

Some people collect stamps. Others collect sneakers. But if you're in sales, marketing, e-commerce, or operations in 2026, chances are you're collecting something a little more… digital. Web data. And not just a little bit—businesses are now spending an average of $5 million a year on web data collection, with web scraping now a standard tool across departments, from strategy to customer service (source).
With this explosion in demand, two names keep popping up in every Python scraping tutorial and business data project: Playwright and Selenium. Both started as browser automation tools for testing, but now they’re the go-to frameworks for anyone looking to turn the web into structured, actionable data. But here’s the catch: choosing between them isn’t just a technical decision—it’s about picking the right tool for your real-world scraping needs. And if you’re not a developer, or you just want results fast, there’s an even easier path (hint: it doesn’t involve writing a single line of Python). Let’s dig in.
From Testing Tools to Web Scraping Powerhouses: Playwright and Selenium Explained
Let’s set the stage. Selenium has been around since 2004, and it’s the old reliable of browser automation. Originally built for QA testers, it lets you control browsers like Chrome, Firefox, and even Internet Explorer (for those who like living dangerously). Playwright, on the other hand, burst onto the scene in 2020, backed by Microsoft, with a modern take on browser automation—think of it as Selenium’s younger, faster sibling.
Both tools let you write scripts (often in Python) that open a browser, navigate to a website, click buttons, fill forms, and—most importantly for us—extract data. While their roots are in automated testing, they’ve become the backbone of web scraping for everything from price monitoring to lead generation (source). Their popularity isn’t just among developers: more and more business users are rolling up their sleeves to build their own scrapers, or at least trying to.
But here’s the twist: when you’re scraping data, your priorities shift. You care less about test coverage and more about getting data reliably, avoiding blocks, and not spending your weekend debugging Python errors. That’s where the real differences between Playwright and Selenium come into play.
Core Differences: Playwright vs. Selenium for Web Scraping

Let’s get straight to the point: Playwright and Selenium can both scrape websites, but they shine in different scenarios.
- Selenium is the veteran. It works with almost every browser and language, has a massive community, and is a great fit for scraping older, static websites with predictable layouts.
- Playwright is the new kid with modern features. It’s designed for today’s dynamic, JavaScript-heavy sites, with built-in tools for handling logins, pop-ups, infinite scroll, and more. It’s also faster and easier to set up, especially for Python users.
But don’t just take my word for it—let’s break it down feature by feature.
Feature Comparison Table: Playwright vs. Selenium
| Feature | Selenium | Playwright |
|---|---|---|
| Language Support | Python, Java, C#, JS, Ruby, more | Python, JS/TS, Java, C# |
| Browser Support | Chrome, Firefox, Edge, Safari, IE, Opera | Chromium (Chrome/Edge), Firefox, WebKit |
| Setup Complexity | Needs browser driver, manual config | One command installs everything |
| Speed/Performance | Slower, more resource-heavy | Generally faster on JS-heavy pages; async/concurrent by design |
| Dynamic Content Handling | Manual waits, more code required | Auto-waits, handles JS-heavy sites easily |
| Anti-Bot Evasion | Prone to detection, needs add-ons | Built-in stealth, better at mimicking users |
| Debugging Tools | Basic (Selenium IDE, screenshots) | Inspector, video recording, codegen |
| Community Support | Huge, mature, lots of tutorials | Growing fast, modern docs, active devs |
| Python Scraper Workflow | More setup, more boilerplate | Smoother, less code, easier for beginners |
Choosing the Right Tool: When to Use Playwright or Selenium for Web Scraping
So, which one should you pick for your next scraping project? Here’s my take, after years of building automation tools and helping teams get data out of the wild west of the web.
- Selenium is your friend if:
- The site you’re scraping is old-school—think static HTML, minimal JavaScript, and no fancy pop-ups.
- You need to support weird browsers (hello, Internet Explorer) or integrate with legacy systems.
- You want the comfort of a massive community and endless StackOverflow answers.
- You’re already familiar with Selenium from testing projects.
- Playwright is the way to go if:
- The site is modern, dynamic, and full of JavaScript (think e-commerce, social media, or anything that makes your laptop’s fan spin).
- You need to log in, click through tabs, handle infinite scroll, or deal with pop-ups.
- You want to get up and running fast, with less setup and less code.
- You’re tired of writing
time.sleep(5)everywhere and want the tool to handle timing for you.
Here’s a simple rule of thumb: If your first attempt at scraping a site with Selenium involves a lot of “why isn’t this loading?” moments, it’s probably time to try Playwright.
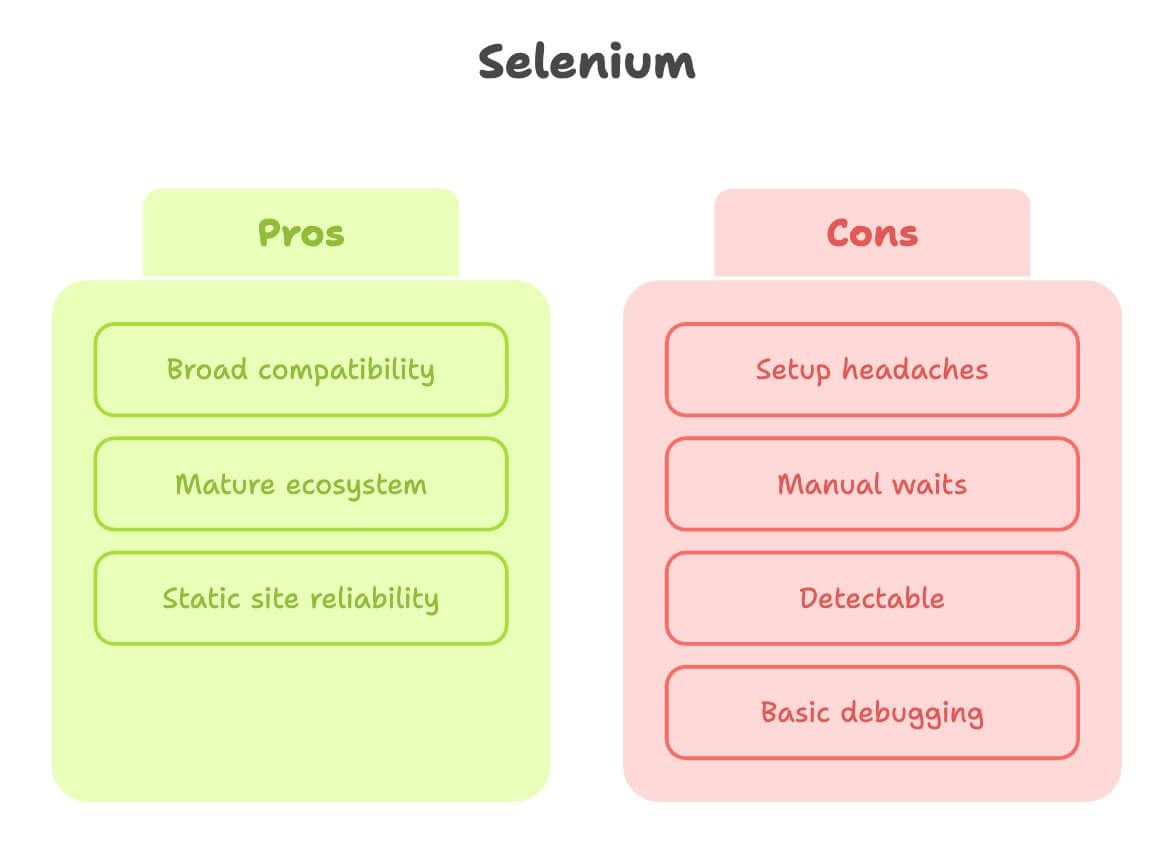
Selenium for Web Scraping: Strengths and Limitations
Let’s give Selenium its due. It’s the granddaddy of browser automation, and for a lot of scraping jobs, it just works.
Strengths:
- Broad compatibility: Works with almost every browser and language.
- Mature ecosystem: Tons of tutorials, Q&A, and plugins.
- Great for static sites: If the page doesn’t change much, Selenium is rock solid.
Limitations:
- Setup headaches: You need to download and configure a browser driver (like ChromeDriver), and keep it updated. Beginners often get stuck here (source).
- Manual waits: Dynamic content? You’ll be writing a lot of explicit waits or, worse, random sleep statements.
- Easier to detect: Many sites can spot Selenium-driven browsers and block them, especially if you’re running on a cloud server.
- Debugging is basic: No built-in video recording or interactive inspector.
In short, Selenium is perfect for simple, stable sites—but can feel like pushing a boulder uphill on modern, interactive pages.
Playwright for Web Scraping: Strengths and Limitations
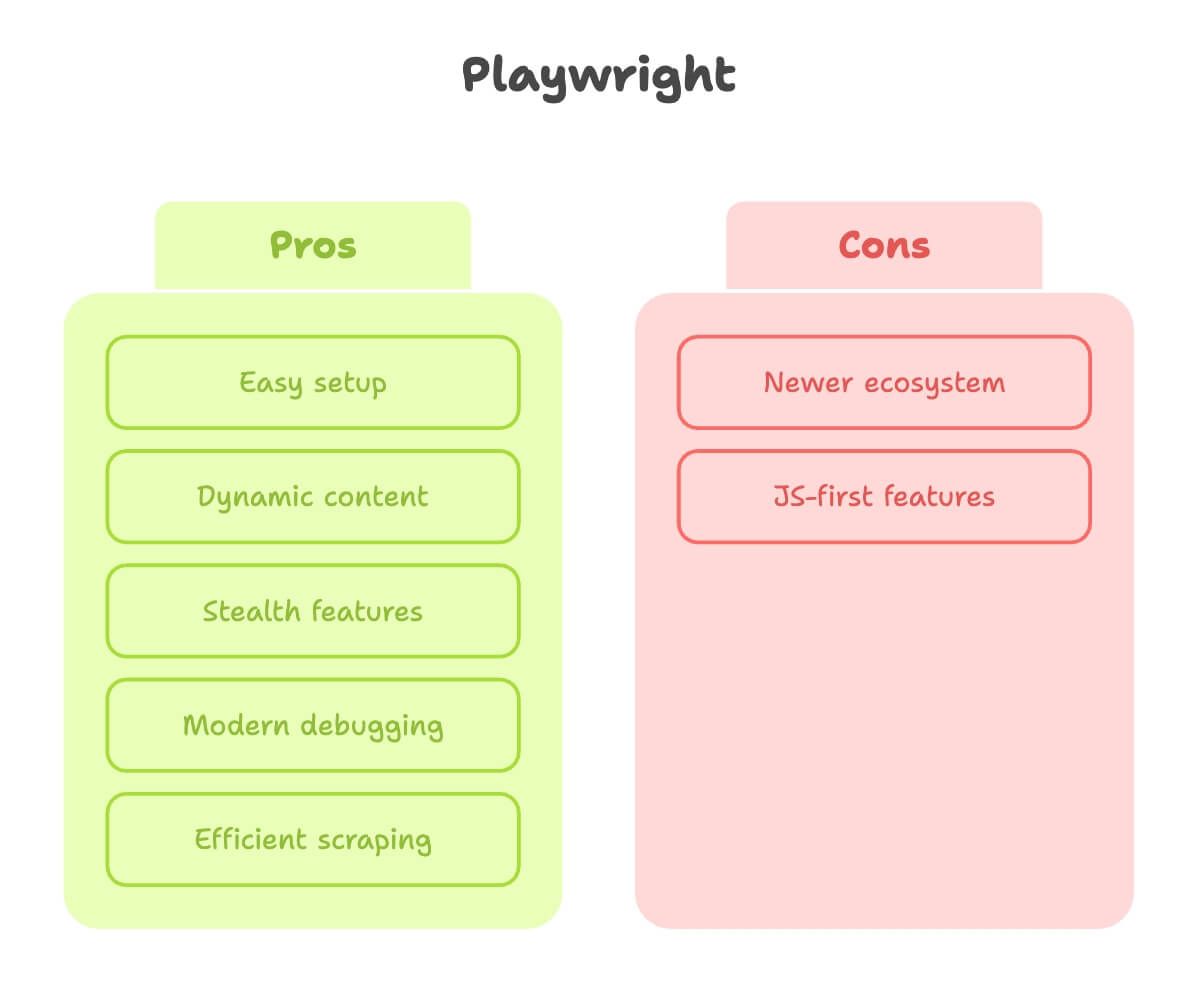
Now, let’s talk Playwright. As someone who’s spent a lot of time wrangling both tools, I can say Playwright feels like it was built by people who’ve actually suffered through web scraping.
Strengths:
- Easy setup: One pip install, one command, and you’re ready to go. No driver drama.
- Handles dynamic content: Auto-waits for elements, so you don’t have to guess when the page is ready (source).
- Stealth features: Mimics real users better, with built-in stealth mode and multi-context support (great for scraping as multiple “users” at once).
- Modern debugging: Inspector, video recording, and even code generation from your manual clicks.
- Faster and more efficient: Especially for scraping lots of pages or running in parallel.
Limitations:
- Newer ecosystem: Slightly fewer tutorials, though the gap is closing fast.
- Some features are JavaScript-first: Most things work in Python, but occasionally you’ll find a feature that’s better documented in JS.
Bottom line: Playwright is my go-to for any site that’s even a little bit dynamic, or when I want to get results fast without fighting with setup.
Anti-Bot Evasion: Which Python Scraper Handles Modern Websites Better?
Let’s address the elephant in the room: getting blocked. In web scraping, the hardest part isn’t writing code—it’s making sure the site doesn’t slam the door in your face.
- Selenium: Out of the box, it’s easier to detect. Websites can spot the
webdriverflag, headless user agents, and other telltale signs. There are workarounds (like undetected-chromedriver), but they require extra setup and are always playing catch-up with anti-bot tech (source). - Playwright: Has built-in stealth features, like automatically hiding automation fingerprints, supporting multiple browser contexts, and waiting for real user-like interactions. It’s not magic, but it’s less likely to get you blocked on your first try.
But here’s the truth: Neither tool is completely immune to anti-bot measures. For high-stakes scraping (think sneaker drops or ticketing sites), you’ll still need to use proxies, rotate IPs, and maybe even solve CAPTCHAs. Playwright just makes it a little less painful.
Developer Experience: Setup, Learning Curve, and Debugging
Let’s talk about the real experience of getting started—especially if you’re a beginner or just want to get the job done without a PhD in Python.
- Selenium:
- Setup: Install Python, install Selenium, download the right browser driver, put it in your PATH, pray you got the versions right. (I’ve seen more people stuck on the driver step than on actual scraping.)
- Learning curve: Lots of resources, but also lots of legacy code and outdated tutorials.
- Debugging: Mostly print statements and screenshots. Selenium IDE exists, but it’s basic.
- Playwright:
- Setup:
pip install playwright, thenplaywright install. Done. - Learning curve: Modern docs, lots of examples, and the API feels more “human”—you can select elements by text, role, or even placeholder.
- Debugging: Inspector lets you step through your script, watch the browser, and even record videos of your scraping runs (source).
- Setup:
If you want to see results quickly and spend less time on setup and troubleshooting, Playwright is the clear winner. Selenium is great if you’re already comfortable with its quirks or need its broad compatibility.
Step-by-Step: Building Your First Python Web Scraper with Playwright or Selenium
Let’s walk through what it actually looks like to build a scraper with each tool—no code, just the steps.
Playwright (Python):
- Install Playwright and browsers:
pip install playwright+playwright install - Launch browser: Start a Chromium, Firefox, or WebKit browser (headless or visible).
- Navigate to page: Use
page.goto("<https://example.com>") - Wait for content: Playwright auto-waits for elements to load.
- Extract data: Use human-friendly selectors (like
get_by_text,locator("span.price")). - Handle pagination or subpages: Loop through pages or click through links—Playwright makes it easy to run multiple pages in parallel.
- Export data: Save to CSV, Excel, or database.
- Debug: Use Inspector or video recording if things go sideways.
Selenium (Python):
- Install Selenium:
pip install selenium - Download browser driver: (e.g., ChromeDriver for Chrome), put it in your PATH.
- Launch browser: Start Chrome, Firefox, or another browser.
- Navigate to page:
driver.get("<https://example.com>") - Wait for content: Manually add explicit waits (
WebDriverWait) or, if you’re feeling lucky,time.sleep. - Extract data: Use
find_elementorfind_elements(CSS/XPath selectors). - Handle pagination or subpages: Loop through URLs or click buttons, but you’ll need to manage timing and navigation yourself.
- Export data: Save to CSV, Excel, or database.
- Debug: Mostly manual—watch the browser, print HTML, or take screenshots.
Notice the difference? Playwright is just a bit more “plug and play” for modern sites.
Beyond Coding: No-Code Web Scraping with Thunderbit AI Web Scraper
Scrape data from any website using AI Get Started Free
Now, let’s be real. Not everyone wants to become a Python guru just to get a table of product prices or a list of leads. Maybe you’re in sales, marketing, real estate, or operations, and you just want the data—now. That’s where Thunderbit comes in.
As the co-founder of Thunderbit, I’ve seen firsthand how many business users just want to skip the coding and get to the good stuff. So we built an AI-powered Chrome extension that lets you scrape any website in two clicks—no Python, no drivers, no debugging.
How Thunderbit Works
- Go to the website you want to scrape.
- Click “AI Suggest Fields.” Thunderbit’s AI scans the page and recommends the data fields (like product name, price, image, rating).
- Click “Scrape.” Instantly, you get a structured table of data.
- Export to Excel, Google Sheets, Airtable, Notion, CSV, or JSON. Done.
No fiddling with selectors, no trial-and-error, no code. It’s as easy as ordering takeout (and, let’s be honest, probably faster than waiting for your food to arrive).
Try Thunderbit AI Web Scraper for Free
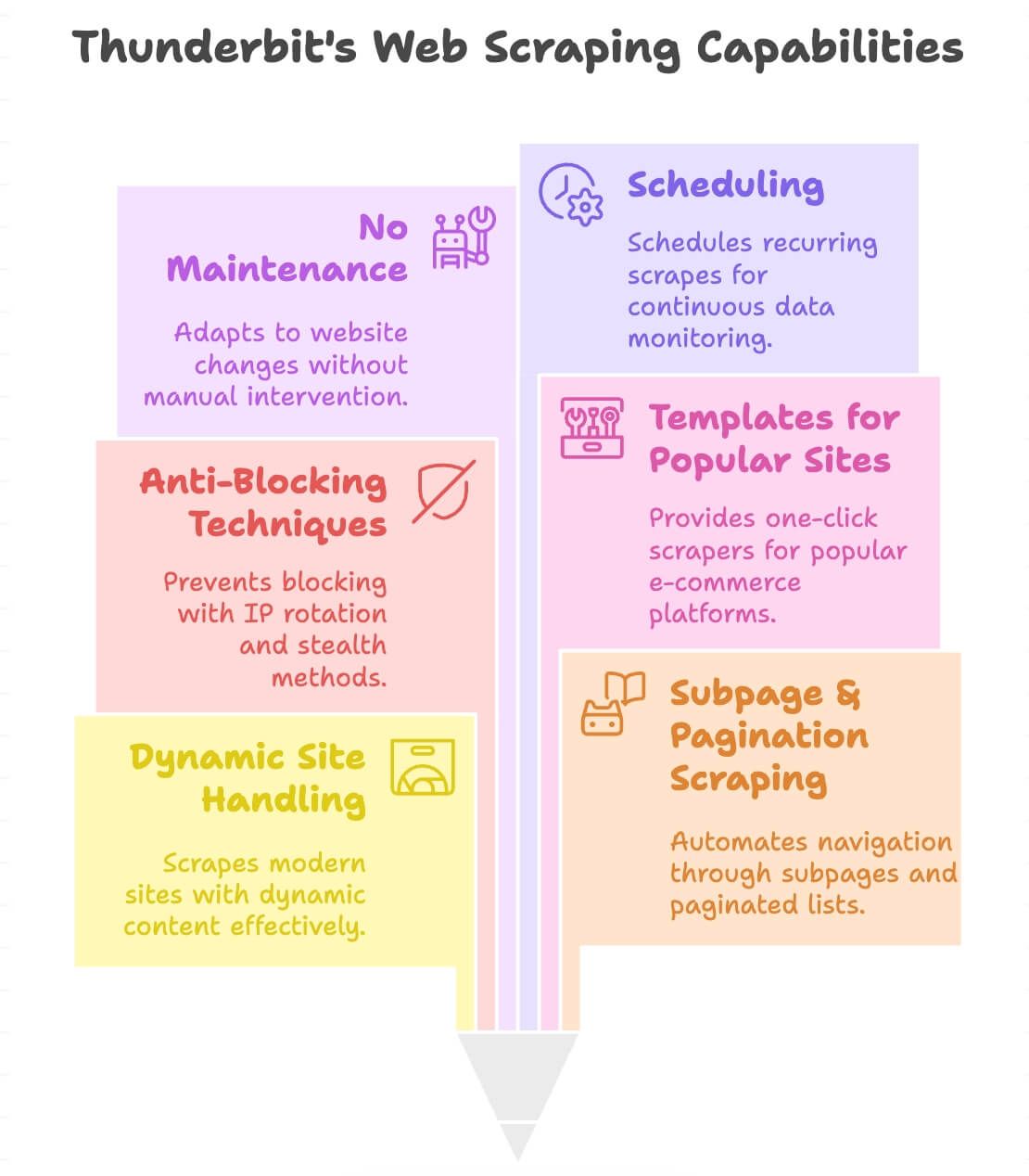
What Makes Thunderbit Different?
- Handles dynamic sites: Scrapes modern e-commerce, directories, and even sites with infinite scroll or pop-ups.
- Subpage & pagination scraping: Automatically clicks through product pages or paginated lists to get all the data you need.
- Anti-blocking built in: Uses backend IP rotation and stealth techniques, so you’re less likely to get blocked.
- Templates for popular sites: One-click scrapers for Amazon, eBay, Shopify, Zillow, and more (see our blog for details).
- Lower maintenance: When a site's layout shifts, the "AI Suggest Fields" pass can usually re-detect the fields, so you often re-run the suggest step instead of rebuilding a selector script from scratch.
- Scheduling: Set up recurring scrapes for ongoing monitoring (e.g., daily price checks).
- Supports 55 languages: Scrape and translate data from almost anywhere.
And the best part? You don’t need to know anything about HTML, CSS, or Python. If you can use a browser, you can use Thunderbit.
Which Web Scraping Solution Is Right for You?
Let’s wrap it up with a quick decision guide:
| Your Situation | Best Tool |
|---|---|
| Scraping a static, simple website; don’t mind setup | Selenium |
| Scraping a modern, dynamic site; want fast results | Playwright |
| Need to support legacy browsers or languages | Selenium |
| Want easy setup, modern debugging, and less code | Playwright |
| Not a developer; want data now, no code, no setup | Thunderbit |
| Need to scrape multiple pages, subpages, or schedule jobs | Thunderbit |
| Want to export directly to Excel, Sheets, Notion, Airtable | Thunderbit |
| Hate debugging Python errors | Thunderbit |
If you’re a developer, or you love tinkering with code, Playwright and Selenium are both powerful options. But if your goal is to get data into a spreadsheet as quickly as possible, Thunderbit is going to save you hours—maybe even days—of work.
Get Started with Thunderbit AI Web Scraper
Conclusion: Fast, Reliable Web Scraping—Your Way
Web scraping has gone mainstream, and for good reason: businesses need data to compete, and they need it now. Playwright and Selenium have both evolved from humble testing tools to essential scraping frameworks, each with their own strengths. Selenium is the old reliable for static sites and legacy setups; Playwright is the modern, speedy choice for dynamic, interactive pages.
But here’s my honest advice, after years in SaaS, automation, and AI: If you’re not in this for the coding, don’t waste your time wrestling with drivers, selectors, and anti-bot tricks. With Thunderbit’s AI Web Scraper, you can go from “I need this data” to “here’s my Excel file” in minutes—not days.
So whether you’re a Python pro or a business user who just wants results, there’s a scraping solution that fits your needs—and your patience. Try them out, see what works for your workflow, and remember: the best scraper is the one that gets you the data you need, with the least amount of hassle.
And if you ever find yourself debugging a Selenium driver error at 2am, just know—Thunderbit will still be here, ready to scrape in two clicks. Happy scraping.
Want to learn more about no-code scraping, AI-powered data extraction, and how Thunderbit can help your team? Check out our blog, or get started with the Thunderbit Chrome Extension today.
P.S. If you’re still not sure which tool to use, or you want to see Thunderbit in action, drop by our YouTube channel for demos, tips, and the occasional web scraping joke. (Yes, we have those.)
Further Reading:
- What Is Data Scraping and How to Do It in 2025
- How To Scrape Amazon Products and Reviews in 2025 using AI
- The Best Web Scraping Tools & Software in 2025
Try AI Web Scraper Get Started Free




