Pixiv 爬虫
深受领先企业专业人士信赖












让 Pixiv 数据抓取变得简单
无需手动复制粘贴,就能提取 Pixiv 的标题、作者和栏目详情等数据。
批量抓取 Pixiv 数据,轻松扩展规模
手动逐页收集 Pixiv 数据很快就会变得很慢,尤其是当你需要几十或几百个标题、文章摘要、作者、发布日期、新闻来源和栏目时。Thunderbit 允许你一次性抓取一批网址,让你从少量页面快速扩展到大量 Pixiv 记录,而不会把时间浪费在重复劳动上。

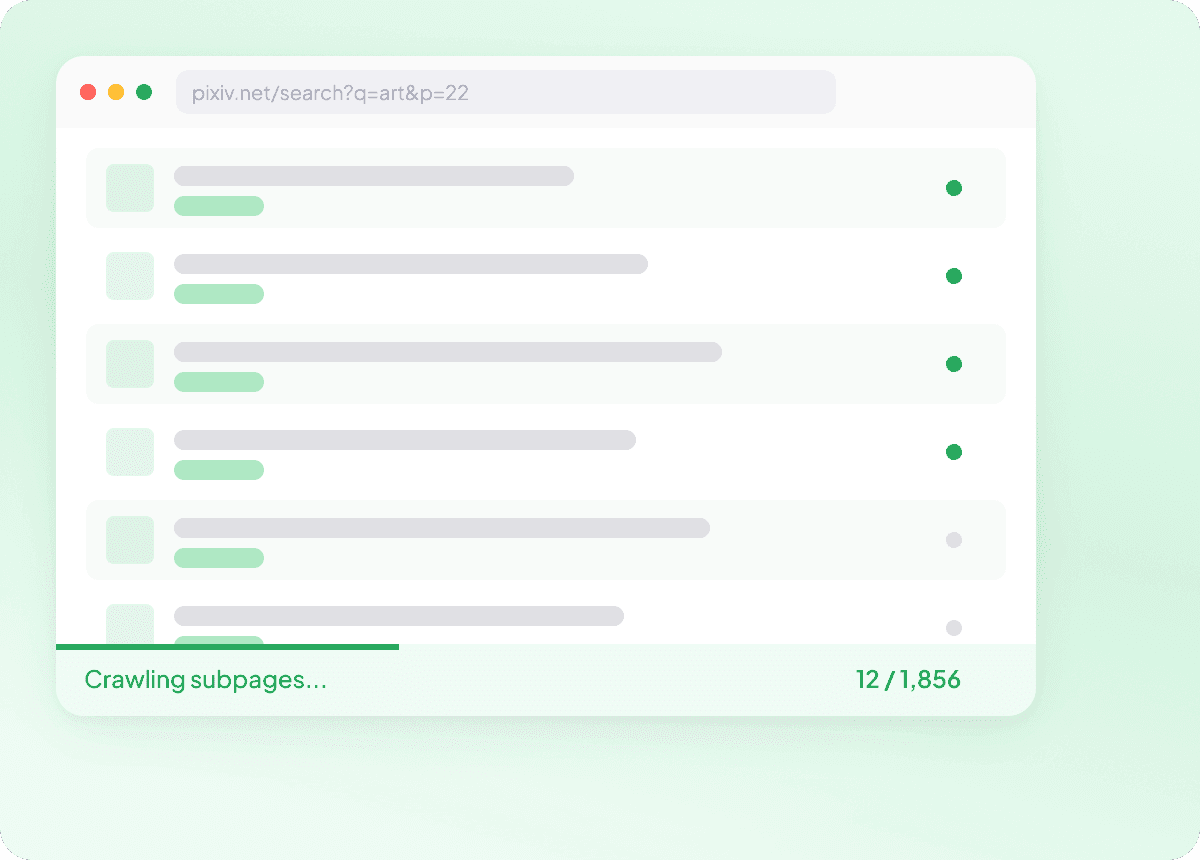
完整抓取 Pixiv 子页面详情
Pixiv 的列表页通常只显示基础信息,而真正的细节往往藏在每篇文章或帖子对应的子页面里。Thunderbit 会访问每一个链接的子页面并抓取完整内容,为你返回更丰富的数据,例如文章摘要、作者、发布日期、新闻来源和栏目,结构也更清晰。
让 Pixiv 数据自动保持最新
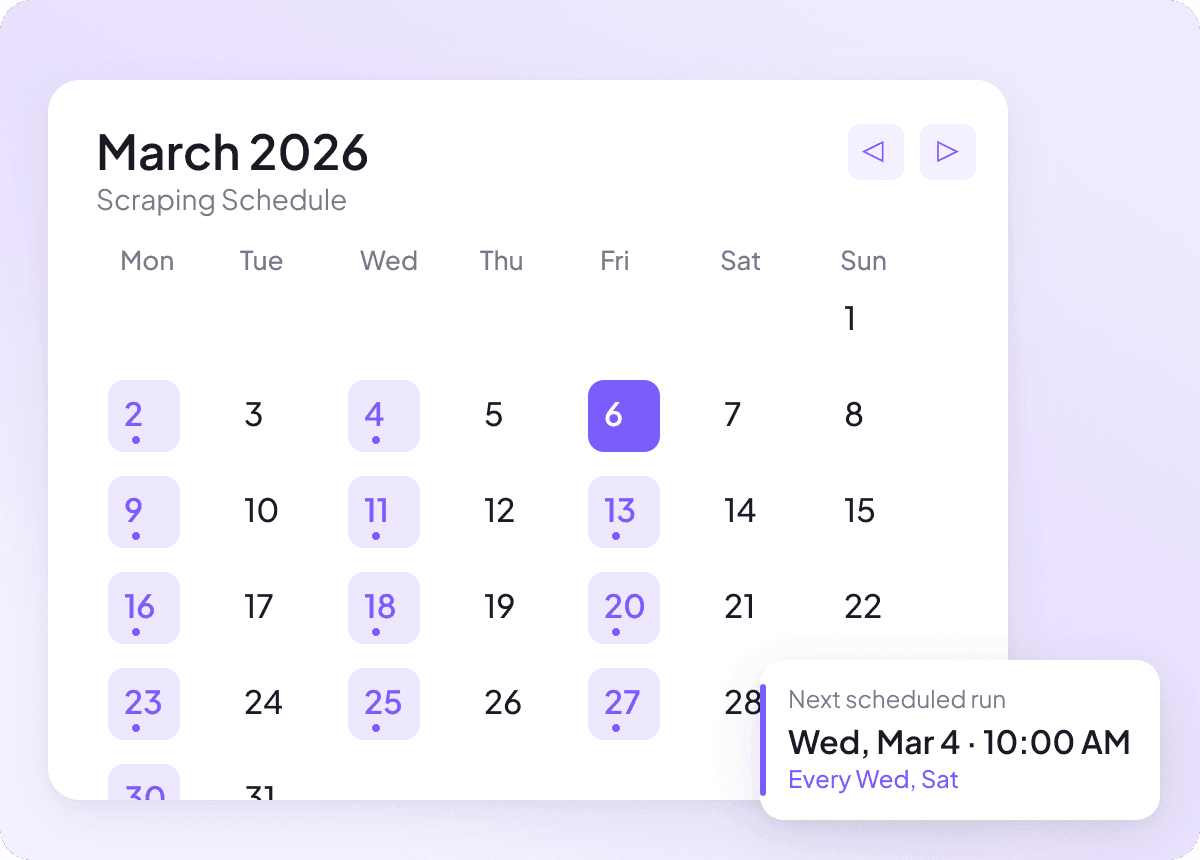
Pixiv 内容每天都可能变化,靠人工跟进意味着要一遍又一遍地查看同样的页面。使用定时抓取后,Thunderbit 会自动运行,并按固定周期把最新的 Pixiv 数据送到你的表格里,让你对标题、作者和栏目等内容的追踪始终保持最新,无需手动操作。
为什么 Thunderbit 与传统的 Pixiv 爬虫不同?
一种更简单的 Pixiv 抓取方式,不需要脆弱的选择器,也不用费力清理数据。
传统爬虫
过去的做法Thunderbit AI
更聪明的方式别只听我们说
看看用户如何评价 Thunderbit。







常见问题
相关 用例
探索 Thunderbit 网页爬虫的更多用例。

白页爬虫
Thunderbit White Pages 爬虫借助 AI 智能字段识别,帮助你高效提取 White Pages 上的电话和商家信息。只需几次点击,即可批量获取姓名、电话号码、地址和网址,助力线索收集、市场营销或数据调研。
了解更多 ->Substack 爬虫
将 Substack 的订阅人数、文章标题和出版物描述整理成干净的电子表格——无需代码,AI 会自动完成结构化处理。
了解更多 ->
Amarillas.com 爬虫
Thunderbit 的 Amarillas.com 爬虫可帮助你从 Amarillas.com 提取结构化数据,包括汽车旅馆和餐厅等商家信息。借助 AI 智能字段推荐,快速收集商家名称、地址、联系电话、评分和评论,助力市场调研、营销推广或销售线索获取。
了解更多 ->
贴吧爬虫
Thunderbit 贴吧爬虫可帮助你从百度贴吧提取数据,包括热门话题和论坛分类。借助 AI 智能字段推荐,快速获取话题名称、链接、帖子数和用户活跃度,无论是做调研、营销还是内容创作都非常高效。非常适合分析贴吧上的社交趋势与讨论动态。
了解更多 ->
iBegin 爬虫
Thunderbit 的 iBegin 爬虫可帮助你从 iBegin 网站提取商家搜索结果及详细信息。借助 AI 智能字段推荐,快速收集商家名称、联系方式、地址、评分等数据,助力获客、市场调研或营销分析。
了解更多 ->
People-Search 爬虫
Thunderbit People-Search 爬虫可帮助您从 People-Search 个人资料和电话反查页面提取结构化数据。借助 AI 智能字段推荐,快速收集姓名、地址、电话号码、邮箱等信息,适用于调研、营销或获客。非常适合需要获取公开记录和联系方式的市场人员、研究者及企业。
了解更多 ->准备好让数据提取全面提速了吗?
加入 100,000+ 已在使用 Thunderbit 自动化网页抓取流程的专业人士行列。
免费试用可为 8 个网页提供无限额度。