“你可以拥有数据而没有信息,但不可能拥有没有数据的信息。” — *
最新估算显示,互联网上有超过 个网站,而且每天还会新增大约 200 万篇内容。在这片数据海洋里,藏着很多有价值的洞见,足以帮你做出更好的决策。但问题在于,其中大约 是非结构化数据,想真正用起来,还得再处理一遍。这正是网页爬虫工具派上用场的地方。对任何想利用在线数据的人来说,它们已经成了离不开的工具。
如果你刚接触网页爬虫,像 和 这些词可能会让你有点发怵。不过到了 AI 时代,这些门槛已经低多了。现在的 AI 驱动爬虫工具,哪怕你没有很深的技术背景,也能很快上手。你可以快速采集和处理数据,不需要编程技能。
最好的网页爬虫工具与软件
- —— 适合想要简单易用、效果出色的 AI 网页爬虫
- —— 适合实时监控和批量数据提取
- —— 适合无需代码、且要和大量应用集成的自动化场景
- —— 适合更专业的可视化网页爬虫
- —— 适合功能强大的无代码爬取,且能规避 IP 封锁和机器人检测
- —— 适合高级 AI 数据提取 API 和知识图谱
试试用 AI 做网页爬取
试试看!你可以边看边点击、探索并运行这个工作流。
网页爬虫是怎么工作的?
网页爬虫本质上就是从网站抓取数据。你给工具一组指令,它就会把网页里的文本、图片,或者你需要的其他内容提取出来,再整理成表格。这在很多场景里都很有用,比如跟踪电商价格、收集研究数据,甚至只是快速整理出一份像样的 Excel 表格或 Google Sheets。
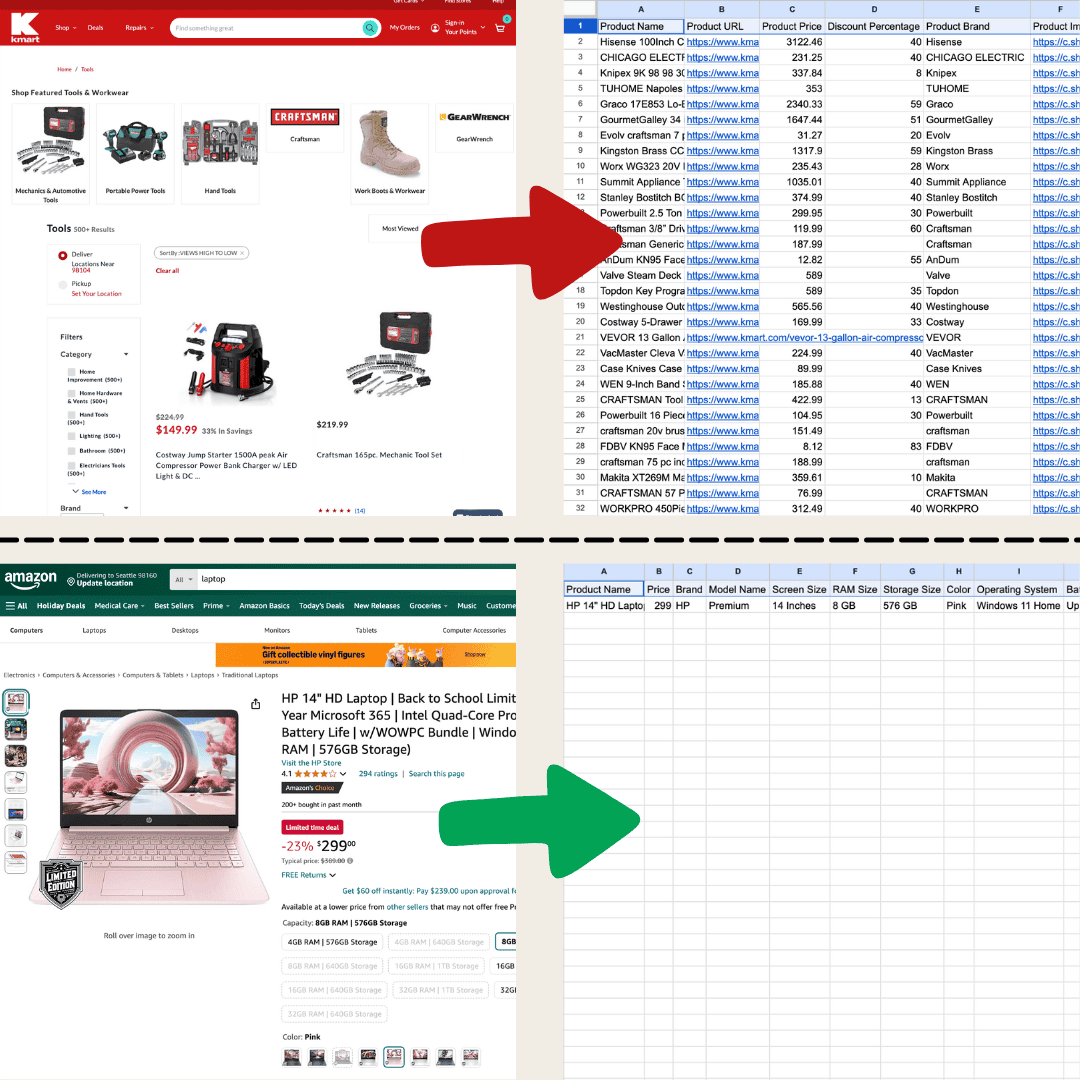 这是我用 Thunderbit 的 AI 网页爬虫做出来的。
这是我用 Thunderbit 的 AI 网页爬虫做出来的。
实现方式有好几种。最简单的办法当然是手动复制粘贴,但如果数据很多,这会非常耗时。所以,大多数人会用三种方式之一:传统网页爬虫、AI 网页爬虫,或者自定义代码。
传统网页爬虫 的工作方式,是根据网页结构设定具体规则来抓取指定数据。比如,你可以设置它从特定的 HTML 标签里抓商品名称或价格。它们最适合那些变化不大的网站,因为一旦页面布局稍有调整,你就得回去修改爬虫配置。
 使用传统爬虫,学习成本会很高,而且完成设置大概率要点上几十次。
使用传统爬虫,学习成本会很高,而且完成设置大概率要点上几十次。
AI 网页爬虫 的思路基本就是:先让 ChatGPT 读完整个网站,再按你的需求提取内容。它可以同时完成数据提取、翻译和总结。它们使用自然语言处理来分析并理解网站结构,所以面对页面变化时也更灵活。比如网站只是稍微调整了一下版块,AI 网页爬虫可能都不需要你重写任何东西,就能自动适应。所以,它们特别适合那些更新频繁,或者结构比较复杂的网站。
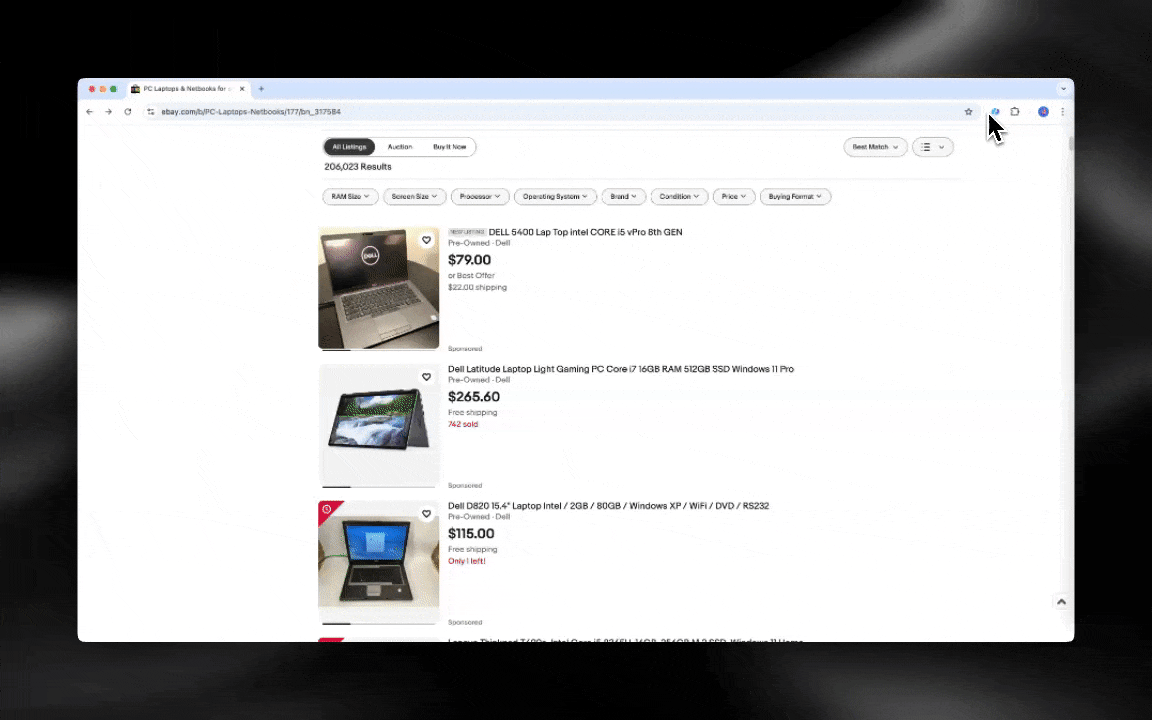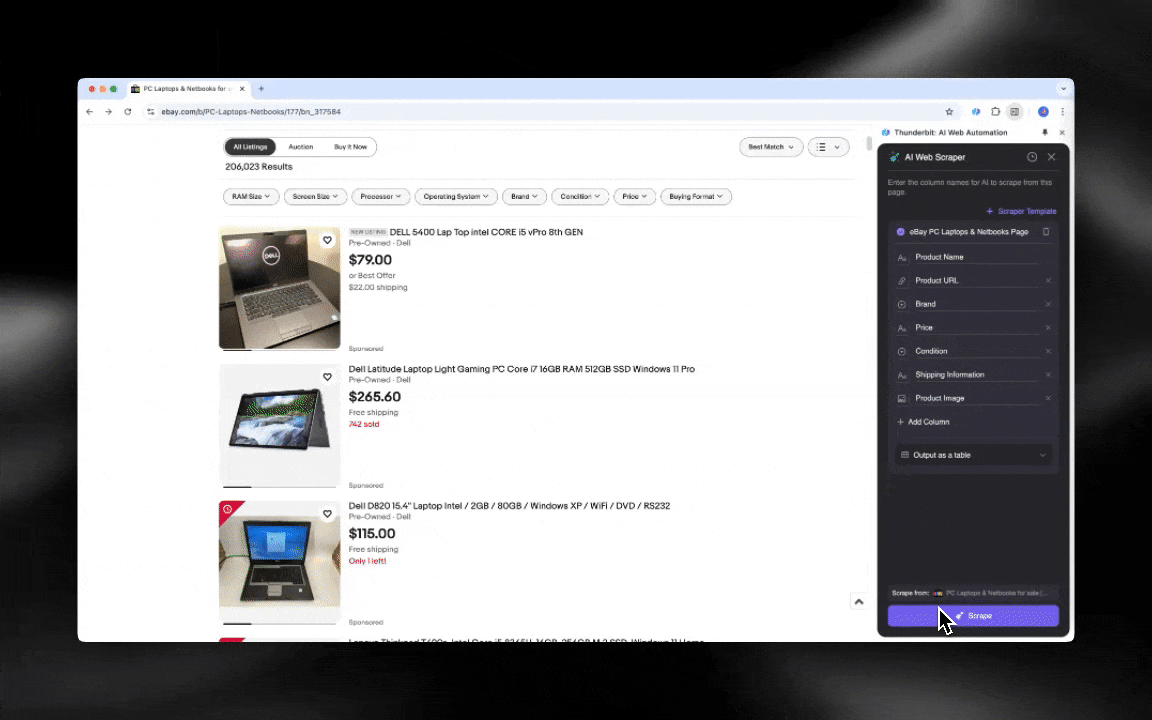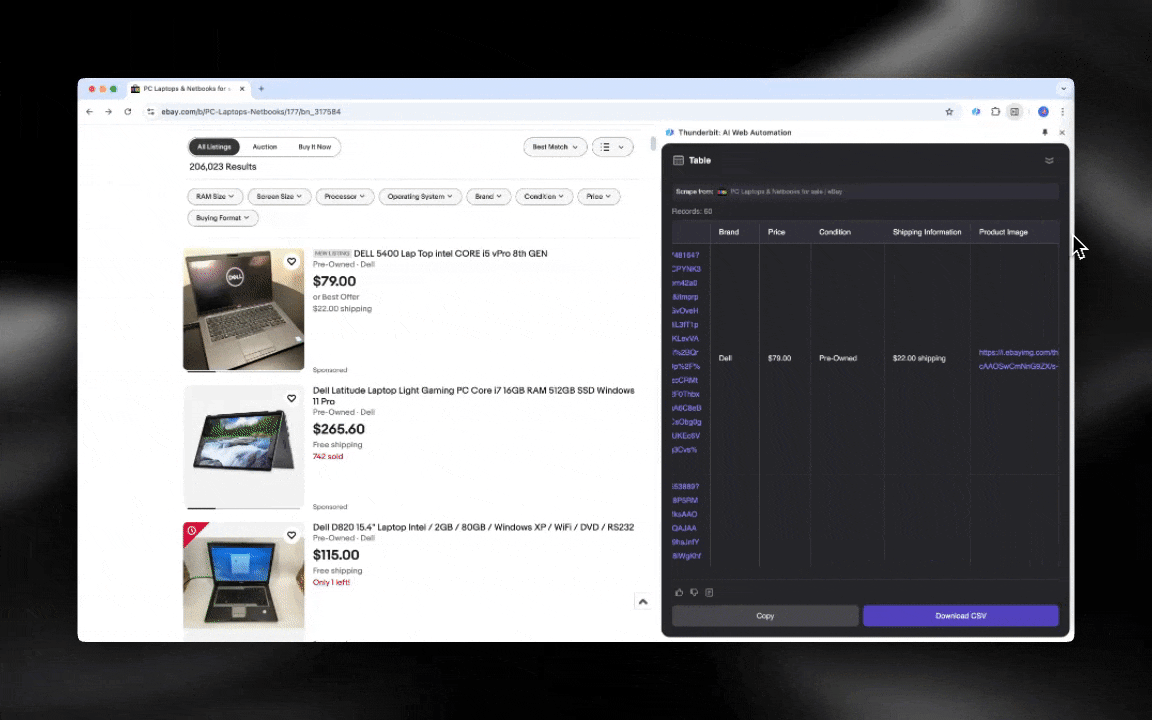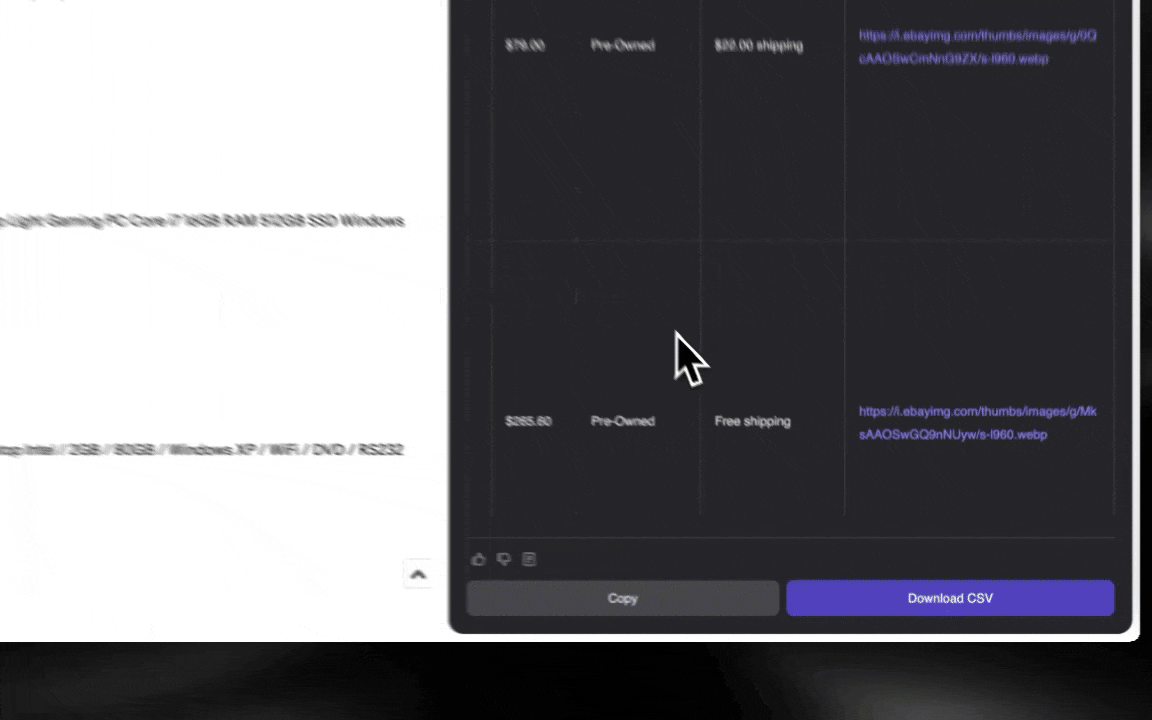 AI 网页爬虫上手很轻松,只要几下点击就能拿到很详细的数据!
AI 网页爬虫上手很轻松,只要几下点击就能拿到很详细的数据!
该怎么选? 这要看你的情况。如果你愿意折腾代码,或者需要在热门网站上采集大量数据,传统爬虫会非常高效。但如果你是网页爬虫新手,或者希望工具能跟着网站更新一起适应变化,AI 网页爬虫通常是更好的选择。下面的表格会给你更具体的适用场景!
| 场景 | 最佳选择 |
|---|---|
| 在目录、购物网站或任何列表型网页上做轻量级抓取 | AI 网页爬虫 |
| 页面数据少于 200 行,使用传统网页爬虫搭建速度太慢 | AI 网页爬虫 |
| 你要抓取的数据需要以特定格式上传到其他平台,比如抓联系人信息上传到 HubSpot | AI 网页爬虫 |
| 大规模抓取热门网站,例如成千上万的 Amazon 商品页或 Zillow 房源页 | 传统网页爬虫 |
一眼看懂:最好的网页爬虫工具与软件
| 工具 | 价格 | 核心功能 | 优点 | 缺点 |
|---|---|---|---|---|
| Thunderbit | 每月 9 美元起,提供免费版 | AI 网页爬虫,自动识别并格式化数据,支持多种格式,一键导出,界面友好。 | 无需代码,AI 支持,支持导出到 Google Sheets 等应用 | 大规模抓取速度可能较慢,高级功能价格更高 |
| Browse AI | 每月 48.75 美元起,提供免费版 | 无代码界面,实时监控,批量数据提取,工作流集成。 | 上手友好,可与 Google Sheets 和 Zapier 集成 | 复杂页面需要额外配置,批量抓取可能超时 |
| Bardeen AI | 每月 60 美元起,提供免费版 | 无代码自动化,支持 130+ 应用集成,MagicBox 可把任务转成工作流。 | 集成丰富,适合企业规模化使用 | 新用户学习曲线较陡,设置耗时 |
| Web Scraper | 本地使用免费,云端版每月 50 美元 | 可视化创建任务,支持动态网站(AJAX/JavaScript),云端爬取。 | 对动态网站效果不错 | 要想配置得最好,需要一定技术知识 |
| Octoparse | 每月 119 美元起,提供免费版 | 无代码抓取,自动检测页面元素,支持定时云端抓取,内置常见网站模板库。 | 动态网站功能强,能处理限制 | 复杂网站上手需要学习 |
| Diffbot | 每月 299 美元起 | 数据提取 API,无规则 API,面向非结构化文本的 NLP,知识图谱丰富。 | AI 提取能力强,API 集成广,适合大规模抓取 | 非技术用户有学习成本,配置时间较长 |
AI 时代最好的网页爬虫
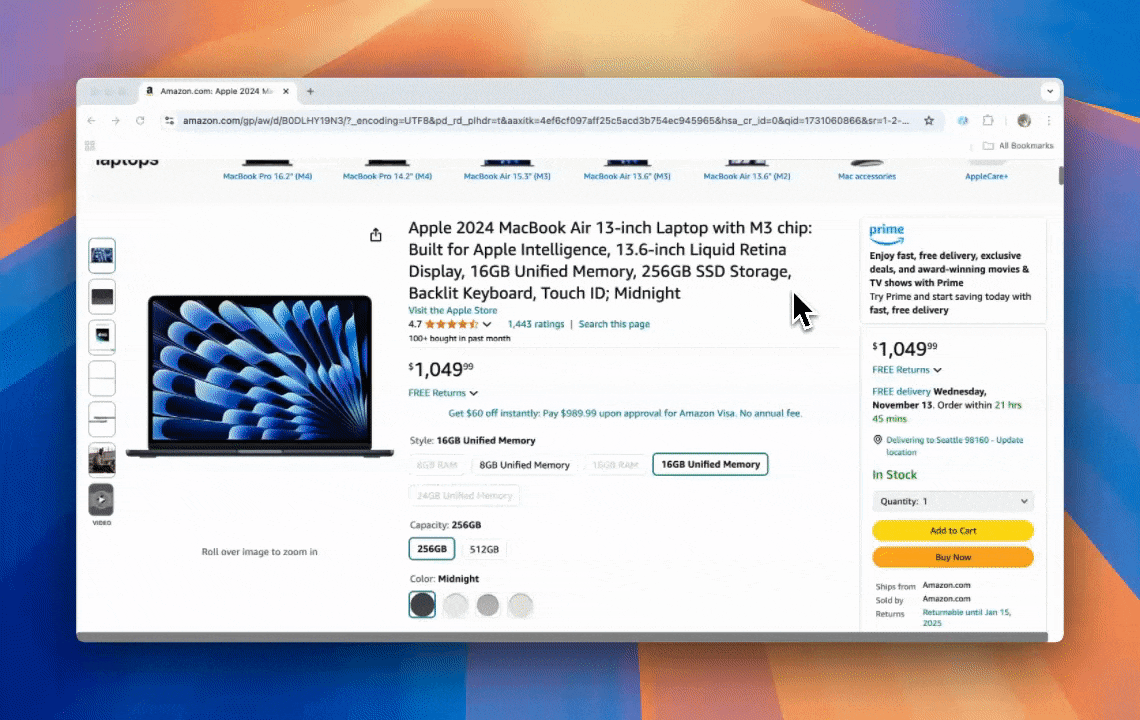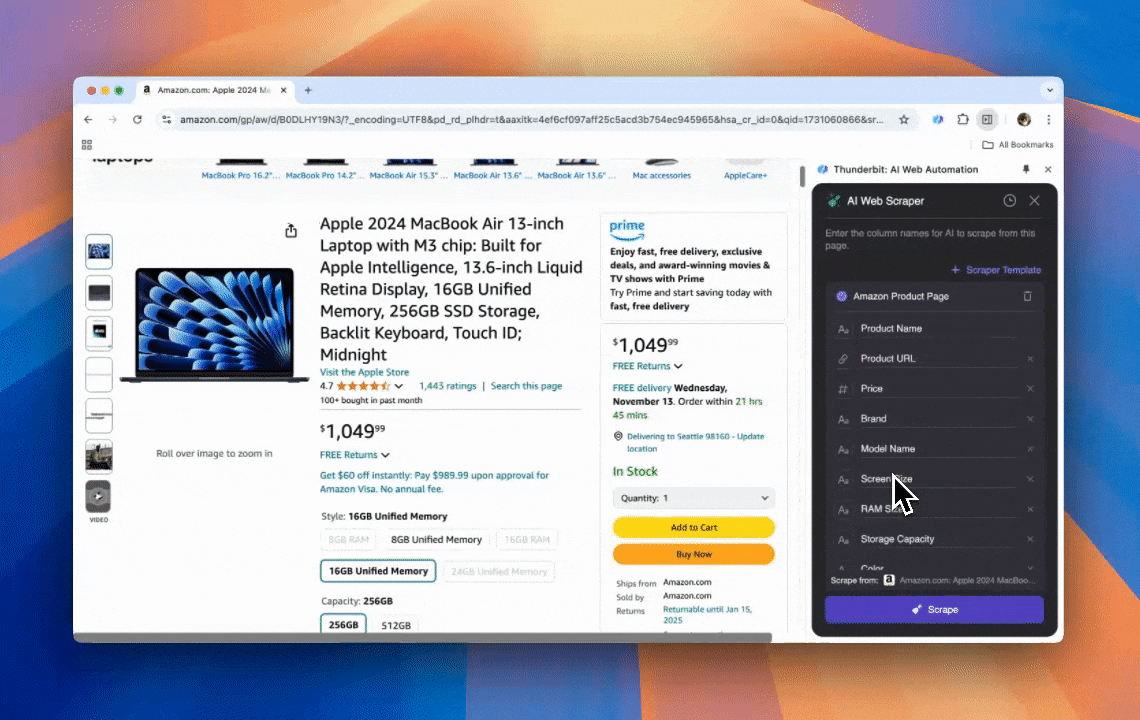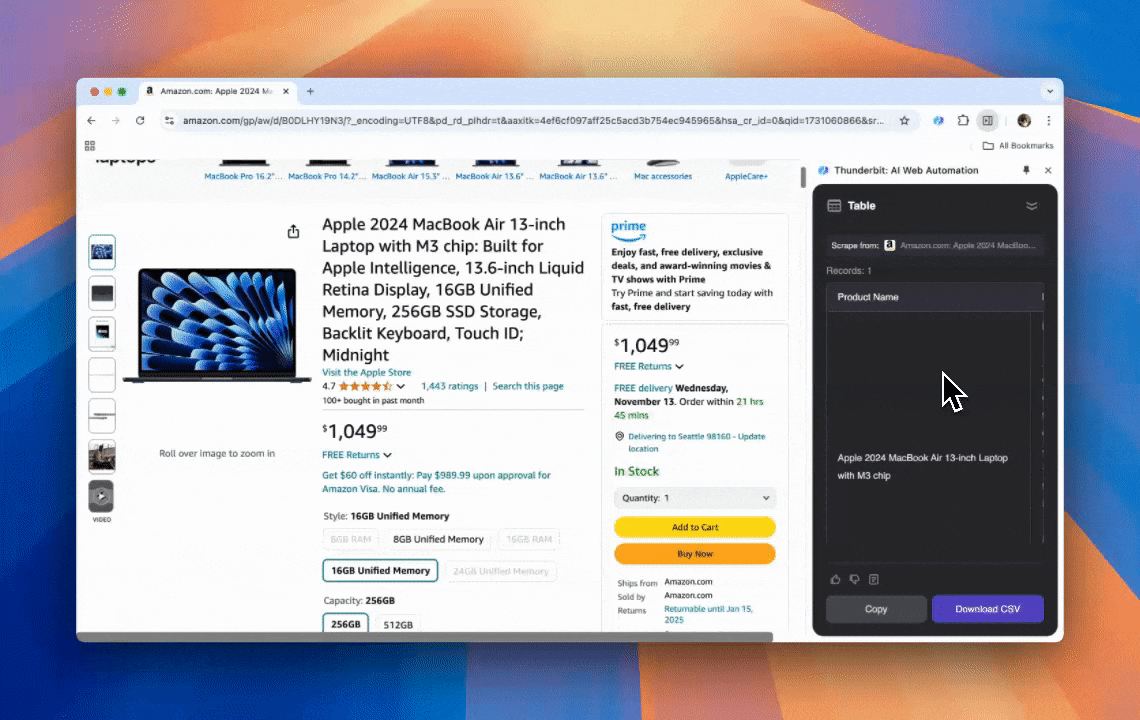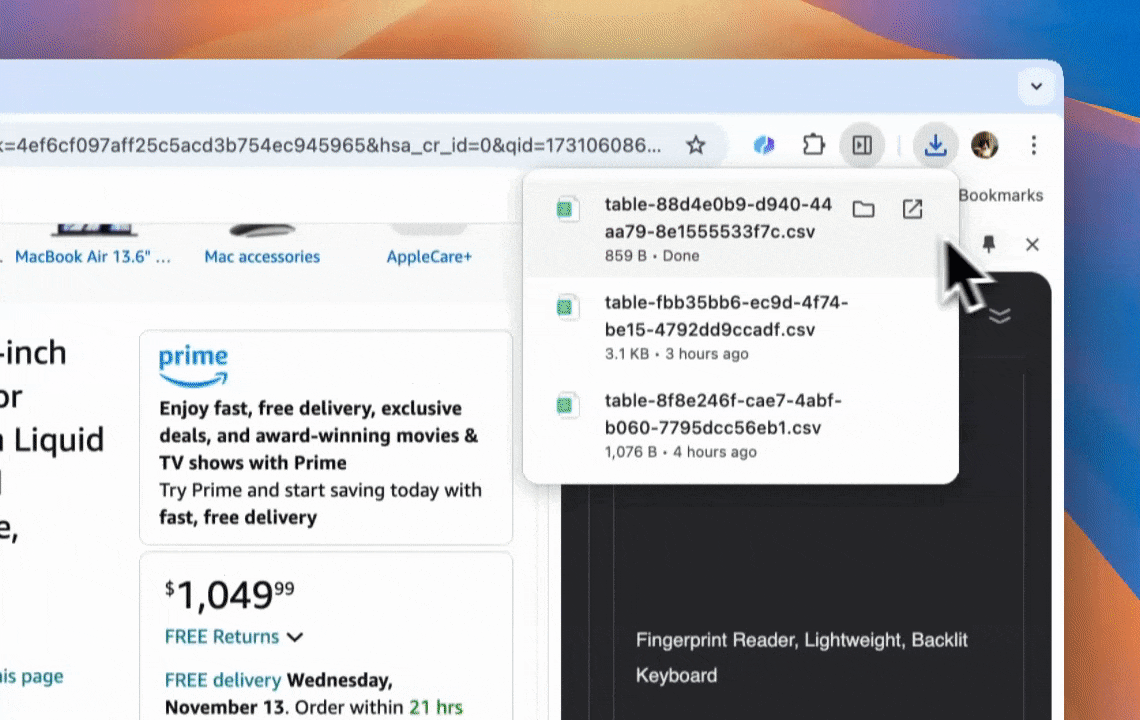
Thunderbit 是一款强大又容易上手的 AI 网页自动化工具,哪怕不懂编程,也能轻松提取并整理数据。配合它的 ,Thunderbit 的 能让数据抓取变得非常简单——你不用手动操作网页元素,也不用针对不同页面布局一个个搭建爬虫,就能快速拿到网页数据。
核心功能
- AI 驱动的灵活性:Thunderbit 的 AI 网页爬虫会自动识别并格式化网页数据,无需 CSS 选择器。
- 最轻松的抓取体验:你只需要在目标页面上点“AI 建议列”,再点“抓取”就行。就是这么简单。
- 支持多种数据格式:Thunderbit 可以抓取 URL、图片,并以多种格式展示采集结果。
- 自动化数据处理:Thunderbit 的 AI 可即时重整数据,包括总结、分类,以及翻译成所需格式。
- 轻松导出数据:一键导出到 Google Sheets、Airtable 或 Notion,数据管理更省事。
- 界面友好:直观的操作界面,适合各种技能水平的用户。
价格
Thunderbit 提供分级套餐,每月 9 美元起,包含 5,000 点数;最高可到每月 199 美元,对应 240,000 点数。年付方案则会一次性发放全部点数。
优点:
- 强大的 AI 支持,让数据提取和处理更简单。
- 无需代码,各种水平的用户都能上手。
- 非常适合目录、购物网站等轻量级抓取场景。
- 集成能力强,可直接导出到常用应用。
缺点:
- 大规模数据抓取可能需要一些时间来保证准确性。
- 某些高级功能可能需要付费订阅。
想了解更多? 你可以先,或者通过 Thunderbit 了解。
最适合数据监控和批量提取的网页爬虫
Browse AI
Browse AI 是一款功能稳健的无代码数据抓取工具,专为帮助用户在不写任何代码的情况下提取和监控数据而设计。它有一些 AI 功能,但还没到完整 AI 抓取的程度。不过,它确实让新用户更容易上手。
核心功能
- 无代码界面:让用户只需点击几下,就能创建自定义工作流。
- 实时监控:通过机器人追踪网页变化,并推送更新后的信息。
- 批量数据提取:一次可处理多达 50,000 条数据。
- 工作流集成:可把多个机器人串联起来,完成更复杂的数据处理。
价格
每月 48.75 美元起,包含 2,000 点数。另有免费版,每月提供 50 点数,方便试用基础功能。
优点:
- 支持与 Google Sheets 和 Zapier 集成。
- 预置机器人能简化常见的数据提取任务。
缺点:
- 复杂页面可能需要额外配置。
- 批量抓取速度会有波动,有时会超时。
最适合工作流集成的网页爬虫
Bardeen AI
Bardeen AI 是一款无代码自动化工具,旨在通过连接各种应用来简化工作流。虽然它会用 AI 来创建定制自动化,但灵活性还是不如完整的 AI 爬取工具。
核心功能
- 无代码自动化:用户可以通过点击来设置工作流。
- MagicBox:你用自然语言描述任务,Bardeen AI 会把它转换成工作流。
- 广泛的集成选项:可与 130 多个应用集成,包括 Google Sheets、Slack 和 LinkedIn。
价格
每月 60 美元起,包含 1,500 点数(约 1,500 行数据)。免费版每月提供 100 点数,供你试用基础功能。
优点:
- 丰富的集成选项,能满足多样化的业务需求。
- 灵活且可扩展,适合各种规模的企业。
缺点:
- 新用户可能需要一些时间来熟悉整个平台。
- 初始设置可能比较耗时。
最适合有经验用户的可视化网页爬虫
Web Scraper
没错,你没看错:这款工具就叫“Web Scraper”。Web Scraper 是一款在 Chrome 和 Firefox 上都很受欢迎的浏览器扩展,可以让用户无需编程就提取数据,并通过可视化方式创建爬取任务。不过,你可能需要花几天时间看教程并边学边练,才能真正掌握这款工具。如果你想让爬取过程对大脑更友好,选 AI 网页爬虫会更省心。
核心功能
- 可视化创建:通过点击网页元素来设置抓取任务。
- 支持动态网站:可处理 AJAX 请求和 JavaScript,适合动态页面。
- 云端抓取:可通过 Web Scraper Cloud 定时执行抓取任务。
价格
本地使用免费;云端功能付费方案每月 50 美元起。
优点:
- 对动态网站表现不错。
- 本地使用免费。
缺点:
- 要想达到最佳配置,需要一定技术知识。
- 页面有变化时,需要做较复杂的测试。
最适合规避 IP 封锁和机器人检测的网页爬虫
Octoparse
Octoparse 是一款功能全面的软件,适合更偏技术型的用户在无需代码的情况下收集和监控特定网页数据,尤其适合大规模数据需求。Octoparse 不是依赖用户浏览器运行,而是使用云端服务器进行数据抓取。因此,它可以通过多种方式规避 IP 封锁和部分网站的机器人检测。
核心功能
- 无代码操作:用户无需编程即可创建抓取任务,适合不同技术水平的人使用。
- 智能自动识别:可自动检测页面数据,快速识别可抓取元素,简化设置过程。
- 云端抓取:支持 24/7 云端数据抓取,并可设置定时任务,灵活获取数据。
- 丰富的模板库:提供数百个预设模板,让你无需复杂配置就能快速获取热门网站的数据。
价格
Octoparse 的套餐每月 119 美元起,包含 100 个任务。另有免费版,每月 10 个任务,方便测试基础功能。
优点:
- 强大的功能支持动态网站抓取,适应性高。
- 能有效应对抓取限制和动态内容问题。
缺点:
- 复杂的网站结构可能需要更多时间来配置。
- 新用户可能需要一段时间学习使用技巧。
最适合高级 AI 数据提取 API 的网页爬虫
Diffbot
Diffbot 是一款高级网页数据提取工具,利用 AI 将非结构化网页内容转换为结构化数据。凭借强大的 API 和知识图谱,Diffbot 可以帮助用户从网页中提取、分析和管理信息,适用于多个行业和应用场景。
核心功能
- 数据提取 API:Diffbot 提供无规则的数据提取 API,用户只需提供 URL,就能自动提取数据,无需为每个网站单独设置规则。
- 自然语言处理 API:可从非结构化文本中提取结构化实体、关系和情绪,有助于你构建自己的知识图谱。
- 知识图谱:Diffbot 拥有全球最大的知识图谱之一,连接了海量实体数据,包括个人和组织的信息。
价格
Diffbot 的套餐每月 299 美元起,包含 250,000 点数(大约相当于 250,000 次基于 API 的网页提取)。
优点:
- 无规则数据提取能力强,适应性高。
- API 集成选项丰富,便于接入现有系统。
- 支持大规模数据抓取,适合企业级应用。
缺点:
- 非技术用户初次设置可能需要一些学习时间。
- 使用时必须编写程序来调用 API。
你可以用爬虫做什么?
如果你是网页爬虫新手,这里有几个常见用法,能帮你快速入门。很多人会用爬虫来获取 Amazon 商品列表、抓取 Zillow 房地产数据,或者收集 Google 地图上的商家信息。但这只是开始——你可以用 Thunderbit 的 从几乎任何网站采集数据,把任务流程简化下来,还能为日常工作节省大量时间。不管是做研究、跟踪价格,还是搭建数据库,网页爬虫都能让你把互联网上的数据真正用起来。
常见问题
-
网页爬虫合法吗?
网页爬取通常是合法的,但必须遵守网站服务条款以及所访问数据的性质。请始终查看相关政策,并遵守法律规范。
-
使用网页爬虫工具需要编程技能吗?
这里介绍的大多数工具都不需要编程技能,但像 Octoparse 和 Web Scraper 这类工具,如果你对网页结构有一些基本认识,并具备一点编程思维,使用体验会更好。
-
有没有免费的网页爬虫工具?
有,比如 BeautifulSoup、Scrapy 和 Web Scraper 都有免费工具可用,另外一些工具也提供功能有限的免费套餐。
-
网页爬取常见的挑战有哪些?
常见挑战包括动态内容、验证码、IP 封锁和复杂的 HTML 结构。高级工具和技术通常可以有效应对这些问题。
了解更多:
-
用 AI 做事,几乎不费力。