借助 (一款由 AI 驱动的网页爬虫),你可以在几分钟内从 We Work Remotely 抓取远程职位列表。Thunderbit 会“读懂”页面并把职位信息整理成结构化表格:你只需要点击 AI Suggest Columns,再点击 Scrape,AI 就会自动整理职位名称、公司、地点、标签、日期和链接,方便导出。如果你还需要更深入的信息,也可以使用 subpage scraping 逐个打开职位详情页,把完整描述和投递链接一并补齐。
🧑💻 什么是 We Work Remotely 爬虫
We Work Remotely 爬虫 是一个 AI 网页爬虫,通过 Thunderbit Chrome 扩展帮助你从 提取职位列表与职位详情。你无需写代码,也不用维护容易失效的选择器:打开你想抓取的页面(例如远程职位目录页),点击 AI Suggest Columns,再点击 Scrape,即可生成整洁的数据表,下载或同步到常用工具中。
使用 Thunderbit 你还可以:
- 处理 分页 与超长列表
- 通过 Subpage Scraping 打开每条职位详情页,抓取完整描述、任职要求与投递 URL
- 免费导出到 Excel、Google Sheets、Airtable 或 Notion(也支持免费导出)
🗂️ We Work Remotely 可以抓取哪些内容
We Work Remotely 是一个热门的远程岗位聚合平台,覆盖工程、产品、设计、市场、客服支持等多个方向。使用 Thunderbit 的 AI 网页爬虫(https://thunderbit.com/),你可以搭建结构化的职位数据库,用于寻源、分析、提醒与报表。
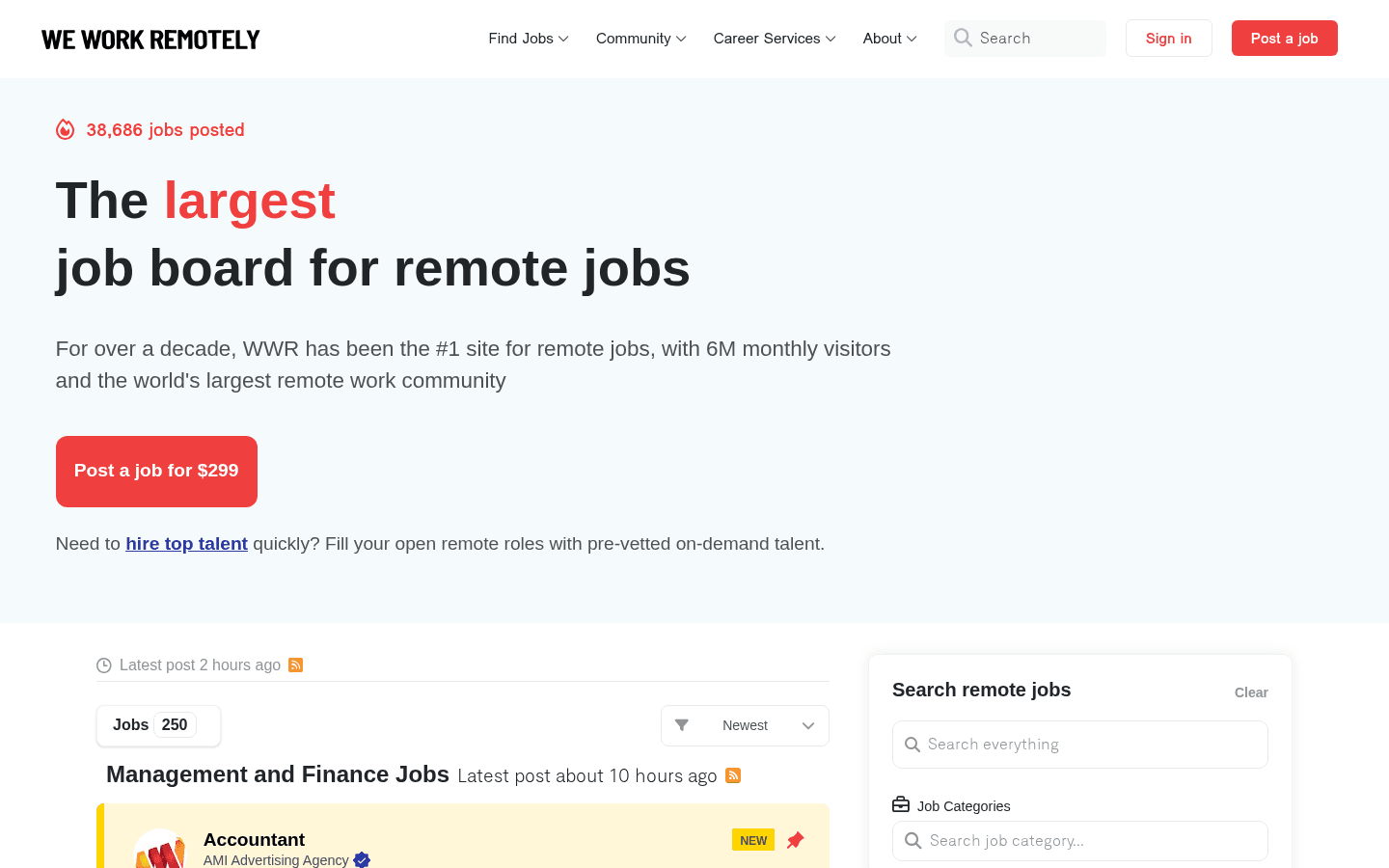
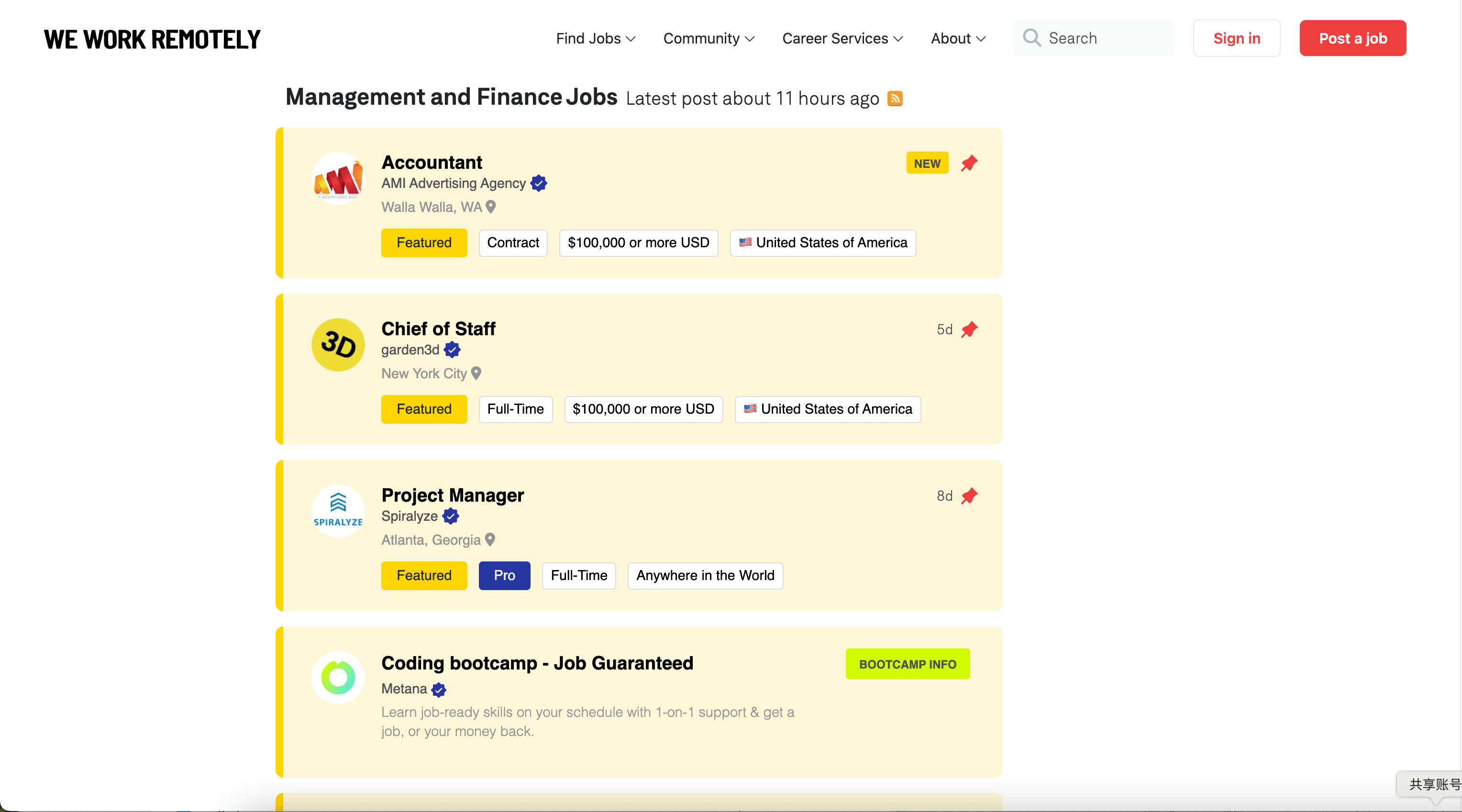
抓取 We Work Remotely 的全部远程职位
该场景主要抓取远程职位主目录页:。适合你希望覆盖更多类别与公司,并在需要时再通过抓取职位详情页来丰富每一行数据。
操作步骤:
- 安装 并注册账号。
- 打开目标页面,例如:https://weworkremotely.com/remote-jobs
- 点击 AI Suggest Columns,让 AI 推荐要提取的字段。
- 点击 Scrape 开始抓取,获取数据并下载文件。
字段(列)建议
| Column | Description |
|---|---|
| 🧾 Job Title | 列表中展示的职位名称(例如 “Senior Backend Engineer”)。 |
| 🏢 Company | 该职位对应的公司名称。 |
| 📍 Location / Region | 地点/区域要求,例如 “Worldwide”“US only” 或特定区域限制。 |
| 🏷️ Tags / Category | 列表中展示的标签/类别,如 Programming、Design、Marketing 等。 |
| 🗓️ Posted Date | 发布时间(或相对时间),如页面提供则可抓取。 |
| 🔗 Job URL | 职位详情页链接(用于子页面抓取非常关键)。 |
| 🖼️ Company Logo URL | 列表中出现时的公司 Logo 图片链接。 |
| 🧩 Short Summary | 列表页展示的简短摘要/预览文本(如有)。 |
小提示: 列表抓取完成后,可使用 Scrape Subpages 逐个访问 Job URL,补充完整描述、任职要求、薪资(如有)以及投递链接等字段。
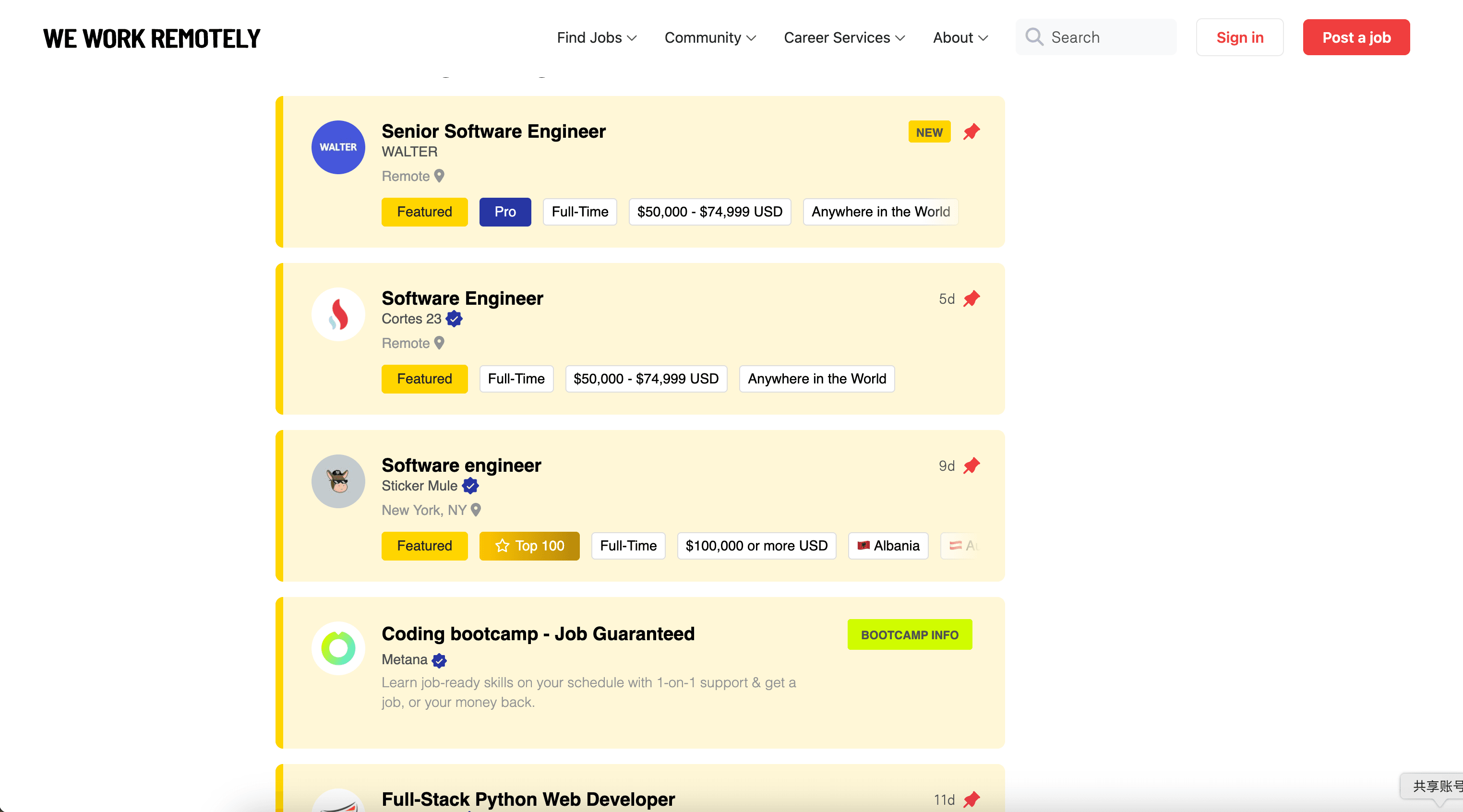
抓取 We Work Remotely 的远程编程岗位
该场景面向特定分类页:。如果你只关注工程/开发岗位,这种方式更省事,数据也更“干净”,后续无需再做大量筛选。
操作步骤:
- 安装 并注册账号。
- 打开目标页面,例如:https://weworkremotely.com/categories/remote-programming-jobs
- 点击 AI Suggest Columns,让 AI 推荐要提取的字段。
- 点击 Scrape 开始抓取,获取数据并下载文件。
字段(列)建议
| Column | Description |
|---|---|
| 💻 Job Title | 分类页中展示的开发/编程岗位名称。 |
| 🏢 Company | 招聘该岗位的公司。 |
| 🌎 Location / Timezone | 地点或时区要求,例如国家/地区限制或时区重叠要求。 |
| 🧠 Tech / Tags | 体现技术栈、级别或岗位类型的标签(如页面展示)。 |
| 🗓️ Posted Date | 发布日期或相对时间提示。 |
| 🔗 Job URL | 职位详情页链接,便于通过子页面抓取补全信息。 |
| 🧾 Category | 分类名称(当你合并多个分类抓取结果时很有用)。 |
| 📝 Notes (AI) | 可选:添加 Field AI Prompt,让 AI 总结岗位或做分类(例如 Backend/Frontend/Full-stack)。 |
🎯 为什么要用 We Work Remotely 工具
抓取 We Work Remotely 的价值在于:把更新很快的招聘信息,变成你可以检索、筛选并用于业务流程的数据资产。
团队常见的使用动机包括:
- 招聘与人才寻源: 建立远程招聘公司的线索库,跟踪新职位,并按地区、技术栈或资历优先级排序。
- 销售与合作拓展: 发现增长迅速的 remote-first 公司,用“正在招聘”作为线索信号(往往意味着预算与紧迫度)。
- 市场研究: 按类别(开发 vs 设计等)追踪招聘趋势、地点限制与岗位频次变化。
- 求职者与职业教练: 在 Google Sheets 或 Notion 里做个人职位追踪表,去重并监控新发布。
- 电商与运营团队招聘技术人才: 持续维护与你所在细分领域相关的工程岗位清单。
Thunderbit 的优势在于更贴近业务工作流:AI 网页爬虫(https://thunderbit.com/)会自动把数据结构化,而 Subpage Scraping 能在无需搭建复杂爬取系统的情况下,为每一行补全详情信息。
想了解更多现代化抓取流程,可参考:
🧩 如何使用 We Work Remotely Chrome 扩展
- 安装 Thunderbit Chrome 扩展:在 获取,并在 创建账号。
- 打开 We Work Remotely 页面:进入 或 。
- 启用 AI 抓取:点击 AI Suggest Columns 自动生成列名、数据类型以及可选的 Field AI Prompts。你也可以重命名列,或新增如“Seniority(资历)”“Comp Range(如有薪资范围)”等字段。
- 抓取并补全:点击 Scrape 获取列表数据;再用 Scrape Subpages 逐个访问职位链接,抓取完整描述、投递链接等更多细节。
进阶用法: 导出到 Google Sheets 便于协作;或导入 Airtable/Notion,搭建轻量级 ATS 风格的职位数据库。导出免费。
💳 We Work Remotely 抓取的定价说明
Thunderbit 采用简单的积分机制:
- 1 credit = 1 条输出行(结果表中的一行职位记录)。
- AI 驱动的抓取体验包含在内,且数据导出免费(CSV/JSON、Excel、Google Sheets、Airtable、Notion)。
免费可体验内容:
- Free tier: 每月可抓取 6 个页面。
- Free trial: 可免费抓取 10 个页面,适合用来测试“列表抓取 + 子页面补全”的完整流程。
单次运行的典型成本(示例):
- 若你抓取 5 页列表,共得到 80 条职位行,则消耗 80 credits。
- 若你再对这 80 条职位做子页面补全,并为每个职位输出一条补全后的行,通常仍按输出行数计费,因此建议按最终表格中希望保留的职位行数来规划积分。
付费方案(按月/按年)会随使用量扩展;如果你长期稳定抓取,年付通常更划算。详情见 。
| Tier | Pricing (Monthly) | Pricing (Yearly) | Yearly Total Price | Credits (Monthly) | Credits (Yearly) |
|---|---|---|---|---|---|
| Free | Free | Free | Free | 6 pages | N/A |
| Starter | $15 | $9 | $108 | 500 | 5,000 |
| Pro 1 | $38 | $16.5 | $199 | 3,000 | 30,000 |
| Pro 2 | $75 | $33.8 | $398 | 6,000 | 60,000 |
| Pro 3 | $125 | $68.4 | $796 | 10,000 | 120,000 |
| Pro 4 | $249 | $137.5 | $1,592 | 20,000 | 240,000 |
❓ 常见问题(FAQ)
-
什么是 AI Powered We Work Remotely Scraper?
这是 Thunderbit 中的一套 AI 抓取流程,用于从 We Work Remotely 提取职位列表与职位详情,并转换为结构化表格。你可以先抓取列表页,再通过子页面抓取访问职位详情页,为每一行补充更多字段。 -
Thunderbit 是什么?
是一款 AI 网页爬虫 Chrome 扩展,可在无需编程的情况下,从网站、PDF 与图片中提取结构化数据。它面向业务用户,强调快速配置、稳定提取,并可轻松导出到 Google Sheets、Airtable、Notion 等工具。 -
抓取 We Work Remotely 需要会写代码吗?
不需要。你只要点击 AI Suggest Columns,Thunderbit 的 AI 会根据页面内容推荐可提取字段。你可以用自然语言调整列,然后点击 Scrape 即可。 -
Thunderbit 也能抓取职位描述和投递链接吗?
可以。抓取列表页后,使用 Subpage Scraping 打开每条职位详情页,即可提取完整描述、职责、要求以及投递 URL 等字段。尤其当列表页只展示职位名和公司时,这个功能非常实用。 -
We Work Remotely 的分页如何处理?
Thunderbit 支持分页抓取:无论是点击式分页还是长列表滚动加载,都会根据网站结构进行适配。如果职位目录分多页,你可以一次运行抓取多页,并把结果汇总到同一张表中。 -
可以导出哪些数据?能导到哪里?
你可以导出为 CSV/JSON,下载用于 Excel,或直接同步到 Google Sheets、Airtable、Notion。导出免费,便于搭建共享的职位追踪表或可检索数据库。 -
针对招聘网站,Cloud Scraping 和 Browser Scraping 有什么区别?
Cloud Scraping 通常更快,适合批量处理大量公开页面;Browser Scraping 则在你的 Chrome 会话中运行,更适合需要登录或依赖本地会话加载内容的网站。 -
免费计划能抓取多少职位?
免费计划按“页面”计量,而不是按“职位数”:每月可抓取 6 个页面。如果单页包含很多职位,你仍能获得相当可观的数据;也可以开启免费试用抓取 10 个页面 来验证流程。 -
用于招聘或研究,抓取 We Work Remotely 合规吗?
抓取公开网页用于研究与商业情报很常见,但你应遵守适用法律、尊重隐私,并查看网站条款。如果要用于生产级流程,建议设置合理的抓取频率,并负责任地使用数据。
📚 了解更多
- 获取扩展:
- 产品与场景:
- 更多教程:
- 实用指南:
想用 AI 网页爬虫(https://thunderbit.com/)从 We Work Remotely 构建一份干净的远程职位数据集?安装 Thunderbit,打开你关注的职位页面,点击 AI Suggest Columns,再点击 Scrape 即可。