

如果你曾经好奇,公司是怎么把堆积如山、零散凌乱的原始数据,变成那些精美的仪表盘和由 AI 驱动的洞察的,那你并不孤单。秘诀是什么?一切都从数据摄取开始——它是每一个数据驱动型业务流程最前面的无名英雄。在一个到 2025 年我们将产生181 泽字节的数据的世界里(如果你在数位数,那就是 21 个 0),把数据快速、准确、并以可用格式从 A 点送到 B 点,从来没有像现在这样重要。
我在 SaaS 和自动化领域做了多年,亲眼见过合适的数据摄取策略如何决定一家公司的成败。无论你是在梳理销售线索、监控市场趋势,还是只是想让运营顺畅运转,理解数据摄取的工作方式(以及它如何演变)都是释放真实商业价值的第一步。那就让我们直接开始:什么是数据摄取,为什么它如此重要,以及像Thunderbit这样的现代工具,正在如何改变分析师到创业者的游戏规则?
什么是数据摄取?数据驱动型业务的基础
从本质上说,数据摄取就是把来自多个来源的数据收集、导入并加载到一个中心系统中——比如数据库、数据仓库或数据湖——以便后续分析、可视化,或用于驱动业务决策。你可以把它想象成数据管道的“前门”:所有原材料(电子表格、API、日志、网页、传感器数据流)都要先通过这里进入“厨房”,然后你才能开始烹制洞察。
数据摄取是任何数据管道中的第一步(Montecarlodata),它打破数据孤岛,确保高质量、及时的数据能够用于分析、商业智能和机器学习。没有它,你宝贵的信息就会被困在彼此孤立的系统里——正如一位行业专家所说,“对需要它的人来说不可见”。
它在整体流程中的位置大致如下:
- 数据摄取:从各种来源收集原始数据,并将其送入中心存储库。
- 数据集成:把来自不同来源的数据组合并对齐,让它们能够协同工作。
- 数据转换:清洗、格式化并丰富数据,让它可以直接用于分析。
你可以把摄取想成把你从不同商店买来的所有食材都运回家。集成是把它们整理进储物柜,转换则是备菜和做饭。
为什么数据摄取对现代组织如此重要
现实一点说:在当今商业世界里,及时且摄取良好的数据是一项战略资产。掌握数据摄取的公司,能够打破数据孤岛、获得实时洞察,并更快、更聪明地做决策。反过来,摄取做得不好,就意味着报告缓慢、错失机会,以及基于过时或不完整数据做决定。
如何使用 AI 抓取任何网站 Get Started Free
高效的数据摄取能从这些具体场景中带来商业价值:
| 使用场景 | 高效数据摄取如何提供帮助 |
|---|---|
| 销售线索生成 | 将来自网页表单、社交媒体和数据库的线索近乎实时地整合到一个系统中,让销售团队能更快响应并提升转化率。 |
| 运营仪表盘 | 持续将生产系统中的数据送入分析平台,为管理层提供最新的 KPI,并支持快速纠偏。 |
| 客户 360° 视图 | 整合 CRM、客服、电商和社交媒体中的客户数据,创建统一画像,用于个性化营销和主动服务(Cake.ai)。 |
| 预测性维护 | 摄取高频传感器和 IoT 数据,让分析模型能够识别异常,并在故障发生前预测问题,从而减少停机并节省成本。 |
| 金融风险分析 | 将交易数据和市场数据流输入风险模型,让银行和交易员实时查看敞口,并实现即时欺诈检测。 |
数据不会说谎:97% 的企业已经投资了大数据项目,但这些投入只有在数据能够被成功摄取并且值得信任时,才真正能产生回报。
数据摄取、数据集成与数据转换:把概念理清楚
这些术语很容易让人绕晕,所以我们来捋一捋:
- 数据摄取:从源系统收集并导入原始数据的第一步。可以理解为:“先把所有东西搬进厨房。”
- 数据集成:把来自不同来源的数据组合并对齐,确保一致性和统一视图。可以理解为:“把储物柜整理好。”
- 数据转换:把数据从原始形态变成可用形态——清洗、格式化、汇总并丰富它。可以理解为:“备菜并做饭。”
一个常见误解是,摄取和 ETL(提取、转换、加载)是一回事。实际上,摄取只是“提取”这一部分——把原始数据拉进来。接下来才是集成和转换,让数据可以用于分析(Astera)。
这为什么重要?如果你只是想从网页上快速拿到一份数据集,一个轻量级的数据摄取工具可能就够了。但如果你要把来自五套不同系统的数据整合并清洗,那你还需要数据集成和数据转换。
传统数据摄取方式:ETL 及其局限
几十年来,数据摄取的首选方式一直是ETL(提取、转换、加载)。数据工程师会编写脚本,或者使用专用软件,定期从源系统拉取数据,清洗和格式化后,再加载到数据仓库里。通常这会按批次运行——比如每晚更新一次。
但随着数据在规模和种类上的爆炸式增长,传统 ETL 开始显露出年代感:
- 设置复杂、耗时:构建和维护 ETL 管道需要大量编码和专业技能。非技术团队只能等 IT 把一切配置好(Medium)。
- 批处理瓶颈:ETL 作业以批次运行,导致数据可用性滞后。在一个洞察越快越有价值的世界里,等几个小时甚至几天根本不够用(SumaSoft)。
- 扩展性和速度问题:传统管道往往难以应对如今海量的数据量,需要不断调优和升级。
- 僵硬且缺乏灵活性:新增数据源或修改 schema 往往很麻烦,容易破坏管道或需要大改。
- 维护成本高:管道可能因为各种原因失败,需要工程师持续盯着。
- 只适合结构化数据:经典 ETL 是为规整的行和列设计的,不适合如今占据90% 新数据的那种杂乱、非结构化数据(比如网页或图片)。
简而言之:ETL 在更简单的年代很强,但它已经越来越跟不上现代数据的速度、规模和多样性了。
现代数据摄取的兴起:由 AI 驱动的自动化方案
新的时代来了:现代数据摄取工具借助自动化、云端弹性扩展和 AI,让数据收集更快、更简单,也更灵活。
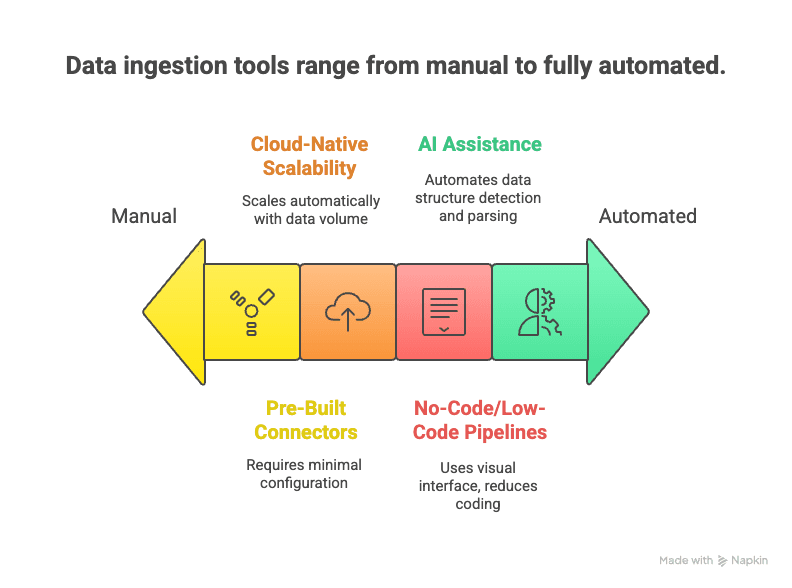
它们的优势在于:
- 无代码/低代码管道:拖拽式界面和 AI 助手让用户无需编写代码就能搭建数据流(Medium)。
- 预置连接器:针对常见数据源提供数百种现成连接器——你只要输入凭据就能开始。
- 云原生弹性扩展:弹性云服务可以实时处理海量数据流(Databricks)。
- 实时和流式支持:现代工具同时支持流式和批量摄取,你可以按需选择(Cake.ai)。
- AI 辅助:AI 可以自动识别数据结构、推荐解析规则,甚至实时进行数据质量检查(Cake.ai)。
- 支持非结构化数据:NLP 和计算机视觉技术可以把杂乱的网页、PDF 或图片转换成结构化表格。
- 维护更少:托管服务会负责监控、扩容和更新——这样你就能专注于使用数据,而不是照看管道。
结果是什么?数据摄取更容易搭建、更容易修改,也更能应对今天这个数据世界的疯狂复杂性。
数据摄取实战:行业应用与挑战
让我们看看数据摄取在真实世界中是怎么落地的,以及不同行业会遇到什么挑战。
零售与电商
零售商会摄取来自收银系统、在线商店、会员应用,甚至门店传感器的数据。通过整合销售交易、网站点击流和库存日志,他们可以实时查看库存水平和购买趋势。挑战是什么?要处理高频、大体量的数据(尤其是在购物高峰期),并整合线上和线下渠道的数据。
金融与银行
银行和交易公司会摄取来自交易、市场数据流和客户互动的数据。实时摄取对于欺诈检测和风险管理至关重要。但在严格的合规和安全要求下,摄取流程中任何小问题都可能带来严重后果。
科技与互联网公司
科技巨头会摄取海量实时事件流(每一次点击、点赞或分享),用来分析用户行为并驱动推荐引擎。规模非常大,挑战在于从噪声中筛选信号——确保数据质量和一致性。
医疗健康
医院会摄取来自电子病历、检验系统和医疗设备的数据,以创建统一的患者记录并支持预测分析。最大的难点是什么?系统互操作性(不同系统讲着不同“语言”)以及患者隐私。
房地产
房地产公司会摄取来自房源平台、房产网站和公共记录的数据,来构建全面数据库。挑战在于整合来自多种来源的数据——而且往往是非结构化数据——并在房源快速变化时保持数据新鲜。
各行业普遍面临的挑战包括:
- 处理多样化数据(结构化、半结构化、非结构化)
- 在实时与批处理需求之间取得平衡
- 确保数据质量和一致性
- 满足安全和合规要求
- 扩展以应对不断增长的数据量
克服这些挑战,是释放更好业务成果的关键——更准确的分析、实时决策,以及更强的合规能力。
Thunderbit:用 AI 网页爬虫简化数据摄取
现在我们来看看 Thunderbit 在这个版图里扮演什么角色。Thunderbit 是一款由 AI 驱动的网页爬虫 Chrome 扩展,旨在让每个人都能轻松完成网页数据摄取——哪怕你一点代码都不会。
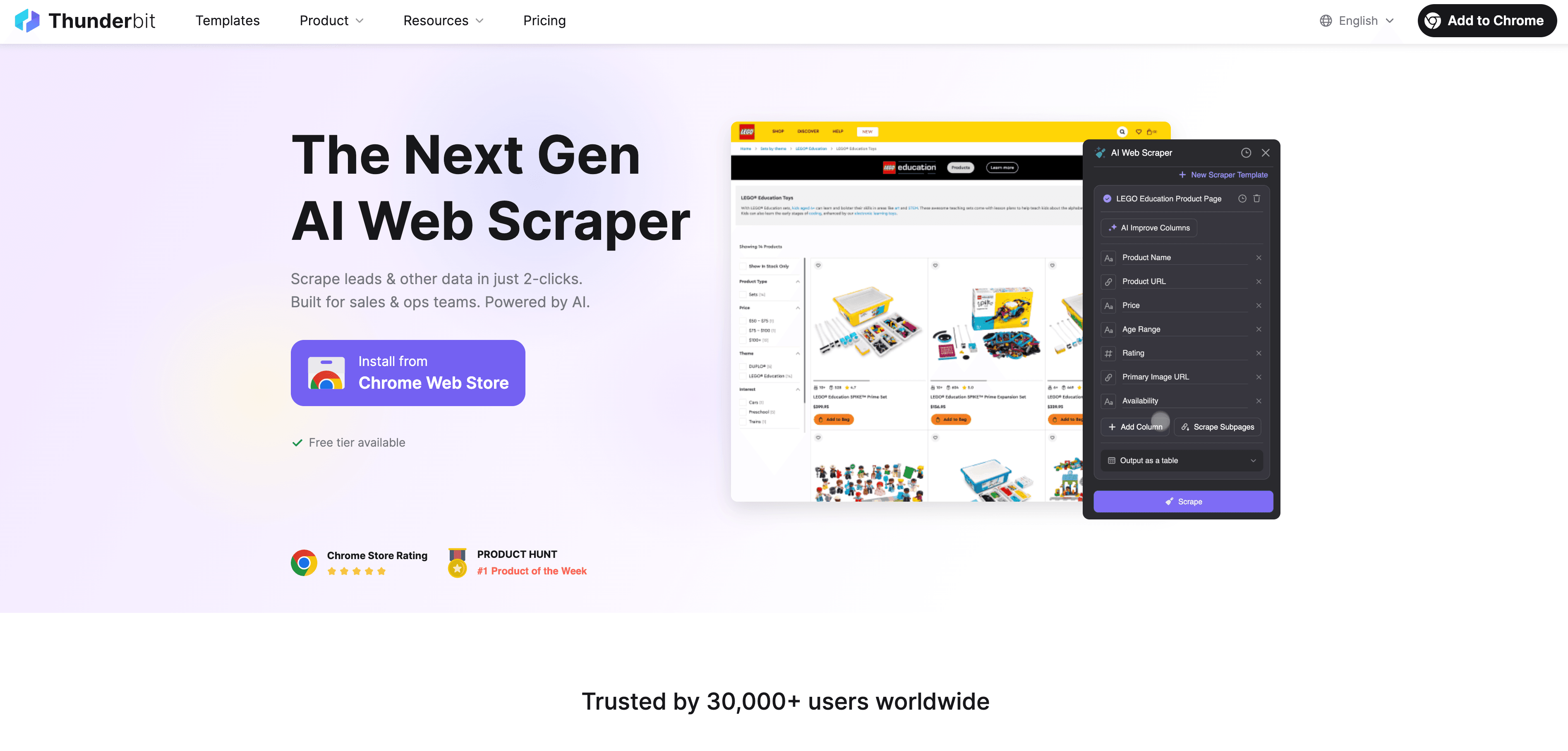
Thunderbit 对商业用户来说为什么是个改变游戏规则的工具?
- 2 次点击网页爬取:两次点击,就能把杂乱网页变成结构化数据集。先点“AI 推荐字段”,再点“爬取”——就完成了。
- AI 字段建议:Thunderbit 的 AI 会读取页面,并推荐最适合提取的列,无论你是在看企业目录、商品列表还是领英个人资料。
- 自动子页面爬取:需要更多细节?Thunderbit 可以自动访问每个子页面(比如商品详情页或单独的个人资料页),并丰富你的表格。
- 分页处理:它能处理分页列表和无限滚动页面,这样你就不会漏掉任何数据。
- 预置模板:针对 Amazon、Zillow 或 Shopify 这类热门网站,Thunderbit 提供一键模板,无需设置。
- 免费导出数据:可直接将数据导出到 Excel、Google Sheets、Airtable 或 Notion,无需额外付费。
- 定时爬取:你可以设置按任意时间间隔自动运行爬取任务(比如每天检查竞品价格)。
- AI 自动填表:还能自动化表单填写和重复性网页任务。
Thunderbit 非常适合销售团队抓取线索、电商分析师监控价格,或房地产经纪人收集房源信息。它的核心,就是把非结构化网页数据快速变成可执行的洞察。
如果你想看看 Thunderbit 的实际效果,可以访问我们的YouTube 频道,或者浏览我们的博客获取更多指南。
对比数据摄取方案:传统方式 vs. 现代方式
下面是一个快速对照表:
| 对比维度 | 传统 ETL 工具 | 现代 AI/云工具 | Thunderbit(AI 网页爬虫) |
|---|---|---|---|
| 用户技能要求 | 高(需要编码/IT) | 中等(低代码,需一些配置) | 低(2 次点击,无需编码) |
| 数据来源 | 结构化(数据库、CSV) | 广泛(数据库、SaaS、API) | 任意网站、非结构化数据 |
| 部署速度 | 慢(数周/数月) | 更快(数天) | 即时(几分钟) |
| 实时支持 | 有限(批处理) | 很强(流式/批处理) | 按需与定时 |
| 可扩展性 | 有挑战 | 高(云原生) | 中高(云端爬取) |
| 维护 | 高(管道脆弱) | 中等(托管服务) | 低(AI 可适应变化) |
| 转换能力 | 刚性、前置 | 灵活、后置 | 基础(AI 字段提示) |
| 最佳使用场景 | 内部批量集成 | 分析管道 | 网页数据、外部来源 |
结论是什么?要根据任务选工具。对于网页数据或非结构化来源,Thunderbit 往往是最快、最省事的选择。
数据摄取的未来:自动化与云优先策略
展望未来,数据摄取只会变得更智能、更自动化。以下是接下来的趋势:
- 默认实时化:过去那种批处理范式正在退场。越来越多的管道正在为实时、事件驱动型数据而构建(Cake.ai)。
- 云优先与“零 ETL”:云平台正在让源和目标之间的连接更容易,不再依赖手工搭建管道。
- AI 驱动的自动化:机器学习将在管道配置、监控和优化中扮演更大角色——识别异常、修正错误,甚至实时丰富数据。
- 无代码与自助式:更多工具会让业务用户通过自然语言或可视化界面来搭建数据流。
- 边缘与 IoT 摄取:随着更多数据在边缘侧产生,摄取会更靠近数据源进行,并配合智能过滤和聚合。
- 治理与元数据:自动标记、血缘追踪和合规能力会内嵌到每一步。
一句话总结:未来的方向是让数据摄取更快、更易用、更可靠——这样你就可以把精力放在洞察上,而不是基础设施上。
结论:给业务用户的关键要点
如何使用 Thunderbit 掌握自动化数据爬取 Get Started Free
- 数据摄取是任何数据驱动项目的关键第一步。如果你想要洞察,就必须先把数据导进来——而且要快、要稳。
- 像 Thunderbit 这样的现代 AI 工具,让数据摄取不再只是 IT 专家的事。通过 2 次点击爬取、AI 字段建议和定时任务,你可以把凌乱的网页数据变成商业金矿。
- 选对工具很重要:对稳定、结构化的内部数据,用传统 ETL;对广泛的分析场景,用现代云工具;对网页和非结构化数据,用 Thunderbit。
- 跟上时代:自动化、云和 AI 正在让数据摄取更聪明、更简单。别困在过去——去探索新方案,让你的数据策略面向未来。
常见问题
1. 用大白话说,什么是数据摄取?
数据摄取就是把来自各种来源(比如网站、数据库或文件)的数据收集并导入到一个中心系统中,以便分析或用于业务决策。它是任何数据管道中的第一步。
2. 数据摄取和数据集成、数据转换有什么区别?
数据摄取是把原始数据导进来。数据集成是把来自不同来源的数据组合并对齐,而数据转换则是清洗和格式化数据,让它适合分析。可以理解为:摄取 = 收集,集成 = 整理,转换 = 备菜和做饭。
3. 传统数据摄取方式最大的挑战是什么?
像 ETL 这样的传统方法搭建慢、需要大量编码、难以处理非结构化数据,也跟不上今天对实时性的需求。它们还维护成本高,而且当数据源变化时缺乏灵活性。
4. Thunderbit 如何让数据摄取更简单?
Thunderbit 通过 AI 让任何人都能在两次点击内抓取并结构化网页数据,无需编程。它可以处理子页面、分页,甚至能安排周期性任务,并可直接导出到 Excel、Google Sheets、Airtable 或 Notion。
5. 数据摄取的未来会怎样?
未来会围绕自动化、云优先策略和 AI 驱动的管道展开。你会看到更多实时数据流、更智能的错误处理,以及让业务用户通过自然语言或可视化界面搭建数据摄取




