Flickr 爬虫
深受领先企业专业人士信赖












两步提取 Flickr 数据
Thunderbit 让 Flickr 数据提取变得更简单,无需编程。
两步完成 Flickr 数据提取
手动复制 Flickr 上的照片标题、作者用户名或上传日期既耗时又繁琐。Thunderbit 让你跳过复制粘贴的麻烦。只要把鼠标指向你想提取的数据——比如照片描述或许可类型——我们的 AI 就会自动处理剩下的部分。只需两次点击,就能完成数据抓取,而且完全不用写代码。
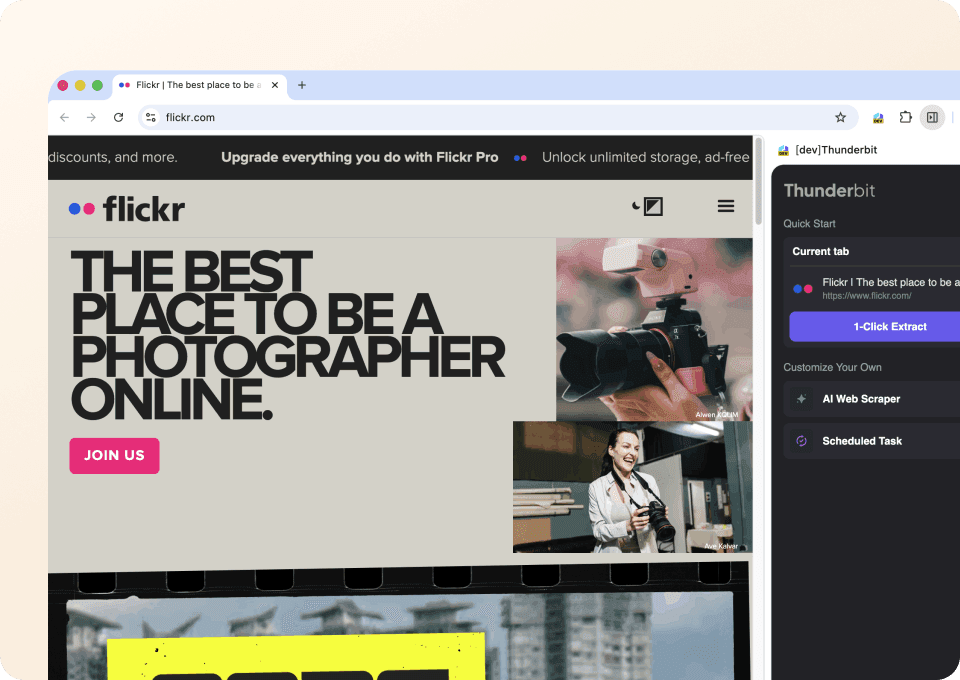
获取完整的 Flickr 照片详情
Flickr 的搜索页或相册页通常只显示基础信息。要获取完整内容,你需要进入每张照片的详情页。Thunderbit 可以自动访问这些链接的子页面,抓取描述、标签和其他详细信息,并在导出结果中将它们作为新列追加进去。再也不用手动逐页点击和复制了。
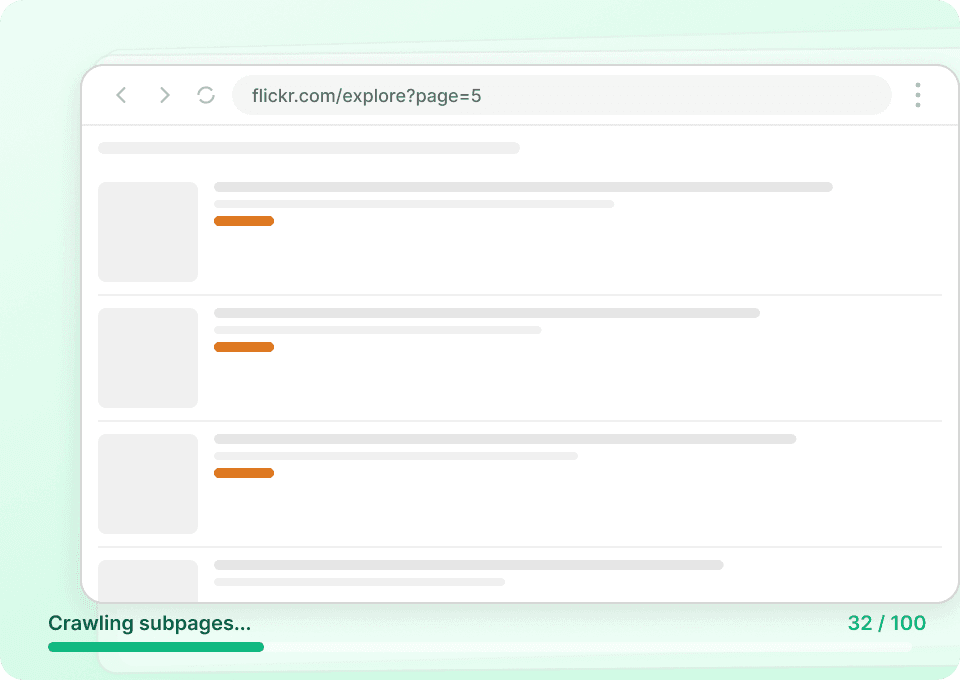
批量提取 Flickr 数据
一张一张抓取 Flickr 照片既慢又不实用。与其手动打开每个页面并提取数据,不如直接输入多个 Flickr URL。Thunderbit 会自动访问这些页面,提取照片标题、作者用户名以及其他数据点,并为你统一整理好。

为什么 Thunderbit 与传统的 flickr 爬虫 不一样?
无需忍受传统抓取带来的麻烦,也能从 Flickr 高效提取数据。
传统爬虫
旧式做法Thunderbit AI
更智能的方式别只听我们说
看看用户如何评价 Thunderbit。






常见问题
相关 用例
探索 Thunderbit 网页爬虫的更多用例。

TripAdvisor 商业列表爬虫
Thunderbit TripAdvisor 商家列表爬虫可帮助你从 TripAdvisor 的商家列表、资源中心和业主论坛中提取数据。借助 AI 智能字段推荐,快速收集资源名称、网址、描述、论坛话题、作者及帖子内容,助力调研、营销或数据分析。
了解更多 ->
白页爬虫
Thunderbit White Pages 爬虫借助 AI 智能字段识别,帮助你高效提取 White Pages 上的电话和商家信息。只需几次点击,即可批量获取姓名、电话号码、地址和网址,助力线索收集、市场营销或数据调研。
了解更多 ->PeopleWhiz 爬虫
Thunderbit PeopleWhiz 爬虫可借助 AI 字段建议,从 PeopleWhiz 的搜索结果和个人资料中提取数据。轻松收集姓名、联系方式、位置等信息,用于研究、营销或线索开发。快速高效地将 PeopleWhiz 数据整理为结构化数据集。
了解更多 ->
ReverseAustralia 爬虫
Thunderbit ReverseAustralia 爬虫可帮助您从 ReverseAustralia 的投诉和评论页面提取数据。借助 AI 智能字段推荐,快速收集电话号码、投诉内容、评论文本、用户名等信息,便于分析与研究。非常适合市场营销人员、研究者及企业获取结构化反馈数据。
了解更多 ->
UNIQLO 爬虫
借助 Thunderbit 的 Chrome 扩展,只需 2 次点击,即可抓取 UNIQLO 商品数据,包括商品名称、价格和可选尺码。
了解更多 ->
UpCity 爬虫
Thunderbit UpCity 爬虫可帮助你从 UpCity 的广告代理机构列表和服务商评论中提取数据。借助 AI 智能字段推荐,快速收集机构名称、所在地、评分、联系方式及详细评论内容,便于分析与研究。非常适合需要结构化 UpCity 数据的市场营销人员、研究者和企业主。
了解更多 ->准备好让数据提取全面提速了吗?
加入 100,000+ 已在使用 Thunderbit 自动化网页抓取流程的专业人士行列。
免费试用可为 8 个网页提供无限额度。