你注册了 ScraperAPI,一看 Hobby 套餐写着“100,000 credits”,就立马开始抓数据。结果三天后,后台显示这些 credits 已经烧掉了 80%——而你大概只抓了 6,000 个页面。这到底怎么回事?答案就在 credit 倍率机制里,而这也正是几乎所有评测都没讲透、却对 ScraperAPI 最关键的一点。
我花了几周时间翻 ScraperAPI 的文档,整理了五家竞品的真实定价数据,还把能找到的 Reddit 讨论和 Capterra 评价都看了一遍。这篇 ScraperAPI 评测,是我真心希望团队当初做选型时就能看到的版本。我会带你算清 credits 的真实消耗,看看 ScraperAPI 真正擅长什么、又会在哪些场景彻底翻车,汇总 G2、Capterra 和 Reddit 上的真实用户反馈,最后也会直接帮你判断:你到底需不需要一个抓取 API。
什么是 ScraperAPI?它适合谁?
ScraperAPI 是一个网页抓取 API,专门负责处理大规模抓取背后的那些麻烦基础设施:通过 自动轮换代理、自动识别 CAPTCHA、进行 JavaScript 渲染,以及失败重试。你只要发一次简单的 API 请求,传入一个 URL,它就会返回 HTML;如果你用的是结构化数据端点,也可以直接拿到解析好的 JSON。这家公司成立于 2018 年,创始人是 Daniel Ni,总部在拉斯维加斯,目前服务 ,包括 Deloitte、Sony 和 Alibaba——每月处理 。
它主要是给开发团队和技术运维人员用的,用来搭建自定义抓取流程。如果你不会写代码,ScraperAPI 其实并不是为你准备的(后面我会展开说)。
核心功能包括:代理轮换、JavaScript 渲染、地理定向、热门网站的结构化数据端点,以及请求失败自动重试。
不过大多数评测都会漏掉一件特别重要的事:ScraperAPI 定价页上的 credits 数字,如果你不懂倍率机制,其实很容易被误导。所以,咱们先从这里讲起。
ScraperAPI 的 credit 机制到底怎么运作?(大多数评测都跳过的部分)
ScraperAPI 用的是 credit 计费。最基础的理解很简单:1 次 API 请求 = 1 个 credit。但真实情况几乎从来不是这么算的。实际消耗取决于两个因素:你抓取的域名,以及你打开了哪些功能开关。而这些成本叠在一起,并不直观。
每个用户注册前都应该看到的 credit 倍率表

在你动任何参数之前,目标网站类型就已经决定了基础 credit 成本:
| 域名类别 | 每次请求基础 credits | 示例 |
|---|---|---|
| 普通网站 | 1 | 博客、新闻站、简单 HTML 页面 |
| 电商网站 | 5 | Amazon、eBay、Walmart |
| SERP(搜索引擎结果页) | 25 | Google、Bing |
| 社交媒体 | 30 |
除此之外,功能开关还会额外加 credits:
| 参数 | 额外 credits | 说明 |
|---|---|---|
render=true(JS 渲染) | +10 | 所有套餐均可用 |
screenshot=true | +10 | 所有套餐均可用 |
premium=true(高级代理) | +10 | 所有套餐均可用 |
ultra_premium=true | +30 | 仅付费套餐可用 |
| 反爬绕过(Cloudflare、DataDome、PerimeterX) | 每项 +10 | 系统自动检测,你无法手动选择 |
premium=true + render=true 组合 | +25 | 不是 +20 |
ultra_premium=true + render=true 组合 | +75 | 不是 +40 |
最后一行才是重点。功能组合后的成本,比各项单独成本加起来还要高。高级代理(+10)加 JavaScript 渲染(+10),按理说应该只多 +20 credits,但 ScraperAPI 实际会收 。ultra-premium(+30)加 JavaScript 渲染(+10),按理说应该是 +40,但实际上要收 ——几乎翻倍。这种非线性叠加在官方文档里并没有被特别强调,也正是很多用户觉得 credits 跑得比预期快得多的主要原因。
不会额外消耗 credits 的参数包括:wait_for_selector、country_code、session_number、device_type、output_format、keep_headers=true、autoparse=true。
每个套餐到底能拿到什么:从免费版到企业版
下面是 ScraperAPI 当前的 :
| 套餐 | 月付价格 | 年付(按月) | API Credits | 并发线程 | 地理定向 |
|---|---|---|---|---|---|
| Free | $0 | — | 1,000 | 5 | 否 |
| Hobby | $49 | $44 | 100,000 | 20 | 仅美国和欧盟 |
| Startup | $149 | $134 | 1,000,000 | 50 | 仅美国和欧盟 |
| Business | $299 | $269 | 3,000,000 | 100 | 国家级(50+ 国家) |
| Scaling | $475 | $427 | 5,000,000 | 200 | 国家级 |
| Enterprise | 定制 | 定制 | 5,000,000+ | 200+ | 国家级 |
如果把倍率算进去,每 1,000 次请求的实际成本如下:
| 套餐 | 标准(1×) | JS 渲染(10×) | 电商(5×) | SERP(25×) | Ultra-Premium + JS(75×) |
|---|---|---|---|---|---|
| Hobby($49) | $0.49 | $4.90 | $2.45 | $12.25 | $36.75 |
| Startup($149) | $0.15 | $1.49 | $0.75 | $3.73 | $11.18 |
| Business($299) | $0.10 | $1.00 | $0.50 | $2.49 | $7.48 |
| Scaling($475) | $0.10 | $0.95 | $0.48 | $2.38 | $7.13 |
一个每月 $49、宣传为“100,000 credits”的套餐,如果你抓的是高防护网站,还开了 ultra-premium + JavaScript 渲染,最后其实只能拿到 1,333 次真实请求。折算下来就是 ——比不少全托管抓取服务还贵。
为什么 credits 会比你预期掉得更快
有三件事最容易让用户措手不及。
第一:按域名计费是自动触发的。 你不会手动去选 Amazon 的 5× 倍率或者 Google 的 25× 倍率,只要 ScraperAPI 识别出域名,它就会自动套用。反爬绕过 credit(Cloudflare、DataDome、PerimeterX 各 +10)也是一样,系统一检测到就会自动加上。
第二:credits 不会结转。 没用完的 credits 会在 ,不会滚到下个月。
第三——这点最扎心——按量付费(Pay-As-You-Go)只在 Scaling($475/月)及以上套餐开放。 如果你在 Hobby、Startup 或 Business 套餐里中途把 credits 用完了,就只能等到下个计费周期恢复,根本没法继续用。你唯一的办法就是升级到更高套餐。
Reddit 上有用户反映,最开始被报的是 60,000,000 credits,按 Amazon 每次 1 credit 来算。但付款之后,系统却在没有提前说明的情况下套用了 5 credit 倍率。结果原本以为能用 6,000 万次请求,实际只够 1,200 万次,也就是比预期少了 。
DataPipeline 的 credit 陷阱
ScraperAPI 的无代码 DataPipeline 功能(定时抓取并通过 webhook 交付)用的是另一套单独、更贵的 credit 规则。一个基础普通请求在 DataPipeline 里要消耗 :
| 请求类型 | 标准 API | DataPipeline | 倍率 |
|---|---|---|---|
| 基础普通请求 | 1 | 6 | 6× |
| 基础电商请求 | 5 | 10 | 2× |
| 基础 SERP | 25 | 30 | 1.2× |
| Ultra-premium + JS(普通) | 75 | 80 | 1.07× |
很多用户把无代码流程搭好之后,以为会按标准 API 的消耗来算,结果发现连基础请求都已经是 6× credits。这个规则其实有写,但你得自己往文档深处翻才找得到。
实际每次请求成本:ScraperAPI 和竞品怎么比
只看首页标价没意义,必须把倍率算进去。我整理了五家服务商的最新价格,并以约 $300/月档位,在三种常见场景下做了统一对比。
基础 HTML 抓取(无 JS、无高级代理)
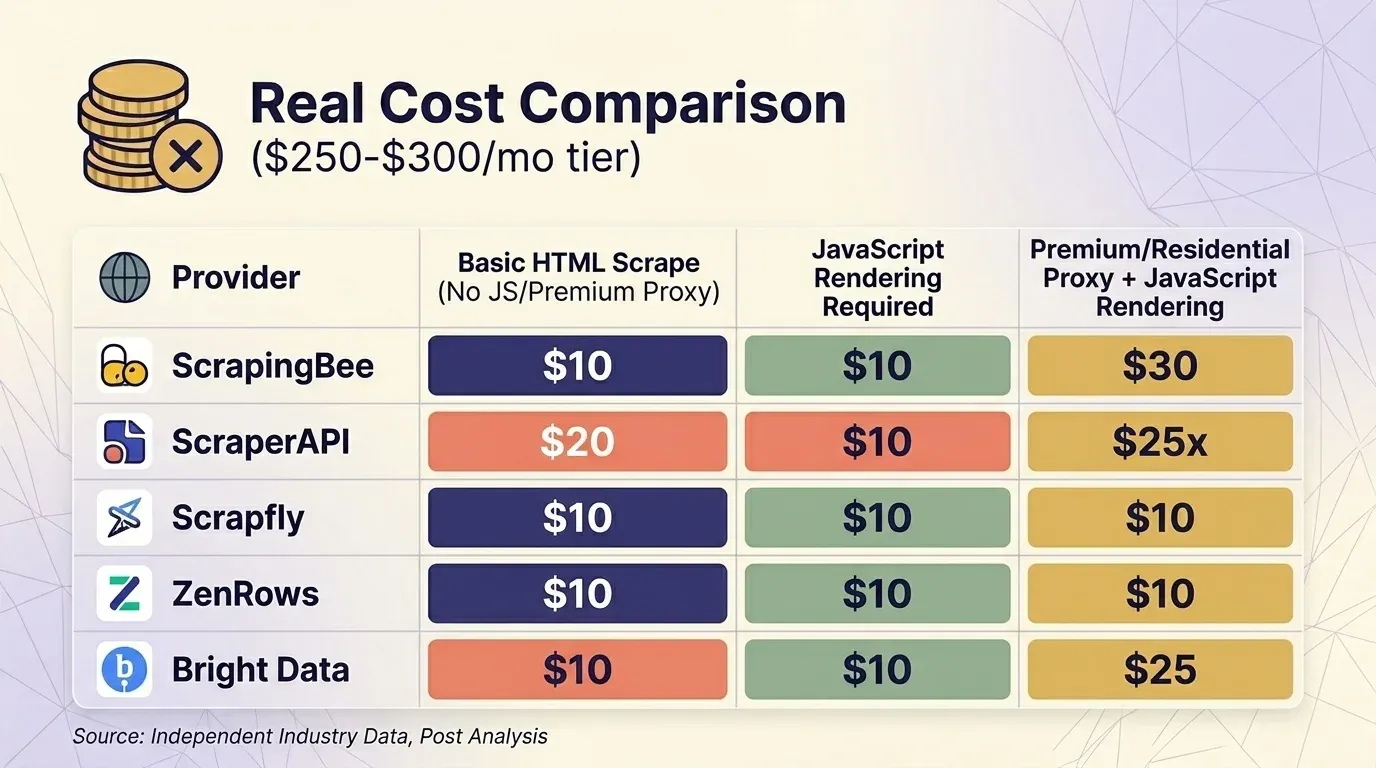
| 服务商 | 套餐 | 每次请求 credits | 可用请求数 | 每千次成本 |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 1 | 3,000,000 | $0.08 |
| ScraperAPI | Business $299 | 1 | 3,000,000 | $0.10 |
| Scrapfly | Startup $250 | 1 | 2,500,000 | $0.10 |
| ZenRows | Business $300 | $0.28/1K | ~1,071,000 | $0.28 |
| Bright Data | 按量付费 | $1.50/1K | ~200,000 | $1.50 |
需要 JavaScript 渲染
| 服务商 | 套餐 | 每次请求 credits | 可用请求数 | 每千次成本 |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 5(默认开启) | 600,000 | $0.42 |
| Scrapfly | Startup $250 | 6 | 416,667 | $0.60 |
| ScraperAPI | Business $299 | 10 | 300,000 | $1.00 |
| ZenRows | Business $300 | 5× | ~214,000 | $1.40 |
| Bright Data | 按量付费 | 固定费率 | ~200,000 | $1.50 |
高级 / 住宅代理 + JavaScript 渲染(高防护网站)
| 服务商 | 套餐 | 每次请求 credits | 可用请求数 | 每千次成本 |
|---|---|---|---|---|
| Bright Data | 按量付费 | 固定费率 | ~200,000 | $1.50 |
| ScrapingBee | Business $249 | 25 | 120,000 | $2.08 |
| ScraperAPI | Business $299 | 25 | 120,000 | $2.49 |
| Scrapfly | Startup $250 | 31 | 80,645 | $3.10 |
| ZenRows | Business $300 | 25× | ~42,857 | $7.00 |
Bright Data 的 Web Unlocker 是唯一一个 的服务商——所有请求都是统一固定价。在大约 $300 的价位里,ScrapingBee 和 ScraperAPI 在高防护站点抓取上都还算有竞争力,而 ZenRows 则最贵。
顺便提一下,ScrapingBee ,成本是 5×。如果你在对比 ScrapingBee 和 ScraperAPI,一定要先确认两边比较的是不是同样的渲染设置。
Scrape.do 的独立分析显示,ScraperAPI 的平均成本高达 ——“比测试过的任何其他服务都贵”,平均响应时间则达到 ,这也让它成了“最慢的服务之一”。做决定前,这一点真的值得认真考虑。
按网站类型的成功率:ScraperAPI 哪些地方强,哪些地方弱
没有哪家抓取 API 能在所有网站上都表现一样好。Scrapeway(2026 年 4 月)的独立基准测试,给出了一个非常明显的两极分化结果。
不同网站类别的表现
| 目标网站 | 成功率 | 平均速度 | 每千次成本(Business 套餐) | |---|---|---|---|---| | Zillow | 100% | 10.5 秒 | $0.49 | | Etsy | 99% | 4.8 秒 | $4.90 | | Amazon | 98% | 6.5 秒 | $2.45 | | LinkedIn | 95% | 17.8 秒 | $14.70 | | Walmart | 93% | 11.4 秒 | $2.45 | | Indeed | 90% | 15.8 秒 | $4.90 | | StockX | 84% | 3.9 秒 | $4.90 | | Realtor.com | 12% | 11.8 秒 | $0.49 | | Instagram | 0% | — | — | | Booking.com | 0% | — | — | | Twitter/X | 0% | — | — |
整体平均成功率是 ,略高于行业平均的 58.2–59.5%。平均响应时间为 5.2–7.3 秒,也比行业平均 9.8 秒更快一些。
ScraperAPI 表现出色的场景
ScraperAPI 在电商(Amazon、Walmart、Etsy)和房地产(Zillow)上的表现确实很强。针对这些网站的结构化数据端点,通常能返回非常稳定的解析结果。如果你的主要需求是抓 Amazon 商品页或者 Google SERP,ScraperAPI 是个合理选择。
ScraperAPI 的短板
社交媒体几乎是一片空白。 Instagram、Twitter/X 和 Booking.com 在独立测试里的成功率都是 0%。LinkedIn 虽然能到 95%,但每次请求要 30 credits,成本非常高。
需要登录的网站明确不支持。 ScraperAPI 虽然支持通过 session_number 参数维持会话,但它 。它不能处理表单填写、双因素认证,或者复杂的登录流程。
高防护目标的数据可能不够新。 ScraperAPI 会对难抓的目标启用 ,也就是说,如果你抓的是价格、库存这类特别看时效的数据,拿到的结果可能已经晚了 10 分钟。
在 Proxyway 2025 年的基准测试里,ScraperAPI 在 Google 目标上的 ,只有 81.72%。
网站类别表现总结
| 网站类别 | ScraperAPI 表现 | 已知问题 | 可能的替代方案 |
|---|---|---|---|
| Amazon / 电商 | ✅ 很强(SDE 端点) | 规模化后 credits 消耗大 | Thunderbit 模板(一键使用,模板本身不按行计费) |
| Google SERP | ✅ 很强 | 地理定向会额外收费;某基准测试中 Google 成功率最低 | — |
| 房地产(Zillow) | ✅ 很优秀(100%) | — | — |
| Instagram / 社交媒体 | ❌ 0% 成功率 | 完全失败 | Playwright + 代理(自行开发) |
| 重 JS 的 SPA | ⚠️ 中等 | 需要 10× credit 的无头渲染 | Scrapfly、ZenRows |
| 需要登录的网站 | ❌ 违反条款 | 不支持会话 / 认证 | Thunderbit 浏览器抓取(使用你的登录会话) |
| Booking.com / 旅行类 | ❌ 0% 成功率 | 完全失败 | Bright Data |
真实用户怎么说:G2、Capterra 和 Reddit 的情绪汇总
我整理了三个平台的反馈。当前评分如下:
| 平台 | 评分 | 评论数 |
|---|---|---|
| G2 | 4.4/5 | 16 |
| Capterra | 4.6/5 | 62 |
| Trustpilot | 4.5/5 | 43 |
Capterra 的子评分:易用性 4.9/5、客户服务 4.6/5、功能 4.5/5、性价比 4.5/5。
按主题汇总用户情绪
| 主题 | 正面信号 | 负面信号 |
|---|---|---|
| 上手难度 / 文档 | “配置超级简单,几分钟就能开始抓取。” — Latenode 社区;Capterra 易用性 4.9/5 | — |
| 定价透明度 | “入门门槛价格还算友好”(多条 Capterra 评价) | “credit 成本拆解让人很困惑” — John S., 创始人,Capterra(2025 年 2 月);“价格涨了 1000%,质量反而下降了” — CTO, Online Media, Capterra(2022 年 9 月) |
| 稳定性 | “抓 Amazon/Google 很稳”(G2、Capterra) | “一旦是高负载任务,ScraperAPI 就开始不稳定了” — emcarter,Latenode;“某些目标站点失败率高达 80%”(Reddit) |
| 客户支持 | “团队响应很快”(Capterra) | 有用户反映曾被报一个价格,最后却按 5 倍收费,且事先没有说明(Reddit) |
| 长期价值 | 只对成功请求(200/404)收费 | “如果你做的是大规模运营,费用会涨得很快”;长期来看,自建基础设施“更划算” — mikezhang,Latenode |
结论其实很清楚:ScraperAPI 在初始配置体验,以及热门、支持良好的目标站点上,口碑不错。争议主要集中在价格惊喜(倍率、意外涨价)和更难抓的网站稳定性上。
ScraperAPI 的结构化数据端点:值不值得多花这些 premium credits?
ScraperAPI 提供跨 5 个平台的 ,直接返回解析后的 JSON,而不是原始 HTML:
- Amazon(3 个端点):根据 ASIN 获取商品详情、搜索结果、竞品报价。可返回 18+ 个字段,包括价格、评分、描述、评论、BSR、图片、卖家信息等。支持 。
- Google(5 个端点):(自然结果、知识图谱、视频、相关问题、分页)、购物、地图、新闻、职位。
- Walmart(4 个端点):商品、搜索、分类、评论。
- eBay(2 个端点):商品、搜索。
- Redfin(4 个端点):搜索、经纪人详情、租赁房源、在售房源。
SDE 在所有套餐里都能用,包括 Free。ScraperAPI 声称其支持的 SDE 域名成功率可以到 ,不过独立基准测试会因具体站点不同而呈现更复杂的结果。
数据完整性
Amazon 的 SDP 是 ScraperAPI 最强的产品之一。它能返回非常完整的字段:价格、评论、BSR、变体、图片、卖家信息等等。Google SERP 的 SDP 则能返回自然结果、广告、精选摘要和 People Also Ask。对于这两个平台来说,数据完整度确实不错。
credit 效率:SDE vs. 自己解析
在 Business 套餐($299/月,300 万 credits)下,抓取 10,000 个 Amazon 商品,使用 SDE 需要消耗 50,000 credits(每条 5 credits)——差不多相当于套餐价值的 $5。如果你自己用标准请求(每条 1 credit)写解析器,只需要 10,000 credits,但你得额外投入开发时间去写和维护解析逻辑。
对于没有开发人员的小团队来说,SDE 能省下大量时间。
对于有工程能力、而且要大规模抓取的团队来说,5× 的 credit 溢价就没那么好接受了。
SDE 和无代码抓取模板相比如何
这个对比比大多数评测说得更重要。 提供 Amazon、Shopify、Zillow 以及 的即用型抓取模板,不需要编程,而且模板本身不按行计费。
| 因素 | ScraperAPI SDE(Amazon) | Thunderbit Amazon 模板 |
|---|---|---|
| 配置时间 | 30–60 分钟(写代码 + 接 API) | 约 2 分钟(安装插件,打开 Amazon,点击模板) |
| 每 1,000 个商品成本(Business 套餐) | 约 $5(50,000 credits,按 $0.10/credit 估算) | 约 $16.50(1,000 行 × 1 credit,Pro 版约 $0.0165/credit) |
| 返回字段 | 18+ 个(非常全面) | 商品名、价格、评分、评论、图片、URL 等 |
| 导出方式 | JSON(需代码解析) | Excel、CSV、Google Sheets、Airtable、Notion,一键导出 |
| 维护成本 | 由 ScraperAPI 维护 SDE | 由 Thunderbit 团队维护模板 |
| 技术门槛 | 需要 Python/Node.js | 不需要 |
对于需要高频抓 Amazon 的开发团队来说,ScraperAPI 的 SDE 在规模化时单品成本更有优势。对于只想把 Amazon 数据导进表格、又不想写代码的业务用户来说,Thunderbit 的上手和使用速度要快得多。
你真的需要抓取 API 吗?很多评测忽略的无代码路径
很多搜索“Scraper API review”的人,其实还没决定要不要走 API 工作流。他们先想搞清楚:自己到底需不需要它。
出乎意料的是,很多人其实并不需要。网页抓取 API 市场规模已经达到 ,年复合增长率 14–18%,但这波增长主要来自企业工程团队——并不是那个只想从网站上拿 500 条线索的销售运营经理。
抓取 API vs. 无代码工具:一张对比决策图
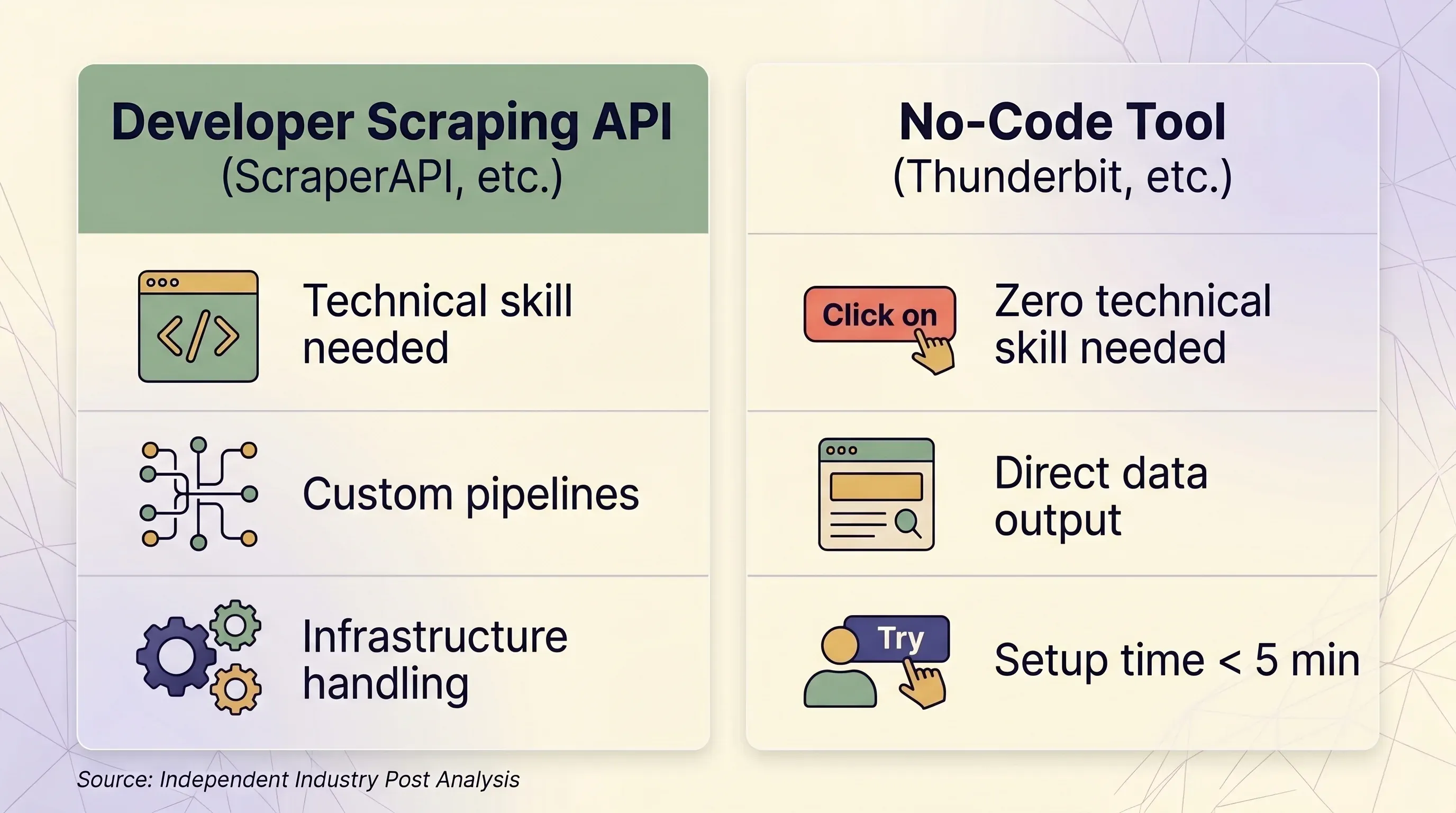
| 因素 | 抓取 API(ScraperAPI 等) | 无代码工具(Thunderbit 等) |
|---|---|---|
| 最适合谁 | 在大规模场景下构建数据管道的开发者 | 业务用户、市场、销售团队、研究人员 |
| 需要的技术能力 | Python/Node.js、HTTP 概念、JSON 解析 | 不需要,浏览器里点点就行 |
| 上手时间 | 至少 1–2 小时(写代码 + 测试 + 调试) | 5 分钟以内 |
| 反爬处理 | 高级代理(每次 10–75 credits) | 真实浏览器会话,自然绕过指纹识别 |
| 需要登录的网站 | ❌ ScraperAPI 条款禁止 | ✅ 浏览器抓取 可使用你现有会话 |
| 规模(每天页面数) | 每月 10 万到 300 万+ 请求 | 按需使用,通常每天少于 1,000 页 |
| 数据输出 | 原始 HTML 或 JSON(需要解析代码) | 结构化行 / 列,开箱即用 |
| 导出 | JSON、CSV(通过代码) | Excel、CSV、Google Sheets、Airtable、Notion、Word、JSON |
| 维护成本 | 需要更新选择器、重试逻辑和基础设施 | 无需维护,AI 每次都会重新识别页面结构 |
| 计费单位 | 按请求 credits 计费(1–75 credits/请求不等) | 按行 credits 计费(1 行 = 1 credit,子页面 2 个) |
| 入门价格 | $49/月,100K credits | 每月 $9(年付,5,000 credits) |
| 免费方案 | 每月 1,000 credits,5 并发 | 每月 6 页,30 credits/页 |
| 定价可预测性 | 低——倍率会带来意外费用 | 高——1 行始终 = 1 credit |
什么时候抓取 API 更合适
- 你有开发或工程团队
- 你需要每天以程序化方式抓取 10 万+ 页面
- 你需要对请求头、会话和重试逻辑做深度定制
- 你的目标站点支持得很好(Amazon、Google、Walmart、Zillow)
什么时候像 Thunderbit 这样的无代码工具更合适
- 你做的是销售、电商运营、市场或房地产,不是工程开发
- 你需要从很多不同网站拿数据,而不是给每个站点都写一套解析器
- 你希望直接导出到 Excel、Google Sheets、Airtable 或 Notion
- 你需要抓取需要登录的网站(Thunderbit 的会使用你的会话)
- 你希望 AI 每次都能重新读取页面,不用在网站改版后维护代码
- 你需要子页面抓取:Thunderbit 可以自动访问详情页并补充行数据
的流程真的很简单:安装扩展、打开任意页面、点“AI Suggest Fields”、点“Scrape”,然后导出。AI 会自动判断页面上的数据并建议列结构——你不用写选择器,也不用写代码。想了解它怎么工作的,可以看看我们的 。
在 2024 年遇到过云成本超支问题,而使用按量计费、又缺乏保护措施的公司,会因为账单惊吓导致 。如果你曾经被浮动 API 费用坑过,那么按行计费模型的可预测性真的值得认真考虑。
ScraperAPI 优缺点一览
| 优点 | 缺点 |
|---|---|
| 强大的代理基础设施(4,000 万+ IP,50+ 国家 / 地区) | credit 倍率机制很复杂——功能叠加后的成本高于简单相加 |
| 文档完善,初始配置简单(Capterra 易用性 4.9/5) | credits 不会按月结转 |
| 在 Amazon、Google、Zillow、Etsy 上表现稳定 | Instagram、Twitter/X、Booking.com 成功率为 0% |
| 仅对成功请求(200/404)收费 | 404 响应也会消耗 credits |
| 18 个结构化数据端点,返回解析后的 JSON | 明确禁止抓取需要登录的网站 |
| 所有套餐都能用,包括 Free | 按量付费只在 Scaling($475/月)及以上开放 |
| 7 天无理由退款政策 | 对难抓目标有 10 分钟强制缓存——可能返回旧数据 |
| 年收入 30–35% 增长,说明产品仍在积极迭代 | DataPipeline 的成本最高可达标准 API 的 6× |
| — | US & EU 之外的地理定向需要 Business 套餐($299/月) |
| — | 没有主动的用量告警,需要手动看后台 |
如果你决定使用 ScraperAPI,如何把它用得更好
每天监控 credit 消耗
ScraperAPI 的 提供使用统计,包括平均延迟、抓取域名和并发指标。不过,它没有主动告警——credits 快用完的时候,不会发邮件或短信提醒。你得自己盯着看。分析历史在 Hobby/Startup 套餐里只保留 2 周,在 Business 及以上保留 6 个月。
建议你在第一个月里,每天都设个提醒去看后台。先把自己目标站点的消耗速度摸清楚,慢慢就有感觉了。
先用免费套餐测试目标站点
先用 1,000 个免费 credits(再加上 7 天 5,000 credits 试用)去测试你的目标站点,确认成功率,再决定要不要升级付费方案。记下哪些站点需要 JavaScript 渲染或高级代理,这样你才能在加入倍率后,估出更真实的月度成本。
除非目标站点需要,否则不要开启高级功能
ScraperAPI 不会自动启用高级代理或 JavaScript 渲染——你必须显式设置 render=true、premium=true 或 ultra_premium=true。但按域名计费是自动的:Amazon 永远是 5 credits,Google 永远是 25,LinkedIn 永远是 30。反爬绕过 credits(Cloudflare、DataDome、PerimeterX 各 +10)也会在系统检测到后自动加上。批量跑之前,一定要把这个规则吃透。
对支持的网站优先使用结构化数据端点
如果你要抓 Amazon 或 Google,SDE 即使更费 credits,也能省下开发时间。对于不支持的网站,可以评估一下 是否比自己写解析器更快、更省。
给不稳定目标准备备选方案
如果 ScraperAPI 在某个站点上的成功率低于 90%,建议把这类请求切换到别的服务商,或者改用浏览器型工具。对于需要登录的网站,ScraperAPI 根本不适用——你需要像 这样能在浏览器会话里工作的工具。
了解这些坑
- 404 响应也会消耗 credits——ScraperAPI 对 200 和 404 都收费
- 取消请求也会收费——如果你在 70 秒处理窗口结束前取消,请求仍然会被计费
- 对难抓目标有 10 分钟强制缓存——你可能拿到旧数据
- 按量付费只在 Scaling($475/月)及以上开放——低阶用户用完就会被切断
- US & EU 之外的地理定向需要 Business 套餐($299/月)
核心结论:ScraperAPI 适合你吗?
研究完这些之后,我的结论是:
- ScraperAPI 很适合开发团队,尤其是抓 Amazon、Google、Walmart、Zillow 这类流量大、支持也好的目标站点。结构化数据端点确实有用,代理基础设施也很强,文档水平高于平均线。
- credit 倍率机制是最大风险。 如果你不明白倍率怎么叠加,就很容易超支。宣传的 credits 和真实请求数之间,差距可能达到 5–75×。付费前,一定要把自己的实际场景先算清楚。
- 稳定性很依赖站点。 ScraperAPI 在电商和房地产上表现出色,在招聘网站和社交媒体上中规中矩,而在 Instagram、Twitter/X、Booking.com 上基本没法用。不要默认它对所有站点都一样好。
- 对非技术团队来说,ScraperAPI 不是最合适的工具。 如果你在销售、市场或运营岗位,需要结构化数据但不想写代码,像 这样的无代码工具,两次点击就能帮你搞定——还带 AI 字段识别、直接导出表格、子页面补充和几乎零维护成本。你可以看看 ,或者去 看教程。
- 预算有限的开发者,建议先用 ScraperAPI 免费套餐在你的目标站点上测试,再把它和 ScrapingBee、Scrapfly、Bright Data 的实际每次请求成本对比后再决定。最便宜的方案,完全取决于你的具体场景和功能需求。
想看看你的抓取需求具体要花多少钱?先用 ScraperAPI 免费套餐测试你的目标站点,或者 ,看看两次点击能做到什么程度。想了解更多,也可以查看我们的套餐方案。
常见问题
ScraperAPI 是免费的吗?
是的,ScraperAPI 提供免费套餐,每月有 ,还有一个包含 5,000 credits 的 7 天试用。不过,因为 JavaScript 渲染、高级代理或高成本域名(Amazon = 5×、Google = 25×、LinkedIn = 30×)会套用倍率,你的实际可用量可能远低于 1,000 次请求。免费套餐不提供 ultra-premium 代理。
ScraperAPI 每次请求多少钱?
这非常取决于功能开关和目标域名。对普通 HTML 网站发起一次标准请求要 1 个 credit。抓 Amazon 要 5 个 credits。抓 Google SERP 要 25 个 credits。开启 JavaScript 渲染会再加 10 个 credits。ultra-premium 代理和 JavaScript 渲染一起用时,每次请求要 75 个 credits。在 Hobby 套餐($49/月,10 万 credits)下,每次请求成本大约从 $0.00049(标准请求)到 $0.0368(ultra-premium + JS)不等。更多细节可见上面的完整成本表。
ScraperAPI 适合抓 Amazon 吗?
ScraperAPI 的 Amazon Structured Data 端点是它最强的功能之一,独立基准测试中成功率达到 ,并能输出非常完整的解析 JSON(18+ 字段)。不过,每次 Amazon 请求最低要 5 个 credits,所以规模一大成本就会涨得很快。对于想把 Amazon 数据直接放进表格、又不想写代码的小团队来说, 提供了一键导出替代方案。
ScraperAPI 的最佳替代方案有哪些?
如果你是开发者,可以考虑:(基础 HTML 最便宜)、(JavaScript 渲染不错)、(高防护站点最佳——不管渲不渲染都按固定费率)、以及 。如果你不是技术用户,可以选 ——一款无代码、AI 驱动的 Chrome 扩展,可直接导出到 Excel、Google Sheets、Airtable 和 Notion。更深入的对比可以看我们的 。
ScraperAPI 能抓需要登录的网站吗?
ScraperAPI 支持通过 session_number 参数维持会话(多次请求使用同一 IP),但它 。它无法处理表单填写、双因素认证,或者复杂的认证流程。对于需要登录的网站,像 这样的浏览器工具——直接用你当前的浏览器会话去抓你能看到的内容——通常会更靠谱。
延伸阅读