
After running somewhere north of a thousand scrapes with Simplescraper, I stopped counting successes and started cataloging failures. That shift — from "did it work?" to "why did it break this time?" — taught me more than any documentation page ever could.
Simplescraper is a solid Chrome extension for pulling data off websites without writing code. With on the Chrome Web Store and a genuinely approachable point-and-click interface, it's earned its place in the no-code scraping toolkit. But here's what nobody tells you on the landing page: getting consistent, reliable results at scale requires understanding where visual scrapers get fragile. A that workers spend more than nine hours a week on repetitive data entry — which is exactly the kind of pain that drives people to tools like Simplescraper. But if you don't know the tool's quirks, you'll spend those nine hours debugging instead of doing something useful. This article covers the five best practices I've distilled from real operational experience: troubleshooting selection failures, choosing the right scraping mode, maximizing the free tier, avoiding blocks, and knowing when to move on.

What Is Simplescraper (and Why Best Practices Matter)
Simplescraper is a Chrome extension that lets you visually select elements on a web page — product titles, prices, images, contact info — and extract them into structured data without writing a line of code. You point, you click, and it builds a "recipe" that can be reused on similar pages.
The core model works like this:
- Visual element selection: Click on what you want. Simplescraper auto-detects repeating patterns (lists of products, search results, job postings).
- Recipes: Save your extraction setup to reuse later or run on batches of URLs.
- Two scraping modes: Browser (local, runs in your Chrome) and Cloud (runs on Simplescraper's servers, unattended).
- Integrations: Export to Google Sheets, Airtable, webhooks, Zapier, Make, CSV, and JSON.
- AI extraction: A newer that generates CSS selectors from a schema prompt.
The target audience is broad — marketers, sales teams, e-commerce operators, researchers — anyone who needs to pull structured data from websites without hiring a developer. And for straightforward pages, Simplescraper delivers quickly.
So why do best practices matter? Because the moment you move past a simple product listing or a clean directory page, friction appears. Dynamic content, anti-bot measures, lazy-loaded images, nested HTML structures — these are the real-world conditions that separate a frustrating experience from a productive one. Knowing the right approach upfront saves hours of trial and error.
Best Practice 1: What to Do When Simplescraper Fails to Select Elements
This is the single most common frustration I've seen. You click an element, Simplescraper highlights it, you feel good — and then the output is missing half your data. Photos are blank. Bios are empty. Locations vanished.
The founder himself that "the element/css selector still ain't 100%." That honesty is refreshing, but it doesn't fix your broken scrape at 11pm on a Wednesday.
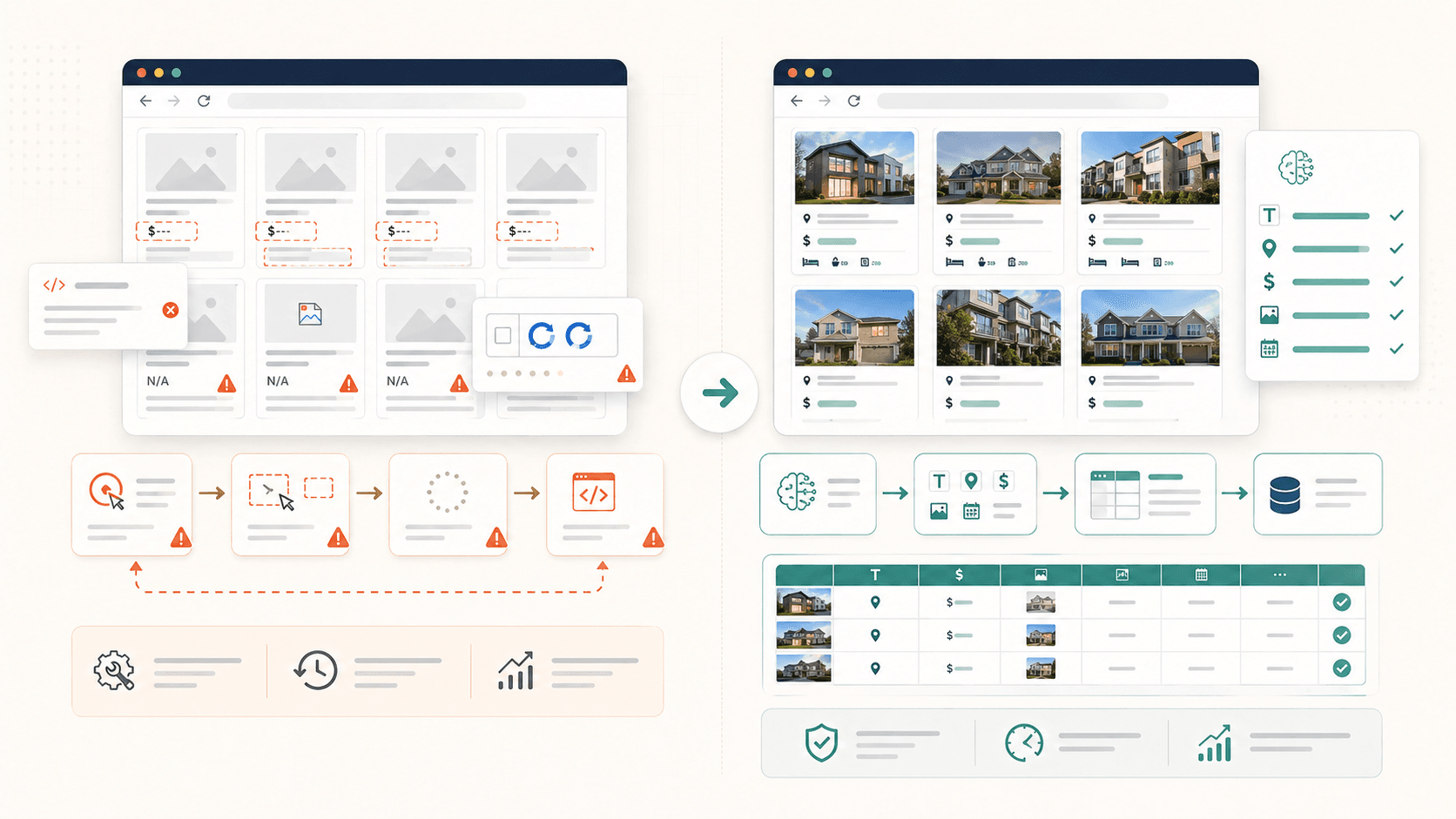
Common Selection Failures (and Why They Happen)
Four patterns trip up Simplescraper most often:
- Lazy-loaded images: The image element literally until you scroll down to it. If you scrape before scrolling, you get empty image fields.
- Nested or grouped containers: Simplescraper's auto-detection , which sometimes means it grabs only one section of a page instead of the full repeating set. Users report tables that "won't select all rows in 1 go."
- Dynamic JavaScript content: Elements that render after the initial page load via React, Vue, or AJAX calls simply aren't there when the scraper acts too early.
- Infinite scroll pagination: The data you want hasn't been loaded into the HTML yet because it requires scrolling or clicking "load more."
Practical Troubleshooting Steps
Before you reach for manual selectors, try these:
- Scroll the entire page first. This forces lazy-loaded images and content into the DOM.
- Use "Include Similar" when your list count looks suspiciously low. Simplescraper's own docs recommend this for grouped content.
- Wait for full page render on JS-heavy sites. Give it a few extra seconds before triggering the scrape.
- Start with a small sample. Confirm row counts on 2-3 pages before committing to a 500-page batch.
Switching to Manual CSS Selectors
When visual selection keeps failing, it's time to go manual. This is the power move that separates casual users from effective ones.
Here's the workflow:
- Right-click the element you want in Chrome → Inspect.
- In DevTools, identify the element's class name or data attribute (e.g.,
.product-card .priceor[data-test="location"]). - In Simplescraper, switch to the and paste your selector.
- Test the selector by running a small scrape.
Tips for robust selectors:
- Prefer class names (
.listing-title) over positional selectors (div:nth-child(3)) - Use when available — they're usually more stable across site updates
- Avoid deeply nested paths that break when the site's HTML structure changes
The AI Alternative: Let Thunderbit Auto-Detect Fields
I'll be upfront — my team built specifically because we got tired of this exact problem. Thunderbit's "AI Suggest Fields" reads the page structure and recommends columns and extraction logic automatically. No CSS knowledge needed. The AI adapts to each site's layout, including nested content and lazy-loaded images.
If you're spending more than a few minutes per scrape debugging selectors, it's worth trying a different approach entirely.
Best Practice 2: Choosing Between Cloud Scraping and Browser Scraping
Most Simplescraper users pick a mode by default — usually whatever they tried first — without thinking about which mode fits their actual use case. This causes preventable failures.
When to Use Browser (Local) Scraping
- Login-required pages: LinkedIn, CRM dashboards, internal tools — anything behind authentication needs your active browser session.
- Quick one-off extractions: You're already on the page, you just want the data now.
- Preserving free credits: Browser scraping doesn't consume cloud credits.
The tradeoff: your computer must stay on, and large jobs crawl compared to cloud.
When to Use Cloud Scraping
- Public pages (e-commerce listings, directories, real estate sites) where no login is needed.
- Scheduled monitoring: Runs unattended on a recurring basis.
- Batch jobs: in a single cloud batch.
- Integration delivery: Automatic pushes to Google Sheets, Airtable, or webhooks.
The tradeoff: cloud scraping — 2 per JavaScript-enabled page, 1 per non-JS page — and burns through the free tier's 100-credit allowance fast.
Decision Framework
| Scenario | Recommended Mode | Why | Risk if Wrong |
|---|---|---|---|
| Pages requiring login (LinkedIn, dashboards) | Browser | Needs your authenticated session | Cloud mode gets login walls |
| Public e-commerce product listings | Cloud | Faster, runs unattended | Browser mode ties up your machine |
| Scheduled recurring monitoring | Cloud | Runs without you | Browser requires you to be present |
| Anti-bot-heavy sites (Amazon, Yelp) | Browser (fallback) or Cloud w/ proxy | IP rotation or session reuse needed | Cloud without proxy gets blocked fast |
| Quick one-off extraction | Browser | Immediate, no credit cost | Overkill to set up cloud for one page |

How Thunderbit Simplifies This
In , the choice is a simple toggle within the same interface. Cloud mode processes up to 50 pages concurrently — no separate paid tier for cloud access. Browser mode handles login-required sites without extra configuration. The mental overhead of "which mode do I need?" drops significantly when both modes live in the same workflow.
Best Practice 3: Getting the Most Out of Simplescraper's Free Tier
Pricing confusion is real. I've seen forum posts where people assume "free Chrome extension" means "free everything." It doesn't. And on the other end, I've seen people assume Simplescraper is expensive because the paid tiers aren't prominently displayed. Neither assumption is helpful.
What Simplescraper's Free Plan Actually Includes
Per :
- Browser scraping: Unlimited (runs locally in your Chrome)
- Cloud credits: 100 per month
- Saved recipes: 3
- Export formats: CSV and JSON
- What's NOT included: Priority support, advanced proxy options, higher cloud credit allowances
A Realistic Free-Tier Scenario
Say you need to scrape 50 product pages from a public e-commerce site.
- Browser mode (free): You can do this entirely free. Open each page (or use a list), run the recipe, export to CSV. Time required: depends on your patience and internet speed, but expect 15-30 minutes of active work for 50 pages with manual navigation.
- Cloud mode (free tier): With JavaScript rendering enabled, each page costs 2 credits. 50 pages = 100 credits. That's your entire monthly cloud allowance in one job. No scheduling, no retries if something fails.
The free tier is genuinely useful for small, occasional scrapes. But it runs out fast once you need cloud automation or scale.
Free-Tier Comparison: Simplescraper vs. Thunderbit
| Feature | Simplescraper Free | Thunderbit Free |
|---|---|---|
| Pages/credits | Unlimited browser + 100 cloud credits | 6 pages with full AI features |
| AI-powered extraction | Limited (Smart Extract uses credits) | Full AI Suggest Fields included |
| Export destinations | CSV, JSON | Excel, Google Sheets, Airtable, Notion — all free |
| Saved configurations | 3 recipes | Templates available |
| Subpage scraping | Manual recipe setup | Included in page count |
The models are genuinely different. Simplescraper gives you unlimited local scraping with constrained cloud. gives you fewer pages but packs full AI capability into each one, plus free exports to the tools most teams actually use. Simplescraper's free tier works if you need basic local scraping and can tolerate manual work. But if you want AI-powered extraction with flexible exports, Thunderbit's free tier packs more punch per page.
Best Practice 4: How to Avoid Getting Blocked While Scraping
Nobody thinks about anti-bot measures until they're staring at a CAPTCHA wall or an empty dataset. By then you've already burned time and possibly credits.
Proactive defense is always cheaper than reactive troubleshooting.
Set Rate Limits and Pace Your Requests
The number-one reason for getting blocked: hammering a site with rapid-fire requests. To a web server, 50 requests in 10 seconds from one IP looks like an attack, not a curious researcher.
General rules of thumb:
- Add 2-5 seconds between page requests for most commercial sites.
- For sensitive targets (marketplaces, review sites), go slower — 5-10 seconds.
- If you're using Simplescraper's API, the parameter can help ensure pages fully load before extraction, which also naturally slows your pace.
When to Enable Proxy Rotation
Proxy rotation changes your IP address between requests, making you look like multiple different users. You'll need this for:
- Amazon, Yelp, TripAdvisor, LinkedIn (aggressive anti-bot systems)
- Any site that rate-limits per IP
- Large batch jobs (hundreds of pages from one domain)
Simplescraper's platform including standard, premium, and residential options. However, the exact plan-level availability isn't always crystal clear from public docs — verify before assuming the free tier covers hard targets. Residential proxies typically cost more but are less likely to be flagged.
Handling JavaScript-Heavy Sites
Modern sites built with React, Vue, or Angular render content after the initial page load. If your scraper acts before JavaScript finishes executing, you get empty fields.
Strategies:
- Use cloud scraping mode for better rendering (Simplescraper's cloud can execute JavaScript).
- Manually scroll the page before running a browser scrape to trigger lazy-loaded content.
- Use
waitForSelectorin API-based workflows to pause until target elements appear. - Accept that some heavily dynamic single-page apps may simply be beyond what a visual scraper can reliably handle.
The Hands-Off Alternative
handles anti-bot protection, CAPTCHAs, and JavaScript rendering automatically — no proxy configuration, no delay tuning, no manual scrolling. For users who don't want to become amateur DevOps engineers just to scrape a product catalog, that matters. The problems don't disappear — they just become someone else's problem.
Best Practice 5: Know When Simplescraper Has Hit Its Ceiling
I wish someone had written this section for me two years ago.
There's a point where the tool stops being a time-saver and starts being a time-sink. Recognizing that threshold early saves you from the sunk-cost trap of "I've already built 15 recipes, I can't switch now."
Simplescraper's Practical Limits
- Dynamic single-page applications that load content via AJAX without traditional page navigation
- Infinite scroll that requires continuous scrolling to load all items (not standard click-based pagination)
- Subpage enrichment: Scraping a listing page and then visiting each detail page for additional data. Simplescraper can do this with , but the setup complexity grows quickly.
- Layout changes that break existing recipes. When a site updates its HTML structure, your carefully tuned CSS selectors stop working.
Signs You've Outgrown the Tool
You've probably hit the ceiling when:
- You're manually tweaking CSS selectors on every scrape because auto-detection keeps failing
- Recipes break after site updates and require rebuilding
- You need to scrape dozens or hundreds of pages simultaneously but keep hitting credit or speed limits
- Subpage data requires complex multi-step recipe chains
- You spend more time maintaining scrapes than actually using the extracted data
That last one is the clearest signal. When maintenance becomes the job, the no-code convenience dividend is gone.
Moving to an AI-Powered Workflow
This is where I'll talk about what my team built with , because it was designed specifically for the failure modes described above:

- AI reads each page fresh every time — no brittle recipes or CSS selectors to maintain. If a site changes its layout, the AI adapts on the next run.
- Subpage scraping enriches your data table with one click. Scrape a listing, then auto-visit each detail page for additional fields.
- Scheduled scraping using natural language ("every Monday at 9am") instead of configuring timing presets.
- Cloud scraping at 50 pages concurrently for speed on public sites.
- Native free exports to Google Sheets, Airtable, Notion, and Excel without webhook configuration.
Simplescraper vs. Thunderbit: Side-by-Side Comparison
Here's everything in one place:

| Capability | Simplescraper | Thunderbit |
|---|---|---|
| Field setup | Manual CSS selectors / visual selection | AI Suggest Fields (plain English) |
| Subpage enrichment | Possible via batch workflows (complex setup) | 1-click auto-enrich |
| Auto-adapt to layout changes | Breaks (manual fix required) | AI re-reads page structure each time |
| Cloud page concurrency | Batch up to 5,000 URLs (varies by plan) | 50 pages simultaneously |
| Export to Notion/Airtable | Via webhook (paid tiers) | Native, free |
| Scheduling | Preset + custom timing controls | Natural language description |
| Anti-bot / CAPTCHA handling | Proxy modes available (plan-dependent) | Automatic, no configuration |
| Free tier | 100 cloud credits + unlimited browser + 3 recipes | 6 pages with full AI features + free exports |
In short: Simplescraper shines for simple, visual, low-setup extraction where occasional manual tuning is acceptable. Thunderbit picks up where that model breaks down — handling page interpretation, layout adaptation, and workflow complexity so you don't have to.
Neither tool is universally better. They sit at different points on the complexity curve — and that's fine.
Quick-Reference: Simplescraper Best Practices Checklist
Bookmark this for your next scraping session:
- Always test on a small sample first. Confirm row counts and field completeness on 2-3 pages before scaling up.
- Scroll the page before scraping to trigger lazy-loaded content.
- Use "Include Similar" when list detection seems too narrow.
- Choose your scraping mode deliberately. Browser for login-required sites; cloud for public pages and scheduled jobs.
- Set delays between requests — 2-5 seconds minimum for commercial sites, longer for anti-bot-heavy targets.
- Know your free-tier math. 100 cloud credits = 50 JavaScript-enabled pages. Plan accordingly.
- Save recipes only for stable pages. If a site updates frequently, recipes will break.
- Learn basic CSS selectors as a fallback. Class names and data attributes beat positional selectors.
- Monitor for blocks proactively. If you're getting empty results or CAPTCHAs, slow down or switch modes.
- Recognize the ceiling. When maintenance time exceeds data-use time, evaluate alternatives.
Conclusion: Make Every Scrape Count
The overarching lesson from a thousand-plus scrapes isn't about any single tool. It's that approach matters more than software. Understanding why a scrape fails — lazy loading, wrong mode, aggressive anti-bot, brittle selectors — is more valuable than any feature list.
Simplescraper genuinely works well for straightforward extraction jobs. If your pages are clean, your needs are modest, and you don't mind occasional manual tuning — it delivers.
But if you find yourself fighting the tool more than using it — debugging selectors, rebuilding broken recipes, configuring proxies, manually scrolling pages — that's a signal, not a personal failure. It means you've outgrown what visual scraping alone can handle.
If that sounds familiar, give a try — six pages with full AI features, free exports to Sheets, Airtable, and Notion. Compare it to your current workflow and see what sticks. Sometimes the best practice is knowing when to reach for a different tool entirely.
FAQs
Is Simplescraper free to use?
Yes, Simplescraper has a free plan that includes unlimited local browser scraping, , 3 saved recipes, and CSV/JSON export. JavaScript-enabled cloud pages cost 2 credits each, so those 100 credits cover about 50 pages in cloud mode. Paid plans start at $39/month (Plus) for 6,000 credits and $70/month (Pro) for 15,000 credits.
Can Simplescraper handle JavaScript-heavy websites?
Sometimes. Simplescraper's cloud mode can render JavaScript, and the tool advertises support for single-page apps. However, complex SPAs with heavy dynamic rendering, infinite scroll, or aggressive anti-bot systems may still produce incomplete results. Using cloud mode with appropriate wait times improves reliability, but heavily dynamic sites remain a challenge for any visual scraper.
What is the difference between cloud and browser scraping in Simplescraper?
Browser scraping runs locally in your Chrome browser — it uses your active session (great for login-required sites), costs no credits, but requires your computer to stay on. runs on Simplescraper's servers — it's faster, runs unattended, supports scheduling and integrations, but costs credits per page and cannot access pages behind your personal login.
When should I switch from Simplescraper to an alternative like Thunderbit?
The clearest signal is when maintenance time exceeds data-use time. If you're regularly fixing broken selectors after site updates, manually configuring proxies, rebuilding recipes, or spending more time troubleshooting than analyzing your extracted data, you've outgrown what manual visual scraping can efficiently provide. Tools like that use AI to interpret page structure on each run eliminate most of that maintenance burden.
How do I avoid getting blocked when scraping with Simplescraper?
Three key practices: First, pace your requests with 2-5 second delays between pages (longer for anti-bot-heavy sites like Amazon or Yelp). Second, use browser mode as a fallback for sites that aggressively block cloud IPs — your browser session looks more like normal traffic. Third, enable proxy rotation for large batch jobs on sensitive targets, though verify which proxy options your plan includes before relying on them.
Learn More