Let me tell you a little secret: the web is basically the world’s biggest library, but most of the books are glued shut. Every day, I talk to business owners, marketers, and sales teams who know there’s gold in those web pages—product specs, competitor prices, customer reviews, contact info—but getting that text out? That’s where things get sticky. I’ve been in the SaaS and automation trenches for years, and I’ve seen every “copy-paste marathon” and “DIY Python adventure” you can imagine. The good news? Extracting text from a website is easier (and way less painful) than ever, thanks to new AI web scraper tools and smarter browser extensions.
In this guide, I’ll walk you through every practical method I know—from the humble copy-paste to advanced AI-powered solutions like (yes, that’s my team’s baby, but I’ll keep it real about the pros and cons). Whether you’re a spreadsheet wizard, a code-slinging developer, or just someone who’s tired of squinting at web pages, you’ll find a step-by-step approach that fits your needs. Let’s crack open those digital books and get you the text you need.
What Does It Mean to Extract Text from a Website?
When we talk about “extracting text from a website,” we’re really talking about pulling out the information you see (and sometimes don’t see) on a web page and getting it into a format you can use—like a spreadsheet, a database, or even just a clean Word doc. But not all website text is created equal:
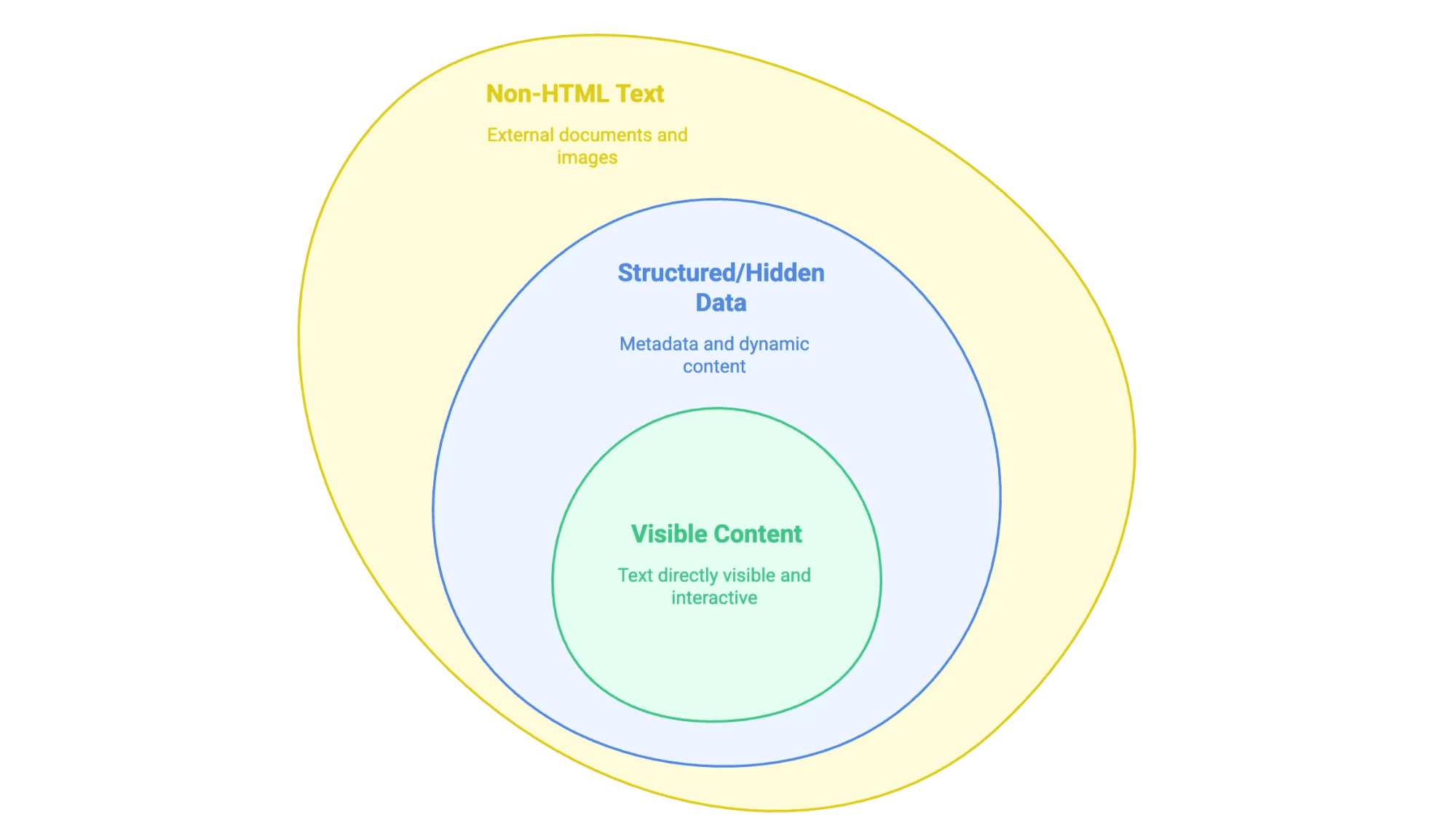
- Visible Content: This is the stuff you can highlight with your mouse—body text, headings, lists, tables, product descriptions, blog posts, etc.
- Structured or Hidden Data: Think metadata in
<meta>tags, JSON-LD scripts, or info loaded by JavaScript that doesn’t show up until you click or scroll. - Non-HTML Text: PDFs, Word docs, and even images with text (like scanned contracts or infographics) that are linked or embedded on the site.
The trick is knowing which type you’re after, because each one calls for a different extraction approach.
Why Extract Text from a Website? Business Benefits and Use Cases
Let’s be honest: nobody’s extracting text from websites just for fun (unless you’re into really weird hobbies). Businesses do it because the ROI is real. The web scraping software market topped , and it’s only getting bigger. Here’s why:
| Team | Use Case Example | Benefit |
|---|---|---|
| Sales | Scrape directories for leads & contact info | Faster, richer prospecting |
| Marketing | Extract competitor blog posts & SEO data | Content gap analysis, trend spotting |
| Operations | Monitor product prices across e-commerce sites | Dynamic pricing, stock tracking |
| Real Estate | Aggregate listings & property details | Market analysis, lead generation |
| Support | Collect customer reviews & forum Q&A | Sentiment analysis, early issue detection |
A few real-world wins:

- Lead Generation: One restaurant supply business in minutes instead of days.
- Competitor Monitoring: Retailers like John Lewis using scraped pricing data.
- SEO Analysis: Teams extract meta tags and keywords to .
And with AI-driven tools, companies are saving compared to old-school methods.
Manual Methods: The Basics of Copying and Pasting Website Text
Let’s start with the basics. Sometimes, you just need to grab a quick snippet—no fancy tools required.
How to Manually Extract Text
- Copy and Paste: Open the page, highlight the text, and hit Ctrl+C (or right-click > Copy). Then paste it into your doc or spreadsheet.
- Save Page As: In your browser, go to File > Save Page As. Save as “Webpage, HTML only” to get the raw HTML, or sometimes as .txt for just the text.
- Print to PDF: Use your browser’s print dialog to “Save as PDF.” Then open the PDF and copy the text (or use a PDF reader’s “Save as Text” feature).
- Developer Tools: Right-click > Inspect or press F12 to open DevTools. You can view the HTML source, find meta tags or hidden JSON, and copy what you need.
Limitations
Manual extraction is fine for one-offs, but it’s a nightmare for anything bigger. It’s . Trust me, I’ve seen interns spend days copying tables row by row—nobody wants that job.
Using Browser Extensions and Online Tools to Extract Text from Websites
Ready to level up? Browser extensions and online tools are the sweet spot for most business users: no code, no drama, just point and click.
Why Use These Tools?

- Faster than manual copy-paste
- No programming required
- Can handle tables, lists, and sometimes even files
- Export to Excel, Google Sheets, CSV, etc.
Let’s break down the most popular options.
Thunderbit: AI Web Scraper for Fast, Accurate Text Extraction
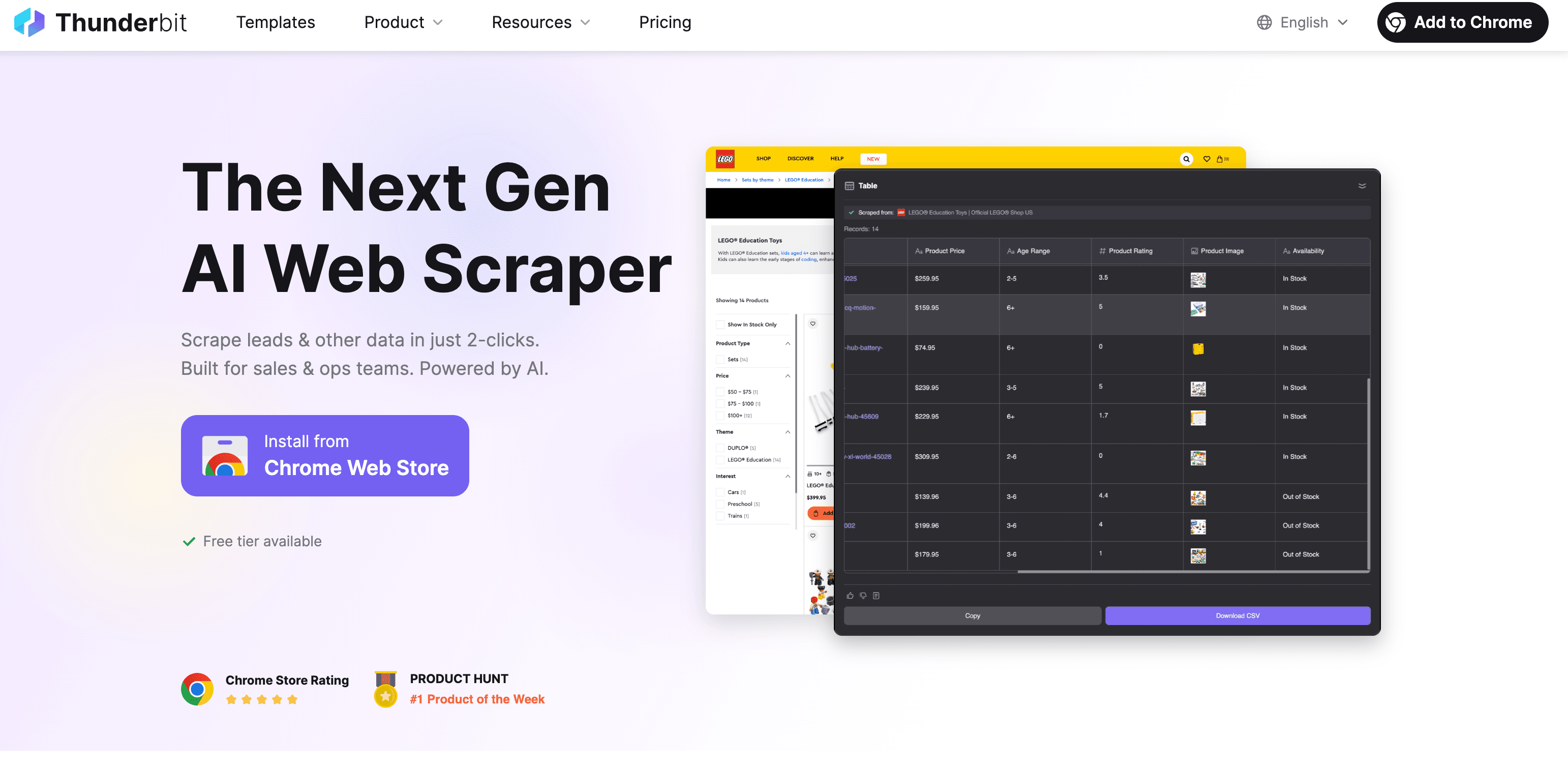
Okay, I’m a little biased here, but really is designed to make web text extraction as easy as ordering takeout. Here’s how it works:
Step-by-Step: Extract Text with Thunderbit
- Install the Chrome Extension: from the Chrome Web Store.
- Open the Website: Navigate to the page you want to extract text from.
- Click “AI Suggest Fields”: Thunderbit’s AI scans the page and recommends which fields (columns) to extract—think product name, price, description, etc.
- Review & Adjust: You can tweak the suggested fields or add your own.
- Click “Scrape”: Thunderbit grabs the data, including from subpages or paginated lists if needed.
- Export: Download your data to Excel, Google Sheets, Airtable, Notion, or as CSV/JSON. No extra fees for exporting.
What Makes Thunderbit Different?
- AI-Powered Field Suggestion: No need to mess with selectors or code. The AI figures out what’s important on the page.
- Handles Subpages & Pagination: Need details from every product page in a category? Thunderbit can click through automatically.
- Extracts from PDFs, Images, and Docs: Got a PDF manual or a product spec image? Thunderbit’s built-in OCR can pull text from those, too.
- Multi-language Support: Works in 34 languages (I’m still waiting for Klingon, but we’re working on it).
- Free Data Export: No paywall for getting your data out.
- Use Cases: Product descriptions, contact info, blog content, lead lists, you name it.
Want to see it in action? Check out our for guides like .
Other Browser Extensions and Online Tools
Let’s give a quick shout-out to some other tools you might run into:
- Web Scraper (): Free, point-and-click, but has a learning curve. Great for tech-savvy analysts, but you’ll need to set up “sitemaps” and selectors. Handles pagination, but not PDFs or images. .
- CopyTables: Super simple—just copies HTML tables to your clipboard or Excel. Perfect for quick, one-off table grabs, but only works one page at a time and only for tables. .
- ScraperAPI (): For developers. You send a URL, it returns the HTML (handles proxies, blocks, etc.), but you still need to parse the text yourself. .
When to Use Which Tool?
- Thunderbit: When you want speed, AI help, and multi-format support (including PDFs/images).
- Web Scraper: When you’re comfortable tinkering and want more control.
- CopyTables: When you just need a table, fast.
- ScraperAPI: When you’re building your own scraper in code.
Automated Web Scraping: Programming Solutions for Extracting Website Text
If you’re a developer (or have one handy), coding your own scraper gives you ultimate control. Here’s the basic workflow:
- Send HTTP Request: Use Python’s
requestsor similar to fetch the page. - Parse HTML: Use
BeautifulSoup,lxml, orScrapyto find the text you want. - Extract & Export: Pull out the text, clean it up, and save to CSV, JSON, or a database.
Example: Python + Beautiful Soup
1import requests
2from bs4 import BeautifulSoup
3url = "<http://quotes.toscrape.com>"
4response = requests.get(url)
5soup = BeautifulSoup(response.text, 'html.parser')
6quotes = [q.get_text() for q in soup.find_all("span", class_="text")]
7for qt in quotes:
8 print(qt)Pros & Cons
- Pros: Maximum flexibility, can handle any site or data type, integrates with your systems.
- Cons: Requires programming skill, ongoing maintenance, and handling anti-bot measures.
When to Go This Route
- You need to scrape thousands (or millions) of pages.
- The site is complex (logins, multi-step forms).
- You want to integrate scraping directly into your app or workflow.
Extracting Text from Non-HTML Formats: PDFs, Word Documents, and Images
Websites aren’t just HTML—they’re full of PDFs, Word docs, and images with valuable text. Here’s how to get at it:
PDFs
- Text-based PDFs: Use tools like Adobe Acrobat, or libraries like
PDFMinerorPyPDF2to extract text. - Scanned PDFs: Use OCR (Optical Character Recognition) tools like Tesseract, , or .
Word/Excel Docs
- Word: Use
python-docxto read .docx files. - Excel: Use
openpyxlorpandasfor .xlsx files.
Images
- OCR Tools: Tesseract for open-source, or cloud services for higher accuracy. Good quality images (150–300 DPI) work best.
Thunderbit’s Approach
“Image/Document Parser” lets you upload or link to a PDF, image, or doc, and the AI will extract the text (and even suggest columns if it finds a table). No need to juggle multiple tools—just treat files like any other web page.
Comparing All Methods: Which Text Extraction Solution Is Right for You?
Here’s a quick side-by-side to help you choose:
| Method | Ease of Use | Scalability | Tech Skill Needed | Data Types Supported | Best For |
|---|---|---|---|---|---|
| Manual (Copy-Paste) | Very Easy | Low | None | Visible text only | One-off, small jobs |
| Browser Extensions/Tools | Easy–Moderate | Medium | Low–Medium | HTML, some tables | Non-tech users, small–medium jobs |
| AI Tools (Thunderbit) | Very Easy | High | None | HTML, PDFs, images, more | Business users, mixed content |
| Programming (Code) | Hard | Very High | High | Any (with right libraries) | Developers, large-scale projects |
| Non-HTML Extraction (OCR) | Moderate | Low–Medium | Medium | PDFs, images, docs | When files/images are key |
If you want the fastest, most flexible, and least stressful route—especially for business use—AI tools like Thunderbit are hard to beat. But if you need total control or are scraping at massive scale, coding your own might make sense.
Key Takeaways: Start Extracting Text from Websites Today
- The web is overflowing with valuable text data, but it’s not always easy to get at.
- Manual methods work for tiny jobs, but they don’t scale.
- Browser extensions and AI web scrapers like make extracting text fast, accurate, and accessible to everyone—no coding required.
- For non-HTML content (PDFs, images), look for tools with built-in OCR and document parsing.
- Choose the method that matches your team’s skills, the size of your project, and the types of data you need.
Happy scraping—and may your Ctrl+C days be few and far between. With the right tools, extracting web data can become a seamless, automated process that frees up your time for more valuable tasks. No more endless hours of copying and pasting, just smart, efficient solutions at your fingertips. Here's to moving beyond the manual grind and embracing a more productive future!
FAQs
Q1: Can I scrape data from any website? A1: Not always. Some websites block scrapers or have terms of service that prohibit scraping. Always check the site's policies first.
Q2: How accurate are AI-powered web scrapers? A2: AI-powered scrapers like Thunderbit are highly accurate but may require some adjustments for complex or highly dynamic pages.
Q3: Do I need coding skills to use web scraping tools? A3: No, tools like Thunderbit and other browser extensions are designed for non-technical users and don’t require coding skills.
Q4: What types of data can I extract from PDFs or images? A4: OCR tools can extract text, tables, and even hidden data from scanned PDFs and images, making data extraction more versatile.
Read More