
Let me take you back to my early days in SaaS and automation, when “web crawling” sounded like something a spider might do on a lazy Sunday. Fast forward to today, and web crawling is the backbone of everything from Google Search to your favorite price comparison site. The web is a living, breathing organism, and everyone—from techies to sales teams—wants a piece of its data. But here’s the kicker: while Python has made building web crawlers more accessible, the reality is that most folks just want the data, not a crash course in HTTP headers or JavaScript rendering.
That’s where the story gets interesting. As the co-founder of , I’ve seen firsthand how the need for web data has exploded across industries. Sales teams want fresh leads, ecommerce managers crave competitor prices, and marketers are hungry for content insights. But not everyone has the time (or desire) to become a Python ninja. So, let’s dive into what a web crawler in Python really is, why it matters, and how the rise of AI-powered tools like Thunderbit are changing the game for business users and developers alike.
Web Crawler Python: What Is It and Why Does It Matter?
Let’s clear up a common misconception right away: web crawlers and web scrapers are not the same thing. I know, I know—people use the terms interchangeably, but they’re as different as a Roomba and a Dyson (both clean, but in very different ways).
- Web Crawlers are like the scouts of the internet. Their job is to systematically discover and index web pages, following links from one page to the next—think Googlebot mapping out the entire web.
- Web Scrapers, on the other hand, are more like skilled foragers. They extract specific data from web pages, such as product prices, contact info, or article content.

When people talk about “web crawler Python,” they’re usually referring to using Python to build these automated bots that traverse and sometimes extract data from the web. Python is the go-to language here because it’s easy to learn, has a massive ecosystem of libraries, and—let’s be honest—nobody wants to write a web crawler in Assembly.
Business Value of Web Crawling and Web Scraping
Why do so many teams care about web crawling and scraping? Because web data is the new oil—except you don’t need to drill, just code (or, as we’ll see, click a few buttons).
Here are some of the most common business use cases:
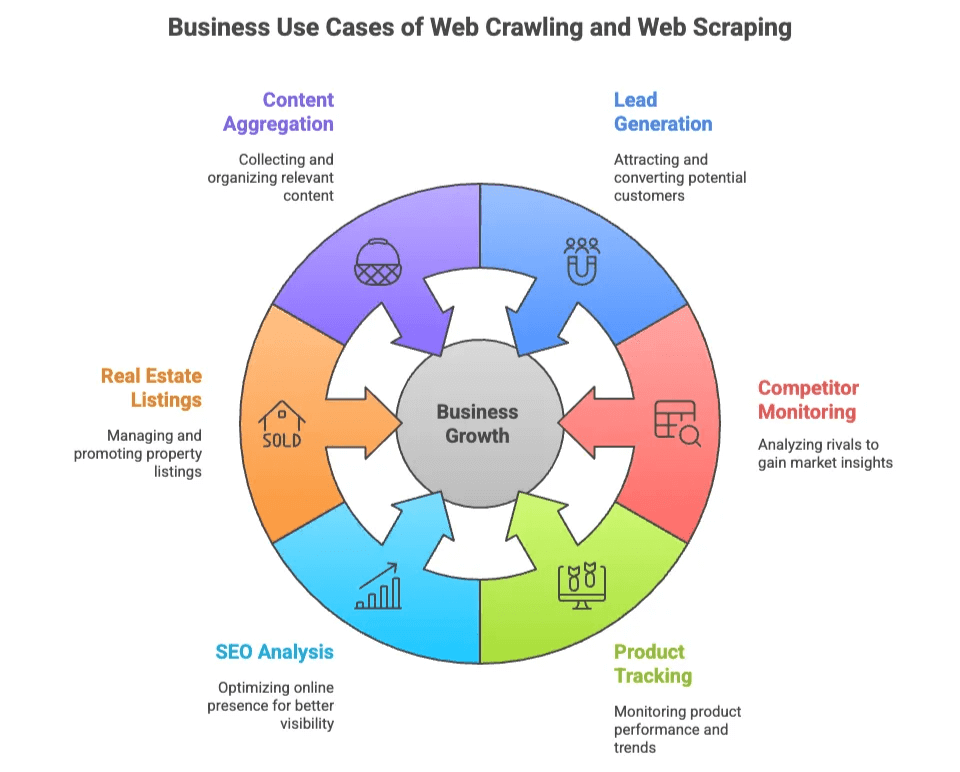
| Use Case | Who Needs It | Value Delivered |
|---|---|---|
| Lead Generation | Sales, Marketing | Build targeted lists of prospects from directories, social sites |
| Competitor Monitoring | Ecommerce, Ops | Track prices, stock, and new products across rival sites |
| Product Tracking | Ecommerce, Retail | Monitor catalog changes, reviews, and ratings |
| SEO Analysis | Marketing, Content | Analyze keywords, meta tags, and backlinks for optimization |
| Real Estate Listings | Realtors, Investors | Aggregate property data and owner contacts from multiple sources |
| Content Aggregation | Research, Media | Collect articles, news, or forum posts for insights |
The beauty is that both technical and non-technical teams can benefit. Developers might build custom crawlers for deep, large-scale projects, while business users just want quick, accurate data—ideally without learning what a CSS selector is.
Popular Python Web Crawler Libraries: Scrapy, BeautifulSoup, and Selenium
Python’s popularity in web crawling isn’t just hype—it’s backed by a trio of libraries that each have their own fan clubs (and quirks).
| Library | Ease of Use | Speed | Dynamic Content Support | Scalability | Best For |
|---|---|---|---|---|---|
| Scrapy | Medium | Fast | Limited | High | Large, automated crawls |
| BeautifulSoup | Easy | Medium | None | Low | Simple parsing, small projects |
| Selenium | Harder | Slow | Excellent | Low-Med | JavaScript-heavy, interactive |
Let’s break down what makes each one tick.
Scrapy: The All-in-One Python Web Crawler
Scrapy is the Swiss Army knife of Python web crawling. It’s a full-fledged framework designed for large-scale, automated crawls—think crawling thousands of pages, handling concurrent requests, and exporting data to pipelines.
Why developers love it:
- Handles crawling, parsing, and data export in one place.
- Built-in support for concurrency, scheduling, and pipelines.
- Great for projects where you need to crawl and scrape at scale.
But… Scrapy has a learning curve. As one developer put it, it’s “over-engineered if you only need to scrape a few pages” (). You’ll need to understand selectors, asynchronous processing, and sometimes even proxies and anti-bot tactics.
Basic Scrapy workflow:
- Define a Spider (the crawler logic).
- Set up Item pipelines (for data processing).
- Run the crawl and export data.
If you’re crawling the web like Google, Scrapy is your friend. If you just want to grab a list of emails, it’s probably overkill.
BeautifulSoup: Simple and Lightweight Web Crawling
BeautifulSoup is the “hello world” of web parsing. It’s a lightweight library focused on parsing HTML and XML, making it perfect for beginners or small projects.
Why people love it:
- Super easy to learn and use.
- Great for extracting data from static pages.
- Flexible for quick-and-dirty scripts.
But… BeautifulSoup doesn’t actually crawl—it parses. You’ll need to pair it with something like requests to fetch pages, and you’ll have to write your own logic for following links or handling multiple pages ().
If you’re just dipping your toes into web crawling, BeautifulSoup is a gentle start. But don’t expect it to handle JavaScript or scale to big projects.
Selenium: Handling Dynamic and JavaScript-Heavy Pages
Selenium is the browser automation king. It can control Chrome, Firefox, or Edge, interact with buttons, fill out forms, and—crucially—render JavaScript-heavy pages.

Why it’s powerful:
- Can “see” and interact with pages just like a human.
- Handles dynamic content and AJAX-loaded data.
- Essential for sites that require login or simulate user actions.
But… Selenium is slow and resource-intensive. It launches a full browser for each page, which can bog down your system if you’re crawling at scale (). Maintenance is also a headache—think managing browser drivers and waiting for dynamic content to load.
Selenium is your go-to when you need to crawl sites that look like Fort Knox to a regular scraper.
Challenges of Building and Running a Python Web Crawler
Now, let’s talk about the not-so-glamorous side of Python web crawling. I’ve spent more hours than I care to admit debugging selectors and fighting anti-bot measures. Here are the big hurdles:
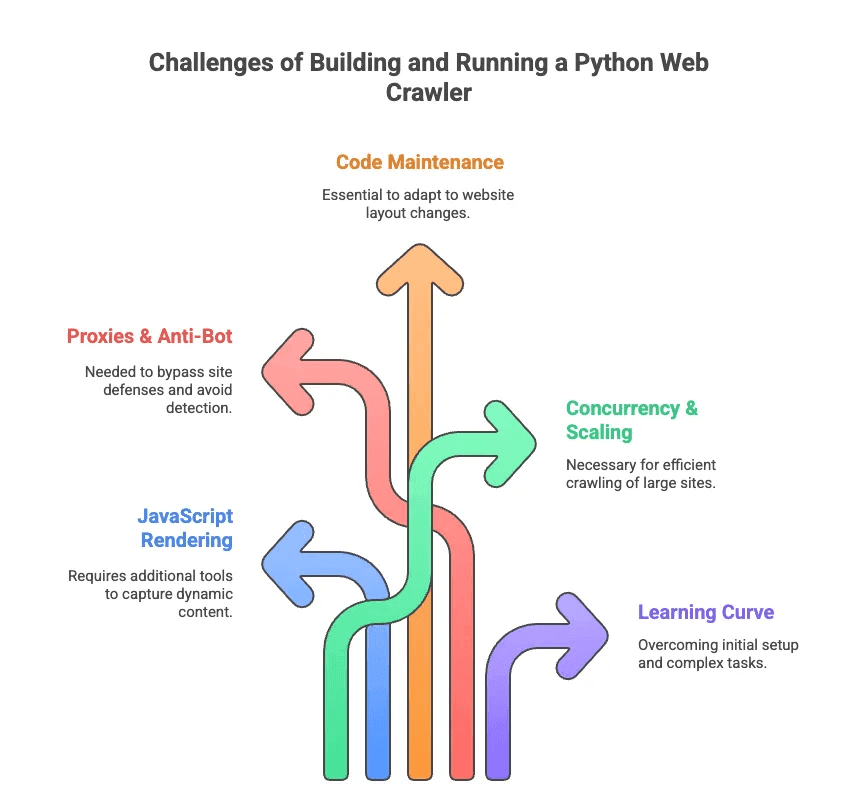
- JavaScript Rendering: Most modern sites load content dynamically. Scrapy and BeautifulSoup can’t see this data without extra tools.
- Proxies & Anti-Bot: Sites don’t like being crawled. You’ll need to rotate proxies, spoof user agents, and sometimes solve CAPTCHAs.
- Code Maintenance: Websites change layouts all the time. Your carefully crafted scraper can break overnight, and you’ll need to update selectors or logic.
- Concurrency & Scaling: Crawling thousands of pages? You’ll need to manage async requests, error handling, and data pipelines.
- Learning Curve: For non-developers, even setting up Python and dependencies can be daunting. Forget about handling pagination or login flows without help.
As one engineer put it, writing custom scrapers often feels like needing “a PhD in selector configuration”—not exactly what your average sales or marketing pro signed up for ().
AI Web Scraper vs. Python Web Crawler: A New Approach for Business Users
So, what if you want the data but not the headaches? Enter the AI web scraper. These tools—like —are built for business users, not coders. They use AI to read web pages, suggest what data to extract, and handle all the messy stuff (pagination, subpages, anti-bot) in the background.
Here’s a quick comparison:
| Feature | Python Web Crawler | AI Web Scraper (Thunderbit) |
|---|---|---|
| Setup | Code, libraries, config | 2-click Chrome extension |
| Maintenance | Manual updates, debugging | AI adapts to site changes |
| Dynamic Content | Selenium or plugins needed | Built-in browser/cloud rendering |
| Anti-Bot Handling | Proxies, user agents | AI & cloud-based bypass |
| Scalability | High (with effort) | High (cloud, parallel scraping) |
| Ease of Use | For developers | For everyone |
| Data Export | Code or scripts | 1-click to Sheets, Airtable, Notion |
With Thunderbit, you don’t need to worry about HTTP requests, JavaScript, or proxies. Just click “AI Suggest Fields,” let the AI figure out what’s important, and hit “Scrape.” It’s like having a personal data butler—minus the tuxedo.
Thunderbit: The Next-Gen AI Web Scraper for Everyone
Let’s get specific. Thunderbit is an designed to make web data extraction as easy as ordering takeout. Here’s what sets it apart:
- AI-Driven Field Detection: Thunderbit’s AI reads the page and suggests which fields (columns) to extract—no more guessing CSS selectors ().
- Dynamic Page Support: Handles both static and JavaScript-heavy pages, thanks to browser and cloud scraping modes.
- Subpage & Pagination: Need details from every product or profile? Thunderbit can click into each subpage and gather info automatically ().
- Template Adaptability: One scraper template can adapt to multiple page structures—no need to rebuild when sites change.
- Anti-Bot Bypass: AI and cloud infrastructure help bypass common anti-scraping defenses.
- Data Export: Send your data straight to Google Sheets, Airtable, Notion, or download as CSV/Excel—no paywall, even on the free tier ().
- AI Data Cleaning: Summarize, categorize, or translate data on the fly—no more messy spreadsheets.
Real-world examples:
- Sales teams scrape prospect lists from directories or LinkedIn in minutes.
- Ecommerce managers monitor competitor prices and product changes without manual effort.
- Realtors aggregate property listings and owner contacts from multiple sites.
- Marketing teams analyze content, keywords, and backlinks for SEO—all without writing a single line of code.
Thunderbit’s workflow is so simple that even my non-technical friends can use it—and they do. Just install the extension, open your target site, click “AI Suggest Fields,” and you’re off to the races. For popular sites like Amazon or LinkedIn, there are even instant templates—one click and you’re done ().
When to Use a Python Web Crawler vs. an AI Web Scraper
So, should you build a Python web crawler or just use Thunderbit? Here’s my honest take:
| Scenario | Python Web Crawler | AI Web Scraper (Thunderbit) |
|---|---|---|
| Need custom logic or massive scale | ✔️ | Maybe (cloud mode) |
| Must integrate deeply with other systems | ✔️ (with code) | Limited (via exports) |
| Non-technical user, need quick results | ❌ | ✔️ |
| Frequent site layout changes | ❌ (manual updates) | ✔️ (AI adapts) |
| Dynamic/JS-heavy sites | ✔️ (with Selenium) | ✔️ (built-in) |
| Budget-conscious, small projects | Maybe (free, but time) | ✔️ (free tier, no paywall) |
Choose Python web crawlers if:
- You’re a developer and need full control.
- You’re crawling millions of pages or need custom data pipelines.
- You’re okay with ongoing maintenance and debugging.
Choose Thunderbit if:
- You want data now, not after a week of coding.
- You’re in sales, ecommerce, marketing, or real estate and just need the results.
- You don’t want to mess with proxies, selectors, or anti-bot headaches.
Still not sure? Here’s a quick checklist:
- Are you comfortable with Python and web technologies? If yes, try Scrapy or Selenium.
- Do you just want the data, fast and clean? Thunderbit is your friend.
Conclusion: Unlocking Web Data—The Right Tool for the Right User
Web crawling and web scraping have become essential skills in today’s data-driven world. But let’s be real: not everyone wants to become a web crawling guru. Python web crawlers like Scrapy, BeautifulSoup, and Selenium are powerful, but they come with a steep learning curve and ongoing maintenance.
That’s why I’m so excited about the rise of AI web scrapers like . We built Thunderbit to put the power of web data in everyone’s hands—not just developers. With AI-driven field detection, dynamic page support, and no-code workflows, anyone can extract the data they need in minutes.
So, whether you’re a developer who loves tinkering with code or a business user who just wants the data, there’s a tool out there for you. Evaluate your needs, your technical comfort, and your timeline. And if you want to see just how easy web data extraction can be, —your future self (and your spreadsheet) will thank you.
Want to dig deeper? Check out more guides on the , like or . Happy crawling—and happy scraping!
FAQs
1. What’s the difference between a Python Web Crawler and a Web Scraper?
A Python web crawler is built to systematically explore and index web pages by following hyperlinks—ideal for discovering site structures. A web scraper, on the other hand, extracts specific data from those pages, like prices or emails. Crawlers map the internet; scrapers collect what you care about. Both are often used together in Python for end-to-end data extraction workflows.
2. Which Python libraries are best for building a Web Crawler?
Popular libraries include Scrapy, BeautifulSoup, and Selenium. Scrapy is fast and scalable for large projects; BeautifulSoup is beginner-friendly but works best for static pages; Selenium excels with JavaScript-heavy sites but is slower. The best choice depends on your technical skills, content type, and project size.
3. Is there an easier way to get web data without coding a Python Web Crawler?
Yes—Thunderbit is an AI-powered Chrome extension that lets anyone extract web data in just two clicks. No code, no setup. It auto-detects fields, handles pagination and subpages, and exports data to Sheets, Airtable, or Notion. Perfect for sales, marketing, ecom, or real estate teams who just want clean data—fast.
Learn More: