还记得我第一次尝试从网站抓取商品数据的场景吗?当时我盯着一整页跑鞋,心里想着:“把这些商品名和价格弄进表格,应该很简单吧?”结果几个小时后,我却被 JavaScript 报错和选择器混乱搞得头大,对那些能从零开发网页爬虫的人真是佩服得五体投地。
如果你也有过类似的经历——不管你是做销售、电商还是运营,只是想快速拿到实时数据来做更明智的决策——你绝对不是一个人在战斗。近几年,网页爬虫的需求暴涨。实际上,全球,预计到 2030 年还会翻一倍。但问题是,大多数传统爬虫工具都需要一定的技术基础。所以我想带你体验两种完全不同的方式:一种是用 Cypress 亲自写代码,另一种是用 这种 AI 驱动的无代码神器。我们就以 为例来实操。
不管你是想提升 JavaScript 技能的开发者,还是只想轻松拿到数据的业务同学,这份指南都能帮你高效搞定任务——不用熬夜加班,也不会抓狂。
什么是网页爬虫?为什么企业都在用?
简单来说,网页爬虫就是用软件自动帮你从网站提取数据。与其手动复制粘贴商品名、价格或联系方式,不如让工具一键帮你搞定。
那企业为什么都在用网页爬虫?因为数据就是新时代的“石油”(或者说燕麦奶,看你喜欢哪种)。销售、电商、运营等团队都在用网页爬虫来:
- 批量获取潜在客户,比如从目录或社交平台一键提取联系方式。
- 监控竞品价格和商品趋势——大约。
- 分析客户口碑,通过抓取评论和评分了解市场反馈。
- 自动化繁琐调研,把原本要花数小时甚至数天的工作一键完成。
而且回报很可观:表示公开网页数据让他们决策更快、更准。换句话说,不用网页爬虫,你可能就错过了商机和洞察。
认识 Cypress:流行的网页爬虫工具
说到工具,Cypress 是一个开源框架,最初是用来做 Web 应用端到端自动化测试的。你可以把它想象成一个能自动点按钮、填表单、检测网页是否正常的“机器人”。但有意思的是:Cypress 在真实浏览器里运行,能和 JavaScript 密集型网站互动,所以也成了一个非常实用(虽然有点“曲线救国”)的网页爬虫工具。
那它和 Python 生态下的爬虫(比如 BeautifulSoup 或 Scrapy)比起来怎么样?简单对比下:
- Cypress: 适合抓取动态、JS 渲染的内容。需要懂 JavaScript 和 Node.js,灵活强大,但更偏向开发者。
- Python 爬虫: BeautifulSoup、Scrapy 等适合大规模静态页面抓取,生态丰富,但遇到需要真实浏览器渲染的页面就有点吃力。
如果你熟悉 JavaScript 或做过 QA 测试,Cypress 会是个高效选择。如果你对代码敬而远之,别急,后面还有无代码方案。
实操演练:用 Cypress 抓取 Adidas 男士跑鞋数据
现在我们来动手,用 Cypress 给 写个爬虫。目标很简单:把商品名、价格、图片和链接都提取出来,保存成文件。
1. 环境搭建
首先,你需要安装 和 npm。准备好后,打开终端输入:
1mkdir adidas-scraper
2cd adidas-scraper
3npm init -y
4npm install cypress --save-dev这样就新建了项目并本地安装了 Cypress。首次启动 Cypress:
1npx cypress openCypress 会自动生成 cypress/ 目录和示例测试文件。你可以删掉示例,自己新建一个,比如 cypress/e2e/adidas-scraper.cy.js。
2. 分析网页结构,确定抓取目标
打开 ,右键商品,选择“检查元素”。你会发现每个商品都被一个卡片包裹,里面有商品名、价格、图片和链接。
比如:
1<div class="product-card">
2 <a href="/us/adizero-sl2-running-shoes/XYZ123.html">
3 <img src="..." alt="Adizero SL2 Running Shoes"/>
4 <div class="product-price">$130</div>
5 <div class="product-name">Adizero SL2 Running Shoes -- Men's Running</div>
6 </a>
7</div>注意像 .gl-price 这样的类名,找出 HTML 结构的规律,这样才能告诉 Cypress 要抓哪些内容。
3. 编写 Cypress 脚本提取数据
下面是一个示例脚本:
1// cypress/e2e/adidas-scraper.cy.js
2describe('Scrape Adidas Running Shoes', () => {
3 it('collects product name, price, image, and link', () => {
4 cy.visit('<https://www.adidas.com/us/men-running-shoes>');
5 const products = [];
6 cy.get('a[href*="/us/"][href*="running-shoes"]').each(($el) => {
7 const name = $el.find('*:contains("Running Shoes")').text().trim();
8 const price = $el.find('.gl-price').text().trim();
9 const imageUrl = $el.find('img').attr('src');
10 const link = $el.attr('href');
11 products.push({ name, price, image: imageUrl, link: `https://www.adidas.com$\{link\}` });
12 }).then(() => {
13 cy.writeFile('cypress/output/adidas_products.json', products);
14 });
15 });
16});脚本做了什么?
cy.visit()加载页面。cy.get()选中所有符合 Adidas 链接规则的商品。.each()遍历每个商品,提取名称、价格、图片和链接。- 数据存入数组,最后写入 JSON 文件。
如果 Adidas 改了页面结构,记得调整选择器,但大致流程就是这样。
4. 导出和使用抓取的数据
运行脚本(用 Cypress GUI 或 npx cypress run),在 cypress/output/adidas_products.json 里就能看到类似这样的数据:
1[
2 {
3 "name": "Adizero SL2 Running Shoes Men's Running",
4 "price": "$130",
5 "image": "<https://assets.adidas.com/images/w_280,h_280,f_auto,q_auto:sensitive/.../adizero-SL2-shoes.jpg>",
6 "link": "<https://www.adidas.com/us/adizero-sl2-running-shoes/XYZ123.html>"
7 },
8 ...
9]你可以把 JSON 转成 CSV,在 Excel 里分析,或者导入 BI 工具。如果想自动化监控价格,还能定时运行脚本。
用 Cypress 抓取网页常见难题
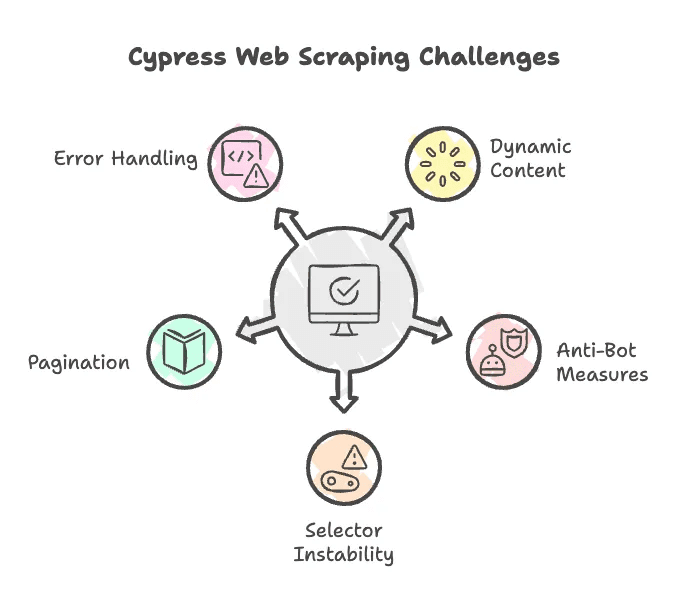
说实话,网页爬虫并不总是顺风顺水。用 Cypress 时常见的挑战有:
- JavaScript 动态渲染: 虽然 Cypress 能处理动态内容,但有时需要等待元素加载或滚动页面触发懒加载。可以用
cy.wait()或滚动命令。 - 反爬机制: 有些网站会检测爬虫,比如检查 User-Agent 或限制访问频率。Cypress 在真实浏览器中运行有一定优势,但遇到强力反爬时,可能还需要用代理、伪装请求头等高级手段。
- 选择器不稳定: 如果 Adidas 改了 HTML 结构或类名,脚本就会失效。要定期维护选择器。
- 分页处理: 大多数商品页都有分页,需要写逻辑点击“下一页”,并合并所有结果。
- 错误处理: Cypress 本质是测试工具,遇到缺失元素时会直接报错。建议加上容错处理,避免脚本中断。
如果你觉得光是抓个鞋子列表都快成了“计算机科学毕业设计”,别担心,这正是我们开发 Thunderbit 的初衷。
太复杂?用 Thunderbit 两步搞定网页爬虫
如果你不想折腾 Node.js、选择器或调试代码,那就试试 ,我们的 AI 网页爬虫 Chrome 插件。它专为业务用户设计,无需写代码、无需配置,轻松获取你想要的数据。
Thunderbit 有哪些亮点?
- 无需写代码或调整选择器: 只需点击,剩下的交给 AI。
- 一套模板,多站通用: Thunderbit 的 AI 能适应不同页面结构,无需每次都重新配置。
- 支持本地和云端爬取: 可根据需求选择速度或稳定性。
- 自动处理分页和子页面: 能自动翻页,甚至进入商品详情页补充数据。
- 免费导出: 一键导出到 Excel、Google Sheets、Airtable 或 Notion,无隐藏收费。
下面以 Adidas 页面为例,演示 Thunderbit 的使用流程。
实操演练:用 Thunderbit 抓取 Adidas 商品数据
1. 安装 Thunderbit Chrome 插件
首先,从 。整个过程不到半分钟,比我早上找咖啡杯还快。
注册免费账号——Thunderbit 提供免费试用(10 页)和永久免费计划(每月 6 页),可以直接在真实场景下体验,无需绑定信用卡。
2. 用 AI 智能识别字段抓取数据
- 打开 。
- 点击浏览器中的 Thunderbit 插件图标,侧边栏会自动弹出。
- 点击 “AI 智能识别字段”。Thunderbit 的 AI 会自动扫描页面,识别出商品名、价格、图片和链接,并在预览表格中展示前几行数据。
- 想调整字段?可以一键重命名或添加新字段。还可以用自然语言提示,比如“再提取可选颜色数量”。
- 点击 “开始抓取”。Thunderbit 会自动提取所有数据,遇到分页会自动翻页。如果想获取商品详情页的更多信息,还能用子页面抓取功能,Thunderbit 会自动访问每个商品详情页,丰富你的数据表。
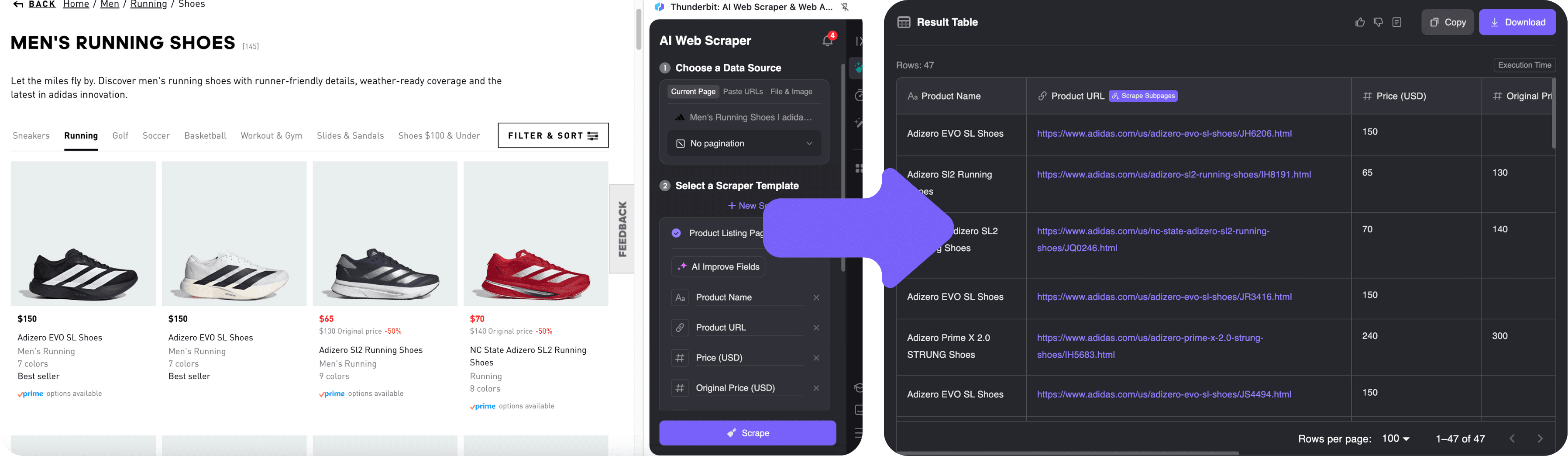
3. 导出和使用数据
抓取完成后,在 Thunderbit 侧边栏预览表格。你可以:
- 一键导出到 Excel、Google Sheets、Airtable 或 Notion。
- 下载为 CSV 或 JSON 文件。
- 支持导出图片、邮箱、电话等多种数据类型。
而且导出完全免费,没有“导出需付费”的套路。
更多技巧可参考 ,或浏览 获取更多实用教程。
Cypress vs Thunderbit:哪款网页爬虫工具更适合你?
我们来对比一下 Cypress 和 Thunderbit,看看各自适合哪些场景:
| 方面 | Cypress(代码爬虫) | Thunderbit(无代码 AI 网页爬虫) |
|---|---|---|
| 上手难度 | 需要 Node.js、npm 和 JavaScript 基础。非开发者初次配置较繁琐。 | 安装 Chrome 插件,登录后几分钟即可使用,无需写代码。 |
| 技术门槛 | 必须懂 JavaScript 和 DOM/CSS 选择器。对非技术人员不友好。 | 无需编程,支持自然语言和可视化操作。 |
| 实施速度 | 编写和调试脚本耗时,复杂页面或分页更费时。 | 几次点击即可完成抓取,自动处理分页和子页面。 |
| 灵活性 | 极高——可自定义逻辑、处理登录、验证码、API 等。 | 针对标准场景优化,AI 能适应大多数网站,极特殊需求需手动调整。 |
| 抗变能力 | 脚本易受页面结构变化影响,需频繁维护。 | 更加稳健——AI 能适应小幅布局变化,模型持续升级。 |
| 扩展性 | 可处理中等规模数据,但基于浏览器的爬取大规模时较慢。 | 云端爬取可支持数百页,按积分计费,适合企业日常需求。 |
| 适用人群 | 需要高度定制和精细控制的开发者或技术用户,适合一次性采集或复杂流程。 | 追求高效、无代码的业务用户,适合价格监控、线索收集、批量采集等重复性任务,尤其适合电商、目录、评论类网站。 |
一句话总结:**Cypress 让你掌控一切,Thunderbit 让你高效省心。**如果你喜欢钻研代码,Cypress 是你的乐园。如果你只想快速拿到数据(老板还催着要),Thunderbit 会是你的好帮手。
总结:如何选择最适合你的网页爬虫方案?
- 网页爬虫已成企业必备——无论是监控竞品、获取客户,还是分析市场趋势。
- Cypress 适合开发者自定义复杂流程,灵活强大,适合动态网站,但学习和维护成本较高。
- Thunderbit 面向所有人。作为一款,两步即可完成抓取,无需代码、无需配置,自动处理分页、子页面,免费导出到常用工具。
- 如果你需要极致灵活性且不怕写代码,选 Cypress。
- 如果你想节省时间、避免技术难题、快速拿到干净数据,Thunderbit 更适合你——尤其适合销售、电商、市场、运营等业务场景。
想了解更多?欢迎访问 ,获取、等实用教程。
下次当你面对满屏跑鞋,不知如何把数据导入表格时,记得你有多种选择。祝你抓取顺利!
常见问题
1. 什么是 Cypress?它如何用于网页爬虫?
Cypress 是一款基于 JavaScript 的自动化测试工具,能与动态网站交互,非常适合抓取 JS 渲染的内容。
2. 用 Cypress 抓取网页时常见难题有哪些?
常见问题包括页面结构变化、懒加载、反爬机制,以及复杂页面的分页或缺失元素处理。
3. 有更简单的无代码网页爬虫方案吗?
有,Thunderbit 是一款 AI 网页爬虫 Chrome 插件,只需几步点击即可抓取数据,无需写代码、无需配置选择器。
了解更多: