
在互联网这个信息爆炸的时代,数据已经成为现代商业的核心竞争力。不管你是做销售、电商、房地产,还是想随时掌握竞争对手的最新动态,谁能第一时间拿到准确的数据,谁就能抢占先机。可说实话,没人愿意花大把时间把网页上的内容一条条复制到表格里。这时候,网页爬虫就派上用场了——其实,操作比你想象的简单多了。
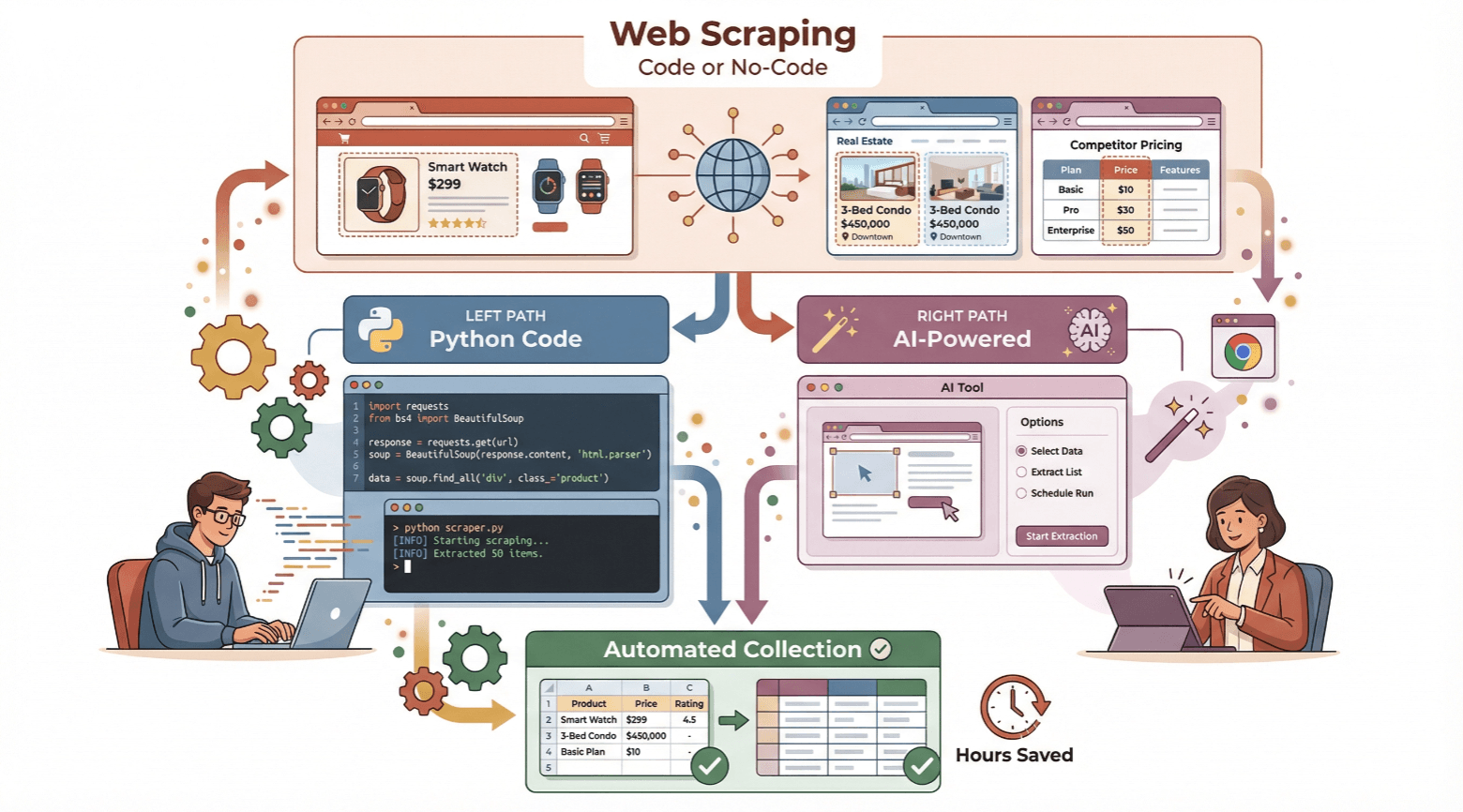
这篇操作指南会手把手教你如何创建网页爬虫——无论你是想用 Python 写代码,还是更喜欢用 这种零代码 AI 工具。我会详细讲解基础原理,分别演示两种方法,帮你选出最适合自己的方案。准备好节省时间,体验自动化数据采集的高效了吗?那我们就开始吧!
什么是网页爬虫?原理一看就懂
网页爬虫其实就是一种自动化工具(软件或服务),能批量帮你从网站上提取信息。比如你想收集本地所有咖啡店的地址和电话,手动复制粘贴不仅慢,还容易出错。网页爬虫就像你的数字小助手,帮你轻松搞定这些繁琐的活儿。
你可以把网页爬虫想象成一个自动逛网页、帮你找出需要数据(比如价格、产品名、联系方式)并整理成表格或数据库的“搬运工”。不用再在浏览器和 Excel 之间来回切换,爬虫能自动完成抓取、解析和保存,效率直接拉满。
它的基本流程其实很简单:
- 请求网页: 爬虫向目标网页发出请求,拿到原始 HTML 内容。
- 解析数据: 分析 HTML 结构,定位你想要的数据(比如
<span>标签里的价格)。 - 提取保存: 把数据提取出来,按结构化格式(如 CSV、Excel、Google Sheets 等)保存。
手动复制粘贴就像用小勺子挖土,而网页爬虫直接开来一台挖掘机。
为什么企业都要自己做网页爬虫?
网页爬虫早就不是技术宅或者数据科学家的专属工具了——现在,任何需要高效、靠谱数据的人都离不开它。几乎 都在投资数据驱动决策,全球网页爬虫市场到 2030 年预计还要翻一倍。
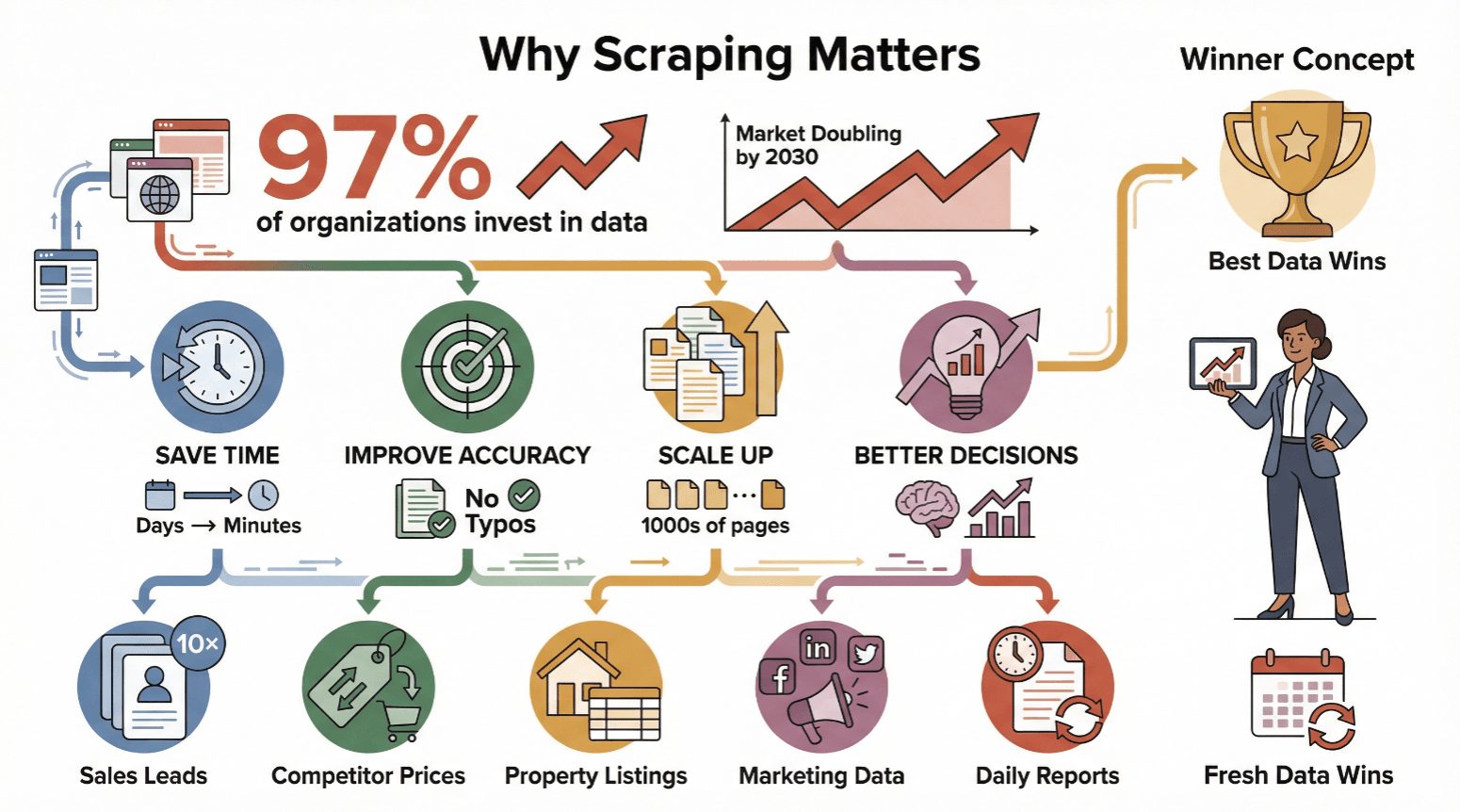
各行各业用网页爬虫的理由很简单:
- 节省时间: 自动化采集让原本几天的活儿几分钟就能搞定。
- 提升准确率: 软件不会累,也不会手抖出错。
- 轻松扩展: 一次能抓成千上万网页,不用只盯着几条数据。
- 助力决策: 实时数据让你能快速调整价格、发现新商机、追踪市场动态。
来看几个实际应用场景:
| 应用场景 | 受益人群 | 典型效果 |
|---|---|---|
| 从企业名录提取销售线索 | 销售团队 | 线索量提升 10 倍,节省大量客户挖掘时间 |
| 监控电商网站竞争对手价格 | 电商运营经理 | 实时调整价格,保护利润空间 |
| 聚合房地产平台房源信息 | 房地产中介 | 更快发现优质房源,获取最新市场动态 |
| 收集网络/社交媒体营销数据 | 市场营销团队 | 精准投放广告,提升活动效果追踪 |
| 自动生成日常网络数据报告 | 运营、数据分析师 | 降低人工成本,减少错误,报告及时且一致 |
一句话总结:谁掌握了最新、最全的数据,谁就能赢得市场。
新手入门:用 Python 快速搭建网页爬虫
想搞懂网页爬虫的底层原理?Python 是入门首选。就算你没写过代码,也能跟着下面的步骤搭个基础爬虫。操作很简单:
环境准备
先在电脑上装好 Python。去 下载最新版,按 Windows 或 Mac 的提示一步步装好,记得勾选“Add Python to PATH”。
然后打开终端或命令行,装好需要的库:
1pip install requests
2pip install bs4
3pip install pandasrequests用来获取网页内容。bs4(Beautiful Soup)用来解析 HTML。pandas方便把数据保存成 CSV 或 Excel。
分析网页结构
写代码前,先搞清楚目标数据在 HTML 里的位置。用 Chrome 打开目标网页,右键点你想采集的数据(比如职位名称),选“检查”,就能看到对应的 HTML 标签(比如带 jobtitle 类的 <a> 标签)。记下这些标签和类名,后面代码要用。
编写并运行爬虫脚本
假设你要抓招聘网站上的职位和公司名称,代码示例:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pd
4URL = "https://example.com/jobs" # 换成你要抓的网址
5response = requests.get(URL)
6soup = BeautifulSoup(response.text, 'html.parser')
7# 找所有职位和公司名称(按实际标签和类名调整)
8titles = [t.get_text().strip() for t in soup.find_all('a', class_='jobtitle')]
9companies = [c.get_text().strip() for c in soup.find_all('div', class_='company')]
10# 保存成 CSV 文件
11df = pd.DataFrame({'Job Title': titles, 'Company': companies})
12df.to_csv('jobs.csv', index=False)
13print("抓取完成!数据已保存到 jobs.csv")- 记得根据实际网站改 URL 和类名。
- 在终端运行脚本:
python yourscript.py - 打开
jobs.csv看结果。
小贴士: 如果遇到分页或动态加载页面,可以用循环或 Selenium 等工具搞定。但大多数静态网页,上面的方法就够用了。
零代码体验:用 Thunderbit 快速创建网页爬虫
如果你完全不想写代码, 就是你的理想选择——它专为商业用户设计,零代码、AI 网页爬虫。用 Thunderbit,采集数据只要两步,导出表格分分钟。
操作流程如下:
步骤 1:安装 Thunderbit Chrome 插件
去 添加插件,注册个免费账号(免费版就能体验不少功能)。
步骤 2:打开目标网页
用 Chrome 打开你要采集的网页。如果需要登录,先登录好,页面下拉加载完所有内容。
步骤 3:描述你的数据需求
点 Thunderbit 图标打开侧边栏,你可以:
- 点 “AI 智能识别字段”,让 Thunderbit 的 AI 自动扫描页面并推荐字段(比如“产品名称”、“价格”、“图片”等)。
- 或者直接用自然语言输入需求(比如“提取本页所有书名和作者”)。
Thunderbit 的 AI 会自动推荐字段和数据类型,你也可以随时重命名、添加或删掉字段。
步骤 4:启动数据采集
设置好字段后,点 “开始抓取”。Thunderbit 会自动提取数据,支持分页抓取,结果直接展示在表格里。如果还要采集子页面(比如商品详情页),点 “抓取子页面”,Thunderbit 会自动访问每个链接补充更多信息。
步骤 5:查看与导出结果
在 Thunderbit 表格里检查数据,满意后点 “导出”,可选 Excel、CSV、Google Sheets、Airtable、Notion 或 JSON 格式。导出不限次数,完全免费。
就是这么简单,无需写代码,无需套模板,无需折腾。
传统网页爬虫 vs 零代码方案
来看看两种方式的优缺点对比:
| 方案 | 上手时间 | 所需技能 | 维护难度 | 灵活性 | 导出格式 |
|---|---|---|---|---|---|
| Python + Beautiful Soup | 数小时/天 | 编码、HTML 基础 | 高(易受网站变动影响) | 非常高 | CSV、Excel、JSON(需编程) |
| 传统零代码工具 | 30-60 分钟 | 需一定技术基础 | 中(需手动修复) | 静态页面表现良好 | CSV、Excel |
| Thunderbit(AI 零代码) | 几分钟 | 无需技术门槛 | 低(AI 自动适应) | 高(支持动态网页) | Excel、CSV、Sheets、Notion... |
Thunderbit 的 AI 驱动方式让你不用反复调试和维护爬虫,把更多时间用在数据分析和业务决策上。
传统网页爬虫常见难题 & Thunderbit 解决方案
传统爬虫常见的痛点有:
- 网页结构变动: 网站一改版,代码就容易失效。Thunderbit 的 AI 能自动适应大多数页面变化,无需你手动改脚本。
- 反爬机制: 很多网站会屏蔽自动脚本。Thunderbit 支持浏览器模式(用你的登录/会话信息)或云端模式,速度和兼容性都能兼顾。
- 动态内容: 无限滚动或“加载更多”按钮会难倒普通爬虫。Thunderbit 的 AI 能自动处理滚动和交互元素。
- 需登录的数据: 只要你能在 Chrome 里看到,Thunderbit 就能帮你采集。
总之,Thunderbit 就是为应对现代网页的各种复杂情况而生,让你省心又省力。
提升效率:Thunderbit 高级网页爬虫功能
Thunderbit 不只是帮你采集数据,更注重数据的高效、整洁和易用。以下是我最喜欢的几个功能:
自动分页与子页面采集
要抓上百个分页商品?Thunderbit 能自动识别分页(比如“下一页”按钮、无限滚动),一键采集所有数据。想获取子页面详情?点“抓取子页面”,Thunderbit 会自动访问每个链接,补充卖家信息、产品参数等字段。
AI 字段推荐与数据结构化
Thunderbit 的 AI 不仅能识别字段,还能理解上下文,自动标注列名、分配数据类型(文本、数字、图片、邮箱等),还能支持自定义指令(比如“只采集价格高于 100 元的商品”或“将描述翻译成英文”)。你还可以添加提示词,对数据进行分类、摘要或格式化。
模板与一键采集
对于热门网站(比如亚马逊、Zillow、Google 地图、Instagram),Thunderbit 提供现成模板,选好网站直接一键采集,无需任何设置。
定时采集与自动化
需要每天获取最新数据?只要设置采集计划(比如“每周一上午 9 点”),Thunderbit 会自动抓取并更新到你的 Google 表格或数据库,无需手动操作。
云端与本地采集灵活切换
你可以选择在浏览器本地运行(适合需登录或交互性强的网站),也可以用云端模式(适合公开数据,支持一次抓取 50 个页面)。
Thunderbit 的强大功能让它成为企业用户高效、可靠、易用的网页爬虫首选。
分步演示:用 Thunderbit 创建网页爬虫
快速上手清单:
- 安装 Thunderbit: 并注册账号。
- 打开目标网页: 如需登录请先登录,滑动页面加载内容。
- 打开 Thunderbit 侧边栏: 点击扩展图标。
- 描述数据需求: 点击“AI 智能识别字段”或输入提示词。
- 检查字段: 可重命名、添加或删除列。
- 点击“开始抓取”: 让 Thunderbit 自动采集。
- (可选)抓取子页面: 需要更详细数据时点击“抓取子页面”。
- 查看结果: 检查表格数据是否准确。
- 导出数据: 支持 Excel、CSV、Google Sheets、Notion、Airtable、JSON 等格式。
- 保存/模板/定时: 可保存设置、创建模板或定时自动采集。
常见问题排查:
- 如果数据不全,试试调整提示词或加自定义指令。
- 动态内容建议用浏览器模式。
- 免费版有抓取页数限制,想要更多功能可以升级套餐。
总结与要点回顾
现在,创建网页爬虫早就不是程序员的专利。无论你想自己用 Python 编码,还是更喜欢让 AI 自动搞定,工具都变得前所未有的简单。
记住这些要点:
- 网页爬虫能极大节省时间、提升准确率,让数据驱动决策变得轻松。
- Python 适合学习和定制化项目,但需要一定编程和维护能力。
- Thunderbit 提供极速、零代码方案——只要描述需求,点“开始抓取”就能搞定。
- 自动分页、子页面采集、AI 字段推荐等高级功能让 Thunderbit 成为企业数据采集神器。
- Thunderbit 支持免费试用,几分钟就能看到效果。
还在手动复制粘贴?现在就 ,体验网页爬虫的高效与便捷。想了解更多实用技巧,欢迎访问 。
常见问题解答
1. 创建网页爬虫一定要会编程吗?
完全不用!虽然用 Python + Beautiful Soup 能高度自定义,但像 Thunderbit 这种零代码工具,任何人都能用自然语言和简单操作创建强大的网页爬虫。
2. Thunderbit 能采集哪些类型的数据?
Thunderbit 几乎能从任意网站提取文本、数字、图片、邮箱、电话等信息,包括分页列表和子页面。热门网站还能直接用模板一键采集。
3. Thunderbit 如何应对网页结构变化?
Thunderbit 的 AI 能自动适应大多数页面布局变动。和传统爬虫不同,Thunderbit 通过语义理解,大大减少了因网站更新导致的失效问题。
4. 网页爬虫是否合法、安全?
只要采集公开数据并遵守网站服务条款,网页爬虫是合法的。Thunderbit 鼓励合规使用,并提供相关功能帮你规范操作。
5. 可以定时采集和自动导出数据吗?
当然可以!Thunderbit 支持自定义采集频率(比如每日、每周等),还能自动把结果导出到 Google Sheets、Notion、Airtable、Excel 或 CSV,无需手动操作。
想体验自动化数据采集?,让网页爬虫人人可用。
延伸阅读