你是不是也遇到过这种情况:网站首页信息少得可怜,想拿到完整数据却得不停点开各种子页面?现在,越来越多的网站把重要内容藏在子页面里,批量采集数据变得特别麻烦。程序员得花大量时间写脚本去遍历子页面,不会写代码的小伙伴只能一个个手动点开。其实,这些问题完全可以靠列表爬取(也叫批量爬取)和子页面爬取来轻松搞定。
列表爬取和子页面爬取对比
什么是列表爬取?
列表爬取(批量爬取)就是通过一组 URL 列表,批量采集网页数据的方法。你得先准备好目标页面的 URL 列表,通常还得用别的爬虫工具先把这些链接抓出来。列表爬取的效果很大程度上取决于你手里这份 URL 列表的质量。如果这些链接指向的页面结构不统一,采集出来的数据就会很乱,整理起来也很费劲。列表爬取特别适合需要大规模、结构化数据的企业、研究员和数据分析师。不过,采集到的数据通常还得人工清洗和整理,才能真正用起来。
工作流程

列表爬取一般分为以下几个步骤:
- 准备 URL 列表:先把所有目标网页的链接收集好。
- 发送 HTTP 请求:系统会依次访问这些链接,获取网页的 HTML 内容。
- 数据提取:用 BeautifulSoup、XPath 或正则表达式等解析工具,把需要的文本、图片、链接等信息提取出来。
- 数据存储:把提取到的数据整理好,存进数据库或表格,方便后续分析。
数据采集完后,还可以用描述性统计、时间序列分析、相关性分析、聚类等方法进行清洗和分析。AI 技术能大大提升整个流程的自动化和数据质量。
想要更高效体验,不妨试试 Thunderbit AI 网页爬虫的批量爬取功能。
推荐工具
-
- 优点:操作简单,解析灵活,功能强大
- 缺点:需要本地运行,依赖浏览器
- 适用场景:追求高质量数据采集
- Scrapy
- 优点:功能强大,可高度定制,适合大规模采集
- 缺点:学习门槛高,需要编程基础
- 适用场景:大型数据采集项目
- Beautiful Soup
- 优点:容易上手,文档丰富,解析灵活
- 缺点:性能一般,不支持异步
- 适用场景:小规模采集、数据分析
- Selenium
- 优点:支持动态页面,可模拟用户操作
- 缺点:速度慢,资源消耗大
- 适用场景:需要处理 JavaScript 渲染页面
子页面爬取详解

什么是子页面爬取?
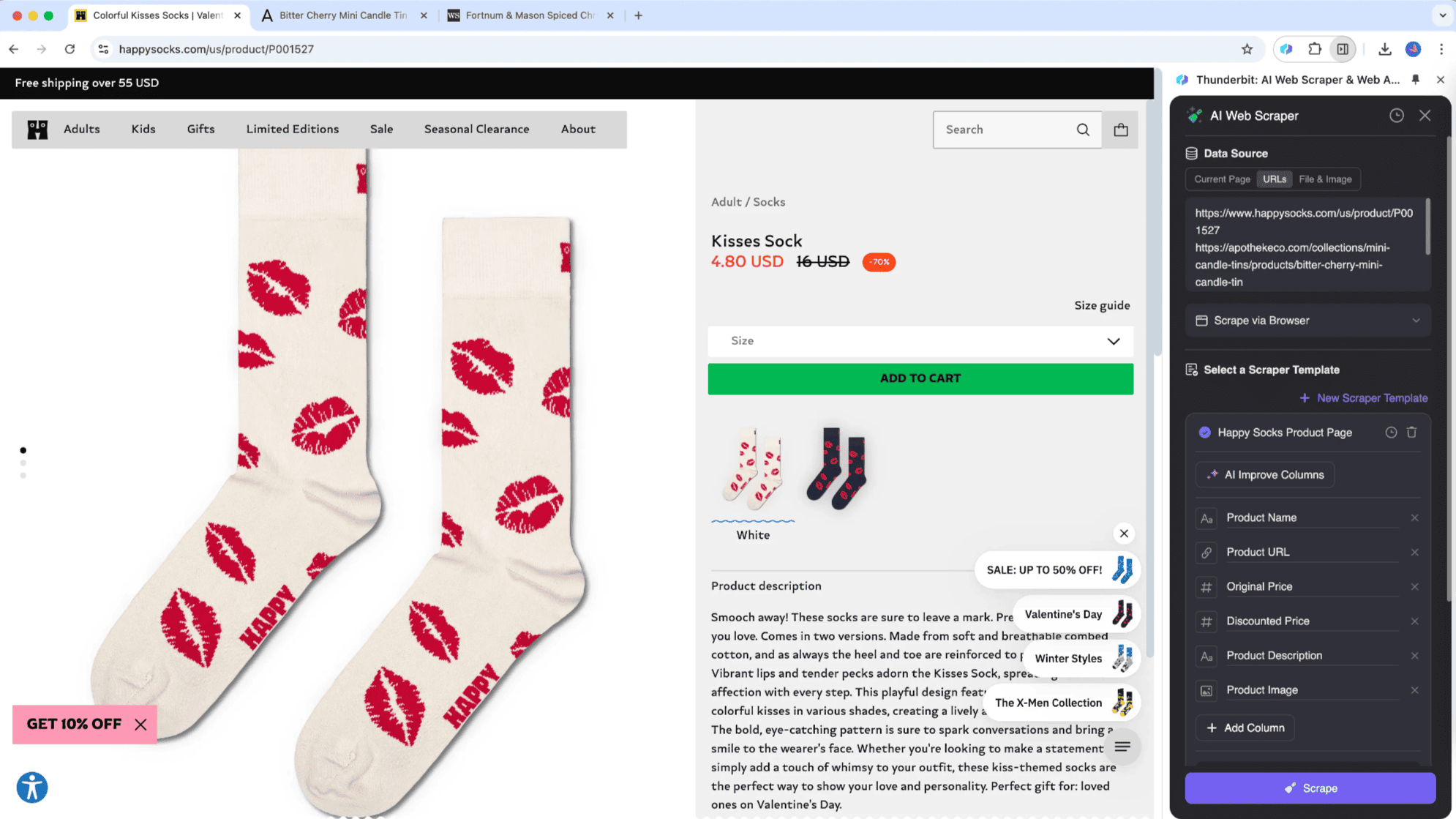
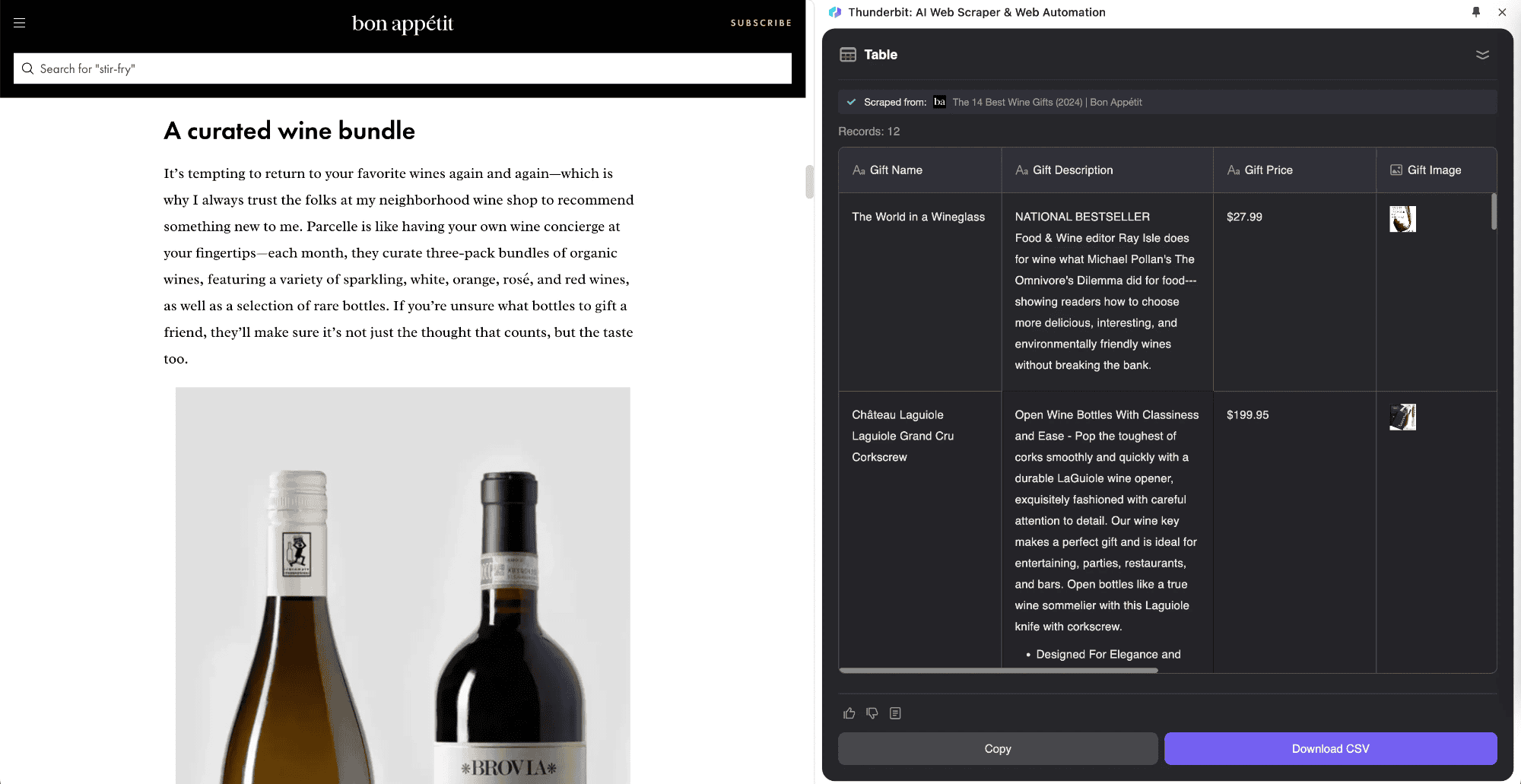
子页面爬取就是先从主页面提取列表数据,再自动抓取每个子页面的详细信息,并把这些内容合并到主表格里。Thunderbit 率先把 AI 能力引入网页爬虫,实现了这种创新流程。它特别适合处理有子页面的场景,比如商品详情页、博客文章、导航站点等。子页面爬取最大的优势,就是能智能采集和整合子页面信息,自动归入主表格。
比如你在看一篇“今日股市”新闻,想采集所有股票报价列表,可以用 。只要定义好表格,系统会自动提取股票列表,再打开每个股票的实时页面,把详细数据合并到主表格。这样你一边看新闻,一边还能同步记录准确数据。Thunderbit 的 AI 网页爬虫能适应不同页面结构,这点是传统爬虫很难做到的。
为什么选择子页面爬取?
Thunderbit AI 网页爬虫有很多提升数据采集效率和准确率的功能。
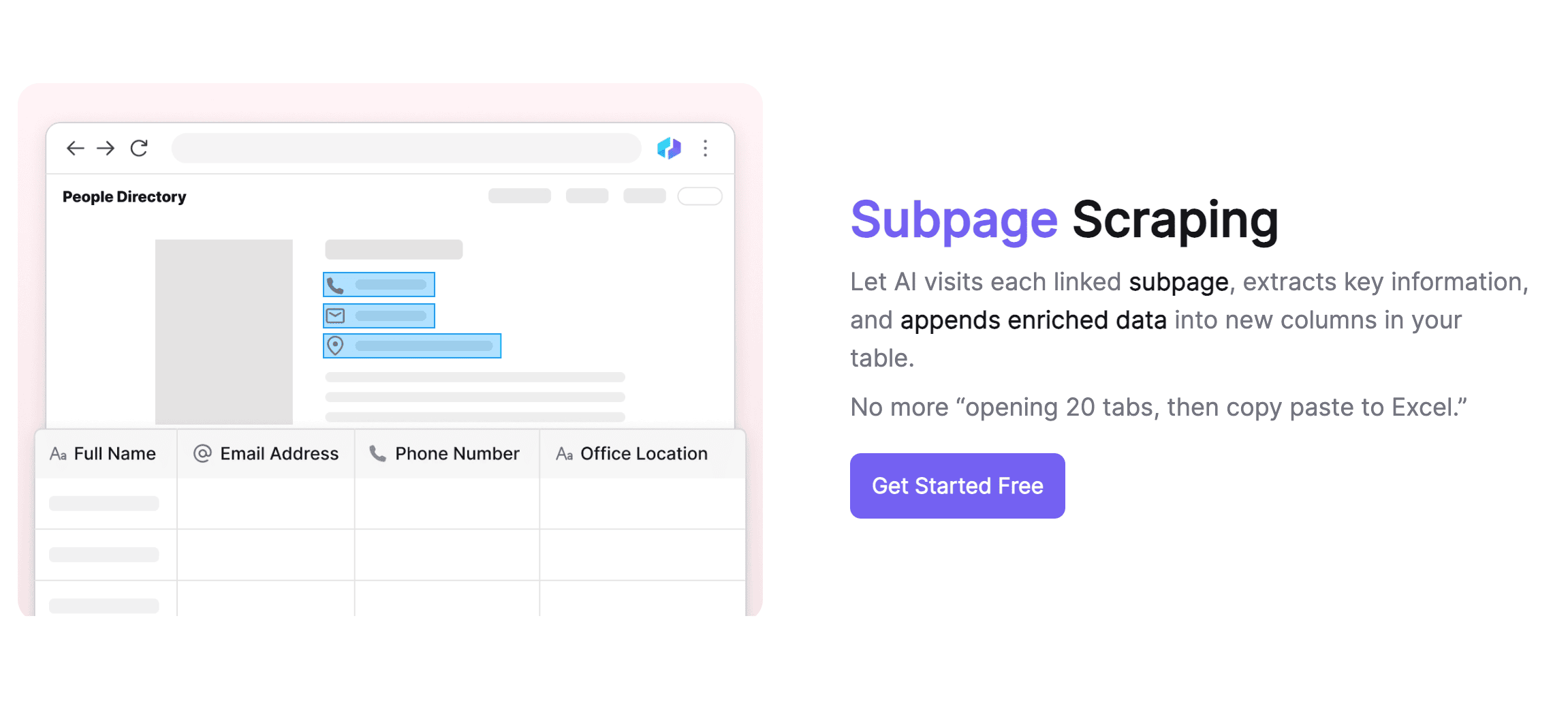
智能数据提取
Thunderbit AI 网页爬虫用 AI 实现智能数据提取,能自动适应网页结构变化。你只需要用自然语言描述想要的数据,系统就能自动生成采集规则。这种智能方式不仅提升了数据准确率,还大大降低了技术门槛,让不会编程的小伙伴也能轻松采集数据。Thunderbit 支持文本、链接、图片等多种数据类型,满足不同需求。
智能子页面处理
Thunderbit 在子页面处理上表现非常出色。它能自动识别并访问子页面,用同一个模板适配不同页面结构。AI 会根据页面变化自动调整采集方式,你不用担心子页面结构不一致。Thunderbit 会自动把子页面内容合并到主表格,帮你更好地整理信息。同时,它还能像 AI 助手一样自动清洗、格式化数据,完成打标签等重复性工作,保证数据质量。
高效数据管理
Thunderbit 提供高效的数据管理功能,支持多种导出格式和平台对接(比如 Google Sheets、Airtable、Notion)。你可以把爬虫模板和 Google 表格关联,采集数据自动归档;也能同步到 Notion 数据库,方便团队协作。灵活的导出方式让你可以根据实际需求选择合适的数据存储方式。自定义数据标签和分类还能自动适配管理平台的数据格式,让后续管理更高效。
实用预设模板
为了提升效率,Thunderbit 提供了丰富的预设模板,覆盖电商数据采集(如 、)、房产信息采集(如 )、社交媒体数据分析(如 、)、企业信息收集(如公司官网、企业名录)等场景。这些模板不仅帮你省下大量时间,还能保证数据采集的一致性和准确性。
操作步骤详解
如何实现子页面爬取
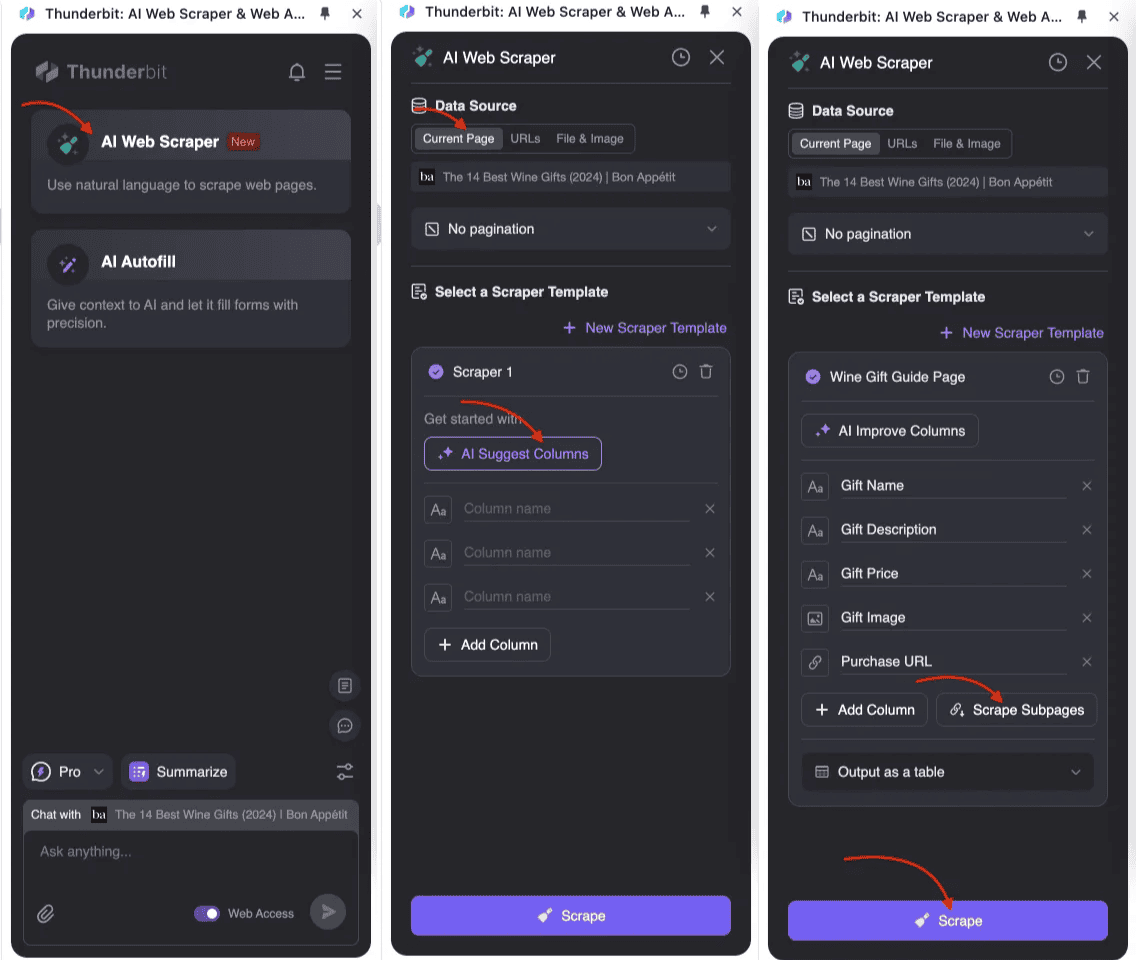
- :打开 Thunderbit AI 网页爬虫,创建新的爬虫模板。
- 定义主表结构:在表格设置里添加需要采集的字段,比如标题、价格、描述等。对于子页面数据,创建对应字段并启用子页面爬取。
- 运行爬虫:Thunderbit 会先从主页面提取列表数据,再自动访问每个子页面,采集详细信息并合并到主表格。整个过程由 AI 驱动,无需复杂编程。
如何实现列表爬取
对于开发者来说,可以用多种编程语言和工具实现列表爬取。Python 因为简单易用、库资源丰富,最受欢迎。下面是一个用 requests 和 BeautifulSoup 实现的基础 Python 示例:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pd
4def scrape_urls(urls):
5 data = []
6 for url in urls:
7 response = requests.get(url)
8 soup = BeautifulSoup(response.text, 'html.parser')
9 titles = soup.find_all('h2', class_='product-title')
10 prices = soup.find_all('span', class_='product-price')
11 for title, price in zip(titles, prices):
12 data.append({
13 'title': title.get_text(),
14 'price': price.get_text()
15 })
16 return pd.DataFrame(data)
17# 示例用法
18urls = ['<http://example.com/product1>', '<http://example.com/product2>']
19data_frame = scrape_urls(urls)
20print(data_frame)总结
在这个时代,数据已经成为企业的核心资产。谁能高效采集和分析数据,谁就能在市场竞争中抢占先机。数据能帮助企业洞察市场趋势和客户需求,为产品开发和营销决策提供有力支撑。但如何高效采集和整理互联网上海量、分散的数据,确实是个大难题。
有了 Thunderbit 这样的工具,企业再也不用为数据采集发愁。它就像一位靠谱的助手,能从庞大的数据中快速找到有价值的信息,让决策更有底气。凭借智能采集和处理能力,企业可以轻松获取竞品信息、市场动态、用户评价等关键数据,助力科学决策。
Thunderbit 不仅有便捷的数据采集功能,还具备强大的数据处理和分析能力。它能自动清洗、结构化采集到的数据,生成直观报告,帮助企业快速发现潜在商机。对于需要定期监控市场变化的企业来说,Thunderbit 的自动化采集功能绝对是省时高效的选择。
在数据驱动的时代,拥有 Thunderbit 这样的工具能极大提升数据采集效率,也为企业数字化转型提供了有力支撑。随着数据在商业决策中的作用越来越大,像 Thunderbit 这样的智能采集工具会成为企业不可或缺的竞争利器。
常见问题解答
-
Thunderbit 是什么? 是一款 Chrome 插件,专为企业用户自动化网页操作而设计。它集成了 AI 网页爬虫、AI 剪贴板、AI 网页助手等功能,支持数据采集、表单自动填写、等多种场景,大大提升工作效率,简化重复性操作。
-
Thunderbit 的 AI 网页爬虫怎么用? Thunderbit 的 AI 网页爬虫通过 AI 技术自动提取网页结构化数据。你只需点击“AI 智能识别字段”,AI 就会自动推荐采集方案,再点“采集”就能拿到数据。它支持采集任意网站、PDF、图片等内容,操作非常简单,只需两步。
-
列表爬取和子页面爬取有什么区别? 列表爬取(批量爬取)是从一组 URL 列表中批量采集数据,适合大型网站。子页面爬取则是在主页面采集列表数据的同时,自动抓取每个子页面的详细信息并合并到主表格。Thunderbit 的 AI 网页爬虫两种方式都支持,还具备智能提取和管理能力。
-
不会编程的人能用 Thunderbit 吗? 当然可以!Thunderbit 设计非常友好,无需编程基础。你只要用自然语言描述想要的数据,系统会自动生成采集规则,零基础也能轻松上手。
-
Thunderbit 支持哪些数据类型? Thunderbit 支持文本、链接、图片等多种数据类型,适用于电商采集、房产信息、社交媒体分析、企业信息收集等多种场景。
-
怎么开始用 Thunderbit? 只需在 下载并安装插件,就能体验 AI 网页爬虫、AI 剪贴板、AI 网页助手等功能,提升网页操作效率。
-
Thunderbit 有预设模板吗? 有的,Thunderbit 提供了丰富的,覆盖电商、房产、社交媒体、企业信息等多种场景,帮你节省时间,保证数据采集一致性和准确性。
-
Thunderbit 如何保证数据质量? Thunderbit 利用 AI 智能提取和处理数据,能自动适应网页结构变化。同时还提供数据清洗、格式化等功能,像 AI 助手一样完成重复性工作,提升数据质量。
-
网页爬虫有哪些应用场景? 有很多实际用途,比如用于市场调研,或做文档分析。 很多企业需要进行分析。现在有了 AI 工具,根本不用写复杂代码,也能。 做社交媒体分析时,可以用或等专用工具,采集营销所需数据。
了解更多: