











用 Thunderbit 轻松提取 Telegram 数据
只需两次点击,抓取 Telegram
别再手动复制 Telegram 消息、用户名和时间戳了。Thunderbit 只需两次点击即可提取数据。你只要指向所需内容——例如消息文本、发送者 ID、频道名称——AI 就会自动完成其余工作。获取所需的 Telegram 数据,无需复杂设置,也不需要编程。

一款爬虫,适用于 Telegram 以及更多场景
Telegram 只是众多数据来源之一。与其为每个网站单独购买爬虫,不如直接使用 Thunderbit 的通用爬虫。我们提供 50 多个预设模板,帮助你快速上手;同时,AI 还能开箱即用地从几乎任何网站、文档或图片中抓取发送者用户名、消息 ID 等数据。
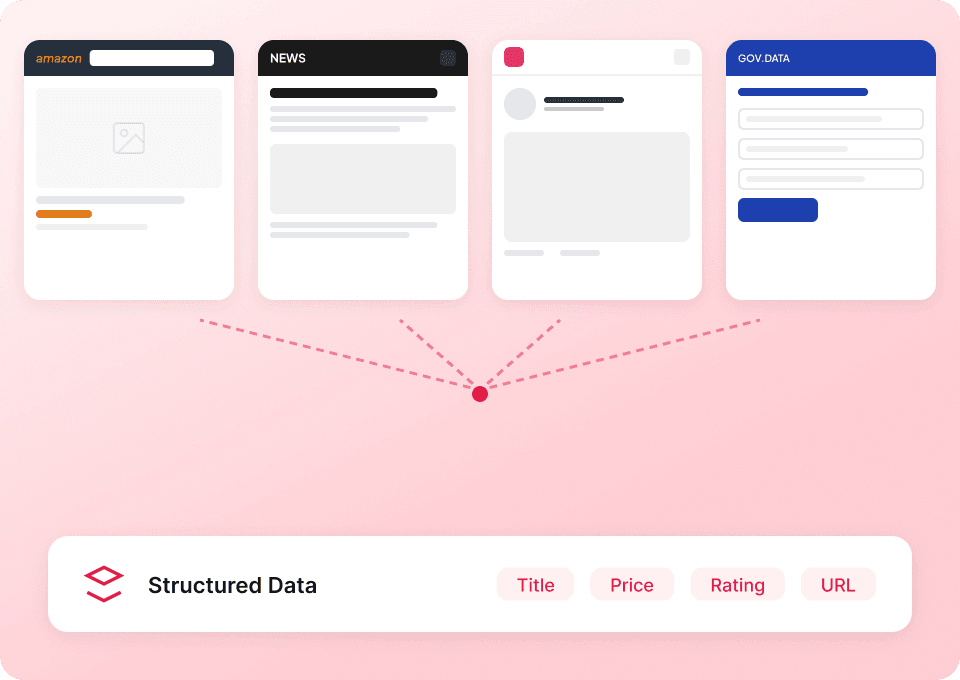
自动化采集 Telegram 数据,持续运行
Telegram 频道内容更新非常快,别再每天手动重复抓取同一个频道了。使用 Thunderbit,你可以设置定时任务,自动提取 Telegram 的消息文本、时间戳和其他数据。新鲜数据会直接送到 Google Sheets、Notion 或 Airtable,几乎无需任何操作。
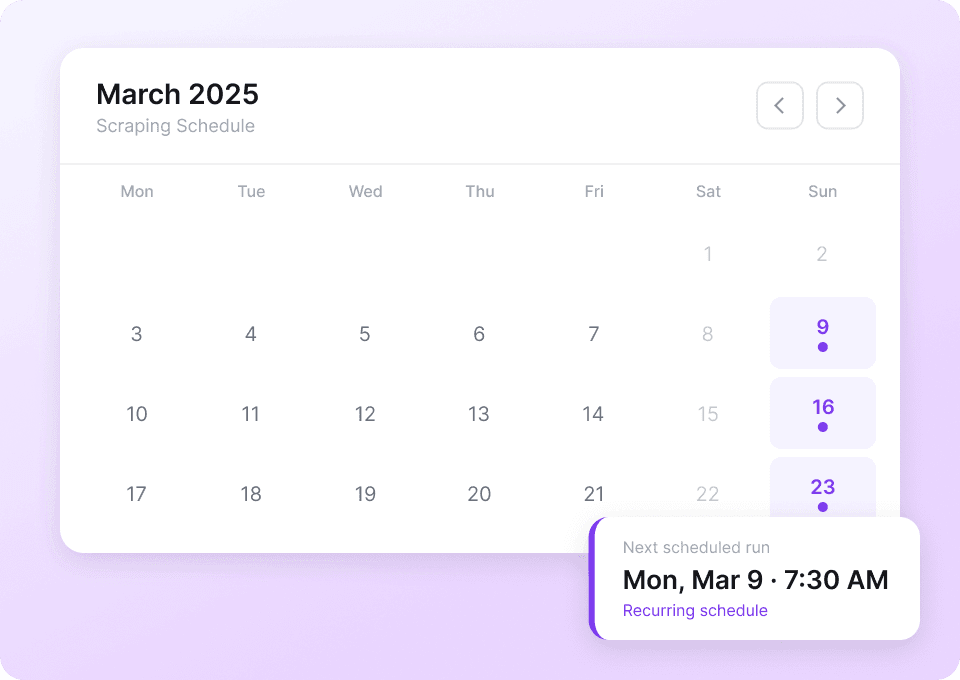
还在为高效抓取 Telegram 发愁?
看看与传统方法相比,Thunderbit 如何让 Telegram 抓取变得更简单。
传统爬虫
老派做法Thunderbit
更聪明的方案





常见问题
相关 应用场景
探索 Thunderbit 网页爬虫的更多应用场景。

ReverseAustralia 爬虫
Thunderbit ReverseAustralia 爬虫可帮助您从 ReverseAustralia 的投诉和评论页面提取数据。借助 AI 智能字段推荐,快速收集电话号码、投诉内容、评论文本、用户名等信息,便于分析与研究。非常适合市场营销人员、研究者及企业获取结构化反馈数据。
了解更多 ->PeopleWhiz 爬虫
Thunderbit PeopleWhiz 爬虫可借助 AI 字段建议,从 PeopleWhiz 的搜索结果和个人资料中提取数据。轻松收集姓名、联系方式、位置等信息,用于研究、营销或线索开发。快速高效地将 PeopleWhiz 数据整理为结构化数据集。
了解更多 ->
HKTVmall 爬虫
只需 2 次点击,即可从 HKTVmall 商品列表中提取商品名称、价格、评分等信息,无需编写代码。数据可直接导出到 Excel、Google Sheets 或 Notion,把 HKTVmall 数据快速转化为可执行的洞察。
了解更多 ->
贴吧爬虫
Thunderbit 贴吧爬虫可帮助你从百度贴吧提取数据,包括热门话题和论坛分类。借助 AI 智能字段推荐,快速获取话题名称、链接、帖子数和用户活跃度,无论是做调研、营销还是内容创作都非常高效。非常适合分析贴吧上的社交趋势与讨论动态。
了解更多 ->Substack 爬虫
只需 2 次点击,即可抓取 Substack 的订阅人数、文章标题和发布简介,并导出到 Excel、Google Sheets 或 Notion。无需编写代码,Thunderbit 的 AI 会自动帮你整理好数据结构。
了解更多 ->
Amarillas.com 爬虫
Thunderbit 的 Amarillas.com 爬虫可帮助你从 Amarillas.com 提取结构化数据,包括汽车旅馆和餐厅等商家信息。借助 AI 智能字段推荐,快速收集商家名称、地址、联系电话、评分和评论,助力市场调研、营销推广或销售线索获取。
了解更多 ->准备好让数据提取全面提速了吗?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
免费试用可为 8 个网页提供无限额度。



