

说真的,社交媒体简直就是各种观点、潮流和梗的聚集地——还有那些总能让我刷到停不下来的猫咪视频。但在这些热门舞蹈和犀利评论背后,其实藏着一座数据金矿。每天都有数以亿计的帖子、评论和个人资料涌现,社交媒体已经成为获取实时消费者和市场洞察的超级宝库。
作为一个长期混迹在 SaaS 和自动化领域的老玩家,我亲眼见过无数企业争分夺秒地想要读懂这些数字世界的“噪音”。不管你是市场营销、销售达人,还是像我一样的数据控,肯定都好奇:企业到底是怎么收集和分析这些社交数据的?这就得靠社交媒体爬虫工具了。今天我就用最接地气的方式,带你搞懂什么是社交媒体爬取、这些工具怎么用,以及无论你是 Python 大神还是完全不会写代码,怎么都能轻松上手提取有价值的信息。
社交媒体爬取:入门扫盲
先来点基础知识。社交媒体爬取,其实就是用自动化的方式,从各种社交平台(比如 Facebook、Twitter/X、Instagram、LinkedIn、TikTok 等)批量收集数据。与其手动复制粘贴帖子或评论(说实话,这比看油漆干还无聊),不如让社交媒体爬虫工具帮你一键搞定。
那社交媒体爬虫工具到底是啥?简单说,就是一种软件或服务,可以自动访问社交媒体页面,读取公开信息,把你关心的内容——比如帖子、评论、标签、用户资料、粉丝数等——统统抓下来。有些人也叫这些工具社交媒体爬虫,因为它们会像小爬虫一样在页面里“爬”来“爬”去找数据。不过爬虫和爬取工具还是有点区别:爬虫更像侦查员,负责发现新页面,爬取工具则是真正把“宝藏”带回来的那位。
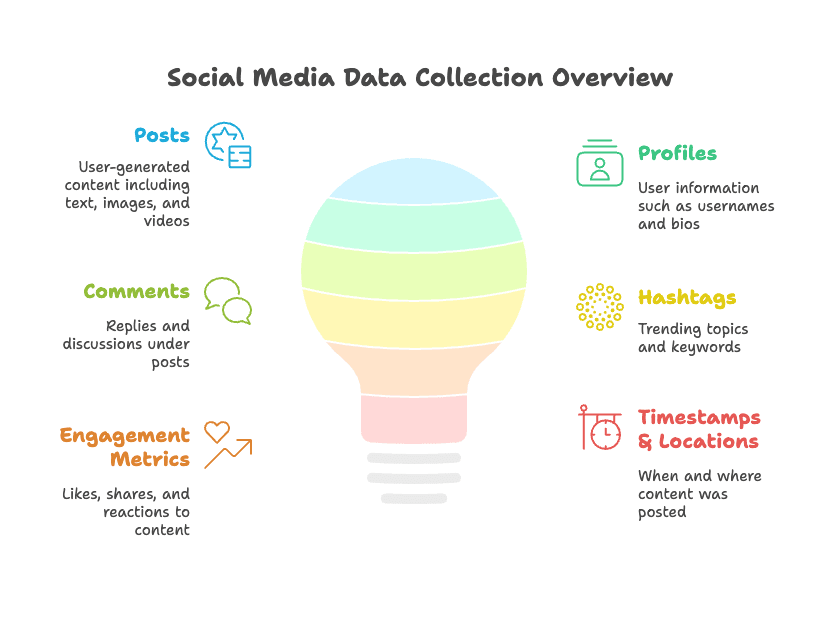
用社交媒体爬虫能采集哪些数据?常见的有:
- 帖子:用户发的内容,包括文字、图片、视频、链接等
- 个人资料:用户名、简介、头像、粉丝/关注数等
- 评论:帖子下的回复和讨论
- 标签:热门话题、活动标签、关键词等
- 点赞、分享、互动:衡量内容热度的各种指标
- 时间与地点:内容发布时间和发布位置
如果你脑补出一个拿着放大镜的机器人在网上溜达,其实也差不多——只不过这些“机器人”不用喝咖啡。
企业为什么要抓社交媒体数据?
企业为啥这么热衷于抓社交媒体?不仅仅是怕错过热点,更是为了挖掘真正有价值的洞察。下面这些就是企业常用社交媒体爬取的主要理由:
| 应用场景 | 价值 | 实际效果举例 |
|---|---|---|
| 市场调研 | 洞察趋势与消费者情绪 | 发现热门标签、流行话题 |
| 消费者洞察 | 了解客户喜好与反馈 | 情感分析、产品评价收集 |
| 潜在客户挖掘 | 寻找潜在客户与合作伙伴 | 从 LinkedIn 构建客户名单 |
| 竞品分析 | 跟踪竞争对手动态 | 监控竞品发帖与粉丝变化 |
| 品牌监测 | 维护品牌声誉,预警公关风险 | 负面舆情实时提醒 |
| 销售情报 | 识别购买信号与潜在客户 | 跟踪职位变动、新员工入职 |
举个例子:你要推出一款新零食,通过抓 Instagram 和 TikTok,可以快速知道什么口味最火、哪些网红在带货、竞争对手热度如何。如果你做 B2B 销售,抓 LinkedIn 资料能帮你精准锁定目标客户和关键决策人。
这些可不是纸上谈兵,很多企业早就用上了。比如,Spotify 的官方 Twitter 账号 SpotifyCares 就用社交数据提升客户服务和产品反馈。Brandwatch 帮英国零售商 Co-op 通过实时 Twitter 数据触达 2350 万人,获得 7500 万次曝光。
社交媒体爬虫工具怎么工作?(通俗易懂版)
接下来,简单聊聊这些工具的工作原理——不用担心,完全不烧脑。
基本流程
- 访问公开数据:工具自动访问社交媒体页面(比如公开的 Instagram 账号或 Twitter 话题页)。
- 提取结构化信息:读取页面内容,抓取你需要的数据(比如帖子、评论、点赞等),并整理成表格或数据表。
- 导出结果:把数据导出成 CSV、Excel、Google Sheets,或者直接对接分析工具。
爬虫、爬取工具和 API 有啥区别
- 社交媒体爬虫:专门从网页里提取特定字段(比如帖子内容、作者、时间等)。
- 社交媒体爬虫(Crawler):自动浏览多个页面(比如个人资料、帖子、评论),发现可采集的新数据,像“探路者”一样。
- 官方 API:平台官方提供(比如 Facebook Graph API、Twitter API),数据合规但有各种限制、速率限制,还得开发者配置。
反爬机制
社交平台可不会对爬虫“敞开大门”。它们会用验证码、访问频率限制、登录验证等方式防止自动抓取。有些工具能用代理、切换浏览器指纹、自动识别验证码等手段绕过这些障碍,但也有工具容易被封号或者数据不全。所以,不同工具的稳定性差别很大。
想深入了解技术细节,AIMultiple 的社交媒体爬虫工具评测可以参考下。
社交媒体爬取方案对比:从 Python 到零代码
抓一条推文(或者 TikTok 热舞)的方法可不止一种。下面简单对比下主流方案:
| 方式 | 技术门槛 | 配置时间 | 灵活性 | 适合人群 |
|---|---|---|---|---|
| Python 库(如 BeautifulSoup、snscrape) | 高 | 长 | 最高 | 开发者、定制项目 |
| 官方 API(如 Facebook Graph API、Twitter API) | 中 | 中 | 高 | 应用集成、合规需求 |
| 零代码工具(如 Thunderbit) | 无 | 快 | 中高 | 商业用户、追求效率 |
| 现成数据集 | 无 | 即时 | 低 | 快速调研、非技术用户 |
- Python 库:适合技术党,灵活性高,可自定义,但要自己搞定代理、数据清洗等。
- 官方 API:合规稳定,但数据类型和抓取量有限制。
- 零代码工具:不用写代码,操作简单,适合想快速拿到数据的用户。
- 现成数据集:适合一次性调研,但数据可能不够新或不完全匹配需求。
用 Python 抓社交媒体数据:快速上手
如果你会 Python,可以用 BeautifulSoup、Requests、snscrape 等库自建爬虫。
基本步骤
-
安装依赖:在终端输入:
pip install beautifulsoup4 requests snscrape -
写脚本:用 Requests 获取网页,用 BeautifulSoup 解析 HTML,或者用 snscrape 抓 Twitter。
-
提取数据:定位包含目标数据的 HTML 元素(比如
<div>、<span>等)。 -
保存结果:导出成 CSV、Excel 或数据库。
-
应对挑战:注意访问频率、登录验证、验证码、数据清洗等问题。
示例:用 snscrape 抓推文
import snscrape.modules.twitter as sntwitter
import pandas as pd
tweets = []
for tweet in sntwitter.TwitterSearchScraper('from:elonmusk').get_items():
tweets.append([tweet.date, tweet.content, tweet.user.username])
if len(tweets) > 100:
break
df = pd.DataFrame(tweets, columns=['Date', 'Content', 'Username'])
df.to_csv('elon_tweets.csv', index=False)
常见难题:
- API 和网页结构经常变,脚本容易失效。
- 抓私有数据要处理认证。
- 大规模抓取得用代理、反爬技术。
想了解更多细节,可以看看 AIMultiple 的 Python 爬虫库指南。
不会编程也能抓社交媒体:Thunderbit 社交媒体爬虫
试用 Thunderbit 社交媒体爬虫 Get Started Free
如果你一看到 Python 代码就头大,不妨试试 Thunderbit 社交媒体爬虫。(没错,我真心推荐它。)
Thunderbit 专为非技术用户设计,只要几步就能抓社交媒体数据:
- 选模板:支持 Instagram、LinkedIn、Twitter/X 等主流平台,直接用现成模板。
- 输入链接:粘贴你想抓的主页、帖子或标签页链接。
- AI 智能识别字段:Thunderbit 的 AI 自动分析页面,推荐可提取的数据字段(比如内容、作者、点赞数等)。
- 一键抓取与导出:点“抓取”,数据就能导出到 Excel、Google Sheets、Airtable 或 Notion,完全免费。
亮点功能
- 子页面抓取:不仅能抓主页面,还能自动采集关联子页面(比如某账号下所有帖子)。
- 即用模板:主流平台一键抓取,无需配置。
- 免费导出:多种格式随时下载,无额外费用。
- 零代码门槛:只要会用鼠标,就能用 Thunderbit。
想看实际操作演示,可以去我们的 YouTube 频道。
能抓哪些社交媒体数据?类型和示例
具体来说,不同平台能抓的数据类型如下(仅限公开数据):
| 平台 | 可抓取数据类型 |
|---|---|
| 账号名称、主页链接、头像、粉丝/关注数、帖子(内容、时间、点赞等) | |
| Twitter/X | 推文、标签、作者、时间、点赞、转发、评论、个人资料 |
| 帖子、文案、标签、作者、发布时间、点赞、评论、个人资料 | |
| 账号名称、职位、公司、地区、帖子、联系人、技能 | |
| TikTok | 视频、文案、标签、作者、点赞、评论、分享、个人资料 |
| YouTube | 视频标题、描述、播放量、点赞、评论、频道信息 |
公开数据 vs. 私有数据:
- 公开数据:不用登录就能看到的内容,比如公开帖子、公开账号、标签等,通常可以合法抓取。
- 私有数据:需要登录、设置为私密或未公开的信息,抓取属于违法或违规。
详细分类可以参考 AIMultiple 关于社交网络可抓取数据的法律指南。
社交媒体爬取的法律和道德须知
这里必须认真点:能抓不代表就该抓,合规和道德底线不能忽视。
关键原则
- 公开与私有:只抓公开数据,私密或受限内容禁止采集。
- 平台规则:每个平台都有自己的使用条款,违规可能被封号甚至追责。
- 数据隐私法规:比如欧洲的 GDPR 等,禁止未经同意收集或传播个人身份信息(PII)。
- 负责任使用:不能把数据用来发垃圾信息、骚扰或其他不当用途。
最佳实践:
- 仔细阅读平台 robots.txt 和服务条款。
- 控制抓取频率,别影响网站正常运行。
- 误采集到 PII 时要及时删除。
- 有疑问时,最好咨询法律专家。
更多内容可以参考 AIMultiple 关于网页爬取合法性的综述。
入门建议:高效合规抓社交媒体数据
准备好动手了吗?下面是我总结的高效又合规的实用建议:
- 从小规模测试:先在少量公开页面试用爬虫,慢慢扩大范围。
- 善用模板:用现成模板(比如 Thunderbit)省时省力,减少出错。
- 关注页面变化:社交平台页面结构经常变,带 AI 的工具(比如 Thunderbit)适应性更强。
- 结合分析工具:抓数据只是第一步,结合分析工具挖掘趋势、情感和洞察。
- 始终合规:随时关注最新法律和道德规范,有疑问时宁可保守。
记住,目标不是单纯收集数据,而是把数据变成推动决策的洞察。
总结:用社交媒体爬虫工具释放数据价值
用 AI 抓取社交媒体数据 Get Started Free
社交媒体爬取早就不是极客或数据科学家的专属。无论你是市场营销、销售负责人,还是想了解网络动态的普通用户,爬虫工具都能帮你实现从市场调研、消费者洞察到客户挖掘和销售情报的全流程自动化。
关键是选对适合自己的工具。如果你喜欢编程,Python 库和 API 灵活性高,但也更复杂。如果你追求速度和简单,Thunderbit 这种零代码工具就是理想选择——选模板、点几下就能搞定。
无论用哪种方式,都要合规抓取、尊重隐私,把数据真正转化为业务价值。如果你想马上体验,可以试试 Thunderbit 的社交媒体爬虫模板,或者去 Thunderbit 博客看看更多实用技巧。
好了,接下来我还要“研究”几段猫咪视频——当然,纯属学术目的。
延伸阅读:
- 什么是数据爬取及 2025 年最新方法
- 如何用 AI 抓取任意网站数据
- 2025 年 6 款最佳 Twitter (x.com) 爬虫推荐
- 2025 年最佳网页爬虫工具与软件
- AIMultiple:社交媒体爬虫工具评测
用 Thunderbit 开始抓取社交媒体数据 Get Started Free
常见问题
1. 什么是社交媒体爬虫工具?它能做什么?
社交媒体爬虫工具是一种自动化软件或服务,可以从 Facebook、Twitter、Instagram、LinkedIn、TikTok 等平台批量采集公开数据,比如帖子、评论、标签、用户资料和互动指标,无需手动复制粘贴,方便后续分析。
2. 企业为什么要用社交媒体爬虫工具?
企业用社交媒体爬虫工具,可以实时洞察市场趋势、消费者情绪、竞品动态和品牌口碑。这些工具助力市场调研、客户挖掘、销售情报和品牌监测,为决策和策略提供数据支撑。
3. 社交媒体爬虫工具的工作原理是什么?
一般来说,社交媒体爬虫工具会自动访问公开页面,提取结构化信息(比如帖子、评论、点赞等),并导出成 CSV、Excel、Google Sheets 等格式。有的工具用爬虫自动浏览页面,有的则通过官方 API 或零代码方案实现合规抓取。
4. 抓社交媒体数据有哪些法律和道德注意事项?
抓取时只能采集公开信息,必须遵守各平台服务条款。私有或受限数据禁止抓取。同时要遵守如 GDPR 等数据隐私法规,未经同意不得收集或传播个人身份信息。合理合规使用数据,避免法律和道德风险。
5. 抓社交媒体数据有哪些方式?一定要会编程吗?
抓取方式很多:会编程的可以用 Python 库,官方 API 适合合规需求,零代码工具如 Thunderbit 则无需技术基础,适合追求效率的商业用户。对于一次性调研,也可以直接购买现成数据集。




