

网页爬虫已经成了各行各业提升效率的“秘密武器”——不管你是做销售、运营、电商还是房产,谁都离不开数据。互联网上信息量巨大,但想要高效地把这些数据抓下来,尤其是面对那些动态加载、交互性强的网站,真不是件容易事。预计到 2025 年,网页爬虫相关市场规模将逼近 $490 亿美元,而且超过 90% 的企业 已经把数据分析当作决策的核心。但问题来了:随着网站越来越复杂,比如无限滚动、弹窗、JavaScript 动态内容,传统爬虫工具经常会卡壳。
用 AI 从任意网站抓取数据 Get Started Free
这时候,Selenium 就像“网页爬虫界的瑞士军刀”一样登场了。它能自动化操作真实浏览器,帮你搞定那些“难缠”的动态网站。如果你曾经想过“要是能像真人一样点点页面、把数据都抓下来就好了”,那 Selenium 就是你的理想搭档。接下来我会带你系统掌握 selenium 网页爬虫的核心技能——不用计算机专业背景也能轻松上手。
什么是 Selenium 网页爬虫?一看就懂的入门介绍
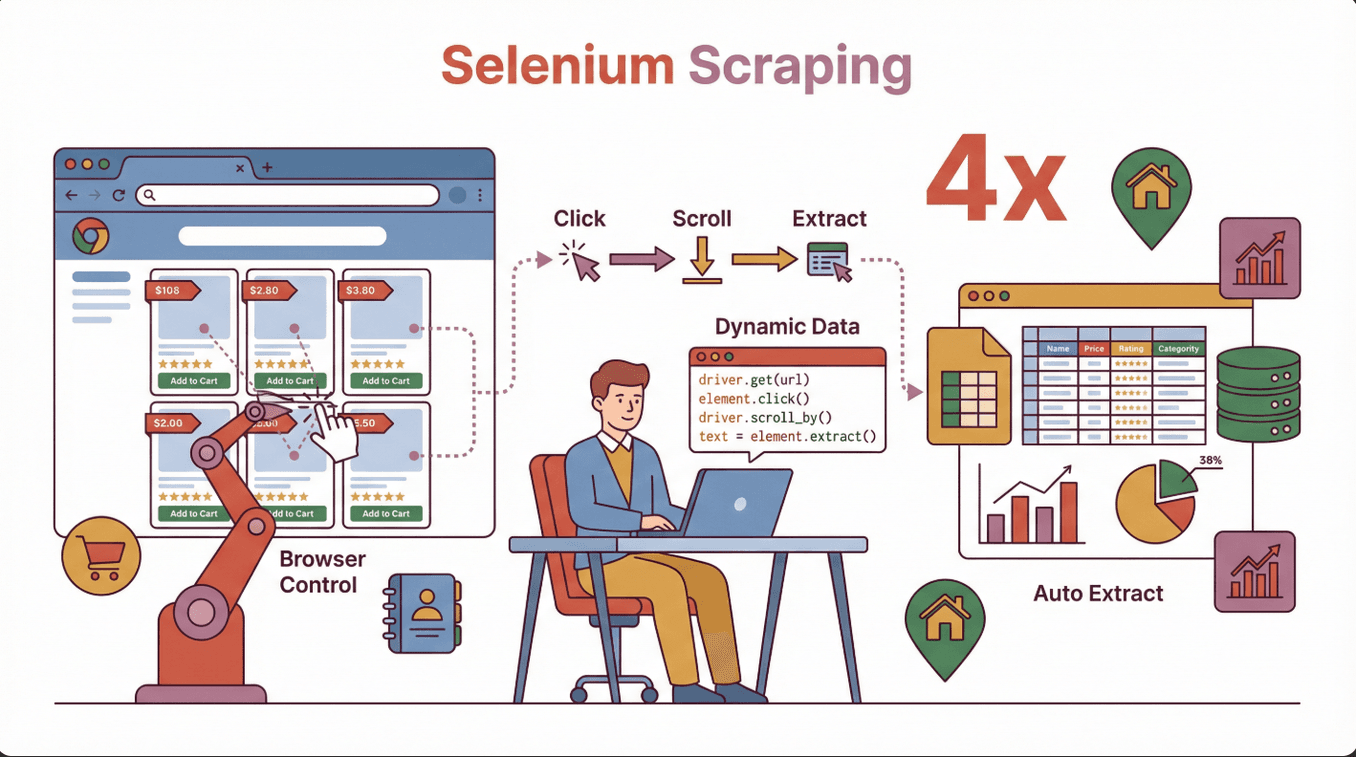 简单来说,用 Selenium 做网页爬虫,就是用 Selenium 库写代码控制真实浏览器(比如 Chrome 或 Firefox),模拟人类的各种操作——点按钮、填表单、滚动页面等等。和只能读静态 HTML 的传统爬虫不一样,Selenium 能像真人一样和网页互动,非常适合抓取那些靠 JavaScript 动态加载内容的数据。
简单来说,用 Selenium 做网页爬虫,就是用 Selenium 库写代码控制真实浏览器(比如 Chrome 或 Firefox),模拟人类的各种操作——点按钮、填表单、滚动页面等等。和只能读静态 HTML 的传统爬虫不一样,Selenium 能像真人一样和网页互动,非常适合抓取那些靠 JavaScript 动态加载内容的数据。
Selenium 适合的业务场景:
- 电商行业: 抓取商品列表、价格、评论等,尤其是需要滚动加载的页面。
- 销售与获客: 从需要登录或多步操作的目录网站提取联系方式。
- 房产领域: 获取带有弹窗或交互地图的房源信息。
- 市场调研: 收集竞品数据,尤其是现代化、交互性强的网站。
如果你用过爬虫却发现总是漏掉一半数据,很可能是因为这些信息在页面初次加载后才通过 JavaScript 动态生成——Selenium 能像用户一样等待、点击、交互,把这些数据都抓下来(参考 BrowserStack)。
为什么选择 Selenium 做网页爬虫?主流工具对比
市面上网页爬虫工具不少,比如 BeautifulSoup、Scrapy、Thunderbit 等。那为什么要选 Selenium?下面这份对比表一目了然:
| 工具 | 最适合场景 | 支持 JavaScript? | 交互能力 | 速度 | 易用性 |
|---|---|---|---|---|---|
| Selenium | 动态、交互性强的网站 | 支持 | 完全 | 较慢 | 中等 |
| BeautifulSoup | 简单、静态 HTML 页面 | 不支持 | 无 | 很快 | 简单 |
| Scrapy | 大规模、静态或半动态网站 | 有限(需插件) | 有限 | 非常快 | 中等 |
| Thunderbit | 商业用户无代码快速提取 | 支持(AI 驱动) | 有限 | 快 | 非常简单 |
Selenium 的优势:
- 能搞定大量 JavaScript 动态内容、无限滚动和弹窗。
- 可以模拟登录、点击、填表单等复杂操作。
- 适合抓取需要用户交互后才显示的数据。
适合用 Selenium 的场景:
- 目标数据在页面加载后才出现(比如 JavaScript 渲染)。
- 需要和网站交互(登录、点击、滚动等)。
- 网站结构复杂,或者用的是单页应用(SPA)框架。
适合用其他工具的场景:
- 网站内容静态且简单——用 BeautifulSoup 或 Scrapy 更快。
- 想要无代码、面向业务的工具——Thunderbit 适合快速提取(参考 Thunderbit Blog)。
Selenium 安装与配置:零基础快速上手
刚接触 Selenium 可能觉得有点复杂,其实操作很简单,按下面步骤来就行:
1. 安装 Python(如果还没装)
Selenium 最常用 Python,也支持 Java、C# 等。去 python.org 下载就行。
2. 用 pip 安装 Selenium
打开终端或命令行,输入:
pip install selenium
(参考 BrowserStack)
3. 下载浏览器驱动
Selenium 需要“驱动”来控制浏览器。Chrome 用 ChromeDriver,Firefox 用 GeckoDriver。
- 查浏览器版本: 打开 Chrome,访问
chrome://settings/help。 - 下载对应驱动: ChromeDriver 下载地址。
- 解压并配置路径: 把驱动放到某个文件夹,并把路径加到系统 PATH 环境变量。
小贴士: 驱动版本必须和浏览器版本一致,否则会报错,比如 chromedriver executable needs to be available in the path(参考 Stack Overflow)。
4. 测试环境是否配置成功
在 Python 里运行:
from selenium import webdriver
driver = webdriver.Chrome() # 或 Firefox()
driver.get("https://www.google.com")
print(driver.title)
driver.quit()
如果浏览器能打开并输出标题,说明配置没问题!
常见问题排查:
- PATH 没设置好——检查环境变量。
- 驱动和浏览器版本不匹配——记得同步更新。
- 权限问题——Mac/Linux 需执行
chmod +x chromedriver。
Selenium 爬虫实战:从零写出你的第一个脚本
下面以抓取电商网站商品名称为例,手把手教你写一个简单的 selenium 网页爬虫:
1. 导入 Selenium 并初始化驱动
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
2. 打开目标网页
driver.get("https://example-ecommerce.com/products")
3. 等待内容加载(针对动态页面)
用显式等待:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.CLASS_NAME, "product-title")))
4. 提取数据
products = driver.find_elements(By.CLASS_NAME, "product-title")
for product in products:
print(product.text)
5. 关闭浏览器
driver.quit()
原理说明: Selenium 打开浏览器,等商品加载出来,找到所有 class 为 product-title 的元素,然后输出文本内容。
动态内容爬取技巧:Selenium 实用操作
现在的网站大多是动态加载,比如无限滚动、弹窗、点击后才显示内容。可以这样应对:
1. 等待元素出现
页面内容加载有延迟时,用显式等待:
wait.until(EC.presence_of_element_located((By.ID, "dynamic-content")))
2. 滚动页面加载更多内容
针对无限滚动页面:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
多执行几次就能加载更多数据。
3. 处理弹窗
查找并关闭弹窗:
try:
close_button = driver.find_element(By.CLASS_NAME, "close-popup")
close_button.click()
except:
pass # 没有弹窗时忽略
4. 操作表单和按钮
比如填写搜索框、点击“下一页”按钮:
search_box = driver.find_element(By.NAME, "search")
search_box.send_keys("laptop")
search_box.submit()
实际案例: 比如抓取房产网站的滚动加载房源,或者点击标签后显示的商品评论。
常见问题与排查:Selenium 爬虫避坑指南
就算是老司机也会遇到各种问题,下面是常见故障和解决方法:
| 问题 | 解决方法 |
|---|---|
| 找不到元素 | 用等待、检查选择器、换种定位方式 |
| 超时错误 | 增加等待时间,看看是不是内容加载慢 |
| 验证码或反爬虫 | 降低请求频率、随机操作、用代理 |
| 驱动/浏览器不匹配 | 同步更新到兼容的最新版本 |
| 网站结构变化 | 定期更新选择器并测试脚本 |
| 运行慢 | 减少浏览器操作,尽量用无头模式 |
小贴士: Selenium 因为模拟真实用户操作,速度比其他工具慢(参考 Reddit)。大规模任务建议分批处理或考虑其他方案。
数据导出与业务集成:让爬取结果真正用起来
数据抓下来后,怎么高效利用?推荐这样做:
1. 存储为列表或 DataFrame
import pandas as pd
data = []
for product in products:
data.append({"name": product.text})
df = pd.DataFrame(data)
2. 导出为 CSV 或 Excel
df.to_csv("products.csv", index=False)
# 或
df.to_excel("products.xlsx", index=False)
(参考 GeeksforGeeks)
3. 集成到业务工具
- 把 CSV 导入 Google Sheets 或 Airtable。
- 用 Zapier 或 API 自动化数据流转。
建议: 导入前先清洗格式不一致或缺失的数据(参考 Thunderbit Blog)。
Selenium + Thunderbit:复杂数据提取的黄金组合
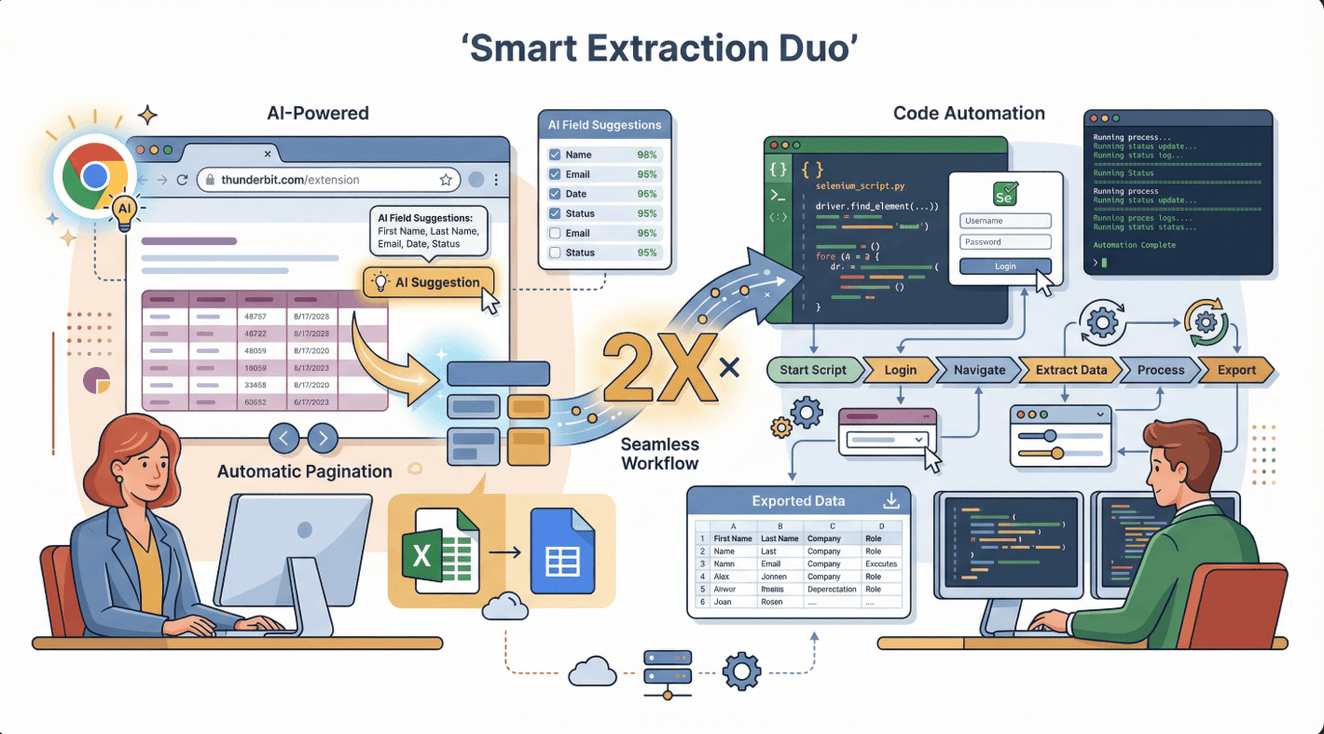 说实话,Selenium 虽然强大,但不是所有场景都最省时省力。这时候,Thunderbit 就能帮你一把。Thunderbit 是一款 AI 网页爬虫 Chrome 插件,只需几步点击就能从大多数网站提取数据——不用写代码,也不用折腾配置。
说实话,Selenium 虽然强大,但不是所有场景都最省时省力。这时候,Thunderbit 就能帮你一把。Thunderbit 是一款 AI 网页爬虫 Chrome 插件,只需几步点击就能从大多数网站提取数据——不用写代码,也不用折腾配置。
怎么搭配用?
- Thunderbit 适合快速抓取表格、列表、简单页面的结构化数据,非常适合销售、电商、调研等团队。
- Selenium 适合需要自动化复杂交互(比如登录、多步操作、动态内容)的场景。
高效工作流: 先用 Thunderbit 处理简单部分,遇到登录或复杂交互时再用 Selenium 补充。你甚至可以把 Thunderbit 导出的数据作为 Selenium 脚本的输入,做更深层处理。
Thunderbit 优势:
- AI 智能字段推荐——点“AI 建议字段”就能自动识别。
- 支持分页、子页面,直接导出到 Excel、Google Sheets、Notion、Airtable。
- 无需维护——AI 自动适应网站变化(参考 Thunderbit Blog)。
合规与道德:用 Selenium 做网页爬虫要注意什么?
网页爬虫虽强大,但也要守规矩。合规建议如下:
1. 查看网站服务条款
爬取前一定要看目标网站的服务条款。有些网站明令禁止爬虫,有些允许个人用途(参考 RoboRabbit)。
2. 遵守 robots.txt
robots.txt 文件会说明哪些内容允许被爬取。可以在 https://website.com/robots.txt 查看(参考 RoboRabbit)。
3. 避免抓取敏感或个人数据
不要爬取健康、金融、隐私等敏感信息,否则可能涉及法律风险(参考 RoboRabbit)。
4. 合理请求频率,主动标识身份
不要高频访问导致服务器压力过大,适当设置延迟,并在可能时标明爬虫身份。
5. 优先使用官方 API
如果网站有公开 API,优先用,最安全可靠。
合规爬虫清单:
- 阅读并遵守网站服务条款和 robots.txt。
- 只抓取公开、非敏感数据。
- 控制请求频率,别影响网站正常运行。
- 如需注明数据来源,务必标注。
- 关注本地法律法规动态(参考 Apify Blog)。
需要扩展时,何时考虑替代 Selenium?
Selenium 适合中小规模任务,但也有局限:
局限性:
- 速度比其他工具慢(因为要跑真实浏览器)。
- 占用资源大——同时开多个浏览器会拖慢电脑。
- 不适合大批量(成千上万页面)快速抓取。
升级时机:
- 需要大规模爬取(成千上万页面)。
- 需要云端或定时自动化爬取。
- 需要高级功能,比如代理轮换、自动重试、分布式爬虫等。
可选方案:
- Thunderbit: 适合业务用户,AI 无代码快速爬取(参考 Thunderbit Pricing)。
- Scrapy: 适合开发者构建大规模、分布式爬虫(参考 Oxylabs)。
- 托管 API: 比如 ScraperAPI、Apify,适合无需维护、可扩展的爬虫服务(参考 ScrapingBee)。
| 工具 | 最适合场景 | 优点 | 缺点 |
|---|---|---|---|
| Selenium | 复杂、交互性强的网站 | 适用所有网站,完全可控 | 速度慢、资源消耗大 |
| Thunderbit | 快速、业务用户 | 无需代码、AI 智能、导出便捷 | 高级定制能力有限 |
| Scrapy | 大规模、开发团队 | 快速、可扩展、可定制 | 需编程、交互性弱 |
| 托管 API | 企业级、自动化 | 可扩展、免维护 | 成本高、灵活性有限 |
总结与核心要点
用 Selenium 做网页爬虫,是搞定动态、交互性网站数据的利器。它能模拟真实用户操作,适合需要点击、滚动、登录等复杂流程的场景。记住这些要点:
- Selenium 适合: 动态网站、JavaScript 内容、交互式流程。
- 安装建议: 驱动和浏览器版本要匹配,PATH 配置正确,动态内容用等待机制。
- 搭配 Thunderbit: 简单任务用 Thunderbit 快速无代码爬取,复杂流程用 Selenium 补充。
- 合规操作: 遵守网站条款、robots.txt,避免敏感数据。
- 大规模任务: 建议用托管 API 或云端工具。
新手建议先用 Selenium 写个简单脚本抓商品名称或价格,再试试 Thunderbit,体验 AI 网页爬虫带来的高效与便捷——免费试用,帮你省下大量手工整理时间(Thunderbit Chrome 插件下载页)。
想深入学习?欢迎访问 Thunderbit Blog 获取更多网页爬虫教程,或订阅我们的 YouTube 频道 看视频教学。
常见问题解答
1. Selenium 和其他网页爬虫工具有何不同?
Selenium 能控制真实浏览器,支持和动态、JavaScript 密集型网站交互——这是 BeautifulSoup 等传统爬虫做不到的。适合需要点击、登录等用户操作的网站。
2. 配置 Selenium 最常见的错误有哪些?
主要问题有浏览器和驱动版本不匹配、驱动没加到 PATH、没对动态内容设置等待。一定要检查版本并用显式等待。
3. Selenium 和 Thunderbit 可以一起用吗?
当然可以。Thunderbit 适合快速无代码爬取,Selenium 适合复杂交互流程。很多团队会用 Thunderbit 抓简单数据,用 Selenium 处理高级任务。
4. 用 Selenium 做网页爬虫合法吗?
只要遵守网站条款、robots.txt、不抓敏感数据、不影响服务器,网页爬虫是合法的。记得关注本地法律法规,合理合规使用。
5. 什么时候需要考虑替代 Selenium?
如果需要大规模、快速爬取或云端自动化,建议用 Thunderbit、Scrapy 或托管 API。Selenium 更适合中小规模、交互性强的任务。
准备好掌握网页爬虫了吗?下一个项目就用 Selenium 试试吧——也别忘了体验 Thunderbit,让你轻松高效获取业务数据。
试用 AI 网页爬虫 Get Started Free
延伸阅读




