Let’s be honest: the web is a wild, ever-growing jungle. Every day, over spring up, and Google’s search index alone holds . If you’ve ever wondered how search engines keep up—or how businesses find the needles in this digital haystack—you’re not alone. I’ve spent years in SaaS and automation, and I still get asked: “What’s the difference between web crawling and web scraping? Aren’t they the same thing?” Spoiler: they’re not, and mixing them up can send your project down the wrong rabbit hole.
So, whether you’re a sales pro hunting for leads, an ecommerce manager tracking prices, or just someone who wants to sound smart at the next team meeting, let’s break down what web crawlers actually do, how they differ from scrapers, and why picking the right tool (like Thunderbit) can save you a ton of headaches—and maybe even your weekend.
Web Crawler Basics: What Is a Web Crawler?

Imagine the world’s most obsessive librarian, one who doesn’t just organize books but insists on visiting every bookshelf, every day, to check for new titles. That’s basically what a web crawler does—except instead of books, it’s browsing billions of web pages. A web crawler (sometimes called a spider or bot) is an automated program that systematically explores the web, following links from page to page, and cataloging what it finds. This is how search engines like Google and Bing build their massive indexes, making the web searchable for all of us.
If you’ve ever heard terms like “Googlebot” or “Bingbot,” those are just the famous web crawlers working behind the scenes. There are also newer tools like , which let developers and businesses crawl entire sites and turn them into structured data for AI or analytics.
But here’s the kicker: crawling is about discovery—finding and indexing pages, not pulling out specific data points. That’s where web scraping comes in (more on that soon).
How Does Web Crawling Work?
Let’s walk through the life of a web crawler. Picture it as a digital explorer with a backpack full of “seed URLs”—the starting points. Here’s the step-by-step journey:
- Seed URLs: The crawler starts with a list of known web addresses.
- Fetch & Parse: It visits each URL, grabs the page, and scans it for links.
- Follow Links: Every new link found gets added to the “to-do” list (the URL frontier).
- Indexing: As it goes, the crawler stores information about each page—sometimes the whole content, sometimes just metadata.
- Politeness: It checks each site’s robots.txt file to see if crawling is allowed, and waits between requests to avoid overwhelming servers.
- Continuous Update: Because the web changes constantly, crawlers revisit pages to keep their index fresh.
It’s a bit like mapping a city by walking every street, noting every new alley and shop, and updating your map every time something changes.
Key Components of a Web Crawler
Even if you’re not technical, it helps to know what’s under the hood:
- URL Frontier (Queue): The master to-do list of URLs to visit next.
- Fetcher/Downloader: The part that actually grabs the web page.
- Parser: The “reader” that extracts links and sometimes other info from the page.
- Deduplication & URL Filter: Prevents the crawler from getting stuck in loops or visiting the same page twice.
- Data Storage/Index: Where all the discovered content is stored for later use.
Think of it as an assembly line: one part grabs the newspaper, another highlights the headlines, a third files away the clippings, and someone else keeps track of which papers to grab next.
How to Web Crawl a Site: Tools and Approaches
If you’re a business user, you might be tempted to build your own crawler. My advice? Don’t. Unless you’re planning to launch the next Google, there are plenty of tools that do the heavy lifting for you.
Popular web crawling tools:
- : Open-source, developer-focused, great for large projects.
- : Used for big data indexing and research.
- : The Internet Archive’s tool for web archiving.
- : A favorite among SEO pros for crawling and auditing websites.
- : Modern, API-driven, lets you crawl and extract structured data from entire sites.
Heads up: Most of these tools require some technical setup. For non-technical users, even “no-code” tools can have a learning curve—think picking HTML elements, dealing with site changes, or handling dynamic content. If you’re just looking to grab data from a few pages, you probably don’t need a full-blown crawler.
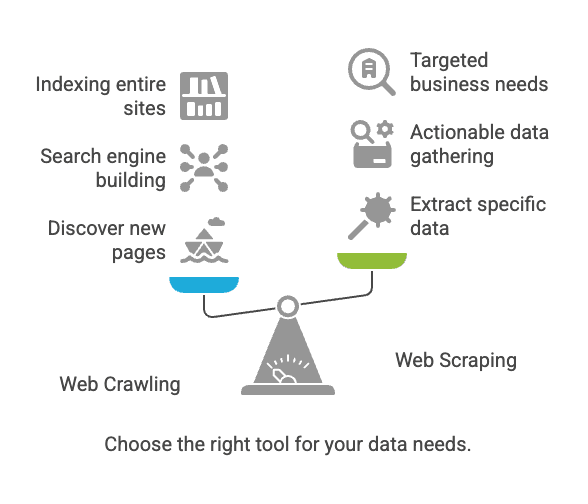
Web Crawling vs. Web Scraping: What’s the Difference?
Here’s where the confusion usually starts. Crawling and scraping are related, but they’re not the same thing.
| Aspect | Web Crawling | Web Scraping |
|---|---|---|
| Goal | Discover and index web pages | Extract specific data from web pages |
| Analogy | Librarian cataloging every book | Copying key info from a few pages |
| Output | List of URLs, page content, site map | Structured data (CSV, Excel, JSON, etc.) |
| Used by | Search engines, SEO tools, archivers | Sales, ecommerce, analysts, researchers |
| Typical Scale | Billions of pages (broad coverage) | Dozens to thousands of pages (targeted) |
In plain English: Crawling is about finding pages; scraping is about grabbing the data you want from those pages ().
Common Challenges and Best Practices in Web Crawling and Scraping
Typical Challenges
- Website Structure Changes: Even a tiny redesign can break your tool ().
- Dynamic Content: Many sites load data with JavaScript, which basic crawlers can’t see.
- Anti-Bot Measures: CAPTCHAs, IP blocks, and login requirements can stop you cold.
- Scale: Crawling thousands of pages can overload your computer (or get your IP banned).
- Legal/Ethical Issues: Scraping public data is usually fine, but always check the site’s terms and privacy laws ().
Best Practices
- Pick the Right Tool: If you’re not a coder, start with a no-code scraper.
- Define Your Data Goals: Know exactly what data you need and why.
- Respect Site Policies: Always check
robots.txtand the site’s terms. - Don’t Overload Sites: Add delays between requests; don’t hammer servers.
- Plan for Maintenance: Sites change—expect to tweak your setup occasionally.
- Keep Data Clean and Secure: Store results safely and check for duplicates or errors.
Typical Use Cases: Crawling vs. Scraping
Web Crawling
- Search Engine Indexing: Googlebot and Bingbot crawl the web to keep search results fresh ().
- Web Archiving: The Internet Archive crawls sites for the Wayback Machine.
- SEO Auditing: Tools crawl your site to find broken links or missing tags.
Web Scraping
- Price Monitoring: Retailers scrape competitor product pages for pricing ().
- Lead Generation: Sales teams scrape directories for contact info.
- Content Aggregation: News or job sites scrape listings from multiple sources.
- Market Research: Analysts scrape reviews or social media for sentiment analysis.
Fun fact: Over use web scraping for external data. If you’re not, your competitors probably are.
When Should You Use Web Crawling vs. Web Scraping?
Here’s my quick decision checklist:
-
Do you need to discover new pages or index a whole site?
→ Use web crawling.
-
Do you already know where your data lives (specific pages or sections)?
→ Use web scraping.
-
Are you building a search engine or archiving the web?
→ Crawling is your friend.
-
Are you gathering actionable data for sales, pricing, or research?
→ Scraping is the way to go.
-
Not sure?
→ Start with scraping. Most business needs don’t require full-scale crawling.
If you’re a business user, chances are you want scraping—targeted, structured data you can use right away.
Web Scraping for Business Users: The Thunderbit Advantage
Now, let’s talk about why most business users—especially non-technical folks—should focus on scraping, and why is designed for you.
I’ve seen too many teams waste days (or weeks) wrestling with “easy” scraping tools that turn out to be anything but. That’s why we built Thunderbit: to make web data extraction as simple as two clicks.
Here’s how Thunderbit stands out:
- Two-Click Workflow: Click “AI Suggest Fields,” then “Scrape.” That’s it. No coding, no fiddling with selectors.
- Bulk URL & PDF Support: Need to extract data from a list of URLs or even from PDFs? Thunderbit’s got you covered.
- Export Anywhere: Send your data straight to Google Sheets, Airtable, Notion, or download as CSV/JSON. No extra fees.
- Subpage Scraping: Thunderbit can automatically visit subpages (like product details) and enrich your data table.
- AI Autofill: Automate form-filling and repetitive web tasks—think of it as your digital assistant for the boring stuff.
- Free Email & Phone Extractors: Grab all the contact info from a page in one click.
- Cloud or Browser Scraping: Choose what fits your needs—Thunderbit can scrape in the cloud (super fast) or in your browser (great for logged-in pages).
- No Learning Curve: Designed for sales, ecommerce, and marketing teams who just want results.
If you want a deeper dive into use cases, check out our guides on , , or .
Thunderbit vs. Traditional Web Scraper
Let’s do a side-by-side comparison for business users:
| Feature/Need | Thunderbit | Traditional Web Scraper (e.g., Scrapy, Nutch) |
|---|---|---|
| Setup | 2 clicks, no coding | Technical setup, often requires scripting |
| Learning Curve | Minimal | Steep (especially for non-coders) |
| Subpage Handling | AI-powered, automatic | Manual scripting or advanced config |
| Bulk URLs/PDFs | Built-in support | Usually not supported out of the box |
| Output Formats | Google Sheets, Airtable, Notion, CSV | CSV, JSON (integration often manual) |
| Adaptability | AI adapts to site changes | Manual updates needed for site changes |
| Business Use Cases | Sales, ecommerce, SEO, operations | Search engine indexing, research, archiving |
| Scheduling | Natural language scheduling | Cron jobs or external schedulers |
| Pricing | Starts at $15/month, free tier available | Free/open-source, but higher setup/maintenance cost |
| Support | User-focused, modern UI | Community-based, developer-centric |
Thunderbit is all about getting you from “I need this data” to “here’s my spreadsheet” as quickly as possible—no IT ticket required.
Conclusion: Choosing the Right Approach for Your Business

Let’s recap:
- Web crawling is for discovering and indexing pages—think search engines and site audits.
- Web scraping is for extracting specific, actionable data—think sales leads, price monitoring, or content aggregation.
- For most business users, scraping is what you need. And you don’t need to be a coder to do it.
The web is only getting bigger and more complex. But with the right approach—and the right tool—you can turn that chaos into clarity. If you’re tired of wrestling with complicated scrapers or waiting on IT, give a try. You’ll be amazed at what you can do in just two clicks (and maybe you’ll finally get your weekend back).
If you want to see Thunderbit in action, grab our , or check out more tips and guides on the .
Happy scraping (not crawling—unless you’re building the next Google)!
FAQs
1. Do I need both a web crawler and a scraper for my business?
Not necessarily. If you already know which pages contain the data you need, a web scraper like Thunderbit is enough. Crawlers are more useful when you need to discover new pages—such as mapping an entire website or performing SEO audits.
2. Is web scraping legal?
In general, scraping public data is legal—especially if you're not bypassing logins, violating terms of service, or collecting sensitive information. However, it's always wise to check a website’s robots.txt file and privacy policy, especially for commercial use.
3. How is Thunderbit different from other web scraping tools?
Thunderbit is designed for business users who don’t code. Unlike traditional scrapers that require HTML knowledge or manual setup, Thunderbit uses AI to identify fields, navigate subpages, and output data in the format you need—all in just two clicks.
4. Can Thunderbit handle dynamic websites and logged-in pages?
Yes. Thunderbit offers browser-based scraping for logged-in sessions and dynamic content, as well as cloud-based scraping for speed and scale. You can choose the best mode based on the type of data you're after.