυναμικού site ().
Δυνατά σημεία:
- Ασυναγώνιστο για SPAs και AJAX-heavy sites
- Open-source και επεκτάσιμο
- Χωρίς όρια χρήσης
Περιορισμοί:
- Θέλει Java και προγραμματισμό/ρύθμιση
- Δεν είναι για μη τεχνικούς
Αν πρέπει να κάνεις crawl μια React ή Angular εφαρμογή “σαν κανονικός χρήστης”, το Crawljax είναι ο άνθρωπός σου.
Apache Nutch: Κλιμακούμενος distributed crawler

Το Apache Nutch είναι από τους “παππούδες” των open-source crawlers. Είναι φτιαγμένο για τεράστια, κατανεμημένα crawls — π.χ. για να στήσεις δική σου μηχανή αναζήτησης ή να ευρετηριάσεις εκατομμύρια σελίδες ().
Δυνατά σημεία:
- Κλιμακώνεται έως δισεκατομμύρια σελίδες με Hadoop
- Πολύ παραμετροποιήσιμο και επεκτάσιμο
- Δωρεάν & open-source
Περιορισμοί:
- Απότομη καμπύλη εκμάθησης (Java, command-line, configs)
- Όχι για μικρά sites ή περιστασιακή χρήση
Αν θες crawling σε κλίμακα και δεν σε τρομάζει το command line, το Nutch είναι το εργαλείο σου.
YaCy: Peer-to-peer crawler και μηχανή αναζήτησης
Το YaCy είναι μια ιδιαίτερη, αποκεντρωμένη λύση crawling και αναζήτησης. Κάθε instance κάνει crawl και indexing, και μπορείς να μπεις σε peer-to-peer δίκτυο ώστε να μοιράζεσαι indexes με άλλους ().
Δυνατά σημεία:
- Έμφαση στην ιδιωτικότητα, χωρίς κεντρικό server
- Ιδανικό για ιδιωτική αναζήτηση ή intranet search
- Δωρεάν & open-source
Περιορισμοί:
- Η ποιότητα αποτελεσμάτων εξαρτάται από την κάλυψη του δικτύου
- Θέλει setup (Java, browser UI)
Αν σε τραβάει η αποκέντρωση ή θες τη δική σου μηχανή αναζήτησης, το YaCy είναι πολύ ψαγμένη επιλογή.
PowerMapper: Οπτικός generator sitemap για UX και QA

Το PowerMapper δίνει βάση στην οπτικοποίηση της δομής του site. Κάνει crawl και δημιουργεί διαδραστικά sitemaps, ενώ παράλληλα ελέγχει προσβασιμότητα, συμβατότητα browsers και βασικά SEO στοιχεία ().
Δυνατά σημεία:
- Τα οπτικά sitemaps είναι τέλεια για agencies και designers
- Έλεγχος προσβασιμότητας και συμμόρφωσης
- Εύκολο GUI, χωρίς τεχνικές γνώσεις
Περιορισμοί:
- Μόνο δωρεάν δοκιμή (30 ημέρες, 100 σελίδες desktop/10 σελίδες online ανά scan)
- Η πλήρης έκδοση είναι επί πληρωμή
Αν θες να παρουσιάσεις site map σε πελάτες ή να κάνεις έλεγχο συμμόρφωσης, το PowerMapper είναι πολύ βολικό.
Πώς να διαλέξεις τον σωστό δωρεάν Web Crawler για τις ανάγκες σου
Με τόσες επιλογές, πώς το αποφασίζεις; Ο γρήγορος οδηγός μου:
- Για SEO audits: Screaming Frog (μικρά sites), PowerMapper (οπτικό), SiteOne (βαθιά audits)
- Για δυναμικές web εφαρμογές: Crawljax
- Για crawling μεγάλης κλίμακας ή custom search: Apache Nutch, YaCy
- Για developers που θέλουν API: Crawlbase, ScraperAPI, Diffbot
- Για τεκμηρίωση ή αρχειοθέτηση: SiteOne Crawler
- Για enterprise κλίμακα με trial: BrightData, Diffbot
Παράγοντες που αξίζει να ζυγίσεις:
- Κλιμάκωση: Πόσο μεγάλο είναι το site ή το crawl job;
- Ευκολία: Θες point-and-click ή είσαι άνετος με κώδικα;
- Εξαγωγή δεδομένων: Χρειάζεσαι CSV, JSON ή σύνδεση με άλλα εργαλεία;
- Υποστήριξη: Υπάρχει κοινότητα ή docs όταν κολλήσεις;
Όταν το Web Crawling συναντά το Web Scraping: γιατί το Thunderbit είναι πιο έξυπνη επιλογή
Η αλήθεια είναι ότι οι περισσότεροι δεν κάνουν crawl απλώς για να φτιάξουν “ωραίους χάρτες”. Συνήθως ο στόχος είναι να πάρουν δομημένα δεδομένα — είτε μιλάμε για λίστες προϊόντων, στοιχεία επικοινωνίας ή απογραφή περιεχομένου. Εκεί μπαίνει το .
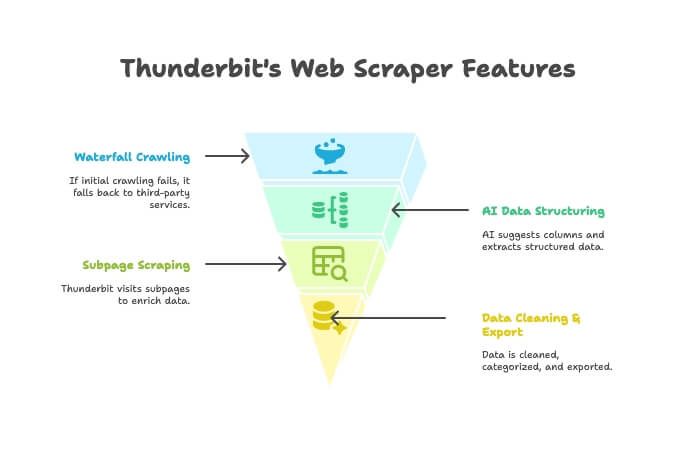
Το Thunderbit δεν είναι μόνο crawler ή μόνο scraper — είναι ένα AI-powered Chrome extension που τα συνδυάζει. Πώς δουλεύει:
- AI Crawler: Το Thunderbit εξερευνά το site όπως ένας crawler ιστοσελίδας.
- Waterfall Crawling: Αν ο δικός του μηχανισμός δεν μπορεί να “πιάσει” τη σελίδα (π.χ. λόγω ισχυρού anti-bot), κάνει αυτόματα fallback σε τρίτες υπηρεσίες crawling — χωρίς χειροκίνητο setup.
- AI δόμηση δεδομένων: Μόλις πάρει το HTML, το AI προτείνει τις σωστές στήλες και εξάγει δομημένα δεδομένα (ονόματα, τιμές, emails κ.λπ.) χωρίς να γράψεις ούτε έναν selector.
- Subpage Scraping: Θες λεπτομέρειες από κάθε σελίδα προϊόντος; Το Thunderbit μπαίνει αυτόματα σε κάθε υποσελίδα και εμπλουτίζει τον πίνακά σου.
- Καθαρισμός & export: Μπορεί να συνοψίσει, να κατηγοριοποιήσει, να μεταφράσει και να εξάγει σε Excel, Google Sheets, Airtable ή Notion με ένα κλικ.
- No-code απλότητα: Αν χρησιμοποιείς browser, μπορείς να χρησιμοποιήσεις Thunderbit. Χωρίς κώδικα, χωρίς proxies, χωρίς δράματα.
Πότε να προτιμήσεις Thunderbit αντί για έναν παραδοσιακό crawler;
- Όταν ο τελικός στόχος είναι ένα καθαρό, αξιοποιήσιμο spreadsheet — όχι απλώς μια λίστα URLs.
- Όταν θες να αυτοματοποιήσεις όλη τη ροή (crawl, extract, clean, export) σε ένα μέρος.
- Όταν εκτιμάς τον χρόνο σου (και την ψυχραιμία σου).
Μπορείς να και να δεις γιατί τόσοι business users το προτιμούν.
Συμπέρασμα: Πώς να αξιοποιήσεις στο έπακρο τους δωρεάν Website Crawlers
Οι website crawlers έχουν ανέβει επίπεδο εντυπωσιακά. Είτε είσαι marketer, developer ή απλώς θες να κρατάς το site σου “καθαρό” και “υγιές”, υπάρχει ένα δωρεάν (ή έστω free-to-try) εργαλείο για σένα. Από enterprise πλατφόρμες όπως BrightData και Diffbot, μέχρι open-source διαμαντάκια όπως SiteOne και Crawljax, και οπτικούς “χαρτογράφους” όπως το PowerMapper, οι επιλογές είναι περισσότερες από ποτέ.
Αν όμως ψάχνεις έναν πιο έξυπνο και ολοκληρωμένο τρόπο για να πας από το “χρειάζομαι αυτά τα δεδομένα” στο “ορίστε το spreadsheet μου”, δοκίμασε το Thunderbit. Είναι φτιαγμένο για business users που θέλουν αποτέλεσμα — όχι απλώς reports.
Έτοιμος να ξεκινήσεις; Κατέβασε ένα εργαλείο, τρέξε ένα scan και δες τι σου είχε ξεφύγει. Και αν θες να περάσεις από το web crawling σε αξιοποιήσιμα δεδομένα με δύο κλικ, .
Για περισσότερα deep dives και πρακτικούς οδηγούς, μπες στο .
FAQ
Ποια είναι η διαφορά ανάμεσα σε website crawler και web scraper;
Ο crawler ανακαλύπτει και χαρτογραφεί όλες τις σελίδες ενός site (σαν να φτιάχνει πίνακα περιεχομένων). Ο scraper εξάγει συγκεκριμένα πεδία δεδομένων (όπως τιμές, emails ή reviews) από αυτές τις σελίδες. Οι crawlers εντοπίζουν, οι scrapers εξάγουν ().
Ποιος δωρεάν web crawler είναι καλύτερος για μη τεχνικούς χρήστες;
Για μικρά sites και SEO audits, το Screaming Frog είναι αρκετά φιλικό. Για οπτική χαρτογράφηση, το PowerMapper είναι πολύ καλό (στη διάρκεια του trial). Το Thunderbit είναι το πιο εύκολο αν ο στόχος σου είναι δομημένα δεδομένα και θες no-code εμπειρία μέσα από τον browser.
Υπάρχουν sites που μπλοκάρουν web crawlers;
Ναι — κάποια sites χρησιμοποιούν robots.txt ή anti-bot μηχανισμούς (όπως CAPTCHAs ή IP bans) για να μπλοκάρουν crawlers. Εργαλεία όπως ScraperAPI, Crawlbase και Thunderbit (με waterfall crawling) συχνά μπορούν να το ξεπεράσουν, αλλά πάντα να κάνεις crawl υπεύθυνα και να σέβεσαι τους κανόνες του site ().
Οι δωρεάν website crawlers έχουν όρια σε σελίδες ή λειτουργίες;
Σχεδόν πάντα. Για παράδειγμα, η δωρεάν έκδοση του Screaming Frog περιορίζεται σε 500 URLs ανά crawl, ενώ το trial του PowerMapper είναι 100 σελίδες. Τα API-based εργαλεία συνήθως έχουν μηνιαία όρια credits. Open-source εργαλεία όπως SiteOne ή Crawljax συνήθως δεν έχουν “σκληρά” όρια, αλλά περιορίζεσαι από το hardware σου.
Είναι νόμιμη και privacy-compliant η χρήση web crawler;
Γενικά, το crawling δημόσιων σελίδων είναι νόμιμο, αλλά πάντα να ελέγχεις τους όρους χρήσης και το robots.txt. Μην κάνεις crawl ιδιωτικά ή password-protected δεδομένα χωρίς άδεια και πρόσεχε τη συμμόρφωση με νόμους περί ιδιωτικότητας όταν εξάγεις προσωπικά δεδομένα ().