

网页已经和以前不一样了。现在,你访问的几乎每个网站都由 JavaScript 驱动,内容会动态加载——比如无限滚动、弹窗,还有那些往往要点一两下才会露出“真面目”的仪表盘。事实上,现在高达 98.7% 的网站都在使用 JavaScript,这意味着那些只能读取静态 HTML 的老式爬虫工具,已经会错过大量有价值的数据。如果你曾经尝试从现代电商网站抓取商品价格,或者从交互式地图里提取房源信息,你一定懂那种挫败感:你想要的数据,根本不在源代码里。
这就是为什么要用 Selenium 来抓取数据。作为一个做了很多年自动化工具的人(是的,也抓过不少网站),我可以很负责地说:掌握 Selenium,对任何需要最新动态数据的人来说,都是一项超级能力。在这篇实战型 Selenium 网页爬虫教程里,我会带你一步步走完整个流程——从环境搭建到自动化,并展示如何把 Selenium 和 Thunderbit 结合起来,输出结构化、可直接导出的数据。无论你是商业分析师、销售从业者,还是只是对 Python 感兴趣的用户,读完后你都能带走实用技能,顺便收获几次会心一笑(毕竟,调 XPath 选择器这件事,真的很考验心态)。
什么是 Selenium?为什么要用它做网页爬取?
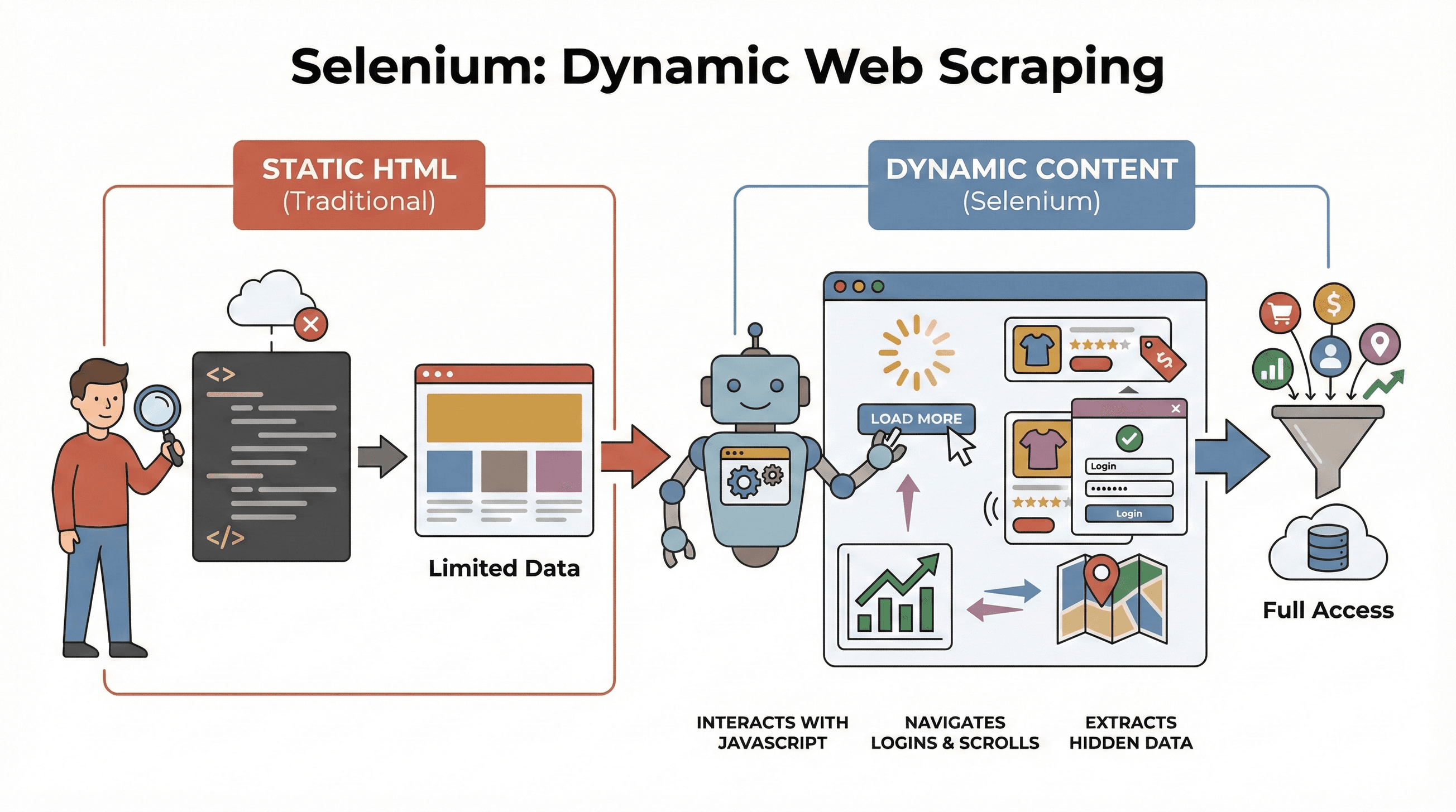 先从基础说起。Selenium 是一个开源框架,可以让你通过代码控制真正的浏览器——比如 Chrome 或 Firefox。你可以把它理解成一个机器人:它能像真人一样打开页面、点击按钮、填写表单、滚动页面,甚至执行 JavaScript。这一点非常关键,因为大多数现代网站不会一上来就把所有数据展示给你,而是会在你和页面交互后,才动态加载内容。
先从基础说起。Selenium 是一个开源框架,可以让你通过代码控制真正的浏览器——比如 Chrome 或 Firefox。你可以把它理解成一个机器人:它能像真人一样打开页面、点击按钮、填写表单、滚动页面,甚至执行 JavaScript。这一点非常关键,因为大多数现代网站不会一上来就把所有数据展示给你,而是会在你和页面交互后,才动态加载内容。
什么是数据抓取,以及 2026 年如何上手 Get Started Free
为什么这对爬取很重要? 像 BeautifulSoup 或 Scrapy 这类传统工具很适合静态 HTML,但它们看不到页面初次加载后由 JavaScript 动态生成的内容。相反,Selenium 可以实时和页面交互,因此特别适合:
- 抓取只有点击“加载更多”后才出现的商品列表
- 提取动态更新的价格或评论
- 处理登录表单、弹窗或无限滚动页面
- 从仪表盘、地图或其他交互式元素中提取数据
简而言之,当你需要抓取那些只会在页面加载完成后,或者在用户操作之后才出现的数据时,Selenium 就是你的首选工具。
Python Selenium 网页爬取的关键步骤
用 Selenium 做爬取,核心可以归纳为三个步骤:
| 步骤 | 你要做什么 | 为什么重要 |
|---|---|---|
| 1. 环境搭建 | 安装 Selenium、WebDriver 和 Python 库 | 把工具准备好,避免配置踩坑 |
| 2. 定位元素 | 使用 ID、class、XPath 等方式找到你要的数据 | 即使内容被 JavaScript 隐藏,也能准确定位 |
| 3. 提取与保存数据 | 抓取文本、链接或表格,并保存到 CSV/Excel | 把原始网页数据变成可直接使用的内容 |
接下来,我们会结合实际示例,逐步拆解每一步。代码你可以直接复制、修改,甚至拿去跟朋友炫耀一下。
步骤 1:搭建 Python Selenium 环境
第一步很简单:你需要安装 Selenium 和浏览器驱动程序(比如 Chrome 的 ChromeDriver)。好消息是,现在这件事比以前容易多了。
安装 Selenium
打开终端,运行:
pip install selenium
获取 WebDriver
- Chrome: 下载 ChromeDriver,并确保它和你的 Chrome 版本匹配。
- Firefox: 下载 GeckoDriver。
小贴士: 从 Selenium 4.6 开始,你可以使用 Selenium Manager 自动下载驱动程序,所以你甚至不一定还需要手动折腾 PATH 变量了(文档)。
你的第一个 Selenium 脚本
下面是一个简短的 Selenium “hello world”:
from selenium import webdriver
driver = webdriver.Chrome() # 或 webdriver.Firefox()
driver.get("https://example.com")
print(driver.title)
driver.quit()
故障排查建议:
- 如果出现“找不到驱动程序”的错误,检查 PATH,或者直接用 Selenium Manager。
- 确保浏览器版本和驱动版本一致。
- 如果你是在无界面服务器上运行(没有 GUI),可以看看下面的无头模式建议。
步骤 2:定位网页元素以提取数据
接下来就是最有趣的部分:告诉 Selenium 你要哪些数据。网页由各种元素组成——div、span、table 等等,而 Selenium 提供了多种方式来定位它们。
常见定位方式
By.ID:通过唯一 ID 找到元素By.CLASS_NAME:通过 CSS 类名找元素By.XPATH:使用 XPath 表达式(非常灵活,但也更容易出问题)By.CSS_SELECTOR:使用 CSS 选择器(适合复杂查询)
下面是实际用法:
from selenium.webdriver.common.by import By
# 通过 ID 查找
price = driver.find_element(By.ID, "price").text
# 通过 XPath 查找
title = driver.find_element(By.XPATH, "//h1").text
# 通过 CSS 选择器查找所有商品图片
images = driver.find_elements(By.CSS_SELECTOR, ".product img")
for img in images:
print(img.get_attribute("src"))
小贴士: 永远优先选择最简单、最稳定的定位方式(ID > class > CSS > XPath)。如果你抓取的页面需要延迟加载数据,记得用显式等待:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
wait = WebDriverWait(driver, 10)
price_elem = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".price")))
这样可以避免数据还没加载出来,脚本就先崩掉。
步骤 3:提取并保存数据
找到元素之后,就该把数据抓出来,保存到合适的地方。
提取文本、链接和表格
假设你要抓取一个商品表格:
data = []
rows = driver.find_elements(By.XPATH, "//table/tbody/tr")
for row in rows:
cells = row.find_elements(By.TAG_NAME, "td")
data.append([cell.text for cell in cells])
用 Pandas 保存为 CSV
import pandas as pd
df = pd.DataFrame(data, columns=["名称", "价格", "库存"])
df.to_csv("products.csv", index=False)
你也可以保存成 Excel(df.to_excel("products.xlsx")),甚至通过 API 推送到 Google Sheets。
完整示例:抓取商品标题和价格
from selenium import webdriver
from selenium.webdriver.common.by import By
import pandas as pd
driver = webdriver.Chrome()
driver.get("https://example.com/products")
data = []
products = driver.find_elements(By.CLASS_NAME, "product-card")
for p in products:
title = p.find_element(By.CLASS_NAME, "title").text
price = p.find_element(By.CLASS_NAME, "price").text
data.append([title, price])
driver.quit()
df = pd.DataFrame(data, columns=["标题", "价格"])
df.to_csv("products.csv", index=False)
Selenium、BeautifulSoup 和 Scrapy:Selenium 有什么独特之处?
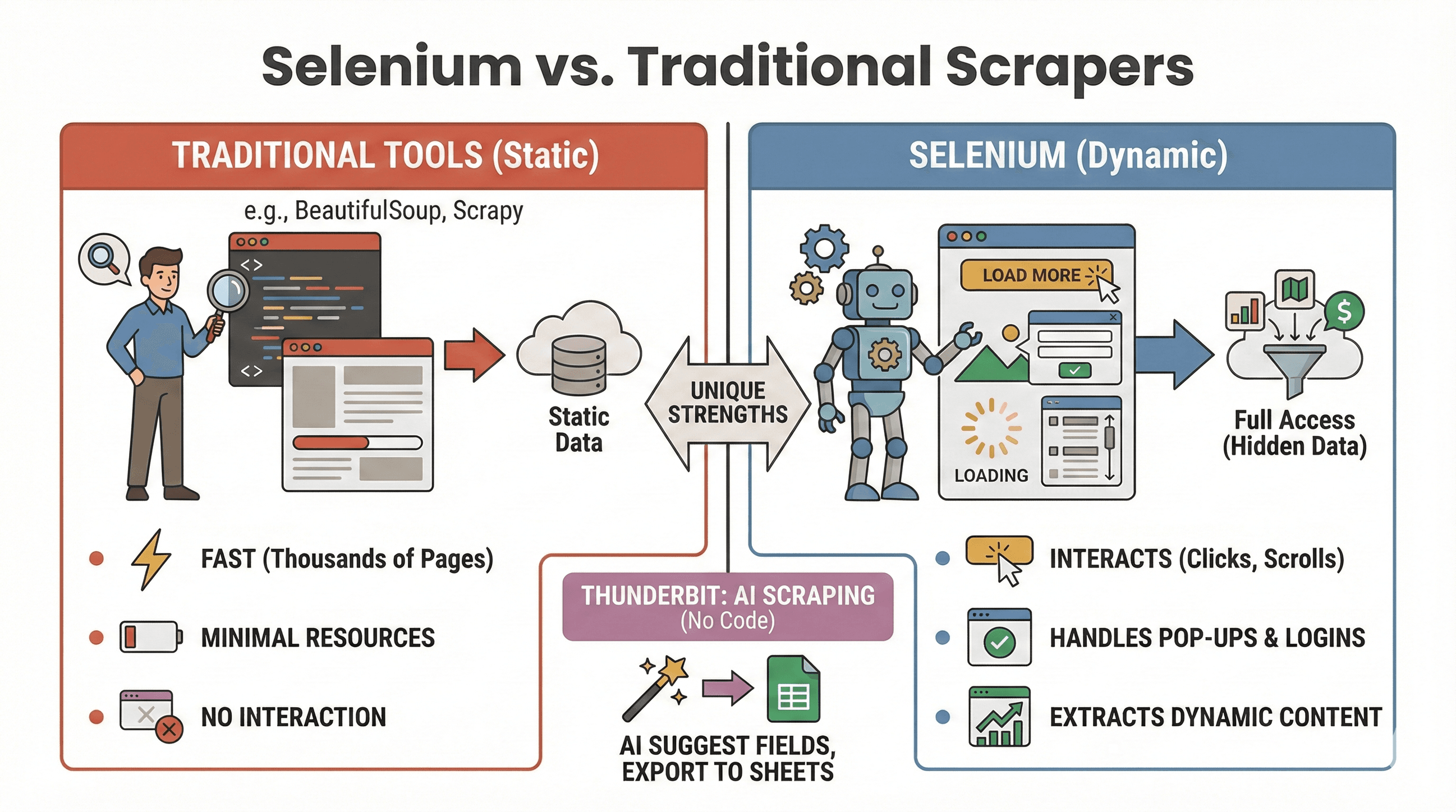 让我们把这个问题说清楚:什么时候该用 Selenium,什么时候 BeautifulSoup 或 Scrapy 更合适?下面快速对比一下:
让我们把这个问题说清楚:什么时候该用 Selenium,什么时候 BeautifulSoup 或 Scrapy 更合适?下面快速对比一下:
| 工具 | 最适合 | 支持 JavaScript 吗? | 速度与资源占用 |
|---|---|---|---|
| Selenium | 动态/交互式网站 | 是 | 较慢,内存占用更多 |
| BeautifulSoup | 简单的静态 HTML 抓取 | 否 | 非常快,轻量 |
| Scrapy | 大批量静态网站爬取 | 有限* | 超快,异步,低内存 |
| Thunderbit | 无代码,适合业务场景的爬取 | 是(AI) | 小中型任务速度很快 |
*Scrapy 可以借助插件处理一些动态内容,但这并不是它的强项(ScrapingBee)。
什么时候用 Selenium:
- 数据只有在点击、滚动或登录后才会出现
- 你需要和弹窗、无限滚动或动态仪表盘交互
- 静态爬虫已经不够用了
什么时候用 BeautifulSoup/Scrapy:
- 数据已经在初始 HTML 里
- 你需要快速抓取成千上万的页面
- 你希望尽量少占用资源
如果你想完全跳过写代码,Thunderbit 也可以用 AI 抓取动态网站——只要点击“AI 建议字段”,就能导出到 Sheets、Notion 或 Airtable。(下面会详细说。)
如何使用 AI 抓取任何网站 Get Started Free
使用 Selenium 和 Python 自动化网页爬取任务
说实话:没人愿意凌晨 2 点爬起来手动跑一个爬虫脚本。好消息是,你可以用 Python 的调度工具,或者操作系统自带的计划任务程序(比如 Linux/Mac 上的 cron,或 Windows 的任务计划程序)来自动化 Selenium 任务。
使用 schedule 库
import schedule
import time
def job():
# 你的爬取代码写在这里
print("正在抓取……")
schedule.every().day.at("09:00").do(job)
while True:
schedule.run_pending()
time.sleep(1)
或者使用 Cron(Linux/Mac)
把下面这行添加到 crontab 中,让它每小时运行一次:
0 * * * * python /path/to/your_script.py
自动化建议:
- 以无头模式运行 Selenium(见下文),避免弹出 GUI 窗口。
- 记录错误日志,并在出问题时给自己发送提醒。
- 一定要用
driver.quit()关闭浏览器,释放资源。
提升效率:更快、更稳定的 Selenium 爬取技巧
Selenium 很强,但如果不注意,它也会变慢、很吃资源。下面这些方法可以帮你提速,并减少常见麻烦:
1. 使用无头模式运行
没必要盯着 Chrome 一次次打开又关闭。无头模式会让浏览器在后台运行:
from selenium.webdriver.chrome.options import Options
opts = Options()
opts.headless = True
driver = webdriver.Chrome(options=opts)
2. 屏蔽图片和其他不必要内容
如果你只是抓文本,何必加载图片?把它们屏蔽掉可以加快页面打开速度:
prefs = {"profile.managed_default_content_settings.images": 2}
opts.add_experimental_option("prefs", prefs)
3. 使用高效的定位方式
- 优先使用 ID 或简单的 CSS 选择器,不要滥用复杂 XPath。
- 尽量不要用
time.sleep(),改用显式等待(WebDriverWait)。
4. 随机化延迟
加入随机暂停,模拟真人浏览行为,降低被封的概率:
import random, time
time.sleep(random.uniform(1, 3))
5. 轮换 User Agent 和 IP(如有需要)
如果你抓取量很大,可以轮换 user agent,并考虑使用代理,避免一些简单的反爬措施。
6. 管理会话和错误
- 用 try/except 处理缺失元素,避免程序直接崩掉。
- 记录错误,并在调试时保存截图。
更多优化建议可以参考 BrowserStack 的指南。
进阶:将 Selenium 与 Thunderbit 结合,导出结构化数据
真正有意思的地方来了——尤其是当你想节省数据清洗和导出的时间时。
用 Selenium 抓取到原始数据后,你可以借助 Thunderbit 来:
- 自动识别字段: Thunderbit 的 AI 可以读取你抓取的页面或 CSV,并推荐列名(“AI 建议字段”)。
- 子页面抓取: 如果你有一组 URL(比如商品页),Thunderbit 可以逐个访问,并为表格补充更多细节——不需要额外写代码。
- 数据增强: 可即时对数据进行翻译、分类或分析。
- 导出到任意位置: 一键导出到 Google Sheets、Airtable、Notion、CSV 或 Excel。
工作流示例:
- 用 Selenium 抓取一组商品 URL 和标题。
- 将数据导出为 CSV。
- 打开 Thunderbit,导入 CSV,让 AI 建议字段。
- 使用 Thunderbit 的子页面抓取,从每个商品 URL 中提取更多详情(比如图片或规格)。
- 将最终整理好的结构化数据导出到 Sheets 或 Notion。
这套组合可以帮你省下好几个小时的手工清洗时间,让你把精力放在分析上,而不是和乱糟糟的数据较劲。想了解更多这套流程,可以看看 Thunderbit 的 Selenium 指南。
使用 Thunderbit AI 导出 Selenium 数据
Selenium 网页爬取的最佳实践与故障排查
网页爬取有点像钓鱼:有时候你能满载而归,有时候却会被水草缠住。下面这些方法能帮你把脚本做得更稳定,也更合规:
最佳实践
- 尊重 robots.txt 和网站条款: 一定先确认网站是否允许爬取。
- 控制请求频率: 不要把服务器压垮——适当加延迟,并留意 HTTP 429 错误。
- 有 API 就优先用 API: 如果数据可以通过公开 API 获取,优先使用,更安全也更稳定。
- 只抓取公开数据: 避免个人信息或敏感信息,并注意隐私法律。
- 处理弹窗和验证码: 可以用 Selenium 关闭弹窗,但验证码很难自动化处理。
- 随机化 user agent 和延迟: 有助于减少被识别和拦截的风险。
常见错误与解决办法
| 错误 | 含义 | 解决方法 |
|---|---|---|
NoSuchElementException | 找不到元素 | 检查定位方式;使用等待机制 |
| 超时错误 | 页面或元素加载时间过长 | 增加等待时间;检查网络速度 |
| 驱动与浏览器不匹配 | Selenium 无法启动浏览器 | 更新驱动和浏览器版本 |
| 会话崩溃 | 浏览器意外关闭 | 使用无头模式;管理好资源 |
更多故障排查建议,可以查看 Thunderbit 的 Selenium 教程。
结论与核心要点
动态网页爬取早就不只是硬核开发者的专属技能了。借助 Python Selenium,你可以自动控制任意浏览器,处理最棘手的 JavaScript 重度网站,并把业务真正需要的数据抓出来——无论是用于销售、研究,还是单纯满足你的好奇心。记住:
- Selenium 是动态、交互式网站的首选工具。
- 三个关键步骤: 搭建环境、定位元素、提取并保存。
- 把脚本自动化,方便定期更新数据。
- 通过无头模式、智能等待和高效定位方式 提升速度和稳定性。
- 把 Selenium 和 Thunderbit 结合起来,能轻松完成数据结构化和导出——尤其适合想跳过表格整理痛苦的人。
准备好自己试试了吗?先从上面的代码示例开始;当你准备把爬取能力提升到新层级时,不妨试试 Thunderbit,体验即时的 AI 数据清洗和导出。如果你还想看更多内容,可以访问 Thunderbit Blog,那里有深度解析、教程,以及最新的网页自动化内容。
祝你抓取顺利——愿你的选择器每次都能精准找到你要的内容。
免费试用 Thunderbit AI 网页爬虫 Get Started Free
常见问题
1. 为什么我应该用 Selenium 做网页爬取,而不是 BeautifulSoup 或 Scrapy?
Selenium 特别适合抓取动态网站,因为内容通常会在用户操作或 JavaScript 执行后才加载。BeautifulSoup 和 Scrapy 处理静态 HTML 更快,但它们无法和动态元素交互,也不能模拟点击和滚动。
2. 怎样让我的 Selenium 爬虫跑得更快?
使用无头模式,屏蔽图片和不必要的资源,使用高效的定位方式,并加入随机延迟来模拟真人浏览。更多技巧可以查看 BrowserStack 的指南。
3. 我能把 Selenium 爬取任务设成自动运行吗?
可以!你可以使用 Python 的 schedule 库,或者使用操作系统自带的计划任务程序(cron 或任务计划程序),按固定时间间隔运行脚本。自动化爬取有助于让数据保持最新。
4. 用 Selenium 抓到的数据,最好的导出方式是什么?
可以用 Pandas 保存为 CSV 或 Excel。如果你需要更高级的导出方式(Google Sheets、Notion、Airtable),可以把数据导入 Thunderbit,再使用它的一键导出功能。
5. Selenium 里怎么处理弹窗和验证码?
你可以定位并点击弹窗的关闭按钮来关闭它们。验证码就难得多了——如果遇到验证码,可以考虑手动处理,或者使用验证码破解服务,同时始终遵守网站服务条款。
想看更多爬虫教程、AI 自动化技巧,或者了解最新的商业数据工具?欢迎订阅 Thunderbit Blog,或者访问我们的 YouTube 频道 看实操演示。
了解更多




