

网页爬虫已经成了现代企业团队的“秘密武器”——不管你是做销售、运营还是市场,能不能高效地从网上收集数据,往往直接影响项目的成败。现在大家都在讲数据驱动决策,企业对工具的要求也越来越高:不仅要快,还得稳、能扩展。Rust 语言最近在网页爬虫圈子里特别火,尤其适合那些对速度和安全性要求极高的团队。
这可不是吹牛——在 Stack Overflow 开发者调查 里,Rust 连续多年被评为“最受欢迎的编程语言”,而且在后端和数据工程领域的应用也越来越多。那么,“用 Rust 做网页爬虫”对企业来说到底意味着什么?它和 Thunderbit 这种零代码工具又有啥区别?接下来我用最接地气的方式给你讲明白,哪怕你没编程基础也能看懂。
Rust 网页爬虫是什么?原理一看就懂
简单说,网页爬虫就是自动帮你从网站上批量提取数据。你可以把它想象成一个数字小助手,帮你访问成百上千个网页,把你关心的信息(比如商品价格、联系方式、评论等)一条条采集下来,整理成结构化的数据。对于需要实时数据做客户开发、市场调研、价格监控等业务的企业来说,这绝对是效率神器。
Rust 是一门以高性能、内存安全和可靠性著称的系统级编程语言。和那些容易出错或者跑得慢的老牌语言不一样,Rust 能在代码运行前就发现大部分问题。对于网页爬虫来说,这意味着你可以做出又快又稳、不容易崩溃或者内存泄漏的工具——尤其适合大规模数据采集。
别以为 Rust 只是程序员的心头好,它带来的好处企业用户也能直接享受。更快、更安全的爬虫意味着数据更新更及时、错误更少、洞察更靠谱。
为什么选 Rust 做网页爬虫?企业用户的核心优势
那为啥现在越来越多团队做网页爬虫时选 Rust,而不是多年来主流的 Python 或 JavaScript?主要优势有这些:
- 高性能: Rust 编译出来就是机器码,运行速度远超 Python 或 JavaScript 这种解释型语言。要是你要抓百万级网页,这种速度优势直接变成业务价值。
- 内存安全: Rust 独特的内存管理机制(没有垃圾回收,所有权规则很严格)大大减少了 bug 和崩溃的风险。你的爬虫任务更不容易半路出问题,省时省心。
- 可靠性: Rust 编译器强制类型检查和错误处理,很多问题在代码跑起来之前就能发现,爬虫流程更稳定、更可控。
- 并发能力: Rust 写并发代码很方便(后面会详细说),要是你需要同时抓很多网页,这点特别关键。
和 Python、JavaScript 相比,虽然它们上手快,但在大规模、对稳定性要求高的场景下,性能和可靠性就有点跟不上了。Rust 的技术优势让你能更快、更高效地采集更多数据,企业竞争力直接拉满。
Rust 的异步能力:大规模网页爬取的效率神器
Rust 有个大杀器就是异步编程。简单说,异步代码能让你的爬虫同时向很多网站发请求,不用等前一个结束再处理下一个。要是你要快速采集海量数据,这就是“效率神器”。
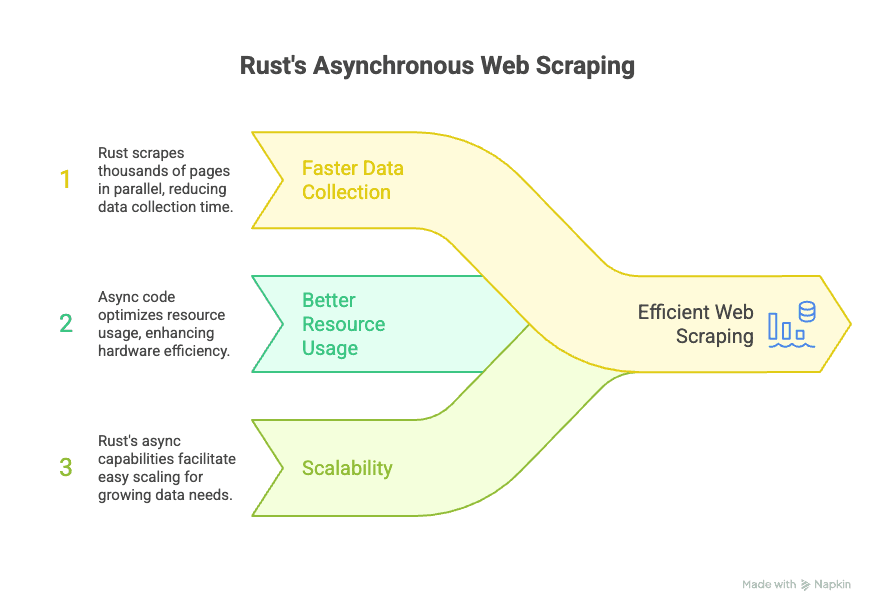
Rust 的异步生态主要靠 Tokio 和 async-std 这些库,能让你的爬虫同时处理成千上万个请求,主进程一点都不卡。对企业来说,这意味着:
- 数据采集更快: 可以并发抓取海量网页,数据收集时间大大缩短。
- 资源利用更高效: 异步代码让你用更少的硬件做更多事。
- 易于扩展: 数据需求涨了,Rust 的异步能力让你不用重写流程就能轻松扩容。
实际用起来,你的团队可以实时响应市场变化、监控对手或者生成销售线索,再也不用苦等数据下载。
Rust 网页爬虫怎么工作?流程一目了然
想知道 Rust 网页爬虫一般怎么跑?我用最简单的方式给你梳理下:
- 需求设定: 先确定要采集哪些数据、目标网站有哪些。
- 数据抓取: 用 Reqwest 这类库发 HTTP 请求,下载网页内容。
- 内容解析: 用 Scraper 或 Select 这些库,从 HTML 里提取你要的信息(比如商品名、价格、邮箱等)。
- 处理分页/子页面: 写逻辑自动翻页或跟进子页面链接(后面会详细说)。
- 数据导出: 把采集到的数据保存成结构化格式(比如 CSV、Excel 或直接写数据库),方便团队后续用。
每个库各有分工:Reqwest 负责“抓”,Scraper/Select 负责“解析”,数据导出和整理可以用 Rust 自带功能或者第三方库搞定。
复杂网站采集:Rust 如何搞定分页和子页面
很多企业级爬虫任务不是只采集一页数据。你可能要:
- 抓多页商品目录下的所有产品
- 收集分布在多个子页面的评论
- 从多层级目录里提取联系人信息
Rust 在这些场景下特别给力。它的强类型系统和错误处理机制让你更容易写出:
- 自动识别并跟进“下一页”或分页链接 的代码
- 访问子页面(比如商品详情、作者简介等),把数据合并到主数据集
- 优雅应对异常情况(比如页面丢失、链接失效),爬虫不容易崩溃
举个例子,一个 Rust 爬虫可以从主商品列表页出发,自动翻页,再一个个访问每个商品详情页,采集价格、描述、评论等信息。最后你能拿到一份全面、实时的数据集,后续分析一点不耽误。
Thunderbit vs. Rust 编码:企业团队的零代码福利
当然,不是每个人都有时间或者技术能力从头写一个 Rust 爬虫。这时候,Thunderbit 就特别适合你。
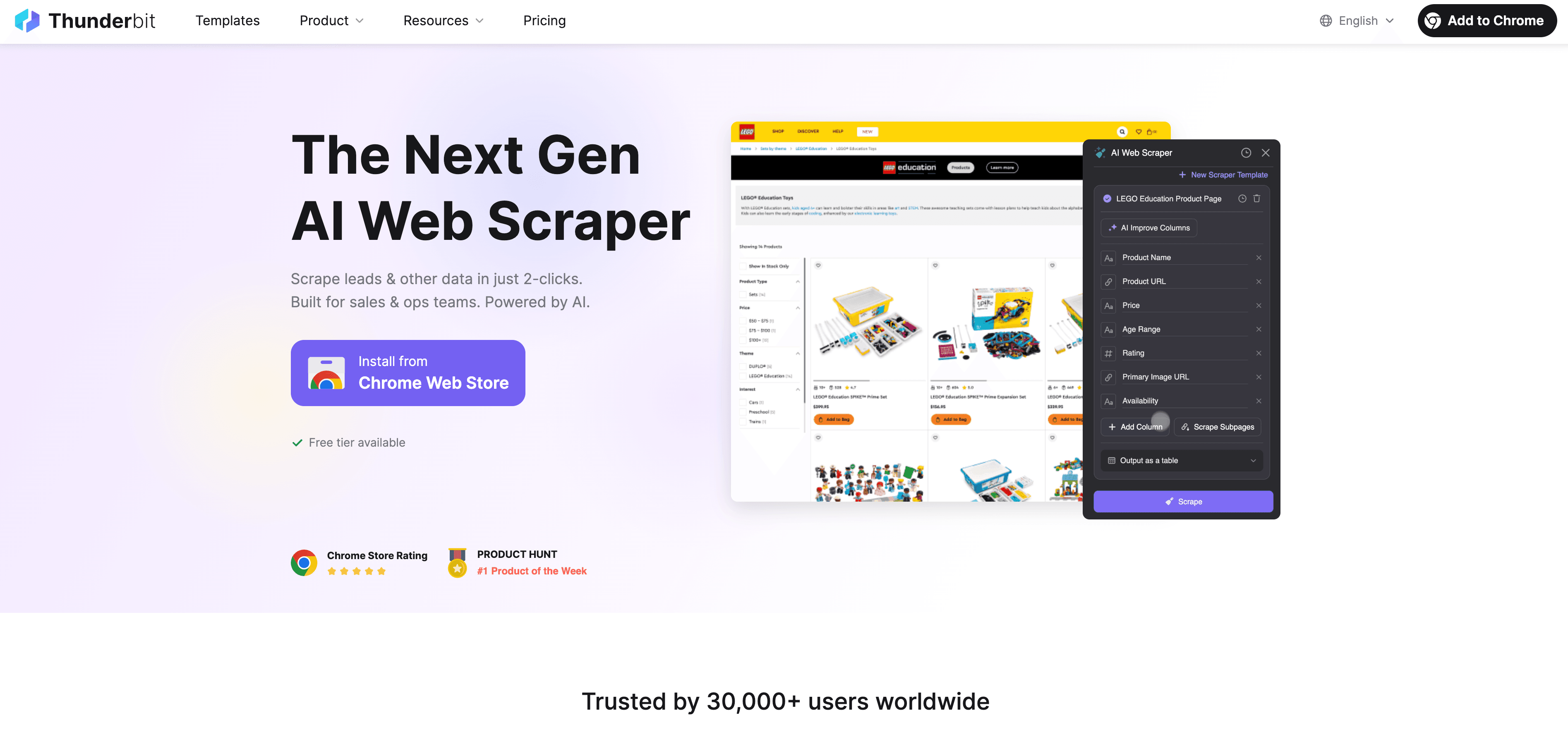
Thunderbit 是一款AI 驱动的零代码网页爬虫,专门为企业用户设计。你只需要:
- 打开 Thunderbit Chrome 插件
- 进入你想采集数据的网站
- 点一下“AI 智能识别字段”,Thunderbit 的 AI 会自动推荐可提取的数据
- 一键“抓取”,结果导出到 Excel、Google Sheets、Airtable 或 Notion
不用模板、不用写代码、不用维护。Thunderbit 还能自动处理分页和子页面采集——就像定制的 Rust 爬虫,但操作简单太多。
什么时候用 Thunderbit,什么时候用 Rust?选型建议
到底哪种方式更适合你的团队?这里有一份速查表:
| 场景 | Thunderbit | Rust |
|---|---|---|
| 快速生成销售线索 | ✅ 最简单、最快速 | 可行,但有些大材小用 |
| 电商价格监控 | ✅ 零代码、可定时 | ✅ 可做深度集成 |
| 复杂自定义采集流程 | 有一定局限 | ✅ 完全可控、极致定制 |
| 大规模数据管道集成 | 可通过 API 实现 | ✅ 深度集成最佳选择 |
| 非技术用户(销售、运营、市场) | ✅ 专为你设计 | ❌ 需编程能力 |
| 快速原型或一次性任务 | ✅ 两步搞定 | 可行,但启动慢 |
一句话总结:Thunderbit 适合追求高效、稳定、零门槛的数据采集场景。Rust 更适合需要极致定制、复杂逻辑或大规模采集的技术团队。
实战案例:Rust 网页爬虫的应用场景
举个实际例子。假如你是市场分析师,要采集某大型电商网站上所有笔记本电脑的数据。这个网站用分页展示,每个产品还有详情页,里面有参数和评论。
用 Rust,你可以这样搞:
- 用 Reqwest 抓主列表页
- 用 Scraper 解析 HTML,提取产品链接
- 自动识别并跟进“下一页”按钮,抓所有分页
- 对每个产品,访问详情页,采集参数和评论
- 优雅处理异常(比如页面丢失),必要时自动重试
- 最后把数据导出成 CSV 或上传到分析平台
业务价值?你能拿到一份完整、实时的市场全景数据,定价、库存、营销决策都能用得上。
Rust 网页爬虫的挑战和注意事项
当然,Rust 虽然很强,网页爬虫还是有不少挑战。常见问题和 Rust 的应对方式如下:
- 网站结构变动: 网站布局一变,爬虫可能失效。Rust 的强类型机制能帮你提前发现问题,但还是要及时更新代码。
- 反爬机制: 很多网站有验证码或限流。Rust 的高性能能降低被封风险,但有时候还得加延时或者用代理。
- 数据清洗: 网页数据经常很乱,Rust 的解析工具能更好地处理杂乱 HTML。
- 维护成本: 定制爬虫需要持续维护。对企业来说,日常采集任务可以考虑用 Thunderbit 这种零代码工具,省时省力。
2025 年数据抓取是什么,怎么做? Get Started Free
小贴士: 不管用 Rust 还是 Thunderbit,采集数据时一定要遵守网站服务条款和相关隐私法规。
总结:Rust 网页爬虫助力企业释放数据价值
在数据驱动的时代,网页爬虫已经成了企业的标配能力。Rust 以超强的性能、安全性和可靠性,为需要定制化、大规模采集的技术团队提供了坚实后盾,尤其适合对速度和稳定性要求极高的场景。但对大多数企业用户来说,技术门槛还是有点高。
这正是 Thunderbit 的优势:它用 AI 和零代码界面,让网页爬虫人人都能用,哪怕是复杂的分页和子页面采集也能轻松搞定。不管你是销售、市场还是分析师,Thunderbit 都能帮你快速拿到想要的数据。
核心要点:
- Rust 适合技术团队做定制化、大规模网页爬虫。
- Thunderbit 让非技术用户也能轻松用上网页爬虫。
- 选对工具:深度定制用 Rust,追求效率和易用性选 Thunderbit。
使用 AI 从任何网站抓取数据 Get Started Free
想让你的企业体验网页爬虫的高效?下载 Thunderbit,感受数据采集的便捷。如果你需要定制化高性能方案,也可以深入了解 Rust 生态。
试用 AI 网页爬虫 Get Started Free
常见问题解答
1. Rust 网页爬虫是什么,和其他语言有啥区别?
Rust 网页爬虫就是用 Rust 语言自动化采集网站数据。和 Python、JavaScript 这些语言比,Rust 最大的优势是速度快、内存安全、稳定性高,特别适合大规模或者对可靠性要求极高的采集任务。
2. Rust 适合非技术企业用户做网页爬虫吗?
Rust 功能很强,但需要编程能力。对于非技术用户,Thunderbit 这种零代码、AI 驱动的工具更友好,让数据采集变得人人可用。
3. Rust 怎么处理分页和子页面等复杂采集任务?
Rust 的强类型系统和异步库让你更容易写出自动翻页、跟进子页面、处理异常的代码,最后拿到更完整、可靠的数据集。
4. 什么时候该用 Thunderbit,什么时候用 Rust 定制爬虫?
如果你需要快速、简单的数据采集(比如销售、市场、运营团队),Thunderbit 是首选。要是需要高度定制、大规模或者深度集成的采集流程,建议用 Rust。
5. Rust 网页爬虫的主要挑战有哪些,怎么应对?
常见挑战有网站结构变动、反爬机制和维护成本。Rust 的安全特性能帮你提前发现问题,但还是要定期更新代码。日常采集任务可以用 Thunderbit 这种零代码工具,省心又高效。
延伸阅读:




