互联网的数据量大到让人咋舌——有预测说,全球网页爬虫市场到。不管你是数据分析师、市场营销人,还是刚入门想玩数据的小白,从网站提取数据已经成了必备技能。毕竟,谁还愿意一遍遍复制粘贴?大家都想直接拿到干净的数据表、自动化流程,省时省力还能挖掘新机会。
这时候,Python 就像数据界的万能工具箱一样闪亮登场。它对新手特别友好,功能却超级强大,无论是单页采集还是批量爬取成千上万网页都不在话下。这篇教程会带你用 Python 玩转网页爬虫,教你怎么搞定动态网站,还会介绍,一款 AI 驱动、零代码的网页爬虫神器,让你抓数据就像点外卖一样简单。无论你想学点代码,还是只想一键搞定数据,这里都能帮到你。
什么是网页爬虫?为什么用 Python 从网站提取数据?
网页爬虫其实就是自动化地从网站上批量提取信息,把它们变成结构化数据(比如表格、CSV 或数据库),方便后续分析或者业务用()。和手动复制粘贴比,爬虫的速度和规模完全不是一个量级。
为啥这项技能这么重要?因为现在做生意,数据驱动决策已经成了标配。都靠数据(很大一部分就是爬虫抓的)来定价、做市场调研、找客户。你可以每天盯着竞品价格、汇总房产信息,或者自定义潜在客户名单——全程不用手动操作。
那为啥选 Python?理由很简单:
- 语法简单易懂: Python 代码清晰,初学者也能很快写出爬虫脚本()。
- 生态圈超丰富: 有
requests、BeautifulSoup、Scrapy、Selenium等一堆强大库,抓取、解析、自动化全都能搞定。 - 社区活跃: Python 连续多年都是,教程、论坛、代码示例应有尽有。
- 可扩展性强: 不管是一次性小脚本还是大规模爬取项目,Python 都能轻松胜任。
总之,不管你是零基础还是老司机,Python 都是入门网页数据世界的首选。
入门指南:Python 网页爬虫基础流程
在动手写代码前,先来看看用 Python 从网站提取数据的基本流程:
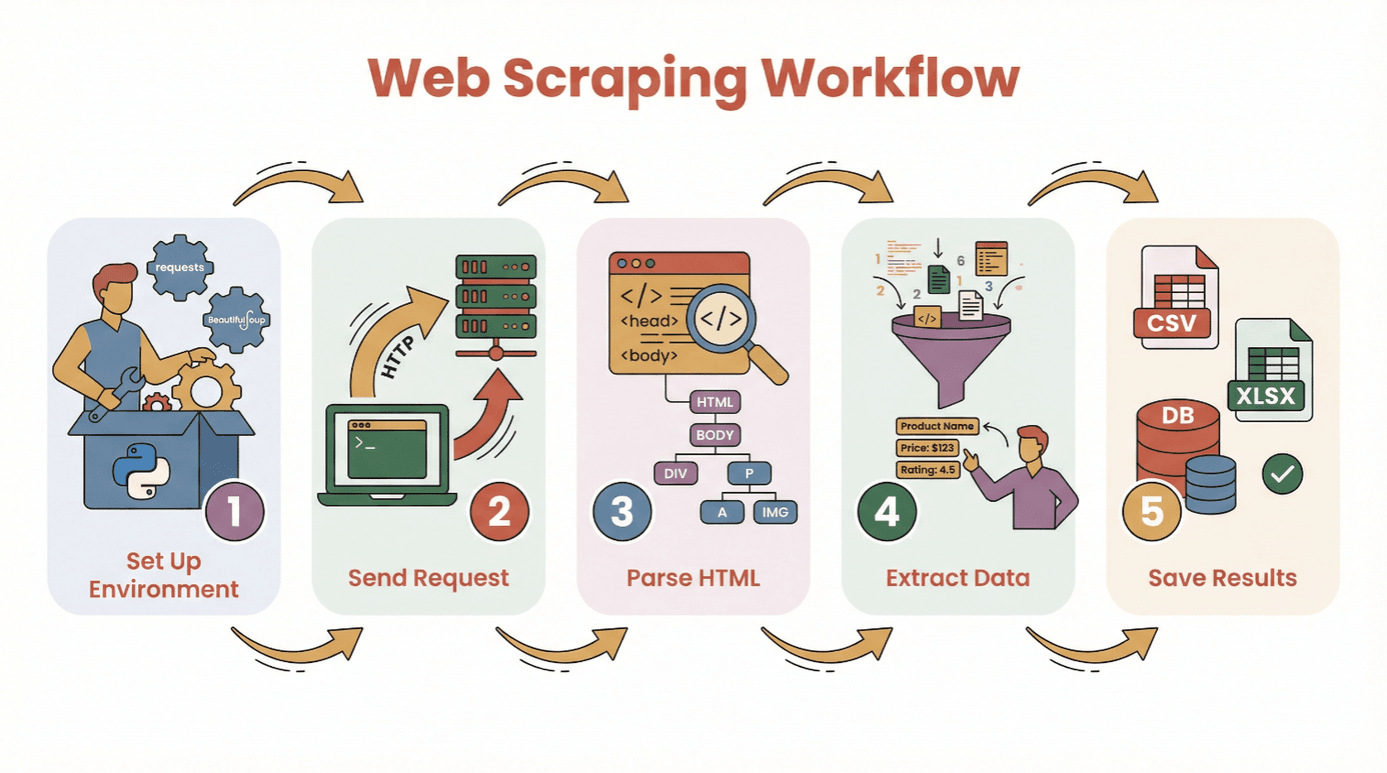
- 环境准备: 安装 Python 和需要的库(比如
requests、BeautifulSoup)。 - 发送请求: 用 Python 获取目标网页的 HTML。
- 解析 HTML: 用解析器分析网页结构。
- 提取数据: 找到并抓取你想要的信息。
- 保存结果: 把数据存成 CSV、Excel 或数据库,方便后续分析。
你不用是编程高手,只要会装 Python、能跑脚本就能上手。新手建议用 或 Jupyter notebook,当然用普通文本编辑器也没问题。
常用库推荐:
requests—— 获取网页内容BeautifulSoup—— 解析 HTMLpandas—— 数据清洗和保存(可选但强烈推荐)
如何选择合适的 Python 网页爬虫库:BeautifulSoup、Scrapy 还是 Selenium?
不同的 Python 爬虫工具各有千秋。下面简单对比三大主流方案:
| 工具 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| BeautifulSoup | 静态页面、小项目、初学者 | 易用、配置简单、文档丰富 | 不适合大规模爬取或动态内容 |
| Scrapy | 大型项目、多页面爬取 | 高效异步、内置数据管道、自动跟踪链接 | 学习曲线较陡,小项目略显复杂、不支持 JS 渲染 |
| Selenium | 动态/JS 页面、自动化操作 | 可渲染 JS、模拟用户操作、支持登录和点击 | 速度慢、资源消耗大、配置相对复杂 |
BeautifulSoup:新手和小项目的首选
BeautifulSoup 特别适合刚入门和小型项目。只要几行代码就能解析 HTML、提取元素。如果目标网站是静态页面(不依赖复杂 JS),BeautifulSoup 搭配 requests 就够用了。
示例:
1import requests
2from bs4 import BeautifulSoup
3url = "https://example.com"
4response = requests.get(url)
5soup = BeautifulSoup(response.text, 'html.parser')
6titles = [h2.text for h2 in soup.find_all('h2', class_='product-title')]
7print(titles)适合场景:一次性采集、博客、产品页、目录类网站。
Scrapy:大规模爬取和结构化数据的利器
Scrapy 是专为大规模、多页面爬取设计的框架。支持异步(速度快)、内置数据清洗和存储管道,还能自动跟踪网页链接。
示例:
1import scrapy
2class ProductSpider(scrapy.Spider):
3 name = "products"
4 start_urls = ["https://example.com/products"]
5 def parse(self, response):
6 for item in response.css('div.product'):
7 yield {
8 'name': item.css('h2::text').get(),
9 'price': item.css('span.price::text').get()
10 }适合场景:大型项目、定时爬取、对速度和结构有要求的任务。
Selenium:动态和 JavaScript 页面专用
Selenium 能控制真实浏览器(比如 Chrome、Firefox),专门用来搞定依赖 JavaScript 加载、需要登录或交互的网站。
示例:
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3driver = webdriver.Chrome()
4driver.get("https://example.com/login")
5driver.find_element(By.NAME, "username").send_keys("myuser")
6driver.find_element(By.NAME, "password").send_keys("mypassword")
7driver.find_element(By.XPATH, "//button[@type='submit']").click()
8dashboard = driver.find_element(By.ID, "dashboard").text
9print(dashboard)
10driver.quit()适合场景:社交媒体、股票网站、无限滚动页面、页面源码看不到数据的情况。
实战演练:用 Python 从网站提取数据(新手教程)
下面用 requests 和 BeautifulSoup 演示怎么抓取图书网站的书名、作者和价格。
步骤 1:环境准备
先安装需要的库:
1pip install requests beautifulsoup4 pandas在脚本里导入:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pd步骤 2:请求网页
获取 HTML 内容:
1url = "http://books.toscrape.com/catalogue/page-1.html"
2response = requests.get(url)
3if response.status_code == 200:
4 html = response.text
5else:
6 print(f"Failed to retrieve page: \{response.status_code\}")步骤 3:解析 HTML
创建 BeautifulSoup 对象:
1soup = BeautifulSoup(html, 'html.parser')查找所有图书容器:
1books = soup.find_all('article', class_='product_pod')
2print(f"Found {len(books)} books on this page.")步骤 4:提取所需数据
遍历每本书,提取详情:
1data = []
2for book in books:
3 title = book.h3.a['title']
4 price = book.find('p', class_='price_color').text
5 data.append({"Title": title, "Price": price})步骤 5:保存数据
转成 DataFrame 并导出:
1df = pd.DataFrame(data)
2df.to_csv('books.csv', index=False)现在你已经有一份干净的 CSV 文件,随时可以分析啦!
常见问题排查:
- 如果结果是空的,看看是不是数据被 JavaScript 加载了(见下节)。
- 用浏览器开发者工具检查 HTML 结构。
- 用
get_text(strip=True)和条件判断处理缺失数据。
动态内容应对:抓取 JavaScript 渲染的数据
现在的网站很多都用 JavaScript,想要的数据可能不在初始 HTML 里,而是页面加载后才出现。如果爬虫抓不到数据,十有八九就是遇到动态内容了。
解决办法:
- Selenium: 模拟真实浏览器,等内容加载好,可以自动点击、滚动。
- Playwright/Puppeteer: 更高级的无头浏览器,原理类似。
Selenium 简要指南:
- 安装 Selenium 和浏览器驱动(比如 ChromeDriver)。
- 用显式等待确保内容加载。
- 获取渲染后的 HTML,再用 BeautifulSoup 解析。
示例:
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3from selenium.webdriver.support.ui import WebDriverWait
4from selenium.webdriver.support import expected_conditions as EC
5driver = webdriver.Chrome()
6driver.get("https://example.com/dynamic")
7WebDriverWait(driver, 10).until(
8 EC.presence_of_element_located((By.CLASS_NAME, "dynamic-content"))
9)
10html = driver.page_source
11soup = BeautifulSoup(html, 'html.parser')
12# 如前提取数据
13driver.quit()什么时候用 Selenium?
- 用
requests.get()拿到的 HTML 没数据,但浏览器能看到。 - 网站有无限滚动、弹窗或需要登录。
用 AI 简化网页爬虫:Thunderbit 一键提取网站数据
说真的,有时候你只想要数据,根本不想写代码。这时候, 就是你的救星。Thunderbit 是一款 AI 网页爬虫 Chrome 插件,只要点几下就能从任意网站提取数据——完全不用 Python。
Thunderbit 怎么用:
- 装好 。
- 打开你想抓数据的网站。
- 点 Thunderbit 图标,选“AI 智能识别字段”。 Thunderbit 的 AI 会自动扫描页面,推荐可提取的数据(比如产品名、价格、邮箱等)。
- 需要的话可以手动调整字段,然后点“抓取”。
- 数据可以直接导出到 Excel、Google Sheets、Notion 或 Airtable。
Thunderbit 的亮点:
- 零代码门槛。 连我妈都能用(她连 Wi-Fi 都要问我)。
- 支持子页面和分页。 多页产品详情一键合并。
- 自然语言指令。 直接说“提取所有产品名和价格”,AI 自动帮你搞定。
- 热门网站模板。 亚马逊、Zillow、LinkedIn 等一键套用。
- 免费导出数据。 支持 CSV、Excel 或直连常用工具。
Thunderbit 已经被,免费版能抓 6 个页面(试用还能提升到 10 页)。对企业来说能省下大把时间,对技术用户来说也是快速原型的利器。
数据清洗与分析:用 Pandas 和 NumPy 处理爬取结果
抓到数据只是第一步。原始网页数据通常很乱——有重复、缺失、格式不统一。这时候 Python 的 pandas 和 NumPy 就能大显身手。
常见清洗操作:
- 去重:
df.drop_duplicates(inplace=True) - 处理缺失值:
df.fillna('未知')或df.dropna() - 数据类型转换:
df['Price'] = df['Price'].str.replace('$','').astype(float) - 日期解析:
df['Date'] = pd.to_datetime(df['Date']) - 异常值过滤:
df = df[df['Price'] > 0]
基础分析:
- 统计汇总:
df.describe() - 按类别分组:
df.groupby('Category')['Price'].mean() - 快速可视化:
df['Price'].hist()或df.groupby('Category')['Price'].mean().plot(kind='bar')
如果需要更高效的数值运算,NumPy 是首选。但大多数业务场景下,pandas 已经能搞定 95% 的需求。
新手资源: 推荐看 。
Python 网页爬虫实用建议与最佳实践
网页爬虫很强大,但也要讲规矩。下面是我的爬虫安全和合规小贴士:
- 遵守 robots.txt 和服务条款。 先查查网站允不允许爬虫()。
- 别太频繁请求。 每次请求间隔下(比如
time.sleep(2)),模拟正常用户访问速度。 - 设置真实请求头。 用 User-Agent 模拟浏览器。
- 异常处理。 用 try/except 捕获错误,失败时重试。
- 必要时用代理。 大规模爬取建议用代理池防止 IP 被封。
- 合法合规。 不要抓取个人隐私或需要登录的数据,除非获得授权。
- 记录过程。 记下爬取内容、来源和时间。
- 优先用官方 API。 有些网站有更稳定的数据接口。
更多建议可以参考 。
总结与要点回顾
用 Python 做网页爬虫,可以把网上的杂乱信息变成结构化、可用的数据。不管你用代码(requests、BeautifulSoup、Scrapy、Selenium),还是用零代码工具 ,都能轻松从网站提取数据,发现新机会。
记住:
- 从简单做起,先抓单页再挑战大项目。
- 选对工具(基础用 BeautifulSoup,大规模用 Scrapy,动态页面用 Selenium,零代码用 Thunderbit)。
- 用 pandas、NumPy 清洗和分析数据。
- 始终遵守道德和法律规范。
准备好动手了吗?不妨先抓个新闻或产品列表试试,体验下从网页到表格的高效转化。如果想更省事,直接,让 AI 帮你全搞定。
更多教程、技巧和爬虫干货,欢迎逛 。
常见问题解答
1. 什么是网页爬虫?为什么 Python 适合做爬虫?
网页爬虫就是自动化提取网站数据的技术。Python 之所以受欢迎,是因为语法简单、库强大(比如 BeautifulSoup、Scrapy、Selenium),社区资源也很丰富()。
2. Python 爬虫用哪个库最好?
静态页面用 BeautifulSoup,大规模或多页面爬取用 Scrapy,动态或 JS 页面用 Selenium。按需求选最合适的工具()。
3. 如何处理 JavaScript 加载的数据?
遇到 JS 渲染内容时,用 Selenium(或 Playwright)模拟浏览器,等内容加载后再提取。有时候也能在网络面板里找到数据接口。
4. Thunderbit 是什么?如何简化网页爬虫?
是一款 AI 网页爬虫 Chrome 插件,无需写代码就能从任意网站提取数据。它能智能识别字段、处理分页和子页面,还能导出到 Excel、Google Sheets、Notion 或 Airtable。
5. 如何用 Python 清洗和分析爬取的数据?
用 pandas 去重、处理缺失、类型转换和数据分析。NumPy 适合数值运算。pandas 还能配合 Matplotlib 快速可视化()。
祝你爬虫顺利,数据干净、结构清晰、随时可用!
延伸阅读