
I still remember the first time I tried to scrape product data from a website. I was staring at a page full of running shoes, thinking, “How hard could it be to get all these names and prices into a spreadsheet?” Fast forward a few hours, and I was knee-deep in JavaScript errors, tangled selectors, and a growing sense of respect for anyone who’s ever built a web scraper from scratch.
If you’ve ever found yourself in that spot—maybe you’re in sales, ecommerce, or operations and just want to grab some real-time data to make smarter decisions—you’re not alone. The demand for web scraping has exploded in recent years. In fact, the global and is set to double by 2030. But here’s the catch: most traditional scraping tools require a fair bit of technical know-how. That’s why I wanted to walk you through two different approaches: a hands-on, code-driven method using Cypress, and a no-code, AI-powered shortcut with . We’ll use the as our playground.
Whether you’re a developer looking to flex your JavaScript muscles or a business user who’d rather not touch a line of code, this guide will help you get the data you need—without losing your sanity (or your weekend).
What is Web Scraping and Why Does It Matter for Business?
Let’s start simple: web scraping is the process of automatically extracting data from websites. Instead of copying and pasting product names, prices, or contact info by hand, you use software to do the heavy lifting for you.
But why does this matter for business? Well, data is the new oil (or oat milk, depending on your dietary preferences). Companies in sales, ecommerce, and operations are using web scraping to:
- Generate leads by pulling contact info from directories or social profiles.
- Monitor competitor prices and product trends—about .
- Analyze customer sentiment by scraping reviews and ratings.
- Automate repetitive research that would take hours (or days) by hand.
And the ROI is real: say public web data helps them make faster, more accurate decisions. In short, if you’re not using web scraping, you’re probably leaving money—and insights—on the table.
Introducing Cypress: A Popular Tool for Web Scraping
Now, let’s talk tools. Cypress is an open-source framework that was originally built for end-to-end testing of web applications. Think of it as a robot that can click buttons, fill out forms, and check if your website is working as expected. But here’s the twist: because Cypress runs in a real browser and can interact with JavaScript-heavy sites, it’s also become a handy (if unconventional) tool for web scraping.
How does Cypress stack up against other scraping tools, especially those built with Python (like BeautifulSoup or Scrapy)? Here’s the quick rundown:
- Cypress: Great for scraping dynamic, JavaScript-rendered content. You’ll need to know JavaScript and be comfortable with Node.js. It’s flexible and powerful, but definitely a developer’s tool.
- Python Scrapers: Tools like BeautifulSoup or Scrapy are optimized for large-scale crawling and static HTML. They have a massive ecosystem, but can struggle with sites that require a real browser to load content.
If you’re already familiar with JavaScript or QA testing, Cypress can be a surprisingly effective way to scrape data. But if you’re allergic to curly braces and semicolons, don’t worry—I’ve got a no-code alternative coming up.
Step-by-Step: Web Scraping with Cypress (Using Adidas Men’s Running Shoes as an Example)
Let’s roll up our sleeves and build a Cypress scraper for the . Our goal: extract product names, prices, images, and links into a neat little file.
1. Setting Up Your Cypress Environment
First things first, you’ll need and npm installed. Once that’s ready, open your terminal and run:
1mkdir adidas-scraper
2cd adidas-scraper
3npm init -y
4npm install cypress --save-devThis sets up a new project and installs Cypress locally. To launch Cypress for the first time:
1npx cypress openCypress will create a cypress/ directory with example tests. You can delete those and create your own test file, say, cypress/e2e/adidas-scraper.cy.js.
2. Inspecting the Website and Identifying Data to Scrape
Time to play detective. Open the in your browser, right-click on a product, and choose “Inspect.” You’ll see that each product is wrapped in a card, with elements for the name, price, image, and link.
For example, you might spot:
1<div class="product-card">
2 <a href="/us/adizero-sl2-running-shoes/XYZ123.html">
3 <img src="..." alt="Adizero SL2 Running Shoes"/>
4 <div class="product-price">$130</div>
5 <div class="product-name">Adizero SL2 Running Shoes -- Men's Running</div>
6 </a>
7</div>Pay attention to class names like .gl-price for prices, and look for consistent patterns in the HTML. This is where you’ll tell Cypress what to grab.
3. Writing Cypress Code to Extract Data
Here’s a sample Cypress script to get you started:
1// cypress/e2e/adidas-scraper.cy.js
2describe('Scrape Adidas Running Shoes', () => {
3 it('collects product name, price, image, and link', () => {
4 cy.visit('<https://www.adidas.com/us/men-running-shoes>');
5 const products = [];
6 cy.get('a[href*="/us/"][href*="running-shoes"]').each(($el) => {
7 const name = $el.find('*:contains("Running Shoes")').text().trim();
8 const price = $el.find('.gl-price').text().trim();
9 const imageUrl = $el.find('img').attr('src');
10 const link = $el.attr('href');
11 products.push({ name, price, image: imageUrl, link: `https://www.adidas.com$\{link\}` });
12 }).then(() => {
13 cy.writeFile('cypress/output/adidas_products.json', products);
14 });
15 });
16});What’s happening here?
cy.visit()loads the page.cy.get()selects all product links matching Adidas’s URL pattern..each()loops through each product, grabbing the name, price, image, and link.- The data is pushed into an array and written to a JSON file.
You’ll want to tweak the selectors if Adidas updates their site, but this should get you most of the way there.
4. Exporting and Using the Scraped Data
Once you run the script (via the Cypress GUI or npx cypress run), check your cypress/output/adidas_products.json file. You’ll see an array of product objects like:
1[
2 {
3 "name": "Adizero SL2 Running Shoes Men's Running",
4 "price": "$130",
5 "image": "<https://assets.adidas.com/images/w_280,h_280,f_auto,q_auto:sensitive/.../adizero-SL2-shoes.jpg>",
6 "link": "<https://www.adidas.com/us/adizero-sl2-running-shoes/XYZ123.html>"
7 },
8 ...
9]From here, you can convert the JSON to CSV, analyze it in Excel, or feed it into your favorite BI tool. If you want to get fancy, you can even automate the whole process to run daily for price monitoring.
Common Challenges When Web Scraping with Cypress
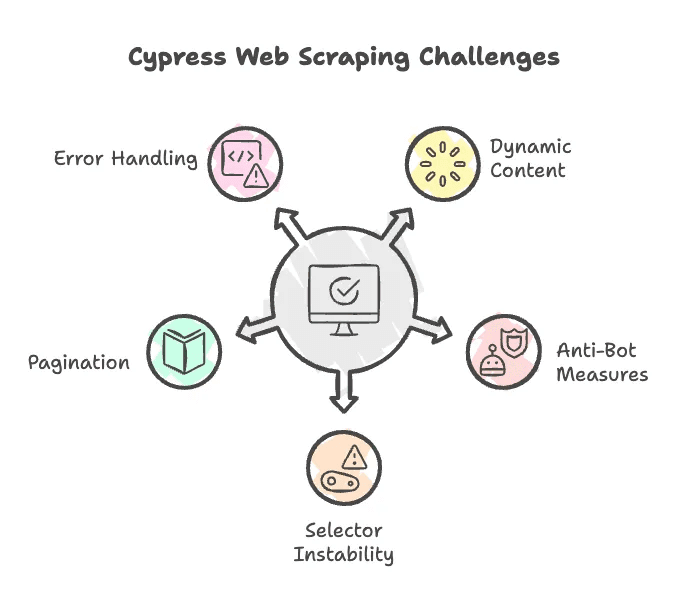
Let’s be honest: web scraping isn’t always smooth sailing. Here are some common hurdles you might face with Cypress (and some tips to get around them):
- JavaScript-Rendered Content: Cypress handles dynamic content well, but you might need to wait for elements to load or scroll the page to trigger lazy loading. Use
cy.wait()or scroll commands as needed. - Anti-Bot Defenses: Some sites block bots by checking user agents or rate-limiting requests. Cypress runs in a real browser, which helps, but persistent blockers may require more advanced tactics (like rotating proxies or spoofing headers).
- Selector Instability: If Adidas changes their HTML structure or class names, your script might break. Be ready to update selectors regularly.
- Pagination: Most product pages have multiple pages. You’ll need to write logic to click “Next” and aggregate results across pages.
- Error Handling: Cypress is designed for testing, so it tends to fail loudly if something’s missing. Add checks to gracefully handle missing elements.
If you’re starting to feel like you need a computer science degree just to get a list of shoes, you’re not alone. That’s exactly why we built Thunderbit.
Too Complicated? Try Thunderbit for Web Scraping in 2 Clicks
Let’s say you don’t want to mess with Node.js, selectors, or debugging JavaScript. Enter , our AI-powered web scraper Chrome extension. It’s built for business users who just want the data—no code, no setup, no headaches.
Here’s what makes Thunderbit different:
- No coding or selector wrangling: Just point, click, and let AI do the rest.
- One template, many sites: Thunderbit’s AI adapts to different page layouts, so you don’t have to reconfigure for every site.
- Browser and cloud scraping: Choose the mode that fits your speed and accuracy needs.
- Handles pagination and subpages: Thunderbit can click through multiple pages and even visit product detail pages to enrich your data.
- Free export: Download your data to Excel, Google Sheets, Airtable, or Notion—no paywall surprises.
Let’s walk through scraping the Adidas page with Thunderbit.
Step-by-Step: Web Scraping with Thunderbit (Adidas Example)
1. Installing Thunderbit Chrome Extension
First, install . It takes about 30 seconds, which is less time than it takes me to find my coffee mug in the morning.
Sign up for a free account—Thunderbit gives you a free trial (10 pages) and a free plan (6 pages per month), so you can try it out on real-world tasks without pulling out your credit card.
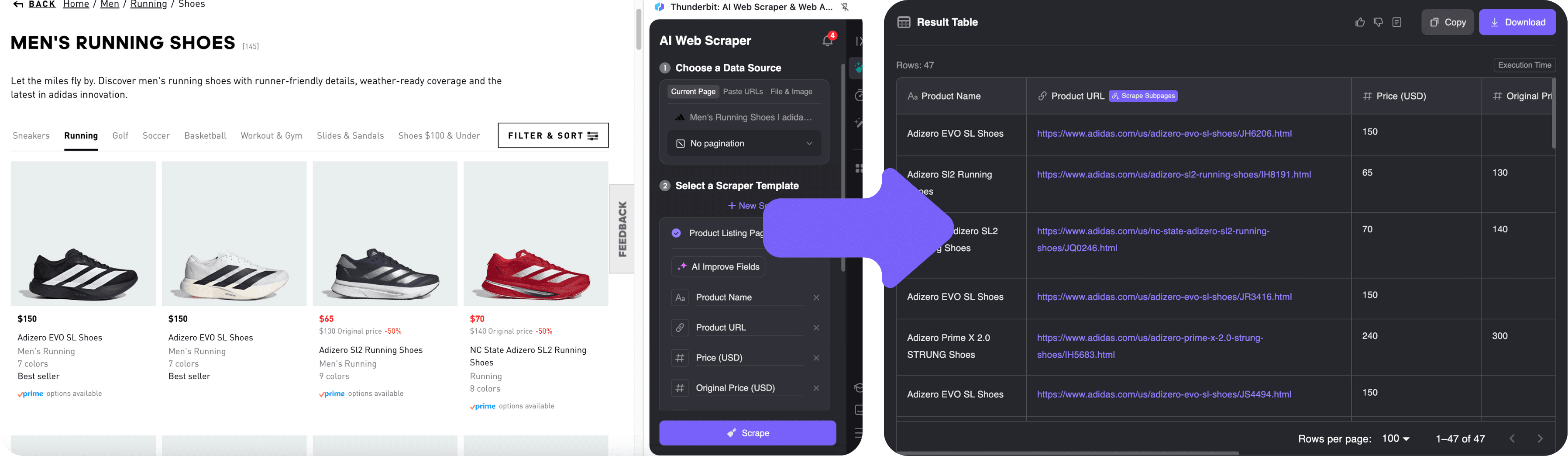
2. Scraping Data with AI Suggest Fields
- Open the .
- Click the Thunderbit extension icon in your browser. The sidebar will pop up.
- Hit “AI Suggest Fields”. Thunderbit’s AI scans the page and automatically detects the product name, price, image, and link fields. You’ll see a preview table with the first few rows.
- Want to tweak the columns? You can rename them or add new fields with a click. If you want to get fancy, you can even give Thunderbit a natural language prompt like “also extract the number of colors available.”
- Click “Scrape”. Thunderbit extracts all the data, automatically clicking through pagination if there are multiple pages. If you want to grab more details from each product’s page, use the subpage scraping feature—Thunderbit will visit each product and enrich your table.
3. Exporting and Using Your Data
Once the scrape is done, review the table in the Thunderbit sidebar. You can:
- Export to Excel, Google Sheets, Airtable, or Notion with one click.
- Download as CSV or JSON.
- Export images, emails, phone numbers, and more—Thunderbit supports all common data types.
And yes, exporting is totally free. No “surprise, pay up!” moments.
For more tips, check out our or browse the for more scraping tutorials.
Comparing Cypress and Thunderbit: Which Web Scraping Tool is Right for You?
Let’s put Cypress and Thunderbit side by side. Here’s a quick comparison table:
| Aspect | Cypress (Code Scraper) | Thunderbit (No-Code AI Scraper) |
|---|---|---|
| Setup Difficulty | Requires Node.js, npm, and JavaScript skills. Initial setup can be time-consuming for non-devs. | Install Chrome extension, log in, and you’re ready to go in minutes. No coding required. |
| Technical Skills Needed | Must know JavaScript and DOM/CSS selectors. High barrier for non-coders. | No coding needed. Natural language and point-and-click interface. |
| Speed of Implementation | Writing and debugging scripts can take hours, especially for complex pages or pagination. | Set up and run a scrape in just a couple of clicks. Handles pagination and subpages automatically. |
| Flexibility | Extremely flexible—can code any logic, handle logins, solve captchas, and integrate with APIs. | Designed for standard patterns. AI handles most sites, but very unique or complex workflows may require manual intervention. |
| Robustness to Changes | Scripts are brittle—if the site’s HTML changes, you’ll need to update your code. | More robust—AI adapts to minor layout changes. Thunderbit’s models are continuously improved to handle new patterns. |
| Scalability | Can handle moderate volume, but browser-based scraping is slower at large scale. | Cloud-backed scraping can handle hundreds of pages. Credit system keeps things manageable for business use. |
| Best For | Developers or technical users who need precision and custom logic. Great for one-off data gathering or complex workflows. | Business users who want fast, no-code scraping for repetitive tasks like price monitoring, lead generation, or extracting listings. Perfect for prototyping and standard ecommerce, directory, or review sites. |
In short: Cypress gives you control, Thunderbit gives you speed and simplicity. If you’re a developer who loves tinkering, Cypress is your playground. If you just want the data (and maybe your boss wants it by lunch), Thunderbit is your best friend.
Key Takeaways: Choosing the Best Web Scraping Approach for Your Needs
- Web scraping is essential for modern business—whether you’re tracking competitors, generating leads, or analyzing market trends.
- Cypress is a powerful, flexible tool for developers who want to code their own scrapers. It’s great for dynamic sites and custom workflows, but comes with a learning curve and ongoing maintenance.
- Thunderbit is built for everyone else. It’s an that makes scraping as easy as two clicks—no code, no setup, no headaches. It handles pagination, subpages, and exports to your favorite tools for free.
- Choose Cypress if you need ultimate flexibility and don’t mind getting your hands dirty with code.
- Choose Thunderbit if you want to save time, avoid technical hassles, and get clean data fast—especially if you’re in sales, ecommerce, marketing, or operations.
If you’re curious to see more, check out our for tutorials on , , and more.
And if you ever find yourself staring at a page full of running shoes, wondering how to get all that data into a spreadsheet—remember, you’ve got options. Happy scraping!
FAQs
1. What is Cypress and how can it be used for web scraping?
Cypress is a JavaScript-based testing tool that can interact with dynamic websites, making it suitable for scraping JavaScript-rendered content.
2. What are the main challenges when scraping websites with Cypress?
Common issues include changing HTML structures, lazy loading, anti-bot defenses, and handling pagination or missing elements in complex pages.
3. Is there an easier way to scrape websites without coding?
Yes, Thunderbit is an AI-powered Chrome extension that scrapes data with just a few clicks—no coding, setup, or selector tweaking required.
Learn More: