让我们走进网页爬虫的世界——这个词听起来可能有点技术范儿,但其实非常实用。简单来说,网页爬虫就是从网站上抓取你需要的信息,比如房源列表、商品价格,甚至社交媒体评论,然后整理到 Excel 里,方便查看和分析。
当然,你也可以手动复制粘贴数据,但想象一下要处理几百上千条记录时会怎样?效率会直接掉到谷底。与其这样,不如让 AI 工具来做这些重活。今天,我们要介绍的是 ,一款让这件事变得轻而易举的 AI 工具。
什么是网页爬虫?
网页爬虫是一种从网站上提取数据的技术。无论你是想收集电商网站上的商品详情,还是房地产平台上的租赁数据,网页爬虫都可以把这些任务自动化,并将数据整理成你可以轻松导入 Excel 的表格。
传统上,网页爬虫主要有两种方式。第一种是基于代码的方式,如果你不是程序员,可能会比较难上手。第二种是使用无代码网页爬虫,比如 ,但设置起来也可能有点麻烦。这类工具通常会为 之类的热门网站提供模板,但在真实场景中,你可能需要从各种独特的网站抓取数据,比如名录网站或 Shopify 商店。面对这类复杂且多样的网站,用 AI 来做网页爬虫显然更聪明。
为什么要用 AI 抓取网站数据?
使用 AI 抓取网站数据,是更聪明也更高效的方式。AI 工具可以自动识别网页上的数据结构和模式。它们会读取网站内容,并直接输出结构化数据,因此既能处理动态内容,也能适应网页布局的变化,快速给出准确结果。而且,这些工具不需要技术背景——只要点几下,就能把抓取到的数据直接导入 Excel、Notion 或 Airtable,继续分析和使用。 就是这样一款 AI 网页爬虫,我们接下来会看看它的功能,以及具体怎么用。
试试用 AI 做网页爬虫
试试看!你可以边看边点击、探索并运行整个流程。
介绍 Thunderbit——AI 网页爬虫
认识一下今天的主角:。它是一款智能的 AI 网页爬虫,既能处理带有预设爬虫的热门网站,也能通过 自定义指令 应对更复杂的网站,满足各种需求。
- 预设网页爬虫 提供了专门为 、 和 等热门网站设计的预设网页爬虫。只要选择一个模板,点几下就能把网站数据抓取到 Excel。
- 自定义指令
对于更复杂的网站,你可以使用 Thunderbit 的 列详细指令 功能,精确指定你想抓取的内容。比如,你只需要地址里的城市和州,可以添加这样的详细指令:“我只需要城市和州。例如:San Francisco, CA。”导出的数据就会符合你的要求。

从网站到 Excel 抓取数据的分步指南
抓取热门网站(Amazon、Zillow、Twitter、Instagram 等)
下面介绍如何使用 从网站抓取数据并导出到 Excel。
- 如何设置 Thunderbit
访问 网站,并将其添加为 Chrome 扩展程序。

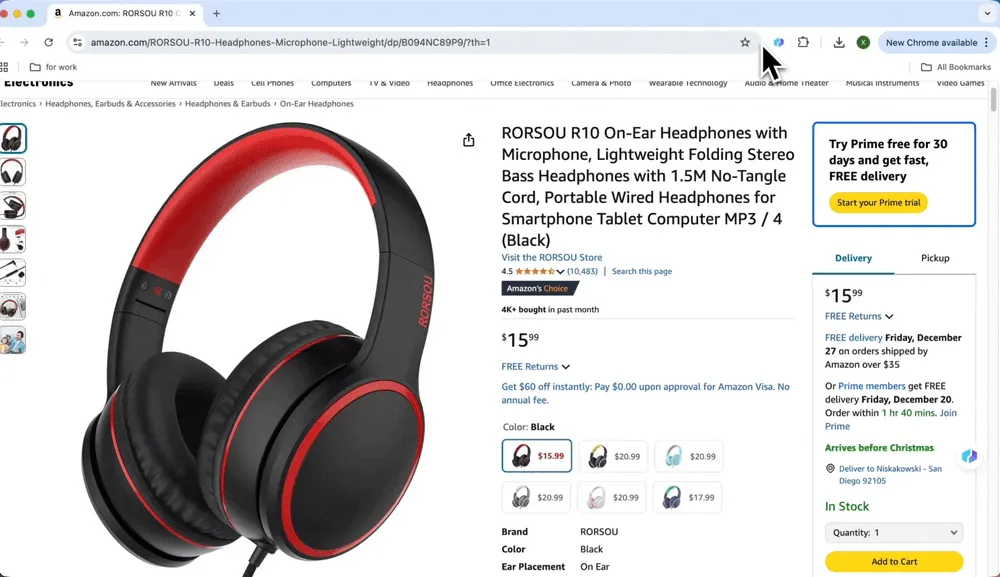
- 抓取
打开你想抓取的网站,比如 或 。预设模板会自动弹出,你只需要点击“抓取”即可。AI 会识别页面上的有用信息,例如商品价格和名称。
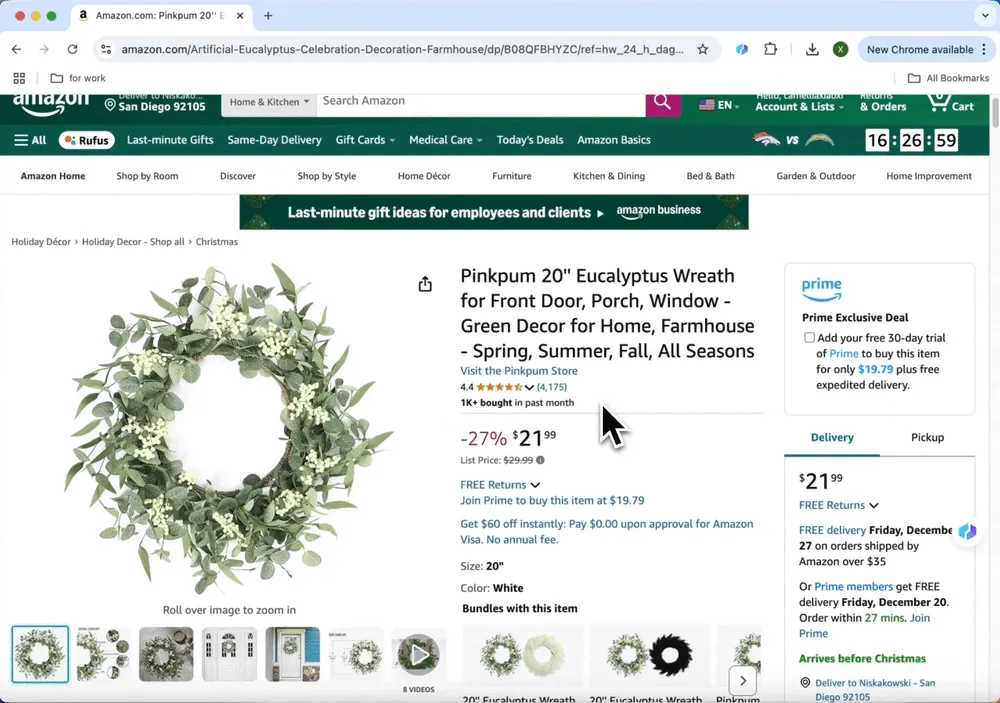
- 选择输出格式
抓取完成后,选择导出格式,比如 Excel,就能方便地整理数据。你也可以复制粘贴到 Google Sheets 中。
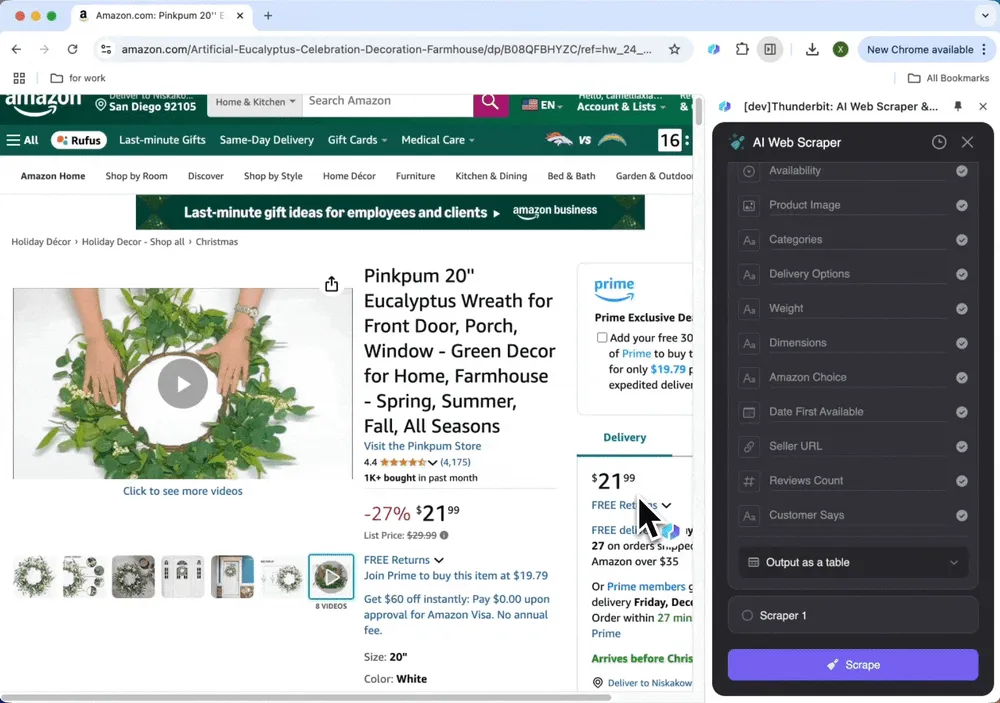
抓取任意网站
如果你想抓取的网站不在模板列表里怎么办?别担心,使用 的 自定义指令 功能,就能灵活调整:
- 设置 AI 爬虫模板
点击“AI 建议列”,AI 会读取整个网站,并自动提取诸如商品价格、描述和评论等列。
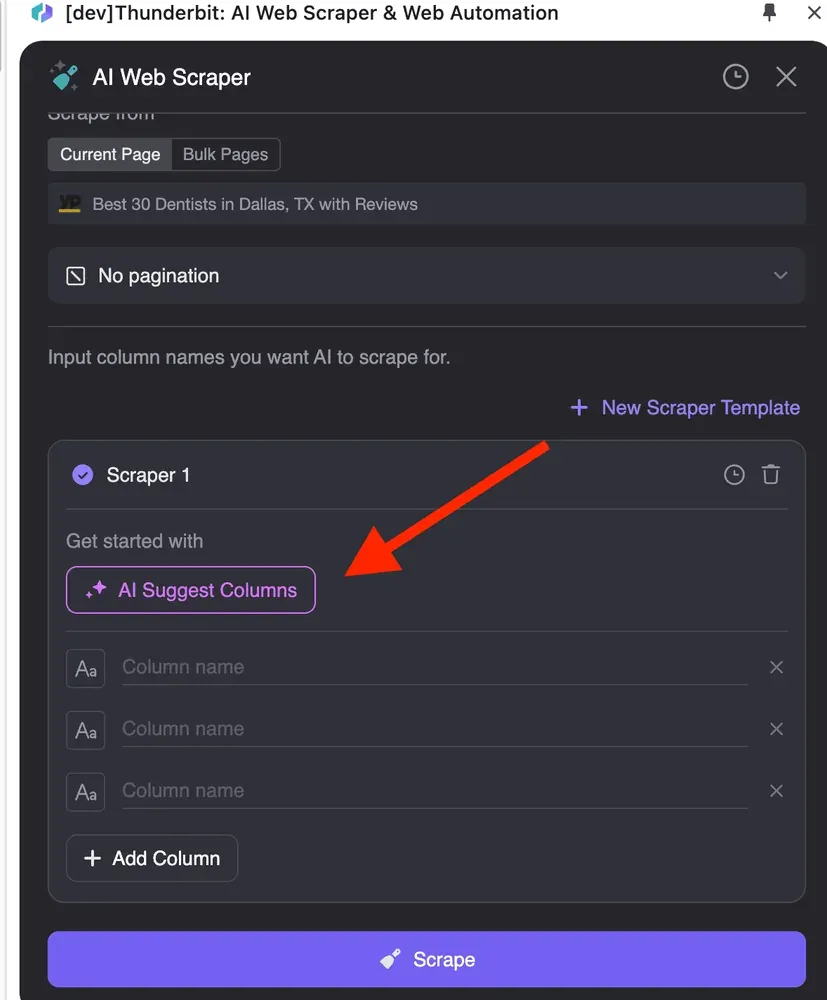
如果你对 AI 生成的列名不满意,还可以自定义每一列的数据格式,比如数字、日期、文本、单选或多选。
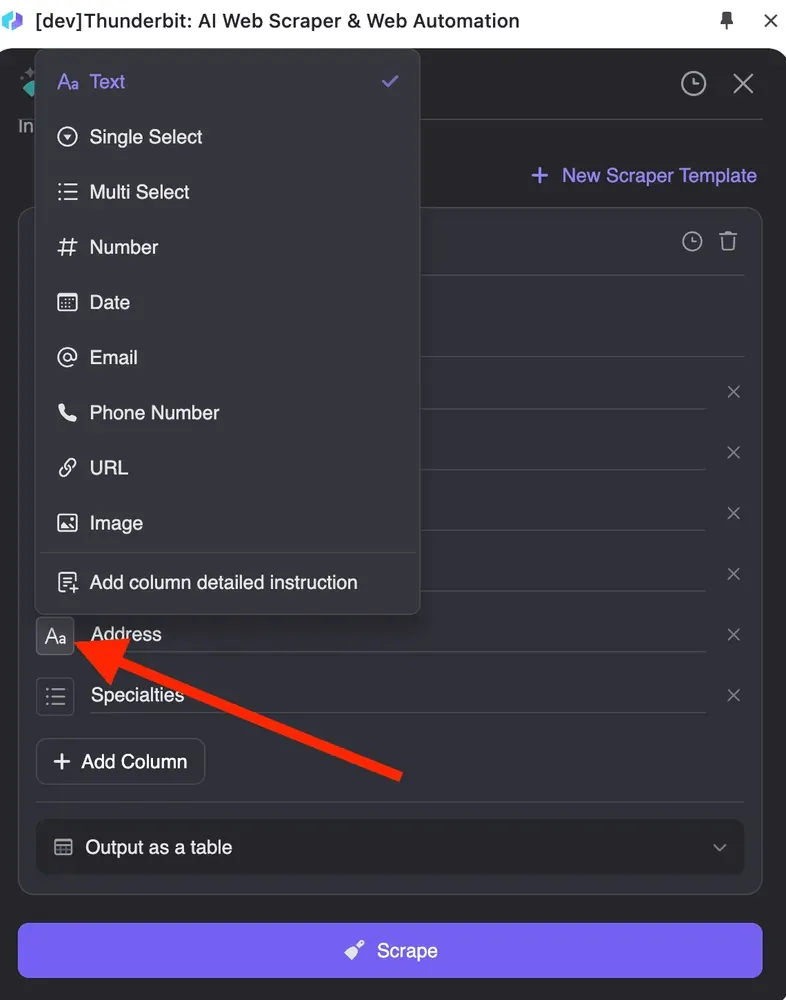
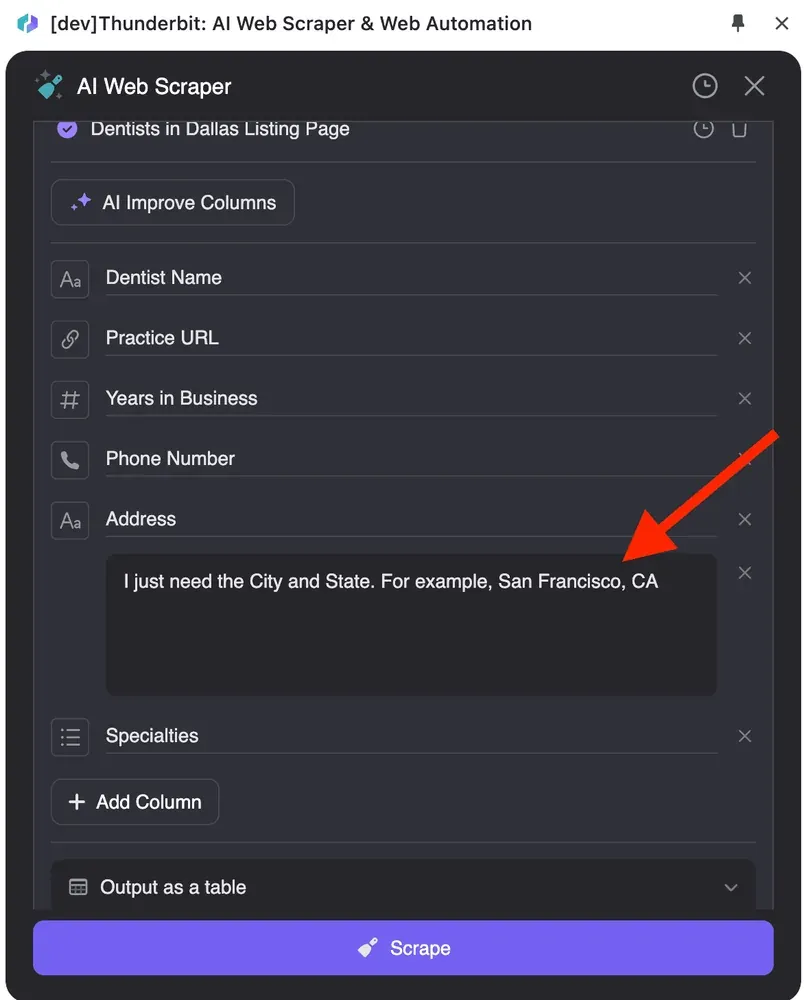
此外,点击“添加列详细指令”来补充更多描述,确保 AI 准确理解你的需求。例如,输入“我只需要城市和州。例如:San Francisco, CA。”导出的数据就会是你想要的格式。
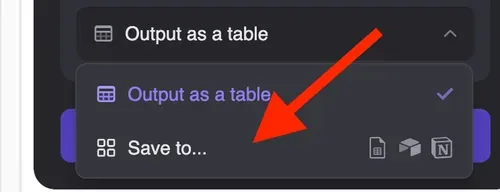
- 连接到你的表格
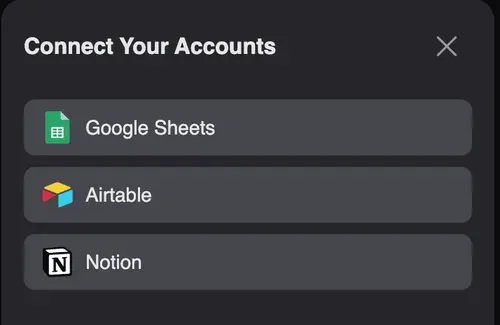
数据抓取完成后,点击“下载 CSV”即可直接导入 Excel。或者选择“保存到…”,将结果同步到 Notion、Airtable、Google Sheets 等工具,方便随时访问。
Thunderbit 的使用场景
线索开发
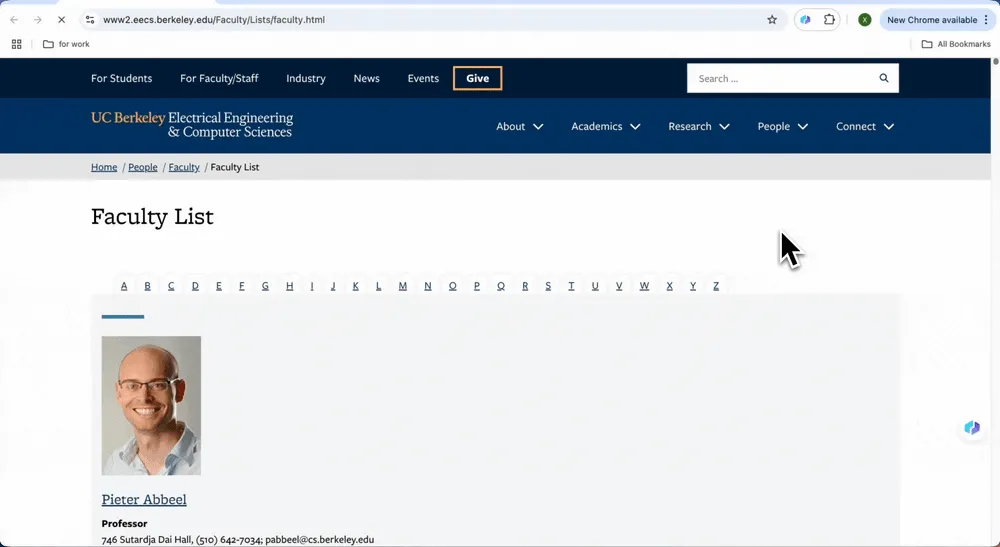
假设你在一家教育软件公司工作,需要寻找大学教授的联系方式来推广产品。院系网站通常没有模板,这时 Thunderbit 的自动抓取功能就非常合适。只需两步,你就能把网站数据抓取到 Excel,帮助你进行线索开发。下面是一个提取教授信息的例子:
- 使用 Thunderbit 抓取加州大学伯克利分校教师名单: 打开你要抓取的页面并启动 Thunderbit。点击“AI 建议列”后,AI 会读取网页,并自动识别你需要的列,例如教授姓名、邮箱和研究领域。
- 导出数据: 点击“抓取”,Thunderbit 就会根据设定好的列名提取数据。点击“下载 CSV”即可直接导入 Excel,或者复制粘贴到你的 Google 表格中。
电商
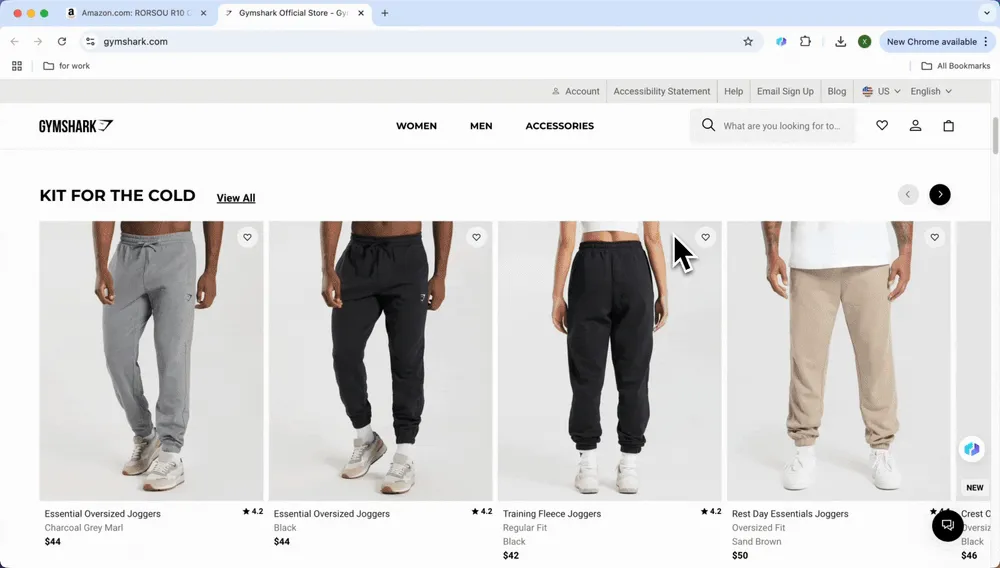
电商卖家需要实时监控竞争对手的价格和商品详情。你可以抓取 或 店铺的商品信息,包括价格、库存和评分,以便快速分析市场趋势。在电商场景里,通常有两种用法:像 Amazon 这样的大型购物平台,可以直接使用预设模板一键提取;而像 Shopify 这样类型多样的店铺,则适合使用 自定义指令。
- Amazon
打开 网站,点击你想抓取的商品页面,预设模板图标就会自动弹出,其中包括 Amazon SKU 详情爬虫和 Amazon SKU 评论爬虫。选择你要抓取的类型,然后点击“抓取”。
- Shopify 店铺
对于界面各不相同的 Shopify 店铺,使用 AI 驱动的 自定义指令 功能最合适。打开你感兴趣的 Shopify 店铺页面,点击右上角的 Thunderbit 插件图标,启动 Thunderbit,然后点击“AI 建议列”。AI 会自动识别你需要的数据:商品名称、价格、评论等。
接着点击“抓取”即可将数据导入 Excel。你也可以选择“复制带表头”或“复制不带表头”,直接粘贴到 Excel 中。
房地产
如果你是房地产经纪人或投资者,就需要整理来自不同地区的房源信息。对于 Zillow 这类热门房地产网站,可以直接使用预设模板一键提取数据;而对于像 这样的房地产公司网站,则可以选择 自定义指令 功能。
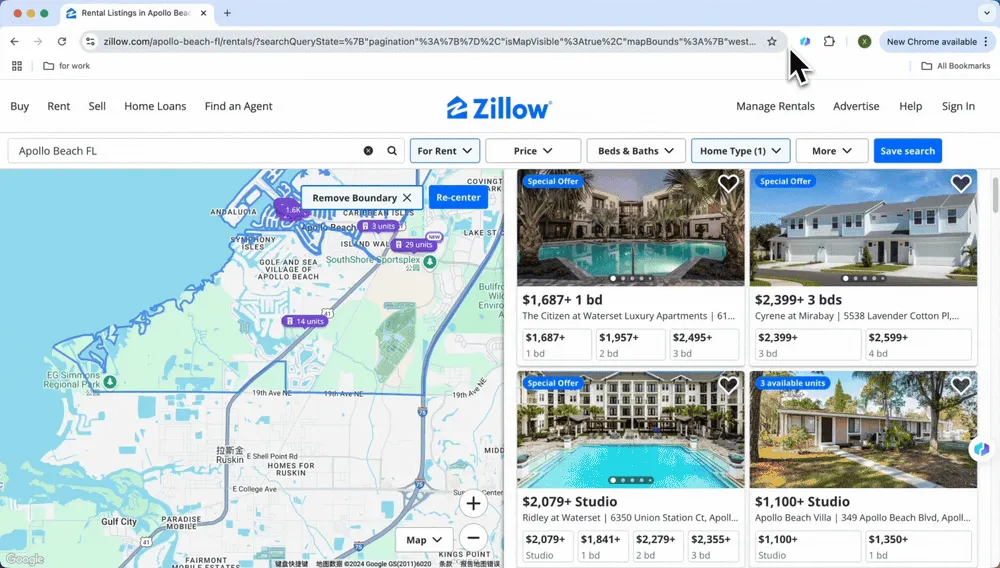
- Zillow
Thunderbit 已为多个热门网站创建了预设模板,列名丰富,比如城市、州、价格、地址等,数据表也非常详细。使用 Thunderbit 的预设模板抓取 Zillow 的房源数据并整理到 Excel 表格中,清晰又高效。如下图所示,你只需要打开 ,搜索你想抓取的信息,Thunderbit 就会自动弹出“使用预设模板”的提示框。点击确认后,就能生成丰富的数据。
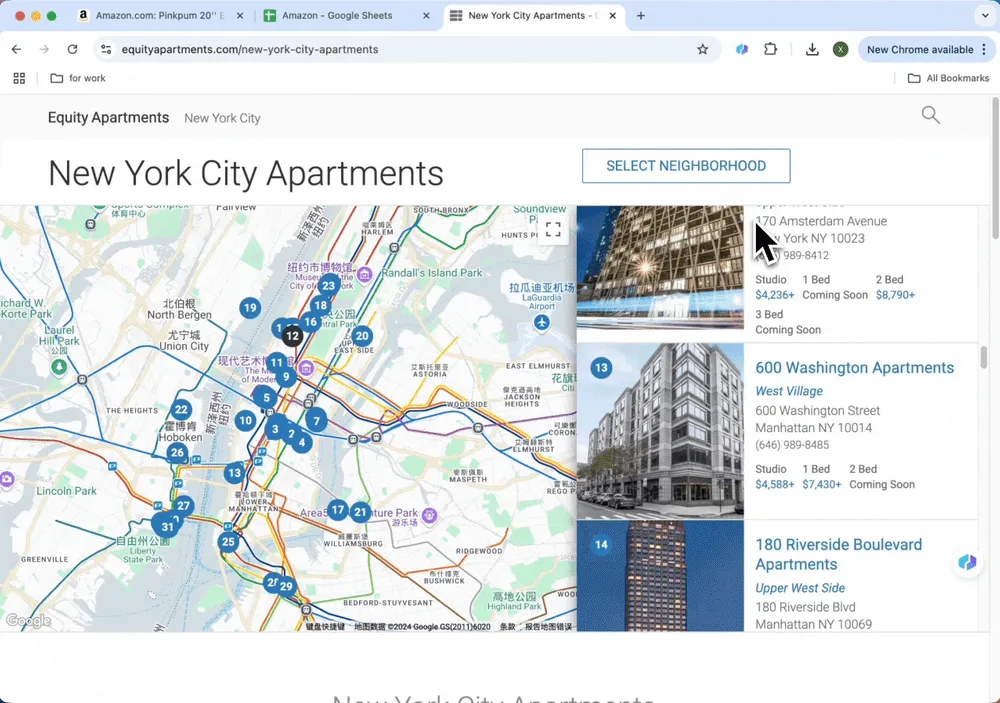
- Equity Apartments
房地产公司网站通常会更新最新房源,但每家公司的网站都不一样,而且可能只有几十条房源。在这种情况下,传统网页爬虫并不适合,因为搭建爬虫所花的时间,往往比直接复制粘贴到 Excel 还要长。所以,AI 网页爬虫才是最佳工具,只需两次点击,就能从网站上抓取房源信息。
-
AI 选择要抓取的数据名称: 打开你需要抓取的网站,点击 AI 网页爬虫,然后点击“AI 建议列”。AI 会读取整个页面,并生成建议的列名,例如公寓名称、地址、电话号码等。
-
点击抓取: 列设置完成后,点击“抓取”。数据生成后,点击“下载 CSV”即可在 Excel 中打开数据。你也可以选择“复制带表头”或“复制不带表头”,直接粘贴到 Excel 中。
使用 Thunderbit 的小技巧
下面这些小技巧可以帮助你更高效地使用 :
- AI 建议列
想抓取一个没有模板的网页,但又不知道该如何分类数据?没问题,交给 AI 建议列就行。打开你想抓取的网页,点击 AI 网页爬虫,再点击 AI 建议列。Thunderbit 会读取整个页面,并自动推荐可能的数据列,比如价格、日期和地址,从而减少手动设置的麻烦。
如果你对 AI 建议列的结果不满意,还可以手动修改数据列,比如更改列名和调整读取格式。数据格式可以是数字、文本、单选或多选,或者图片。你还可以添加列详细指令,输入命令,把你的具体需求告诉 AI。它会根据你的要求提取你想要的数据。
- 与 Notion、Airtable、Google Sheet 集成
导出的数据可以选择复制带表头或不带表头,方便你粘贴到 Excel 中。此外,Thunderbit 还可以与其他工具协作,无缝同步抓取到的数据到 Notion 和 Airtable 等效率工具,非常适合长期项目或团队协作。
导出的数据也可以直接在 Google Sheets 中打开,供你个人使用。
- 抓取 PDF
除了常规网页数据外, 也能识别网页上的 PDF 文件。PDF 文件看起来很整洁,但实际上可能包含各种数据形式,比如文本、表格和图片。使用传统的 PDF 爬虫可能很复杂,但有了 Thunderbit,从 PDF 中提取数据就变得很简单。正如我在文章 中提到的,你也可以用 Thunderbit 把网页上的 PDF 数据抓取到 Excel 中。
别再为繁琐的手动整理数据发愁了。无论是 Amazon、Zillow 这样的热门网站,还是你想抓取的小众页面, 通常都能在几次点击内把数据整理到 Excel 里。它并不能完美处理开放网络上的每一个网站——反爬很强的页面,以及需要登录会话的网站,仍然需要一些额外设置——但对于日常那种“我只想把这个表放进电子表格里”的任务来说,它大概已经是 2026 年最直接的工作流了。
常见问题
- 我可以用 Thunderbit 从任何网站抓取数据吗?
可以,Thunderbit 允许用户通过自定义指令功能从任何网站抓取数据。用户可以准确指定自己想提取的数据,AI 会相应生成所需输出。
- 我可以用 Thunderbit 抓取哪些类型的数据?
你可以抓取各种类型的数据,包括商品名称、价格、描述、联系方式等。Thunderbit 的 AI 会根据正在抓取的网站内容,建议相关列。
- 我如何导出抓取到的数据?
抓取完成后,你可以轻松将数据导出为 CSV 等格式,或者直接导入 Excel。Thunderbit 还允许你将抓取到的数据同步到 Notion 或 Airtable 等工具中,方便进一步分析。
- 使用网页爬虫工具需要编程技能吗?
不需要——Thunderbit 是本指南从头到尾讲解的唯一工具,它的设计初衷就是无需编写代码即可使用。AI 建议列会帮你选择字段,自定义指令框也支持直接输入自然语言。即使你后来接触到 Octoparse、ParseHub 或基于浏览器的 Web Scraper 这类更早期的无代码工具,了解页面结构的基本概念(列表、表格、分页)会有帮助,但并不是跟着本教程操作的必要条件。
- 使用 Thunderbit 做网页爬虫有哪些场景?
常见场景包括线索开发(例如从大学网站提取院系信息)、电商价格监控(例如跟踪 Amazon 上的竞争对手),以及房地产数据收集(例如整理 Zillow 的房源列表)。
了解更多