

让我们把时间拨回到不算太久以前:我坐在办公桌前,手里端着咖啡,盯着一张比周日晚上冰箱还空的表格。销售团队要竞品定价数据,市场团队要新鲜线索,运营团队则昨天就想要从十几个网站抓来的商品列表。我知道数据就在那里,但真正难的是怎么把它弄到手。如果你也曾经历过一边复制粘贴、一边像在玩数字版打地鼠,那你绝对不是一个人。
快进到今天,局面已经大不一样了。网页爬虫已经从极客的小项目,变成了核心业务策略。JavaScript 和 Node.js 现在站在舞台中央,既能跑一次性的脚本,也能支撑完整的数据管道。但问题在于:工具虽然比以往都强大,学习曲线却还是像穿着拖鞋去爬珠穆朗玛峰。无论你是业务用户、数据爱好者,还是单纯受够了手动录入数据的人,这篇指南都适合你。我会帮你拆解整个生态、核心库、常见痛点,以及为什么有时候,最聪明的做法就是让 AI 来干重活。
为什么 JavaScript 和 Node.js 网页爬虫对业务很重要
先说“为什么”。到了 2026 年,网页数据已经不只是加分项,而是决定成败的关键。根据最新研究,73% 的公司认为公共网页数据帮助他们更快、更准确地做决策,而且大约42% 的企业数据预算已经用于网页数据采集。替代数据市场(其中就包括网页爬虫)已经是一个49 亿美元的行业,而且还在快速增长。
那这股热潮到底由什么驱动?下面是一些最常见的业务场景:
- 竞争定价与电商: 零售商会抓取竞品网站的价格和库存信息,有时还能把销售额提升4% 以上。
- 线索生成与销售情报: 销售团队自动采集目录网站和社交平台上的邮箱、电话号码和公司信息。
- 市场研究与内容聚合: 分析师提取新闻、评论和情绪数据,用于发现趋势和做预测。
- 广告与广告技术: 广告技术公司实时追踪广告投放位置和竞品活动。
- 房地产与旅游: 机构抓取房源、价格和评价,用于估值模型和市场分析。
- 内容与数据聚合平台: 平台整合多个来源的数据,支撑比价工具和仪表盘。
JavaScript 和 Node.js 已经成了这些任务的首选技术栈,尤其是越来越多网站都依赖动态的 JavaScript 渲染内容。Node.js 擅长异步操作,非常适合大规模爬取。再加上蓬勃发展的库生态,你可以做出从快速脚本到生产级爬虫的各种方案。
什么是数据爬取,以及如何在 2025 年完成它 Get Started Free
核心工作流程:JavaScript 和 Node.js 网页爬虫是怎么工作的
我们先把典型的网页爬虫流程讲清楚。无论你抓的是一个简单博客,还是一个大量使用 JavaScript 的电商网站,步骤都大同小异:
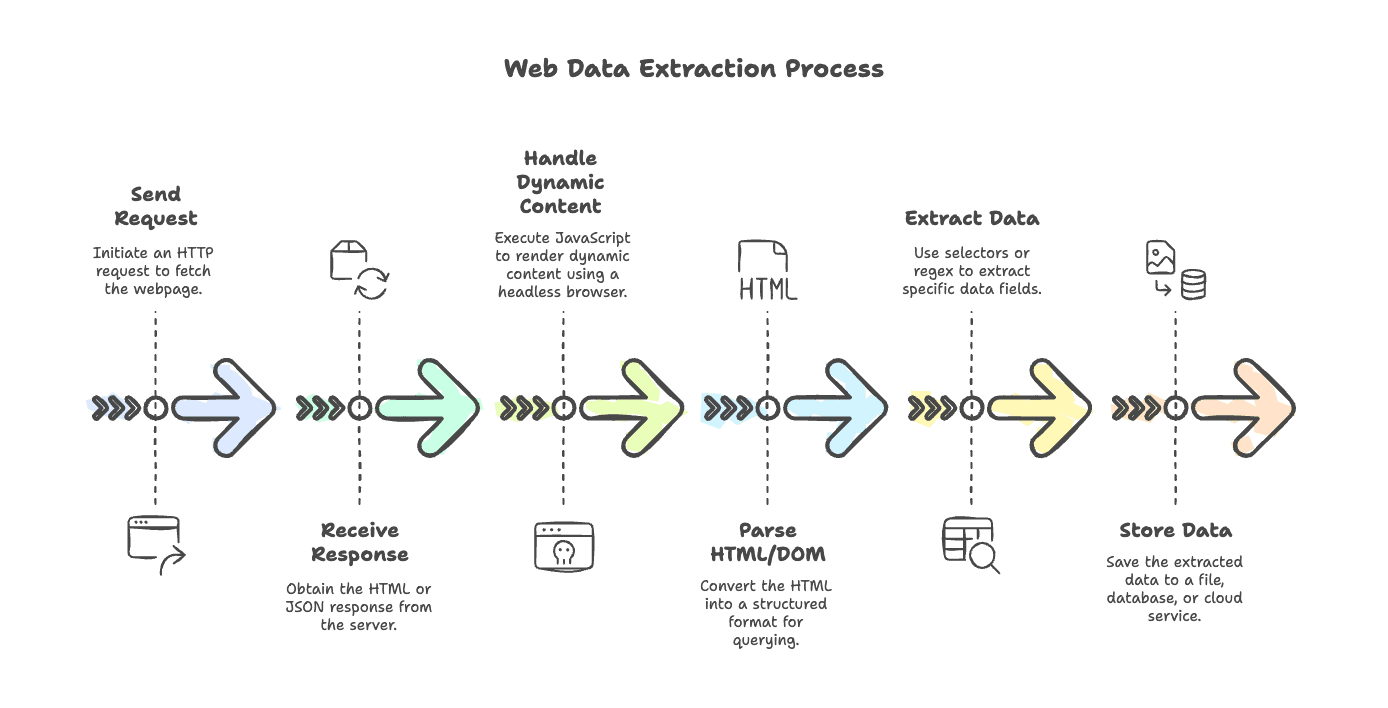
- 发送请求: 使用 HTTP 客户端抓取页面(比如
axios、node-fetch或got)。 - 接收响应: 从服务器返回 HTML(有时也可能是 JSON)。
- 处理动态内容: 如果页面由 JavaScript 渲染,就用无头浏览器(如 Puppeteer 或 Playwright)执行脚本并获取最终内容。
- 解析 HTML/DOM: 使用解析器(
cheerio、jsdom)把 HTML 转成可查询的结构。 - 提取数据: 用选择器或正则表达式提取所需字段。
- 存储数据: 把结果保存到文件、数据库或云服务中。
每一步都有各自的工具和最佳实践,下面我们会逐个展开。
JavaScript 网页爬虫必备的 HTTP 请求库
任何爬虫的第一步都是发起 HTTP 请求。Node.js 提供了丰富的选择——既有经典方案,也有现代方案。下面我们来看看最常用的库:
1. Axios
一个面向 Node 和浏览器的 Promise 型 HTTP 客户端。它几乎就是大多数爬虫需求的“瑞士军刀”。
const axios = require('axios');
const response = await axios.get('https://example.com/api/items', { timeout: 5000 });
console.log(response.data);
优点: 功能丰富,支持 async/await,自动解析 JSON,支持拦截器和代理。
缺点: 稍重一些,有时对数据处理方式显得有点“魔法”。
2. node-fetch
在 Node.js 中实现了浏览器的 fetch API。轻量、现代。
import fetch from 'node-fetch';
const res = await fetch('https://api.github.com/users/github');
const data = await res.json();
console.log(data);
优点: 轻便,API 熟悉,适合从前端 JavaScript 转过来的人。
缺点: 功能较少,错误处理要手动写,代理配置比较啰嗦。
3. SuperAgent
一款老牌 HTTP 库,支持链式调用。
const superagent = require('superagent');
const res = await superagent.get('https://example.com/data');
console.log(res.body);
优点: 成熟,支持表单、文件上传、插件。
缺点: API 感觉有点旧,依赖体积也更大。
4. Unirest
一个简单、语言无关的 HTTP 客户端。
const unirest = require('unirest');
unirest.get('https://httpbin.org/get?query=web')
.end(response => {
console.log(response.body);
});
优点: 语法简单,适合快速脚本。
缺点: 功能较少,社区活跃度也不高。
5. Got
一个适用于 Node.js 的高性能、功能强大的 HTTP 客户端。
import got from 'got';
const html = await got('https://example.com/page').text();
console.log(html.length);
优点: 速度快,支持 HTTP/2、重试、流式处理。
缺点: 只能在 Node 中使用,对新手来说 API 可能稍显复杂。
6. Node 内置的 http/https
你也可以走最传统的路线:
const https = require('https');
https.get('https://example.com/data', (res) => {
let data = '';
res.on('data', chunk => { data += chunk; });
res.on('end', () => {
console.log('响应长度:', data.length);
});
});
优点: 没有额外依赖。
缺点: 冗长、回调风格重、没有 Promise。
点击这里查看详细功能对比和代码示例。
如何为你的项目选择合适的 HTTP 客户端
怎么判断该用哪个工具?我通常会看这些点:
- 易用性: Axios 和 Got 都很适合 async/await,语法也干净。
- 性能: Got 和 node-fetch 轻量、速度快,适合高并发爬取。
- 代理支持: Axios 和 Got 更容易做代理轮换。
- 错误处理: Axios 默认会对 HTTP 错误抛异常;node-fetch 需要你自己检查。
- 社区: Axios 和 Got 社区活跃,示例也多。
我的快速建议:
- 快速脚本或原型: node-fetch 或 Unirest。
- 生产级爬取: Axios(功能更全)或 Got(性能更好)。
- 浏览器自动化: Puppeteer 或 Playwright 会在内部处理请求。
HTML 解析与数据提取:Cheerio、jsdom 及更多
拿到 HTML 之后,你需要把它变成真正能操作的结构,这就是解析器登场的时候。
Cheerio
你可以把 Cheerio 理解成服务器端的 jQuery。它快、轻量,非常适合静态 HTML。
const cheerio = require('cheerio');
const $ = cheerio.load('<ul><li class="item">Item 1</li></ul>');
$('.item').each((i, el) => {
console.log($(el).text());
});
优点: 速度飞快,API 熟悉,能处理脏 HTML。
缺点: 不执行 JavaScript,只能看到 HTML 里原本的内容。
jsdom
jsdom 在 Node.js 中模拟浏览器式的 DOM。它可以执行简单脚本,比 Cheerio 更接近“浏览器环境”。
const { JSDOM } = require('jsdom');
const dom = new JSDOM(`<p id="greet">Hello</p><script>document.querySelector('#greet').textContent += ", world!";</script>`);
console.log(dom.window.document.querySelector('#greet').textContent);
优点: 可以运行脚本,支持完整 DOM API。
缺点: 比 Cheerio 慢,也更重,不是真正的完整浏览器。
什么时候该用正则表达式或其他解析方式
网页爬虫里的正则表达式就像辣酱——适量很好,但别什么都往里倒。正则适合:
- 从文本中提取模式(邮箱、电话号码、价格)。
- 清理或校验抓取到的数据。
- 从长文本或脚本标签中提取信息。
示例:从文本中提取数字
const text = "总销量:1,234 件";
const match = text.match(/([\d,]+)\s*件/);
if (match) {
const units = parseInt(match[1].replace(/,/g, ''));
console.log("售出数量:", units);
}
但不要试图用正则去解析完整 HTML——这种情况请用 DOM 解析器。更多网页爬虫正则技巧。
处理动态网站:Puppeteer、Playwright 和无头浏览器
现代网站都很爱用 JavaScript。有时候,你要的数据根本不在初始 HTML 里,而是页面加载后由脚本渲染出来的。这时就轮到无头浏览器上场了。
Puppeteer
这是 Google 推出的 Node.js 库,用来控制 Chrome/Chromium。你可以把它理解成一个帮你自动点击、滚动网页的机器人。
const puppeteer = require('puppeteer');
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const title = await page.$eval('h1', el => el.textContent);
console.log(title);
await browser.close();
优点: 完整的 Chrome 渲染,API 简单,非常适合动态内容。
缺点: 只能用 Chromium,资源占用也更高。
Playwright
这是微软推出的新一代库,支持 Chromium、Firefox 和 WebKit。你可以把它理解成更酷、还能跨浏览器的 Puppeteer 表亲。
const { chromium } = require('playwright');
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const content = await page.textContent('h1');
console.log(content);
await browser.close();
优点: 跨浏览器、支持并行上下文、元素自动等待。
缺点: 学习曲线稍陡,安装包也更大。
Nightmare
这是一个基于 Electron 的自动化工具,很多年前很流行。它的仓库后来被迁到了 segment-boneyard GitHub 组织——那是 Segment 用来存放已停止维护项目的“仓库停放场”,而且它最后一次 npm 发布还是在 2019 年。到了 2026 年,我不会把它作为新项目的首选;如果你接手的是一个还在用它的旧脚本,那问题不大,但新项目就直接上 Playwright 或 Puppeteer 吧。
无头浏览器方案对比
| 方面 | Puppeteer(Chrome) | Playwright(多浏览器) | Nightmare(Electron) |
|---|---|---|---|
| 浏览器支持 | Chrome/Edge | Chrome、Firefox、WebKit | Chrome(旧版) |
| 性能与规模 | 快,但占资源 | 快,并行能力更强 | 更慢,稳定性较差 |
| 动态爬取 | 非常出色 | 非常出色,功能更多 | 适合简单网站 |
| 维护情况 | 维护良好 | 非常活跃 | 已归档(segment-boneyard,最后一次 npm 发布为 2019) |
| 最适合 | Chrome 爬取 | 复杂、跨浏览器任务 | 简单、遗留任务 |
我的建议: 新的复杂项目优先用 Playwright。只需要 Chrome 的任务,Puppeteer 依然很好。Nightmare 基本只适合怀旧或维护旧脚本。
辅助工具:调度、环境、命令行和数据存储
真正落地的爬虫不只是“请求 + 解析”。下面这些辅助工具我也经常会用到:
调度:node-cron
让爬虫按计划自动运行。
const cron = require('node-cron');
cron.schedule('0 9 * * MON', () => {
console.log('每周一早上 9 点开始爬取');
});
环境管理:dotenv
把密钥和配置从代码里分离出去。
require('dotenv').config();
const apiKey = process.env.API_KEY;
命令行工具:chalk、commander、inquirer
- chalk: 给控制台输出上色。
- commander: 解析命令行参数。
- inquirer: 提供交互式提示,收集用户输入。
数据存储
- fs: 写入文件(JSON、CSV)。
- lowdb: 轻量级 JSON 数据库。
- sqlite3: 本地 SQL 数据库。
- mongodb: 适合更大项目的 NoSQL 数据库。
示例:保存数据到 JSON
const fs = require('fs');
fs.writeFileSync('output.json', JSON.stringify(data, null, 2));
使用 JavaScript 和 Node.js 传统网页爬虫时的痛点
说实话,传统爬虫并不是什么阳光和彩虹。下面这些问题,是我见过也亲身感受过的最大麻烦:

- 学习曲线高: 你得搞懂 DOM、选择器、异步逻辑,有时候还要面对浏览器的各种奇怪行为。
- 维护负担重: 网站一改版,选择器就失效,你得不停补代码。
- 扩展性差: 每个网站都要单独写脚本,根本没有真正“一套通吃”的方案。
- 数据清洗复杂: 抓回来的数据通常很乱,清洗、格式化、去重本身就是一项工作。
- 性能受限: 浏览器自动化在大规模任务里速度慢,而且很吃资源。
- 封禁和反爬措施: 网站会封爬虫、抛 CAPTCHA,或者把数据藏在登录后。
- 法律与伦理灰区: 你还得处理服务条款、隐私和合规问题。
Thunderbit vs. 传统网页爬虫:一场生产力革命
现在我们来谈谈那个大家都在想的问题:如果你能跳过所有代码、选择器和维护工作,会怎样?
这就是 Thunderbit 的价值所在。作为联合创始人兼 CEO,我难免有点偏爱,但请听我说——Thunderbit 就是为想要数据、而不是想要麻烦的业务用户打造的。
Thunderbit 对比如何
| 方面 | Thunderbit(AI 无代码) | 传统 JS/Node 爬虫 |
|---|---|---|
| 设置 | 两步完成,无需代码 | 编写脚本、调试 |
| 动态内容 | 在浏览器内处理 | 需要无头浏览器脚本 |
| 维护 | AI 自动适应变化 | 手动更新代码 |
| 数据提取 | AI 建议字段 | 手动写选择器 |
| 子页面抓取 | 内置,1 次点击 | 按网站循环编写代码 |
| 导出 | Excel、Sheets、Notion | 手动对接文件/数据库 |
| 后处理 | 总结、打标签、格式化 | 额外编写代码或使用工具 |
| 适用人群 | 任何有浏览器的人 | 仅开发者 |
| 适用人群 | 任何有浏览器的人 | 仅开发者 |
Thunderbit 的 AI 会读取页面、建议字段,并在几次点击内完成数据抓取。它还能处理子页面,适应布局变化,甚至在抓取过程中自动总结、打标签或翻译数据。你可以导出到 Excel、Google Sheets、Airtable 或 Notion——完全不需要技术配置。
Thunderbit 特别适合的场景:
- 电商团队跟踪竞品 SKU 和价格
- 销售团队抓取线索和联系方式
- 市场研究人员整合新闻或评论
- 房地产经纪人提取房源和房产详情
对于高频、关键业务的爬取,Thunderbit 能节省大量时间。对于定制化、大规模或深度集成的项目,传统脚本仍然有用武之地——但对大多数团队来说,Thunderbit 是从“我需要数据”到“我已经有数据”最快的方式。
查看 Thunderbit Chrome 扩展的实际效果 或在 Thunderbit 博客查看更多使用场景。
快速参考:流行的 JavaScript 与 Node.js 网页爬虫库
下面是 2026 年 JavaScript 爬虫生态的速查表:
HTTP 请求
- Axios:基于 Promise、功能丰富的 HTTP 客户端。
- node-fetch:Node.js 版 Fetch API。
- Got:快速、功能先进的 HTTP 客户端。
- SuperAgent:成熟、支持链式调用的 HTTP 请求库。
- Unirest:简单、语言无关的客户端。
HTML 解析
动态内容
- Puppeteer:无头 Chrome 自动化。
- Playwright:多浏览器自动化。
- Nightmare:基于 Electron 的旧版浏览器自动化。
调度
- node-cron:Node.js 中的 cron 任务。
CLI 与实用工具
存储
框架
- Crawlee:Apify 推出的高层级爬取与抓取框架。截至 2026 年 5 月,JavaScript/TypeScript 版本已到 v3.16,是更成熟的主线(Python 版本更新一些)。它把 Puppeteer、Playwright、Cheerio 和 JSDOM 封装在一个 API 后面,并内置代理轮换和队列功能——如果你发现自己总是在爬虫外面重复搭建同一套脚手架,这会特别有用。
(记得随时查看最新文档和 GitHub 仓库获取更新。)
掌握 JavaScript 网页爬虫的推荐资源
想更深入一点?下面这份精选资源清单,可以帮你快速提升爬虫能力:
官方文档与指南
教程与课程
- freeCodeCamp:Node.js 网页爬虫终极指南
- YouTube:使用 Node.js 进行网页爬虫(freeCodeCamp)
- DigitalOcean:如何使用 Node.js 和 Puppeteer 抓取网站
开源项目与示例
社区与论坛
书籍与综合指南
- O’Reilly 的《Web Scraping with Python》(用于理解跨语言概念)
- Udemy/Coursera 上的“Web Scraping in Node.js”课程
(记得查看最新版本和更新。)
如何使用 AI 抓取任意网站 Get Started Free
结论:为你的团队选择最合适的方法
结论很简单:JavaScript 和 Node.js 为网页爬虫提供了惊人的能力和灵活性。你几乎可以构建任何东西——从粗糙但快速的脚本,到强大且可扩展的爬虫。但能力越强,维护责任也越大。传统脚本适合那些定制化、工程投入高、需要完全控制且能接受持续维护的项目。
而对其他所有人来说——业务用户、分析师、营销人员,以及任何只想拿到数据的人——像 Thunderbit 这样的现代无代码方案,会让人眼前一亮。Thunderbit 的 AI Chrome 扩展能让你在几分钟内完成数据抓取、结构化和导出,而不是花上几天。无需代码,无需选择器,没有头疼的问题。
那么,什么才是正确的做法?如果你的团队有工程实力,而且需求独特,那就深入 Node.js 工具箱。如果你想要速度、简单性,并希望把精力放在洞察而不是基础设施上,那就试试 Thunderbit。不管怎样,网页就是你的数据库——去把数据拿回来吧。
如果你哪天卡住了,记住:就连最厉害的爬虫,也都是从一张空白页和一杯浓咖啡开始的。祝你爬取愉快。
想进一步了解 AI 驱动的爬取,或者看看 Thunderbit 的实际表现?
如果你有问题、故事,或者最喜欢的爬虫“恐怖经历”,欢迎在评论里留言,或者直接联系我。我很喜欢听大家是怎么把网页变成自己的数据游乐场的。
保持好奇,保持咖啡因在线,也要更聪明地爬取,而不是更辛苦地爬取。
试用 AI 网页爬虫 Get Started Free
常见问题:
1. 为什么在 2025 年使用 JavaScript 和 Node.js 做网页爬虫?
因为现在大多数现代网站都是用 JavaScript 构建的。Node.js 速度快、适合异步处理,而且生态丰富(例如 Axios、Cheerio、Puppeteer),可以支持从简单请求到大规模动态内容爬取的各种场景。
2. 用 Node.js 抓取网站的典型流程是什么?
通常是这样的:
请求 → 处理响应 →(可选)执行 JS → 解析 HTML → 提取数据 → 保存或导出
每一步都可以由 axios、cheerio 或 puppeteer 这类专用工具来完成。
3. 如何抓取动态、由 JavaScript 渲染的页面?
使用 Puppeteer 或 Playwright 这类无头浏览器。它们会加载完整页面(包括 JS),让你抓到用户真正看到的内容。
4. 传统爬虫最大的挑战是什么?
- 网站结构变化
- 反爬检测
- 浏览器资源消耗
- 手动数据清洗
- 长期维护成本高
这些问题会让大规模或对开发者不友好的爬取方式很难持续下去。
5. 什么时候我该用 Thunderbit 这类工具,而不是写代码?
如果你需要速度、简单性,又不想编写或维护代码,就该用 Thunderbit。它非常适合销售、市场或研究团队,帮助他们快速提取并结构化数据——尤其是面对复杂或多页面网站时。




