
Thunderbit AI 驱动的 namu.wiki 爬虫 是一款专为从 namu.wiki 精确且轻松提取数据而设计的工具。通过使用 ,用户可以将网站内容转换为结构化数据集,只需两次点击即可导出数据。
📚 什么是 namu.wiki 爬虫
爬虫是一种 AI 网页爬虫,允许用户使用人工智能从 namu.wiki 网站抓取数据。用户只需导航到 ,点击 AI 推荐列 按钮和 抓取 按钮,即可高效提取有价值的数据。
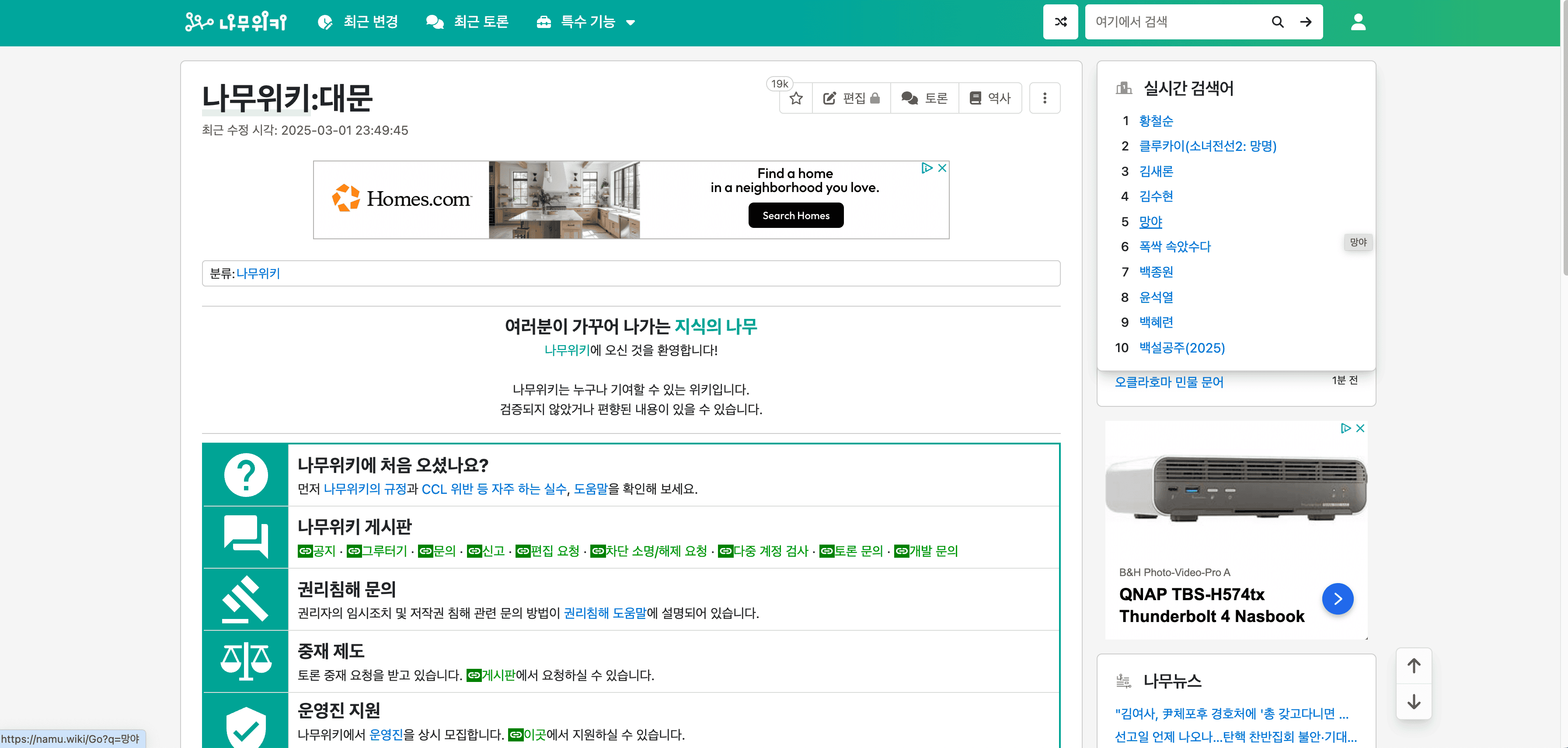
🔍 namu.wiki 爬虫可以抓取什么
📄 抓取 NamuWiki 需要的页面列表页
AI 驱动的 namu.wiki 爬虫 使用户能够从 提取详细信息。此功能非常适合收集有关需要创建或更新内容的页面的见解。
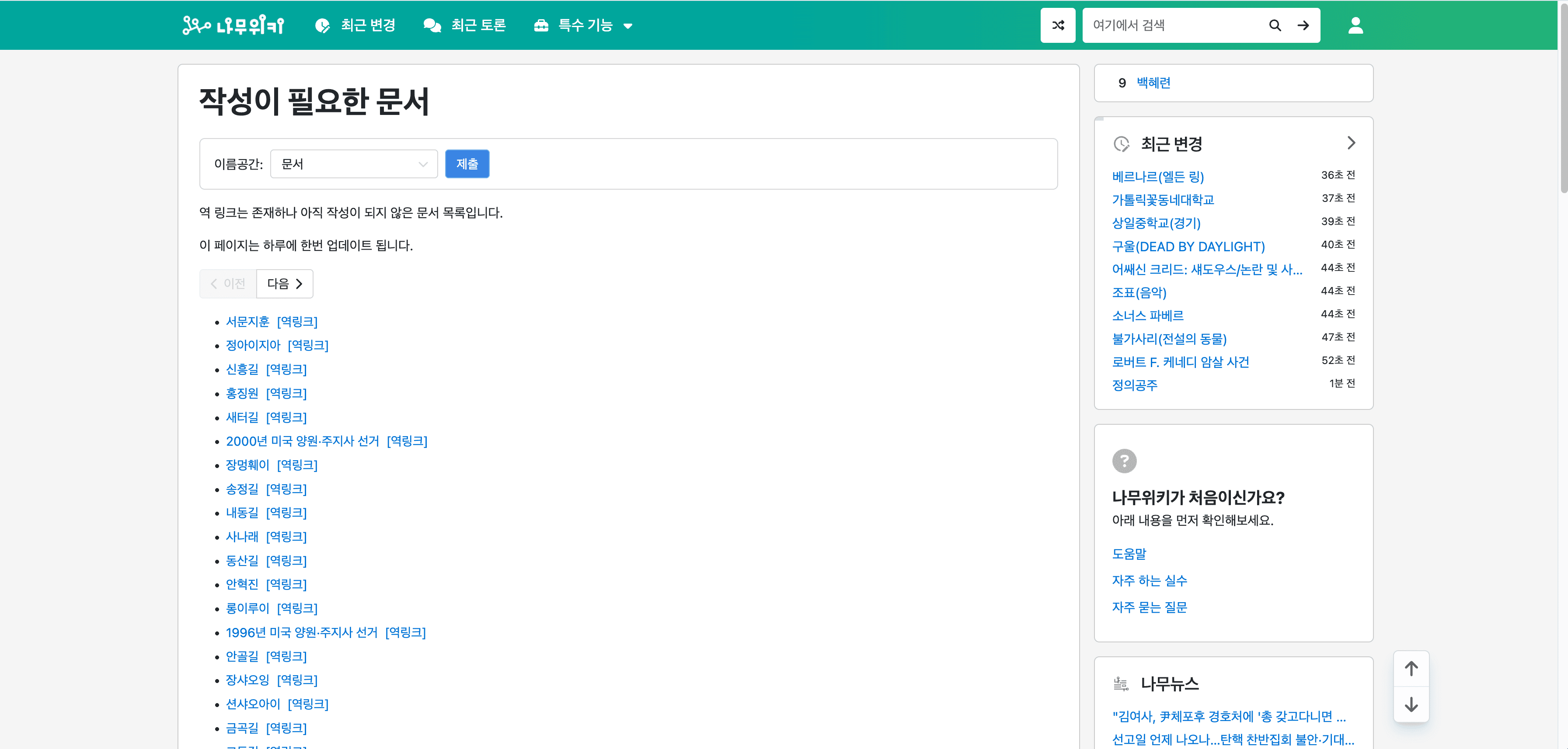
步骤:
- 下载 并注册一个账户。
- 前往目标页面,例如:。
- 点击 AI 推荐列,AI 将读取网页并推荐列名。
- 点击 抓取 运行爬虫,获取数据并下载文件。
列名
| 列 | 描述 |
|---|---|
| 📄 页面标题 | 需要的页面的标题。 |
| 🔗 页面链接 | 需要的页面的链接。 |
| 📅 最后编辑 | 页面最后编辑的日期。 |
| ✍️ 编辑者 | 最后编辑者的用户名。 |
💬 抓取 NamuWiki 最近讨论页面
AI 驱动的 namu.wiki 爬虫 还允许用户从 提取信息。此功能非常适合监控正在进行的讨论和社区互动。
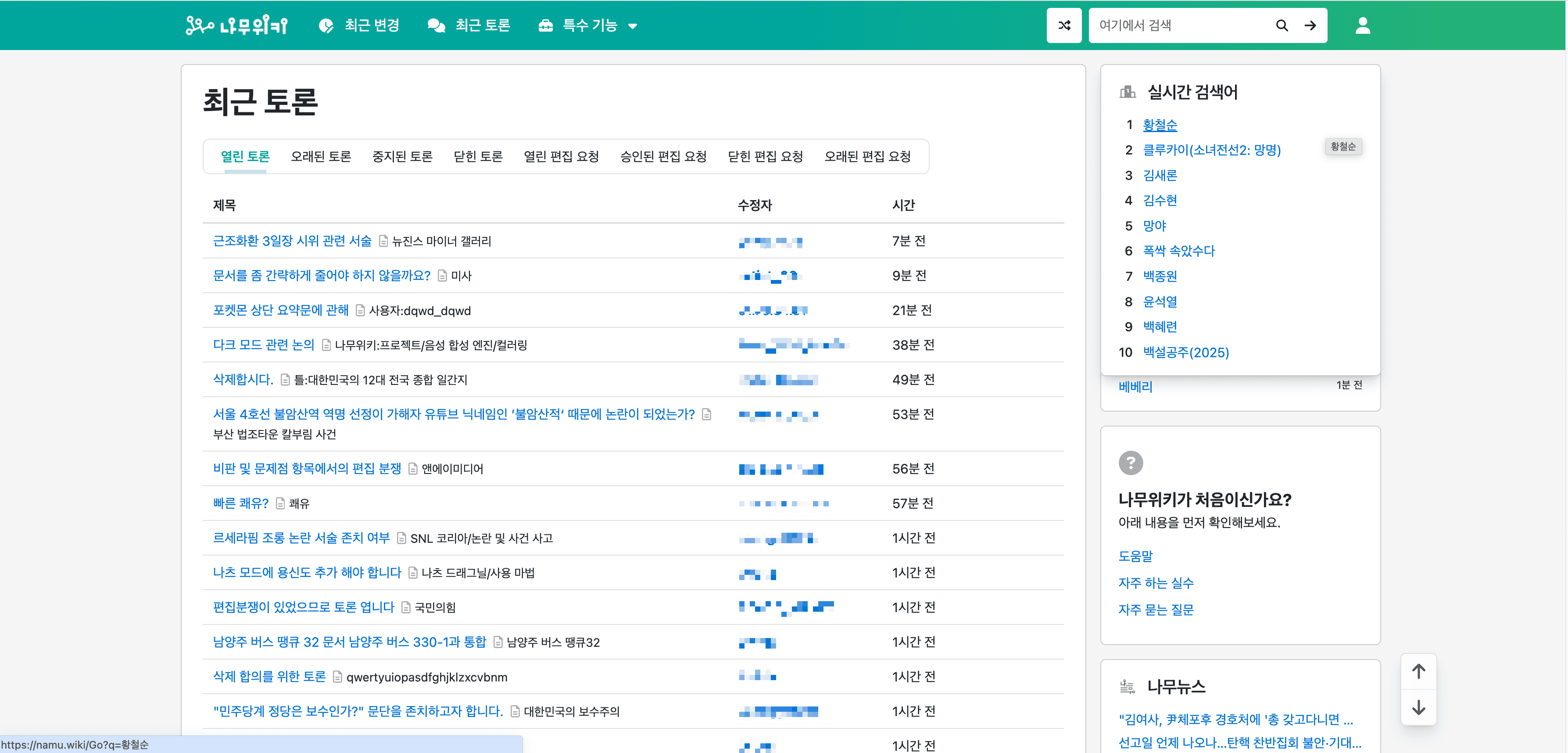
步骤:
- 下载 并注册一个账户。
- 前往目标页面,例如:。
- 点击 AI 推荐列,AI 将读取网页并推荐列名。
- 点击 抓取 运行爬虫,获取数据并下载文件。
列名
| 列 | 描述 |
|---|---|
| 💬 讨论主题 | 讨论的主题。 |
| 🔗 讨论链接 | 讨论页面的链接。 |
| 🕒 最后活动 | 讨论中最后活动的时间戳。 |
| 👤 参与者 | 讨论中参与者的用户名。 |
🤔 为什么使用 namu.wiki 工具
抓取 namu.wiki 可以为各种目的提供有价值的见解:
- 研究人员:分析内容差距和社区互动。
- 内容创作者:识别需要创建内容的页面。
- 社区经理:监控讨论并与社区互动。
- 企业:提取结构化数据用于市场研究和分析。
通过提取准确且组织良好的数据,你可以做出数据驱动的决策并解锁新的机会。
🛠️ 如何使用 namu.wiki Chrome 扩展程序
- 安装 Thunderbit Chrome 扩展程序:下载扩展程序并注册你的账户。
- 导航到需要的页面或最近讨论页面:前往你想要抓取的 namu.wiki 页面。
- 激活 AI 驱动的爬虫:点击 AI 推荐列 生成列名或自定义列以满足你的需求。
💰 namu.wiki 爬虫的定价
Thunderbit 采用基于信用的系统,其中 1 个信用等于 1 行抓取的数据。该工具可以免费试用,额外的计划为偶尔和高容量用户提供灵活性。
计划:
| 等级 | 月费 | 年费 | 年总费用 | 每月信用 | 每年信用 |
|---|---|---|---|---|---|
| 免费 | 免费 | 免费 | 免费 | 6 页 | N/A |
| 入门 | $15 | $9 | $108 | 500 | 5,000 |
| 专业 1 | $38 | $16.5 | $199 | 3,000 | 30,000 |
| 专业 2 | $75 | $33.8 | $406 | 6,000 | 60,000 |
| 专业 3 | $125 | $68.4 | $821 | 10,000 | 120,000 |
| 专业 4 | $249 | $137.5 | $1,650 | 20,000 | 240,000 |
免费功能:
- 每月 6 页 在免费计划中。
- 免费试用 提供 10 页免费,非常适合探索爬虫的功能。
❓ 常见问题
-
什么是 AI 驱动的 namu.wiki 爬虫?
AI 驱动的 namu.wiki 爬虫是一款专门设计用于从 namu.wiki 的需要页面和最近讨论中提取详细信息的工具。它通过利用 Thunderbit 的 Chrome 扩展程序简化数据收集,使用户能够快速轻松地收集结构化数据用于研究、内容创建或分析,而无需技术专长。
-
什么是 Thunderbit?
Thunderbit 是一款尖端的 Chrome 扩展程序,利用人工智能简化网页抓取、数据提取和自动化任务。它允许用户从网站抓取数据,自定义列,自动填写在线表单,并总结内容。Thunderbit 通过使繁琐的基于网页的任务更快、更简单、更准确,迎合了市场营销、电子商务、研究等领域的专业人士。
-
免费试用可以抓取多少页面?
使用 Thunderbit 的免费试用,你可以免费抓取多达 10 页。这使用户能够探索工具的功能,并决定它是否满足他们的数据提取需求,然后再升级到付费计划。
-
我可以自定义要抓取的列和数据字段吗?
当然可以!Thunderbit 提供强大的自定义选项,让你指定要提取的确切数据字段。从页面详细信息如标题、链接和最后编辑日期到讨论数据如主题、链接和参与者姓名,爬虫可以根据你的要求进行调整。
-
我可以多频繁地运行爬虫?
运行爬虫的频率取决于你的订阅计划和账户中的信用数量。更高等级的计划包括更多的信用,允许进行更大规模或更频繁的数据提取。需要持续访问工具的用户可以升级到高级计划以获得不间断的使用。
-
如果我用完了信用怎么办?
如果你用完了信用,可以轻松按需购买额外的信用或升级到更高等级的订阅计划。这确保你在需要时可以持续访问爬虫的功能。
-
抓取 namu.wiki 页面和讨论是否合法?
从 namu.wiki 抓取公开可访问的数据通常是允许的,只要你遵守适用法律,尊重隐私权,并避免违反 namu.wiki 的服务条款。使用数据时务必负责任,并确保遵守所有相关法规以避免潜在问题。
-
我可以从 namu.wiki 提取哪些类型的数据?
你可以从 namu.wiki 提取多种数据,包括页面标题、链接、最后编辑日期、讨论主题和参与者姓名。这些数据可用于分析、内容创建和社区参与,为平台的内容和互动提供有价值的见解。
-
我如何确保抓取的数据准确且最新?
Thunderbit 的 AI 驱动爬虫旨在通过持续分析网站的结构和内容来提供准确且最新的数据。然而,始终建议手动验证数据并与其他来源交叉参考,以确保其准确性和相关性。
📖 了解更多
有关网页抓取和如何有效使用 Thunderbit 的更多信息,请访问我们的 并探索文章如 和 。