
If you’re exploring AI-powered web scraping tools, you’ve probably come across Crawl4AI. It’s a popular open-source project that’s been making waves among developers for its speed and flexibility. But what if you’re not a coder—or you just want to get data fast, without wrestling with Python scripts? Whether you’re considering Crawl4AI for your next project or you’re searching for a more user-friendly alternative, especially as a sales, marketing, e-commerce, or real estate professional, you’re in the right place. In this review, I’ll break down what Crawl4AI offers, where it shines, and where it might leave you wanting more. I’ll also show you how Thunderbit stacks up as a modern, no-code solution for business users who want to scrape the web with just a couple of clicks.
What is Crawl4AI?
Crawl4AI is an open-source Python library designed for web crawling and data extraction, with a special focus on AI and large language model (LLM) use cases. It’s gained traction on GitHub for its high-speed, parallel crawling and its ability to output data in AI-friendly formats like JSON and Markdown. In short, it’s a developer’s toolkit for scraping websites at scale, then feeding that data into AI models, analytics dashboards, or custom databases.
![]()
Key Products and Features:
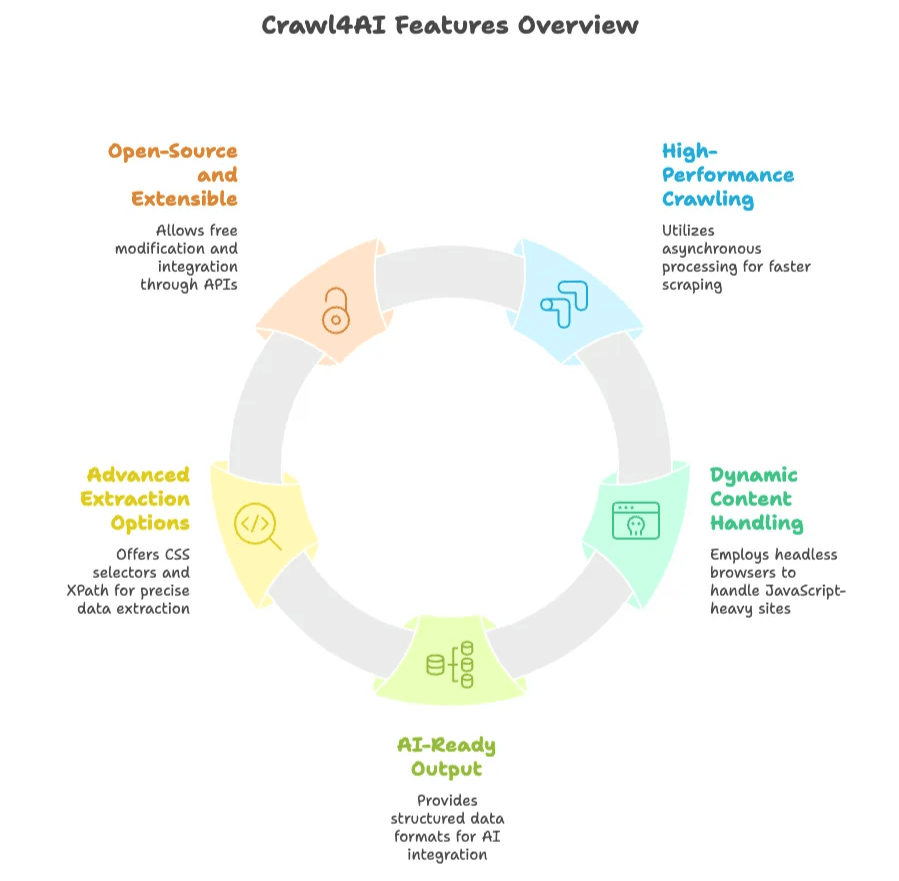
- High-Performance Crawling: Uses asynchronous, parallel processing to crawl multiple pages at once, making it much faster than many traditional scrapers.
- Dynamic Content Handling: Controls a headless browser (like Chromium via Playwright) to execute JavaScript and scrape modern, dynamic websites.
- AI-Ready Output: Outputs data as structured text (JSON, Markdown, or cleaned HTML) that’s ready for AI or data analysis.
- Advanced Extraction Options: Lets users specify extraction rules using CSS selectors or XPath, and even integrate LLMs for content summarization or extraction.
- Open-Source and Extensible: Free to use, modify, and extend. Offers a Python API, command-line interface, and REST API for flexible integration.
Crawl4AI’s philosophy is to “democratize data” by giving developers a fast, code-driven scraper without the paywalls or restrictions of commercial tools. If you’re comfortable with Python, it’s a powerful way to gather large amounts of web data quickly.
Who is Crawl4AI For?
Crawl4AI is built primarily for technical users—think developers, data scientists, AI researchers, and anyone who’s comfortable writing Python scripts. Here are some typical use cases:
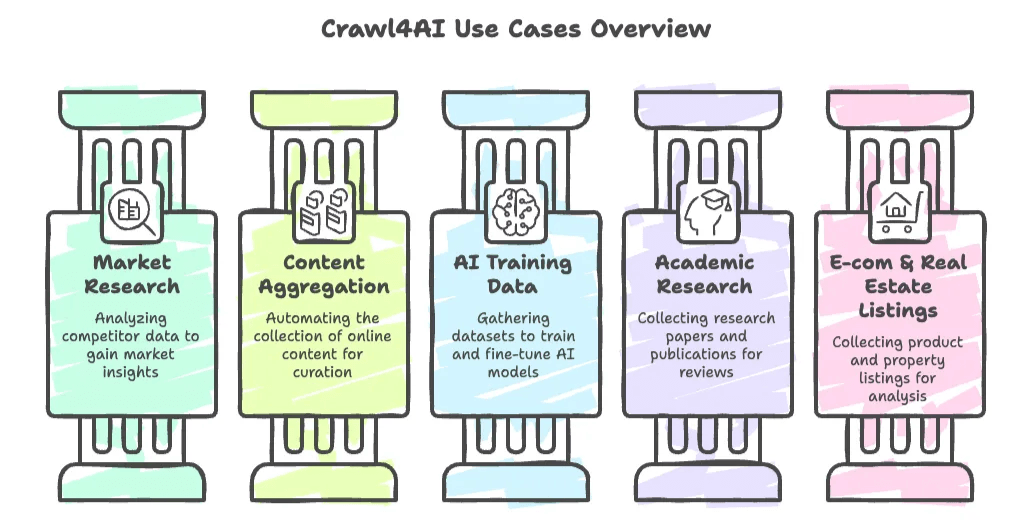
- Market Research & Competitive Analysis: Scrape competitor websites, news articles, or social media for insights.
- Content Aggregation: Automate the collection of news, blogs, or forum posts for curation or trend tracking.
- AI Training Data Collection: Gather large datasets (like documentation, Q&A, or articles) to train or fine-tune language models.
- Academic Research: Automatically collect research papers, case law, or online publications for literature reviews.
- E-commerce & Real Estate Listings: Developers can build custom crawlers to collect product or property listings for analysis.
But here’s the catch: Crawl4AI is not designed for non-technical users. If you’re a sales manager, marketer, or real estate agent without coding experience, you’ll likely find the setup and usage daunting. The tool assumes you know your way around Python and are comfortable configuring extraction rules and troubleshooting issues.
Crawl4AI Pricing Plan
One of Crawl4AI’s biggest selling points is its price: it’s completely free. As an open-source project, there are no license fees, subscription tiers, or paywalls. You can install it via pip and start using it right away.
However, “free” comes with some caveats:
- Setup and Maintenance: You’ll need to invest time in setting up your environment, writing scripts, and maintaining your scraping workflows.
- Indirect Costs: If you’re running large crawls, you may need to pay for proxies, servers, or cloud resources.
- Support: There’s no official customer support—just community forums and GitHub issues.
For businesses with in-house technical talent, this can be a cost-effective solution. But for non-technical teams, the time and effort required to get up and running can quickly outweigh the zero-dollar price tag.
User Feedback for Crawl4AI
To get a real sense of how Crawl4AI performs, I dug into user reviews on tech blogs, AI tool directories, and community forums. Here’s what I found:
What Users Like
- Speed and Cost-Efficiency: Developers rave about how fast Crawl4AI can scrape large websites, often outperforming paid tools. The fact that it’s free is a huge plus.
- Open-Source Flexibility: Users love having full control over the code, with no vendor lock-in or feature restrictions.
- AI-Ready Output: The structured, clean data output (especially in JSON or Markdown) saves time for those feeding data into AI models or analytics tools.
Where Users Struggle
But the praise comes with some big caveats—especially for beginners or non-programmers.
1. Steep Learning Curve
A recurring theme is that Crawl4AI is not beginner-friendly. If you’re new to web scraping or not comfortable with Python, you’ll face a steep learning curve. There’s no point-and-click interface; everything is done through scripts and configuration files. Setting up the environment, writing extraction rules, and handling asynchronous crawling all require technical know-how. One reviewer put it bluntly: “If you’re not a coder, you’ll be lost.”
2. Not Friendly for New Beginners
Even for those with some technical background, Crawl4AI can be challenging. The documentation is improving, but the community is still small, so finding help can be slow. Users report running into bugs or crashes on complex sites, and troubleshooting often means digging through GitHub issues or Stack Overflow. There’s also a lack of built-in features for common business needs—like logging into websites, solving CAPTCHAs, or scheduling recurring crawls. If you want to scrape data on a schedule or handle authentication, you’ll need to build those features yourself.
Real-World Example:
- A marketing manager at a mid-sized e-commerce company tried using Crawl4AI to monitor competitor prices. After several days of wrestling with Python scripts and browser drivers, they gave up and switched to a no-code tool. The technical hurdles and lack of support made it impractical for their team.
- A real estate agent wanted to scrape property listings from multiple sites. They found Crawl4AI’s setup overwhelming and couldn’t get past the initial configuration. Without a developer on hand, the project stalled.
In short, while Crawl4AI is a powerhouse for developers, it’s a tough sell for business users who just want to get data without the headaches.
Key Takeaways from the Crawl4AI Review
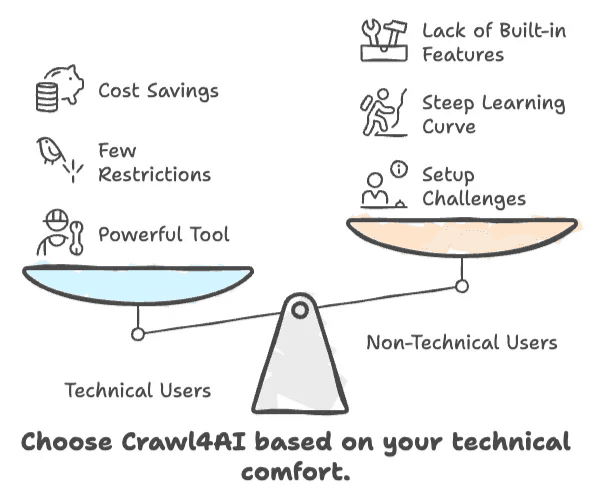
- Crawl4AI is fast, flexible, and free—but only if you’re comfortable with code.
- Non-technical users will struggle with the setup, learning curve, and lack of built-in business features.
- If you need a point-and-click, no-code solution, Crawl4AI probably isn’t for you.
- For developers and AI practitioners, it’s a powerful tool with few restrictions.
- For business users, the time and effort required may outweigh the cost savings.
Introducing Thunderbit: The No-Code AI Web Scraper for Business Users
After seeing where Crawl4AI falls short for non-technical users, let’s talk about a better alternative: Thunderbit.
Thunderbit is an AI-powered web scraper Chrome extension built specifically for business users—sales, marketing, e-commerce, and real estate pros who want to extract data from any website, fast, with zero coding required. I’ve tested a lot of scraping tools, and Thunderbit stands out for its simplicity and power.
What Makes Thunderbit Different?
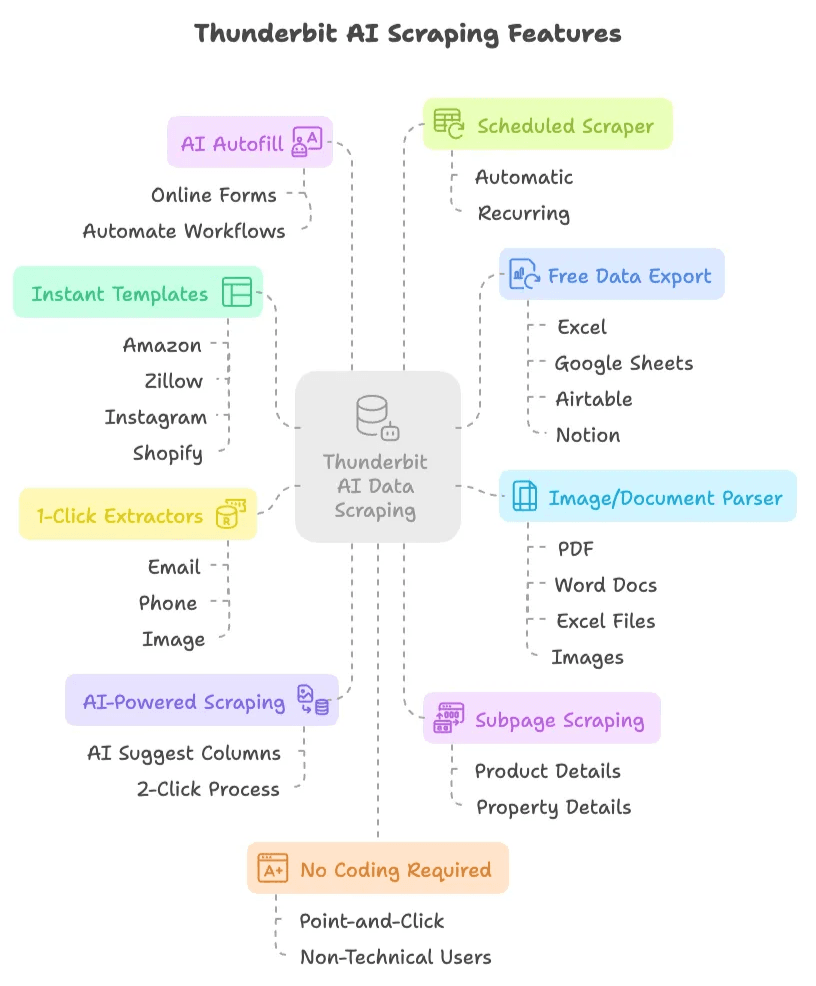
- AI-Powered, 2-Click Scraping: Just click “AI Suggest Columns,” let the AI recommend what to extract, then hit “Scrape.” That’s it. No scripts, no selectors, no headaches.
- Subpage Scraping: Thunderbit’s AI can automatically visit subpages (like product or property details) and enrich your data table—no manual setup needed.
- Instant Data Scraper Templates: For popular sites like Amazon, Zillow, Instagram, and Shopify, you can export data in one click using pre-built templates.
- Free Data Export: Export your scraped data to Excel, Google Sheets, Airtable, or Notion—without paying extra.
- AI Autofill (Completely Free): Use AI to fill out online forms and automate workflows. Just select the context and let Thunderbit handle the rest.
- Scheduled Scraper: Set up automatic, recurring scrapes with a simple schedule—no cron jobs or server setup required.
- 1-Click Email, Phone, and Image Extractors: Instantly grab emails, phone numbers, or images from any website.
- Image/Document Parser: Extract tables from PDFs, Word docs, Excel files, or images. Upload your file, let AI structure the data, and click “Scrape.”
- No Coding Required: Everything is point-and-click, designed for non-technical users.
Scrape data from any website using AI Get Started Free
Thunderbit is all about making web data accessible to everyone—not just developers. If you want to see how it works, check out the Thunderbit Chrome Extension Download Page or browse the Thunderbit Blog for real-world use cases.
Try Thunderbit AI Web Scraper for Free
Thunderbit Pricing Plans
Thunderbit uses a simple credit system: 1 credit = 1 output row. Here’s how the plans break down:
| Tier | Monthly Price | Yearly Price (per month) | Credits (Monthly) |
|---|---|---|---|
| Free | Free | Free | 6 pages |
| Starter | $15 | $9 | 500 |
| Pro 1 | $38 | $16.5 | 3,000 |
| Pro 2 | $75 | $33.8 | 6,000 |
| Pro 3 | $125 | $68.4 | 10,000 |
| Pro 4 | $249 | $137.5 | 20,000 |
You can start for free and scrape up to 6 pages (or 10 with a free trial). Paid plans unlock more credits and advanced features, but even the free tier is generous for light users. For more details, visit the Thunderbit Pricing page.
Thunderbit vs Crawl4AI: Side-by-Side Comparison
Let’s put Thunderbit and Crawl4AI head-to-head so you can see where each tool excels—and where Thunderbit makes life easier for business users.
| Feature / Criteria | Thunderbit | Crawl4AI |
|---|---|---|
| No-Code, Point-and-Click UI | ✅ | ❌ |
| AI Suggest Columns (Auto-Detect) | ✅ | ❌ |
| Subpage Scraping (Auto) | ✅ | ❌ |
| Instant Templates (Amazon, etc.) | ✅ | ❌ |
| Free Data Export (Excel, Sheets) | ✅ | ❌ |
| AI Autofill (Form Filling) | ✅ | ❌ |
| Scheduled Scraping (No Code) | ✅ | ❌ |
| 1-Click Email/Phone/Image Extract | ✅ | ❌ |
| Image/Document Table Extraction | ✅ | ❌ |
| Handles Dynamic Content | ✅ | ✅ |
| Open-Source | ❌ | ✅ |
| Requires Coding | ❌ | ✅ |
| Free Tier Available | ✅ | ✅ |
| Community Support | ✅ | ⚠️ (Limited) |
| Built for Business Users | ✅ | ❌ |
| Built for Developers | ⚠️ | ✅ |
| Pricing | $ (Free & Paid) | Free |
| Customer Support | ✅ | ❌ |
Legend:
✅ = Yes
❌ = No
⚠️ = Limited/Partial
$ = Paid plans available
Conclusion
If you’re a developer who loves tinkering with code and wants total control, Crawl4AI is a powerful, free tool for large-scale web scraping. But if you’re a business user—especially in sales, marketing, e-commerce, or real estate—who just wants to get data without the hassle, Thunderbit is the clear winner. It’s built for non-technical users, with AI-powered automation, instant templates, and a friendly interface that gets you from website to spreadsheet in seconds.
Scrape Any Website with Thunderbit
FAQs
1. How does Thunderbit compare to other AI web scrapers like Crawl4AI?
Thunderbit is designed for non-technical users, offering a no-code, point-and-click interface, while Crawl4AI is a developer-focused, open-source Python library. Thunderbit automates complex tasks with AI, making web scraping accessible to everyone.
2. What unique features does Thunderbit offer for business users?
Thunderbit provides AI-powered column suggestions, subpage scraping, instant templates for popular sites, and free data export to Excel or Google Sheets—all without coding. It also includes scheduled scraping and 1-click extractors for emails, phone numbers, and images.
3. Can Thunderbit handle complex data extraction like PDFs or images?
Absolutely! Thunderbit’s AI can extract tables from PDFs, Word docs, Excel files, and images. Just upload your file, let the AI structure the data, and click “Scrape” for instant results. Learn more on the Thunderbit Blog.
Learn More
- What Is Data Scraping and How to Do It in 2025 – Thunderbit Blog
- The Best Web Scraping Tools & Software in 2025 – Thunderbit Blog
- The Top AI Data Collection Tools for Model-Ready Datasets – Medium
- How AI Web Scrapers Can Help With Data Extraction And Analysis - Forbes
Try AI Web Scraper Get Started Free




