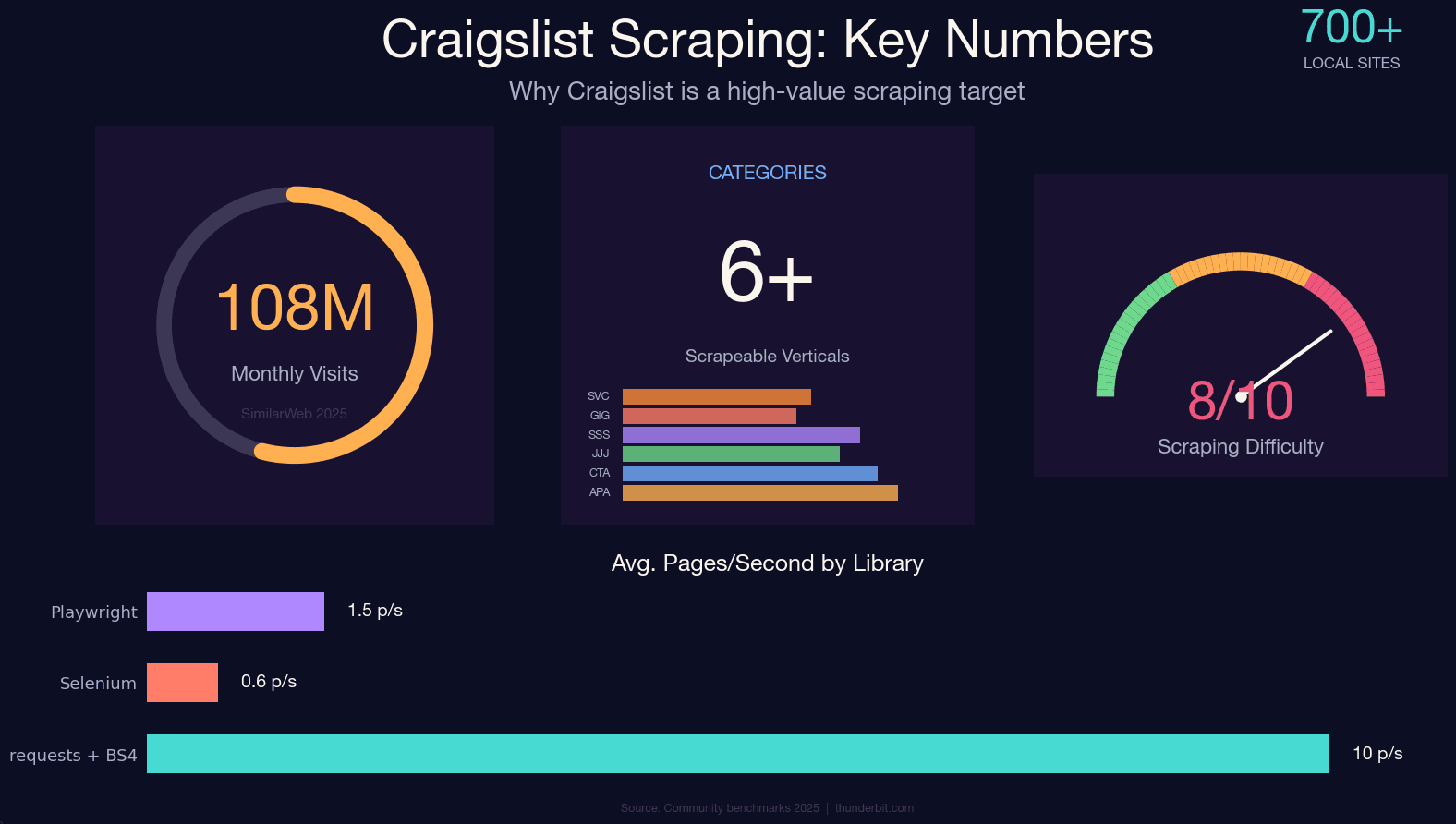
لا يزال Craigslist يستقبل ما يقارب عبر نحو 700 موقع محلي — ومع ذلك لا يوفّر أي API عام. إذا كنت تريد بيانات منظمة من إعلانات الشقق، السيارات المستعملة، الوظائف، أو عروض الأعمال الحرة، فعملية استخراج البيانات هي عمليًا خيارك الوحيد.
لكن نظام الحماية ضد الروبوتات في Craigslist صارم للغاية. فهو لا يستخدم Cloudflare أو DataDome — بل يعتمد على محدد معدل مبني على nginx طُوّر على مدى أكثر من عقد. إذا أخطأت في التعامل معه، فستتلقى خطأ 403 مباشرة قبل أن تنتهي من فنجان قهوتك الثاني. لقد أمضيت وقتًا طويلًا في تجربة أساليب مختلفة أمام دفاعات Craigslist، وهذه المقالة هي خلاصة ذلك: دليل Python محدّث لعام 2025، يصلح لكل الفئات، ويشرح طريقة استخراج JSON-LD (وهي أكبر تحسين مقارنة بالأدلة القديمة)، واستراتيجيات واقعية لتجنّب الحظر، والمشهد القانوني، وبديلًا بدون كود لمن يريد البيانات فقط من دون كتابة سطر واحد.
ماذا يعني استخراج بيانات Craigslist باستخدام Python؟
استخراج بيانات Craigslist عبر الويب يعني استخدام سكربتات Python لزيارة صفحات Craigslist برمجيًا، ثم سحب البيانات المنظمة التي تهمك — مثل العناوين، الأسعار، الوصف، الصور، المواقع، وتواريخ النشر — وحفظها في جدول بيانات أو قاعدة بيانات أو ملف JSON.
Python هو الخيار المفضل لهذا الغرض بسبب منظومته الواسعة من المكتبات. فبفضل requests وBeautifulSoup وlxml وcurl_cffi يمكنك بناء أداة فعالة لاستخراج بيانات Craigslist في أقل من 100 سطر. كما أن المجتمع ضخم جدًا، لذلك عندما يغيّر Craigslist شيئًا ما — وهذا يحدث فعلًا — يكون هناك من اكتشف الحل بالفعل.
النقطة الأهم التي يجب معرفتها: Craigslist . الواجهة الرسمية الوحيدة للبرمجة هي Bulk Posting Interface (BAPI)، وهي للكتابة فقط — أي تتيح للناشرين المعتمدين والمدفوعين إرسال الإعلانات، لكنها لا تسمح بجلبها. كل منتج "Craigslist API" تراه في المنصات الخارجية هو في الحقيقة أداة استخراج غير رسمية، وليس نقطة نهاية معتمدة. إذا كنت تريد بيانات جماعية، فعليك الاستخراج.
لماذا نستخرج بيانات Craigslist؟ استخدامات واقعية
Craigslist ليس مجرد مكان للعثور على أريكة مستعملة. إنه مجموعة بيانات ضخمة تُحدَّث باستمرار عبر عشرات المجالات. إليك الجهات التي تستفيد منه فعليًا:
| حالة الاستخدام | من يستفيد | ما الذي تستخرجه |
|---|---|---|
| مراقبة أسعار الشقق والإيجارات | وكلاء العقارات، المستأجرون، شركات PropTech | السعر، المساحة، عدد الغرف، الحي، خط العرض/الطول |
| تحليل سوق السيارات المستعملة | معارض السيارات، التطبيقات الاستهلاكية، الباحثون | السعر، الماركة، الطراز، السنة، عداد المسافة، الحالة |
| أبحاث سوق العمل | مسؤولو التوظيف، خبراء اقتصاد العمل، محللو القوى العاملة | المسمى الوظيفي، التعويض، نوع الوظيفة، تاريخ النشر |
| توليد العملاء المحتملين | فرق المبيعات، مقدمو الخدمات | بيانات التواصل، أسماء الشركات، نطاق الخدمة |
| التسعير التنافسي | مقدمو الخدمات المحليون، عمليات التجارة الإلكترونية | أسعار الخدمات، الأوصاف، المناطق المخدومة |
ومن أكثر الأمثلة الأكاديمية تداولًا — وهي تضم قرابة 500,000 إعلان سيارات مستعملة في الولايات المتحدة مع 26 متغيرًا، وكانت أساسًا لعشرات الأبحاث، بما فيها دراسة على ResearchGate عام 2024 حول ديناميكيات سوق السيارات المستعملة في أمريكا. كما اشترت صناديق تحوط بيانات إيجارات Craigslist المجمعة لأغراض تحليل اتجاهات الإيجار. وتقوم فرق المبيعات باستمرار باستخراج فئات الخدمات والأعمال الحرة لتوليد العملاء.
المعادلة بسيطة: 8 ساعات من النسخ واللصق اليدوي مقابل نحو 10 دقائق فقط باستخدام أداة استخراج جيدة.
استخراج Craigslist باستخدام Python: كل الفئات، وليس السيارات فقط
معظم أدلة استخراج Craigslist التي وجدتها تركز فقط على سيارات البيع — وهذا يشبه كتابة دليل عن Google يشرح البحث بالصور فقط. لدى Craigslist عشرات الفئات، وتختلف أنماط الروابط لكل منها.
البنية دائمًا تكون كالتالي: https://\{city\}.craigslist.org/search/\{category_slug\}
غيّر النطاق الفرعي للمدينة والـ slug، وستنتقل إلى مجال مختلف تمامًا. فيما يلي جدول مرجعي لأشهر الفئات (تم التحقق في أبريل 2025):
| الفئة | جزء الرابط | الحقول المعتادة للاستخراج |
|---|---|---|
| الشقق / السكن | /search/apa | السعر، المساحة، عدد الغرف، الموقع، سياسة الحيوانات الأليفة |
| السيارات والشاحنات | /search/cta | السعر، الماركة، الطراز، السنة، عداد المسافة |
| الوظائف | /search/jjj | المسمى الوظيفي، الشركة، الراتب، نوع التوظيف |
| الخدمات | /search/bbb | المسمى، الوصف، رقم الهاتف، المنطقة |
| الأعمال الحرة | /search/ggg | المسمى، التعويض، التاريخ، الفئة |
| المعروض للبيع (عام) | /search/sss | المسمى، السعر، الحالة، الموقع |
يمكنك أيضًا إضافة معلمات بحث للتصفية:
| المعلمة | الغرض | مثال |
|---|---|---|
query | كلمة مفتاحية بالنص الكامل | ?query=studio |
min_price / max_price | نطاق السعر | &min_price=1500&max_price=3000 |
hasPic | المنشورات التي تحتوي على صور فقط | &hasPic=1 |
postedToday | آخر 24 ساعة | &postedToday=1 |
sort | ترتيب النتائج | &sort=priceasc |
s | إزاحة التصفح الصفحي (120 نتيجة لكل صفحة) | ?s=120 |
إذًا رابط مثل https://newyork.craigslist.org/search/apa?min_price=1500&max_price=3000&hasPic=1 يعرض لك شقق نيويورك بين 1,500 و3,000 دولار مع صور. كل سكربت Python في هذا الدليل يعمل عبر هذه الفئات — فقط غيّر الـ slug.
محددات HTML في Craigslist لعام 2025: القديم مقابل الجديد (والاختصار عبر JSON)
السبب الأول الذي يجعل سكربتات Craigslist تتعطل هو تغيّر بنية HTML. إذا كنت تتبع شرحًا من عام 2022 يطلب منك استهداف .result-row أو .result-info، فسكربتك أصبح متوقفًا بالفعل.
لقد أعاد Craigslist كتابة ترميز نتائج البحث في 2023–2024. أسماء الأصناف القديمة ما تزال موجودة داخل أغلفة جديدة، لكن استهدافها في أعلى شجرة DOM سيعيد قائمة فارغة. إليك ما الذي تغيّر:
| العنصر | المحدد القديم (قبل 2024) | المحدد الحالي (2025) |
|---|---|---|
| حاوية الإعلان | .result-info | .cl-search-result |
| رابط العنوان | .result-title | .posting-title a |
| السعر | .result-price | .priceinfo |
| البيانات الوصفية (المنطقة) | .result-hood | .meta |
لكن إليك الفكرة الأهم — وهي ما يميز أداة استخراج حديثة لعام 2025 عن كل ما سبق: لست بحاجة لتحليل HTML أصلًا في نتائج البحث.
الآن يضم Craigslist كل إعلان ظاهر داخل وسم <script id="ld_searchpage_results"> على شكل بيانات JSON-LD منظمة. استدعاء واحد لـ requests.get() يعيد كامل مخطط schema.org من نوع ItemList بكل إعلان في الصفحة — العنوان، السعر، العملة، الموقع، رابط الصورة، ورابط صفحة التفاصيل. من دون أي حاجة إلى تشغيل JavaScript. ومن دون هشاشة محددات CSS.
أسلوب JSON-LD أسرع وأكثر ثباتًا، واحتمال تعطّله أقل بكثير عندما يغيّر Craigslist واجهته. وهو ما تستخدمه كل المستودعات النشطة على GitHub، وهو ما سنعتمد عليه في الشرح أدناه.
هناك ملاحظة واحدة: كتلة JSON-LD — مثل الشقق (apa)، والمبيعات (sss), والسيارات (cta)، والسكن (hhh). وغالبًا ما تكون غائبة أو محدودة في الوظائف (jjj) والأعمال الحرة (ggg) والمجتمع (ccc) والخدمات (bbb) لأن هذه الإعلانات لا تتضمن schema.org/Offer pricing. في هذه الحالات، ارجع إلى مسار HTML عبر .cl-search-result.
اختيار مكدس Python: Requests + BS4 أم Selenium أم Playwright؟
هذا السؤال يتكرر في كل منتدى خاص بالاستخراج: "أي مكتبة أستخدم؟" وبالنسبة لـ Craigslist، الجواب أوضح بكثير من معظم المواقع.
| العامل | requests + BeautifulSoup | Selenium | Playwright |
|---|---|---|---|
| السرعة | 5–15 صفحة/ثانية (محددة بالشبكة) | 0.3–1 صفحة/ثانية | 0.5–2 صفحة/ثانية |
| المحتوى المعتمد على JavaScript | لا | نعم | نعم |
| استهلاك الذاكرة | ~30–60 MB | ~400–700 MB | ~300–500 MB |
| تعقيد الإعداد | منخفض | متوسط | متوسط |
| مقاومة الحظر | منخفضة (تحتاج Headers / Proxies) | متوسطة (متصفح حقيقي) | متوسطة إلى عالية |
| أفضل استخدام مع Craigslist | نتائج البحث (JSON-LD) | صفحات التفاصيل ذات المحتوى الديناميكي | الاستخراج واسع النطاق غير المتزامن |
| سهولة التعلم | مناسب للمبتدئين | متوسط | متوسط |
صفحات Craigslist تُعرض من الخادم. وكتلة JSON-LD موجودة في HTML الأولي. لا توجد تحديات JavaScript في مسارات القراءة. وكل تستخدم requests + BeautifulSoup أو Scrapy. ولا تستخدم Selenium أو Playwright. وهذا ليس صدفة — فإطار أتمتة المتصفح يضيف مئات الميغابايت من الذاكرة، ويبطّئ التنفيذ من 10 إلى 100 مرة، ويجعل البصمة أكثر وضوحًا من دون أي فائدة حقيقية.
توصيتي:
- requests + BS4: ابدأ هنا. فهو يتوافق تمامًا مع طريقة استخراج JSON-LD ويغطي 95% من احتياجات Craigslist.
- Selenium: فقط إذا كنت تحتاج التفاعل مع محتوى ديناميكي في صفحات معينة (وهذا نادر في Craigslist).
- Playwright: إذا كنت تتوسع إلى آلاف الصفحات مع تنفيذ متوازٍ غير متزامن — لكن بصراحة، عنق الزجاجة الحقيقي هو محدد المعدل في Craigslist، لا إنتاجية المكتبة.
وقد تناولنا مقارنة ومراجعة في مقالات منفصلة إذا أردت الشرح الكامل.
البديل بدون كود: استخراج Craigslist من دون كتابة Python
قبل أن ندخل في الكود، هذه الفقرة مخصّصة لكل من ليس مطورًا. وكلاء العقارات، فرق المبيعات، ومديرو العمليات — إذا كنت تريد البيانات فقط ولا يهمك كتابة Python، فهناك طريق أسرع.
هو أداة استخراج ويب بالذكاء الاصطناعي تعمل كإضافة لمتصفح Chrome. يمكنه استخراج Craigslist في نحو خطوتين فقط، من دون كود. وهذه هي الطريقة:
- انتقل إلى أي صفحة نتائج بحث في Craigslist (شقق، سيارات، وظائف — أي فئة).
- انقر "اقتراح الحقول بالذكاء الاصطناعي" في الشريط الجانبي لـ Thunderbit. يقرأ الذكاء الاصطناعي الصفحة ويتعرف تلقائيًا على الأعمدة مثل عنوان الإعلان، السعر، الموقع، والرابط.
- انقر "استخراج" — وستُسحب البيانات خلال ثوانٍ.
- استخدم استخراج الصفحات الفرعية لزيارة صفحة التفاصيل لكل إعلان وإثراء بياناتك بالوصف الكامل، أرقام الهاتف، الصور، والخصائص.
- صدّر النتائج مباشرة إلى Google Sheets أو Excel أو Airtable أو Notion — مجانًا تمامًا.
وللاحتياجات المتكررة — مثل مراقبة أسعار الشقق يوميًا أو أخذ لقطات أسبوعية لإعلانات الوظائف — تتيح لك ميزة Scheduled Scraper في Thunderbit وصف الجدول الزمني بالعربية/الإنجليزية العادية، وهي تعمل تلقائيًا. لا حاجة إلى cron jobs أو إعداد خادم.
كما يتعامل Thunderbit مع إجراءات مكافحة الروبوتات عبر وضع Cloud Scraping، لذلك لن تحتاج إلى إدارة proxies متغيرة أو إعداد headers يدويًا. إذا أردت تجربته، حمّل وجرب بنفسك.
إذا كنت تريد تحكمًا كاملًا وتخصيصًا أعمق، تابع القراءة للشرح العملي خطوة بخطوة في Python.
خطوة بخطوة: كيفية استخراج Craigslist باستخدام Python (الشرح الكامل)
- مستوى الصعوبة: متوسط
- الوقت المطلوب: حوالي 30 دقيقة (الإعداد + أول عملية استخراج)
- ما تحتاجه: Python 3.8+، متصفح Chrome (لفحص الصفحات)، وسطر أوامر
الخطوة 1: إعداد بيئة Python
ثبّت المكتبات المطلوبة:
1pip install requests beautifulsoup4 lxmlمكتبة lxml اختيارية لكنها تسرّع تحليل BeautifulSoup بشكل ملحوظ. وإذا واجهت لاحقًا مشاكل في بصمة TLS (سنعود لهذا في قسم تجنب الحظر)، يمكنك أيضًا تثبيت curl_cffi:
1pip install curl_cffiكتلة الاستيراد:
1import requests
2from bs4 import BeautifulSoup
3import json
4import csv
5import time
6import randomالآن أصبحت لديك بيئة Python نظيفة مع تثبيت جميع الاعتماديات.
الخطوة 2: إنشاء رابط Craigslist لأي فئة
ابنِ الرابط المستهدف ديناميكيًا باستخدام المدينة + slug الفئة + الفلاتر الاختيارية:
1from urllib.parse import urlencode
2BASE = "https://\{city\}.craigslist.org/search/\{slug\}"
3def build_url(city, slug, **params):
4 return f"{BASE.format(city=city, slug=slug)}?{urlencode(params)}"
5# مثال: شقق نيويورك، من 1500 إلى 3000 دولار، مع صور
6url = build_url("newyork", "apa", min_price=1500, max_price=3000, hasPic=1)
7print(url)
8# https://newyork.craigslist.org/search/apa?min_price=1500&max_price=3000&hasPic=1بدّل "apa" بـ "cta" (السيارات)، أو "jjj" (الوظائف)، أو "bbb" (الخدمات)، أو أي slug من جدول الفئات أعلاه. وبدّل "newyork" بـ "sfbay" أو "chicago" أو "losangeles"، إلخ.
الخطوة 3: جلب الصفحة واستخراج JSON المضمّن
أرسل طلب GET مع headers مناسبة، ثم حلّل كتلة JSON-LD:
1HEADERS = {
2 "User-Agent": (
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/124.0.0.0 Safari/537.36"
6 ),
7 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept-Encoding": "gzip, deflate, br",
10 "Referer": "https://www.craigslist.org/",
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-Mode": "navigate",
13 "Sec-Fetch-Site": "same-origin",
14 "Upgrade-Insecure-Requests": "1",
15}
16session = requests.Session()
17r = session.get(url, headers=HEADERS, timeout=20)
18r.raise_for_status()
19soup = BeautifulSoup(r.text, "html.parser")
20tag = soup.select_one("script#ld_searchpage_results")
21data = json.loads(tag.text) if tag else {"itemListElement": []}إذا كانت tag تساوي None، فهذا يعني أن كتلة JSON-LD غير موجودة لتلك الفئة — عندها انتقل إلى تحليل HTML (انظر جدول المحددات أعلاه). أما بالنسبة للشقق والسيارات وفئات البيع العام، فكتلة JSON-LD تكون متوفرة بشكل موثوق.
الخطوة 4: تحويل بيانات الإعلانات إلى سجلات منظمة
مرّ على عناصر JSON واستخرج الحقول التي تحتاجها:
1listings = []
2for entry in data["itemListElement"]:
3 item = entry["item"]
4 offers = item.get("offers", {}) or {}
5 addr = (offers.get("availableAtOrFrom") or {}).get("address", {})
6 listings.append({
7 "name": item.get("name"),
8 "url": offers.get("url"),
9 "price": offers.get("price"),
10 "currency": offers.get("priceCurrency"),
11 "locality": addr.get("addressLocality"),
12 "region": addr.get("addressRegion"),
13 "image": item.get("image"),
14 })
15print(f"Found {len(listings)} listings")سترى شيئًا مثل "Found 120 listings" (يعرض Craigslist عادة 120 نتيجة لكل صفحة). قد تحتوي بعض الإعلانات على None في السعر إذا لم يذكر الناشر السعر — تعامل مع ذلك بسلاسة في المنطق اللاحق.
الخطوة 5: استخراج صفحات التفاصيل للحصول على بيانات أغنى
نتائج البحث تمنحك ملخصًا فقط. للحصول على الوصف الكامل والخصائص (عدد الغرف، المساحة، سياسة الحيوانات الأليفة)، وإحداثيات خط العرض/الطول، والصور، عليك زيارة رابط تفاصيل كل إعلان.
1def fetch_detail(url, session):
2 r = session.get(url, headers=HEADERS, timeout=20)
3 r.raise_for_status()
4 s = BeautifulSoup(r.text, "html.parser")
5 body = s.select_one("#postingbody")
6 mp = s.select_one("#map")
7 return {
8 "description": body.get_text("\n", strip=True) if body else None,
9 "attributes": [x.get_text(" ", strip=True)
10 for x in s.select("p.attrgroup span, div.attrgroup .attr")],
11 "lat": mp.get("data-latitude") if mp else None,
12 "lng": mp.get("data-longitude") if mp else None,
13 "images": [img["src"] for img in s.select("div.gallery img")],
14 }
15for item in listings:
16 item.update(fetch_detail(item["url"], session))
17 time.sleep(random.uniform(3, 6)) # مهم جدًا: تباين زمني لتجنب الحظرtime.sleep(random.uniform(3, 6)) ليست خطوة اختيارية. إذا تخطيتها، فغالبًا ستواجه خطأ 403 خلال عشرات الطلبات فقط. صفحات التفاصيل تُعرض من الخادم بمحددات ثابتة (#titletextonly و#postingbody و#map) لم تتغير تقريبًا منذ 2017 — وهي من الأشياء القليلة في Craigslist التي يمكن الاعتماد عليها فعلًا.
الخطوة 6: التعامل مع التصفح الصفحي لاستخراج كل النتائج
يستخدم Craigslist معامل الإزاحة `?s=