

Let me take you back to a not-so-distant past: I’m sitting at my desk, coffee in hand, staring at a spreadsheet that’s emptier than my fridge on a Sunday night. The sales team wants competitor pricing data, the marketing folks want fresh leads, and the ops crew wants product listings from a dozen sites—yesterday. I know the data is out there, but getting it? That’s the real challenge. If you’ve ever felt like you’re playing digital whack-a-mole with copy-paste, you’re not alone.
Fast forward to today, and the landscape has changed. Web scraping has gone from a nerdy side project to a core business strategy. JavaScript and Node.js are now front and center, powering everything from one-off scripts to full-blown data pipelines. But here’s the thing: while the tools are more powerful than ever, the learning curve can still feel like climbing Everest in flip-flops. So, whether you’re a business user, a data enthusiast, or just someone who’s tired of manual data entry, this guide is for you. I’ll break down the ecosystem, the essential libraries, the pain points, and why, sometimes, the smartest move is to let AI do the heavy lifting.
Why Web Scraping with JavaScript and Node.js Matters for Business
Let’s start with the “why.” In 2026, web data isn’t just a nice-to-have—it’s mission-critical. According to recent research, 73% of companies credit public web data for enabling faster, more accurate decision-making, and about 42% of enterprise data budgets are now dedicated to web data collection. The alternative data market (which includes web scraping) is already a $4.9 billion industry and growing at a brisk pace.
So what’s driving this gold rush? Here are some of the most common business use cases:
- Competitive Pricing & E-commerce: Retailers scrape competitor sites for pricing and inventory, sometimes boosting sales by 4% or more.
- Lead Generation & Sales Intelligence: Sales teams automate the collection of emails, phone numbers, and company details from directories and social platforms.
- Market Research & Content Aggregation: Analysts pull news, reviews, and sentiment data for trend spotting and forecasting.
- Advertising & Ad Tech: Ad tech firms track ad placements and competitor campaigns in real time.
- Real Estate & Travel: Agencies scrape property listings, prices, and reviews to feed valuation models and market analyses.
- Content & Data Aggregators: Platforms aggregate data from multiple sources to power comparison tools and dashboards.
JavaScript and Node.js have become the go-to stack for these tasks, especially as more websites rely on dynamic, JavaScript-rendered content. Node.js excels at asynchronous operations, making it a natural fit for scraping at scale. And with a thriving ecosystem of libraries, you can build anything from quick scripts to robust, production-grade scrapers.
What Is Data Scraping and How to Do It in 2025 Get Started Free
The Core Workflow: How Web Scraping with JavaScript and Node.js Works
Let’s demystify the typical web scraping workflow. Whether you’re scraping a simple blog or a JavaScript-heavy e-commerce site, the steps are pretty consistent:
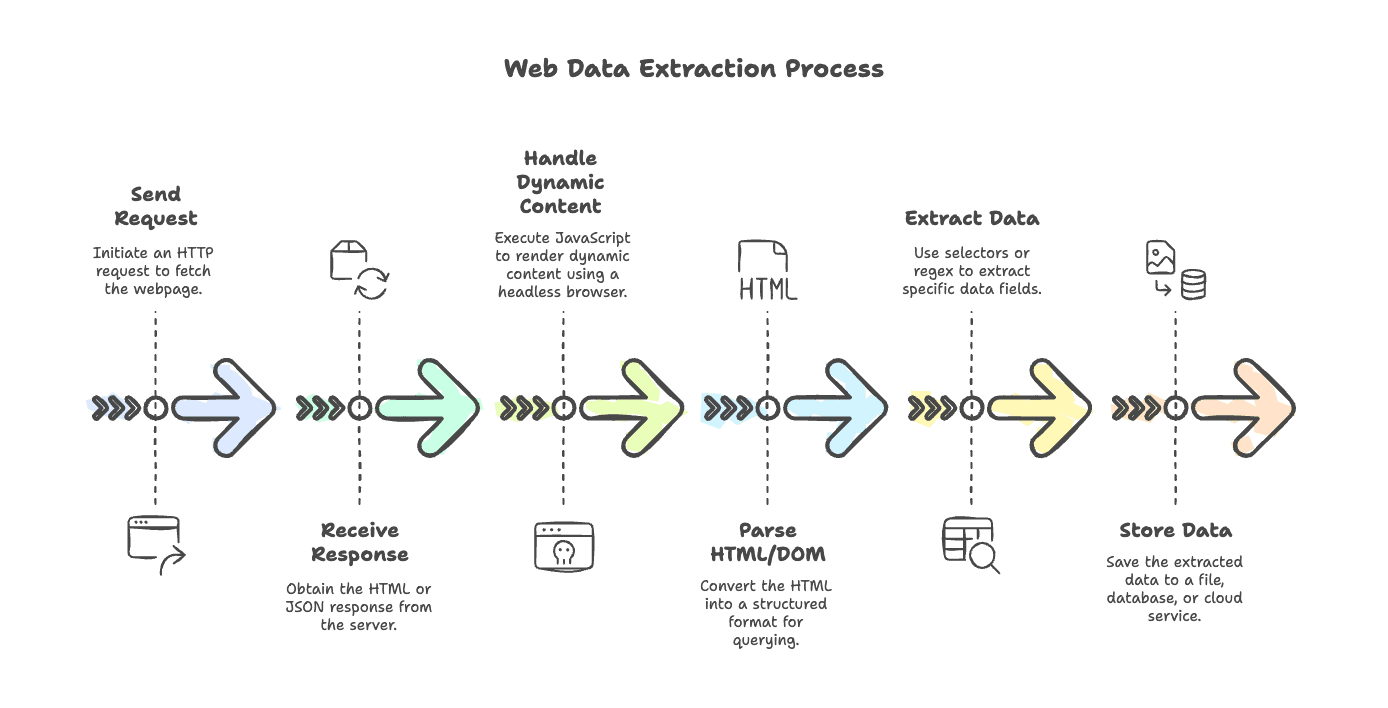
- Send Request: Use an HTTP client to fetch the page (think
axios,node-fetch, orgot). - Receive Response: Get the HTML (or sometimes JSON) back from the server.
- Handle Dynamic Content: If the page is rendered by JavaScript, use a headless browser (like Puppeteer or Playwright) to execute scripts and get the final content.
- Parse HTML/DOM: Use a parser (
cheerio,jsdom) to turn the HTML into a structure you can query. - Extract Data: Use selectors or regex to pull out the fields you need.
- Store Data: Save the results to a file, database, or cloud service.
Each step has its own set of tools and best practices, which we’ll dig into next.
Essential HTTP Request Libraries for Web Scraping JavaScript
The first step in any scraper is making HTTP requests. Node.js gives you a buffet of options—some classic, some modern. Here’s a rundown of the most popular libraries:
1. Axios
A promise-based HTTP client for Node and browsers. It’s the “Swiss Army knife” for most scraping needs.
const axios = require('axios');
const response = await axios.get('https://example.com/api/items', { timeout: 5000 });
console.log(response.data);
Pros: Feature-rich, supports async/await, automatic JSON parsing, interceptors, and proxy support.
Cons: Slightly heavier, sometimes “magical” in how it handles data.
2. node-fetch
Implements the browser fetch API in Node.js. Minimal and modern.
import fetch from 'node-fetch';
const res = await fetch('https://api.github.com/users/github');
const data = await res.json();
console.log(data);
Pros: Lightweight, familiar API for those coming from frontend JS.
Cons: Minimal features, manual error handling, proxy setup is verbose.
3. SuperAgent
A veteran HTTP library with a chainable API.
const superagent = require('superagent');
const res = await superagent.get('https://example.com/data');
console.log(res.body);
Pros: Mature, supports forms, file uploads, plugins.
Cons: API feels a bit dated, larger dependency.
4. Unirest
A simple, language-neutral HTTP client.
const unirest = require('unirest');
unirest.get('https://httpbin.org/get?query=web')
.end(response => {
console.log(response.body);
});
Pros: Easy syntax, good for quick scripts.
Cons: Fewer features, less active community.
5. Got
A robust, fast HTTP client for Node.js with advanced features.
import got from 'got';
const html = await got('https://example.com/page').text();
console.log(html.length);
Pros: Fast, supports HTTP/2, retries, streams.
Cons: Node-only, API can be a bit dense for newcomers.
6. Node’s Built-in http/https
You can always go old-school:
const https = require('https');
https.get('https://example.com/data', (res) => {
let data = '';
res.on('data', chunk => { data += chunk; });
res.on('end', () => {
console.log('Response length:', data.length);
});
});
Pros: No dependencies.
Cons: Verbose, callback-heavy, no promises.
See a detailed feature comparison and code samples here.
Choosing the Right HTTP Client for Your Project
How do you pick the right tool for the job? Here’s what I look for:
- Ease of use: Axios and Got are great for async/await and clean syntax.
- Performance: Got and node-fetch are lean and fast for high-concurrency scraping.
- Proxy support: Axios and Got make it easy to rotate proxies.
- Error handling: Axios throws on HTTP errors by default; node-fetch requires manual checks.
- Community: Axios and Got have active communities and lots of examples.
My quick recommendations:
- Quick scripts or prototypes: node-fetch or Unirest.
- Production scraping: Axios (for its features) or Got (for performance).
- Browser automation: Puppeteer or Playwright handle requests internally.
HTML Parsing and Data Extraction: Cheerio, jsdom, and More
Once you’ve fetched the HTML, you need to turn it into something you can actually work with. That’s where parsers come in.
Cheerio
Think of Cheerio as jQuery for the server. It’s fast, lightweight, and perfect for static HTML.
const cheerio = require('cheerio');
const $ = cheerio.load('<ul><li class="item">Item 1</li></ul>');
$('.item').each((i, el) => {
console.log($(el).text());
});
Pros: Blazing fast, familiar API, handles messy HTML.
Cons: No JavaScript execution—only sees what’s in the HTML.
Learn more about Cheerio’s speed and use cases.
jsdom
jsdom simulates a browser-like DOM in Node.js. It can execute simple scripts and is more “browser-like” than Cheerio.
const { JSDOM } = require('jsdom');
const dom = new JSDOM(`<p id="greet">Hello</p><script>document.querySelector('#greet').textContent += ", world!";</script>`);
console.log(dom.window.document.querySelector('#greet').textContent);
Pros: Can run scripts, supports full DOM API.
Cons: Slower and heavier than Cheerio, not a full browser.
Compare Cheerio and jsdom in detail.
When to Use Regular Expressions or Other Parsing Methods
Regex in web scraping is like hot sauce—great in moderation, but don’t pour it on everything. Regex is handy for:
- Extracting patterns from text (emails, phone numbers, prices).
- Cleaning or validating scraped data.
- Pulling data from blobs of text or script tags.
Example: Extracting a number from text
const text = "Total sales: 1,234 units";
const match = text.match(/([\d,]+)\s*units/);
if (match) {
const units = parseInt(match[1].replace(/,/g, ''));
console.log("Units sold:", units);
}
But don’t try to parse full HTML with regex—use a DOM parser for that. More regex tips for scraping.
Handling Dynamic Websites: Puppeteer, Playwright, and Headless Browsers
Modern websites love JavaScript. Sometimes, the data you want isn’t in the initial HTML—it’s rendered by scripts after the page loads. Enter headless browsers.
Puppeteer
A Node.js library from Google that controls Chrome/Chromium. It’s like having a robot click and scroll through pages for you.
const puppeteer = require('puppeteer');
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const title = await page.$eval('h1', el => el.textContent);
console.log(title);
await browser.close();
Pros: Full Chrome rendering, easy API, great for dynamic content.
Cons: Chromium-only, heavier on resources.
Read more about Puppeteer’s strengths.
Playwright
A newer library from Microsoft, Playwright supports Chromium, Firefox, and WebKit. It’s like Puppeteer’s cooler, cross-browser cousin.
const { chromium } = require('playwright');
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const content = await page.textContent('h1');
console.log(content);
await browser.close();
Pros: Cross-browser, parallel contexts, auto-waiting for elements.
Cons: Slightly steeper learning curve, bigger install.
Why Playwright is gaining ground.
Nightmare
An Electron-based automation tool that was popular years ago. The repository was moved to the segment-boneyard GitHub org — Segment’s parking lot for projects they’ve stopped supporting — and the last npm release was back in 2019. I wouldn’t reach for it on anything new in 2026; if you’re inheriting a script that still uses it, fine, but for a fresh project skip straight to Playwright or Puppeteer.
Comparing Headless Browser Solutions
| Aspect | Puppeteer (Chrome) | Playwright (Multi-browser) | Nightmare (Electron) |
|---|---|---|---|
| Browser Support | Chrome/Edge | Chrome, Firefox, WebKit | Chrome (old) |
| Performance & Scale | Fast, but heavy | Fast, better parallelism | Slower, less stable |
| Dynamic Scraping | Excellent | Excellent + more features | OK for simple sites |
| Maintenance | Well-maintained | Very active | Archived (segment-boneyard, last npm publish 2019) |
| Best For | Chrome scraping | Complex, cross-browser | Simple, legacy jobs |
My advice: Use Playwright for new, complex projects. Puppeteer is still great for Chrome-only tasks. Nightmare is mostly for nostalgia or old scripts.
Supporting Tools: Scheduling, Environment, CLI, and Data Storage
A real-world scraper is more than just fetch-and-parse. Here are some supporting tools I rely on:
Scheduling: node-cron
Schedule scrapers to run automatically.
const cron = require('node-cron');
cron.schedule('0 9 * * MON', () => {
console.log('Scraping at 9 AM every Monday');
});
Node-cron is perfect for automating repetitive jobs.
Environment Management: dotenv
Keep secrets and configs out of your code.
require('dotenv').config();
const apiKey = process.env.API_KEY;
CLI Tools: chalk, commander, inquirer
- chalk: Colorize console output.
- commander: Parse command-line options.
- inquirer: Interactive prompts for user input.
Data Storage
- fs: Write to files (JSON, CSV).
- lowdb: Lightweight JSON database.
- sqlite3: Local SQL database.
- mongodb: NoSQL database for larger projects.
Example: Save data to JSON
const fs = require('fs');
fs.writeFileSync('output.json', JSON.stringify(data, null, 2));
The Pain Points of Traditional Web Scraping with JavaScript and Node.js
Let’s be real—traditional scraping isn’t all sunshine and rainbows. Here are the biggest headaches I’ve seen (and felt):

- High learning curve: You need to grok DOM, selectors, async logic, and sometimes browser quirks.
- Maintenance burden: Websites change, selectors break, and you’re constantly patching code.
- Poor scalability: Every site needs its own script; nothing is truly “one size fits all.”
- Data cleaning complexity: Scraped data is messy—cleaning, formatting, and deduping is a job in itself.
- Performance limits: Browser automation is slow and resource-intensive for large-scale jobs.
- Blocking and anti-bot measures: Sites block scrapers, throw CAPTCHAs, or hide data behind logins.
- Legal and ethical gray areas: You need to navigate terms of service, privacy, and compliance.
Read more about these pain points and real-world stats.
Thunderbit vs. Traditional Web Scraping: A Productivity Revolution
Now, let’s talk about the elephant in the room: what if you could skip all the code, the selectors, and the maintenance?
That’s where Thunderbit comes in. As the co-founder and CEO, I’m a little biased, but hear me out—Thunderbit is built for business users who want data, not headaches.
How Thunderbit Compares
| Aspect | Thunderbit (AI No-Code) | Traditional JS/Node Scraping |
|---|---|---|
| Setup | 2-click, no code | Write scripts, debug |
| Dynamic Content | Handled in-browser | Headless browser scripting |
| Maintenance | AI adapts to changes | Manual code updates |
| Data Extraction | AI Suggest Fields | Manual selectors |
| Subpage Scraping | Built-in, 1-click | Loop and code per site |
| Export | Excel, Sheets, Notion | Manual file/db integration |
| Post-processing | Summarize, tag, format | Extra code or tools |
| Who Can Use | Anyone with a browser | Developers only |
Thunderbit’s AI reads the page, suggests fields, and scrapes data in just a couple of clicks. It handles subpages, adapts to layout changes, and can even summarize, tag, or translate data as it scrapes. You can export to Excel, Google Sheets, Airtable, or Notion—no technical setup required.
Use cases where Thunderbit shines:
- E-commerce teams tracking competitor SKUs and prices
- Sales teams scraping leads and contact info
- Market researchers aggregating news or reviews
- Real estate agents pulling listings and property details
For high-frequency, business-critical scraping, Thunderbit is a massive time-saver. For custom, large-scale, or deeply integrated projects, traditional scripting still has its place—but for most teams, Thunderbit is the fastest way from “I need data” to “I have data.”
See Thunderbit’s Chrome Extension in action or check out more use cases on the Thunderbit Blog.
Quick Reference: Popular JavaScript & Node.js Web Scraping Libraries
Here’s your cheat sheet for the JavaScript scraping ecosystem in 2026:
HTTP Requests
- Axios: Promise-based, feature-rich HTTP client.
- node-fetch: Fetch API for Node.js.
- Got: Fast, advanced HTTP client.
- SuperAgent: Mature, chainable HTTP requests.
- Unirest: Simple, language-neutral client.
HTML Parsing
Dynamic Content
- Puppeteer: Headless Chrome automation.
- Playwright: Multi-browser automation.
- Nightmare: Electron-based, legacy browser automation.
Scheduling
- node-cron: Cron jobs in Node.js.
CLI & Utilities
- chalk: Terminal string styling.
- commander: CLI argument parser.
- inquirer: Interactive CLI prompts.
- dotenv: Environment variable loader.
Storage
- fs: Built-in file system.
- lowdb: Tiny local JSON database.
- sqlite3: Local SQL database.
- mongodb: NoSQL database.
Frameworks
- Crawlee: High-level crawling and scraping framework from Apify. The JavaScript/TypeScript version is on v3.16 as of May 2026 and is the more mature track (the Python port is newer). It wraps Puppeteer, Playwright, Cheerio, and JSDOM behind one API, with proxy rotation and queueing built in — useful if you find yourself rebuilding the same scaffolding around your scrapers.
(Always check the latest docs and GitHub repos for updates.)
Recommended Resources for Mastering Web Scraping JavaScript
Want to go deeper? Here’s a curated list of resources to level up your scraping skills:
Official Docs & Guides
- MDN Web Docs: Web Scraping
- Puppeteer Documentation
- Playwright Documentation
- Crawlee Documentation
- Apify Web Scraping Academy
Tutorials & Courses
- freeCodeCamp: The Ultimate Guide to Web Scraping with Node.js
- YouTube: Web Scraping with Node.js (freeCodeCamp)
- DigitalOcean: How To Scrape a Website using Node.js and Puppeteer
Open-Source Projects & Examples
Community & Forums
Books & Comprehensive Guides
- O’Reilly’s “Web Scraping with Python” (for cross-language concepts)
- Udemy/Coursera: “Web Scraping in Node.js” courses
(Always check for the latest editions and updates.)
How to Scrape Any Website Using AI Get Started Free
Conclusion: Choosing the Right Approach for Your Team
Here’s the bottom line: JavaScript and Node.js give you incredible power and flexibility for web scraping. You can build anything—from quick-and-dirty scripts to robust, scalable crawlers. But with great power comes great… maintenance. Traditional scripting is best for custom, engineering-heavy projects where you need full control and are prepared for ongoing upkeep.
For everyone else—for business users, analysts, marketers, and anyone who just wants the data—modern no-code solutions like Thunderbit are a breath of fresh air. Thunderbit’s AI-powered Chrome Extension lets you scrape, structure, and export data in minutes, not days. No code, no selectors, no headaches.
So, what’s the right approach? If your team has engineering muscle and unique requirements, dive into the Node.js toolbox. If you want speed, simplicity, and the freedom to focus on insights instead of infrastructure, give Thunderbit a try. Either way, the web is your database—go get that data.
And if you’re ever stuck, just remember: even the best scrapers started with a blank page and a strong cup of coffee. Happy scraping.
Want to learn more about AI-powered scraping or see Thunderbit in action?
- Thunderbit Official Website
- Download the Thunderbit Chrome Extension
- Thunderbit Blog
- How to Scrape Any Website Using AI
- What Is Data Scraping and How to Do It in 2025
If you’ve got questions, stories, or favorite scraping horror stories, drop them in the comments or reach out to me. I love hearing how people are turning the web into their own data playground.
Stay curious, stay caffeinated, and keep scraping smarter—not harder.
Download Thunderbit Chrome Extension
Try AI Web Scraper Get Started Free
FAQ:
1. Why use JavaScript and Node.js for web scraping in 2025?
Because most modern websites are built with JavaScript. Node.js is fast, async-friendly, and has a rich ecosystem (e.g. Axios, Cheerio, Puppeteer) that supports everything from simple fetches to scraping dynamic content at scale.
2. What’s the typical workflow for scraping a website with Node.js?
It usually looks like this:
Request → Handle Response → (Optional JS Execution) → Parse HTML → Extract Data → Save or Export
Each step can be handled by dedicated tools like axios, cheerio, or puppeteer.
3. How do you scrape dynamic, JavaScript-rendered pages?
Use headless browsers like Puppeteer or Playwright. They load the full page (including JS), making it possible to scrape what users actually see.
4. What are the biggest challenges with traditional scraping?
- Site structure changes
- Anti-bot detection
- Browser resource costs
- Manual data cleaning
- High maintenance over time
These make large-scale or non-dev-friendly scraping tough to sustain.
5. When should I use something like Thunderbit instead of code?
Use Thunderbit if you need speed, simplicity, and don’t want to write or maintain code. It’s ideal for teams in sales, marketing, or research who want to extract and structure data fast—especially from complex or multi-page websites.




