网络上的数据多到爆,但问题是:手动收集这些数据,和看油漆慢慢变干一样无聊——效率也差不多。到了 2025 年,企业面对的网页内容比以往任何时候都多,平均每天的网页数据摄入量从 2020 年的 1.2 TB 飙升到 2025 年的 8 TB()。无论你做的是销售、市场营销、电商还是运营,对快速、结构化、准确的网页数据的需求都不只是“有更好”——而是业务运转的刚需。说实话,没人有时间没完没了地复制粘贴。
这也是为什么内容爬取工具这几年突然火起来。从 AI 驱动的 Chrome 扩展,到企业级平台,这些工具都能帮你把整个流程自动化,把杂乱的网页变成干净的表格、数据库,或者实时仪表盘。我在 SaaS 和自动化领域做了很多年,可以负责任地说:合适的工具不只是帮你省时间,还会彻底改变团队的工作方式。所以,接下来就让我们一起看看 2025 年最值得用的 18 款内容爬取工具,重点聊聊每款工具的独特之处、适合哪些业务场景,以及你该怎么为自己的工作流选到最合适的那一款。
为什么企业需要顶级内容爬取工具
如果你曾经手动整理过潜在客户名单、监控过竞品价格,或者跟踪过市场情绪,你就知道人工收集数据会有多快变成一场噩梦。速度慢、容易出错,而且等你忙完,数据可能早就过时了。这也是为什么到 2025 年,超过 70% 的企业已经采用了自动化网页提取,把人工工作量削减了大约 60%()。
内容爬取工具可以自动从网站中提取结构化数据,让你能够:
- 把新的潜在客户直接导入 CRM(再也不用从目录里反复复制粘贴)
- 实时监控竞品价格和库存
- 汇总评论、新闻和社媒提及,用于营销洞察
- 构建用于研究或分析的自定义数据集
- 定时抓取数据,支持持续性报表
而且 ROI 是真真切切的:使用网页爬取的企业在 2020 到 2025 年间合计节省了超过 5 亿美元,运营效率提升了 20%–40%()。说到底,内容爬取工具释放了团队的时间,让大家能把精力放在战略上,而不是重复劳动上。
我们是如何筛选出顶级内容爬取工具的
并不是所有网页爬虫都一样。我整理这份榜单时,是从真实业务用户的视角来评估的——销售、市场、运营和研究团队需要的是结果,不是麻烦。以下几点最重要:
- 易用性: 非技术用户能不能快速上手?有没有点选式界面或 AI 辅助?
- 自动化与功能: 工具能不能处理分页、子页面、定时任务和动态内容?能不能在云端运行,以获得更快速度和更高扩展性?
- 数据导出与集成: 能不能导出到 Excel、CSV、Google Sheets、Airtable、Notion,或者通过 API 连接?
- 扩展性: 适不适合一次性任务,还是适合大规模、持续性的项目?
- 自定义能力: 能不能调整提取逻辑、添加自定义字段,或者处理棘手网站?
- 合规与隐私: 工具能不能帮助你遵守 GDPR、CCPA 和网站条款?
- 支持与社区: 有没有文档、客服,或者用户社区帮你排查问题?
- 成本: 有没有免费版或试用?价格是否符合你的规模和预算?
当然,我也特别强调了 Thunderbit——这是我和团队做出来的工具,因为我真心相信,它是业务用户开始使用 AI 网页爬虫的最简单方式。
2025 年最值得用的 18 款内容爬取工具
接下来,我们按“从 AI 驱动的极简方案,到开发者级强力工具,再到两者之间的各种选择”来逐一拆解。
1. Thunderbit
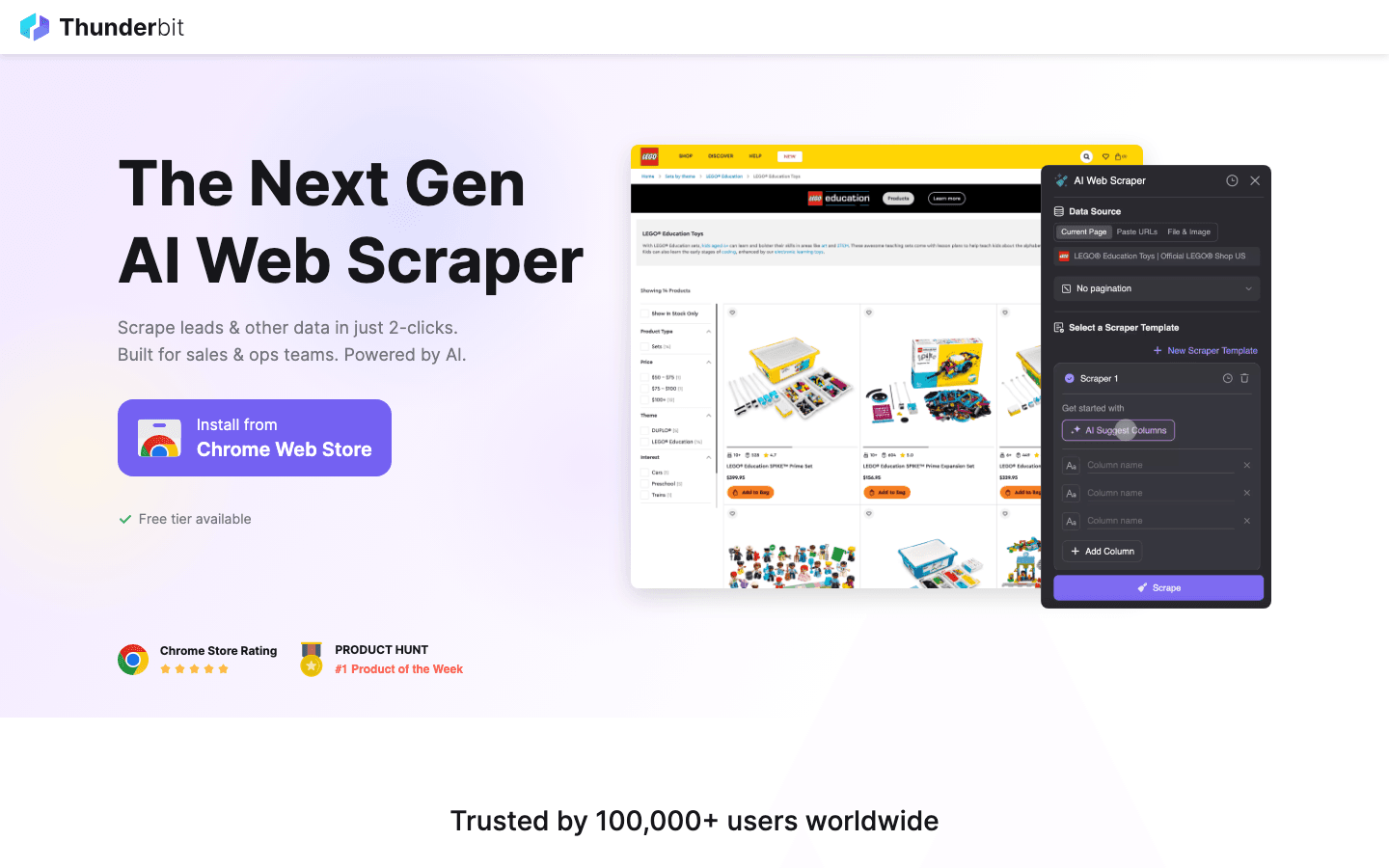 是一款面向业务用户的 AI 网页爬虫 Chrome 扩展,主打“快出结果”。它最亮眼的功能是 AI 推荐字段:你只需要打开网页,点击“AI 推荐”,Thunderbit 的 AI 就会读取页面,推荐要提取的字段,并自动帮你设置好爬虫。无需编程,也不用折腾选择器——点一下,抓取,导出,就这么简单。
是一款面向业务用户的 AI 网页爬虫 Chrome 扩展,主打“快出结果”。它最亮眼的功能是 AI 推荐字段:你只需要打开网页,点击“AI 推荐”,Thunderbit 的 AI 就会读取页面,推荐要提取的字段,并自动帮你设置好爬虫。无需编程,也不用折腾选择器——点一下,抓取,导出,就这么简单。
- 子页面抓取: Thunderbit 可以自动访问每个子页面(比如产品详情或个人资料详情),丰富你的数据集,非常适合线索开发或电商研究。
- 分页与模板: 可处理多页列表,并为 Amazon、Zillow、Instagram 等网站提供即用模板。
- 免费导出数据: 可导出到 Excel、Google Sheets、Airtable、Notion、CSV 或 JSON,不设付费墙。
- AI 自动填表: 用 AI 自动填写在线表单,把抓取能力延伸到工作流自动化。
- 云端与浏览器抓取: 可根据需要选择云端高速抓取公共网站,或在浏览器模式下处理登录态会话。
- 价格: 免费可抓取 6 个页面(试用可到 10 个),付费方案每月仅从 15 美元起。
Thunderbit 非常适合希望在没有技术门槛的情况下自动化数据收集的销售、市场和运营团队。它就是我当年希望能早点拥有的工具——现在,任何人都能在几分钟内搭好线索名单或监控竞品。
2. Scrapy
 是面向开发者的开源强力工具。它是一个基于 Python 的框架,允许你编写自定义 spider,大规模爬取并提取数据。Scrapy 为速度和灵活性而生,支持异步爬取、自定义数据管道、代理轮换,以及与数据库或 API 的集成。
是面向开发者的开源强力工具。它是一个基于 Python 的框架,允许你编写自定义 spider,大规模爬取并提取数据。Scrapy 为速度和灵活性而生,支持异步爬取、自定义数据管道、代理轮换,以及与数据库或 API 的集成。
- 适合人群: 开发者和数据工程师,适合构建大型、复杂或持续性的爬取项目。
- 优势: 完全可控、可扩展、社区庞大、稳定性经过实战验证。
- 不足: 非程序员学习曲线陡峭;没有可视化界面。
如果你会 Python,并且想构建稳定、可扩展的爬虫,Scrapy 就是行业标杆。
3. Octoparse
 是一款无代码、基于云端的网页爬虫,带有可视化拖拽界面。你可以通过点选来选择数据、设置分页,甚至借助 AI 辅助的模式识别来加快配置。
是一款无代码、基于云端的网页爬虫,带有可视化拖拽界面。你可以通过点选来选择数据、设置分页,甚至借助 AI 辅助的模式识别来加快配置。
- 预置模板: 几分钟内即可从 Amazon、Twitter 和 Google 地图等热门网站提取数据。
- 云端抓取与定时: 可在 Octoparse 的服务器上运行任务,设置循环执行,处理大规模项目。
- 导出选项: CSV、Excel、JSON、API 集成。
- 价格: 有功能受限的免费版;付费方案约从每月 75 美元起。
Octoparse 非常适合希望在不写代码的情况下获得强大抓取能力的业务分析师和非程序员。
4. ParseHub
 是一款可视化网页爬虫,擅长处理动态内容和复杂的网站结构。它的点选式界面让你可以通过条件逻辑、循环和多层级导航来构建工作流。
是一款可视化网页爬虫,擅长处理动态内容和复杂的网站结构。它的点选式界面让你可以通过条件逻辑、循环和多层级导航来构建工作流。
- 动态内容: 可处理下拉菜单、无限滚动和交互元素。
- 云端与本地运行: 可在云端运行项目(付费),或者本地运行小型任务。
- 导出: CSV、Excel、JSON、API。
- 价格: 免费版比较慷慨;付费方案每月从 49 美元起。
ParseHub 很适合需要灵活性和强大能力、且要处理棘手网站的非程序员。
5. Data Miner
 是一个适用于 Chrome/Edge 的扩展,主打快速、基于模板的抓取。它提供 50,000+ 个公开提取配方,覆盖 15,000+ 网站,很多时候你只要点一下,就能把页面抓下来。
是一个适用于 Chrome/Edge 的扩展,主打快速、基于模板的抓取。它提供 50,000+ 个公开提取配方,覆盖 15,000+ 网站,很多时候你只要点一下,就能把页面抓下来。
- Google Sheets 集成: 可将抓取的数据直接上传到 Sheets。
- 自定义配方: 通过点选或 XPath 构建自己的提取逻辑。
- 分页与自动化: 支持多页抓取和定时运行。
- 价格: 有免费版;付费方案从每月 19 美元起。
非常适合需要从浏览器里快速抓取中小规模数据的分析师和市场人员。
6. WebHarvy
 是一款 Windows 桌面应用,具有点选式界面和自动模式识别功能。你只要点击一个元素,WebHarvy 就会高亮显示所有相似项,方便提取。
是一款 Windows 桌面应用,具有点选式界面和自动模式识别功能。你只要点击一个元素,WebHarvy 就会高亮显示所有相似项,方便提取。
- 支持图片、文本、分页: 可抓取产品图片、邮箱、URL 等更多内容。
- 桌面定时: 可在你的电脑上安排定时抓取。
- 一次性授权: 每台电脑大约 199 美元。
非常适合想要简单、无订阅、可周期性使用的中小企业用户。
7. Import.io
 是一款面向企业级大规模数据提取的云平台。它提供 AI 驱动的数据清洗、实时监控和强大的合规功能。
是一款面向企业级大规模数据提取的云平台。它提供 AI 驱动的数据清洗、实时监控和强大的合规功能。
- API 集成: 可直接把数据送到数据库、BI 仪表盘或应用程序中。
- 合规性: 从设计上就考虑了 GDPR 和 CCPA。
- 价格: 企业合同,高端定价。
最适合需要可靠、合规、可扩展网页数据管道的大型组织。
8. Apify
 是一个云端自动化平台,也是网页爬虫 “actor”(机器人)的市场。你可以直接使用常见网站的预制 actor,也可以用 JavaScript 或 Python 自己开发。
是一个云端自动化平台,也是网页爬虫 “actor”(机器人)的市场。你可以直接使用常见网站的预制 actor,也可以用 JavaScript 或 Python 自己开发。
- 市场: 提供数百个可直接使用的爬虫,覆盖 LinkedIn、Amazon 等网站。
- 定时与 API: 可运行、定时,并通过 API 集成 actor。
- 价格: 有免费版;付费使用从每月 49 美元起。
非常适合想要自动化、灵活性和社区驱动解决方案的开发者和技术型团队。
9. Visual Web Ripper
 是一款桌面工具,适合高级、大批量数据提取。它的工作流构建器让你可以设计多层级爬取并自动化大规模项目。
是一款桌面工具,适合高级、大批量数据提取。它的工作流构建器让你可以设计多层级爬取并自动化大规模项目。
- 定时与自动化: 可按设定间隔运行项目。
- 数据库集成: 可直接导出到 SQL、Excel、CSV、XML 或 JSON。
- 一次性授权: 大约 349 美元。
最适合需要在内部提取海量数据的 IT 团队或高级用户。
10. Dexi.io
 是一个基于云端的平台,适合协作式网页数据项目。它提供工作流自动化、定时任务和团队管理功能。
是一个基于云端的平台,适合协作式网页数据项目。它提供工作流自动化、定时任务和团队管理功能。
- 工作流自动化: 可在团队之间构建并共享数据管道。
- API 与导出: 可与数据库、云存储或 BI 工具集成。
- 价格: 定制报价;主要面向团队和企业。
非常适合管理持续进行、需要协作的组织数据项目。
11. Content Grabber
 是面向代理商和企业的专业级抓取工具。它提供高级自动化、错误处理,甚至还有白标方案。
是面向代理商和企业的专业级抓取工具。它提供高级自动化、错误处理,甚至还有白标方案。
- 脚本与自定义: 可使用 C# 或 VB.NET 进行深度控制。
- 错误恢复与日志: 为大规模任务的稳定性而设计。
- 企业定价: 偏高端;提供免费试用。
最适合为客户打造自定义、可重复使用抓取方案的代理商或企业。
12. Helium Scraper
 是一款将可视化提取与脚本灵活性结合起来的桌面工具。大多数任务可以直接点选完成;遇到高级逻辑时,也可以写自定义 JavaScript。
是一款将可视化提取与脚本灵活性结合起来的桌面工具。大多数任务可以直接点选完成;遇到高级逻辑时,也可以写自定义 JavaScript。
- 支持动态内容: 可抓取 AJAX 较多的网站。
- 数据清洗与转换: 内置脚本功能,便于自定义工作流。
- 一次性授权: 大约 99 美元。
非常适合既想要灵活性、又不想订阅付费的高级用户。
13. Web Scraper
 是一款免费的 Chrome 扩展,很多人都是从它开始接触网页爬取的。你可以定义站点地图,点击选择元素,然后导出到 CSV 或 JSON。
是一款免费的 Chrome 扩展,很多人都是从它开始接触网页爬取的。你可以定义站点地图,点击选择元素,然后导出到 CSV 或 JSON。
- 多层级爬取: 可跟随链接、处理分页、抓取嵌套数据。
- 本地使用免费: 也提供付费云版本,用于定时和扩展规模。
非常适合初学者、学生,或者任何想快速免费处理小任务的人。
14. Mozenda
 是一个企业级云平台,重点关注合规、可扩展性和托管服务。它的点选式界面可以让你构建用于数据提取的 “agent”。
是一个企业级云平台,重点关注合规、可扩展性和托管服务。它的点选式界面可以让你构建用于数据提取的 “agent”。
- 托管服务: Mozenda 团队可以为你构建并维护爬虫。
- 合规与支持: 非常重视 GDPR、CCPA 和企业需求。
- 价格: 起价约每月 500 美元。
最适合想要交钥匙式、可扩展网页数据方案,并且需要强力支持的大型组织。
15. SimpleIndex
 是一款同时支持文档和网页数据提取的自动化工具,重点在 OCR 和索引。
是一款同时支持文档和网页数据提取的自动化工具,重点在 OCR 和索引。
- 屏幕抓取 OCR: 可从扫描文档、PDF,甚至屏幕上的网页表单中提取数据。
- 集成: 可输出到数据库、文档管理系统。
- 一次性授权: 每个工作站几百美元。
非常适合把文档流程和网页数据流程结合在一起的组织。
16. Spinn3r
 是一款面向博客、新闻和社交媒体的实时内容爬取平台。它的 Firehose API 能从数百万个来源持续输出新的内容流。
是一款面向博客、新闻和社交媒体的实时内容爬取平台。它的 Firehose API 能从数百万个来源持续输出新的内容流。
- 垃圾信息过滤与语言处理: 输出干净、结构化的数据流。
- API 访问: 可直接集成到你的系统中。
- 订阅式定价: 按使用量计费。
最适合媒体监测、新闻聚合,或需要实时内容流的研究团队。
17. FMiner
 是一款用于复杂网页爬取的可视化工作流构建工具。它的拖拽式界面让你可以设计多层级、带条件判断的抓取流程。
是一款用于复杂网页爬取的可视化工作流构建工具。它的拖拽式界面让你可以设计多层级、带条件判断的抓取流程。
- Python 脚本: 可插入自定义代码实现高级逻辑。
- 跨平台: 支持 Windows 和 Mac。
- 一次性授权: 起价约 168 美元。
非常适合想要用可视化方式梳理复杂工作流的分析师或数据科学家。
18. G2 Webscraper
 (这里指的是 G2 上评分很高的工具)因简单有效而广受好评。用户喜欢那些免费、易用、还能节省大量时间的工具——比如 Web Scraper Chrome 扩展或 Data Miner。
(这里指的是 G2 上评分很高的工具)因简单有效而广受好评。用户喜欢那些免费、易用、还能节省大量时间的工具——比如 Web Scraper Chrome 扩展或 Data Miner。
- 用户评价强: 在易用性和可靠性方面评分很高。
- 快速上手: 适合基础到中级任务,学习成本低。
如果你想要一个“开箱即用”的简单抓取工具,G2 上的用户热门款通常是稳妥选择。
对比表:顶级内容爬取工具一览
| 工具 | 易用性 | 自动化与功能 | 导出格式 | 合规与隐私 | 价格 | 最适合 |
|---|---|---|---|---|---|---|
| Thunderbit | ⭐⭐⭐⭐⭐ | AI 字段、子页面、云端 | Excel、CSV、Sheets、Notion、Airtable、JSON | 用户引导 | 免费,起价 $15/月 | 非程序员、销售、运营 |
| Scrapy | ⭐ | 全代码、异步、插件 | CSV、JSON、数据库 | 用户自主管理 | 免费,开源 | 开发者、大型项目 |
| Octoparse | ⭐⭐⭐⭐ | 可视化、模板、云端 | CSV、Excel、JSON、API | 用户引导 | 免费,起价 $75/月 | 分析师、电商、非程序员 |
| ParseHub | ⭐⭐⭐⭐ | 可视化、动态内容、云端 | CSV、Excel、JSON、API | 用户引导 | 免费,起价 $49/月 | 非程序员、复杂网站 |
| Data Miner | ⭐⭐⭐⭐⭐ | 模板、浏览器、Sheets | CSV、Excel、Sheets | 用户引导 | 免费,起价 $19/月 | 快速浏览器任务 |
| WebHarvy | ⭐⭐⭐⭐⭐ | 可视化、模式识别 | Excel、CSV、XML、JSON | 用户引导 | 一次性 $199 | Windows 用户、中小企业 |
| Import.io | ⭐⭐⭐⭐ | AI、云端、监控 | CSV、API、数据库 | GDPR、CCPA | 企业版 | 大型组织、合规需求 |
| Apify | ⭐⭐⭐ | 云端、市场、API | JSON、API、Sheets | 用户自主管理 | 免费,起价 $49/月 | 开发者、自动化、集成 |
| Visual Web Ripper | ⭐⭐⭐ | 工作流、定时 | CSV、Excel、数据库 | 用户引导 | 一次性 $349 | IT 团队、大批量数据 |
| Dexi.io | ⭐⭐⭐ | 云端、团队、工作流 | CSV、API、数据库、存储 | 用户引导 | 定制报价 | 团队、持续性项目 |
| Content Grabber | ⭐⭐⭐ | 脚本、自动化 | CSV、XML、数据库 | 用户引导 | 企业版 | 代理商、自定义方案 |
| Helium Scraper | ⭐⭐⭐ | 可视化 + 脚本 | CSV、数据库 | 用户引导 | 一次性 $99 | 高级用户、自定义逻辑 |
| Web Scraper | ⭐⭐⭐⭐⭐ | 站点地图、浏览器 | CSV、JSON | 用户引导 | 免费(本地) | 初学者、小任务 |
| Mozenda | ⭐⭐⭐ | 云端、托管、合规 | CSV、API、数据库 | GDPR、CCPA | $500+/月 | 企业、托管服务 |
| SimpleIndex | ⭐⭐⭐ | OCR、网页、文档 | 数据库、文档管理系统 | 用户引导 | 一次性 $500 | 文档 + 网页数据 |
| Spinn3r | ⭐⭐ | 实时、API | JSON、API | 用户引导 | 订阅制 | 媒体、新闻、研究 |
| FMiner | ⭐⭐⭐ | 可视化工作流、Python | CSV、数据库 | 用户引导 | 一次性 $168 | 复杂、可视化工作流 |
| G2 Webscraper | ⭐⭐⭐⭐⭐ | 简单、浏览器 | CSV、JSON | 用户引导 | 免费/不定 | 简洁、快速见效 |
如何为你的业务选择合适的内容爬取工具
选对工具,关键是把你的需求和工具的强项对上号。下面是我的快速检查清单:
- 先定义使用场景: 一次性还是持续性?小规模还是大规模?公开数据还是登录后数据?
- 匹配技能水平: 非程序员可以优先从 Thunderbit、Octoparse、ParseHub 或 WebHarvy 入手。开发者则可以直接上 Scrapy 或 Apify。
- 检查导出需求: 需要 Excel、Sheets 还是 API 集成?确认工具支持这些能力。
- 考虑合规: 如果你所在行业受监管,或者要抓取个人数据,请优先选择带合规功能的工具(Import.io、Mozenda)。
- 先从小处试起: 用免费版或试用版先在真实数据上测试,再决定是否投入。
- 提前考虑扩展: 你的需求会不会增长?选择一款能跟着你一起扩展的工具。
还有一点要记住:有时候,最简单的工具反而最合适。如果你只是想快速做个表格,别把事情搞得太复杂。
数据隐私与合规:需要注意什么
网页爬取打开了无数可能性,但也带来了责任。下面是如何确保你站在法律和最佳实践这一边:
- 尊重 robots.txt 和网站政策: 始终检查网站是否允许抓取,并遵守其规则。
- 除非你有合法理由和同意,否则不要抓取个人数据: GDPR 和 CCPA 不是闹着玩的。
- 不要猛轰服务器: 使用内置限速、延迟和定时功能,避免被封禁,同时也做个守规矩的网络公民。
- 如果你所在行业较敏感,就使用带合规功能的工具: Import.io 和 Mozenda 都是按 GDPR/CCPA 思路设计的。
- 记录你的操作: 保留你抓取了什么、为什么抓取的记录,尤其是用于业务或受监管场景时。
有伦理的抓取,才是可持续的抓取——也能让你的业务远离麻烦。
结语:用合适的内容爬取工具赋能你的团队
网络就是你业务里最大、最杂乱的数据库——而有了合适的内容爬取工具,你终于可以让它真正为你所用。不管你是在建立线索名单、追踪竞品,还是喂数据给实时仪表盘,这 18 款工具都覆盖了各种场景、技能水平和预算。
如果你想要最快看到结果, 是我最推荐给业务用户的选择:AI 驱动、无代码,而且几分钟内就能把任何网站变成结构化数据集。但无论你的需求是什么,都建议先从免费试用开始,动手试试,看看哪款最适合你的工作流。
准备好告别复制粘贴的苦差事了吗?下载 ,看看网页数据能有多简单。如果你想更深入了解网页爬取,也可以去看看 ,那里有更多指南、技巧和教程。
常见问题
1. 什么是内容爬取工具?它和普通网页爬虫有什么区别?
内容爬取工具是一类网页爬虫,专门用于自动从网站提取结构化数据。虽然所有网页爬虫都能收集数据,但内容爬取工具通常还提供定时、子页面导航、AI 字段识别,以及与业务工作流集成等功能,因此对业务团队来说更强大,也更容易上手。
2. 哪款内容爬取工具最适合非技术用户?
Thunderbit、Octoparse、ParseHub、Data Miner 和 WebHarvy 都非常适合非程序员。Thunderbit 尤其突出,因为它主打 AI 简化操作,并且可以直接导出到 Excel、Sheets、Airtable 或 Notion。
3. 如何确保网页爬取合法且合规?
始终遵守网站条款、robots.txt 和 GDPR、CCPA 等隐私法规。除非你有合法理由和同意,否则不要抓取个人数据。对于敏感行业,请选择内置合规功能的工具(例如 Import.io、Mozenda)。
4. 这些工具能处理带 JavaScript 或无限滚动的动态网站吗?
可以——Thunderbit、Octoparse、ParseHub、Apify 和 FMiner 等工具都能处理动态内容、无限滚动和多层级导航。对于复杂网站,有些工具可能还需要额外配置或使用云端运行。
5. 为我的业务选择内容爬取工具时,应该考虑什么?
要考虑团队的技术能力、数据需求规模、导出/集成要求、合规顾虑以及预算。先用免费版或试用版测试,再在真实场景中验证工具是否适合你,之后再决定是否正式投入。
祝你抓取顺利——也愿你的数据永远新鲜、结构化,并随时可用。
了解更多