
Picture this: It’s 2025, you’re sipping your morning coffee, and you want to know if Walmart just dropped the price on that 65-inch TV you’ve been eyeing—or maybe you’re running an e-commerce business and need to keep tabs on Walmart’s pricing, inventory, and customer sentiment in real time. Manually checking Walmart’s website for every product, every day? That’s a full-time job (and not a fun one). But with a little Python and some web scraping know-how, you can automate the grunt work and unlock a goldmine of data.
I’ve spent years building automation and AI tools for business users. Walmart scraping is one of those “secret weapons” that can turn hours of tedious research into a few lines of code—and I’m here to show you exactly how to do it. In this guide, I’ll walk you through what Walmart scraping is, why it’s so valuable for business in 2025, and how to build a robust Walmart scraper in Python—step by step, with real code and practical tips. Grab your coffee (or your favorite debugging snack), and let’s get started.
What is Walmart Scraping? The Basics for 2025
Let’s break it down: Walmart scraping means automatically extracting product, price, and review data from Walmart’s website using software—usually a script that acts like a super-speedy web browser. Instead of copying and pasting info by hand (which, trust me, nobody enjoys), you write a Python script that fetches Walmart pages, digs out the data you want, and saves it for analysis.
Why Python? Well, Python is the Swiss Army knife of web scraping: it’s easy to read, has fantastic libraries (like Requests, BeautifulSoup, and pandas), and there’s a huge community sharing tips and code. Whether you’re a solo researcher or part of a business team, Python makes scraping Walmart approachable—even if you’re not a full-time developer.
It’s also important to note the difference between scraping for personal use (say, tracking prices on a few products for your own shopping) and for business use (like monitoring thousands of SKUs for competitive intelligence). The scale and complexity ramp up quickly for businesses, and so do the technical challenges—especially since Walmart doesn’t offer a public product API as of 2025 ().
Why Scrape Walmart? Real Business Value
Walmart isn’t just America’s biggest brick-and-mortar retailer—it’s now a digital powerhouse, with online sales topping and e-commerce making up nearly 18% of total sales (). That’s a lot of products, prices, reviews, and trends—ripe for analysis.
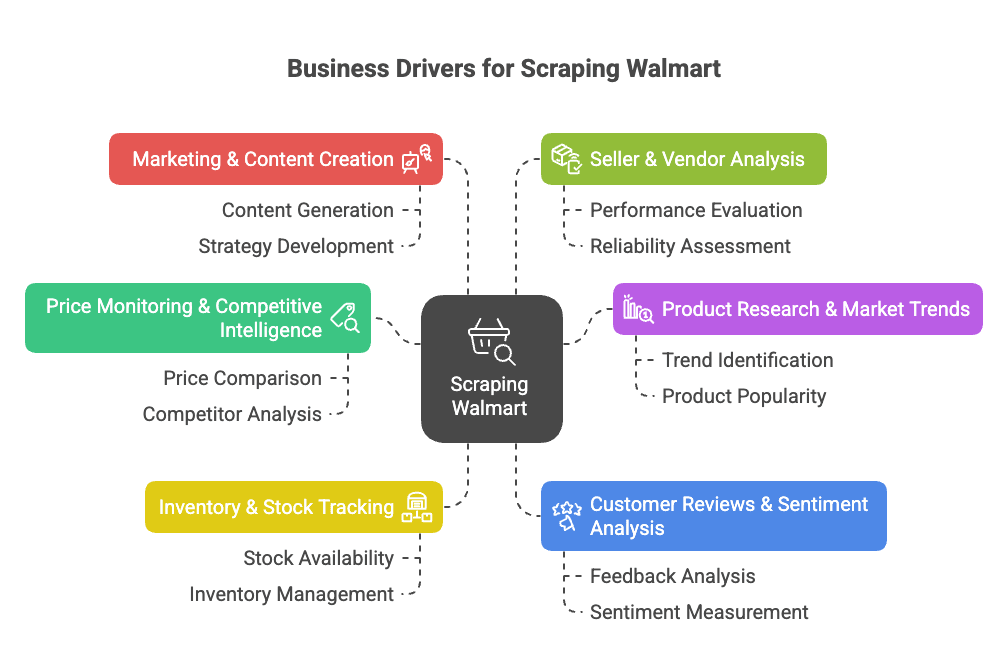
So, why scrape Walmart? Here are the big business drivers:
- Price Monitoring & Competitive Intelligence: Instantly track Walmart’s prices, promotions, and catalog changes to inform your own pricing and product strategies ().
- Product Research & Market Trends: Analyze Walmart’s assortment, specs, and category trends to spot gaps or new opportunities ().
- Inventory & Stock Tracking: Monitor in-stock/out-of-stock status to optimize your supply chain or capitalize on competitor shortages ().
- Customer Reviews & Sentiment Analysis: Aggregate and analyze reviews to improve products or identify pain points ().
- Marketing & Content Creation: See which products are labeled “Bestseller,” how they’re presented, and what content drives conversions ().
- Seller & Vendor Analysis: Identify top-performing third-party sellers or unauthorized listings ().
Here’s a quick table to sum up the use cases, who benefits, and what you get out of it:
| Use Case | Who Benefits | Benefits & ROI |
|---|---|---|
| Price Monitoring | Pricing & Sales Teams | Real-time competitor pricing, dynamic pricing, protect margins |
| Assortment & Catalog Analysis | Product Management, Merchandising | Identify gaps, launch new products, improve catalog completeness |
| Stock Level Tracking | Operations & Supply Chain | Better demand forecasting, avoid stockouts, optimize distribution |
| Customer Reviews & Sentiment | Product Dev, Customer Experience | Data-driven product improvements, increased satisfaction |
| Market Trends & Analytics | Strategy & Market Research | Spot trends, inform strategic decisions, enter new segments early |
| Content & Pricing Strategy | Marketing & E-commerce Teams | Refine pricing, learn from high-performing content |
| Seller Monitoring | Sales & Partnership Teams | Find partners, protect brand, monitor unauthorized sellers |
The bottom line? Walmart scraping saves time, boosts revenue, and gives you a data edge. Instead of manually checking 50 pages every morning, your script can pull thousands of listings in minutes ().
Walmart scraping is a game-changer for e-commerce, sales, and market research teams. With the right tools, you can automate data collection and focus on insights, not grunt work.
Walmart Scraping with Python: What You’ll Need
Before you start scraping, you’ll need to set up your Python environment. Here’s your toolkit:
- Python 3.9+ (I recommend 3.11 or 3.12 if you’re reading this in 2025)
- Requests: For fetching web pages
- BeautifulSoup (bs4): For parsing HTML
- pandas: For organizing and exporting data
- json: For handling JSON data (built-in)
- A web browser with Developer Tools: To inspect Walmart’s page structure (F12 is your friend)
- pip: To install Python packages
Quick install command:
1pip install requests beautifulsoup4 pandasOptional: If you want to keep your project tidy, set up a virtual environment:
1python3 -m venv walmart-scraper
2source walmart-scraper/bin/activate # On Mac/Linux
3# or
4walmart-scraper\\Scripts\\activate.bat # On WindowsTest your setup with:
1import requests, bs4, pandas
2print("Libraries loaded successfully!")If you see that message, you’re good to go.
Step 1: Setting Up Your Python Walmart Scraper
Let’s get organized:
- Create a project folder (e.g.,
walmart_scraper/). - Open your code editor (VSCode, PyCharm, or even Notepad++—no judgment here).
- Start a new script (e.g.,
walmart_scraper.py).
Here’s a quick template to kick things off:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pd
4import jsonYou’re now ready for the main event: fetching Walmart product pages.
Step 2: Fetching Walmart Product Pages with Python
To scrape Walmart, you need to fetch the HTML of a product page. But here’s the catch: Walmart is pretty aggressive about blocking bots. If you just use requests.get(url), you’ll probably get a “Robot or human?” challenge faster than you can say “rollback savings.”
The trick? Mimic a real browser. That means setting headers like User-Agent and Accept-Language to look like Chrome or Firefox.
Here’s how:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0 Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9"
4}
5response = requests.get(url, headers=headers)
6html = response.textPro tip: Use a requests.Session() to persist cookies and look even more like a human:
1session = requests.Session()
2session.headers.update(headers)
3session.get("<https://www.walmart.com/>") # Grab homepage to set cookies
4response = session.get(product_url)Always check response.status_code (should be 200). If you get a weird page or a CAPTCHA, slow down, try a different IP, or take a break. Walmart’s anti-bot system is no joke ().
Handling Walmart’s Anti-Bot Measures
Walmart uses tools like Akamai and PerimeterX to sniff out bots by checking your IP, headers, cookies, and even your TLS fingerprint. Here’s how to stay under the radar:
- Always set realistic headers (see above).
- Throttle your requests—wait 3–6 seconds between page loads.
- Randomize your delays so you don’t look like a robot on a caffeine bender.
- Rotate proxies if you’re scraping at scale (more on that later).
- If you see a CAPTCHA, back off—don’t try to brute-force your way through.
If you want to go full ninja, libraries like curl_cffi can make your Python requests look even more like Chrome (). But for most use cases, headers and patience go a long way.
Step 3: Extracting Walmart Product Data with BeautifulSoup
Now for the fun part: pulling out the data you care about. Walmart’s site is built with Next.js, so most product info is embedded in a <script id="__NEXT_DATA__"> tag as a big JSON blob.
Here’s how you grab it:
1from bs4 import BeautifulSoup
2import json
3soup = BeautifulSoup(html, "html.parser")
4script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
5if script_tag:
6 json_text = script_tag.string
7 data = json.loads(json_text)Now, you’ve got a Python dictionary with all the product info. For a typical product page, you’ll find the details under:
1product_data = data["props"]["pageProps"]["initialData"]["data"]["product"]Then, extract what you need:
1name = product_data.get("name")
2price_info = product_data.get("price", {})
3current_price = price_info.get("price")
4currency = price_info.get("currency")
5rating_info = product_data.get("rating", {})
6average_rating = rating_info.get("averageRating")
7review_count = rating_info.get("numberOfReviews")
8description = product_data.get("shortDescription") or product_data.get("description")Why use the JSON? Because it’s structured, robust, and less likely to break if Walmart tweaks their HTML. Plus, you get all the juicy details—sometimes even more than what’s visible on the page ().
Working with Dynamic Content and JSON Data
Sometimes, things like reviews or stock status are loaded dynamically via JavaScript or separate API calls. The good news: the initial JSON often includes a snapshot of what you need. If not, you can inspect the Network tab in your browser’s DevTools to find the API endpoints Walmart uses and mimic those requests.
But for most product data, the __NEXT_DATA__ JSON is your best friend.
Step 4: Saving and Exporting Walmart Data
Once you’ve got your data, you’ll want to save it in a structured format—CSV, Excel, or JSON are all good options. Here’s how to do it with pandas:
1import pandas as pd
2product_record = {
3 "Product Name": name,
4 "Price (USD)": current_price,
5 "Rating": average_rating,
6 "Review Count": review_count,
7 "Description": description
8}
9df = pd.DataFrame([product_record])
10df.to_csv("walmart_products.csv", index=False)If you’re scraping multiple products, just append each record to a list and create the DataFrame at the end.
Want Excel? Use df.to_excel("walmart_products.xlsx", index=False) (make sure you have openpyxl installed). For JSON: df.to_json("walmart_products.json", orient="records", indent=2).
Pro tip: Always spot-check your exported data to make sure it matches what’s on the site. Nothing’s worse than thinking you’ve scraped 1,000 prices, only to realize they’re all “None” because Walmart changed a key name.
Step 5: Scaling Up Your Walmart Scraper
Ready to go big? Here’s how to scrape multiple product pages:
1product_urls = [
2 "<https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/720559357>",
3 "<https://www.walmart.com/ip/SAMSUNG-65-Class-QLED-4K-Q60C/180355997>",
4 # ...more URLs
5]
6all_records = []
7for url in product_urls:
8 resp = session.get(url)
9 # ...parse and extract as before...
10 all_records.append(product_record)
11 time.sleep(random.uniform(3, 6)) # Be polite!If you don’t have a list of URLs, you can start from a search results page, extract product links, and then scrape each one ().
But beware: Scraping hundreds or thousands of pages quickly will almost certainly get your IP blocked. That’s where proxies come in.
Using Proxies and Scraper APIs for Walmart
Proxies let you rotate your IP address, making it harder for Walmart to block you. You can buy residential proxies (which look like real users) or use proxy pools. Here’s how you’d use a proxy with requests:
1proxies = {
2 "http": "<http://your.proxy.address>:port",
3 "https": "<https://your.proxy.address>:port"
4}
5response = session.get(url, proxies=proxies)For large-scale scraping, you might want to use a scraper API—these services handle proxies, CAPTCHAs, and even JavaScript rendering for you. You just send a Walmart URL, and they send back the data (sometimes already parsed as JSON).
Here’s a quick comparison:
| Approach | Pros | Cons | Best For |
|---|---|---|---|
| DIY Python + Proxies | Full control, cost-effective for small jobs | Maintenance, proxy costs, risk of blocks | Developers, custom needs |
| Third-Party Scraper API | Easy, handles anti-bot, scales well | Cost at scale, less flexibility, third-party dependency | Business users, large-scale, quick results |
If you’re not a developer or just want the data fast, tools like can do all this with a couple of clicks—no code, no proxies, no headaches. (More on that in a bit.)
Common Challenges in Walmart Scraping (and How to Solve Them)
Walmart scraping isn’t all sunshine and rollback prices. Here are the most common headaches—and how to fix them:
- Aggressive Anti-Bot Measures: Walmart uses advanced detection (IP, headers, cookies, TLS fingerprinting, JavaScript checks). Solution: Set realistic headers, use sessions, add delays, and rotate proxies ().
- CAPTCHAs: If you get hit with a CAPTCHA, pause and retry later. For persistent issues, consider CAPTCHA-solving services, but these add cost and complexity ().
- Site Structure Changes: Walmart updates their site often. If your scraper breaks, re-inspect the JSON structure and update your code. Modular code helps here.
- Pagination & Subpages: Scraping lots of data means handling pagination. Use loops with proper stop conditions, and always check if you’ve reached the end ().
- Data Volume & Rate Limits: For huge scrapes, batch your requests and write partial results to disk. Don’t try to load 100,000 products into memory at once.
- Legal & Ethical Issues: Only scrape public data, respect Walmart’s terms, and don’t overload their servers. If you’re building a business on this data, double-check compliance.
When should you switch to a managed solution? If you’re spending more time fighting CAPTCHAs than analyzing data, it might be time to use a tool like Thunderbit or a scraper API. For non-developers, no-code tools are often the smartest move ().
Walmart Scraping with Python: Full Example Code
Let’s put it all together. Here’s a complete, annotated Python script for scraping Walmart product pages:
1import requests
2from bs4 import BeautifulSoup
3import json
4import pandas as pd
5import time
6import random
7# Set up session and headers
8session = requests.Session()
9session.headers.update({
10 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0 Safari/537.36",
11 "Accept-Language": "en-US,en;q=0.9"
12})
13# Visit homepage to set cookies
14session.get("<https://www.walmart.com/>")
15# List of product URLs to scrape
16product_urls = [
17 "<https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/720559357>",
18 "<https://www.walmart.com/ip/SAMSUNG-65-Class-QLED-4K-Q60C/180355997>",
19 # Add more URLs as needed
20]
21all_products = []
22for url in product_urls:
23 try:
24 response = session.get(url)
25 except Exception as e:
26 print(f"Request error for \{url\}: \{e\}")
27 continue
28 if response.status_code != 200:
29 print(f"Failed to fetch \{url\} (status \{response.status_code\})")
30 continue
31 soup = BeautifulSoup(response.text, "html.parser")
32 script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
33 if not script_tag:
34 print(f"No data script found for \{url\} - possibly blocked or changed page format.")
35 continue
36 try:
37 data = json.loads(script_tag.string)
38 except json.JSONDecodeError as e:
39 print(f"JSON parse error for \{url\}: \{e\}")
40 continue
41 try:
42 product_info = data["props"]["pageProps"]["initialData"]["data"]["product"]
43 except KeyError:
44 print(f"Product data not found in JSON for \{url\}.")
45 continue
46 name = product_info.get("name")
47 brand = product_info.get("brand", {}).get("name") or product_info.get("brand", "")
48 price_obj = product_info.get("price", {})
49 price = price_obj.get("price")
50 currency = price_obj.get("currency")
51 orig_price = price_obj.get("priceStrikethrough") or price_obj.get("price_strikethrough")
52 rating_obj = product_info.get("rating", {})
53 avg_rating = rating_obj.get("averageRating")
54 review_count = rating_obj.get("numberOfReviews")
55 desc = product_info.get("description") or product_info.get("shortDescription") or ""
56 product_record = {
57 "URL": url,
58 "Name": name,
59 "Brand": brand,
60 "Price": price,
61 "Currency": currency,
62 "OriginalPrice": orig_price,
63 "AverageRating": avg_rating,
64 "ReviewCount": review_count,
65 "Description": desc
66 }
67 all_products.append(product_record)
68 # Random delay to avoid detection
69 time.sleep(random.uniform(3.0, 6.0))
70df = pd.DataFrame(all_products)
71print(df.head(5))
72df.to_csv("walmart_scrape_output.csv", index=False)Customize:
- Add more URLs to
product_urls. - Tweak the fields you extract based on your needs.
- Adjust the delay for your risk tolerance.
Conclusion & Key Takeaways
Let’s recap what we’ve covered:
- Walmart scraping is a powerful way to unlock pricing, product, and review data—critical for competitive intelligence, pricing, and product development in 2025.
- Python is your go-to tool: With Requests, BeautifulSoup, and pandas, you can build a robust scraper—even if you’re not a coding whiz.
- Anti-bot defenses are real: Mimic browser headers, use sessions, add delays, and rotate proxies as you scale.
- Extract data from the
__NEXT_DATA__JSON: It’s cleaner, more robust, and less likely to break than scraping HTML tags. - Export your data for analysis: Use pandas to save to CSV, Excel, or JSON.
- Scale thoughtfully: For large jobs, consider proxies or a scraper API. If you’re not technical, can handle Walmart (and other sites) in just a couple of clicks—no code required. You can even export directly to Excel, Google Sheets, Airtable, or Notion for free ().
My advice:
Start small—scrape a single product, then a handful. Make sure your data is accurate. Respect Walmart’s terms and don’t overload their servers. As your needs grow, consider moving to managed tools or APIs to save time and headaches. And if you ever get tired of debugging Python, remember: with Thunderbit, you can scrape Walmart (and just about any site) in two clicks, with AI handling all the heavy lifting ().
Want to dive deeper into web scraping, data automation, or AI-powered productivity? Check out more guides on the .
Happy scraping—and may your data always be fresh, accurate, and free of CAPTCHAs.
P.S. If you ever find yourself scraping Walmart at 2am and muttering at your screen, just remember: even the best of us have been there. Debugging is just character building for data people.
FAQs
1. Is it legal to scrape data from Walmart’s website using Python?
Scraping publicly available data for personal or non-commercial analysis is generally permissible, but business use may raise legal and ethical concerns. Always consult Walmart’s terms of service and ensure your scraping does not violate rate limits, overload their servers, or harvest sensitive data.
2. What kind of data can I extract from Walmart using Python scraping?
You can extract product names, prices, brand info, descriptions, customer reviews, ratings, stock status, and more—especially by parsing the structured JSON found in Walmart’s <script id="__NEXT_DATA__"> tag.
3. How do I avoid getting blocked while scraping Walmart?
Use realistic headers, maintain sessions, add random delays between requests (3–6 seconds), rotate proxies, and avoid making too many requests in a short period. For larger projects, consider scraper APIs or tools like Thunderbit that handle anti-bot detection automatically.
4. Can I scale up to scrape hundreds or thousands of Walmart product pages?
Yes, but you’ll need to manage proxies, implement request throttling, and possibly use a scraper API for efficiency. Walmart has robust anti-bot measures, so scaling without preparation can result in blocks or CAPTCHA challenges.
5. What’s the easiest way to scrape Walmart if I don’t know how to code?
Tools like Thunderbit’s AI Web Scraper Chrome Extension let you scrape Walmart product pages without writing a single line of code. It handles anti-bot protections, supports data export to Excel, Notion, and Sheets, and is ideal for non-developers or business teams needing quick insights.