Thunderbit 的 FlexJobs 爬虫 可通过 AI 将 FlexJobs 页面整理成干净、结构化的数据集。你既能抓取远程职位列表,也能抓取职业建议文章;随后再用 子页面抓取 为每一行补充完整的职位详情或文章全文。通过 ,几分钟内即可导出到 Excel、Google Sheets、Airtable 或 Notion。
🤖 什么是 FlexJobs 爬虫
AI 驱动的 FlexJobs 爬虫 是一款 ,可从 提取数据并自动整理成表格,支持下载或同步到你的常用工具。操作很简单:打开你要抓取的页面(例如职位目录或博客),点击 AI Suggest Columns,再点击 Scrape 即可。
它面向真实业务场景:你往往需要的不止是列表页上“看得到”的信息。借助 子页面抓取,Thunderbit 会自动访问每个职位详情页或文章页,把更多字段(如完整描述、任职要求、分类、作者等)回填到同一份数据集中。
🧲 你可以从 FlexJobs 抓取哪些内容
FlexJobs 常用于寻找 远程工作、混合办公岗位 与 灵活用工机会,同时也提供丰富的职业资源。使用 Thunderbit,你可以同时抓取职位列表与内容页面,用于调研、线索挖掘、招聘运营以及内容分析等场景。
🧑💻 抓取 FlexJobs 远程职位列表
在 抓取职位目录页,快速搭建包含岗位、公司与职位元数据的结构化数据库。随后再抓取每个职位的子页面,补全完整职位描述、任职要求与申请信息。
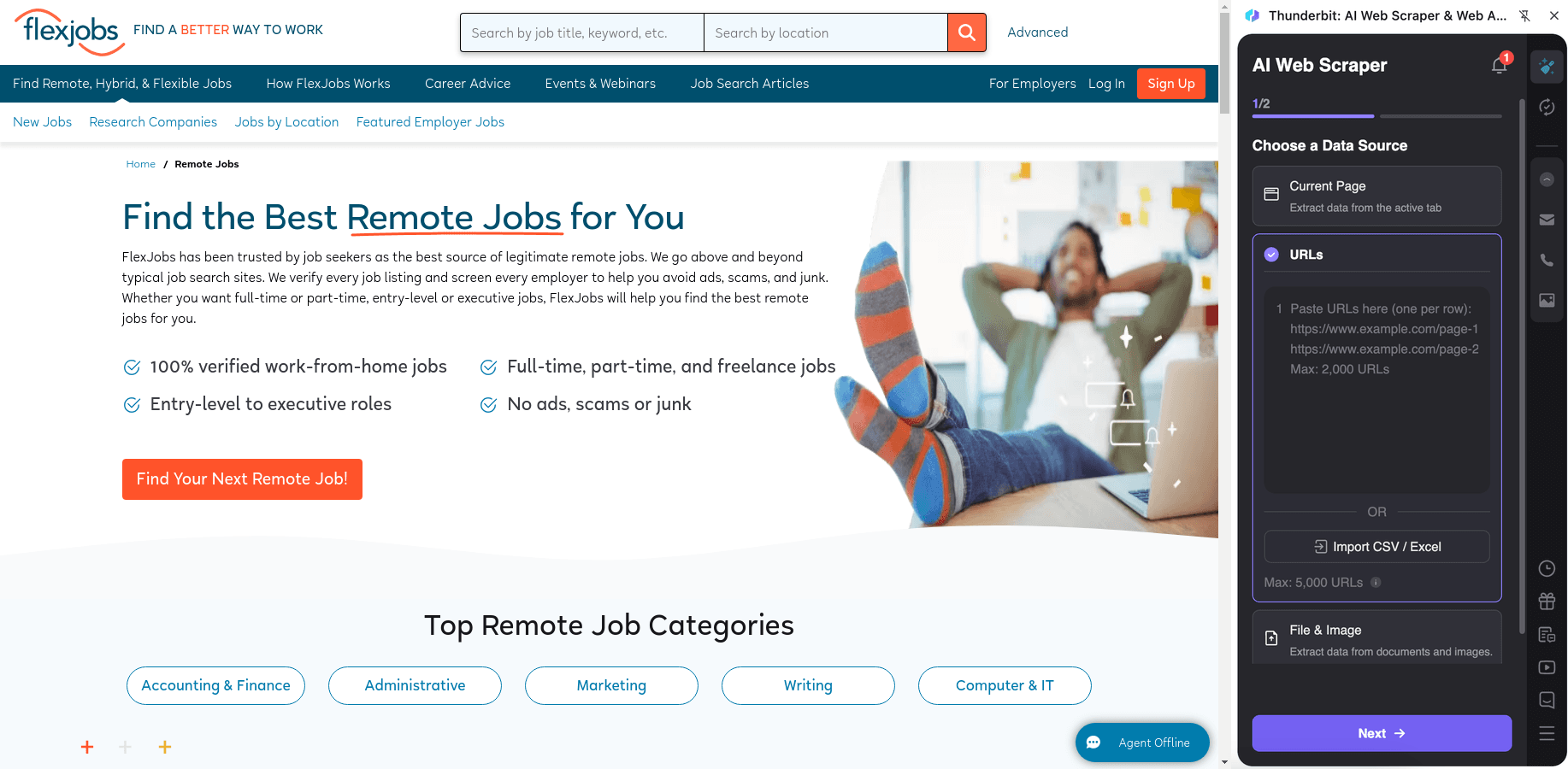
操作步骤:
- 安装 并注册账号。
- 打开目标页面,例如:。
- 点击 AI Suggest Columns,自动生成推荐的字段名与数据类型。
- 点击 Scrape 开始抓取,然后导出到 Excel、Google Sheets、Airtable 或 Notion。
字段示例
| 字段 | 说明 |
|---|---|
| 🧾 职位名称 | 结果页上展示的职位标题。 |
| 🏢 公司 | 雇主/招聘公司名称(如有)。 |
| 📍 地点 / 远程类型 | 地点信息,例如远程、仅限美国、州限制或城市/州。 |
| 🕒 工作类型 | 全职、兼职、自由职业、合同工、临时等。 |
| 🧩 类别 / 职级 | 职位类别和/或资历级别(如有展示)。 |
| 🗓️ 发布日期 | 职位发布或最近更新日期(如有)。 |
| 🔗 职位链接 | 指向职位详情页的直达链接,用于子页面抓取。 |
| 📝 简要摘要 | 列表页上的摘要/预览文本。 |
| 🧠 技能 / 关键词 | 列表中展示的关键技能或标签(如有)。 |
| 📄 完整职位描述(子页面) | 从职位详情页提取的完整职位描述。 |
| ✅ 任职要求(子页面) | 从职位详情页提取的要求/资格条件。 |
| 📬 申请方式(子页面) | 申请说明或申请链接信息(如有)。 |
📚 抓取 FlexJobs 职业建议文章
在 抓取博客列表页,收集文章元信息,用于内容调研、SEO 分析或搭建内部知识库。再通过子页面抓取获取文章全文、标题层级与作者信息。
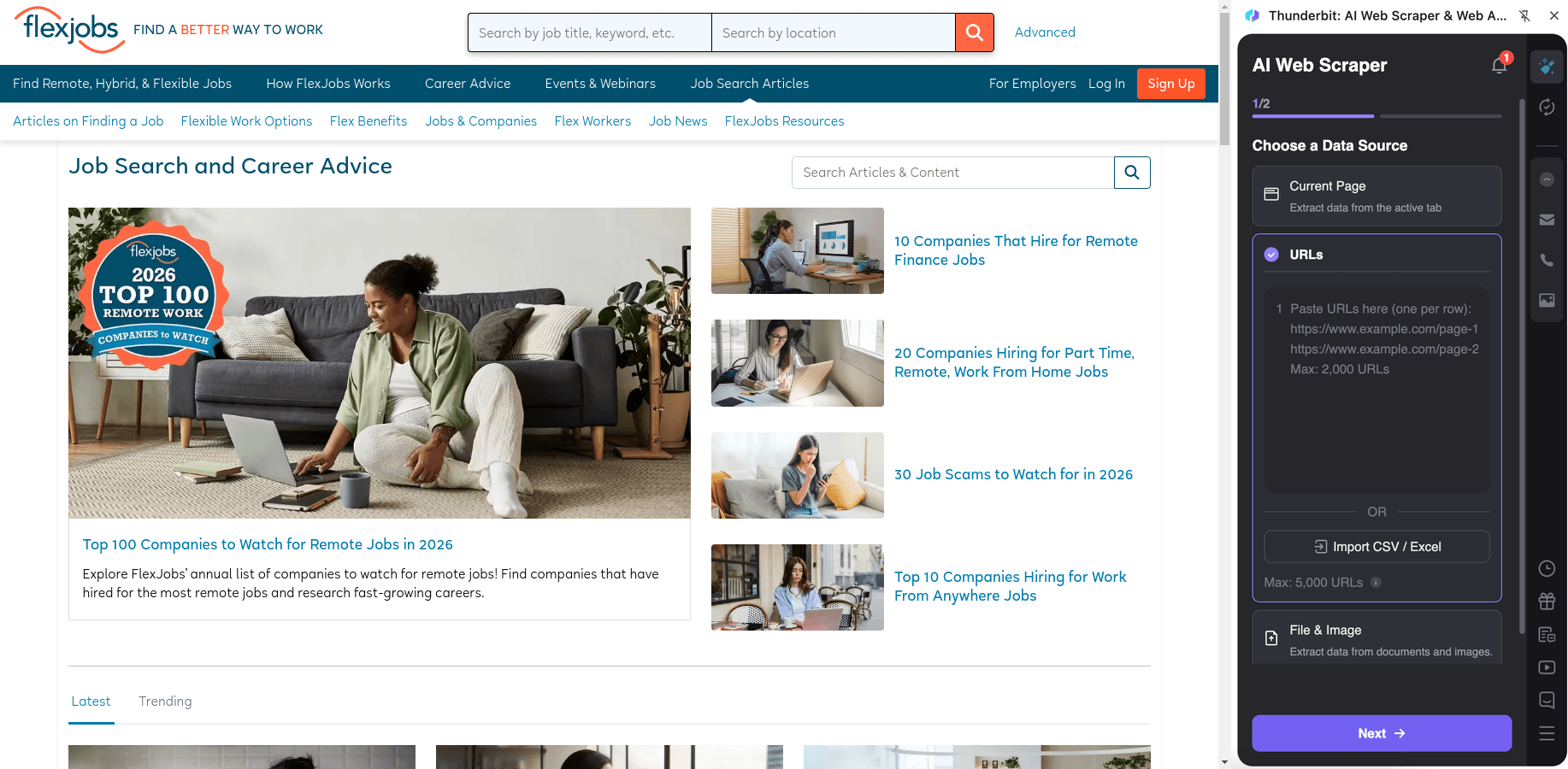
操作步骤:
- 安装 并注册账号。
- 打开目标页面,例如:。
- 点击 AI Suggest Columns,自动生成推荐的字段名与数据类型。
- 点击 Scrape 提取数据,然后导出到 Excel、Google Sheets、Airtable 或 Notion。
字段示例
| 字段 | 说明 |
|---|---|
| 📰 文章标题 | 博客文章的标题。 |
| 🔗 文章链接 | 指向文章页的链接,用于子页面抓取。 |
| ✍️ 作者 | 页面展示的作者姓名(如有)。 |
| 🗓️ 发布日期 | 文章发布的日期。 |
| 🏷️ 分类 / 标签 | 博客分类或标签(列表页或子页面可能提供)。 |
| 🧷 摘要 | 博客列表页上的简短预览文本。 |
| 🖼️ 头图链接 | 文章关联的主图 URL(如有)。 |
| 🧾 文章全文(子页面) | 从文章页提取的完整正文内容。 |
| 🔠 标题层级(子页面) | 抓取 H2/H3 等标题,用于大纲与分析。 |
| ⏱️ 阅读时长(可选) | 页面提供的预计阅读时间(如有)。 |
🎯 为什么要用 FlexJobs 爬虫工具
抓取 FlexJobs 能为多个团队与工作流提供支持,尤其是在需要结构化数据的场景。
- 招聘与人才运营:按类别、地点限制与工作类型建立可检索的远程岗位库;跟踪趋势并与团队共享统一数据。
- 销售与合作拓展:识别正在招聘远程岗位的公司,并按行业、招聘节奏与岗位类型丰富线索名单。
- 职业教练与内容创作者:收集就业市场信号,把职业建议文章整理成内容库,用于通讯、课程或辅导项目。
- 市场与 SEO 团队:分析 FlexJobs 博客选题、发布频率与内容结构,为你的选题与排期提供参考。
- 电商运营与数据分析(没错,也适用):如果你在做招聘平台、用工市场或 HR 产品,可用抓取到的职位数据做竞品研究与分类体系建设。
Thunderbit 面向希望“快且稳”的业务用户,无需维护脆弱的抓取脚本。页面布局变化时,AI 会重新理解页面并自动适配。
🧩 如何使用 FlexJobs Chrome 扩展
- 安装 Thunderbit Chrome 扩展:在 获取并创建账号。
- 打开 FlexJobs 页面:抓职位就进入 ,抓文章就进入 。
- 启用 AI 抓取:点击 AI Suggest Columns 生成字段;如有需要可调整字段名与数据类型(文本、日期、URL、图片等)。
- 抓取并用子页面补全:先对列表页点击 Scrape,再用 Scrape Subpages 把完整职位详情或文章全文补充到同一张表里。
如果你刚接触数据抓取,这些资料会很有帮助:
- 更多指南请见
💳 FlexJobs 爬虫的定价
Thunderbit 采用简单的积分机制:
- 1 积分 = 结果表中的 1 行输出(例如一条职位记录或一篇文章记录)。
- 导出免费:可导出到 Excel、Google Sheets、Airtable 或 Notion,也可下载 CSV/JSON。
你可以从 Free 方案开始,每月可抓取 6 个页面。开启免费试用后,可 免费抓取 10 个页面,非常适合在升级前测试职位分页与子页面补全效果。
付费方案会随工作量扩展:
- Starter 适合轻量抓取与一次性项目。
- Pro 更适合持续的招聘运营、岗位市场监测与内容跟踪。
- 年付方案 通常性价比更高,因为相较月付会有折扣。
可在 查看具体选项。
❓ 常见问题
-
什么是 AI 驱动的 FlexJobs 爬虫?
AI 驱动的 FlexJobs 爬虫是一套 Thunderbit 工作流,可将 FlexJobs 的职位列表与博客文章提取为结构化的行与列。它通过 AI 理解页面布局,让你在快速抓取的同时,仍能获得清晰字段(如标题、公司、地点与链接)。
你还可以通过子页面抓取进一步补全完整职位描述或文章全文。 -
Thunderbit 是什么?
是一款 AI 网页爬虫 Chrome 扩展,可将网站、PDF 与图片中的信息提取为结构化表格。它面向线索挖掘、招聘、电商运营与市场调研等业务场景。
通常只需点击 AI Suggest Columns 再点击 Scrape,必要时 Thunderbit 也能处理分页与子页面。 -
抓取 FlexJobs 需要会写代码吗?
不需要。Thunderbit 为非技术用户设计,你无需 Python、选择器或抓取基础设施。
只要会打开网页并点击几个按钮,就能做出可用的数据集。 -
Thunderbit 能抓取每个职位详情页的内容吗?
可以。抓完列表页后,你可以使用 子页面抓取 访问每个职位链接,提取更深层字段,如完整描述、任职要求与申请说明。
当列表页只展示简短摘要时,这一点尤其有用。 -
Thunderbit 如何处理 FlexJobs 的分页与无限滚动?
Thunderbit 支持点击翻页与无限滚动两种分页模式,可在一次运行中抓取多页数据,适合收集数百条职位信息。
如果选择 Cloud Scraping,Thunderbit 可更快批量处理(通常一次可到 50 页,具体取决于网站行为)。 -
支持导出哪些格式?
你可以将数据导出到 Excel、Google Sheets、Airtable 或 Notion,也可以下载为 CSV 或 JSON。
导出免费,你可以把预算更多用在抓取规模上,而不是文件访问上。 -
FlexJobs 抓取时,Cloud Scraping 和 Browser Scraping 有什么区别?
Browser Scraping 在你的 Chrome 会话中运行,适合需要登录或个性化访问的网站;Cloud Scraping 在 Thunderbit 云端运行,抓取公开页面通常更快。
如果页面依赖你的账号会话,通常更建议使用 Browser Scraping。 -
我能抓取多少行?“500 max rows”是什么意思?
“max rows”(例如 500)是单次运行的实用参考值,取决于页面结构与配置。实际可抓取量会受分页深度、积分以及是否启用子页面补全影响。
由于 1 积分 = 1 行输出,你可以按计划收集的职位/文章数量来预估成本。 -
抓取 FlexJobs 数据合规吗?
你应始终遵守 FlexJobs 的条款,尊重隐私,并符合适用法律法规。Thunderbit 负责帮助你提取与结构化数据,但如何使用数据由你自行负责。
如不确定,建议先小规模测试,并确认用途符合你的合规要求。
📘 了解更多
- 获取扩展:
- 查看产品详情:
- 价格与方案:
- 学习抓取基础:
- 抓取到表格:
- 用 AI 更高效抓取:
- 观看教程: