
Το 2015, το web scraping σήμαινε είτε να παρακαλάς έναν developer να σου γράψει ένα Python script είτε να «φας» ένα ολόκληρο Σαββατοκύριακο προσπαθώντας να καταλάβεις XPath. Το 2026, απλώς γράφεις «πάρε όλα τα ονόματα προϊόντων και τις τιμές» και η AI κάνει τα υπόλοιπα — τόσο απλά.
Και το πιο τρελό; Αυτή η μετάβαση έγινε στο άψε-σβήσε. Πάνω από στηρίζονται πλέον στο web scraping. Η αγορά ξεπέρασε το και πάει ολοταχώς για διπλασιασμό μέχρι το 2030.
Ο βασικός «μοχλός» πίσω από όλα αυτά; Οι AI web crawler λύσεις. Προσαρμόζονται όταν αλλάζει το layout. «Πιάνουν» τι λέει η σελίδα, όχι μόνο τα HTML tags. Και το καλύτερο: δουλεύουν και για ανθρώπους που δεν έχουν γράψει ούτε μία γραμμή κώδικα στη ζωή τους.
Έκατσα και δοκίμασα 15 λύσεις για μήνες. Παρακάτω θα βρεις τα συμπεράσματά μου — και το γιατί το Thunderbit (ναι, η εταιρεία που συνίδρυσα) βγήκε πρώτο.
Γιατί η AI αλλάζει το Web Page Scraping: Η νέα εποχή των εργαλείων Web Scraper
Ας το πούμε όπως είναι: το παραδοσιακό web scraping δεν φτιάχτηκε ποτέ για τον μέσο επαγγελματία. Ήταν ιστορία με κώδικα, selectors και… σταυροκοπήματα για να μη «σκάσει» το script την επόμενη φορά που ένα site θα άλλαζε εμφάνιση. Με την AI και τα LLMs, το σκηνικό έχει γυρίσει ανάποδα.
Δες τι άλλαξε:
- Οδηγίες σε φυσική γλώσσα: Αντί να μπλέκεις με κώδικα, λες απλά τι θες. Εργαλεία όπως το καταλαβαίνουν οδηγίες σε απλά Αγγλικά και στήνουν την εξαγωγή για σένα ().
- Προσαρμοστική μάθηση: Οι AI Web Scraper λύσεις μπορούν να , κόβοντας δραστικά τη συντήρηση.
- Διαχείριση δυναμικού περιεχομένου: Τα σύγχρονα sites είναι γεμάτα JavaScript και infinite scroll. Τα AI εργαλεία αλληλεπιδρούν με αυτά και πιάνουν δεδομένα που οι «παλιοί» scrapers συχνά χάνουν.
- Δομημένη έξοδος με AI parsing: Οι scrapers που βασίζονται σε LLMs και επιστρέφουν καθαρά, δομημένα δεδομένα.
- Αυτόματη παράκαμψη anti-bot: Οι AI scrapers μπορούν να και να χρησιμοποιούν proxies/headless browsers για να αποφεύγουν IP blocks.
- Ενσωματωμένες ροές δεδομένων: Τα καλύτερα εργαλεία δεν «μαζεύουν» απλώς δεδομένα — στα δίνουν εκεί που τα θες, με εξαγωγή ενός κλικ σε Google Sheets, Airtable, Notion και άλλα ().
Το αποτέλεσμα; Το web scraping έγινε εμπειρία point-and-click (ή ακόμη και σαν chat), ανοίγοντας τον δρόμο σε ομάδες sales, marketing και operations — όχι μόνο σε developers — να αξιοποιούν απευθείας web data.
15 AI Web Crawlers που αξίζουν την προσοχή σου το 2026
Πάμε να δούμε τους 15 κορυφαίους AI web crawler παίκτες, ξεκινώντας από το Thunderbit. Για κάθε εργαλείο θα σου δώσω τα βασικά χαρακτηριστικά, σε ποιους ταιριάζει, τιμές και τι το κάνει να ξεχωρίζει. Και ναι — θα είμαι ωμά ειλικρινής για το πού «γράφει» το καθένα (και πού ζορίζεται).
1. Thunderbit: Το AI Web Scraper για όλους
Οκ, είμαι λίγο προκατειλημμένος, αλλά το Thunderbit είναι το AI Web Scraper που θα ήθελα να είχα στα χέρια μου πριν χρόνια. Να γιατί είναι #1 στη λίστα:
- Εξαγωγή με φυσική γλώσσα: «Μιλάς» με το Thunderbit. Περιγράφεις τι δεδομένα θες — «κάνε scrape όλα τα ονόματα προϊόντων και τις τιμές από αυτή τη σελίδα» — και η AI αναλαμβάνει (). Χωρίς κώδικα, χωρίς selectors, χωρίς δράματα.
- Crawling υποσελίδων & πολλαπλών επιπέδων: Το Thunderbit μπορεί να . Π.χ. παίρνεις λίστα προϊόντων και μετά μπαίνει σε κάθε προϊόν για λεπτομέρειες — όλα σε μία εκτέλεση.
- Άμεση δομημένη έξοδος: Η AI , προτείνοντας χρήσιμα πεδία, ομογενοποιώντας formats και ακόμη και συνοψίζοντας ή κατηγοριοποιώντας κείμενο.
- Υποστήριξη πολλών πηγών: Το Thunderbit δεν είναι μόνο για HTML — μπορεί να εξάγει από PDFs και εικόνες με ενσωματωμένο OCR και vision AI ().
- Ενσωματώσεις για επιχειρήσεις: Εξαγωγή ενός κλικ σε Google Sheets, Airtable, Notion ή Excel (). Προγραμμάτισε scrapes και στείλε τα δεδομένα κατευθείαν στη ροή εργασίας της ομάδας.
- Έτοιμα templates: Για sites όπως Amazon, LinkedIn, Zillow κ.ά., το Thunderbit προσφέρει για εξαγωγή δεδομένων με ένα κλικ.
- Φιλικό και προσβάσιμο: Point-and-click περιβάλλον με διαισθητικό assistant. Οι χρήστες λένε ότι ξεκινούν μέσα σε λίγα λεπτά.

Το Thunderbit το εμπιστεύονται , συμπεριλαμβανομένων ομάδων σε Accenture, Grammarly και Puma. Ομάδες sales το χρησιμοποιούν για να , μεσίτες συγκεντρώνουν αγγελίες ακινήτων και marketers παρακολουθούν ανταγωνιστές — χωρίς να γράψουν ούτε μία γραμμή κώδικα.
Τιμολόγηση: Υπάρχει (έως 100 steps/μήνα), με επί πληρωμή πλάνα από $14.99/μήνα. Ακόμη και τα pro πλάνα είναι προσιτά για άτομα και μικρές ομάδες.
Το Thunderbit είναι ό,τι πιο κοντινό έχω δει στο «να μετατρέπεις το web σε βάση δεδομένων» — και είναι φτιαγμένο για όλους, όχι μόνο για engineers.
2. Crawl4AI
Για ποιον είναι: Developers και τεχνικές ομάδες που χτίζουν custom pipelines.
Το Crawl4AI είναι ένα open-source framework σε Python, βελτιστοποιημένο για ταχύτητα και crawling μεγάλης κλίμακας, με . Είναι εξαιρετικά γρήγορο, υποστηρίζει headless browsers για δυναμικό περιεχόμενο και μπορεί να δομεί τα δεδομένα ώστε να «κουμπώνουν» εύκολα σε AI workflows.
- Ιδανικό για: Developers που θέλουν ισχυρή, παραμετροποιήσιμη μηχανή crawling.
- Τιμολόγηση: Δωρεάν (MIT license). Χρειάζεται να το φιλοξενήσεις και να το τρέξεις μόνος σου.
3. ScrapeGraphAI
Για ποιον είναι: Developers και analysts που φτιάχνουν AI agents ή σύνθετα data pipelines.
Το ScrapeGraphAI είναι μια prompt-driven, open-source βιβλιοθήκη Python που μετατρέπει websites σε δομημένα «graphs» δεδομένων με LLMs. Γράφεις prompts όπως «Εξήγαγε όλα τα ονόματα προϊόντων, τιμές και αξιολογήσεις από τις πρώτες 5 σελίδες» και δημιουργεί workflow scraping για σένα ().
- Ιδανικό για: Τεχνικούς χρήστες που θέλουν ευέλικτο scraping με prompts.
- Τιμολόγηση: Δωρεάν για την open-source βιβλιοθήκη· cloud API από $20/μήνα.
4. Firecrawl
Για ποιον είναι: Developers που χτίζουν AI agents ή data pipelines μεγάλης κλίμακας.
Το Firecrawl είναι πλατφόρμα crawling και API με επίκεντρο την AI, που μετατρέπει ολόκληρα websites σε δεδομένα «έτοιμα για LLM» (). Επιστρέφει Markdown ή JSON, χειρίζεται δυναμικό περιεχόμενο και ενσωματώνεται με frameworks όπως LangChain και LlamaIndex.
- Ιδανικό για: Developers που θέλουν να τροφοδοτούν AI μοντέλα με live web data.
- Τιμολόγηση: Open-source core δωρεάν· cloud πλάνα από $19/μήνα.
5. Browse AI
Για ποιον είναι: Business users, growth hackers και analysts.
Το Browse AI είναι no-code πλατφόρμα με . «Εκπαιδεύεις» ένα robot κάνοντας κλικ στα δεδομένα που θέλεις και η AI γενικεύει το μοτίβο για μελλοντικά scrapes. Υποστηρίζει logins, infinite scroll και μπορεί να παρακολουθεί sites για αλλαγές.
- Ιδανικό για: Μη τεχνικούς χρήστες που θέλουν αυτοματοποίηση συλλογής δεδομένων και monitoring.
- Τιμολόγηση: Δωρεάν πλάνο (50 credits/μήνα)· επί πληρωμή από $19/μήνα.
6. LLM Scraper
Για ποιον είναι: Developers που θέλουν η AI να κάνει το parsing.
Το LLM Scraper είναι open-source βιβλιοθήκη JavaScript/TypeScript που σου επιτρέπει να και να αφήσεις ένα LLM να εξάγει αυτά τα δεδομένα από οποιαδήποτε σελίδα. Βασίζεται στο Playwright, υποστηρίζει πολλούς LLM providers και μπορεί ακόμη και να δημιουργεί επαναχρησιμοποιήσιμο κώδικα.
- Ιδανικό για: Developers που θέλουν να μετατρέπουν οποιαδήποτε σελίδα σε δομημένα δεδομένα με LLMs.
- Τιμολόγηση: Δωρεάν (MIT license).
7. Reader (Jina Reader)
Για ποιον είναι: Developers που φτιάχνουν LLM εφαρμογές, chatbots ή summarizers.
Το Jina Reader είναι API που εξάγει , επιστρέφοντας Markdown ή JSON έτοιμο για LLM. Τροφοδοτείται από custom AI model και μπορεί ακόμη και να δημιουργεί captions για εικόνες.
- Ιδανικό για: Λήψη καθαρού, αναγνώσιμου περιεχομένου για LLMs ή Q&A συστήματα.
- Τιμολόγηση: Δωρεάν API (χωρίς key για βασική χρήση).
8. Bright Data
Για ποιον είναι: Enterprises και επαγγελματίες χρήστες που χρειάζονται κλίμακα, συμμόρφωση και αξιοπιστία.
Το Bright Data είναι «βαρύ όνομα» στον χώρο των web data, με τεράστιο proxy network και . Προσφέρει έτοιμους scrapers, γενικό Web Scraper API και data feeds «LLM-ready».
- Ιδανικό για: Οργανισμούς που χρειάζονται αξιόπιστα web data σε μεγάλη κλίμακα.
- Τιμολόγηση: Με βάση τη χρήση, premium. Διαθέσιμα free trials.
9. Octoparse
Για ποιον είναι: Από μη τεχνικούς έως semi-technical χρήστες.
Το Octoparse είναι καθιερωμένο no-code εργαλείο με και AI auto-detect. Υποστηρίζει logins, infinite scroll και εξαγωγή σε διάφορα formats.
- Ιδανικό για: Analysts, ιδιοκτήτες μικρών επιχειρήσεων ή ερευνητές.
- Τιμολόγηση: Διαθέσιμο free tier· επί πληρωμή από $119/μήνα.
10. Apify
Για ποιον είναι: Developers και τεχνικές ομάδες που χρειάζονται custom scraping/automation.
Το Apify είναι cloud πλατφόρμα για εκτέλεση scraping scripts («actors») και διαθέτει . Κλιμακώνεται εύκολα, ενσωματώνεται με AI και υποστηρίζει proxy management.
- Ιδανικό για: Developers που θέλουν να τρέχουν custom scripts στο cloud.
- Τιμολόγηση: Free tier· επί πληρωμή με βάση τη χρήση από $49/μήνα.
11. Zyte (Scrapy Cloud)
Για ποιον είναι: Developers και εταιρείες που χρειάζονται enterprise-grade scraping.
Η Zyte είναι η εταιρεία πίσω από το Scrapy και προσφέρει cloud πλατφόρμα με . Υποστηρίζει scheduling, proxies και projects μεγάλης κλίμακας.
- Ιδανικό για: Dev teams που τρέχουν μακροχρόνια scraping projects.
- Τιμολόγηση: Από free trials έως custom enterprise πλάνα.
12. Webscraper.io
Για ποιον είναι: Αρχάριους, δημοσιογράφους και ερευνητές.
Το είναι ένα για point-and-click εξαγωγή δεδομένων. Είναι απλό, δωρεάν για τοπική χρήση και προσφέρει cloud service για μεγαλύτερες εργασίες.
- Ιδανικό για: Γρήγορες, εφάπαξ εργασίες scraping.
- Τιμολόγηση: Δωρεάν extension· cloud πλάνα από ~ $50/μήνα.
13. ParseHub
Για ποιον είναι: Μη τεχνικούς χρήστες που χρειάζονται περισσότερη ισχύ από τα βασικά εργαλεία.
Το ParseHub είναι desktop app με visual workflow για scraping δυναμικού περιεχομένου, συμπεριλαμβανομένων χαρτών και φορμών. Μπορεί να τρέχει projects στο cloud και προσφέρει API.
- Ιδανικό για: Digital marketers, analysts και δημοσιογράφους.
- Τιμολόγηση: Free tier (200 σελίδες/εκτέλεση)· επί πληρωμή από $189/μήνα.
14. Diffbot
Για ποιον είναι: Enterprises και AI εταιρείες που χρειάζονται δομημένα web data σε μεγάλη κλίμακα.
Το Diffbot αξιοποιεί computer vision και NLP για να από οποιαδήποτε σελίδα, προσφέροντας APIs για άρθρα, προϊόντα και ένα τεράστιο knowledge graph.
- Ιδανικό για: Market intelligence, finance και training data για AI.
- Τιμολόγηση: Premium, από ~ $299/μήνα.
15. DataMiner
Για ποιον είναι: Μη τεχνικούς χρήστες, ειδικά σε sales, marketing και δημοσιογραφία.
Το DataMiner είναι για γρήγορη, point-and-click εξαγωγή web δεδομένων. Διαθέτει βιβλιοθήκη με έτοιμες «συνταγές» και εξάγει απευθείας σε Google Sheets.
- Ιδανικό για: Γρήγορες εργασίες όπως εξαγωγή πινάκων ή λιστών σε spreadsheets.
- Τιμολόγηση: Free tier (500 σελίδες/ημέρα)· Pro από ~ $19/μήνα.
Σύγκριση κορυφαίων εργαλείων AI Web Scraper: Ποιο ταιριάζει στις ανάγκες σου;
Ακολουθεί μια γρήγορη σύγκριση για να δεις τι σου «κάθεται» καλύτερα:
| Tool | AI/LLM Usage | Ease of Use | Output/Integration | Ideal For | Pricing |
|---|---|---|---|---|---|
| Thunderbit | UI φυσικής γλώσσας· η AI προτείνει πεδία | Πιο εύκολο (no-code chat) | Εξαγωγές σε Sheets, Airtable, Notion | Μη τεχνικές ομάδες | Free tier· Pro ~ $30/μήνα |
| Crawl4AI | Crawling έτοιμο για AI· ενσωμάτωση LLMs | Δύσκολο (Python code) | Library/CLI· ενσωμάτωση μέσω κώδικα | Devs που θέλουν γρήγορα AI data pipelines | Δωρεάν |
| ScrapeGraphAI | LLM prompt pipelines για scraping | Μέτριο (λίγος κώδικας ή API) | API/SDK· JSON output | Devs/analysts που χτίζουν AI agents | Free OSS· API $20+/μήνα |
| Firecrawl | Crawling σε LLM-ready Markdown/JSON | Μέτριο (χρήση API/SDK) | SDKs (Py, Node κ.λπ.)· LangChain integ | Devs που ενσωματώνουν live web data σε AI | Δωρεάν + paid cloud |
| Browse AI | AI-assisted point & click | Εύκολο (no-code) | 7000+ integrations (Zapier) | Μη τεχνικοί χρήστες για web monitoring | Free 50 runs· Paid $19+/μήνα |
| LLM Scraper | Χρήση LLMs για parsing σε schema | Δύσκολο (TS/JS code) | Code library· JSON output | Devs που θέλουν η AI να κάνει parsing | Δωρεάν (με δικό σου LLM API) |
| Reader (Jina) | AI model εξάγει κείμενο/JSON | Εύκολο (απλό API call) | REST API επιστρέφει Markdown/JSON | Devs που προσθέτουν web content σε LLMs | Δωρεάν API |
| Bright Data | AI-enhanced scraping APIs· μεγάλο proxy network | Δύσκολο (API, τεχνικό) | APIs/SDKs· streams ή datasets | Enterprise κλίμακα | Με βάση τη χρήση |
| Octoparse | AI auto-detect λιστών | Μέτριο (no-code app) | CSV/Excel, API για αποτελέσματα | Semi-technical χρήστες | Free limited· $59–$166/μήνα |
| Apify | Κάποιες AI δυνατότητες (Actors, tutorials) | Δύσκολο (scripts) | Πλήρες API· ενσωμάτωση με LangChain | Devs για custom scraping στο cloud | Free tier· pay-as-you-go |
| Zyte (Scrapy) | ML-based auto extraction· Scrapy framework | Δύσκολο (Python code) | API, Scrapy Cloud UI· JSON/CSV | Dev teams, μακροχρόνια projects | Custom pricing |
| Webscraper.io | Χωρίς AI (manual templates) | Εύκολο (browser extension) | CSV download, Cloud API | Αρχάριοι, γρήγορα one-off scrapes | Δωρεάν extension· Cloud ~ $50/μήνα |
| ParseHub | Χωρίς ξεκάθαρο LLM· visual builder | Μέτριο (no-code app) | JSON/CSV· API για cloud runs | Μη devs για σύνθετα sites | Free 200 pages· Paid $189+/μήνα |
| Diffbot | AI vision/NLP για κάθε σελίδα· knowledge graph | Εύκολο (API calls) | APIs (Article/Prod/...) + Knowledge Graph query | Enterprise, δομημένα web data | Από ~ $299/μήνα |
| DataMiner | Χωρίς LLM· community recipes | Πιο εύκολο (browser UI) | Export σε Excel/CSV· Google Sheets | Μη τεχνικοί χρήστες για spreadsheets | Free limited· Pro ~ $19/μήνα |
Κατηγορίες εργαλείων: Από «βαριά» developer λύσεις έως business-friendly Web Scrapers
Για να μη χαθείς, ας τα βάλουμε σε κουτάκια:
1. Ισχυρά εργαλεία για Developers & Open-Source
- Παραδείγματα: Crawl4AI, LLM Scraper, Apify, Zyte/Scrapy, Firecrawl
- Δυνατά σημεία: Τρελή ευελιξία, κλίμακα και παραμετροποίηση. Τέλεια για custom pipelines ή σύνδεση με AI μοντέλα.
- Συμβιβασμοί: Θέλουν coding και περισσότερη ρύθμιση.
- Use cases: Custom data pipeline, scraping σύνθετων sites ή σύνδεση με εσωτερικά συστήματα.
2. Scraping agents με ενσωματωμένη AI
- Παραδείγματα: Thunderbit, ScrapeGraphAI, Firecrawl, Reader (Jina), LLM Scraper
- Δυνατά σημεία: Μικραίνουν την απόσταση ανάμεσα στο scraping και στην «κατανόηση» των δεδομένων. Τα interfaces φυσικής γλώσσας τα κάνουν πολύ πιο βατά.
- Συμβιβασμοί: Κάποια είναι ακόμη σε φάση εξέλιξης· ίσως δεν δίνουν απόλυτα λεπτομερή έλεγχο.
- Use cases: Γρήγορες απαντήσεις ή datasets, αυτόνομοι agents, τροφοδότηση live data σε LLMs.
3. No-Code/Low-Code, φιλικά για επιχειρήσεις
- Παραδείγματα: Thunderbit, Browse AI, Octoparse, ParseHub, , DataMiner
- Δυνατά σημεία: Εύχρηστα, ελάχιστος ή καθόλου κώδικας, ιδανικά για καθημερινές επιχειρησιακές ανάγκες.
- Συμβιβασμοί: Μπορεί να «κολλήσουν» σε πολύ σύνθετα sites ή σε τεράστια κλίμακα.
- Use cases: Lead generation, παρακολούθηση ανταγωνισμού, ερευνητικά projects, εφάπαξ εξαγωγές.
4. Enterprise πλατφόρμες δεδομένων και υπηρεσίες
- Παραδείγματα: Bright Data, Diffbot, Zyte
- Δυνατά σημεία: End-to-end λύσεις, managed services, συμμόρφωση και αξιοπιστία σε κλίμακα.
- Συμβιβασμοί: Πιο ακριβές, με περισσότερο onboarding και διαδικασία.
- Use cases: Μεγάλης κλίμακας, always-on data pipelines, market intelligence, AI training data.
Πώς να επιλέξεις τον σωστό AI Web Crawler για τις ανάγκες σου στο Web Page Scraping
Η επιλογή μπορεί να μοιάζει χάος, οπότε πάμε με έναν πρακτικό οδηγό βήμα-βήμα:
- Καθόρισε στόχους και απαιτήσεις δεδομένων: Ποια sites και ποια δεδομένα χρειάζεσαι; Πόσο συχνά; Σε τι όγκο; Και τι θα τα κάνεις;
- Αξιολόγησε το τεχνικό σου επίπεδο: Χωρίς κώδικα; Δοκίμασε Thunderbit, Browse AI ή Octoparse. Λίγο scripting; LLM Scraper ή DataMiner. Ισχυρές dev δεξιότητες; Crawl4AI, Apify ή Zyte.
- Σκέψου συχνότητα και κλίμακα: Εφάπαξ; Δωρεάν εργαλεία. Επαναλαμβανόμενο; Ψάξε scheduling. Μεγάλη κλίμακα; Enterprise λύσεις ή open-source σε κλίμακα.
- Budget και μοντέλο τιμολόγησης: Τα free plans είναι τέλεια για δοκιμές. Συνδρομή vs. χρέωση ανά χρήση εξαρτάται από το τι θες να κάνεις.
- Δοκιμή και proof of concept: Τεστάρισε 2–3 εργαλεία πάνω στα πραγματικά σου δεδομένα. Τα περισσότερα έχουν free tiers.
- Συντήρηση και υποστήριξη: Ποιος θα το «μαζεύει» όταν αλλάζει το site; Τα no-code με AI μπορεί να «αυτοθεραπεύουν» μικρές αλλαγές· το open-source βασίζεται σε σένα ή την κοινότητα.
- Ταίριαξε εργαλεία με σενάρια: Sales για leads; Thunderbit ή Browse AI. Ερευνητής για tweets; DataMiner ή . AI μοντέλο που χρειάζεται ειδήσεις; Jina Reader ή Zyte. Comparison site; Apify ή Zyte.
- Πρόβλεψε εναλλακτική: Κάποιες φορές ένα εργαλείο απλά δεν «κάθεται» σε συγκεκριμένο site. Κράτα plan B.
Το «σωστό» εργαλείο είναι αυτό που σου δίνει τα δεδομένα που χρειάζεσαι με τη λιγότερη τριβή και μέσα στο budget σου. Πολύ συχνά, είναι συνδυασμός.
Thunderbit vs. παραδοσιακά εργαλεία Web Scraper: Τι το κάνει να ξεχωρίζει;
Ας το κάνουμε συγκεκριμένο: τι είναι αυτό που διαφοροποιεί το Thunderbit;
- Interface φυσικής γλώσσας: Χωρίς κώδικα, χωρίς ακροβατικά point-and-click. Απλά περιγράφεις τι θέλεις ().
- Μηδενική ρύθμιση & προτάσεις templates: Το Thunderbit εντοπίζει αυτόματα pagination, υποσελίδες και προτείνει templates για συνηθισμένα sites ().
- AI καθαρισμός και εμπλουτισμός δεδομένων: Σύνοψη, κατηγοριοποίηση, μετάφραση και enrichment την ώρα του scraping ().
- Λιγότερα προβλήματα συντήρησης: Η AI του Thunderbit αντέχει σε μικρές αλλαγές site, μειώνοντας τα «σπασίματα».
- Ενσωμάτωση με business εργαλεία: Άμεση εξαγωγή σε Google Sheets, Airtable, Notion — τέλος στο «μαγείρεμα» CSV ().
- Γρήγορη απόδοση αξίας: Από ιδέα σε δεδομένα σε λεπτά, όχι σε μέρες.
- Καμπύλη εκμάθησης: Αν μπορείς να σερφάρεις και να περιγράψεις τι χρειάζεσαι, μπορείς να χρησιμοποιήσεις Thunderbit.
- Ευελιξία: Websites, PDFs, εικόνες και άλλα — με ένα εργαλείο.
Το Thunderbit δεν είναι απλώς Web Scraper — είναι data assistant που «κουμπώνει» στη ροή εργασίας σου, είτε είσαι σε sales, marketing, ecommerce ή real estate.
Βέλτιστες πρακτικές για Web Page Scraping με εργαλεία AI Web Scraper
Για να πάρεις το μέγιστο από τα AI Web Scraper εργαλεία, κράτα αυτές τις συμβουλές:
- Όρισε ξεκάθαρα τι δεδομένα χρειάζεσαι: Ποια πεδία, πόσες σελίδες, και σε ποιο format.
- Αξιοποίησε τις AI προτάσεις: Χρησιμοποίησε field detection και προτάσεις AI για να μην σου ξεφύγουν κρίσιμα δεδομένα ().
- Ξεκίνα μικρά και επιβεβαίωσε: Δοκίμασε σε μικρό δείγμα, έλεγξε την έξοδο και μετά κλιμάκωσε.
- Διαχειρίσου δυναμικό περιεχόμενο: Βεβαιώσου ότι το εργαλείο υποστηρίζει interactions (pagination, infinite scroll κ.λπ.).
- Σεβάσου τις πολιτικές των sites: Έλεγξε robots.txt, απόφυγε ευαίσθητα δεδομένα και σεβάσου rate limits.
- Ενσωμάτωσε για αυτοματοποίηση: Χρησιμοποίησε exports και webhooks για να μπαίνουν τα δεδομένα κατευθείαν στο workflow.
- Διατήρησε ποιότητα δεδομένων: Κάνε sanity checks, post-processing και παρακολούθησε σφάλματα.
- Γράφε σύντομα και συγκεκριμένα prompts: Στα AI-driven εργαλεία, οι καθαρές οδηγίες φέρνουν καλύτερα αποτελέσματα.
- Μάθε από την κοινότητα: Forums και communities δίνουν tips και λύσεις όταν κολλάς.
- Μείνε ενημερωμένος: Τα AI εργαλεία τρέχουν με ρυθμούς φωτιάς — παρακολούθησε νέα features και βελτιώσεις.
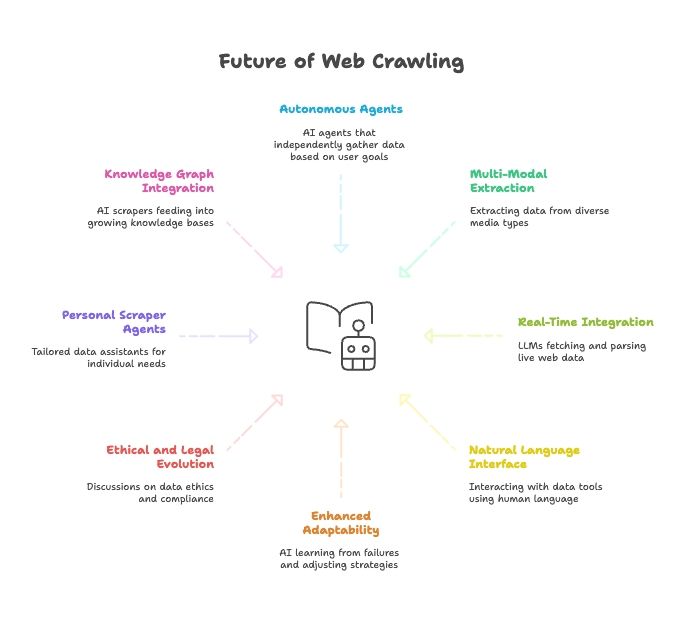
Το μέλλον του Web Scraping: AI, LLMs και η άνοδος των agents φυσικής γλώσσας
Αν κοιτάξουμε λίγο πιο μπροστά, η σύγκλιση AI και web scraping επιταχύνεται:
- Πλήρως αυτόνομοι scraper agents: Σύντομα θα λες τον τελικό στόχο και ο agent θα βρίσκει μόνος του πώς να πάρει τα δεδομένα.
- Multi-modal εξαγωγή δεδομένων: Scrapers θα τραβούν δεδομένα από κείμενο, εικόνες, PDFs και ακόμη και βίντεο.
- Real-time σύνδεση με AI μοντέλα: Τα LLMs θα έχουν ενσωματωμένα modules για ανάκτηση και parsing live web data.
- Όλα σε φυσική γλώσσα: Θα μιλάμε στα data tools όπως μιλάμε σε ανθρώπους, κάνοντας τη συλλογή/μετασχηματισμό δεδομένων προσβάσιμα σε όλους.
- Ακόμη μεγαλύτερη προσαρμοστικότητα: Οι AI scrapers θα μαθαίνουν από αποτυχίες και θα αλλάζουν στρατηγική αυτόματα.
- Ηθική και νομική εξέλιξη: Περισσότερη συζήτηση για ethics, compliance και fair use.
- Προσωπικοί scraper agents: Ένας προσωπικός data assistant που μαζεύει ειδήσεις, αγγελίες εργασίας κ.ά., προσαρμοσμένα στις ανάγκες σου.
- Ενσωμάτωση με knowledge graphs: Οι AI scrapers θα τροφοδοτούν συνεχώς knowledge bases, ενισχύοντας πιο «έξυπνη» AI.
Συμπέρασμα; Το μέλλον του web crawling και του web scraping είναι δεμένο κόμπο με το μέλλον της AI. Τα εργαλεία γίνονται πιο έξυπνα, πιο αυτόνομα και πιο προσβάσιμα μέρα με τη μέρα.
Συμπέρασμα: Πώς να ξεκλειδώσεις επιχειρησιακή αξία με τον σωστό AI Web Crawler
Το web scraping πέρασε από μια εξειδικευμένη τεχνική δεξιότητα σε βασική επιχειρησιακή δυνατότητα — χάρη στην AI. Τα 15 εργαλεία που κάλυψα εδώ δείχνουν το καλύτερο που είναι εφικτό το 2026, από «βαριά» developer εργαλεία έως business-friendly assistants.
Το πραγματικό μυστικό; Η σωστή επιλογή εργαλείου μπορεί να εκτοξεύσει την αξία που παίρνεις από τα web data. Για μη τεχνικές ομάδες, το Thunderbit είναι ο πιο εύκολος τρόπος να μετατρέψεις το web σε δομημένη, έτοιμη για ανάλυση βάση δεδομένων — χωρίς κώδικα, χωρίς ταλαιπωρία, μόνο αποτέλεσμα.
Είτε μαζεύεις leads, είτε παρακολουθείς ανταγωνιστές, είτε τροφοδοτείς το επόμενο AI μοντέλο σου, αξίζει να αξιολογήσεις τις ανάγκες σου, να δοκιμάσεις μερικά εργαλεία και να δεις τι σου ταιριάζει. Και αν θέλεις να ζήσεις το μέλλον του web scraping από σήμερα, . Τα insights που χρειάζεσαι απέχουν ένα prompt.
Θες περισσότερα; Δες το για αναλυτικά άρθρα, tutorials και τα νεότερα στην AI-powered εξαγωγή δεδομένων.
Περαιτέρω ανάγνωση:
Συχνές ερωτήσεις (FAQs)
1. Τι είναι ένας AI web crawler και σε τι διαφέρει από τα παραδοσιακά web scrapers;
Ένας AI web crawler αξιοποιεί επεξεργασία φυσικής γλώσσας και machine learning για να κατανοεί, να εξάγει και να δομεί web δεδομένα. Σε αντίθεση με τους παραδοσιακούς scrapers που απαιτούν χειροκίνητο κώδικα και XPath selectors, τα AI εργαλεία χειρίζονται δυναμικό περιεχόμενο, προσαρμόζονται σε αλλαγές layout και καταλαβαίνουν οδηγίες σε απλή γλώσσα.
2. Ποιοι πρέπει να χρησιμοποιούν εργαλεία AI web scraping όπως το Thunderbit;
Το Thunderbit είναι φτιαγμένο τόσο για μη τεχνικούς όσο και για τεχνικούς χρήστες. Είναι ιδανικό για επαγγελματίες σε sales, marketing, operations, research και ecommerce που θέλουν να εξάγουν δομημένα δεδομένα από websites, PDFs ή εικόνες — χωρίς να γράψουν κώδικα.
3. Ποια χαρακτηριστικά κάνουν το Thunderbit να ξεχωρίζει από άλλους AI web crawlers;
Το Thunderbit προσφέρει interface φυσικής γλώσσας, multi-level crawling, αυτόματη δόμηση δεδομένων, υποστήριξη OCR και απρόσκοπτες εξαγωγές σε πλατφόρμες όπως Google Sheets και Airtable. Περιλαμβάνει επίσης AI προτάσεις πεδίων και έτοιμα templates για δημοφιλή sites.
4. Υπάρχουν δωρεάν επιλογές για AI web scraping το 2026;
Ναι. Πολλά εργαλεία όπως Thunderbit, Browse AI και DataMiner προσφέρουν δωρεάν πλάνα με περιορισμένη χρήση. Για developers, open-source επιλογές όπως Crawl4AI και ScrapeGraphAI παρέχουν πλήρη λειτουργικότητα χωρίς κόστος, αλλά απαιτούν τεχνική εγκατάσταση.
5. Πώς επιλέγω τον σωστό AI web crawler για τις ανάγκες μου;
Ξεκίνα εντοπίζοντας τους στόχους δεδομένων σου, το τεχνικό σου επίπεδο, το budget και τις απαιτήσεις κλίμακας. Αν θέλεις no-code και εύκολη χρήση, το Thunderbit ή το Browse AI είναι εξαιρετικές επιλογές. Για μεγάλη κλίμακα ή custom ανάγκες, εργαλεία όπως Apify ή Bright Data ταιριάζουν καλύτερα.