

There’s something timeless about opening a terminal, typing a single command, and watching raw web data pour in like you’ve just cracked open the Matrix. For developers and technical power users, cURL is that magic wand—an unassuming command-line tool that’s quietly running on billions of devices, from cloud servers to your smart fridge. And even in 2026, with all the shiny no-code and AI scraping tools out there, web-scraping-with-curl is still a go-to move for anyone who wants speed, control, and scriptability.
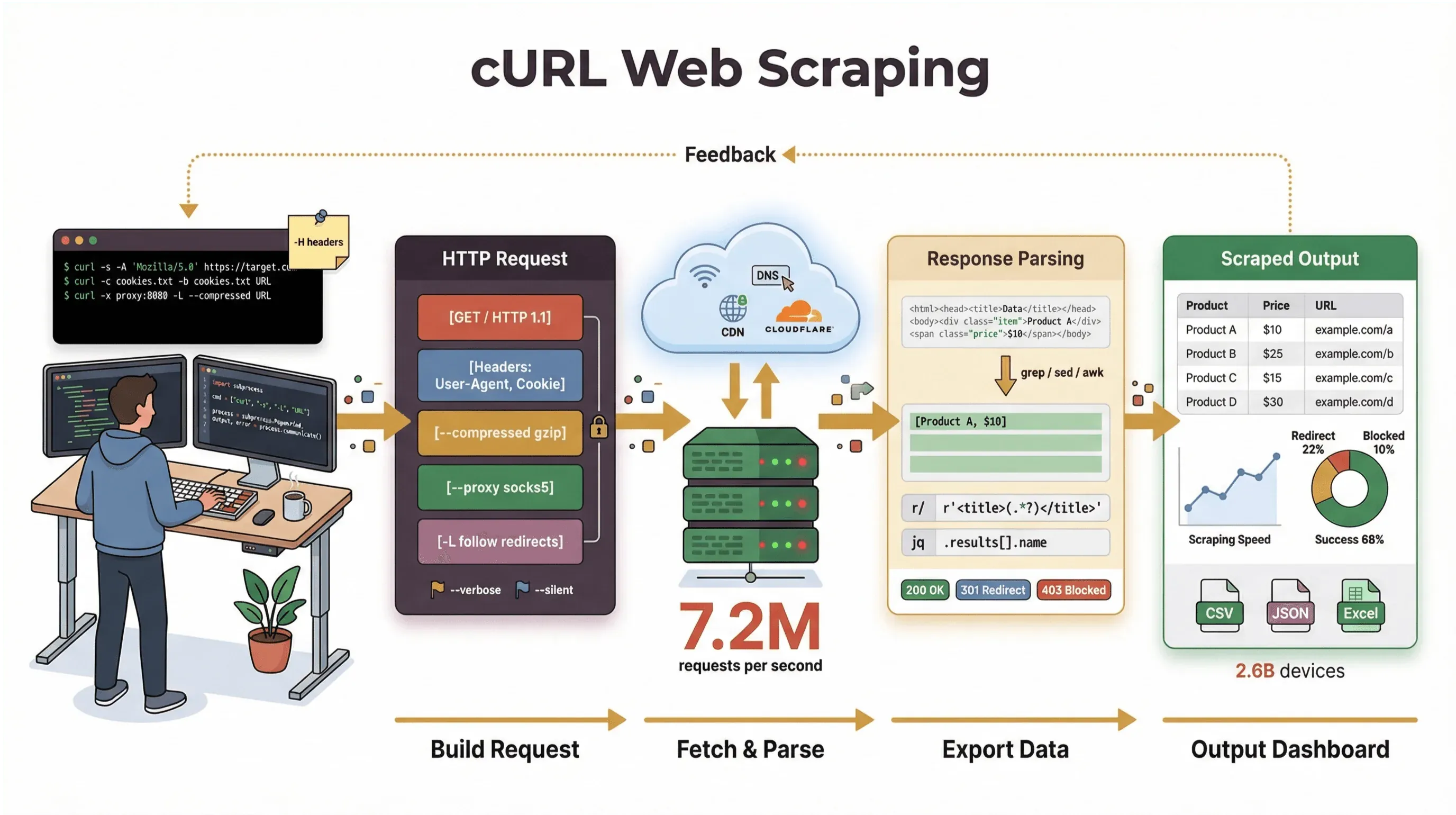 I’ve spent years building automation tools and helping teams wrangle web data, and I still reach for cURL when I need to grab a page, debug an API, or prototype a scraping workflow. In this guide, I’ll walk you through a curl web scraping tutorial that covers both the basics and the pro tricks—complete with real command examples, practical tips, and a clear-eyed look at where cURL shines (and where it hits a wall). And if you’re more of a business user who’d rather not touch the command line, I’ll show you how Thunderbit, our AI-powered web scraper, can take you from “I need this data” to “here’s my spreadsheet” in two clicks—no code required.
I’ve spent years building automation tools and helping teams wrangle web data, and I still reach for cURL when I need to grab a page, debug an API, or prototype a scraping workflow. In this guide, I’ll walk you through a curl web scraping tutorial that covers both the basics and the pro tricks—complete with real command examples, practical tips, and a clear-eyed look at where cURL shines (and where it hits a wall). And if you’re more of a business user who’d rather not touch the command line, I’ll show you how Thunderbit, our AI-powered web scraper, can take you from “I need this data” to “here’s my spreadsheet” in two clicks—no code required.
Let's dive in and see why cURL is still relevant for web scraping in 2026, how to use it effectively, and when it's time to reach for something even more powerful.
What is cURL? The Foundation of Web-Scraping-with-curl
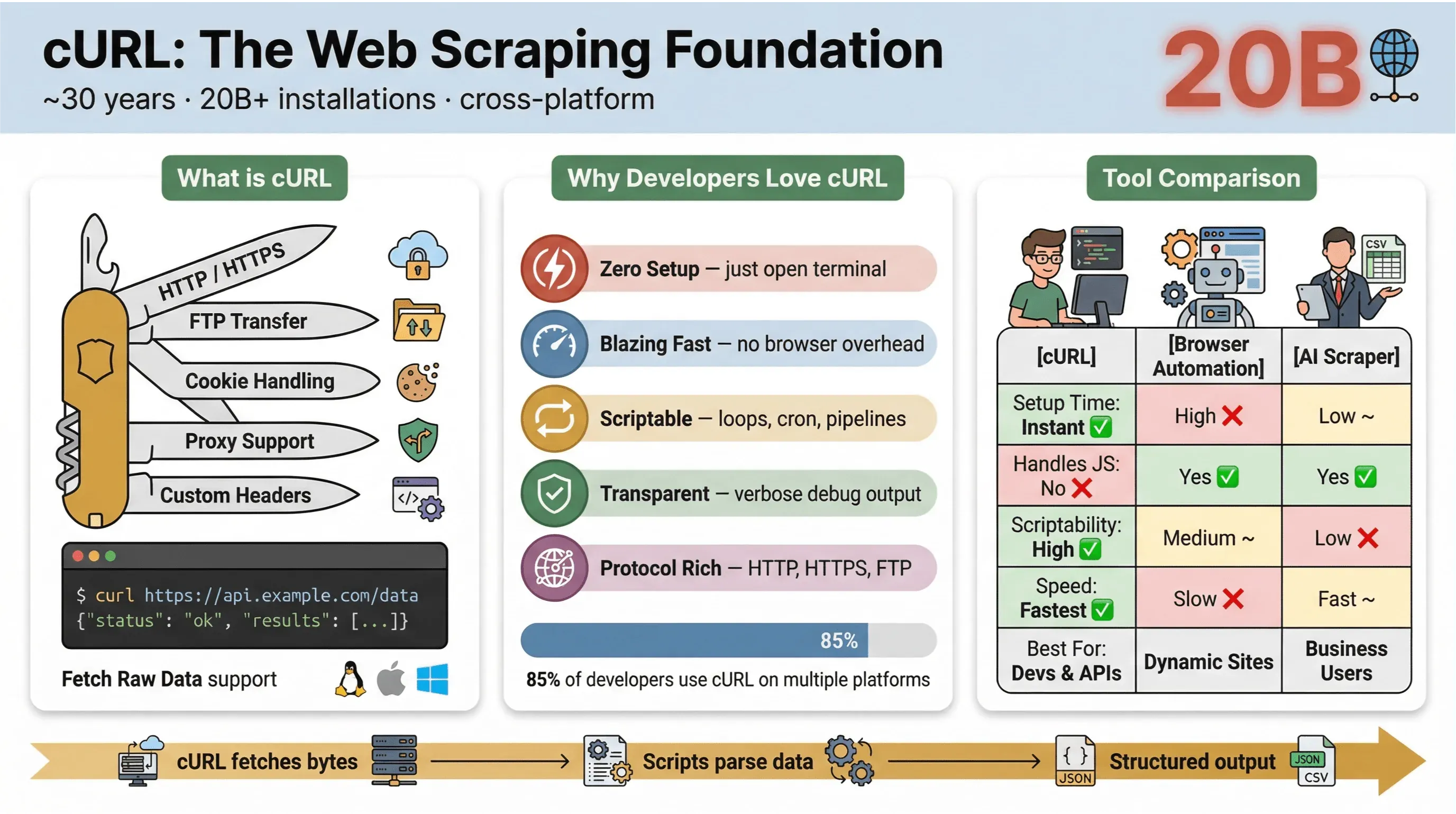
At its core, cURL is a command-line tool and library for transferring data with URLs. It’s been around for nearly 30 years (yes, really), and it’s everywhere—embedded in operating systems, powering scripts, and quietly handling data transfers in more than twenty billion installations. If you’ve ever run a quick command to fetch a web page, test an API, or download a file, there’s a good chance you’ve used cURL.
 Here’s what makes cURL so popular for web scraping:
Here’s what makes cURL so popular for web scraping:
- Lightweight and cross-platform: Runs on Linux, macOS, Windows, and even embedded devices.
- Protocol support: Handles HTTP, HTTPS, FTP, and more.
- Scriptable: Perfect for automation, cron jobs, and glue code.
- No user interaction required: Designed for non-interactive use—great for batch jobs and pipelines.
But let’s be clear: cURL’s main job is to fetch raw data—HTML, JSON, images, you name it. It doesn’t parse, render, or structure that data for you. Think of cURL as the “first mile” of web scraping: it gets you the bytes, but you’ll need other tools (like Python scripts, grep/sed/awk, or an AI web scraper) to turn that into structured information.
If you want to see the official docs, check out cURL’s HTTP scripting guide.
Why Use cURL for Web Scraping? (curl web scraping tutorial)
So why do developers and technical users keep coming back to cURL for web scraping, even with all the new tools out there? Here’s what makes cURL stand out:
- Minimal setup: No installs, no dependencies—just open your terminal and go.
- Speed: Instantly fetch data without waiting for a browser to load.
- Scriptability: Easily loop over URLs, automate requests, and chain commands.
- Protocol and feature support: Handle cookies, proxies, redirects, custom headers, and more.
- Transparency: See exactly what’s happening with verbose/debug output.
In the 2025 cURL user survey, 85.7% of respondents said they use the cURL command-line tool, and 96.2% reported using it on Linux — still the top platform for cURL by a wide margin.
--- It’s still the Swiss Army knife for HTTP requests, quick data pulls, and troubleshooting.
Here’s a quick comparison of cURL versus other scraping methods:
| Feature | cURL | Browser Automation (e.g., Selenium) | AI Web Scraper (e.g., Thunderbit) |
|---|---|---|---|
| Setup Time | Instant | High | Low |
| Scriptability | High | Medium | Low (no code needed) |
| Handles JavaScript | No | Yes | Yes (Thunderbit: via browser) |
| Cookie/Session Support | Manual | Automatic | Automatic |
| Data Structuring | Manual (parse later) | Manual (parse later) | AI/Template-based |
| Best For | Devs, quick pulls | Complex, dynamic sites | Business users, structured export |
In short: cURL is unbeatable for quick, scriptable data grabs—especially for static pages, APIs, or when you want to automate simple workflows. But as soon as you need to parse complex HTML, handle JavaScript, or export structured data, you’ll want something more specialized.
Getting Started: Basic cURL Web Scraping Command Examples
Let’s get hands-on. Here’s how to use cURL for basic web scraping tasks, step by step.
Fetching Raw HTML with cURL
The simplest use case: grab the HTML of a web page.
curl https://books.toscrape.com/
This command fetches the homepage of Books to Scrape, a public demo site for web scraping. You’ll see the raw HTML output in your terminal—look for tags like <title> or snippets like “In stock.”
Saving Output to a File
Want to save that HTML for later parsing? Use the -o flag:
curl -o page.html https://books.toscrape.com/
Now you’ll have a page.html file with the full HTML content. This is perfect for running further analysis or parsing with other tools.
Sending POST Requests with cURL
Need to submit a form or interact with an API? Use the -d flag for POST requests. Here’s an example using httpbin, a site designed for HTTP testing:
curl -X POST https://httpbin.org/post -d "key1=value1&key2=value2"
You’ll get a JSON response echoing your submitted data—great for testing and prototyping.
Inspecting Headers and Debugging
Sometimes you want to see the response headers or debug the request:
-
Headers only (HEAD request):
curl -I https://books.toscrape.com/ -
Include headers with body:
curl -i https://httpbin.org/get -
Verbose/debug output:
curl -v https://books.toscrape.com/
These flags help you understand what’s happening under the hood—essential for troubleshooting.
Here’s a quick reference table for these commands:
| Task | Command Example | Notes |
|---|---|---|
| Fetch HTML | curl URL | Outputs HTML to terminal |
| Save to file | curl -o file.html URL | Writes output to file |
| Inspect headers | curl -I URL or curl -i URL | -I for HEAD only, -i includes headers with body |
| POST form data | curl -d "a=1&b=2" URL | Sends form-encoded data |
| Debug request/response | curl -v URL | Shows detailed request/response info |
For more examples, check out the official cURL scripting docs.
Level Up: Advanced Web Scraping with cURL (web-scraping-with-curl)
Once you’re comfortable with the basics, cURL opens up a world of advanced features for more complex scraping tasks.
Handling Cookies and Sessions
Many sites require cookies to maintain login sessions or track users. With cURL, you can store and reuse cookies across requests:
# Store cookies after login
curl -c cookies.txt https://example.com/login
# Use cookies for subsequent requests
curl -b cookies.txt https://example.com/account
This lets you mimic browser sessions and access pages behind login walls (as long as there’s no JavaScript challenge).
Spoofing User-Agent and Custom Headers
Some websites serve different content based on your User-Agent or headers. By default, cURL identifies itself as “curl/VERSION,” which can trigger blocks or alternate content. To mimic a browser:
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" https://example.com/
You can also set custom headers, like language preferences:
curl -H "Accept-Language: en-US,en;q=0.9" https://example.com/
This helps you get the same content a real browser would see.
Using Proxies for Web Scraping
Need to route your requests through a proxy (for geo-testing or to avoid IP bans)? Use the -x flag:
curl -x http://proxy.example.org:4321 https://remote.example.org/
Just be sure you’re using proxies responsibly and within the site’s terms of service.
Automating Multi-Page Scraping
Want to scrape multiple pages—like paginated product listings? Use a simple shell loop:
for p in $(seq 2 5); do
curl -s -o "books-page-${p}.html" \
"https://books.toscrape.com/catalogue/category/books_1/page-${p}.html"
sleep 1
done
This grabs pages 2 to 5 of the Books to Scrape catalog and saves each to a separate file. (Page 1 is the homepage.)
Limitations of Web-Scraping-with-curl: What You Need to Know
As much as I love cURL, it’s not a silver bullet. Here’s where it falls short:
- No JavaScript execution: cURL can’t handle pages that require JavaScript to render content or solve anti-bot challenges (developers.cloudflare.com).
- Manual parsing required: You get raw HTML or JSON, but you’ll need to parse it yourself—often with additional scripts or tools.
- Limited session handling: Managing complex logins, tokens, or multi-step forms can get messy fast.
- No built-in data structuring: cURL doesn’t turn web pages into rows, tables, or spreadsheets.
- Susceptible to anti-bot detection: Many sites now use advanced bot defenses (JavaScript, fingerprinting, CAPTCHAs) that cURL simply can’t bypass (datadome.co).
Here’s a quick comparison table:
| Limitation | cURL Alone | Modern Scraping Tools (e.g., Thunderbit) |
|---|---|---|
| JavaScript Support | No | Yes |
| Data Structuring | Manual | Automatic (AI/Template) |
| Session Handling | Manual | Automatic |
| Anti-Bot Bypass | Limited | Advanced (browser-based/AI) |
| Ease of Use | Technical | Non-technical |
For static pages and APIs, cURL is fantastic. For anything more dynamic or protected, you’ll want to move up the toolchain.
Thunderbit vs. cURL: The Best Web Scraping Approach for Non-Technical Users
Now, let’s talk about Thunderbit, our AI-powered web scraper Chrome Extension. If you’re a sales rep, marketer, or operations pro who just wants to get data from a website into Excel, Google Sheets, or Notion—without touching the command line—Thunderbit is built for you.
Here’s how Thunderbit compares to cURL:
| Feature | cURL | Thunderbit |
|---|---|---|
| User Interface | Command line | Point-and-click (Chrome Extension) |
| AI Field Suggestion | No | Yes (AI reads page, suggests columns) |
| Handles Pagination/Subpages | Manual scripting | Automatic (AI detects and scrapes) |
| Data Export | Manual (parse + save) | Direct to Excel, Google Sheets, Notion, Airtable |
| JavaScript/Protected Pages | No | Yes (browser-based scraping) |
| No-Code Required | No (requires scripting) | Yes (anyone can use) |
| Free Tier | Always free | Free for up to 6 pages (10 with trial boost) |
With Thunderbit, you just open the extension, click “AI Suggest Fields,” and let the AI figure out what data to extract. You can scrape tables, lists, product details, and even visit subpages automatically. Then, export your data directly to your favorite business tools—no parsing, no headaches.
Thunderbit is trusted by over 100,000 users worldwide, and it's especially popular among sales, ecommerce, and real estate teams who need structured data fast.
Try Thunderbit Chrome Extension for Web Scraping
Want to try it? Download the Chrome Extension here.
Combining cURL and Thunderbit: Flexible Web Scraping Strategies
If you’re a technical user, there’s no need to pick just one tool. In fact, many teams use cURL and Thunderbit together for maximum flexibility:
- Prototype with cURL: Use cURL to quickly test endpoints, inspect headers, and understand how a site responds.
- Scale up with Thunderbit: When you need structured data, multi-page scraping, or a repeatable workflow, switch to Thunderbit for point-and-click extraction and direct exports.
Here’s a sample workflow for market research:
- Use cURL to fetch a few pages and inspect the HTML structure.
- Identify the data fields you want (e.g., product names, prices, reviews).
- Open Thunderbit, click “AI Suggest Fields,” and let the AI set up the scraper.
- Scrape all pages (including subpages or paginated lists) and export to Google Sheets.
- Analyze, share, and act on your data—no manual parsing required.
Here’s a quick decision table:
| Scenario | Use cURL | Use Thunderbit | Use Both |
|---|---|---|---|
| Quick API or static page fetch | ✅ | ||
| Need structured data in a spreadsheet | ✅ | ||
| Debugging headers/cookies | ✅ | ||
| Scraping dynamic/JS-heavy pages | ✅ | ||
| Building a repeatable, no-code workflow | ✅ | ||
| Prototyping, then scaling up | ✅ | ✅ | Hybrid workflow |
Common Challenges and Pitfalls in Web Scraping with cURL
Before you go wild with cURL, let’s talk about the real-world challenges you’ll face:
- Anti-bot systems: Many sites now use advanced defenses (JavaScript challenges, CAPTCHAs, fingerprinting) that cURL can’t bypass (developers.cloudflare.com).
- Data quality issues: HTML changes, missing fields, or inconsistent layouts can break your scripts.
- Maintenance overhead: Every time a site changes, you’ll need to update your parsing logic.
- Legal and compliance risks: Always check the site’s terms of service, robots.txt, and relevant laws before scraping. Just because data is public doesn’t mean it’s free to use (calawyers.org, polsinelli.com).
- Scaling limits: cURL is great for small jobs, but for large-scale scraping, you’ll need to manage proxies, rate limits, and error handling.
Tips for troubleshooting and staying compliant:
- Always start with permissioned or demo sites (like Books to Scrape).
- Respect rate limits—don’t hammer endpoints.
- Avoid scraping personal data unless you have a lawful basis.
- If you hit JavaScript or CAPTCHA walls, consider switching to a browser-based tool like Thunderbit.
Step-by-Step Summary: How to Scrape Websites with cURL
Here’s your quick-reference checklist for web-scraping-with-curl:
- Identify your target URL(s): Start with a static page or API endpoint.
- Fetch the page:
curl URL - Save output to a file:
curl -o file.html URL - Inspect headers/debug:
curl -I URL,curl -v URL - Send POST data:
curl -d "a=1&b=2" URL - Handle cookies/sessions:
curl -c cookies.txt ...,curl -b cookies.txt ... - Set custom headers/User-Agent:
curl -A "..." -H "..." URL - Follow redirects:
curl -L URL - Use proxies (if needed):
curl -x proxy:port URL - Automate multi-page scraping: Use shell loops or scripts.
- Parse and structure data: Use additional tools/scripts as needed.
- Switch to Thunderbit for structured, no-code scraping or dynamic pages.
Conclusion & Key Takeaways: Choosing the Right Web Scraping Tool
Scrape data from any website using AI Get Started Free
Web-scraping-with-curl is still a powerful skill for technical users in 2026—especially for quick data pulls, prototyping, and automation. cURL’s speed, scriptability, and ubiquity make it a staple in every developer’s toolbox. But as the web gets more dynamic and protected, and as business users demand structured data without code, tools like Thunderbit are redefining what’s possible.
Key takeaways:
- Use cURL for static pages, APIs, and quick prototyping—especially when you want full control.
- Switch to Thunderbit (or similar AI web scrapers) when you need structured data, handle dynamic/JavaScript-heavy pages, or want a no-code, business-friendly workflow.
- Combine both for maximum flexibility: prototype with cURL, scale up and structure with Thunderbit.
- Always scrape responsibly—respect site terms, rate limits, and legal boundaries.
Curious to see how easy web scraping can be? Try Thunderbit’s free Chrome Extension and experience AI-powered data extraction for yourself. And if you want to go deeper, check out the Thunderbit Blog for more tutorials, tips, and industry insights. You may also like:
- How to Scrape Any Website Using AI
- How to Scrape Website Data into Excel using AI
- What Is Data Scraping and How to Do It in 2025
Happy scraping—and may your data always be clean, structured, and just a command (or click) away.
Explore Thunderbit Plans for Scalable Web Scraping
FAQs
1. Can cURL handle JavaScript-rendered web pages?
No, cURL cannot execute JavaScript. It fetches raw HTML as delivered by the server. If a page requires JavaScript to render content or solve anti-bot challenges, cURL will not be able to access the data. For those cases, use browser-based tools like Thunderbit.
2. How do I save cURL output directly to a file?
Use the -o flag: curl -o filename.html URL. This writes the response body to a file instead of displaying it in your terminal.
3. What’s the difference between cURL and Thunderbit for web scraping?
cURL is a command-line tool for fetching raw web data—great for technical users and automation. Thunderbit is an AI-powered Chrome Extension designed for business users who want to extract structured data from any website, handle dynamic pages, and export directly to tools like Excel or Google Sheets—no code required.
4. Is it legal to scrape websites with cURL?
Scraping public data is generally legal in the U.S. after recent court rulings, but always check the website’s terms of service, robots.txt, and relevant laws. Avoid scraping personal or protected data without permission, and respect rate limits and ethical guidelines (calawyers.org, polsinelli.com).
5. When should I switch from cURL to a more advanced tool like Thunderbit?
If you need to scrape dynamic/JavaScript-heavy pages, want structured data in a spreadsheet, or prefer a no-code workflow, Thunderbit is the better choice. Use cURL for quick, technical tasks; use Thunderbit for business-friendly, repeatable data extraction.
For more web scraping tips and tutorials, visit the Thunderbit Blog or check out our YouTube Channel.
Try Thunderbit AI Web Scraper Get Started Free




