

There’s a running joke among sales and ops folks: “I didn’t sign up for a career in copy-paste.” Yet, here we are—drowning in PDFs, web forms, invoices, and spreadsheets, all begging for someone to pull out the right nuggets of info and put them somewhere useful. I’ve seen it firsthand: teams burning hours (and brain cells) just to wrangle data from one place to another. And it’s not just a minor annoyance. Industry data backs this up: sales reps lose roughly 6 hours a week to manual data entry, and Docsumo's 2025 IDP market report found that automating document extraction can cut processing times by 50% or more and deliver a 30–200% ROI in the first year. That’s not just a little extra coffee break time—it’s a workflow revolution.
Try Thunderbit for AI-Powered Data Extraction Get Started Free
So, what’s the secret sauce? It’s called key information extraction (KIE), and it’s changing the way businesses handle data. In this post, I’ll break down what KIE really means, who needs it, how it works (without the jargon), and why tools like Thunderbit are making it easier than ever to turn document chaos into structured, actionable information. And yes, I’ll share some real-world stories, a few practical tips, and maybe even a dad joke or two—because if you can’t laugh at data entry, what can you laugh at?
What is Key Information Extraction? A Simple Guide to Key Value Pair Extraction
Let’s start with the basics. Key information extraction is all about automatically finding and pulling out the important details from documents, web pages, PDFs, emails, or even images, and turning them into structured, usable data. Think of it as teaching your computer to do what you’d do with a highlighter and a stack of forms—but way faster, and without the risk of getting a paper cut.
At the heart of KIE is something called key value pair extraction. This is where the magic happens: the software looks for “keys” (labels like “Company Name,” “Invoice Number,” or “Contact Email”) and grabs the corresponding “values” (like “Thunderbit,” “11897,” or “info@thunderbit.com”). It’s like filling out a spreadsheet, but the computer does the reading and typing for you.
For example, from a company registration page, a KIE tool might extract:
- Company Name: Thunderbit
- Contact Email: info@thunderbit.com
- Phone: +1-555-1234
This process is the backbone of document information extraction—a broader term that covers any method of pulling structured data out of unstructured or semi-structured content. Whether you’re dealing with a PDF invoice, a web directory, or a scanned contract, the goal is the same: turn messy, human-friendly content into machine-friendly tables.
Why does this matter? Because structured data is gold. It’s what lets you automate workflows, analyze trends, and make decisions—without spending your days copying and pasting.
Who Needs Key Information Extraction? Use Cases Across Teams
Honestly, just about every team that touches documents or web data can benefit from KIE. But let’s get specific. Here’s a quick rundown of who’s using it and why:
| Department/Function | Use Case for Key-Value Extraction | Problem Without Automation |
|---|---|---|
| Sales & Marketing | Lead capture from websites, event lists, emails | Manual CRM entry, delays, lost leads, typos |
| E-commerce Operations | Product data scraping (name, price, stock from competitor sites) | Outdated pricing, missed market changes, manual upkeep |
| Finance/Accounting | Invoice and receipt processing (vendor, date, amount) | Hours of typing, errors, payment issues, rework |
| HR & Recruiting | Resume parsing (name, skills, experience from CVs) | Slow hiring, inconsistent evaluations, missed details |
| Compliance & Legal | KYC checks, contract clause extraction | Tedious verification, risk of missing critical info |
Let’s be real: without automation, these teams are stuck in a loop of manual entry, slow follow-ups, and all the “oops” moments that come from human error. I’ve seen sales teams miss out on hot leads because the data wasn’t in the CRM fast enough, and finance teams spend days reconciling invoices that could have been processed in minutes.
And the pain is real. One real estate firm that automated lead capture saw a 35% increase in high-quality leads and cut data entry time by 30%. That’s not just a win for the bottom line—it’s a win for everyone’s sanity.
Why Key Information Extraction Matters for Workflow Efficiency
Let’s talk about the “why.” Automating document information extraction isn’t just about saving a few minutes—it’s about transforming the way your team works.
The Big Wins:
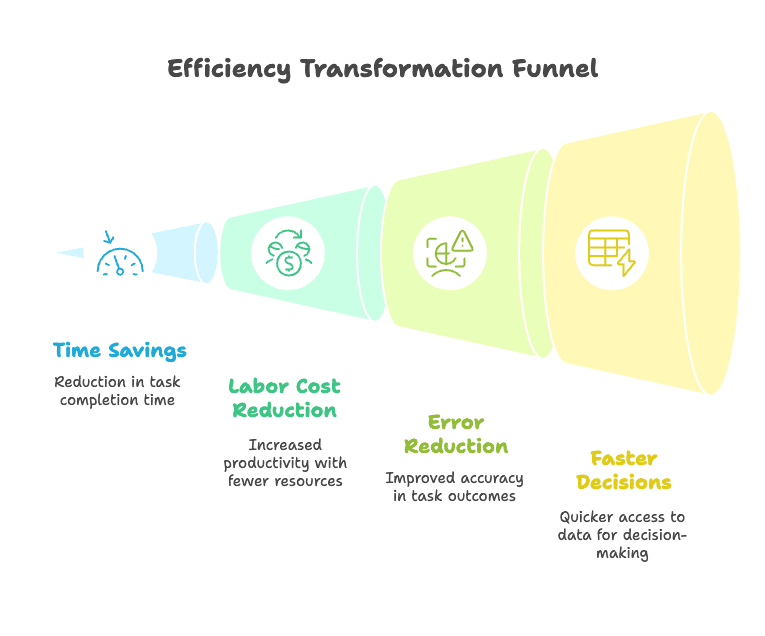
- Time Savings: Tasks that took hours or days now take minutes. One logistics company cut document handling time from over 7 minutes per file to under 30 seconds—a >90% reduction.
- Labor Cost Reduction: Teams can do more with less, or reallocate people to higher-value work. Some firms have seen 30–200% ROI in the first year.
- Error Reduction: Advanced extraction systems can hit 99%+ accuracy, and companies have seen error rates drop by over 52%.
- Faster Decisions: Data is available sooner, so teams can act quickly—whether that’s following up on a lead, adjusting prices, or paying an invoice.
Before-and-After: The Real Impact
Before automation: An insurance company’s claim approval might have taken two weeks, mostly due to data entry and verification.
After automation: Claims are processed in a day or two, because relevant data is extracted and verified by AI. Staff can approve faster, and customers get paid sooner. In some cases, claims processing times have dropped from weeks to minutes (source).
The bottom line? Key information extraction makes your processes faster, cheaper, and better. It’s not just about working harder—it’s about working smarter.
How Does Key Information Extraction Work? From OCR to AI-Powered Extraction
You don’t need to be a data scientist to understand how this works (thank goodness). Here’s the plain-English version of the typical workflow:
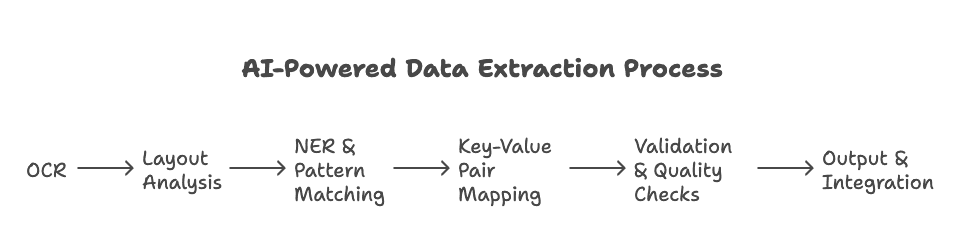
- OCR (Optical Character Recognition): For scanned documents or images, OCR turns pictures of text into actual text. Modern OCR, powered by AI, can even handle handwriting and messy scans (learn more).
- Layout Analysis: The system figures out where the keys and values are—like matching “Total Amount:” with “$5,000” on an invoice, even if the layout is weird or the fields are all over the place (details).
- Named Entity Recognition (NER) & Pattern Matching: AI looks for things like names, dates, amounts, or emails, using both learned patterns and rules (more).
- Key-Value Pair Mapping: The software pairs up the labels and the data, building a structured record (think: “Name” → “John Doe”).
- Validation & Quality Checks: Automated checks (and sometimes a quick human review) ensure the data is accurate.
- Output & Integration: The structured data is exported to Excel, Google Sheets, a database, or even directly into your CRM or ERP system (see how).
The Role of AI in Document Information Extraction
AI is the brains of the operation. It’s what lets these tools:
- Handle complex or unfamiliar layouts (no more “template broke because the field moved” headaches)
- Support multiple languages (Thunderbit, for example, supports 55 languages as of its May 2026 release)
Location 2 — under "1. Thunderbit: The Easiest AI Web Scraper..." bullet "Multi-language & Field Translation":
- Suggest fields automatically (like Thunderbit’s “AI Suggest Fields”)
- Clean, standardize, and even translate data on the fly
In other words, AI takes KIE from “maybe it works if everything is perfect” to “it just works, even when things get messy.”
4 Hot Tools for Key Information Extraction (And Why Thunderbit Leads)
There are plenty of tools out there, but not all are created equal. Here are four worth knowing about, with Thunderbit at the top (for good reason):
1. Thunderbit: The Easiest AI Web Scraper for Key Information Extraction
Thunderbit is an AI-powered Chrome extension that makes web and document data extraction accessible to everyone—no coding, no setup headaches. Here’s why I’m a fan:
- Automated Lead Data Capture: Instantly grab company, contact, email, and more from event pages, job boards, or company profiles—no manual collection needed.
- Smart Field Recognition & Standardization: Thunderbit’s AI identifies and formats fields like company name, email, phone, and even industry classification. It can standardize phone numbers, translate field names, and more.
- Handles Complex Structures: Need to scrape paginated lists, subpages (like each exhibitor’s profile at a trade show), or multi-page PDFs? Thunderbit’s got you covered.
- Multi-language & Field Translation: Supports 55 languages and can translate fields for global teams.
Location 3 — under "Overcoming Common Challenges..." bullet:
- No-Code, Instant Results: Click “AI Suggest Fields,” review the columns, and hit “Scrape.” Export to Excel, Google Sheets, Airtable, or Notion—no extra charge.
Let me walk you through a real-world scenario:
Scenario: You’re prepping a campaign targeting companies from a tech event. The event site lists exhibitors (with links to profile pages), and you’ve got a PDF brochure with more details.
- With Thunderbit, you open the exhibitors page, click “AI Suggest Columns,” and the AI suggests fields like Company Name, Industry, Website.
- Hit “Scrape,” and Thunderbit pulls in all the companies.
- Want more details from each profile? Use Subpage Scraping—Thunderbit visits each link, grabs emails, phones, and appends them to your table.
- Got a PDF? Open it in Chrome, use Thunderbit’s PDF parser, and extract tables or text.
- Export everything to Google Sheets, ready for your campaign.
Total time: maybe 10–15 minutes. No coding, no copy-paste, no headaches.
Thunderbit stands out for its AI-driven ease of use, breadth of features, and focus on web-based data extraction. It’s built for business users in sales, marketing, e-commerce, real estate, and more. And with features like scheduled scraping (just describe when you want it to run), it can keep your data fresh automatically.
Want to see it in action? Check out the Thunderbit Chrome Extension or browse the Thunderbit Blog for more use cases.
Try Thunderbit for Key Information Extraction
2. Kili Technology
 Kili Technology is all about custom AI for complex documents. If you have highly specialized forms or need to train a model for your unique use case (think: insurance claims, ID documents across countries), Kili lets you label data, train models, and build your own extractor. It’s powerful, but best suited for organizations with machine learning expertise and lots of variability in their documents.
Kili Technology is all about custom AI for complex documents. If you have highly specialized forms or need to train a model for your unique use case (think: insurance claims, ID documents across countries), Kili lets you label data, train models, and build your own extractor. It’s powerful, but best suited for organizations with machine learning expertise and lots of variability in their documents.
3. Klippa DocHorizon
 Klippa DocHorizon is an all-in-one document processing platform with strong OCR and AI. It’s especially popular for finance and accounting (invoices, receipts, contracts, IDs), and offers APIs for integration. Klippa can process a wide variety of document types out-of-the-box, with high accuracy and flexible export options (JSON, XML, Excel, etc.). It’s a great fit for companies automating back-office tasks at scale.
Klippa DocHorizon is an all-in-one document processing platform with strong OCR and AI. It’s especially popular for finance and accounting (invoices, receipts, contracts, IDs), and offers APIs for integration. Klippa can process a wide variety of document types out-of-the-box, with high accuracy and flexible export options (JSON, XML, Excel, etc.). It’s a great fit for companies automating back-office tasks at scale.
4. Rossum
 Rossum is an AI platform for high-volume document processing, especially in accounts payable and logistics. It combines AI extraction with a human-in-the-loop validation UI, so you can process thousands of documents with high accuracy and minimal manual effort. Rossum is ideal for enterprises looking for end-to-end automation with robust quality control.
Rossum is an AI platform for high-volume document processing, especially in accounts payable and logistics. It combines AI extraction with a human-in-the-loop validation UI, so you can process thousands of documents with high accuracy and minimal manual effort. Rossum is ideal for enterprises looking for end-to-end automation with robust quality control.
Overcoming Common Challenges in Key Information Extraction
Even the best tools face some hurdles. Here’s what I’ve seen, and how modern solutions (especially Thunderbit) address them:
- Document/Layout Variability: AI-based extractors learn patterns, not positions. Thunderbit’s “AI Suggest Fields” adapts to new layouts without manual reconfiguration.
- Language Barriers: Multilingual OCR and translation features (Thunderbit supports 55 languages) mean you can extract from global sources.
- Data Quality: Built-in normalization and field prompts help clean and standardize data as it’s extracted.
- Integration: Direct exports to Google Sheets, Airtable, Notion, or APIs mean your data flows right into your workflow.
- Privacy & Compliance: Choose tools with strong security, encryption, and compliance features. Only extract and store what you need.
- User Adoption: The easier the tool, the faster your team will embrace it. Thunderbit’s two-click workflow is a big win here.
Tips for Best Results:
- Use AI field suggestions and prompts to fine-tune extraction.
- Regularly review and update your extraction templates.
- Leverage translation features for multi-language data.
- Document your process and keep humans in the loop for quality control.
Step-by-Step: How to Use Key Information Extraction in Your Workflow
Ready to get started? Here’s a simple, actionable process:
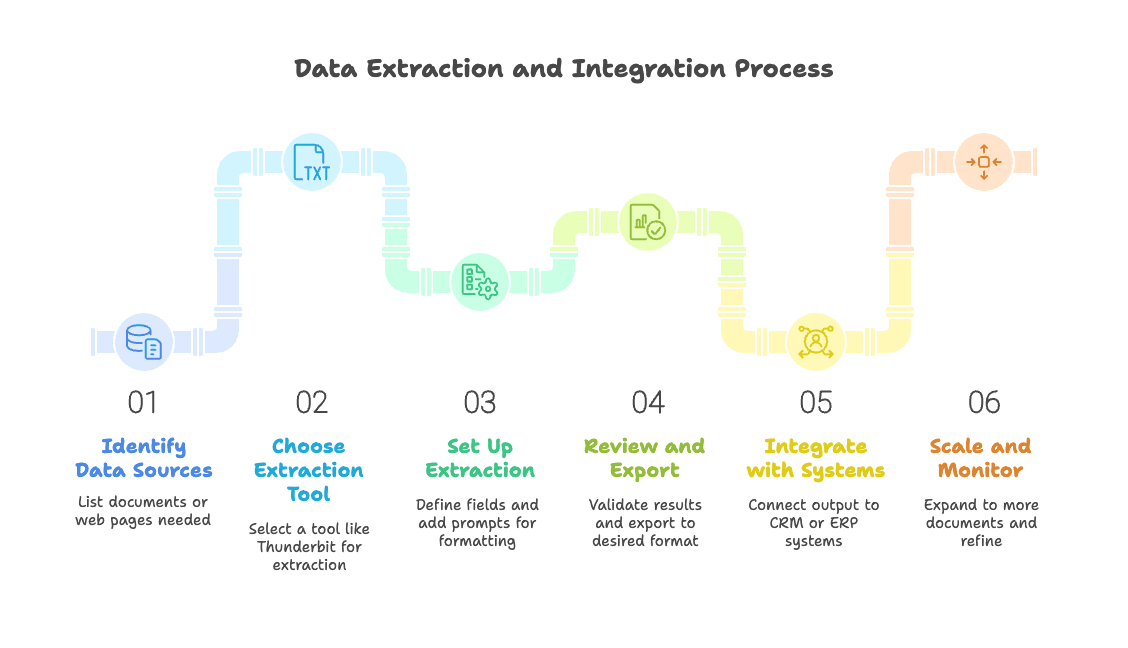
- Identify Your Sources: List the documents or web pages you need data from. Prioritize high-impact use cases.
- Choose a Tool: For web and document extraction with minimal setup, Thunderbit is a great choice. Test a few tools if you have unique needs.
- Set Up Extraction: Use AI suggestions to define fields. Adjust as needed, and add prompts for special formatting or translation.
- Review & Export: Run a test extraction, validate the results, and export to Excel, Google Sheets, Airtable, or Notion.
- Integrate: Connect your output to your CRM, ERP, or other systems. Use scheduling features for recurring tasks.
- Scale & Monitor: Roll out to more documents or pages. Spot-check outputs and refine as you go.
Quick Checklist:
- ✔ Define info needed and sources
- ✔ Pick the right tool
- ✔ Set up fields (use AI suggestions)
- ✔ Test and validate extraction
- ✔ Export/integrate with your workflow
- ✔ Monitor and refine regularly
Key Value Pair Extraction in Action: Real-World Examples
Let’s bring this to life with a few quick stories:
Example 1: Sales Lead Generation from Events
Before: Sales coordinators spent a full day copying attendee info from event lists into the CRM. By the time leads were ready, the event “heat” was gone.
After: With Thunderbit, the coordinator extracts all relevant fields from the event page or PDF in about 10 minutes. Leads are in the CRM same-day, and the team saw a 20% increase in conversion rate.
Example 2: E-commerce Price Monitoring
Before: An intern spent hours each week checking competitor prices for 100 products, often missing updates.
After: The manager sets up Thunderbit to scrape competitor pages nightly. Data lands in Google Sheets, and price changes are flagged automatically. The company reacts faster and stays competitive, with weekly hours saved reallocated to analysis.
Example 3: Invoice Processing in Finance
Before: AP clerks manually entered invoice data, taking 5–10 minutes per invoice and making errors.
After: An AI-driven tool (like Rossum or Doxis AI.dp) extracts all fields with up to 99% accuracy. Processing time drops by 50% or more, and errors become rare.
Best Practices for Document Information Extraction Success
Here’s what I’ve learned (sometimes the hard way):
- Leverage AI Suggestions: Use features like Thunderbit’s “AI Suggest Columns” to save time and catch fields you might miss.
- Keep Templates Updated: Websites and forms change—review your extraction settings regularly.
- Use Multi-Language Features: Standardize field names and values across languages for global teams.
- Integrate & Automate: Export directly to the tools your team already uses. Automate recurring tasks.
- Ensure Privacy & Compliance: Only extract what you need, secure your data, and follow regulations.
- Keep Humans in the Loop: Periodically review outputs for quality, especially for critical data.
- Document Your Process: Keep notes on what you’re extracting, how, and where it goes.
- Stay Updated: Follow your tool’s updates—new features can make your life even easier.
Conclusion: Unlock Workflow Efficiency with Key Information Extraction
Learn More About Data Scraping with AI Get Started Free
In today’s business world, time and accuracy are the new currency. Automating key information extraction isn’t just a nice-to-have—it’s a must for teams that want to move fast, stay competitive, and avoid the dreaded copy-paste burnout. From sales to finance to HR, the benefits are clear: faster processes, fewer errors, and more time for the work that actually matters.
AI-powered tools like Thunderbit are leading the way, making extraction accessible to everyone—no coding, no headaches, just results. Whether you’re scraping leads from a website, pulling data from a PDF, or keeping tabs on competitors, KIE can transform your workflow.
So, here’s my challenge: pick one process in your org that’s bogged down by manual data entry. Try key information extraction—maybe with Thunderbit’s free tier—and see the difference for yourself. The time you save, the errors you avoid, and the insights you unlock might just make you wonder how you ever lived without it.
And if you ever find yourself missing the old days of copy-paste, don’t worry—I hear there’s a support group for that. They meet on spreadsheets every Friday.
Want to learn more?
- Thunderbit Blog
- What Is Data Scraping and How to Do It
- How to Scrape Website Data into Excel using AI
- Thunderbit Chrome Extension Download Page
Ready to unlock your workflow efficiency? Let’s get extracting.
Try Thunderbit AI Web Scraper for Free Get Started Free
FAQs
1. What is key information extraction (KIE) and why is it important?
Key information extraction (KIE) is the automated process of identifying and pulling specific, valuable data—like names, emails, invoice totals, or product details—from unstructured sources such as PDFs, emails, web pages, or scanned documents. It’s crucial for turning messy, human-readable content into clean, structured data that can drive automation, analytics, and faster decision-making.
2. Which teams benefit the most from KIE tools?
KIE benefits a wide range of teams, including sales and marketing (for lead capture), e-commerce (for price tracking), finance (for invoice processing), HR (for resume parsing), and legal/compliance (for document verification). Any role that involves repetitive data entry from documents can see major time and accuracy gains.
3. How does key-value pair extraction work?
Key-value pair extraction identifies "keys" (like “Invoice Number” or “Company Name”) and matches them with their corresponding "values" (like “#93843” or “Thunderbit”). The process uses AI-powered OCR, layout analysis, named entity recognition (NER), and pattern matching to map and export the data in a structured format like spreadsheets or CRM databases.
4. What makes Thunderbit stand out among KIE tools?
Thunderbit combines AI-powered field recognition, multi-language support, PDF parsing, subpage scraping, and one-click field suggestions into an easy-to-use Chrome extension. It’s designed for non-coders and supports export to tools like Google Sheets, Airtable, and Notion. It’s especially strong in web-based lead generation, event scraping, and structured data capture at scale.
5. What are some real-world examples of KIE in action?
- Sales teams use Thunderbit to scrape lead data from event pages and upload it to CRMs in minutes.
- E-commerce managers automate competitor price monitoring from websites.
- Finance departments process invoices in under 30 seconds using AI extraction, reducing errors and saving hours weekly.
These examples show how KIE can transform slow, error-prone manual processes into efficient, reliable workflows.




