想象一下,2025年清晨,你一边喝着咖啡,一边想看看Walmart上那台65英寸电视是不是又降价了——或者你是电商行业的小伙伴,需要随时掌握Walmart的价格、库存和用户评价。要是每天都手动查Walmart的每个商品,那简直是体力活,还特别枯燥。但只要你会点Python和网页爬虫的基本操作,这些繁琐的活儿都能自动化,数据宝藏轻松到手。
这些年我一直在帮企业做自动化和AI工具开发。walmart数据抓取就是那种能把繁琐调研变成几行代码的“秘密武器”。这篇文章会带你了解什么是walmart数据抓取、2025年它对企业的价值,以及如何用Python一步步搭建一个高效的walmart爬虫,附上实用代码和经验分享。准备好你的咖啡(或者调试零食),我们正式开工!
什么是walmart数据抓取?2025年基础解析
简单来说,walmart数据抓取就是用软件自动提取Walmart网站上的商品、价格和评论信息——通常是用脚本模拟高速浏览器操作。与其手动复制粘贴(相信我,没人喜欢),不如写个Python脚本,自动获取页面、提取所需数据并保存分析。
为什么选Python?Python简直就是网页爬虫的万能工具:语法简单,生态丰富(比如Requests、BeautifulSoup、pandas等库),社区活跃,资源多。不管你是独立研究者还是企业团队成员,Python都能让walmart数据抓取变得很容易上手——就算你不是专业开发者也没问题。
还要注意,个人用途(比如自己跟踪几个商品价格)和企业用途(比如监控成千上万SKU做竞品分析)在规模和技术难度上差别很大——尤其是Walmart到2025年依然没有公开的商品API()。
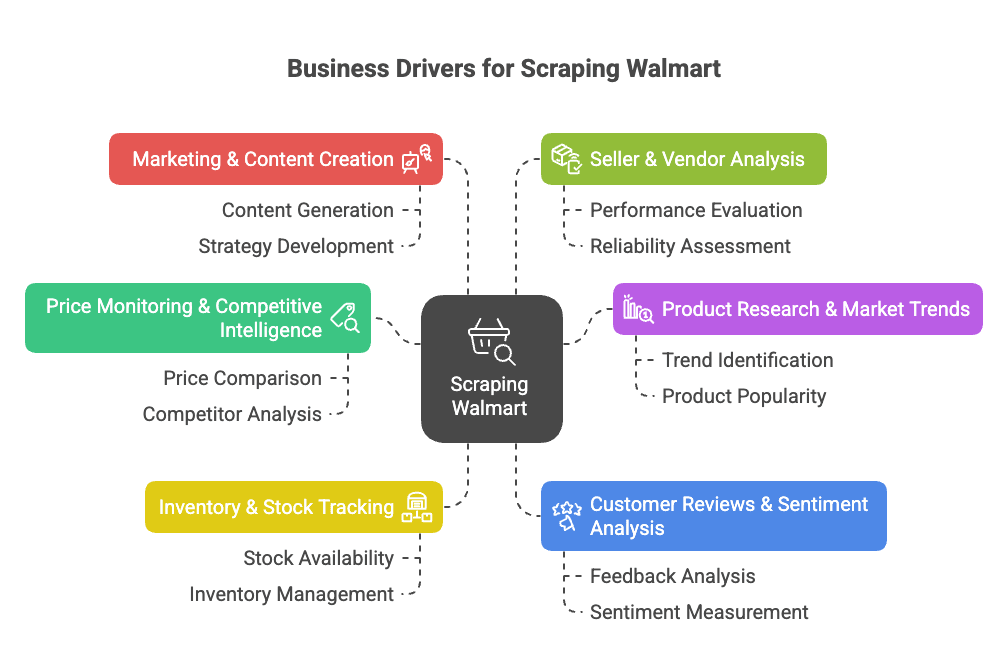
为什么要抓取Walmart?企业数据价值
Walmart不仅是美国最大的线下零售商,现在也是电商巨头,2023年线上销售额突破,电商业务占总销售近18%()。这背后蕴藏着海量商品、价格、评论和趋势数据,极具分析价值。
为什么要抓取Walmart?主要商业驱动力如下:
- 价格监控与竞品分析: 实时追踪Walmart价格、促销和商品变动,优化自己的定价和产品策略()。
- 商品调研与市场趋势: 分析Walmart的商品结构、参数和品类趋势,发现市场空白或新机会()。
- 库存与供货监控: 跟踪商品库存状态,优化供应链,抓住竞品断货机会()。
- 用户评论与口碑分析: 汇总并分析评论,提升产品质量,发现用户痛点()。
- 营销与内容优化: 了解哪些商品被标记为“畅销”,分析页面内容和转化要素()。
- 卖家与供应商分析: 识别表现突出的第三方卖家或未授权商品()。
下面这张表快速总结了应用场景、受益人群和带来的价值:
| 应用场景 | 受益团队 | 价值与回报 |
|---|---|---|
| 价格监控 | 定价与销售团队 | 实时竞品价格、动态定价、保护利润率 |
| 商品与目录分析 | 产品管理、商品运营 | 发现品类空白、上新、完善商品目录 |
| 库存跟踪 | 运营与供应链 | 更准的需求预测、避免断货、优化分销 |
| 用户评论与口碑 | 产品开发、客户体验 | 数据驱动产品优化、提升满意度 |
| 市场趋势与分析 | 战略与市场研究 | 把握趋势、辅助决策、抢占新市场 |
| 内容与定价策略 | 市场与电商团队 | 优化定价、借鉴高转化内容 |
| 卖家监控 | 销售与合作伙伴团队 | 寻找合作、保护品牌、监控未授权卖家 |
一句话总结:walmart数据抓取能帮你省下大量时间、提升营收,让你在数据竞争中快人一步。不用每天手动查几十页,脚本几分钟就能批量拉取上千条商品信息()。
walmart数据抓取对电商、销售和市场调研团队来说就是效率神器。用好工具,自动化采集数据,把精力用在分析洞察上,而不是重复劳动。
用Python抓取Walmart:你需要准备什么?
开始抓取前,先搭建好Python环境。推荐工具包如下:
- Python 3.9及以上(2025年建议用3.11或3.12)
- Requests:抓取网页
- BeautifulSoup (bs4):解析HTML
- pandas:整理和导出数据
- json:处理JSON数据(内置)
- 带开发者工具的浏览器:分析Walmart页面结构(F12快捷键)
- pip:安装Python库
快速安装命令:
1pip install requests beautifulsoup4 pandas可选:想让项目更整洁,可以新建虚拟环境:
1python3 -m venv walmart-scraper
2source walmart-scraper/bin/activate # Mac/Linux
3# 或
4walmart-scraper\\Scripts\\activate.bat # Windows测试环境:
1import requests, bs4, pandas
2print("Libraries loaded successfully!")看到提示就说明环境OK。
步骤1:搭建你的Python walmart爬虫
先整理好项目结构:
- 新建项目文件夹(比如
walmart_scraper/)。 - 打开代码编辑器(VSCode、PyCharm或Notepad++都行)。
- 新建脚本文件(比如
walmart_scraper.py)。
快速模板如下:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pd
4import json现在可以正式抓取Walmart商品页面了。
步骤2:用Python获取Walmart商品页面
抓取Walmart,第一步是获取商品页面的HTML。但要注意:Walmart对爬虫拦截很严格,直接用requests.get(url),很可能立刻被识别为机器人。
诀窍是:模拟真实浏览器。 也就是设置User-Agent、Accept-Language等请求头,让请求看起来像Chrome或Firefox。
示例代码:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0 Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9"
4}
5response = requests.get(url, headers=headers)
6html = response.text进阶建议: 用requests.Session()保持会话和Cookie,更像真人:
1session = requests.Session()
2session.headers.update(headers)
3session.get("<https://www.walmart.com/>") # 先访问首页设置Cookie
4response = session.get(product_url)记得检查response.status_code(应为200)。如果遇到异常页面或验证码,放慢速度、换IP或暂停一会儿。Walmart的反爬机制非常强大()。
应对Walmart反爬机制
Walmart采用Akamai、PerimeterX等技术,通过IP、请求头、Cookie甚至TLS指纹识别爬虫。应对方法:
- 始终设置真实请求头(见上文)。
- 控制请求频率——每次请求间隔3–6秒。
- 延迟时间随机化,避免规律操作被识别。
- 大规模抓取时轮换代理IP(后文详述)。
- 遇到验证码就暂停,不要强行破解。
如果想更隐蔽,可以用curl_cffi等库让请求更像真实浏览器()。但大多数场景下,合理设置请求头和耐心等待就够了。
步骤3:用BeautifulSoup提取Walmart商品数据
接下来就是提取你关心的数据。Walmart网站基于Next.js,大部分商品信息都嵌在<script id="__NEXT_DATA__">标签的JSON数据里。
提取方法如下:
1from bs4 import BeautifulSoup
2import json
3soup = BeautifulSoup(html, "html.parser")
4script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
5if script_tag:
6 json_text = script_tag.string
7 data = json.loads(json_text)现在你就得到了包含所有商品信息的Python字典。一般商品详情在:
1product_data = data["props"]["pageProps"]["initialData"]["data"]["product"]然后提取所需字段:
1name = product_data.get("name")
2price_info = product_data.get("price", {})
3current_price = price_info.get("price")
4currency = price_info.get("currency")
5rating_info = product_data.get("rating", {})
6average_rating = rating_info.get("averageRating")
7review_count = rating_info.get("numberOfReviews")
8description = product_data.get("shortDescription") or product_data.get("description")为什么用JSON? 因为结构清晰、稳定,不容易因页面微调而失效,而且能拿到更多细节()。
动态内容与JSON数据处理
有些信息(如评论、库存)是通过JavaScript或API动态加载的。好消息是,初始JSON通常已包含快照。如果没有,可以用浏览器开发者工具的Network面板找API接口,模拟请求。
但大多数商品数据,__NEXT_DATA__里的JSON就够用了。
步骤4:保存与导出Walmart数据
数据抓取后,建议用结构化格式保存——CSV、Excel或JSON都可以。用pandas导出示例:
1import pandas as pd
2product_record = {
3 "Product Name": name,
4 "Price (USD)": current_price,
5 "Rating": average_rating,
6 "Review Count": review_count,
7 "Description": description
8}
9df = pd.DataFrame([product_record])
10df.to_csv("walmart_products.csv", index=False)如果抓取多个商品,把每条数据加到列表,最后统一生成DataFrame。
想导出Excel?用df.to_excel("walmart_products.xlsx", index=False)(需安装openpyxl)。导出JSON:df.to_json("walmart_products.json", orient="records", indent=2)。
小贴士: 导出后一定要抽查数据,确保和网页一致。别等抓了1000条才发现全是“None”,只因字段名变了。
步骤5:批量抓取Walmart商品
想批量抓取?可以这样:
1product_urls = [
2 "<https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/720559357>",
3 "<https://www.walmart.com/ip/SAMSUNG-65-Class-QLED-4K-Q60C/180355997>",
4 # ...更多URL
5]
6all_records = []
7for url in product_urls:
8 resp = session.get(url)
9 # ...按前述方法解析提取...
10 all_records.append(product_record)
11 time.sleep(random.uniform(3, 6)) # 礼貌延迟!如果没有商品URL列表,可以从搜索结果页提取商品链接,再逐个抓取()。
注意: 快速抓取数百上千页面,IP很容易被封,这时就需要用代理。
Walmart代理与爬虫API的使用
代理可以轮换IP,降低被封风险。可购买住宅代理或用代理池。用requests设置代理示例:
1proxies = {
2 "http": "<http://your.proxy.address>:port",
3 "https": "<https://your.proxy.address>:port"
4}
5response = session.get(url, proxies=proxies)大规模抓取时,也可以用爬虫API——这些服务帮你搞定代理、验证码、甚至JS渲染。你只需提交Walmart链接,直接拿到数据(有时已解析为JSON)。
对比如下:
| 方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 自建Python+代理 | 完全可控,小规模成本低 | 需维护、代理费用、易被封 | 开发者、定制需求 |
| 第三方爬虫API | 简单易用、自动防封、易扩展 | 大规模成本高、灵活性有限、依赖第三方 | 企业用户、大规模、快速需求 |
如果你不会编程,或者想快速拿到数据,能一键搞定——无需代码、无需代理、无烦恼。(后文有详细介绍。)
Walmart数据抓取常见难题与解决方案
walmart数据抓取并不是一帆风顺,常见问题及应对方法如下:
- 强力反爬机制: Walmart通过IP、请求头、Cookie、TLS指纹、JS检测等多重手段识别爬虫。解决办法:设置真实请求头、用Session、加延迟、轮换代理()。
- 验证码拦截: 遇到验证码时暂停,稍后重试。若频繁遇到,可考虑验证码识别服务,但会增加成本和复杂度()。
- 页面结构变动: Walmart经常调整页面。如果爬虫失效,重新检查JSON结构并更新代码。模块化代码有助于维护。
- 分页与子页面: 批量抓取需处理分页。用循环并设置好终止条件,确保不会漏抓或死循环()。
- 数据量与速率限制: 大批量抓取时,分批请求并及时写入磁盘,避免内存溢出。
- 法律与合规风险: 只抓取公开数据,遵守Walmart条款,不要对服务器造成压力。如用于商业用途,务必合规。
什么时候该用托管工具? 如果你花在对抗验证码上的时间多于分析数据,建议用Thunderbit或爬虫API。对非开发者来说,无代码工具往往是最优解()。
用Python抓取Walmart:完整示例代码
综合前文,下面是一个完整、带注释的Walmart商品抓取脚本:
1import requests
2from bs4 import BeautifulSoup
3import json
4import pandas as pd
5import time
6import random
7# 设置会话和请求头
8session = requests.Session()
9session.headers.update({
10 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0 Safari/537.36",
11 "Accept-Language": "en-US,en;q=0.9"
12})
13# 先访问首页设置Cookie
14session.get("<https://www.walmart.com/>")
15# 商品URL列表
16product_urls = [
17 "<https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/720559357>",
18 "<https://www.walmart.com/ip/SAMSUNG-65-Class-QLED-4K-Q60C/180355997>",
19 # 可添加更多URL
20]
21all_products = []
22for url in product_urls:
23 try:
24 response = session.get(url)
25 except Exception as e:
26 print(f"请求出错:\{url\}: \{e\}")
27 continue
28 if response.status_code != 200:
29 print(f"获取失败:\{url\}(状态码\{response.status_code\})")
30 continue
31 soup = BeautifulSoup(response.text, "html.parser")
32 script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
33 if not script_tag:
34 print(f"未找到数据脚本:\{url\},可能被拦截或页面结构变动。")
35 continue
36 try:
37 data = json.loads(script_tag.string)
38 except json.JSONDecodeError as e:
39 print(f"JSON解析失败:\{url\}: \{e\}")
40 continue
41 try:
42 product_info = data["props"]["pageProps"]["initialData"]["data"]["product"]
43 except KeyError:
44 print(f"JSON中未找到商品数据:\{url\}。")
45 continue
46 name = product_info.get("name")
47 brand = product_info.get("brand", {}).get("name") or product_info.get("brand", "")
48 price_obj = product_info.get("price", {})
49 price = price_obj.get("price")
50 currency = price_obj.get("currency")
51 orig_price = price_obj.get("priceStrikethrough") or price_obj.get("price_strikethrough")
52 rating_obj = product_info.get("rating", {})
53 avg_rating = rating_obj.get("averageRating")
54 review_count = rating_obj.get("numberOfReviews")
55 desc = product_info.get("description") or product_info.get("shortDescription") or ""
56 product_record = {
57 "URL": url,
58 "Name": name,
59 "Brand": brand,
60 "Price": price,
61 "Currency": currency,
62 "OriginalPrice": orig_price,
63 "AverageRating": avg_rating,
64 "ReviewCount": review_count,
65 "Description": desc
66 }
67 all_products.append(product_record)
68 # 随机延迟,防止被封
69 time.sleep(random.uniform(3.0, 6.0))
70df = pd.DataFrame(all_products)
71print(df.head(5))
72df.to_csv("walmart_scrape_output.csv", index=False)可自定义:
- 在
product_urls中添加更多商品链接。 - 根据需求调整提取字段。
- 根据风险偏好调整延迟时间。
总结与要点回顾
回顾一下核心内容:
- walmart数据抓取能高效获取价格、商品、评论等关键信息,助力2025年竞品分析、定价和产品开发。
- Python是首选工具:用Requests、BeautifulSoup和pandas,即使非专业开发者也能搭建高效爬虫。
- 反爬机制需重视:模拟浏览器请求头、用Session、加延迟、批量时用代理。
- 优先解析
__NEXT_DATA__里的JSON:结构清晰、稳定,远比直接抓HTML标签可靠。 - 数据导出便于分析:用pandas导出CSV、Excel或JSON。
- 批量抓取需谨慎扩展:大规模建议用代理或爬虫API。不会编程可用,支持Walmart等多站点一键抓取,还能免费导出到Excel、Google Sheets、Airtable或Notion()。
我的建议:
从小规模做起——先抓一个商品,再试几个。确保数据准确,遵守Walmart条款,不要对服务器造成压力。需求扩大时,考虑用托管工具或API,省时省心。如果你厌倦了调试Python,记得:用Thunderbit,抓取Walmart和几乎所有网站只需两步,AI自动搞定所有难题()。
想深入了解网页抓取、数据自动化或AI高效办公?欢迎访问。
祝你抓取顺利,数据新鲜、准确、无验证码困扰!
P.S. 如果你凌晨2点还在抓Walmart,一边敲代码一边碎碎念,别担心——每个数据人都经历过。调试,其实就是数据人的修炼之路。
常见问题解答
1. 用Python抓取Walmart数据合法吗?
抓取公开数据用于个人或非商业分析通常是允许的,但企业用途可能涉及法律和合规风险。务必查阅Walmart服务条款,确保不违反访问频率、不抓取敏感数据、不对服务器造成负担。
2. 用Python能抓到哪些Walmart数据?
可以抓取商品名称、价格、品牌、描述、用户评论、评分、库存状态等,尤其是解析Walmart <script id="__NEXT_DATA__">标签中的结构化JSON数据。
3. 如何避免抓取Walmart时被封?
设置真实请求头、保持会话、请求间隔随机(3–6秒)、轮换代理,避免短时间内大量请求。大规模项目建议用爬虫API或Thunderbit等自动防封工具。
4. 能批量抓取上百上千个Walmart商品吗?
可以,但需管理代理、控制请求速率,必要时用爬虫API提升效率。Walmart反爬机制很强,盲目扩展易被封或遇到验证码。
5. 不会编程怎么抓取Walmart?
用Thunderbit AI网页爬虫Chrome插件,无需写代码即可抓取Walmart商品数据,自动防封,支持导出到Excel、Notion、Sheets,非常适合非开发者或需要快速洞察的企业团队。