

Reddit 帖子爬虫是一款高效工具,能够自动采集 Reddit 帖子的详细信息。通过这个预设爬虫模板,用户可以轻松获取帖子标题、发帖人、社区详情,以及评论数、点赞数等互动数据。
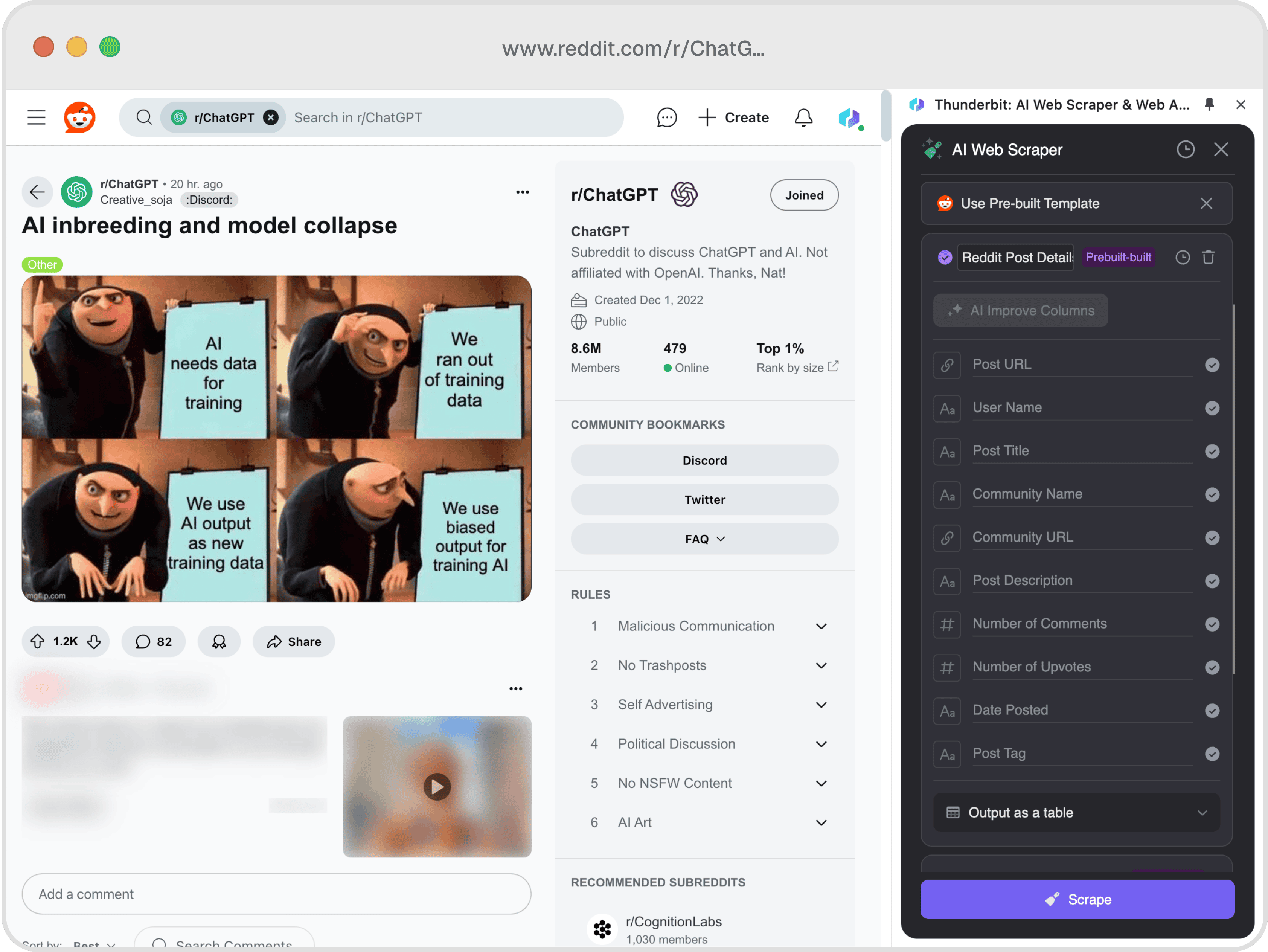
📊 字段说明
| 字段 | 说明 |
|---|---|
| 🔗 帖子链接 | Reddit 帖子的直接访问链接。 |
| 👤 用户名 | 发帖用户的名称。 |
| 📝 帖子标题 | Reddit 帖子的标题。 |
| 🌐 社区名称 | 发帖所在的子版块(subreddit)名称。 |
| 🔗 社区链接 | 子版块的访问链接。 |
| 📝 帖子内容 | 帖子的正文或描述。 |
| 💬 评论数 | 该帖子的总评论数。 |
| 👍 点赞数 | 该帖子获得的总点赞数。 |
| 📅 发布时间 | 帖子发布的日期。 |
| 🏷️ 帖子标签 | 与帖子相关的标签。 |
🤔 为什么要抓取 Reddit 数据?
抓取 Reddit 数据能为各类专业人士带来丰富的洞察:
- 市场营销人员:分析热门趋势、追踪用户情绪、发现新话题,优化营销策略和活动。
- 研究人员:收集大规模数据集,分析公众观点,挖掘细分领域的讨论内容,助力学术或行业研究。
- 内容创作者:获取灵感,洞察受众偏好,基于热门话题策划内容。
- 产品经理/开发者:了解用户反馈、痛点和功能需求,助力产品优化。
- 社交媒体分析师:监控子版块动态,追踪品牌提及、竞品分析或社区活跃度。
通过抓取 Reddit,你可以高效获取并分析数据,助你做出更明智的决策,始终走在行业前沿。🚀
🛠️ Reddit 帖子爬虫使用指南
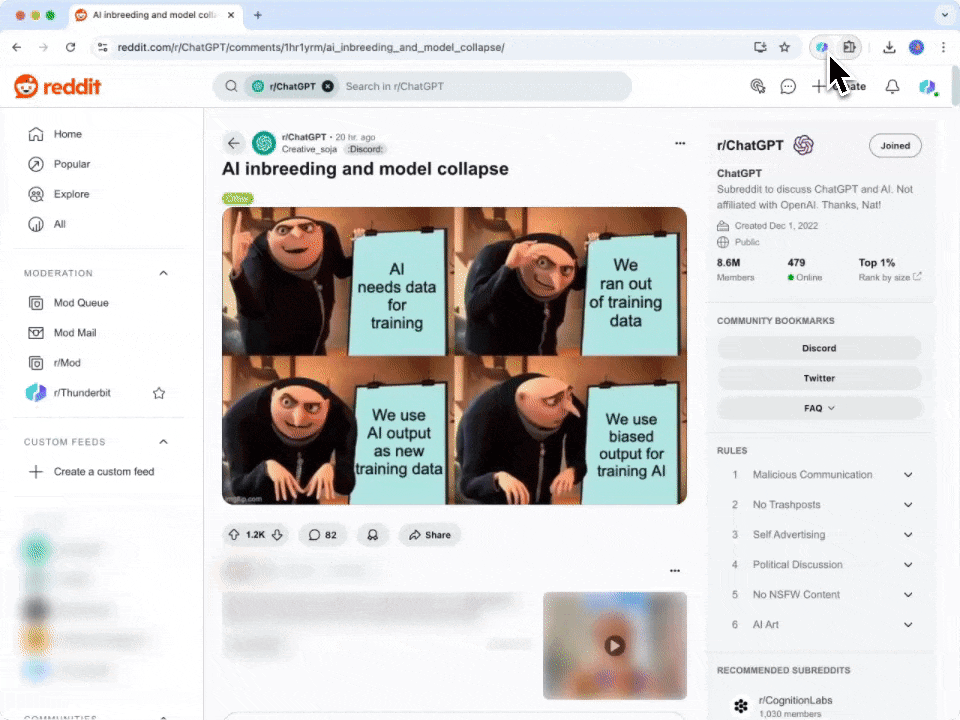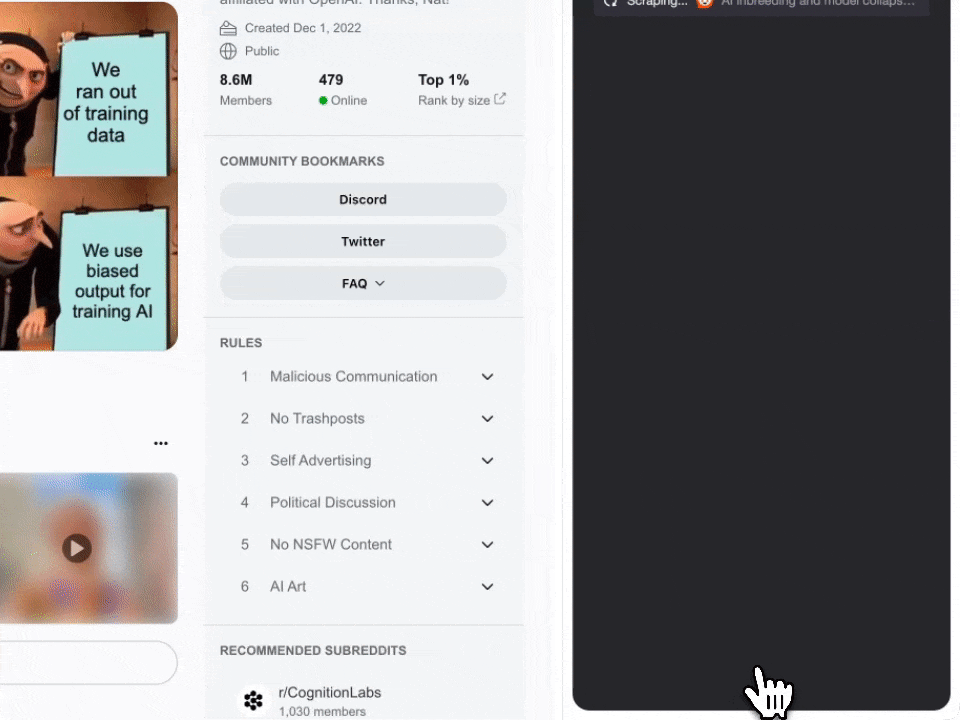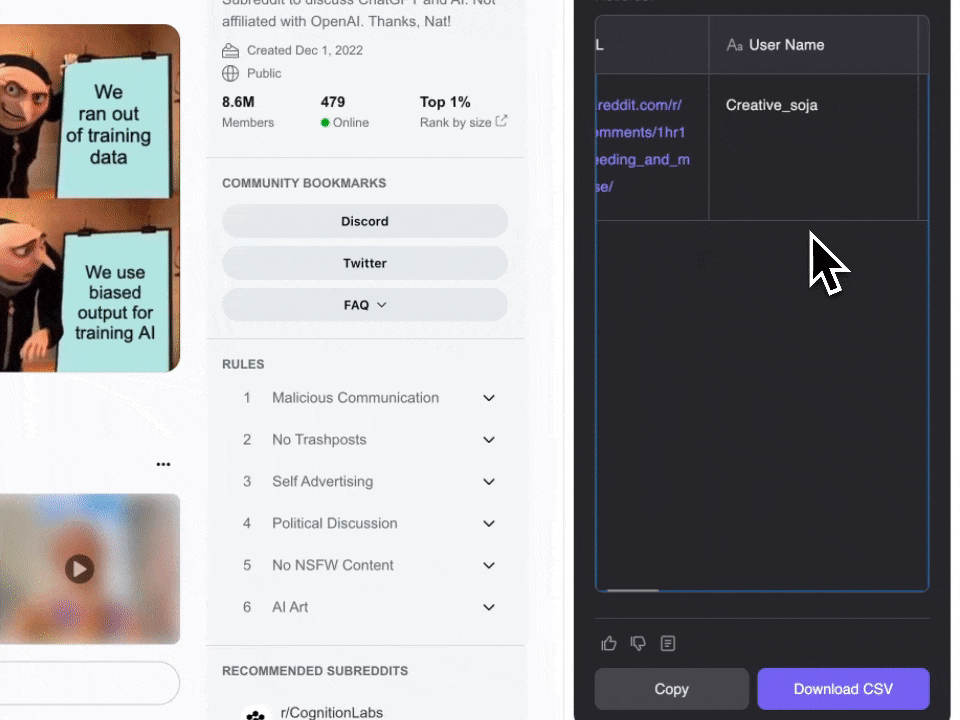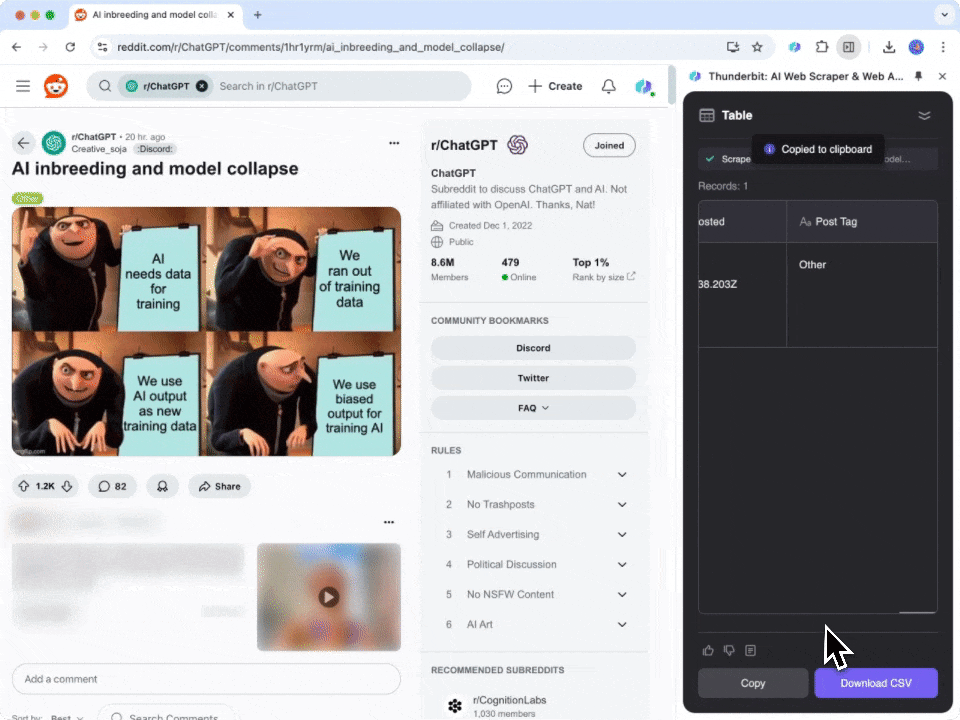
- 下载安装:首先,下载 并注册账号。
- 访问 Reddit:前往你想要抓取的 或子版块页面。
- 启动爬虫:页面会弹出提示,建议你使用预设的 Reddit 帖子爬虫模板。点击即可开始。注意,该功能属于付费计划,但你可以先免费试用,体验其强大功能。
💰 Reddit 帖子爬虫的费用
Reddit 帖子爬虫采用积分计费,每运行一次消耗 1 积分。Thunderbit 免费试用期间,你最多可免费抓取 10 个页面。每个积分对应一行输出数据,方便你灵活管理和预估成本。
🤖 还可以用 AI 快速抓取 Reddit
借助 Thunderbit 的 ,你只需两步即可抓取 Reddit 数据。AI 工具具备自动整理和分类数据的能力,适合需要快速获取结构化数据的用户。与预设爬虫不同,AI 网页爬虫可适应不同页面结构,灵活性更高,操作更便捷。
❓ 常见问题
- 什么是预设网页爬虫?
预设网页爬虫是一种即开即用的工具,无需自定义配置即可抓取特定网站的数据。它为常见的数据采集任务提供了模板,让用户无需技术背景或编程知识也能轻松上手。 - Thunderbit 是什么?
Thunderbit 是一款 Chrome 插件,帮助用户通过 AI 自动化网页任务,如数据抓取、表单填写和内容摘要。它专为提升效率而设计,让重复性在线操作变得简单高效,无论新手还是专业人士都能轻松使用。 - Reddit 帖子爬虫如何工作?
Reddit 帖子爬虫基于预设模板自动提取 Reddit 帖子数据。用户只需打开目标页面,爬虫即可自动采集所需信息,无需手动整理,极大提升工作效率。 - Reddit 帖子爬虫可以免费用吗?
可以,Thunderbit 提供免费试用,允许用户最多抓取 10 个页面,零风险体验其功能。试用结束后,如需无限量抓取,则需订阅付费计划。 - Reddit 帖子爬虫能提取哪些数据?
你可以提取帖子标题、用户名、社区信息、评论数、点赞数等多种数据。这些丰富的数据可用于分析、研究或内容创作。 - Reddit 帖子爬虫抓取的数据准确吗?
是的,爬虫会根据预设模板准确采集 Reddit 帖子数据,确保结果可靠一致,是你数据采集的得力助手。 - 如何管理 Thunderbit 的积分?
积分用于衡量你可抓取的数据量。每运行一次 Reddit 帖子爬虫消耗 1 积分。 你可以在 Thunderbit 账户后台轻松管理积分,查看使用情况、购买更多积分,并合理规划采集任务。 - Reddit 帖子爬虫可以自定义数据字段吗?
预设爬虫的数据字段是固定的,适用于常见场景。如果你需要更灵活的自定义,可以使用 Thunderbit 的 AI 网页爬虫,根据你的需求自定义采集内容。
📚 了解更多
想进一步了解 Thunderbit 及其功能,请访问 ,或前往 获取更多教程和实用技巧。