

Zillow 汇聚了1.6 亿条美国房产记录,如何批量获取这些数据,一直是房地产数据工作里最常被提到、也最让人头疼的任务之一。如果你曾经尝试抓取 Zillow,最后却盯着验证码页面而不是房源数据,那你绝对不是一个人。
我花了很多时间研究和测试不同的 Zillow 抓取方案——既包括 Python 方案,也包括我们在 Thunderbit 做的无代码工具方案。这篇指南会把两条路线都讲清楚。无论你想要完整的 Python 实战教程和反爬策略,还是只想在午饭前把 200 条房源放进表格里,这里都有适合你的内容。我们会讲清楚 Zillow 数据为什么重要、网站底层结构是什么、Python 具体怎么写、爬虫为什么会失效,以及如何把定时抓取自动化,用于价格监控。
为什么要抓取 Zillow 数据?
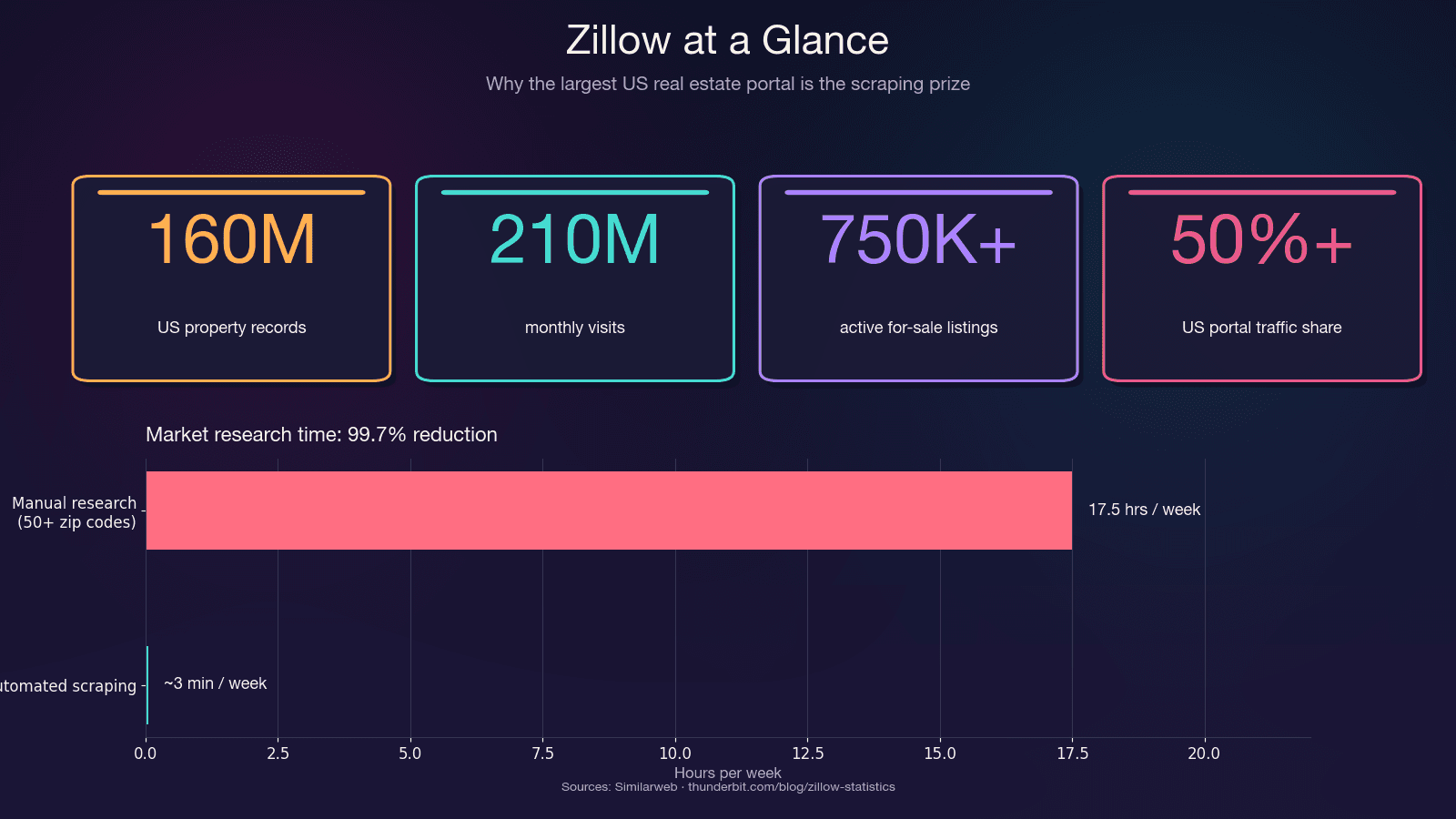
Zillow 是美国住宅房地产数据最大的集中地。它每月带来2.1 亿次访问,平台上大约有 75 万条在售房源和 190 万条出租房源。它承载了美国房地产门户流量的一半以上,超过下一个竞争对手的两倍多。
在开始写 Python 代码之前,先要知道:抓 Zillow 并不只有 Python 一条路,选错方法会白白浪费好几个小时。像 httpx 和 BeautifulSoup 这类 Python 工具适合有一定基础的人,需要手动处理请求头和代理,速度中等(每页 1–3 秒),而且维护成本高,优点是免费;Selenium 或 Playwright 通过渲染 JavaScript,反爬处理更好,但速度更慢(每页 5–15 秒),维护也更麻烦;ScraperAPI 或 ScrapFly 这类抓取 API 速度更快,自带反反爬支持,维护成本中等,但价格通常在每月 30–599 美元;Zillow 官方通过 Bridge Interactive 提供的 API 速度快、维护低,但权限有限,费用大约每月 500 美元;而像 Thunderbit 这样的无代码工具对新手更友好,速度快,借助 AI 自适应几乎不需要维护,通常还提供免费增值模式。
单从节省时间来看,效果就非常明显。人工研究 50 多个邮编区域,一周可能要花 15–20 个小时;自动化抓取只需要几分钟,时间成本可减少 99.7%。
抓 Zillow 的所有方式:Python、API 和无代码对比
在直接上 Python 代码前,先记住:"用 Python 抓 Zillow" 不是唯一选项。选错方法会浪费很多时间。下面给你一个横向对比,方便你自己选:
| 方法 | 技能要求 | 反爬处理 | 速度 | 维护成本 | 费用 |
|---|---|---|---|---|---|
| Python + httpx/BeautifulSoup | 中级 | 手动处理(请求头、代理) | 中等(1–3 秒/页) | 高(选择器容易失效) | 免费 |
| Python + Selenium/Playwright | 中级 | 更好(可渲染 JS) | 较慢(5–15 秒/页) | 高 | 免费 |
| 抓取 API(ScraperAPI、ScrapFly) | 中级 | 内置支持 | 快 | 中等 | 每月 30–599 美元 |
| Zillow 官方 API(Bridge Interactive) | 初级–中级 | 不适用 | 快 | 低 | 约每月 500 美元,访问受限 |
| 无代码工具(Thunderbit) | 初级 | 内置(AI 自适应) | 快 | 几乎为零(AI 会重新读取页面) | 免费增值模式 |
如果你现在就需要数据,不想写代码,可以直接从 Thunderbit 开始。如果你想搞清楚底层机制,或者需要高度自定义,那就继续看下面的 Python 教程。
2 分钟搞定:用 Thunderbit 抓 Zillow(无需代码)
在深入 Python 之前,先给只想快速拿到 Zillow 数据的人一条捷径——不用搭 Python 环境,不用配代理,不用维护选择器。我们在 Thunderbit 里专门做了这个流程,目标就是在不增加工程负担的前提下,直接拿到结构化房地产数据。
难度: 初级 所需时间: 约 2 分钟 你需要准备: Chrome 浏览器、Thunderbit Chrome 扩展(免费版即可)
第 1 步:安装 Thunderbit 并打开 Zillow
先从 Chrome 网上应用店安装 Thunderbit 扩展。然后打开 Zillow 的搜索结果页,比如在休斯顿,德州搜索房源。
第 2 步:点击“AI Suggest Fields”
打开 Thunderbit 侧边栏,点击“AI Suggest Fields”。AI 会自动读取页面并推荐字段:价格、地址、卧室数、浴室数、面积、Zestimate、房源链接等等。根据我的测试,它通常能自动识别 20 多个字段,几乎不用手动配置。
第 3 步:点击“Scrape”
点击 Scrape 按钮,数据就会以结构化表格的形式出现在扩展里。Thunderbit 会自动处理 Zillow 的分页,包括点击翻页和无限滚动。
第 4 步:用子页面抓取补全详情
如果你想要税务记录、学校评分、历史价格等详情页数据,可以使用“Scrape Subpages”来补全表格。Thunderbit 会逐个打开房源详情页并提取附加字段,不需要额外写代码。
第 5 步:导出
你可以直接导出到 Google Sheets、Excel、Airtable 或 Notion,而且导出是免费的。
为什么 Thunderbit 特别适合抓 Zillow
真正的优势在于稳定性。Thunderbit 的 AI 每次抓取时都会重新读取页面结构。即使 Zillow 频繁改版,也不用去修那些脆弱的 CSS 选择器,AI 会自动适应。这确实解决了很多代码爬虫“天生脆弱”的老问题。
你能从 Zillow 抓到什么数据?(20+ 字段)
很多教程只抓价格和地址就结束了,但 Zillow 房源实际上能提取的数据远不止这些。下面是一个参考表:
| 字段 | 位置 | 提取难度 |
|---|---|---|
| 标价 | 搜索页 + 详情页 | 简单 |
| 地址 / 邮编 | 搜索页 + 详情页 | 简单 |
| Zestimate | 搜索页 + 详情页 | 简单 |
| 价格历史(每一条记录) | 详情页 | 困难(嵌套 JSON) |
| 税务历史 | 详情页 | 困难(嵌套 JSON) |
| 卧室 / 浴室 / 面积 | 搜索页 + 详情页 | 简单 |
| 建造年份 | 详情页 | 简单 |
| HOA 费用 | 详情页 | 中等 |
| 步行分 / 交通分 | 详情页(iframe) | 困难(需要 JS 渲染) |
| 学校评分 | 详情页 | 中等 |
| 地块面积 | 详情页 | 简单 |
| 在 Zillow 上的天数 | 搜索页 | 简单 |
| 房源经纪人 / 代理公司 | 搜索页 + 详情页 | 中等 |
| MLS 编号 | 详情页 | 简单 |
| 房产类型 | 搜索页 + 详情页 | 简单 |
| 纬度 / 经度 | __NEXT_DATA__ JSON | 中等 |
| 描述文本 | 详情页 | 简单 |
| 图片链接 | 搜索页 + 详情页 | 中等 |
| Rent Zestimate | 详情页 | 中等 |
| 附近可比成交房源 | 详情页 | 困难 |
其中“困难”字段——比如价格历史、税务历史、可比成交房源——通常藏在详情页里的嵌套 JSON 中。下面的 Python 部分会演示如何精确提取这些内容。如果你不想写代码,Thunderbit 的 AI Suggest Fields 可以自动识别大多数字段,而它的 Subpage Scraping 也能自动抓取详情页内容。
配置 Python 环境来抓取 Zillow
难度: 中级 所需时间: 搭建约 5 分钟,完整教程约 30 分钟 你需要准备: Python 3.8+、Chrome 浏览器(用于检查页面)、文本编辑器或 IDE
先安装所需库:
pip install httpx beautifulsoup4 pandas lxml
它们分别负责什么:
- httpx —— HTTP 客户端,性能比
requests更好,还支持异步 - beautifulsoup4 + lxml —— 负责 HTML 解析
- pandas —— 用于导出 CSV/Excel
- 可选:如果你需要渲染 JavaScript 密集型页面,可以再装 selenium 或 playwright
在动手抓取前,先理解 Zillow 的页面结构
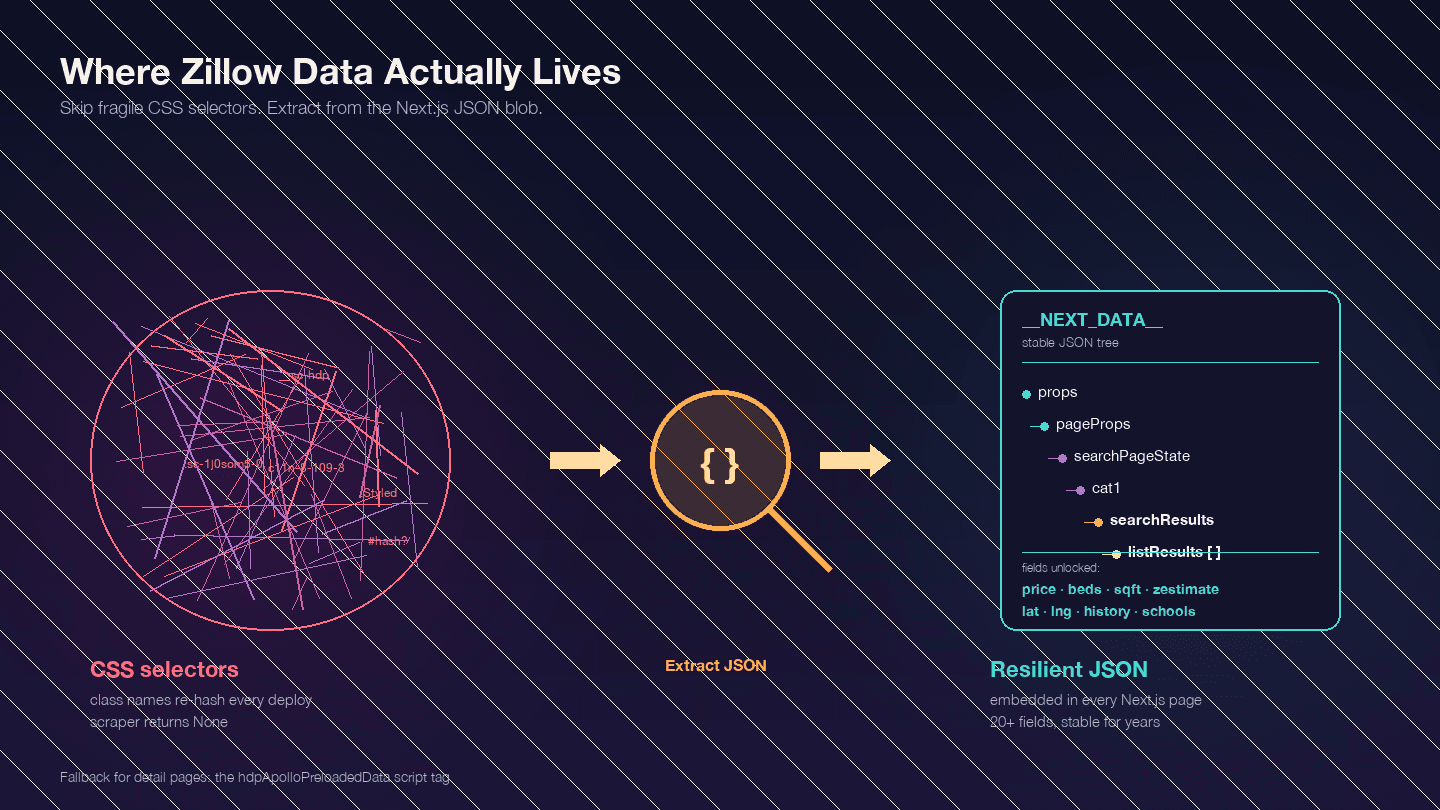
在写任何代码之前,这一步最关键。Zillow 是一个 Next.js 应用——这一点已由 Zillow 员工的工程帖子 证实。也就是说,你想要的大多数数据并不直接写在可见的 HTML 元素里,而是嵌在一个 <script id="__NEXT_DATA__"> 的 JSON 数据块中。
打开任意一个 Zillow 房源页面,按 F12,进入 Elements,搜索 __NEXT_DATA__。你会找到一个非常大的 JSON 对象,里面包含所有房源数据——价格、坐标、房屋详情、价格历史、税务记录、学校评分等等。
为什么这很重要?因为 Zillow 的 CSS 类名是哈希化的(由 styled-components 生成),而且每次部署都会变。比如一个 StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0 这样的类名,下周就可能变成完全不同的哈希值。任何依赖 CSS 选择器的爬虫,都会频繁失效。
相比之下,读取 __NEXT_DATA__ 里的 JSON 要稳定得多,因为它根本不依赖 HTML 结构。
搜索结果页中最关键的 JSON 路径:
| 路径 | 内容 |
|---|---|
props.pageProps.searchPageState.cat1.searchResults.listResults | 搜索结果数组 |
props.pageProps.searchPageState.cat1.searchResults.mapResults | 地图视图结果 |
props.pageProps.searchPageState.cat1.searchList.totalPages | 可用总页数 |
对于详情页,有些页面使用 __NEXT_DATA__,有些则使用另一个名为 hdpApolloPreloadedData 的 script 标签。下面的代码会把这两种情况都处理掉。
分步教程:如何用 Python 抓取 Zillow
第 1 步:设置 HTTP 请求头,避免一上来就被拦截
如果你直接向 Zillow 发起一个裸 httpx.get() 请求,拿到的通常不是房源数据,而是验证码页面。Zillow 同时使用 PerimeterX(HUMAN Security) 和 Cloudflare——在抓取基准测试里,这两者的难度都被评为 8/10。系统会检查你的 TLS 指纹、HTTP 请求头以及 IP 声誉。
下面是截至 2025 年仍然有效的最小请求头配置:
import httpx
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
"image/avif,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Sec-Ch-Ua": '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
"Sec-Ch-Ua-Platform": '"Windows"',
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
}
Sec-Ch-Ua 这一组请求头非常关键。很多教程会漏掉它们——这也是为什么那些代码在 PerimeterX 面前根本跑不通。
第 2 步:抓取 Zillow 搜索结果页
Zillow 的搜索 URL 有比较固定的规律。比如休斯顿,德州:
- 第 1 页:
https://www.zillow.com/houston-tx/ - 第 2 页:
https://www.zillow.com/houston-tx/2_p/ - 第 3 页:
https://www.zillow.com/houston-tx/3_p/
每页大约有 41 条房源。Zillow 最多只开放 20 页结果(约 820 条房源)。如果你要更大的数据集,就需要按地理区域拆分(后面会讲)。
下面是通过提取 __NEXT_DATA__ JSON 来抓取搜索结果的代码:
from bs4 import BeautifulSoup
import json
import time
import random
def scrape_zillow_search(url):
"""从 Zillow 搜索结果页抓取房源数据。"""
response = httpx.get(url, headers=headers, timeout=15)
if response.status_code != 200:
print(f"Got status {response.status_code} for {url}")
return []
soup = BeautifulSoup(response.text, "lxml")
script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
if not script_tag:
print("No __NEXT_DATA__ found — likely blocked by CAPTCHA")
return []
next_data = json.loads(script_tag.string)
try:
results = (
next_data["props"]["pageProps"]["searchPageState"]
["cat1"]["searchResults"]["listResults"]
)
except KeyError:
print("Unexpected JSON structure — Zillow may have changed its format")
return []
listings = []
for item in results:
listing = {
"zpid": item.get("zpid"),
"address": item.get("addressStreet"),
"city": item.get("addressCity"),
"state": item.get("addressState"),
"zipcode": item.get("addressZipcode"),
"price": item.get("unformattedPrice") or item.get("price"),
"beds": item.get("beds"),
"baths": item.get("baths"),
"sqft": item.get("area"),
"zestimate": item.get("zestimate"),
"days_on_zillow": item.get("daysOnZillow"),
"listing_url": item.get("detailUrl"),
"img_src": item.get("imgSrc"),
"property_type": item.get("hdpData", {}).get("homeInfo", {}).get("homeType"),
"latitude": item.get("latLong", {}).get("latitude"),
"longitude": item.get("latLong", {}).get("longitude"),
}
listings.append(listing)
return listings
要抓多页内容,可以配合延迟循环:
all_listings = []
base_url = "https://www.zillow.com/houston-tx/"
for page in range(1, 6): # 前 5 页
url = base_url if page == 1 else f"{base_url}{page}_p/"
print(f"Scraping page {page}...")
page_listings = scrape_zillow_search(url)
all_listings.extend(page_listings)
# 随机延迟 3–7 秒
delay = random.uniform(3, 7)
time.sleep(delay)
print(f"Total listings scraped: {len(all_listings)}")
如果一切正常,你会看到结构化的房源数据不断累积到 all_listings 里。要是结果为空,可以看下面的“为什么爬虫会失效”部分。
第 3 步:抓取 Zillow 房源详情页
搜索结果只能拿到基础信息。详情页才包含更深的数据:价格历史、税务历史、学校评分、中介信息和房源描述。第 2 步中拿到的每个房源链接,都会指向一个详情页。
Zillow 详情页可能使用两种数据格式。下面的代码能同时兼容这两种情况:
def scrape_zillow_detail(url):
"""从 Zillow 房源页面抓取详细数据。"""
response = httpx.get(url, headers=headers, timeout=15)
if response.status_code != 200:
return None
soup = BeautifulSoup(response.text, "lxml")
# 先尝试 __NEXT_DATA__(最常见)
script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
if script_tag:
next_data = json.loads(script_tag.string)
try:
cache_str = next_data["props"]["pageProps"]["componentProps"]["gdpClientCache"]
cache = json.loads(cache_str)
first_key = next(iter(cache))
prop = cache[first_key]["property"]
return extract_property_fields(prop)
except (KeyError, StopIteration):
pass
# 备用方案:hdpApolloPreloadedData
apollo_tag = soup.find("script", {"id": "hdpApolloPreloadedData"})
if apollo_tag:
raw = json.loads(apollo_tag.string)
api_cache = json.loads(raw["apiCache"])
for key, value in api_cache.items():
if "ForSale" in key or "property" in str(value)[:100]:
prop = value.get("property", value)
return extract_property_fields(prop)
return None
def extract_property_fields(prop):
"""从 Zillow 房源 JSON 对象中提取结构化字段。"""
return {
"zpid": prop.get("zpid"),
"zestimate": prop.get("zestimate"),
"rent_zestimate": prop.get("rentZestimate"),
"description": prop.get("description"),
"year_built": prop.get("yearBuilt"),
"lot_size": prop.get("lotSize"),
"hoa_fee": prop.get("monthlyHoaFee"),
"mls_id": prop.get("mlsid"),
"broker_name": prop.get("brokerName") or prop.get("attributionInfo", {}).get("brokerName"),
"price_history": [
{
"date": event.get("date"),
"event": event.get("event"),
"price": event.get("price"),
}
for event in prop.get("priceHistory", [])
],
"tax_history": [
{
"year": record.get("time"),
"tax_paid": record.get("taxPaid"),
"value": record.get("value"),
}
for record in prop.get("taxHistory", [])
],
"schools": [
{
"name": school.get("name"),
"rating": school.get("rating"),
"distance": school.get("distance"),
}
for school in prop.get("schools", [])
],
}
然后按延迟循环处理每个房源链接:
detail_data = []
for listing in all_listings[:10]: # 先用 10 条测试
detail_url = listing.get("listing_url")
if not detail_url:
continue
if not detail_url.startswith("http"):
detail_url = f"https://www.zillow.com{detail_url}"
print(f"Scraping detail: {detail_url}")
detail = scrape_zillow_detail(detail_url)
if detail:
detail_data.append({**listing, **detail})
time.sleep(random.uniform(3, 8))
完成这一步后,你就会得到一个字典列表,里面同时包含每套房子的搜索页数据和详情页数据。
第 4 步:处理分页,抓取更多页面
如果某个区域的房源超过 820 条(20 页上限),你就需要按地理范围拆分。Zillow 的内部 API 支持 mapBounds 参数。做法是把地图分成多个象限分别抓取。
def split_bounds(bounds):
"""把地图边界切成 4 个象限。"""
mid_lat = (bounds["north"] + bounds["south"]) / 2
mid_lng = (bounds["east"] + bounds["west"]) / 2
return [
{"north": bounds["north"], "south": mid_lat, "east": bounds["east"], "west": mid_lng},
{"north": bounds["north"], "south": mid_lat, "east": mid_lng, "west": bounds["west"]},
{"north": mid_lat, "south": bounds["south"], "east": bounds["east"], "west": mid_lng},
{"north": mid_lat, "south": bounds["south"], "east": mid_lng, "west": bounds["west"]},
]
对于大多数使用场景——比如监控某个特定区域 50–200 套房源——标准 URL 分页就够用了。象限拆分主要适用于城市级或州级的大范围抓取。
第 5 步:导出你抓到的 Zillow 数据
用 pandas 保存为 CSV:
import pandas as pd
df = pd.DataFrame(detail_data)
df.to_csv("zillow_houston_listings.csv", index=False)
print(f"Exported {len(df)} listings to zillow_houston_listings.csv")
导出为 JSON:
with open("zillow_houston_listings.json", "w") as f:
json.dump(detail_data, f, indent=2)
如果你想直接跳过导出步骤,Thunderbit 可以免费导出到 Google Sheets、Airtable 和 Notion——如果你想马上在协作环境里使用数据,这会非常方便。
为什么 Zillow 爬虫会失效,以及如何做得更稳
这部分相当于生存指南。
根据我的经验,Zillow 爬虫通常会因为三个具体原因失效,而每一个都有对应的解决办法。
PerimeterX 和验证码:为什么你的请求会拿到空数据
Zillow 的 PerimeterX 集成会同时检查多个信号:TLS 指纹、HTTP 请求头、IP 声誉和请求模式。一旦它判断是自动化访问,就会返回“Press & Hold”验证码页面,而不是房源数据。
典型失败场景: 你用默认的 Python 请求头发起请求,响应 HTML 里只有 PerimeterX 的挑战脚本,没有房产数据——于是 BeautifulSoup 根本找不到 __NEXT_DATA__ 标签。
解决办法: 使用第 1 步里的完整浏览器伪装请求头。如果你要发起几十个以上的请求,还需要配合代理轮换(下面会讲)。如果是高强度抓取,可以考虑使用 curl_cffi 并设置 impersonate="chrome"——它是目前少数可以匹配真实 Chrome TLS 指纹的 Python HTTP 客户端。
动态 CSS 选择器:为什么 BeautifulSoup 会返回 None
如果你在用类似 .list-card-price 这样的 CSS 选择器,或者带哈希的 class 名,你的爬虫每次 Zillow 部署新版本后都会坏掉。
Zillow 使用 styled-components 生成类名,比如 StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0。其中的哈希部分每次构建都会变。
解决办法: 完全不要依赖 CSS 选择器。像上面的代码那样,直接从 __NEXT_DATA__ JSON 数据块里提取信息。这种方式之所以稳定,是因为 JSON 结构的变化频率远低于 HTML 标记。
如果你非得解析 HTML,那就优先找 data-test 属性(比如 data-test="property-card"),或者使用包含字符串匹配的类选择器,比如 [class*="PropertyCard"]。但总体来说,JSON 提取更可靠。
代理轮换和指数退避:能扛住 IP 封禁的代码
Zillow 会立即封禁数据中心 IP。最稳妥的做法 是使用住宅代理。安全请求频率大致是每个 IP 3–8 秒一次,每小时不超过 500 次请求。
下面是一个带抖动的指数退避重试装饰器:
import random
import time
def backoff_with_jitter(attempt, base_delay=2, max_delay=60):
"""AWS 风格的全抖动指数退避。"""
delay = min(max_delay, base_delay * (2 ** attempt))
return random.uniform(0, delay)
def fetch_with_retry(url, max_retries=5):
for attempt in range(max_retries):
try:
response = httpx.get(url, headers=headers, timeout=15)
if response.status_code == 200:
return response
if response.status_code in (403, 429):
delay = backoff_with_jitter(attempt, base_delay=5)
print(f"Blocked ({response.status_code}). Retrying in {delay:.1f}s...")
time.sleep(delay)
continue
except Exception as e:
if attempt == max_retries - 1:
raise
time.sleep(backoff_with_jitter(attempt))
return None
再来一个简单的代理池轮换示例:
class ProxyPool:
def __init__(self, proxies):
self.proxies = proxies
self.index = 0
self.failures = {}
def get_next(self):
proxy = self.proxies[self.index % len(self.proxies)]
self.index += 1
return {"http://": proxy, "https://": proxy}
def report_failure(self, proxy):
self.failures[proxy] = self.failures.get(proxy, 0) + 1
if self.failures[proxy] > 3:
self.proxies.remove(proxy)
# 使用示例:
pool = ProxyPool(proxies=[
"http://user:pass@residential1.example.com:8080",
"http://user:pass@residential2.example.com:8080",
])
如果你在找代理服务商,DataImpulse 的住宅代理大约 1 美元/GB,是比较便宜的选择;IPRoyal 和 Smartproxy 也是不错的中端方案,大约 4–7 美元/GB。
零维护替代方案
如果你经常抓 Zillow,又不想反复修选择器、折腾代理池,那么 Thunderbit 的 AI 每次都会重新读取页面结构。没有需要维护的选择器,也不用配置代理。它确实能解决代码爬虫那种让人持续头疼的脆弱问题。
自动化 Zillow 抓取:定时任务和价格监控
我接触过的每个房地产投资者都想要这个功能,但几乎没有哪篇 Zillow 抓取教程真正讲过:如何定期自动抓取并监控价格变化。
给 Python 用户:Cron 定时任务和价格变化检测
你可以设置一个每周运行一次的 cron 任务,用来抓取数据并标记价格变化:
import pandas as pd
from datetime import datetime
def detect_price_changes(new_data, historical_file, threshold=0.05):
"""将新抓取的数据与历史数据比较,标记涨跌幅超过阈值的项目。"""
try:
old = pd.read_csv(historical_file)
except FileNotFoundError:
new_data.to_csv(historical_file, index=False)
print("First run — saved baseline data.")
return pd.DataFrame()
merged = new_data.merge(old, on="zpid", suffixes=("_new", "_old"))
merged["price_change_pct"] = (
(merged["price_new"] - merged["price_old"]) / merged["price_old"]
)
alerts = merged[merged["price_change_pct"].abs() > threshold]
# 追加带时间戳的新数据
new_data["scraped_at"] = datetime.now().isoformat()
new_data.to_csv(historical_file, mode="a", header=False, index=False)
return alerts
把它加到 crontab 里,设置为每周一早上 6 点执行:
0 6 * * 1 cd /path/to/scraper && python zillow_monitor.py
一个实际场景:每周监控 50 条奥斯汀,德州的房源。每周一,脚本抓取当前价格,与上周数据对比,并输出一个 CSV,标出所有跌幅超过 5% 的房源。
给非程序员:Thunderbit Scheduled Scraper
Thunderbit 的 Scheduled Scraper 允许你用自然语言描述执行频率(比如“每周一上午 9 点”),输入 Zillow 搜索 URL,然后点击 Schedule 即可。每次运行后,数据会自动导出到 Google Sheets。无需 Python、无需 cron、也不用自己维护服务器。对于房地产经纪人或运营团队来说,这种方式尤其适合需要稳定价格监控、但又没有工程支持的场景。
负责任地抓取 Zillow 的一些建议
最后提醒几点,帮助你尽量站在合规的一边:
- 只抓取公开可访问的数据。 不要访问登录后才能看到的页面或需要身份验证的内容。
- 控制请求频率。 每次请求间隔 3–8 秒,不要狂轰滥炸服务器。
- 不要抓取个人或私密用户数据。 房源里的经纪人姓名和中介信息属于公开信息;用户账户数据不属于。
- 以合乎道德的方式存储和使用数据。 市场研究、投资分析和线索生成都是合理用途;垃圾邮件不是。
- 法律背景: hiQ v. LinkedIn 判决 确立了抓取公开可访问数据不违反 CFAA。Meta v. Bright Data(2024)也延续了类似原则。不过,Zillow 的服务条款仍限制自动化访问,而且他们主要通过 IP 封禁和验证码来执行,而不是直接诉讼。请始终关注最新规定,并尊重 robots.txt。
选择适合你的 Zillow 抓取方式
最适合你的方案,取决于你当前的情况:
想快速拿数据,不写代码? Thunderbit 可以让你在大约 2 分钟内,从 Zillow 搜索页直接变成结构化表格。AI 会自动适配页面变化,处理分页,并且支持免费导出。安装 Chrome 扩展 后,直接在 Zillow 搜索页试试看。
想要完全控制? 使用本指南里的 Python 代码。为了稳定,优先从 __NEXT_DATA__ JSON 提取,而不是 CSS 选择器。配好浏览器级请求头,轮换住宅代理,并使用指数退避提升可靠性。
要扩大规模? 像 ScrapFly 这类抓取 API(在 Zillow 上成功率可达 99%)或 ScraperAPI,会帮你处理代理和验证码基础设施,费用大约每月 30–599 美元,取决于用量。
要长期跟踪价格? 可以设置 cron 任务配合价格变化检测脚本;或者直接用 Thunderbit 的 Scheduled Scraper,走零维护路线。
数据本身就在那儿,唯一的问题是:你愿意花多少工程时间把它拿出来。想了解更多如何把网页数据放进表格,可以看看我们的 将网站数据抓取到 Excel 的指南 或 Zillow 数据统计汇总 获取最新平台数据。你也可以在 Thunderbit YouTube 频道 观看教程。
试试 Thunderbit 抓取 Zillow 数据 Get Started Free
常见问题
可以免费用 Python 抓 Zillow 吗?
可以——httpx、BeautifulSoup 和 pandas 都是免费且开源的。代价是时间:你需要自己处理请求头、代理轮换和选择器维护。初始搭建预计要花 4–8 小时,而 Zillow 一旦改版,每月还要再花 4–10 小时维护。如果你想完全避免这些编码成本,Thunderbit 也提供免费版。
Zillow 有官方 API 吗?
Zillow 在 2021 年 9 月停用了免费的公开 API。现在的访问要通过 Bridge Interactive,通常需要审批,费用大约每月 500 美元,主要面向持牌房地产从业者。对大多数用户——投资者、研究人员、做市场分析的经纪人——来说,抓取仍然是更实用的替代方案。Zillow 也确实会提供一些可免费下载的研究数据 CSV,地址是 zillow.com/research/data/,包括 Zillow Home Value Index 和 Zillow Observed Rent Index。
抓 Zillow 时怎么避免被封?
有三点:1)使用真实浏览器请求头,包括 Sec-Ch-Ua——这是很多教程会漏掉、但 PerimeterX 最先检查的头;2)轮换住宅代理——数据中心 IP 会被立刻拉黑;3)从 __NEXT_DATA__ 的 JSON 中提取数据,而不是用 HTML 选择器,避免页面改版导致失效。每个 IP 的请求频率控制在 3–8 秒一次。或者直接用 Thunderbit 这类会自动处理反爬的工具。
不写代码抓 Zillow,最好的方法是什么?
Thunderbit 的 AI Web Scraper 是最快的路径。安装 Chrome 扩展,进入 Zillow 搜索页,点击 “AI Suggest Fields” 自动识别列,再点 “Scrape” 即可。你可以直接导出到 Google Sheets、Excel、Airtable 或 Notion,全程不需要写代码。AI 每次都会重新读取页面,所以 Zillow 改版也不容易坏。
Zillow 多久会改一次网站结构,这对爬虫有什么影响?
Zillow 会频繁发布更新,有时甚至每周都会改。由于它使用 styled-components,CSS 类名会随着每次部署而变化,基于 CSS 选择器的爬虫也就经常失效。对 Python 来说,最稳妥的办法是从 __NEXT_DATA__ 的 JSON 数据块里提取,因为它的结构变化频率低得多。如果你想完全免维护,Thunderbit 的 AI 会在每次抓取时重新读取页面结构,并自动适应布局变化。
了解更多




