Let me tell you, if I had a dollar for every time someone sent me a PDF packed with “important data” and expected me to magically turn it into a spreadsheet, I’d probably have enough to buy a lifetime supply of coffee (and maybe a few extra Chrome extensions). PDFs are everywhere—sales contracts, product catalogs, research papers, invoices, you name it. But when it comes to actually using the data inside those files? Well, that’s where the fun (read: headaches) begin.
I’ve been in the trenches—copying, pasting, reformatting, and sometimes just plain giving up when the formatting goes haywire or the images and links vanish into thin air. But here’s the good news: the world of PDF scraping has changed dramatically, especially with the rise of AI-powered tools. If you’re tired of spending hours re-keying numbers or losing your mind over broken tables, you’re in the right place. Let’s dive into the world of PDF scraping, why it matters, and how tools like are making it (finally) painless.
What is PDF Scraping? Understanding the Basics of PDF Data Extraction
Let’s start simple: PDF scraping is just a fancy way of saying “getting structured data out of PDF files—automatically.” A PDF scraper is a tool (software, extension, or service) that pulls out the stuff you care about—text, tables, images, links, you name it—and puts it into a format you can actually use, like Excel, Google Sheets, or a database.
But here’s the catch: PDFs aren’t like web pages or Excel files. They’re more like digital printouts, designed to look the same everywhere, not to be easily picked apart by a computer. Some PDFs have selectable text, others are just scanned images (which need OCR—optical character recognition), and the formatting can be all over the place. So, scraping a PDF isn’t just about copying text—it’s about decoding a jigsaw puzzle of layouts, fonts, and sometimes even hidden metadata.
What can you extract from a PDF?
- Plain text (paragraphs, headings, etc.)
- Tables (think: financials, product specs, survey data)
- Images and graphics (charts, logos, scanned signatures)
- Hyperlinks and references (embedded URLs, citations)
- Form data (fields from fillable forms)
- Metadata (author, title, creation date, tags)
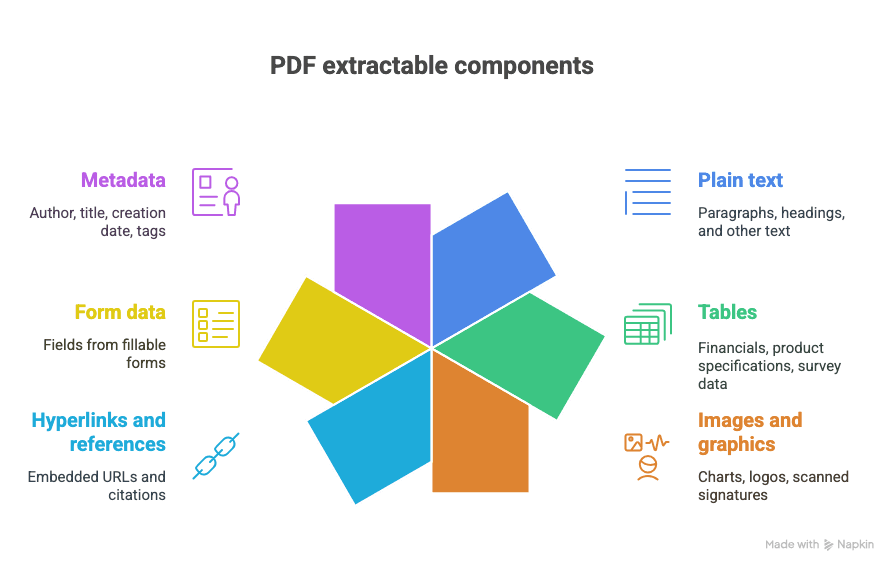
And yes, sometimes all of these are jumbled together in one glorious, chaotic document.
Why PDF Scraping Matters: Real-World Use Cases and Business Benefits
So, why bother scraping PDFs? Because everyone uses them, and the data inside is often critical for business. Here’s where PDF scraping shines:
| Use Case | Manual Effort | With PDF Scraper | Time & Error Savings |
|---|---|---|---|
| Sales Lead Extraction | Hours copying contacts from proposals or event PDFs, risk of missing leads | Instantly pulls all leads into a spreadsheet | 80–90% faster, fewer mistakes |
| E-commerce Product Data | Days entering product specs from supplier PDFs, formatting nightmares | Bulk extraction into CSV or Sheets | 95%+ time saved, consistent data |
| Research Data Analysis | Weeks transcribing tables from academic papers, high risk of typos | Extracts tables, references, and even scanned text | 80% time saved, higher accuracy |
Let’s put some numbers on it:
- are created every year.
- use PDF as a primary format for sharing info.
- Manual digital admin (like PDF data entry) eats up .
- Automated tools can reduce error rates from .
If you’re in sales, e-commerce, or research, automating PDF data extraction isn’t just a nice-to-have—it’s a competitive edge.
Traditional PDF Scraping Methods: Challenges and Limitations
Let’s be honest: the old ways of getting data out of PDFs are… not great. Here’s what most of us have tried (and why it’s so frustrating):

1. Manual Copy-Paste
- Pain points: Formatting gets mangled, tables turn into a mess, images and links disappear, and you’re left with a migraine.
- Labor cost: High. If you have 5,000 PDFs, even at 1 minute each, that’s 80+ hours of your life you’ll never get back.
- Error rate: 5–10%. Typos, missed rows, accidental deletions—been there, done that.
2. Convert to Word/Excel, Then Clean Up
- Pain points: Sometimes works for simple docs, but complex layouts or tables get scrambled. You still have to clean up the mess.
- Images/links: Usually lost in translation.
- Targeted extraction: Forget it—you get the whole document, not just what you need.
3. Custom Scripts (Python, etc.)
- Pain points: You need to be a coder (or have one on speed dial). Every new PDF format means tweaking the script. Scanned PDFs? Good luck.
- Maintenance: High. Every time a vendor changes their invoice template, your script breaks.
- Scalability: Not for the faint of heart (or the non-technical).
4. Online Converters
- Pain points: Easy for one-off jobs, but you have to upload sensitive docs to a third-party server (hello, compliance issues). Limited control over what gets extracted.
- Formatting: Hit-or-miss. You might spend more time cleaning up than you saved.
Bottom line: Traditional methods are slow, error-prone, and don’t scale. That’s why so many teams just “live with it”—but at a huge productivity cost.
Modern Solutions for PDF Scraping: From Code to No-Code Tools
Thankfully, we’re not stuck in the dark ages anymore. The landscape has exploded with smarter, faster, and more user-friendly PDF scraping options.
1. Coding Libraries (For Developers)
- Examples: , , .
- Strengths: Super flexible, can be automated for large batches, free (open source).
- Weaknesses: High setup time, requires programming skills, brittle (breaks with new formats), limited OCR/image support.
2. Online PDF Converters
- Examples: , , .
- Strengths: Zero setup, easy for non-techies, quick for small jobs.
- Weaknesses: Limited customization, privacy concerns, formatting errors, file size/page limits.
3. AI-Powered PDF Scrapers
- Examples: , Nanonets, Docparser.
- Strengths: No coding needed, handles text/tables/images/links, AI suggests what to extract, supports batch jobs, integrates with Sheets/Notion/Airtable.
- Weaknesses: Some have credit/page limits, may need internet connection, occasional learning curve for complex docs.
Comparing PDF Scraping Tools: Which Approach Fits Your Needs?
| Tool/Method | Setup | Best For | Extracts | Customizable? | Cost |
|---|---|---|---|---|---|
| Tabula (Tabula-py) | Moderate (UI/coding) | Tables in PDFs | Tables | Somewhat | Free |
| PDFMiner | Coding required | Text-heavy PDFs | Text | Yes (code) | Free |
| PyPDF2 | Coding required | Simple text/metadata | Text, metadata | Yes (code) | Free |
| Smallpdf/Online Conv. | None (web-based) | Quick conversions | Whole doc (Word/Excel) | No | Freemium |
| Thunderbit | 2-click install | Business users, teams | Text, tables, images, links | Yes (AI prompts) | Freemium ($16.5/mo for Pro) |
Meet Thunderbit: The AI PDF Scraper Chrome Extension
Now, let’s talk about the tool that’s made my life (and a lot of business users’ lives) so much easier: .
What makes Thunderbit different?
- 2-click extraction: Open a PDF in Chrome, click the Thunderbit extension, and let AI do the rest.
- AI-driven field suggestions: Thunderbit’s “AI Suggest Fields” reads your PDF and recommends the columns you probably want (like “Name,” “Email,” “Price,” etc.).
- Handles images, links, and tables: Not just plain text—Thunderbit can pull out images, hyperlinks, and even run OCR on scanned docs.
- Custom prompts: Need only phone numbers or product specs? Add a custom instruction and Thunderbit will focus on just that.
- Exports everywhere: Send your data straight to Excel, Google Sheets, Airtable, or Notion. No more CSV gymnastics.
- Batch and subpage scraping: Got a list of PDFs or links? Thunderbit can process them all in one go.
- Business-grade reliability: Designed for accuracy, privacy, and real-world workflows.
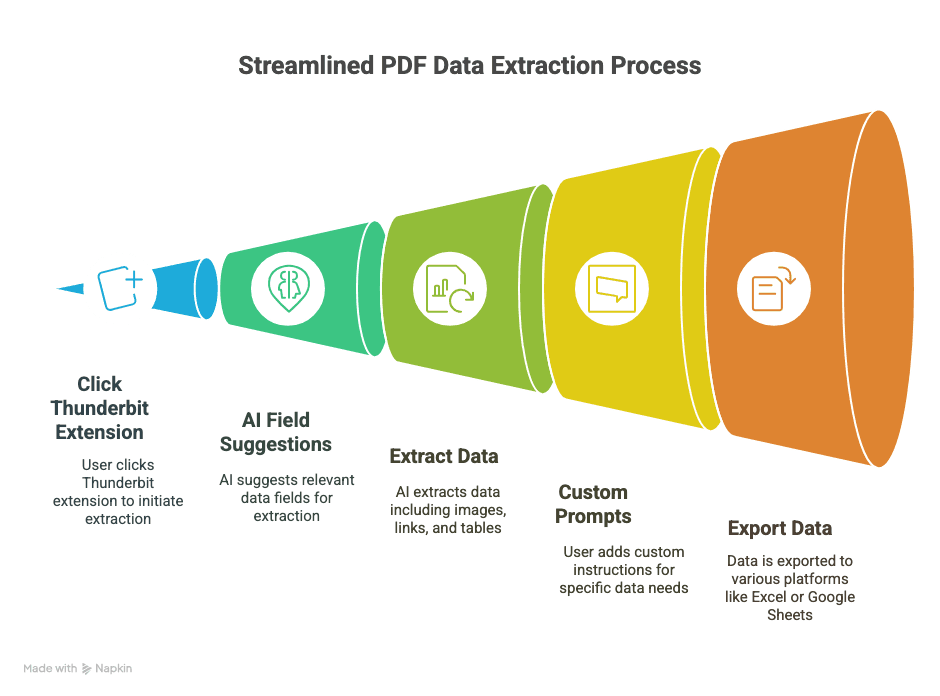
In short, it’s like having a digital intern who actually likes doing data entry (and never gets tired).
How to Scrape Data from a PDF Using Thunderbit: Step-by-Step Guide
Ready to see how easy it can be? Here’s how I use Thunderbit to turn PDFs into structured, usable data:
1. Install Thunderbit
- Grab the .
- Sign up (Google account or email—takes seconds).
2. Open Your PDF in Chrome
- Either open a PDF from a web link or drag a local PDF into a Chrome tab.
3. Launch Thunderbit on the PDF
- Click the Thunderbit icon in your browser toolbar.
- Select “AI Web Scraper”—Thunderbit will detect the PDF and get ready to work.
4. Let AI Suggest Fields
- Click “AI Suggest Columns.”
- Thunderbit’s AI scans the PDF and recommends columns (like “Date,” “Amount,” “Contact Name,” etc.).
- Preview the extracted data in a table right inside the extension.
5. Customize (If Needed)
- Rename columns, delete extras, or add your own (e.g., “Warranty Term” or “Product URL”).
- For tricky data, select text in the PDF to train the AI on what you want.
6. Choose Your Export Format
- Pick from CSV, Google Sheets, Airtable, or Notion.
- Authorize Thunderbit to connect (one-time setup).
7. Scrape and Export
- Hit “Scrape” or “Export.”
- Thunderbit processes the PDF and sends the data where you want it—usually in seconds.
That’s it. No coding, no copy-paste, no drama.
Tips for Accurate PDF Data Extraction with Thunderbit
- Review AI-suggested fields: The AI is smart, but a quick glance ensures you’re getting exactly what you need.
- Handle complex tables: For multi-page or weirdly formatted tables, use the preview to spot issues and adjust columns as needed.
- Extract images/links: Make sure to include these fields if your PDF has them—Thunderbit can grab them too.
- Scanned PDFs: Thunderbit’s built-in OCR is solid, but the cleaner the scan, the better the results.
- Custom prompts: Want only emails or phone numbers? Add a prompt like “Extract all email addresses” and Thunderbit will focus on those.
Advanced PDF Scraping: Extracting Images, Links, and Custom Data
Thunderbit isn’t just about plain text. Here’s how you can get even more out of your PDFs:
- Images: Extract logos, charts, or any embedded graphics. Thunderbit can even OCR text inside images.
- Hyperlinks: Pull out all URLs or references—great for research papers or resumes.
- Custom data types: Use AI prompts to extract just what you need (e.g., “Find all product SKUs and their prices”).
- Summaries and categorization: Add a column and ask Thunderbit to summarize a section or categorize data on the fly.
Parsing Data from PDF for Specific Business Needs
- Sales: Extract only contact info from a batch of proposals.
- E-commerce: Pull product specs, prices, and images from supplier catalogs.
- Research: Grab tables, references, and even generate summaries from academic papers.
And once you have the data, structure it for easy analysis in Excel, Google Sheets, or Notion—Thunderbit does the heavy lifting, you just get to use the results.
Exporting and Using Your PDF Data: From Extraction to Action
Getting the data out is just the start. Here’s how to make it work for you:
- Export options: CSV, Excel, Google Sheets, Airtable, Notion—pick your favorite.
- Formatting tips: Use Thunderbit’s column type settings (number, date, text) for clean, analysis-ready data.
- Workflow integration: Connect your exported data to CRMs, inventory systems, or analytics dashboards.
- Collaboration: Share Google Sheets or Airtable bases with your team—everyone works from the same, up-to-date data.
The best part? No more emailing spreadsheets back and forth or wondering if you missed a row.
Common Pitfalls in PDF Scraping and How to Avoid Them
Even with the best tools, a few gotchas can pop up. Here’s what I’ve learned (sometimes the hard way):
- OCR errors: Blurry scans or weird fonts can trip up even the best OCR. Try to use the cleanest PDFs possible, and double-check critical fields.
- Complex layouts: Multi-column or nested tables might need a little manual guidance—use Thunderbit’s manual selection or prompts.
- Data types: Numbers with commas or dates in odd formats? Set the column type before exporting, or clean up in Excel/Sheets.
- File size/page limits: Huge PDFs? Split them into smaller chunks, or use Thunderbit’s cloud mode for batch jobs.
- AI “hallucination”: Rare, but sometimes AI might guess a column name or fill in missing data. Always spot-check the output, especially for important numbers.
- Manual review: For mission-critical data, do a quick validation—automated tools are accurate, but a human eye never hurts.
And if you hit a wall, Thunderbit’s support and community are there to help.
Conclusion & Key Takeaways: Making PDF Scraping Work for Your Business
Let’s wrap it up. Scraping data from PDFs used to be a nightmare—slow, error-prone, and just plain tedious. But with modern tools like , it’s now fast, accurate, and (dare I say) almost enjoyable.
Here’s what you get:
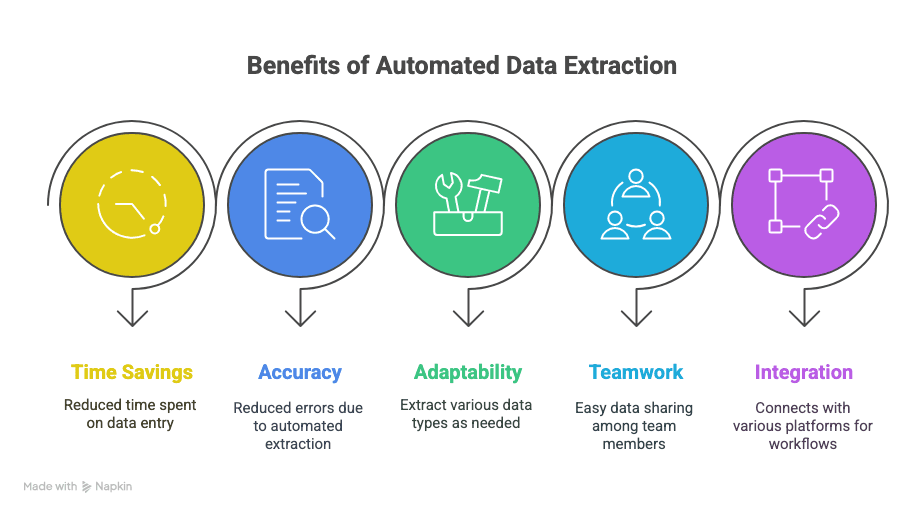
- Time back: Hours (or even weeks) saved on manual data entry.
- Fewer mistakes: Automated extraction means fewer typos and missed rows.
- Flexibility: Extract exactly what you need—text, tables, images, links, you name it.
- Collaboration: Share data instantly with your team, wherever they are.
- Smarter workflows: Integrate with Sheets, Notion, Airtable, and more.
Ready to try it out? Download the , run it on your next PDF, and see how much easier life can be. Your future self (and your carpal tunnel) will thank you.
For more tips and guides, check out the or dive deeper with .
Let’s turn those PDF headaches into productivity wins—one click at a time.
Shuai Guan, Co-founder & CEO, Thunderbit