
Picture this: It’s 2 p.m. on a Tuesday, your boss just asked for a competitor price list, and you’re staring at a website full of juicy data—locked away behind a wall of HTML. Do you roll up your sleeves and start coding a Python scraper? Or do you wish for a magic button that just… does it for you?
Web scraping isn’t just for hackers in hoodies or data scientists with three monitors anymore. It’s become a must-have skill for business teams, marketers, researchers, and anyone who’s ever wanted to turn web pages into spreadsheets. In fact, the web scraping industry is booming—worth and growing fast. But with so many tools out there, picking the right one can feel like choosing between a Swiss Army knife and a scalpel. Today, let’s break down the two Python heavyweights—Scrapy and Beautiful Soup—and see where no-code AI tools like fit into the picture for everyone who’d rather not touch a line of code.
Scrapy vs. Beautiful Soup: The Basics of Python Web Scraping
If you’ve ever Googled “Python scraper,” you’ve probably run into Scrapy and Beautiful Soup. They’re both legends in the Python scraping world, but they play very different roles.
- Scrapy is a framework. Think of it as a full kitchen appliance set: it handles everything from fetching web pages, following links, parsing data, to exporting results. It’s built for big jobs—crawling hundreds or thousands of pages, managing requests, and keeping your data pipeline humming.
- Beautiful Soup is a library. It’s more like a sharp chef’s knife: perfect for slicing and dicing HTML, but you have to bring your own ingredients (like the HTML itself) and do the rest of the cooking (fetching, crawling, saving) yourself.
Both are used to build “Python scrapers”—scripts or programs that extract data from websites. But the choice between them isn’t just about features; it’s about matching the tool to your project and your comfort with code.

When to Use Scrapy: Power and Scale for Web Scraping Projects
Let’s say you’re tasked with scraping an entire e-commerce site—thousands of product pages, regular updates, maybe even dodging some anti-bot roadblocks. This is Scrapy’s home turf.
Scrapy is designed for large-scale, automated web scraping. It’s got:
- Asynchronous requests: Fetch dozens of pages at once, not one after another.
- Built-in crawling: Automatically follow links, handle pagination, and manage a queue of URLs.
- Pipelines: Clean, validate, and export your data to CSV, JSON, or databases—no extra code needed.
- Proxy and user-agent rotation: Outsmart simple anti-bot blocks with built-in middleware.
- Scheduling: Run your spiders on a schedule for ongoing monitoring or data refreshes.
If you’re building something that needs to run every day, handle errors, and scale up as your needs grow, Scrapy is like hiring a professional kitchen staff.
Scrapy Strengths for Python Scraper Projects
- Scalability: Scrapy can crawl thousands (or millions) of pages, managing concurrency and memory efficiently ().
- Speed: Its asynchronous engine means high throughput—great for big jobs ().
- Extensibility: Need to solve CAPTCHAs, render JavaScript, or export to S3? There’s a plugin or middleware for that.
- Automation: Scrapy is built for recurring, production-grade scraping—set it and let it run.
Scrapy Limitations and Learning Curve
But here’s the catch: Scrapy isn’t exactly beginner-friendly. You’ll need to learn about spiders, pipelines, middlewares, and project structures. Installing Scrapy can be a headache (hello, Twisted dependencies), and debugging selectors in a non-visual environment takes patience.
- Steep learning curve: Expect to spend a few hours (or days) getting your first spider running ().
- Not ideal for tiny jobs: If you just want to scrape a single page, Scrapy can feel like overkill.
- Handling JavaScript-heavy sites: Scrapy alone can’t execute JavaScript—you’ll need to integrate with tools like Splash or Selenium for dynamic content.

Beautiful Soup: Quick, Flexible, and Beginner-Friendly Web Scraping
Now, imagine you just want to grab the latest news headlines from a single page, or extract a table from Wikipedia for a one-off analysis. This is where Beautiful Soup shines.
Beautiful Soup is a lightweight HTML/XML parsing library. It doesn’t fetch web pages—you’ll usually pair it with the requests library to download the HTML, then use Beautiful Soup to navigate and extract the data you need.
- Minimal setup: Install with pip, import, and you’re off to the races.
- Gentle learning curve: Even if you’re new to Python, you can get results in an hour or two ().
- Flexible parsing: Search by tag, class, ID, or text—great for messy or irregular HTML.
Beautiful Soup Advantages for Python Scraper Beginners
- Beginner-friendly: No need to learn a framework—just basic Python and HTML.
- Quick results: Perfect for prototyping, academic projects, or one-time data pulls.
- Flexible: Integrates easily with other Python tools (requests, pandas, etc.).
- Handles messy HTML: Beautiful Soup is forgiving—even with broken markup.
Where Beautiful Soup Falls Short
But Beautiful Soup isn’t a full scraping solution:
- No built-in crawling: You have to manually loop through pages or follow links.
- Slower for large jobs: Works sequentially; scraping hundreds of pages can be slow.
- Limited anti-bot features: You’ll need to manually set headers or proxies, and handling blocks is up to you.
- Not great for dynamic content: If the site relies on JavaScript, you’ll need to bring in Selenium or Playwright.

Scrapy vs. Beautiful Soup: Feature-by-Feature Comparison
Let’s put them side by side:
| Feature | Scrapy | Beautiful Soup |
|---|---|---|
| Type | Framework (all-in-one) | Library (parser only) |
| Setup | Project structure, CLI, config files | Simple script, pip install |
| Best for | Large-scale, recurring, automated scraping | Small jobs, prototyping, one-off tasks |
| Speed | Fast at scale (async, concurrent) | Fast for single pages, slow at scale |
| Crawling | Built-in (follows links, pagination) | Manual (write your own loops) |
| Anti-bot features | Proxies, user-agent rotation, retries, plugins | Manual (set headers, proxies in requests) |
| Extensibility | Plugins, middlewares, pipelines | Combine with other Python libs |
| Learning curve | Steep (spiders, pipelines, async) | Gentle (basic Python + HTML) |
| Dynamic content | Needs plugins (Splash, Selenium) | Needs Selenium/Playwright |
| Data export | CSV, JSON, DBs (built-in) | Manual (write to file or use pandas) |
| Best fit | Developers, data engineers, ongoing projects | Beginners, analysts, quick scripts |
In short: Scrapy is your go-to for big, complex, or recurring scraping jobs—if you’re comfortable with Python and frameworks. Beautiful Soup is perfect for small, focused tasks or when you’re just getting started.
Learning Curve: Which Python Scraper Is Easier for Beginners?
Let’s be honest—nobody wants to spend a week learning a tool just to grab a table from a website.
- Beautiful Soup: You can go from zero to scraping in an afternoon. All you need is basic Python and a little HTML. Tons of tutorials exist, and you’ll see results fast ().
- Scrapy: You’ll need to learn about spiders, pipelines, asynchronous flow, and command-line tools. It’s not rocket science, but it’s definitely more than a “hello world” script ().
If you’re a non-technical user, or you just want to get the job done with minimal fuss, Beautiful Soup is a gentler introduction. But if you’re planning to build a scraper that runs every day, handles errors, and scales up, investing the time to learn Scrapy pays off.
Performance and Anti-Bot Capabilities: Scrapy vs. Beautiful Soup in Action
Performance:
- Scrapy: Handles concurrency out of the box. You can scrape 16, 32, or more pages in parallel, making it much faster for big jobs ().
- Beautiful Soup: Works sequentially unless you add your own threading or async logic. Great for a few pages, but slow for hundreds.
Anti-bot:
- Scrapy: Middleware for proxies, user-agent rotation, retries, and even plugins for CAPTCHA solving or JavaScript rendering ().
- Beautiful Soup: You’re on your own. You can set headers or proxies in your requests, but there’s no built-in protection. If you get blocked, you’ll need to debug and patch things up yourself ().
Typical Use Cases: Matching the Python Scraper to Your Project
Here’s a cheat sheet for picking the right tool:
| Use Case | Best Tool | Why? |
|---|---|---|
| Lead generation (small batch) | Beautiful Soup | Quick, one-off extraction from a few pages |
| Lead generation (large/ongoing) | Scrapy or Thunderbit | Scrapy for devs, Thunderbit for non-tech users—handles scale and automation |
| E-commerce price monitoring | Scrapy or Thunderbit | Scrapy for custom, ongoing crawls; Thunderbit for instant, no-code scraping |
| Content/news monitoring | Scrapy or Thunderbit | Scrapy for scheduled, multi-site crawls; Thunderbit for business users, quick setup |
| SEO audits (few pages) | Beautiful Soup | Easy to script, quick results |
| SEO audits (site-wide) | Scrapy | Crawl hundreds of pages, export structured data |
| Social media scraping | Thunderbit | Pre-built templates, handles dynamic content, no coding required |
| Academic research (one-off) | Beautiful Soup | Fast prototyping, minimal setup |
| Data enrichment/aggregation | Thunderbit | AI-powered enrichment, easy export to Sheets/Airtable |
For most business users, if you’re not a developer, tools like are a game-changer (oops, I mean… a real time-saver).
Beyond Python: Introducing Thunderbit for No-Code Web Scraping
Alright, let’s talk about the elephant in the room: not everyone wants to code. And honestly, you shouldn’t have to—especially if your goal is to turn a web page into a spreadsheet, not launch a NASA mission.
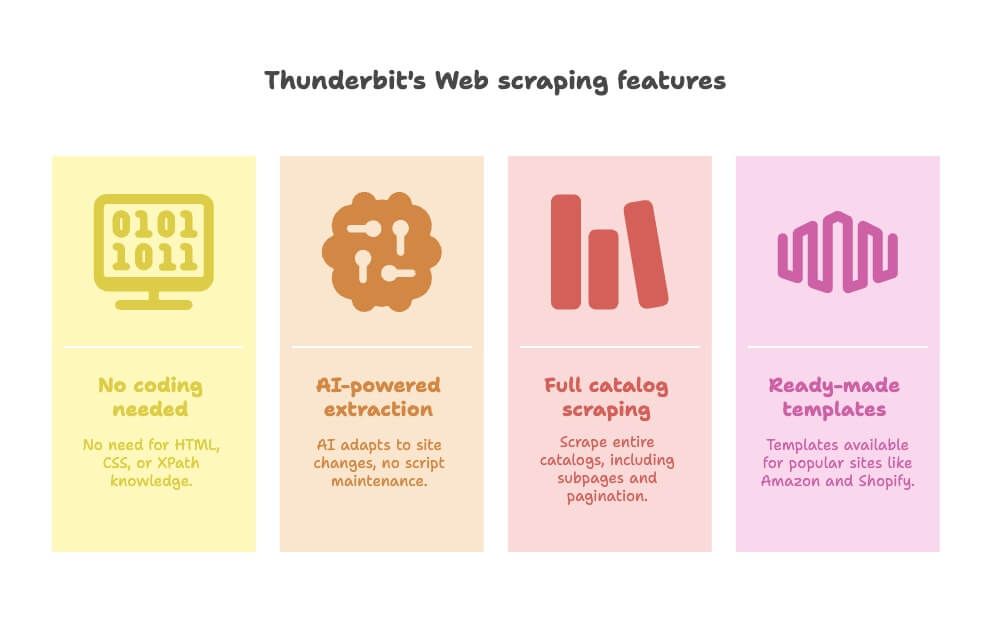
That’s where comes in. Thunderbit is a no-code AI web scraper—a Chrome extension that lets you extract data from any website in just a couple of clicks. Here’s how it flips the script:
- No Python, no setup: Install the extension, open the page, and you’re ready.
- AI field suggestion: Click “AI Suggest Fields” and Thunderbit reads the page, recommends columns, and sets up your table automatically ().
- Subpage scraping: Need to grab details from linked pages? Thunderbit follows links and enriches your data—no nested loops or spiders required ().
- Pagination and infinite scroll: Handles multi-page listings or endless scrolls with a simple toggle.
- Instant data export: Send your data directly to Google Sheets, Airtable, Notion, or download as CSV/Excel ().
- Real-time preview: See your results as you scrape—no more “run and pray” coding.
- AI-powered enrichment: Summarize, categorize, or translate data on the fly ().
And yes, Thunderbit even has pre-built templates for popular sites like Amazon, LinkedIn, Google Maps, and more. For most business scraping needs, it’s as close to “just press the button” as you can get.
Why Choose Thunderbit Over Python Scraping Tools?
- Zero learning curve: You don’t need to know Python, HTML, or how to debug a 403 error. If you can use a browser, you can use Thunderbit.
- Speed: Go from “I need this data” to “Here’s your spreadsheet” in minutes—not hours or days.
- Maintenance-free: Thunderbit’s AI adapts to many site changes, and templates are updated by the team. No more scripts breaking in the middle of the night.
- Anti-bot handling: Runs in your browser (looks like a real user) or in the cloud, with built-in strategies to avoid blocks.
- Collaboration: Share templates and results with your team, no code repos or version control needed.
- Cost-effective: Free tier for small jobs, affordable paid plans for bigger projects ().
For sales, marketing, ops, or anyone who just wants data now, Thunderbit is a breath of fresh air. (And as someone who’s spent too many late nights debugging Python scripts, I can’t tell you how much I appreciate that.)
Choosing the Right Web Scraping Tool: A Practical Guide
So, which tool should you pick? Here’s my quick decision flow:
- Are you comfortable coding in Python?
- Yes: Move to step 2.
- No: Use or another no-code tool.
- Is your project small (one page, one-off, or prototype)?
- Yes: Use Beautiful Soup (with requests).
- No: Use Scrapy for large, recurring, or complex jobs.
- Do you need to handle anti-bot measures, concurrency, or automation?
- Yes: Scrapy is your friend.
- No: Beautiful Soup is fine for simple, low-risk tasks.
- Do you want instant results, easy export, or team collaboration?
- Yes: Thunderbit is the way to go—no code, no hassle.
Here’s a simple checklist:
| Your Need | Best Tool |
|---|---|
| No coding, instant results | Thunderbit |
| Small, one-off, scriptable job | Beautiful Soup |
| Large, automated, complex crawl | Scrapy |
| Ongoing business data collection | Thunderbit or Scrapy |
| Academic prototyping | Beautiful Soup |
Conclusion: Scrapy, Beautiful Soup, or Thunderbit—What’s Best for You?
Web scraping is more accessible—and more essential—than ever. Whether you’re a developer building a robust data pipeline or a business user who just wants to turn a web page into a spreadsheet, there’s a tool that fits your needs.
- Scrapy: Best for developers, large-scale, recurring, or complex scraping projects. Powerful, but comes with a learning curve.
- Beautiful Soup: Ideal for beginners, analysts, or anyone needing to quickly extract data from a few pages. Simple, flexible, and perfect for prototyping.
- Thunderbit: The no-code, AI-powered solution for everyone else. If you want to skip the coding, debugging, and maintenance, Thunderbit lets you scrape, enrich, and export data in minutes—right from your browser.
If you’re ready to see what no-code scraping feels like, and give it a spin. Or check out our for more guides, tips, and use cases.
At the end of the day, the best tool is the one that gets you the data you need—without turning your Tuesday afternoon into a Python debugging marathon. And if you ever want to swap web scraping war stories, you know where to find me.
FAQs
1. Which is better for beginners: Scrapy or Beautiful Soup?
Beautiful Soup is much more beginner-friendly. It’s simpler to install, easier to understand, and ideal for small scraping tasks. Scrapy is powerful but comes with a steeper learning curve—best suited for developers building large or recurring crawlers.
2. Can I use Scrapy or Beautiful Soup without coding?
Not really. Both tools require Python knowledge and some understanding of HTML. If you’re not comfortable writing scripts, a no-code tool like is a better choice—it lets you scrape data using plain language, directly in your browser.
3. Do I need to use both Scrapy and Beautiful Soup together?
In most cases, no. Scrapy has its own parsing engine and works independently. Beautiful Soup is typically used alone for smaller jobs. Advanced users sometimes combine them, but it’s rarely necessary—especially if you're looking for fast, practical results.
4. What if the site uses JavaScript or infinite scroll?
Neither Scrapy nor Beautiful Soup can handle JavaScript out of the box—you’d need to integrate extra tools like Selenium. handles many modern websites automatically, including those with infinite scroll or dynamic content.
5. I just need to turn one webpage into a spreadsheet. Do I really need to learn Python?
No. If your goal is quick, structured data—like pulling a price list or directory into Excel—learning Scrapy or Beautiful Soup is often overkill. can do it in two clicks, without writing a single line of code.
Curious to learn more? Check out , , or explore more on the .